

Jest coś ponadczasowego w otwarciu terminala, wpisaniu jednej komendy i obserwowaniu, jak surowe dane z sieci spływają do Ciebie, jakbyś właśnie otworzył Matrix. Dla programistów i zaawansowanych użytkowników technicznych cURL jest właśnie taką magiczną różdżką — niepozornym narzędziem wiersza poleceń, które cicho działa na miliardach urządzeń, od serwerów w chmurze po inteligentne lodówki. I nawet w 2026 roku, mimo całego błyszczącego no-code i narzędzi AI do scrapowania, web scraping z cURL nadal jest jednym z podstawowych sposobów dla każdego, kto chce szybkości, kontroli i możliwości automatyzacji.
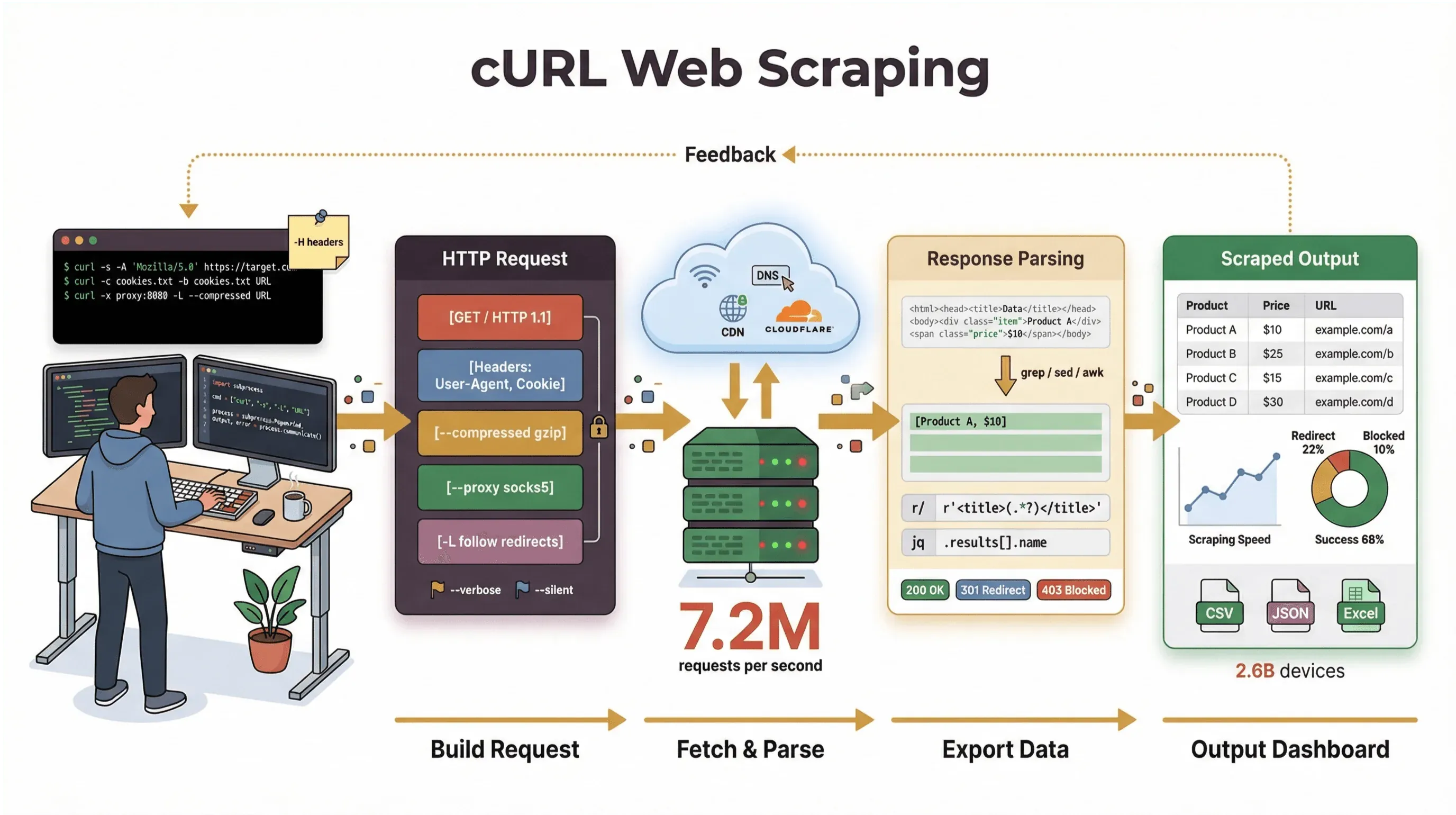 Od lat tworzę narzędzia automatyzujące pracę i pomagam zespołom ogarniać dane z internetu, a po cURL nadal sięgam, gdy muszę pobrać stronę, zdebugować API albo zrobić prototyp workflow do scrapowania. W tym przewodniku przeprowadzę Cię przez tutorial scrapowania stron za pomocą cURL — od podstaw po zaawansowane triki — wraz z realnymi przykładami komend, praktycznymi wskazówkami i trzeźwym spojrzeniem na to, gdzie cURL błyszczy, a gdzie napotyka ścianę. A jeśli jesteś bardziej użytkownikiem biznesowym i wolisz nie dotykać linii poleceń, pokażę Ci, jak Thunderbit, nasz scraper stron internetowych wspierany przez AI, może przenieść Cię od „potrzebuję tych danych” do „oto mój arkusz” w dwa kliknięcia — bez pisania kodu.
Od lat tworzę narzędzia automatyzujące pracę i pomagam zespołom ogarniać dane z internetu, a po cURL nadal sięgam, gdy muszę pobrać stronę, zdebugować API albo zrobić prototyp workflow do scrapowania. W tym przewodniku przeprowadzę Cię przez tutorial scrapowania stron za pomocą cURL — od podstaw po zaawansowane triki — wraz z realnymi przykładami komend, praktycznymi wskazówkami i trzeźwym spojrzeniem na to, gdzie cURL błyszczy, a gdzie napotyka ścianę. A jeśli jesteś bardziej użytkownikiem biznesowym i wolisz nie dotykać linii poleceń, pokażę Ci, jak Thunderbit, nasz scraper stron internetowych wspierany przez AI, może przenieść Cię od „potrzebuję tych danych” do „oto mój arkusz” w dwa kliknięcia — bez pisania kodu.
Zanurzmy się i sprawdźmy, dlaczego cURL wciąż ma znaczenie przy scrapowaniu stron w 2026 roku, jak używać go skutecznie i kiedy czas sięgnąć po coś jeszcze mocniejszego.
Czym jest cURL? Fundament web scrapingu z cURL
W swojej istocie cURL to narzędzie wiersza poleceń i biblioteka do przesyłania danych za pomocą URL-i. Istnieje już od prawie 30 lat (tak, naprawdę) i jest wszędzie — osadzone w systemach operacyjnych, napędzające skrypty i cicho obsługujące transfery danych w ponad dwudziestu miliardach instalacji. Jeśli kiedykolwiek uruchomiłeś szybką komendę, by pobrać stronę, przetestować API albo ściągnąć plik, jest spora szansa, że korzystałeś z cURL.
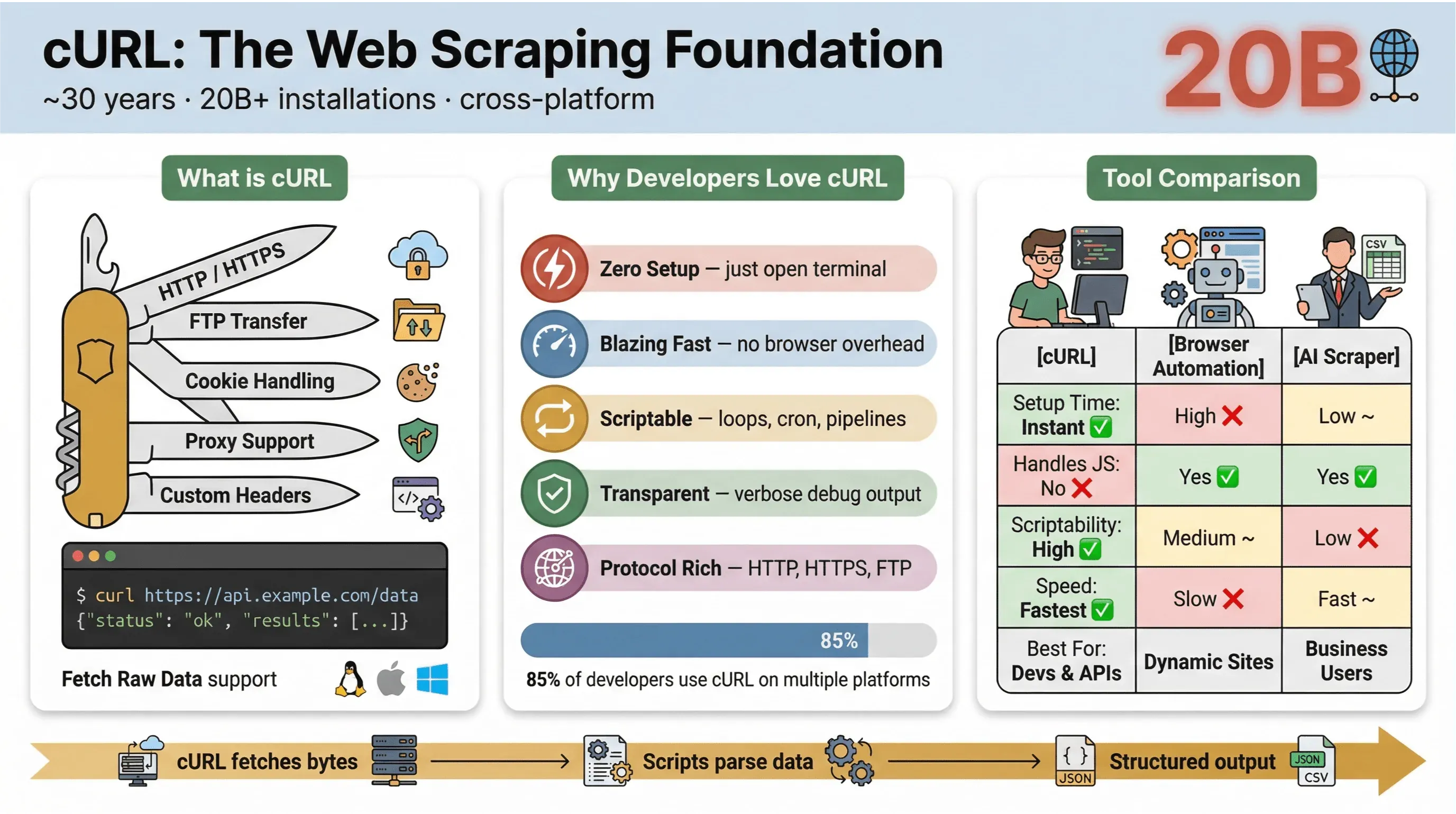 To właśnie dlatego cURL jest tak popularny w web scrapingu:
To właśnie dlatego cURL jest tak popularny w web scrapingu:
- Lekki i wieloplatformowy: Działa na Linuxie, macOS, Windowsie, a nawet na urządzeniach wbudowanych.
- Obsługa protokołów: Radzi sobie z HTTP, HTTPS, FTP i wieloma innymi.
- Możliwość automatyzacji: Idealny do skryptów, zadań cron i „kleju” między narzędziami.
- Bez interakcji z użytkownikiem: Zaprojektowany do pracy nieinteraktywnej — świetny do zadań wsadowych i potoków danych.
Ale bądźmy precyzyjni: głównym zadaniem cURL jest pobieranie surowych danych — HTML, JSON, obrazów, czegokolwiek potrzebujesz. Nie parsuje, nie renderuje ani nie porządkuje tych danych za Ciebie. Myśl o cURL jak o „pierwszym kilometrze” web scrapingu: dostarcza Ci bajty, ale do zamiany ich w uporządkowaną informację potrzebujesz innych narzędzi (np. skryptów Pythona, grep/sed/awk albo AI Web Scrapera).
Jeśli chcesz zajrzeć do oficjalnej dokumentacji, sprawdź przewodnik cURL po skryptowaniu HTTP.
Dlaczego używać cURL do web scrapingu? (tutorial scrapowania z curl)
Więc dlaczego deweloperzy i użytkownicy techniczni wciąż wracają do cURL przy scrapowaniu stron, mimo tylu nowych narzędzi? Oto, co wyróżnia cURL:
- Minimalna konfiguracja: Bez instalacji, bez zależności — po prostu otwierasz terminal i działasz.
- Szybkość: Natychmiastowe pobieranie danych bez czekania, aż uruchomi się przeglądarka.
- Możliwość automatyzacji: Łatwo iterować po URL-ach, automatyzować żądania i łączyć komendy w łańcuchy.
- Obsługa protokołów i funkcji: Obsługa ciasteczek, proxy, przekierowań, własnych nagłówków i nie tylko.
- Przejrzystość: Dokładnie widzisz, co się dzieje, dzięki trybowi verbose/debug.
W ankiecie użytkowników cURL z 2025 roku 85,7% respondentów zadeklarowało, że używa narzędzia cURL w wierszu poleceń, a 96,2% korzysta z niego na Linuxie — nadal to zdecydowanie najważniejsza platforma dla cURL.
--- Nadal jest szwajcarskim scyzorykiem do żądań HTTP, szybkiego pobierania danych i rozwiązywania problemów.
Oto szybkie porównanie cURL z innymi metodami scrapowania:
| Funkcja | cURL | Automatyzacja przeglądarki (np. Selenium) | AI Web Scraper (np. Thunderbit) |
|---|---|---|---|
| Czas konfiguracji | Natychmiast | Wysoki | Niski |
| Możliwość automatyzacji | Wysoka | Średnia | Niska (bez kodu) |
| Obsługa JavaScript | Nie | Tak | Tak (Thunderbit: przez przeglądarkę) |
| Obsługa ciasteczek/sesji | Ręczna | Automatyczna | Automatyczna |
| Strukturyzacja danych | Ręczna (parsowanie później) | Ręczna (parsowanie później) | Oparta na AI / szablonie |
| Najlepsze zastosowanie | Deweloperzy, szybkie pobrania | Złożone, dynamiczne strony | Użytkownicy biznesowi, eksport strukturalny |
Krótko mówiąc: cURL nie ma sobie równych, jeśli chodzi o szybkie, dające się automatyzować pobieranie danych — szczególnie ze stron statycznych, API albo wtedy, gdy chcesz zautomatyzować proste workflow. Ale gdy tylko potrzebujesz parsować złożony HTML, obsłużyć JavaScript albo wyeksportować dane w uporządkowanej formie, przyda Ci się coś bardziej wyspecjalizowanego.
Pierwsze kroki: podstawowe przykłady komend do web scrapingu w cURL
Przejdźmy do praktyki. Oto jak używać cURL do podstawowych zadań związanych ze scrapowaniem stron — krok po kroku.
Pobieranie surowego HTML za pomocą cURL
Najprostszy przypadek użycia: pobranie HTML strony.
curl https://books.toscrape.com/
Ta komenda pobiera stronę główną Books to Scrape, publicznej strony demonstracyjnej do web scrapingu. W terminalu zobaczysz surowy HTML — szukaj tagów takich jak <title> albo fragmentów typu „In stock”.
Zapisywanie wyniku do pliku
Chcesz zachować ten HTML do późniejszego parsowania? Użyj flagi -o:
curl -o page.html https://books.toscrape.com/
Teraz będziesz mieć plik page.html z pełną zawartością HTML. To idealne rozwiązanie do dalszej analizy lub parsowania innymi narzędziami.
Wysyłanie żądań POST za pomocą cURL
Musisz wysłać formularz albo skomunikować się z API? Użyj flagi -d dla żądań POST. Oto przykład z użyciem httpbin, strony stworzonej do testowania HTTP:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
Otrzymasz odpowiedź JSON, która odzwierciedli przesłane dane — świetne do testów i prototypowania.
Podgląd nagłówków i debugowanie
Czasem chcesz zobaczyć nagłówki odpowiedzi albo zdebugować żądanie:
-
Tylko nagłówki (żądanie HEAD):
curl -I https://books.toscrape.com/ -
Nagłówki razem z treścią:
curl -i https://httpbin.org/get -
Szczegółowy wynik debugowania:
curl -v https://books.toscrape.com/
Te flagi pomagają zrozumieć, co dzieje się pod spodem — a to kluczowe przy rozwiązywaniu problemów.
Oto szybka tabela referencyjna dla tych komend:
| Zadanie | Przykład komendy | Uwagi |
|---|---|---|
| Pobranie HTML | curl URL | Wyświetla HTML w terminalu |
| Zapis do pliku | curl -o file.html URL | Zapisuje wynik do pliku |
| Sprawdzenie nagłówków | curl -I URL lub curl -i URL | -I tylko HEAD, -i dodaje nagłówki do treści |
| Wysłanie danych formularza | curl -d "a=1&b=2" URL | Wysyła dane zakodowane jak formularz |
| Debugowanie żądania/odpowiedzi | curl -v URL | Pokazuje szczegółowe informacje o żądaniu i odpowiedzi |
Więcej przykładów znajdziesz w oficjalnej dokumentacji cURL dotyczącej skryptowania.
Wejdź poziom wyżej: zaawansowany web scraping z cURL (web-scraping-with-curl)
Gdy opanujesz podstawy, cURL otwiera przed Tobą cały świat zaawansowanych funkcji przy bardziej złożonych zadaniach scrapowania.
Obsługa ciasteczek i sesji
Wiele stron wymaga ciasteczek, aby utrzymać sesję logowania lub śledzić użytkowników. W cURL możesz zapisywać i ponownie wykorzystywać ciasteczka między żądaniami:
# Zapis ciasteczek po logowaniu
curl -c cookies.txt https://example.com/login
# Użycie ciasteczek w kolejnych żądaniach
curl -b cookies.txt https://example.com/account
Dzięki temu możesz naśladować sesje przeglądarki i uzyskiwać dostęp do stron za logowaniem (o ile nie trzeba rozwiązywać wyzwania JavaScript).
Podszywanie się pod User-Agent i niestandardowe nagłówki
Niektóre strony wyświetlają różne treści w zależności od User-Agent albo nagłówków. Domyślnie cURL identyfikuje się jako „curl/VERSION”, co może wywoływać blokady albo podmianę treści. Aby naśladować przeglądarkę:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
Możesz też ustawić własne nagłówki, na przykład preferencję języka:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
To pomaga uzyskać dokładnie taką treść, jaką zobaczyłaby prawdziwa przeglądarka.
Używanie proxy do web scrapingu
Musisz kierować żądania przez proxy (np. do testów geolokalizacji albo by uniknąć blokad IP)? Użyj flagi -x:
curl -x http://proxy.example.org:4321 https://remote.example.org/
Pamiętaj tylko, by korzystać z proxy odpowiedzialnie i zgodnie z regulaminem strony.
Automatyzacja scrapowania wielu stron
Chcesz scrapować wiele stron — na przykład paginowane listy produktów? Użyj prostego pętli w shellu:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
Ta komenda pobiera strony 2–5 katalogu Books to Scrape i zapisuje każdą do osobnego pliku. (Strona 1 to strona główna.)
Ograniczenia web scrapingu z cURL: co warto wiedzieć
Choć bardzo lubię cURL, nie jest to srebrna kula. Oto, gdzie ma ograniczenia:
- Brak wykonywania JavaScript: cURL nie poradzi sobie ze stronami, które wymagają JavaScriptu do wyrenderowania treści albo rozwiązania zabezpieczeń anty-bot (developers.cloudflare.com).
- Wymagane ręczne parsowanie: Dostajesz surowy HTML albo JSON, ale musisz samodzielnie go przetworzyć — często przy pomocy dodatkowych skryptów lub narzędzi.
- Ograniczona obsługa sesji: Zarządzanie złożonym logowaniem, tokenami czy wieloetapowymi formularzami szybko robi się kłopotliwe.
- Brak wbudowanej strukturyzacji danych: cURL nie zamienia stron internetowych w wiersze, tabele ani arkusze kalkulacyjne.
- Podatność na wykrywanie botów: Wiele stron korzysta dziś z zaawansowanych zabezpieczeń anty-bot (JavaScript, fingerprinting, CAPTCHA), których cURL po prostu nie ominie (datadome.co).
Oto szybka tabela porównawcza:
| Ograniczenie | Sam cURL | Nowoczesne narzędzia do scrapowania (np. Thunderbit) |
|---|---|---|
| Obsługa JavaScript | Nie | Tak |
| Strukturyzacja danych | Ręczna | Automatyczna (AI / szablon) |
| Obsługa sesji | Ręczna | Automatyczna |
| Omijanie anty-bot | Ograniczone | Zaawansowane (na bazie przeglądarki / AI) |
| Łatwość użycia | Techniczne | Dla nietechnicznych |
Do stron statycznych i API cURL sprawdza się znakomicie. Przy czymś bardziej dynamicznym lub chronionym będziesz chciał sięgnąć po bardziej odpowiednie narzędzie.
Thunderbit kontra cURL: najlepsze podejście do web scrapingu dla użytkowników nietechnicznych
Porozmawiajmy teraz o Thunderbit, naszym rozszerzeniu Chrome do scrapowania stron wspieranym przez AI. Jeśli jesteś handlowcem, marketerem albo osobą z działu operacji i po prostu chcesz przenieść dane ze strony do Excela, Google Sheets albo Notion — bez dotykania linii poleceń — Thunderbit jest stworzony dla Ciebie.
Tak wygląda porównanie Thunderbit i cURL:
| Funkcja | cURL | Thunderbit |
|---|---|---|
| Interfejs użytkownika | Wiersz poleceń | Klikanie punktowe (rozszerzenie Chrome) |
| Sugestie pól AI | Nie | Tak (AI czyta stronę i proponuje kolumny) |
| Obsługa paginacji/podstron | Ręczne skryptowanie | Automatyczna (AI wykrywa i scrapuje) |
| Eksport danych | Ręczny (parsowanie + zapis) | Bezpośrednio do Excel, Google Sheets, Notion, Airtable |
| Strony JavaScript / chronione | Nie | Tak (scraping oparty na przeglądarce) |
| Bez kodu wymagane | Nie (wymaga skryptów) | Tak (może go użyć każdy) |
| Darmowy plan | Zawsze darmowy | Darmowy do 6 stron (10 z bonusem próbnym) |
Z Thunderbit po prostu otwierasz rozszerzenie, klikasz „AI Suggest Fields” i pozwalasz AI zdecydować, jakie dane wyciągnąć. Możesz scrapować tabele, listy, szczegóły produktów, a nawet automatycznie odwiedzać podstrony. Potem eksportujesz dane bezpośrednio do ulubionych narzędzi biznesowych — bez parsowania, bez bólu głowy.
Thunderbit cieszy się zaufaniem ponad 100 000 użytkowników na całym świecie i jest szczególnie popularny wśród zespołów sprzedaży, e-commerce i nieruchomości, które szybko potrzebują danych w uporządkowanej formie.
Wypróbuj rozszerzenie Thunderbit do Chrome do scrapowania stron
Chcesz przetestować? Pobierz rozszerzenie Chrome tutaj.
Łączenie cURL i Thunderbit: elastyczne strategie web scrapingu
Jeśli jesteś użytkownikiem technicznym, nie musisz wybierać tylko jednego narzędzia. W praktyce wiele zespołów korzysta z cURL i Thunderbit razem, aby uzyskać maksymalną elastyczność:
- Prototypuj z cURL: Użyj cURL, aby szybko testować endpointy, sprawdzać nagłówki i rozumieć, jak strona odpowiada.
- Skaluj z Thunderbit: Gdy potrzebujesz uporządkowanych danych, scrapowania wielu stron albo powtarzalnego workflow, przejdź na Thunderbit do klikanego wydobywania danych i bezpośrednich eksportów.
Oto przykładowy workflow do badań rynkowych:
- Użyj cURL, aby pobrać kilka stron i sprawdzić strukturę HTML.
- Zidentyfikuj potrzebne pola danych (np. nazwy produktów, ceny, opinie).
- Otwórz Thunderbit, kliknij „AI Suggest Fields” i pozwól AI skonfigurować scraper.
- Zeskrob wszystkie strony (w tym podstrony lub listy z paginacją) i wyeksportuj dane do Google Sheets.
- Analizuj, udostępniaj i wykorzystuj dane — bez ręcznego parsowania.
Oto szybka tabela decyzyjna:
| Scenariusz | Użyj cURL | Użyj Thunderbit | Użyj obu |
|---|---|---|---|
| Szybkie pobranie API lub strony statycznej | ✅ | ||
| Potrzeba uporządkowanych danych w arkuszu | ✅ | ||
| Debugowanie nagłówków / ciasteczek | ✅ | ||
| Scrapowanie dynamicznych stron z dużą ilością JS | ✅ | ||
| Budowa powtarzalnego workflow no-code | ✅ | ||
| Prototypowanie, a potem skalowanie | ✅ | ✅ | Hybrydowy workflow |
Najczęstsze wyzwania i pułapki web scrapingu z cURL
Zanim całkiem rozpędzisz się z cURL, porozmawiajmy o realnych wyzwaniach, które napotkasz:
- Systemy anty-bot: Wiele stron korzysta dziś z zaawansowanych zabezpieczeń (wyzwania JavaScript, CAPTCHA, fingerprinting), których cURL nie ominie (developers.cloudflare.com).
- Problemy z jakością danych: Zmiany w HTML, brakujące pola lub niespójne układy mogą popsuć Twoje skrypty.
- Koszty utrzymania: Za każdym razem, gdy strona się zmienia, musisz aktualizować logikę parsowania.
- Ryzyka prawne i zgodność: Zawsze sprawdzaj regulamin strony, robots.txt i odpowiednie przepisy, zanim zaczniesz scrapować. To, że dane są publiczne, nie znaczy, że można ich używać bez ograniczeń (calawyers.org, polsinelli.com).
- Ograniczenia skalowania: cURL świetnie sprawdza się przy małych zadaniach, ale przy scrapowaniu na dużą skalę musisz ogarniać proxy, limity zapytań i obsługę błędów.
Wskazówki dotyczące debugowania i zgodności:
- Zawsze zaczynaj od stron testowych lub demo (takich jak Books to Scrape).
- Szanuj limity zapytań — nie bombarduj endpointów.
- Unikaj scrapowania danych osobowych, chyba że masz ku temu legalną podstawę.
- Jeśli trafisz na ścianę z JavaScriptem lub CAPTCHA, rozważ przejście na narzędzie oparte na przeglądarce, takie jak Thunderbit.
Podsumowanie krok po kroku: jak scrapować strony internetowe za pomocą cURL
Oto Twoja szybka checklista do web scrapingu z cURL:
- Zidentyfikuj docelowy adres URL: Zacznij od strony statycznej lub endpointu API.
- Pobierz stronę:
curl URL - Zapisz wynik do pliku:
curl -o file.html URL - Sprawdź nagłówki / debuguj:
curl -I URL,curl -v URL - Wyślij dane POST:
curl -d "a=1&b=2" URL - Obsłuż ciasteczka / sesje:
curl -c cookies.txt ...,curl -b cookies.txt ... - Ustaw własne nagłówki / User-Agent:
curl -A "..." -H "..." URL - Śledź przekierowania:
curl -L URL - Używaj proxy (jeśli trzeba):
curl -x proxy:port URL - Zautomatyzuj scrapowanie wielu stron: Użyj pętli w shellu lub skryptów.
- Parsuj i strukturyzuj dane: W razie potrzeby użyj dodatkowych narzędzi / skryptów.
- Przejdź na Thunderbit do uporządkowanego scrapowania bez kodu lub stron dynamicznych.
Wnioski i najważniejsze spostrzeżenia: jak wybrać odpowiednie narzędzie do web scrapingu
Zeskrob dane z dowolnej strony za pomocą AI Get Started Free
Web scraping z cURL nadal jest bardzo przydatną umiejętnością dla użytkowników technicznych w 2026 roku — szczególnie przy szybkim pobieraniu danych, prototypowaniu i automatyzacji. Szybkość, możliwość automatyzacji i powszechność cURL czynią z niego stały element zestawu narzędzi każdego dewelopera. Ale wraz z tym, jak sieć staje się coraz bardziej dynamiczna i zabezpieczona, a użytkownicy biznesowi oczekują uporządkowanych danych bez pisania kodu, narzędzia takie jak Thunderbit wyznaczają nowe standardy.
Najważniejsze wnioski:
- Używaj cURL do stron statycznych, API i szybkiego prototypowania — zwłaszcza gdy chcesz mieć pełną kontrolę.
- Przejdź na Thunderbit (lub podobne AI Web Scrapery), gdy potrzebujesz uporządkowanych danych, obsługi stron dynamicznych / ciężkich od JavaScriptu albo chcesz workflow no-code przyjazny dla biznesu.
- Łącz oba narzędzia, aby uzyskać maksymalną elastyczność: prototypuj z cURL, a skaluj i strukturyzuj dane z Thunderbit.
- Scrapuj odpowiedzialnie — respektuj regulaminy stron, limity zapytań i granice prawne.
Ciekawi Cię, jak łatwy może być web scraping? Wypróbuj darmowe rozszerzenie Thunderbit do Chrome i przekonaj się sam o ekstrakcji danych wspieranej przez AI. A jeśli chcesz pójść dalej, zajrzyj na blog Thunderbit, gdzie znajdziesz więcej poradników, wskazówek i analiz branżowych. Mogą Cię też zainteresować:
- Jak zeskrobać dowolną stronę internetową za pomocą AI
- Jak zeskrobać dane ze strony internetowej do Excela za pomocą AI
- Czym jest data scraping i jak robić to w 2025 roku
Udanych scrapów — i niech Twoje dane zawsze będą czyste, uporządkowane i zawsze na wyciągnięcie jednej komendy (albo kliknięcia).
Sprawdź plany Thunderbit do skalowalnego web scrapingu
FAQ
1. Czy cURL obsługuje strony renderowane przez JavaScript?
Nie, cURL nie potrafi wykonywać JavaScriptu. Pobiera surowy HTML dostarczony przez serwer. Jeśli strona wymaga JavaScriptu do wyrenderowania treści albo rozwiązania zabezpieczeń anty-bot, cURL nie będzie w stanie uzyskać dostępu do tych danych. W takich przypadkach użyj narzędzi opartych na przeglądarce, takich jak Thunderbit.
2. Jak zapisać wynik cURL bezpośrednio do pliku?
Użyj flagi -o: curl -o filename.html URL. Spowoduje to zapisanie treści odpowiedzi do pliku zamiast wyświetlania jej w terminalu.
3. Jaka jest różnica między cURL a Thunderbit w web scrapingu?
cURL to narzędzie wiersza poleceń do pobierania surowych danych z sieci — świetne dla użytkowników technicznych i automatyzacji. Thunderbit to rozszerzenie Chrome wspierane przez AI, stworzone dla użytkowników biznesowych, którzy chcą wyciągać uporządkowane dane z dowolnej strony, obsługiwać strony dynamiczne i eksportować dane bezpośrednio do narzędzi takich jak Excel czy Google Sheets — bez kodu.
4. Czy scrapowanie stron za pomocą cURL jest legalne?
Scrapowanie publicznych danych jest zazwyczaj legalne w USA po ostatnich orzeczeniach sądowych, ale zawsze sprawdzaj regulamin strony, robots.txt i odpowiednie przepisy. Unikaj scrapowania danych osobowych lub chronionych bez zgody i respektuj limity zapytań oraz zasady etyczne (calawyers.org, polsinelli.com).
5. Kiedy powinienem przejść z cURL na bardziej zaawansowane narzędzie, takie jak Thunderbit?
Jeśli musisz scrapować strony dynamiczne / oparte mocno na JavaScripcie, chcesz mieć dane w uporządkowanej formie w arkuszu albo preferujesz workflow no-code, Thunderbit będzie lepszym wyborem. Używaj cURL do szybkich, technicznych zadań; używaj Thunderbit do przyjaznej dla biznesu, powtarzalnej ekstrakcji danych.
Więcej porad i tutoriali dotyczących web scrapingu znajdziesz na blogu Thunderbit albo na naszym kanale YouTube.
Wypróbuj AI Web Scraper Thunderbit Get Started Free




