

„Można mieć dane bez informacji, ale nie można mieć informacji bez danych.” — Daniel Keys Moran*
Najnowsze szacunki wskazują, że w internecie jest ponad 1,5 miliarda stron internetowych, a każdego dnia publikowanych jest około 2 milionów nowych wpisów. W tym oceanie danych kryją się wartościowe informacje, które pomagają podejmować decyzje, ale jest jeden haczyk: około 80% z nich jest nieustrukturyzowane, więc zanim stanie się użyteczne, trzeba je jeszcze przetworzyć. Właśnie tutaj przydają się narzędzia do web scrapingu, które stają się niezbędne dla każdego, kto chce pracować z danymi online.
Jeśli dopiero zaczynasz przygodę z web scrapingiem, terminy takie jak komponenty webowe i HTML mogą brzmieć trochę onieśmielająco. Ale w erze AI te przeszkody są znacznie łatwiejsze do pokonania. Dzisiejsze narzędzia do scrapingu wspierane przez AI pozwalają zacząć bez głębokiej wiedzy technicznej. Umożliwiają szybkie zbieranie i przetwarzanie danych — bez znajomości kodowania.
Najlepsze narzędzia i oprogramowanie do web scrapingu
- Thunderbit — łatwy w użyciu AI Web Scraper z najlepszymi wynikami
- Browse AI — do monitorowania w czasie rzeczywistym i masowego pobierania danych
- Bardeen AI — automatyzacja bez kodu z rozbudowanymi integracjami aplikacji
- Web Scraper — bardziej zaawansowany wizualny web scraping
- Octoparse — wydajny scraping bez kodu, z unikaniem blokad IP i wykrywania botów
- Diffbot — zaawansowane API do ekstrakcji danych wspierane przez AI i grafy wiedzy
Wypróbuj AI w web scrapingu
Wypróbuj! Możesz klikać, eksplorować i uruchamiać proces, obserwując go na bieżąco.
Jak działa web scraping?
Web scraping polega po prostu na pobieraniu danych ze stron internetowych. Wystarczy podać narzędziu zestaw instrukcji, a ono wyciągnie tekst, obrazy lub inne potrzebne informacje do tabeli z danej strony. Przydaje się to wszędzie — od śledzenia cen w e-commerce, przez zbieranie danych do badań, aż po budowanie porządnego arkusza Excel lub Google Sheets.
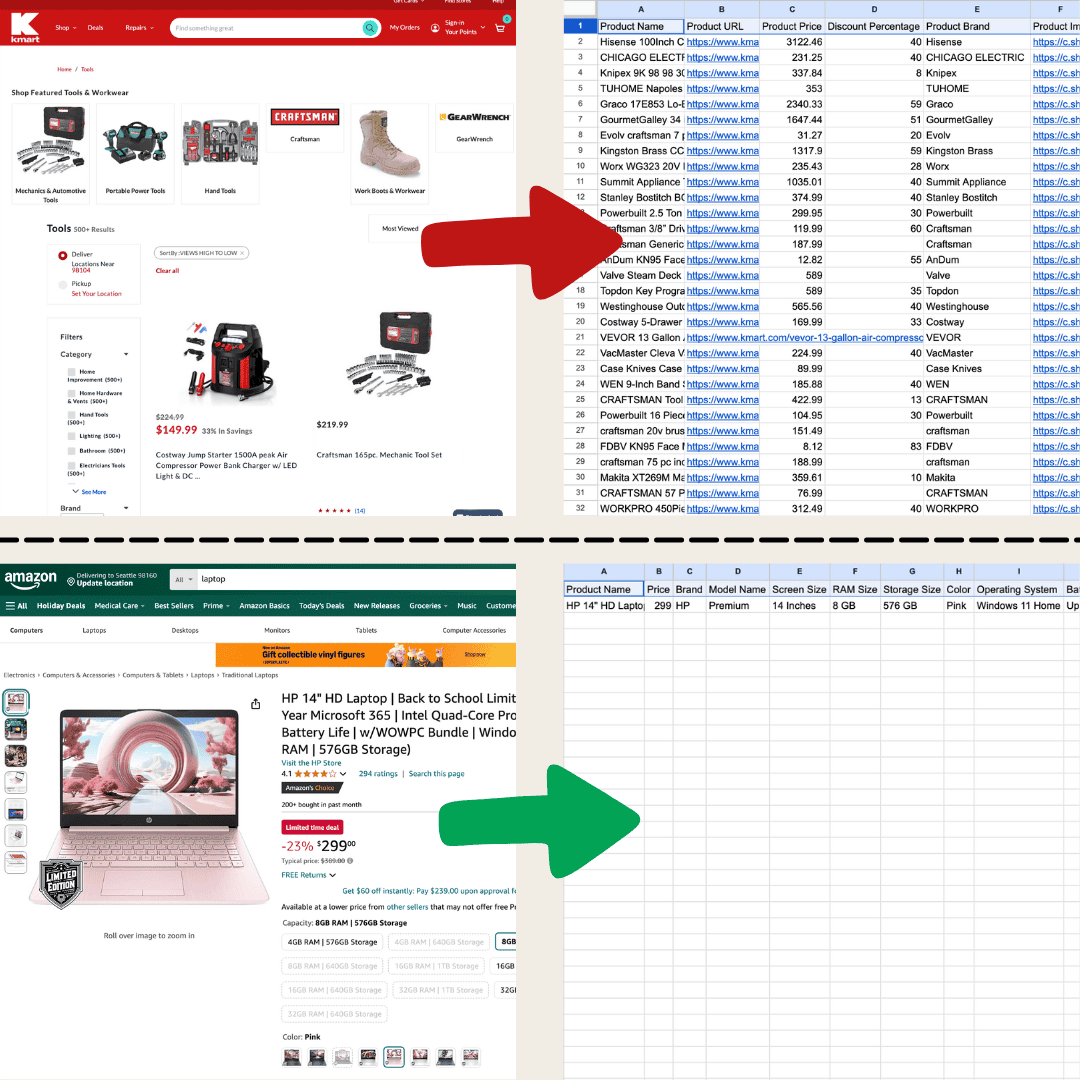 Zrobiłem to w Thunderbit, korzystając z AI Web Scraper.
Zrobiłem to w Thunderbit, korzystając z AI Web Scraper.
Można to zrobić na kilka sposobów. Najprościej byłoby ręcznie kopiować i wklejać dane, ale przy dużej ilości informacji to masa pracy. Dlatego większość osób korzysta z jednej z trzech metod: tradycyjnych scraperów, AI web scraperów albo własnego kodu.
Tradycyjne web scrapery działają na podstawie ściśle określonych reguł dotyczących tego, jakie dane mają pobierać, w oparciu o strukturę strony. Na przykład można ustawić pobieranie nazw produktów lub cen z konkretnych tagów HTML. Najlepiej sprawdzają się na stronach, które nie zmieniają się zbyt często, bo każda modyfikacja układu oznacza konieczność ponownego wejścia do ustawień i poprawienia scrapera.
 Nauka korzystania z tradycyjnego scrapera zajmie sporo czasu, a konfiguracja prawdopodobnie pochłonie dziesiątki kliknięć.
Nauka korzystania z tradycyjnego scrapera zajmie sporo czasu, a konfiguracja prawdopodobnie pochłonie dziesiątki kliknięć.
Wyciągaj dane z dowolnej strony dzięki AI Get Started Free
AI web scrapery można opisać tak: ChatGPT czyta całą stronę, a potem wyciąga treści zgodnie z Twoimi potrzebami. Potrafią jednocześnie pobierać dane, tłumaczyć je i podsumowywać. Wykorzystują przetwarzanie języka naturalnego do analizy i zrozumienia układu strony, dzięki czemu lepiej radzą sobie ze zmianami w serwisie. Jeśli strona trochę przestawi sekcje, AI web scraper może się dostosować bez konieczności przepisywania czegokolwiek. Dlatego świetnie sprawdza się przy stronach wymagających częstych zmian albo bardziej złożonej strukturze.
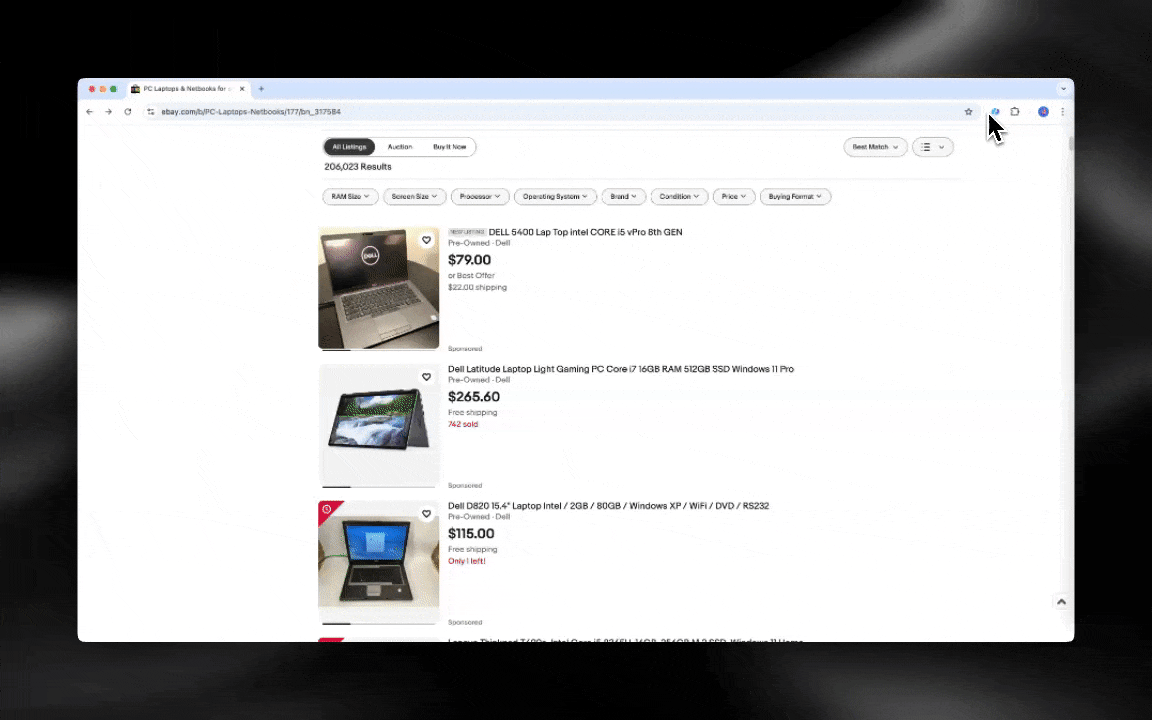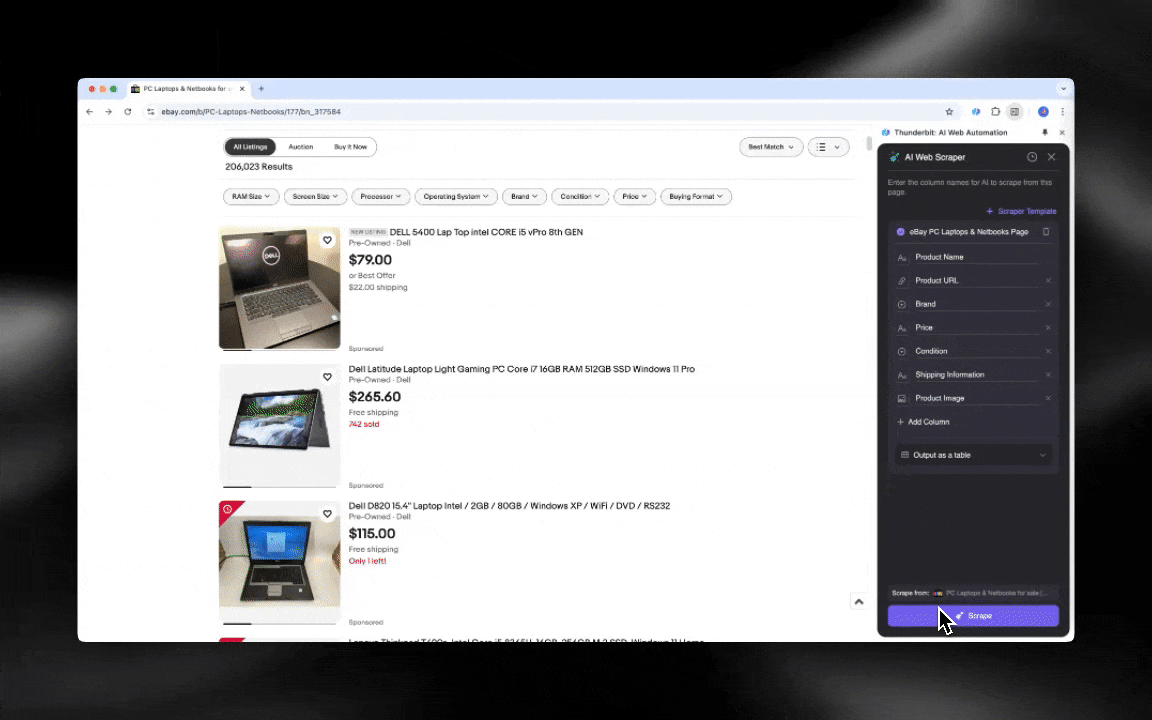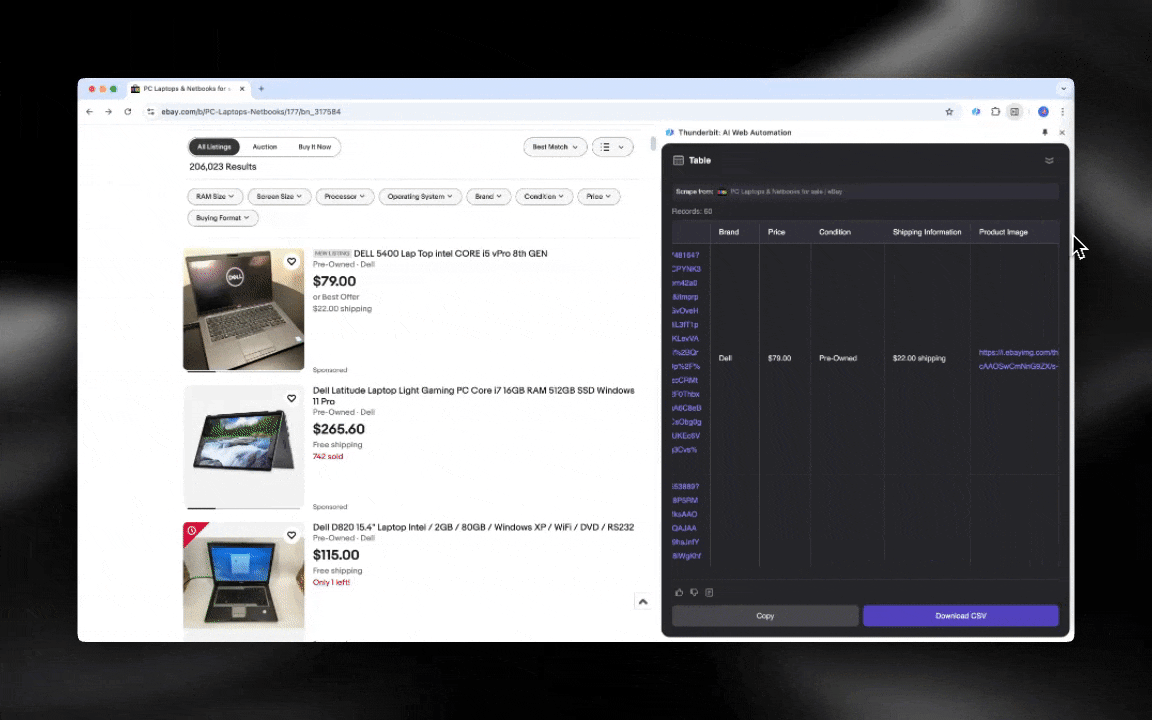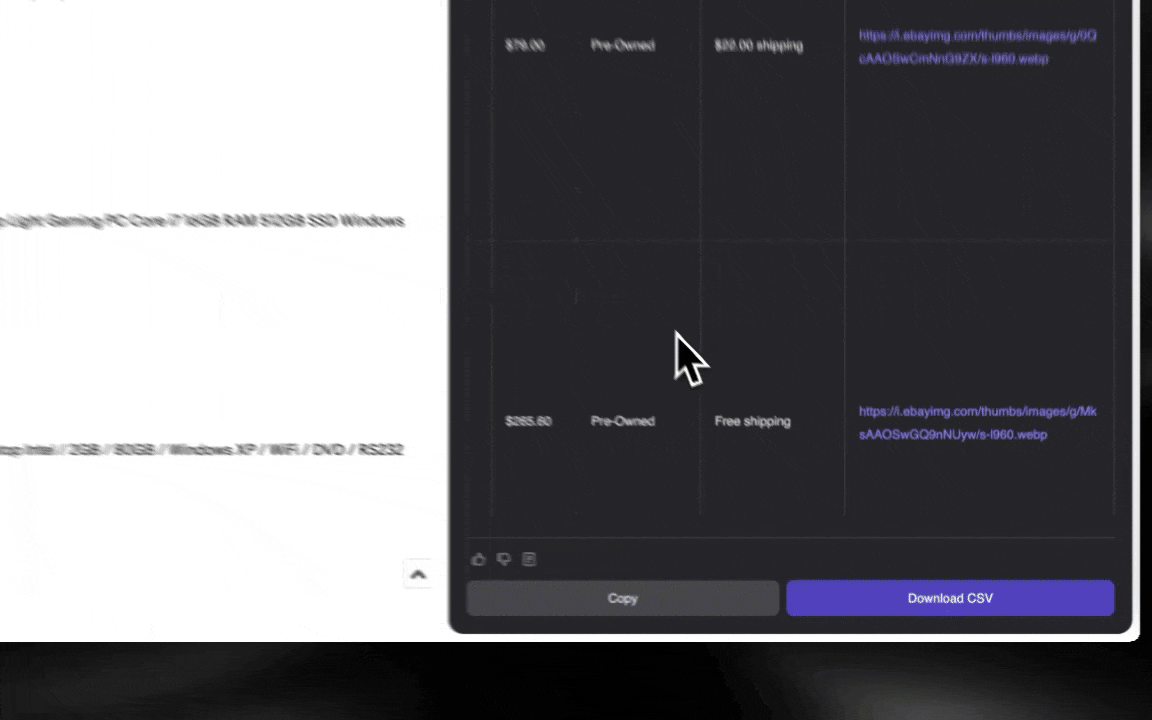 AI web scraper łatwo uruchomić i w kilku kliknięciach uzyskać szczegółowe dane!
AI web scraper łatwo uruchomić i w kilku kliknięciach uzyskać szczegółowe dane!
Który wybrać? To zależy. Jeśli dobrze czujesz się z kodem albo chcesz pobierać duże ilości danych z popularnej strony, tradycyjne scrapery mogą być bardzo wydajne. Jeśli jednak dopiero zaczynasz albo zależy Ci na narzędziu, które poradzi sobie ze zmianami na stronie, AI web scrapery zwykle będą lepszym wyborem. Zobacz tabelę poniżej, aby poznać bardziej szczegółowe scenariusze!
| Scenariusz | Najlepszy wybór |
|---|---|
| Lekkie scrapowanie stron takich jak katalogi, sklepy internetowe lub dowolna strona z listą | AI Web Scraper |
| Strona zawiera mniej niż 200 wierszy danych, a budowa scrapera za pomocą tradycyjnego web scrapera zajmuje zbyt dużo czasu | AI Web Scraper |
| Dane, które chcesz wyciągnąć, muszą mieć określony format, aby można je było załadować gdzie indziej. Na przykład: wyciąganie danych kontaktowych do przesłania do HubSpot. | AI Web Scraper |
| Szeroko używane serwisy na dużą skalę, takie jak dziesiątki tysięcy stron produktów Amazon albo ofert nieruchomości w Zillow. | Tradycyjny Web Scraper |
Najlepsze narzędzia i oprogramowanie do web scrapingu w skrócie
| Narzędzie | Cena | Najważniejsze funkcje | Zalety | Wady |
|---|---|---|---|---|
| Thunderbit | Od 9 USD/mies., dostępny darmowy plan | AI Web Scraper, automatycznie wykrywa i formatuje dane, obsługuje wiele formatów, eksport jednym kliknięciem, przyjazny interfejs. | Bez kodu, wsparcie AI, integracje z aplikacjami takimi jak Google Sheets | Scrapowanie na dużą skalę może być wolne, zaawansowane funkcje mogą kosztować więcej |
| Browse AI | Od 48,75 USD/mies., dostępny darmowy plan | Interfejs bez kodu, monitorowanie w czasie rzeczywistym, masowe pobieranie danych, integracja z workflow. | Przyjazne dla użytkownika, integruje się z Google Sheets i Zapier | Złożone strony wymagają dodatkowej konfiguracji, masowe scrapowanie może powodować timeouty |
| Bardeen AI | Od 60 USD/mies., dostępny darmowy plan | Automatyzacja bez kodu, integracje z ponad 130 aplikacjami, MagicBox zamienia zadania w workflow. | Szerokie możliwości integracji, skalowalne dla firm | Stroma krzywa uczenia dla nowych użytkowników, czasochłonna konfiguracja |
| Web Scraper | Darmowy do użytku lokalnego, 50 USD/mies. za chmurę | Tworzenie zadań wizualnie, obsługa dynamicznych stron (AJAX/JavaScript), scraping w chmurze. | Dobrze działa na stronach dynamicznych | Najlepsza konfiguracja wymaga wiedzy technicznej |
| Octoparse | Od 119 USD/mies., dostępny darmowy plan | Scrapowanie bez kodu, automatyczne wykrywanie elementów strony, scraping w chmurze z zadaniami według harmonogramu, biblioteka szablonów dla popularnych stron. | Potężne funkcje dla stron dynamicznych, radzi sobie z ograniczeniami | Złożone serwisy wymagają nauki |
| Diffbot | Od 299 USD/mies. | API do ekstrakcji danych, API bez reguł, NLP dla nieustrukturyzowanego tekstu, rozbudowany graf wiedzy. | Silna ekstrakcja AI, szerokie integracje API, scrapowanie na dużą skalę | Krzywa uczenia dla osób nietechnicznych, czas konfiguracji |
Najlepszy web scraper w erze AI
Thunderbit
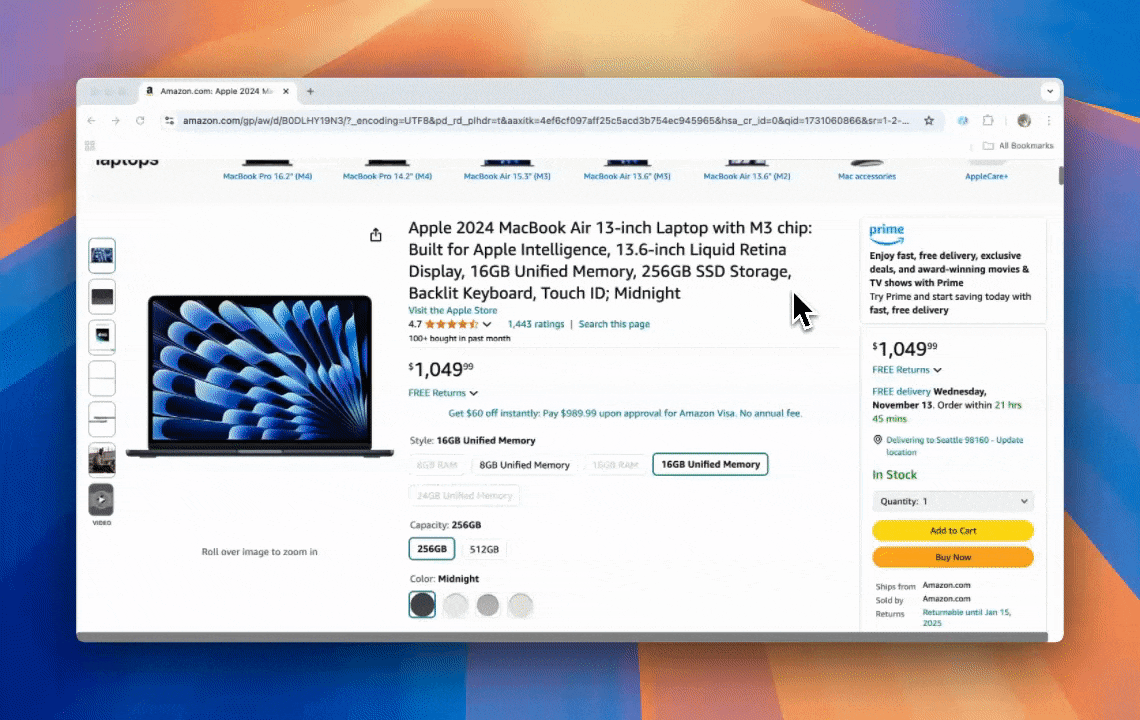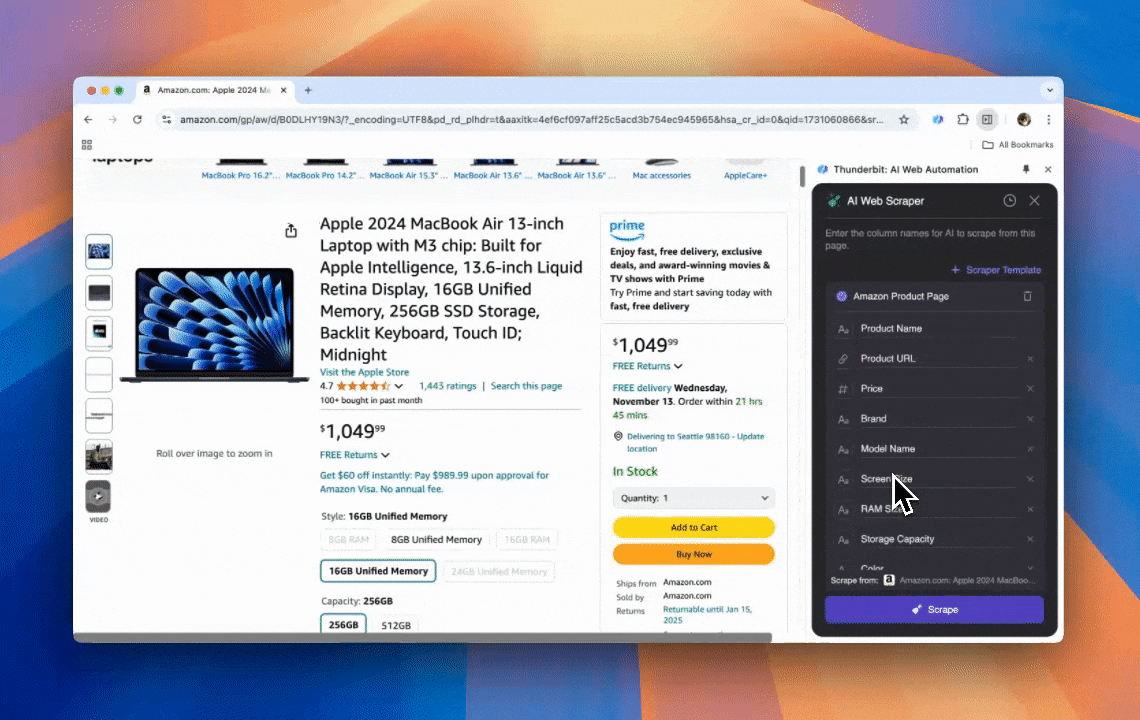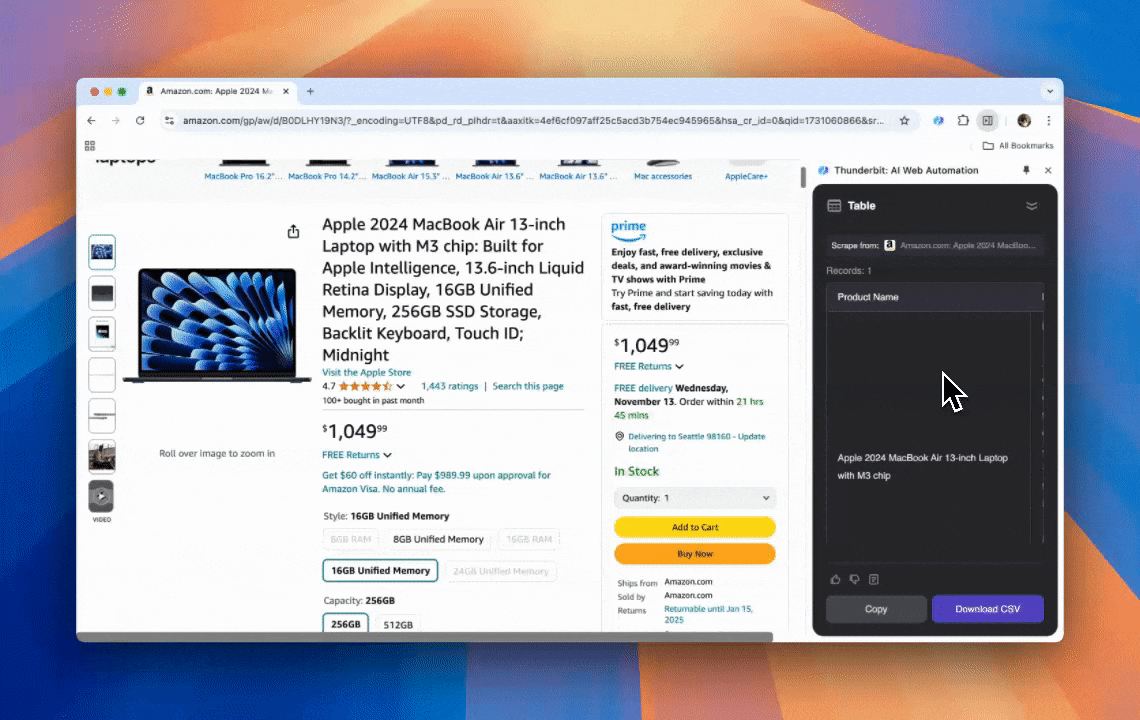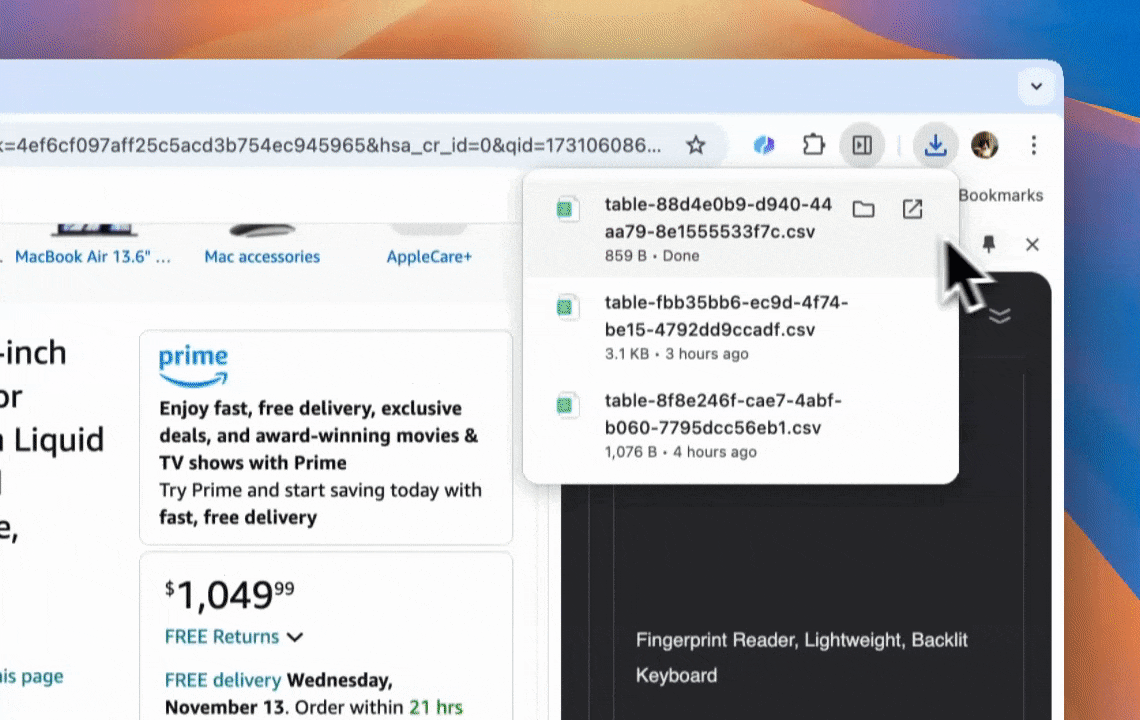
Thunderbit to wydajne, przyjazne użytkownikowi narzędzie do automatyzacji webowej z AI, które pozwala osobom bez umiejętności programowania łatwo wyciągać i porządkować dane. Dzięki rozszerzeniu do Chrome AI Web Scraper od Thunderbit upraszcza scrapowanie danych — użytkownicy mogą szybko pobierać dane ze stron bez ręcznego klikania elementów ani tworzenia osobnych scraperów dla różnych układów stron.
Najważniejsze funkcje
- Elastyczność oparta na AI: AI Web Scraper od Thunderbit automatycznie wykrywa i formatuje dane ze stron, eliminując potrzebę używania selektorów CSS.
- Najprostsze doświadczenie scrapingu: Wystarczy kliknąć „AI suggest column”, a potem „Scrape” na stronie, z której chcesz pobrać dane. Tyle.
- Obsługa różnych formatów danych: Thunderbit może pobierać adresy URL, obrazy i wyświetlać zebrane dane w wielu formatach.
- Automatyczne przetwarzanie danych: AI Thunderbit potrafi na bieżąco zmieniać format danych, w tym je podsumowywać, kategoryzować i tłumaczyć do wymaganego formatu.
- Łatwy eksport danych: Eksportuj dane do Google Sheets, Airtable lub Notion jednym kliknięciem, upraszczając zarządzanie danymi.
- Przyjazny interfejs: Intuicyjny interfejs sprawia, że jest dostępny dla użytkowników na każdym poziomie zaawansowania.
Cennik
Thunderbit oferuje plany warstwowe, zaczynające się od 9 USD miesięcznie za 5 000 kredytów. Najwyższy plan kosztuje 199 USD za 240 000 kredytów. W planie rocznym wszystkie kredyty otrzymujesz z góry.
Zalety:
- Silne wsparcie AI upraszcza ekstrakcję i przetwarzanie danych.
- Bez kodu, dostępne dla użytkowników o każdym poziomie umiejętności.
- Idealne do lekkiego scrapingu, np. katalogów, sklepów internetowych itp.
- Duże możliwości integracji i bezpośredniego eksportu do popularnych aplikacji.
Wady:
- Scrapowanie dużych zbiorów danych może wymagać trochę czasu, aby zapewnić dokładność.
- Niektóre zaawansowane funkcje mogą wymagać płatnej subskrypcji.
Chcesz więcej informacji? Zacznij od zainstalowania Thunderbit albo sprawdź, jak łatwo scrapować strony z Thunderbit.
Najlepszy web scraper do monitorowania danych i masowej ekstrakcji
Browse AI
Browse AI to solidne narzędzie do scrapingu danych bez kodu, stworzone po to, by pomagać użytkownikom wyciągać i monitorować dane bez pisania kodu. Browse AI ma pewne funkcje AI, ale nie dorównuje pełnoprawnym narzędziom do AI scrapingu. Mimo to ułatwia start nowym użytkownikom.
Najważniejsze funkcje
- Interfejs bez kodu: Umożliwia tworzenie własnych workflow za pomocą kilku kliknięć.
- Monitorowanie w czasie rzeczywistym: Korzysta z botów do śledzenia zmian na stronach i dostarczania zaktualizowanych informacji.
- Masowa ekstrakcja danych: Potrafi obsłużyć nawet 50 000 rekordów danych za jednym razem.
- Integracja workflow: Łączy wiele botów w celu bardziej złożonego przetwarzania danych.
Cennik
Plan startuje od 48,75 USD miesięcznie i obejmuje 2 000 kredytów. Dostępny jest darmowy plan z 50 kredytami miesięcznie do wypróbowania podstawowych funkcji.
Zalety:
- Oferuje integracje z Google Sheets i Zapier.
- Gotowe boty upraszczają typowe zadania związane z wyciąganiem danych.
Wady:
- Przy złożonych stronach może być potrzebna dodatkowa konfiguracja.
- Szybkość masowego scrapingu bywa różna, czasem powodując timeouty.
Najlepszy web scraper do integracji workflow
Bardeen AI
Bardeen AI to narzędzie do automatyzacji bez kodu, stworzone po to, by usprawniać workflow poprzez łączenie różnych aplikacji. Choć wykorzystuje AI do tworzenia własnych automatyzacji, nie ma elastyczności pełnoprawnego narzędzia do AI scrapingu.
Najważniejsze funkcje
- Automatyzacja bez kodu: Umożliwia użytkownikom tworzenie workflow za pomocą kliknięć.
- MagicBox: Opisujesz zadania prostym językiem, a Bardeen AI zamienia je w workflow.
- Szerokie możliwości integracji: Integruje się z ponad 130 aplikacjami, w tym Google Sheets, Slack i LinkedIn.
Cennik
Plan zaczyna się od 60 USD miesięcznie i obejmuje 1 500 kredytów (około 1 500 wierszy danych). Darmowy plan oferuje 100 kredytów miesięcznie do wypróbowania podstawowych funkcji.
Zalety:
- Rozbudowane opcje integracji wspierają różnorodne potrzeby biznesowe.
- Elastyczne i skalowalne rozwiązanie dla firm każdej wielkości.
Wady:
- Nowi użytkownicy mogą potrzebować czasu, by poznać całą platformę.
- Początkowa konfiguracja może być czasochłonna.
Najlepszy wizualny web scraper dla osób z doświadczeniem
Web Scraper
Tak, dobrze słyszysz: to narzędzie nazywa się „Web Scraper”. Web Scraper to popularne rozszerzenie do przeglądarek Chrome i Firefox, które pozwala wyciągać dane bez kodowania, oferując wizualny sposób tworzenia zadań scrapingu. Żeby jednak w pełni opanować to narzędzie, możesz potrzebować kilku dni na oglądanie i naukę z powyższych tutoriali. Jeśli chcesz, by scraping był łatwy do ogarnięcia, wybierz AI Web Scraper.
Najważniejsze funkcje
- Tworzenie wizualne: Pozwala użytkownikom konfigurować zadania scrapingu poprzez klikanie elementów strony.
- Obsługa dynamicznych stron: Radzi sobie z żądaniami AJAX i JavaScript na dynamicznych stronach.
- Scraping w chmurze: Umożliwia planowanie zadań przez Web Scraper Cloud dla okresowego scrapingu.
Cennik
Darmowy do użytku lokalnego; płatne plany zaczynają się od 50 USD miesięcznie za funkcje chmurowe.
Zalety:
- Dobrze działa na stronach dynamicznych.
- Darmowy do użytku lokalnego.
Wady:
- Najlepsza konfiguracja wymaga wiedzy technicznej.
- Zmiany wymagają dokładnego testowania.
Najlepszy web scraper z ochroną przed blokadą IP i wykrywaniem botów
Octoparse
Octoparse to wszechstronne oprogramowanie dla bardziej technicznych użytkowników, umożliwiające zbieranie i monitorowanie konkretnych danych ze stron bez kodu — idealne do potrzeb związanych z dużą skalą danych. Octoparse nie działa w oparciu o przeglądarkę użytkownika; zamiast tego korzysta z serwerów chmurowych do scrapowania danych. Dzięki temu oferuje różne metody omijania blokad IP i niektórych mechanizmów wykrywania botów na stronach.
Najważniejsze funkcje
- Obsługa bez kodu: Użytkownicy mogą tworzyć zadania scrapingu bez pisania kodu, co czyni narzędzie dostępnym dla osób o różnym poziomie technicznym.
- Inteligentne automatyczne wykrywanie: Automatycznie wykrywa dane na stronie, szybko identyfikując elementy dostępne do scrapowania i upraszczając konfigurację.
- Scraping w chmurze: Obsługuje całodobowy scraping danych w chmurze oraz zadania według harmonogramu, zapewniając elastyczne pobieranie danych.
- Rozbudowana biblioteka szablonów: Oferuje setki gotowych szablonów, dzięki którym użytkownicy mogą szybko pobierać dane z popularnych stron bez skomplikowanej konfiguracji.
Cennik
Plan cenowy Octoparse zaczyna się od 119 USD miesięcznie i obejmuje 100 zadań. Dostępny jest też darmowy plan z 10 zadaniami miesięcznie do testowania podstawowej funkcjonalności.
Zalety:
- Potężne funkcje wspierają scrapowanie dynamicznych stron z dużą elastycznością.
- Zapewnia rozwiązania dla ograniczeń scrapingu i problemów z dynamiczną treścią.
Wady:
- Złożone struktury stron mogą wymagać więcej czasu na konfigurację.
- Nowi użytkownicy mogą potrzebować czasu, aby nauczyć się obsługi.
Najlepszy web scraper do zaawansowanego API do ekstrakcji danych wspieranego przez AI
Diffbot
Diffbot to zaawansowane narzędzie do ekstrakcji danych ze stron, które wykorzystuje AI do przekształcania nieustrukturyzowanych treści webowych w dane ustrukturyzowane. Dzięki potężnym API i grafowi wiedzy Diffbot pomaga użytkownikom wyciągać, analizować i zarządzać informacjami z internetu, sprawdzając się w różnych branżach i zastosowaniach.
Najważniejsze funkcje
- API do ekstrakcji danych: Diffbot oferuje API do ekstrakcji danych bez reguł, dzięki czemu użytkownik może po prostu podać URL, a dane zostaną pobrane automatycznie — bez potrzeby ustawiania własnych reguł dla każdej strony.
- API przetwarzania języka naturalnego: Wyciąga z nieustrukturyzowanego tekstu ustrukturyzowane encje, relacje i sentyment, pomagając użytkownikom budować własne grafy wiedzy.
- Graf wiedzy: Diffbot posiada jeden z największych grafów wiedzy, łączący rozbudowane dane o encjach, w tym informacje o osobach i organizacjach.
Cennik
Plan cenowy Diffbot zaczyna się od 299 USD miesięcznie i obejmuje 250 000 kredytów (co odpowiada mniej więcej 250 000 ekstrakcjom stron opartym na API).
Zalety:
- Silne możliwości ekstrakcji danych bez reguł i wysoka elastyczność.
- Rozbudowane opcje integracji API, ułatwiające łączenie z istniejącymi systemami.
- Obsługuje scrapowanie na dużą skalę, odpowiednie dla zastosowań korporacyjnych.
Wady:
- Początkowa konfiguracja może wymagać czasu na naukę dla osób nietechnicznych.
- Aby korzystać z API, trzeba napisać program, który je wywoła.
Do czego możesz używać scraperów?
Jeśli dopiero zaczynasz przygodę z web scrapingiem, poniżej znajdziesz kilka popularnych zastosowań, które pomogą Ci wystartować. Wiele osób używa scraperów do pobierania ofert produktów z Amazon, wyciągania danych o nieruchomościach z Zillow albo zbierania informacji o firmach z Google Maps. Ale to dopiero początek — możesz użyć Thunderbit AI Web Scraper, by pobierać dane z niemal każdej strony, usprawniając zadania i oszczędzając czas w codziennym workflow. Niezależnie od tego, czy chodzi o badania, śledzenie cen czy budowanie baz danych, web scraping otwiera niezliczone sposoby wykorzystania danych z internetu.
FAQ
-
Czy web scraping jest legalny?
Web scraping jest zwykle legalny, ale musi być zgodny z regulaminem strony i charakterem pobieranych danych. Zawsze sprawdzaj odpowiednie zasady i przestrzegaj wymogów prawnych.
-
Czy do korzystania z narzędzi do web scrapingu potrzebne są umiejętności programowania?
Większość opisanych tutaj narzędzi nie wymaga umiejętności programowania, ale narzędzia takie jak Octoparse i Web Scraper mogą działać lepiej, jeśli użytkownik ma podstawową wiedzę o strukturze stron i myślenie programistyczne.
-
Czy istnieją darmowe narzędzia do web scrapingu?
Tak, dostępne są darmowe narzędzia, takie jak BeautifulSoup, Scrapy i Web Scraper, a niektóre narzędzia oferują też darmowe plany z ograniczoną funkcjonalnością.
-
Jakie są najczęstsze wyzwania w web scrapingu?
Do najczęstszych wyzwań należą obsługa dynamicznej treści, CAPTCHA, blokady IP i złożone struktury HTML. Zaawansowane narzędzia i techniki mogą skutecznie rozwiązywać te problemy.
Dowiedz się więcej:
Korzystaj z AI i pracuj bez wysiłku. Get Started Free




