
Scraping Facebooka wciąż ma sens w 2026 roku, ale tylko wtedy, gdy wybierzesz odpowiedni model pozyskiwania danych. Pew Research Center podał 20 listopada 2025 r., że 71% dorosłych w USA korzysta z Facebooka, a Meta poinformowała 29 kwietnia 2026 r., że jej rodzina aplikacji osiągnęła 3,56 miliarda dziennych aktywnych użytkowników w marcu 2026 roku. Taka skala sprawia, że Facebook nadal jest przydatny do monitorowania Marketplace, badania publicznych stron, pozyskiwania leadów i śledzenia konkurencji. Problem nie polega na znalezieniu zastosowań. Prawdziwe wyzwanie to zdobycie czystych danych bez utknięcia na ekranach logowania, dynamicznym ładowaniu, tymczasowych blokadach czy kruchych konfiguracjach scrapingu.
Ta coroczna lista została przygotowana z myślą o szybkim podejmowaniu decyzji. 8 maja 2026 r. sprawdziłem ponownie oficjalne strony produktów, dokumentację i sygnały cenowe, a potem zawęziłem wybór do narzędzi, które nadal mają sens dla realnych użytkowników biznesowych. Jeśli Twój proces to głównie „weź dane z tej strony i wyślij je do arkusza”, zacznij od Thunderbit. Jeśli potrzebujesz infrastruktury na skalę API, Bright Data, Apify i Nimble by Nimbleway powinny znaleźć się wysoko na liście. Jeśli Twoja praca obejmuje automatyzacje w chmurze lub działania następcze po zebraniu danych, PhantomBuster zasługuje na bliższe spojrzenie.
Szybkie wybory według zadania
- Potrzebujesz najszybszego eksportu z Facebooka lub Marketplace bez kodu? Zacznij od Thunderbit.
- Potrzebujesz skali API dla firm i zarządzanego odblokowywania? Zawęź wybór do Bright Data.
- Potrzebujesz elastycznych workflow do scrapingu w chmurze? Przyjrzyj się Apify.
- Potrzebujesz pozyskiwania danych publicznych z podejściem API-first i mniejszą potrzebą utrzymania scrapera? Rozważ Nimble by Nimbleway.
- Potrzebujesz budżetowego API do lżejszych zadań? ScrapingBot nadal ma znaczenie.
- Potrzebujesz scrapingu połączonego z automatyzacją workflow? PhantomBuster będzie lepszym wyborem.
- Potrzebujesz wizualnego kreatora workflow z harmonogramem? Octoparse pozostaje solidną opcją no-code.
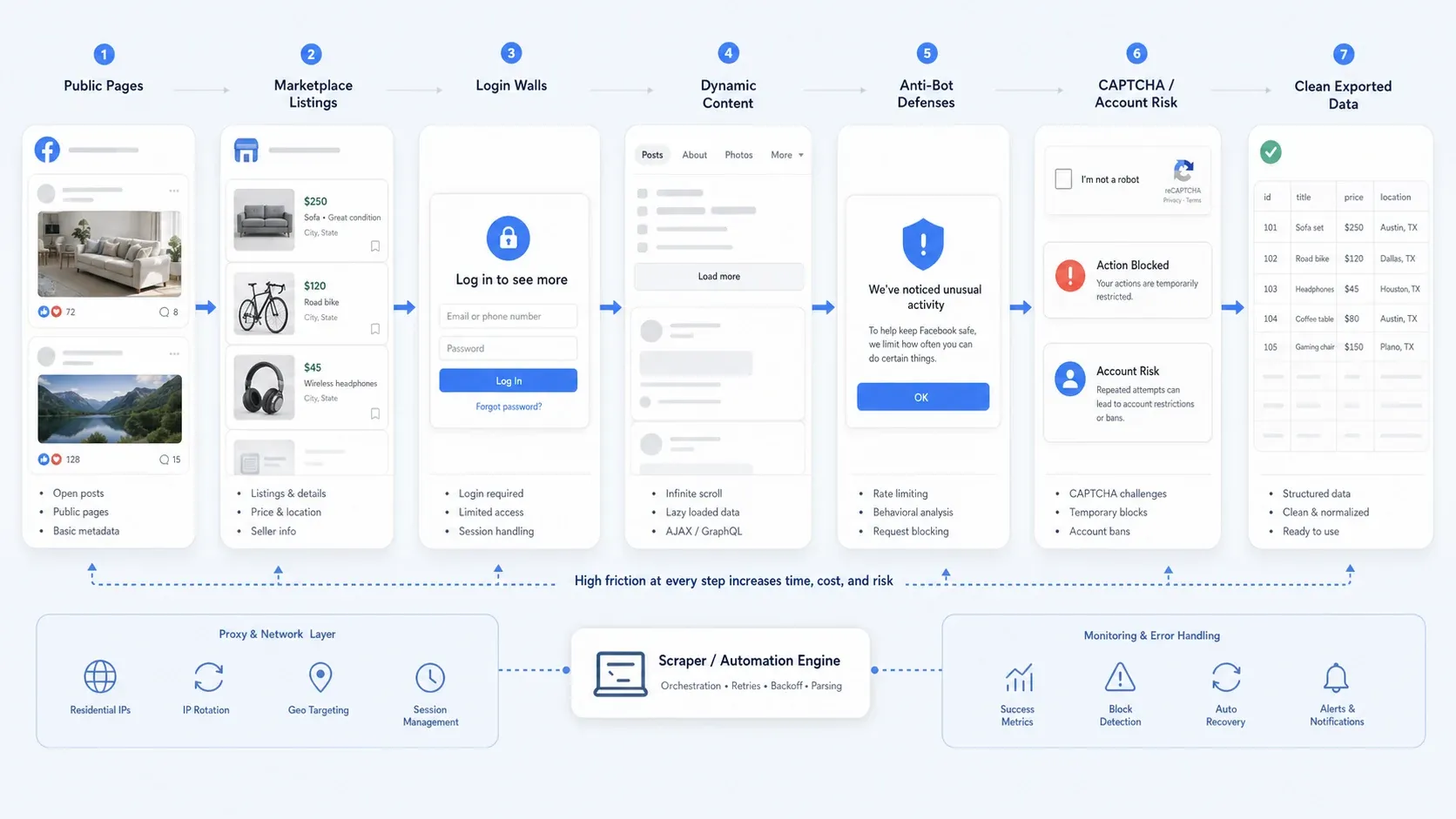
Dlaczego scraping Facebooka nadal jest trudny w 2026 roku
Pozyskiwanie danych z Facebooka rzadko sprowadza się już tylko do problemu selektorów. W praktyce większość zespołów napotyka jeden lub kilka z tych problemów:
- Częściowy dostęp publiczny: część stron pozostaje publiczna, ale inne przepływy prowadzą do logowania, jeśli chcesz zobaczyć więcej szczegółów.
- Dynamiczna treść: widoki Marketplace, długie wątki komentarzy i zawartość stron często ładują się stopniowo.
- Ochrona anty-botowa: limity zapytań, kontrole zachowania, CAPTCHA i tymczasowe blokady akcji psują proste automatyzacje.
- Ryzyko operacyjne: zbieranie danych po zalogowaniu jest znacznie bardziej ryzykowne niż scraping publicznych stron, zwłaszcza jeśli zależy Ci na bezpieczeństwie konta i powtarzalności.
Jak oceniłem te narzędzia
Ten artykuł zoptymalizowałem pod kątem szybkiego budowania shortlisty, a nie dopisywania sztucznych funkcji. Narzędzia porównywałem według:
- Dopasowania do workflow: czy produkt naprawdę pasuje do zadań związanych z Facebookiem i Marketplace, które wykonują realne zespoły?
- Łatwości użycia: czy osoby nietechniczne albo małe zespoły mogą szybko uzyskać użyteczny wynik?
- Skali i niezawodności: czy narzędzie nadal ma sens, gdy wykraczamy poza jednorazowy scraping?
- Obsługi anty-botów i sesji: ile problemów z infrastrukturą produkt usuwa?
- Jakości wyników: czy da się bez większego czyszczenia wprowadzić dane do CSV, Sheets albo systemów downstream?
- Sygnału cenowego: czy produkt jest praktyczny do oceny, czy wymaga ciężkiego procesu enterprise?
- Podejścia do zgodności: czy narzędzie wyraźnie stawia na zbieranie danych publicznych i odpowiedzialne użycie?
Jakiego typu scrapera Facebooka potrzebujesz?
Najszybszy sposób, by dobrze wybrać, to najpierw wybrać właściwą kategorię. Narzędzia do scrapingu Facebooka zwykle mieszczą się w czterech modelach działania:
- Narzędzia browserowe bez kodu: najlepsze, gdy chcesz szybko wyciągnąć dane ze strony, którą już masz otwartą.
- API do scrapingu: najlepsze, gdy potrzebujesz niezawodnego, powtarzalnego pozyskiwania danych na większą skalę.
- Workflow automatyzacji: najlepsze, gdy scraping jest tylko jednym krokiem szerszego procesu go-to-market.
- Własne zestawy dla developerów: najlepsze, gdy zespół chce mieć maksymalną kontrolę i jest gotowy przejąć ciężar utrzymania.
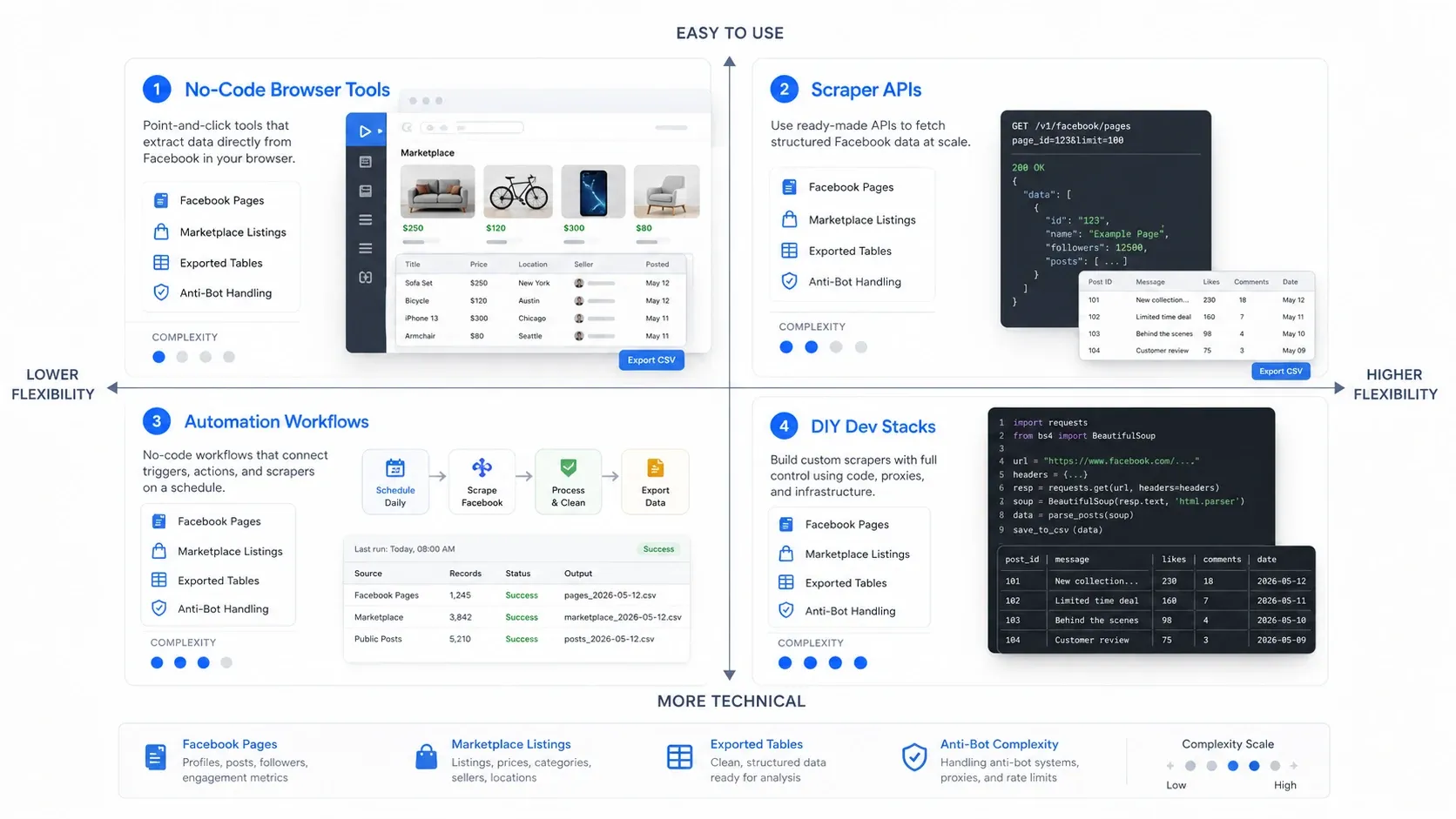
Tabela porównawcza
| Narzędzie | Najlepsze do | Dlaczego trafiło na shortlistę | Sygnał cenowy |
|---|---|---|---|
| Thunderbit | Zespoły nietechniczne i szybkie zadania doraźne | AI wykrywa pola, obsługa dynamicznych stron w przeglądarce, szybki eksport | Darmowy okres próbny; płatne plany oparte na kredytach |
| Bright Data | Duże pipeline’y danych społecznościowych publicznych | Dedykowane API do scrapingu social mediów, zarządzane odblokowywanie, duża skala | Cennik zależny od użycia i ofert enterprise |
| Apify | Elastyczne workflow scrapingu w chmurze | Gotowe aktory Facebooka, harmonogramy, dostęp do API, możliwość dostosowania | Płatne plany platformy plus rozliczanie użycia |
| Nimble by Nimbleway | Pozyskiwanie danych publicznych w modelu API-first | Workflow API oparty na URL i mniejszy ciężar utrzymania scrapera | Cennik prowadzony przez dział sprzedaży |
| ScrapingBot | Małe zadania z danymi publicznymi i prototypy | Proste API, obsługa renderowania, niższy próg wejścia cenowego | Darmowy plan; płatne od około 22 USD/mies. |
| PhantomBuster | Automatyzacje workflow GTM | Automatyzacje w chmurze, workflow akcji w przeglądarce, dobre dopasowanie do lead gen | Darmowy okres próbny; płatne plany od około 56 USD/mies. |
| Octoparse | Wizualny scraping no-code z harmonogramem | Kreator typu point-and-click, ekstrakcja w chmurze, powtarzalne workflow | Darmowy plan; płatne od około 119 USD/mies. |
1. Thunderbit
Thunderbit to najsilniejszy wybór, jeśli chcesz szybko zamienić stronę Facebooka lub listę wyników Marketplace w uporządkowane dane bez budowania i utrzymywania scrapera. Jego kluczową przewagą jest semantyczna ekstrakcja: narzędzie czyta stronę, sugeruje przydatne pola i pozwala wyeksportować wynik bez walki z selektorami, proxy czy kodem.
Dlaczego się wyróżnia:
- AI Suggest Fields: Thunderbit rozpoznaje prawdopodobne pola, takie jak tytuł, cena, sprzedawca, lokalizacja, dane kontaktowe i adresy URL.
- Obsługa natywna dla przeglądarki: ponieważ działa tam, gdzie renderuje się strona, dobrze radzi sobie z dynamicznymi stronami przewijanymi w nieskończoność.
- Wzbogacanie podstron: możesz najpierw zebrać dane listy, a potem otworzyć każdą ofertę lub stronę po więcej szczegółów.
- Przydatne eksporty: Excel, Google Sheets, Airtable i Notion to naturalne miejsca docelowe.
Jeśli chcesz obejrzeć jedno wideo przed samodzielnym testem workflow natywnego dla przeglądarki, ten praktyczny przewodnik po Thunderbit to najlepszy punkt startowy, bo pokazuje faktyczny proces ekstrakcji zamiast pozostawać na poziomie obietnic funkcji:
Najlepsze dla: użytkowników nietechnicznych, zespołów sprzedaży, operatorów i badaczy, którzy chcą szybkich wyników.
Sygnał cenowy: dostępny darmowy okres próbny; płatne plany oparte na kredytach. Sprawdź oficjalny cennik.
Uruchom darmową próbkę danych z Facebooka
2. Bright Data
Bright Data to wybór nastawiony przede wszystkim na infrastrukturę. Według dokumentacji Bright Data jego Social Media Scraper APIs obejmują 10 platform i 68 dedykowanych endpointów, w tym Facebooka. Jeśli Twoim zadaniem jest pozyskiwanie danych publicznych na dużą skalę, taki zarządzany stos API jest zwykle bardziej realistyczny niż próba skalowania rozszerzenia do przeglądarki albo ręcznie napisanego scrapera.
Dlaczego trafiło na shortlistę:
- Dedykowane endpointy do scrapingu social mediów
- Zarządzane odblokowywanie i ekstrakcja
- Strukturalne dostarczanie wyników do pipeline’ów danych
- Lepsze dopasowanie do monitoringu i analityki wymagających niezawodności
Najlepsze dla: analityków, zespołów danych, dużych projektów monitoringu i publicznych zbiorów danych społecznościowych na dużą skalę.
Sygnał cenowy: cena zależy od produktu i wolumenu. Sprawdź aktualny cennik Bright Data.
3. Apify
Apify nadal jest ważne, bo daje dobry środek między gotowymi szablonami a pełną personalizacją. Jego aktor Facebook Pages Scraper to użyteczny punkt startowy, a szersza platforma Apify zapewnia uruchamianie w chmurze, harmonogramy, API i przestrzeń do rozbudowy workflow, gdy potrzeby stają się bardziej złożone.
Dlaczego znalazło się na liście:
- Gotowe aktory Facebooka
- Uruchamianie w chmurze i cykliczne harmonogramy
- Elastyczne eksporty i dostęp do API
- Łatwiejsza rozbudowa niż w czysto no-code workflow w przeglądarce
Najlepsze dla: marketerów technicznych, agencji, zespołów operacyjnych i cyklicznych zadań zbierania danych z wielu stron.
Sygnał cenowy: plany platformy są płatne, a użycie aktorów jest rozliczane osobno. Sprawdź cennik Apify.
4. Nimble by Nimbleway
Nimble by Nimbleway to opcja API-first dla zespołów, które chcą po prostu podać URL, a platforma ma zająć się dostępem, renderowaniem i dostarczeniem danych. Nimble pozycjonuje swoje Web Scraper API jako kompleksowe pozyskiwanie danych publicznych z sieci, co czyni je przydatnym, gdy scraping Facebooka jest tylko częścią większego stosu danych.
Dlaczego warto je ocenić:
- Workflow API oparty na URL
- Mniejszy ciężar utrzymania scrapera dla zespołów inżynieryjnych
- Dobre dopasowanie do odpornej ekstrakcji danych publicznych z sieci
- Przydatne, gdy dane ze scrapingu zasilają produkty wewnętrzne lub dashboardy
Najlepsze dla: zespołów prowadzonych przez inżynierię, pipeline’ów danych produktowych i organizacji, które chcą abstrakcji infrastruktury zamiast pojedynczych narzędzi.
Sygnał cenowy: Nimble nie eksponuje publicznego cennika self-serve na stronach głównego API, więc należy spodziewać się wyceny prowadzonej przez sprzedaż i sprawdzić szczegóły bezpośrednio z Nimble by Nimbleway.
5. ScrapingBot
ScrapingBot to budżetowa opcja API na tej liście. Nie jest to najbardziej wyspecjalizowana platforma Facebookowa, ale nadal ma sens przy mniejszych zadaniach z danymi publicznymi, gdy potrzebujesz API, wsparcia renderowania i niższego progu kosztowego niż w enterprise’owej infrastrukturze scrapingu.
Gdzie pasuje:
- Prosty scraping publiczny sterowany przez API
- Niższy próg wejścia cenowego
- Renderowanie i obsługa proxy w zestawie
- Lepsze do prototypów i lekkich cyklicznych pobrań niż do dużych programów analitycznych
Najlepsze dla: startupów, małych firm i developerów testujących lżejsze przypadki użycia zbierania danych z publicznych stron.
Sygnał cenowy: dostępny darmowy plan; obecna publiczna strona cenowa zaczyna płatne plany od około 22 USD/mies..
6. PhantomBuster
PhantomBuster mniej koncentruje się na samej infrastrukturze scrapingu, a bardziej na tym, co dzieje się po zebraniu danych. Jeśli Twój przypadek użycia brzmi „zbierz dane, a potem uruchom outreach, enrichment albo działania follow-up”, PhantomBuster często będzie bardziej użyteczny niż zwykły ekstraktor, bo został zaprojektowany wokół automatyzacji w chmurze i workflow akcji w przeglądarce.
Dlaczego zespoły nadal go rozważają:
- Automatyzacje workflow oparte na chmurze
- Przydatne do lead generation i operacji GTM
- Lepsze dopasowanie, gdy scraping jest tylko jednym krokiem szerszego procesu
- Praktyczne dla operatorów, którym zależy na działaniach, a nie tylko na eksportach
Najlepsze dla: zespołów GTM, growth, rekruterów i operatorów łączących zbieranie danych z działaniami downstream.
Sygnał cenowy: dostępny darmowy okres próbny; płatne plany na aktualnej stronie cenowej zaczynają się od około 56 USD/mies..
7. Octoparse
Octoparse pozostaje jednym z lepszych wizualnych narzędzi no-code do scrapingu dla osób, które chcą powtarzalnych workflow i zaplanowanych uruchomień w chmurze. Nie jest tak lekkie jak Thunderbit do szybkich jednorazowych zadań na Facebooku, ale daje osobom nietechnicznym bardziej jawne sterowanie tym, jak logika ekstrakcji jest budowana i powtarzana.
Dlaczego pozostaje istotne:
- Wizualny kreator workflow typu point-and-click
- Ekstrakcja w chmurze i planowanie zadań
- Dobre do strukturalnych, powtarzalnych zadań
- Lepiej pasuje do analityków, którzy chcą powtarzalności bez kodu
Najlepsze dla: analityków nietechnicznych, zespołów operacyjnych SMB i powtarzalnych zadań zbierania danych z bardziej jawnie zdefiniowaną logiką workflow.
Sygnał cenowy: publiczna strona cenowa Octoparse pokazuje płatne plany od około 119 USD/mies..
Shortlista według zespołu
Jeśli już wiesz, jaki zespół będzie właścicielem workflow, zacznij tutaj:
- Samodzielny operator lub mała firma: Thunderbit, ScrapingBot lub Octoparse
- Zespół sprzedaży / GTM: Thunderbit lub PhantomBuster
- Analityk operacyjny: Thunderbit, Apify lub Octoparse
- Zespół automatyzacji growth: PhantomBuster lub Apify
- Zespół data engineering: Bright Data, Nimble lub Apify

Jak wybrać właściwego scrapera Facebooka
- Wybierz Thunderbit, jeśli szybkość i prostota są ważniejsze niż maksymalna skala.
- Wybierz Bright Data, jeśli potrzebujesz skali danych publicznych i zarządzanej niezawodności.
- Wybierz Apify, jeśli chcesz elastycznej platformy i workflow opartych na aktorach.
- Wybierz Nimble, jeśli chcesz abstrakcji API-first z mniejszym utrzymaniem scrapera.
- Wybierz PhantomBuster, jeśli scraping jest tylko jednym krokiem w szerszym workflow automatyzacji GTM.
- Wybierz Octoparse, jeśli chcesz wizualnej powtarzalności bez kodu.
- Wybierz ScrapingBot, jeśli liczy się budżet, a zadanie jest stosunkowo proste.
Ostateczny wniosek
Rynek jest w 2026 roku wyraźniej podzielony niż rok temu. Tak naprawdę nie wybierasz jednego uniwersalnego „najlepszego scrapera Facebooka”. Wybierasz model pozyskiwania danych: szybkie no-code extraction, zarządzaną skalę API, automatyzację w chmurze albo praktyczną wizualną kontrolę workflow. Zacznij od tego, a shortlistowanie stanie się dużo prostsze.
Jeśli Twój zespół chce najszybszej drogi od strony Facebooka lub listy Marketplace do użytecznych, uporządkowanych danych, Thunderbit nadal jest najłatwiejszym miejscem startu. Jeśli wolumen lub wymagania inżynieryjne są znacznie większe, bardziej sensowne będą Bright Data, Apify i Nimble. Jeśli workflow zaczyna się od scrapingu, ale kończy na działaniach follow-up, PhantomBuster jest mądrzejszym wyborem do shortlisty.
FAQ
1. Jaki jest najłatwiejszy w użyciu tool do scrapingu Facebooka dla osób nietechnicznych?
Thunderbit jest najłatwiejszym punktem startowym dla większości użytkowników nietechnicznych, ponieważ działa w przeglądarce, automatycznie sugeruje pola i szybko eksportuje dane bez kodu.
2. Które narzędzie do scrapingu Facebooka jest najlepsze do dużej skali danych publicznych?
Bright Data to najsilniejszy wybór infrastrukturalny na tej liście, gdy zadanie polega na dużej skali pozyskiwania publicznych danych społecznościowych, a niezawodność jest ważniejsza niż łatwość użycia.
3. Co jeśli potrzebuję scrapingu i automatyzacji działań follow-up?
PhantomBuster będzie lepszym wyborem, gdy pozyskiwanie danych jest tylko jednym krokiem szerszego workflow generowania leadów lub GTM.
4. Czy scraping Facebooka nadal jest trudny w 2026 roku?
Tak. Dynamiczna treść, ekrany logowania, limity zapytań, systemy anty-botowe i ryzyko związane z kontem nadal sprawiają, że Facebook jest trudniejszy do scrapowania niż prostsze publiczne strony internetowe.
5. Jak zespoły powinny myśleć o zgodności?
Skup się na danych publicznych, używaj rozsądnych limitów, unikaj nadużywania danych uwierzytelniających i przed skalowaniem workflow sprawdź warunki platformy oraz obowiązujące zasady prywatności.
Dalsza lektura:
- Jak wyszukiwać posty na Facebooku według słów kluczowych (przewodnik 2025)
- 55 kluczowych statystyk o Facebooku, które musisz znać
- Jak scrapować dowolną stronę internetową za pomocą AI
Wypróbuj Thunderbit do scrapingu Facebooka i Marketplace Get Started Free




