Zillow opiera się na , a wyciąganie tych danych na dużą skalę to jedno z najczęściej zgłaszanych — i najbardziej frustrujących — zadań w pracy z danymi nieruchomości. Jeśli kiedykolwiek próbowałeś zeskrobać Zillow i zamiast danych ofertowych zobaczyłeś stronę CAPTCHA, nie jesteś sam.
Poświęciłem sporo czasu na badanie i testowanie różnych podejść do scrapowania Zillow — zarówno w Pythonie, jak i z użyciem narzędzi no-code, które tworzymy w Thunderbit. Ten przewodnik obejmuje obie ścieżki. Niezależnie od tego, czy chcesz pełny tutorial w Pythonie z metodami anty-bot, czy po prostu potrzebujesz 200 ofert w arkuszu przed lunchem, znajdziesz tu coś dla siebie. Omówimy, dlaczego dane Zillow są ważne, jak serwis jest zbudowany od środka, krok po kroku przejdziemy przez tutorial w Pythonie, pokażemy dokładnie, dlaczego scrapery się psują, oraz jak zautomatyzować cykliczne pobieranie danych do monitorowania cen.
Dlaczego w ogóle zeskrobywać dane z Zillow?
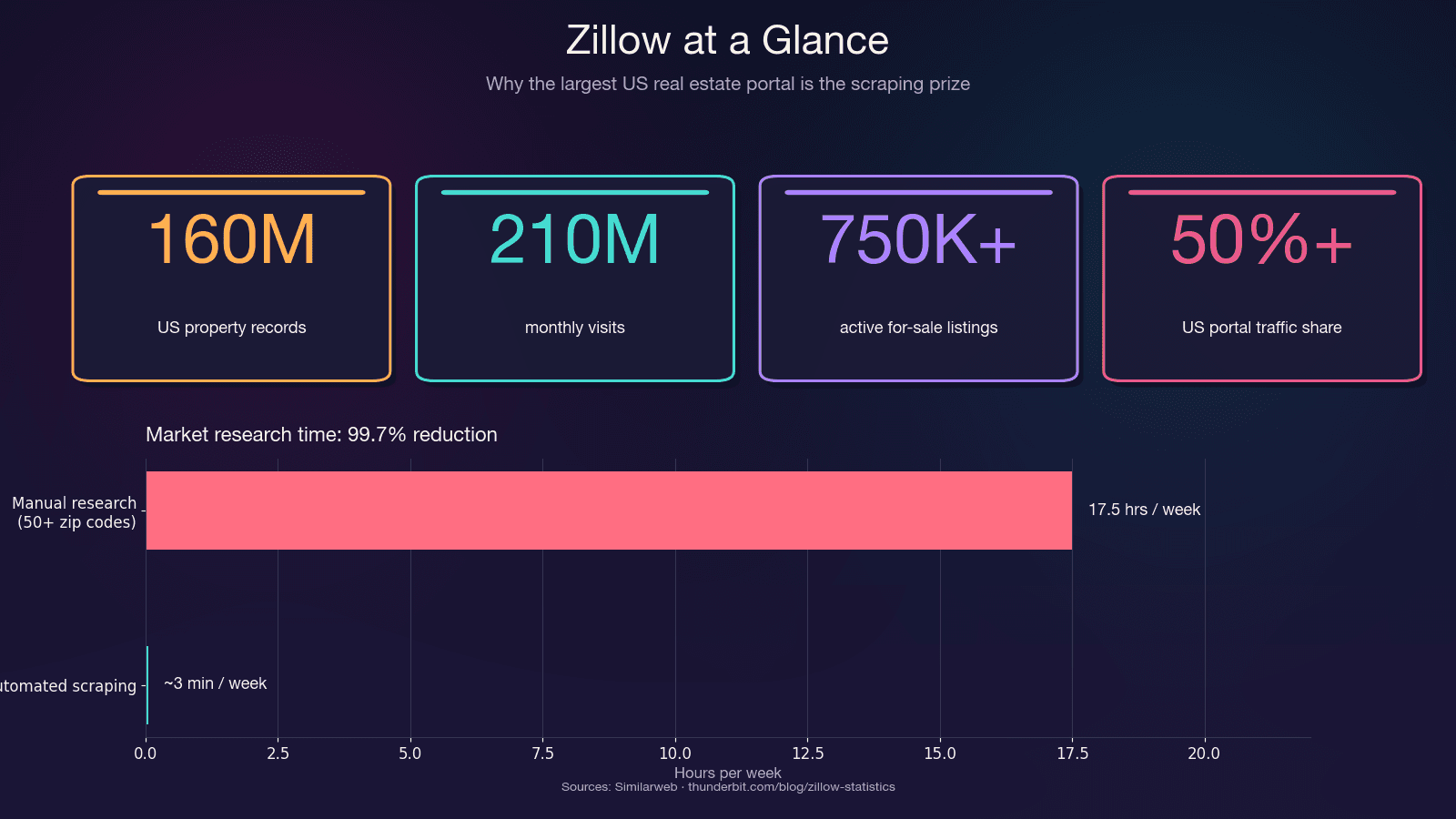
Zillow to największe repozytorium danych o amerykańskich nieruchomościach mieszkaniowych. Serwis notuje i hostuje około 750 000+ aktywnych ofert sprzedaży oraz 1,9 miliona ofert najmu. Platforma odpowiada za ponad 50% całego ruchu na portalach nieruchomości w USA — ponad dwa razy więcej niż najbliższy konkurent.
Zanim przejdziemy do kodu w Pythonie, warto wiedzieć, że scraping Zillow za pomocą Pythona nie jest jedyną opcją, a wybór niewłaściwej metody może kosztować godziny. Narzędzia Pythonowe, takie jak httpx i BeautifulSoup, wymagają średniego poziomu umiejętności, ręcznej obsługi nagłówków i proxy, działają ze średnią prędkością (1–3 sekundy na stronę) i wymagają częstych poprawek — choć są darmowe. Selenium lub Playwright lepiej radzą sobie z mechanizmami anty-bot dzięki renderowaniu JavaScriptu, ale działają wolniej (5–15 sekund na stronę) i nadal wymagają dużej opieki. API do scrapowania, takie jak ScraperAPI czy ScrapFly, są szybsze, mają wbudowaną ochronę anty-bot i umiarkowany poziom utrzymania, ale kosztują 30–599 USD miesięcznie. Oficjalne API Zillow przez Bridge Interactive jest szybkie i ma niskie koszty utrzymania, ale jest ograniczone i kosztuje około 500 USD miesięcznie. Z kolei narzędzia no-code, takie jak Thunderbit, są przyjazne dla początkujących, szybkie, nie wymagają utrzymania dzięki adaptacji AI i zwykle działają w modelu freemium.
Oszczędność czasu jest ogromna. Ręczne przeszukiwanie ponad 50 kodów pocztowych może pochłonąć 15–20 godzin tygodniowo. Automatyczny scraping robi to samo w kilka minut — to redukcja czasu o 99,7%.
Wszystkie sposoby na zeskrobanie Zillow: Python vs API vs no-code
Zanim wejdziesz w kod Pythona, pamiętaj, że „scrape Zillow with Python” to nie jedyna opcja. Zły wybór metody potrafi zmarnować godziny. Oto porównanie obok siebie, żeby łatwiej dobrać rozwiązanie:
| Metoda | Poziom umiejętności | Obsługa anty-bot | Szybkość | Utrzymanie | Koszt |
|---|---|---|---|---|---|
| Python + httpx/BeautifulSoup | Średniozaawansowany | Ręczna (nagłówki, proxy) | Umiarkowana (1–3 s/stronę) | Wysokie (selektory się psują) | Darmowe |
| Python + Selenium/Playwright | Średniozaawansowany | Lepsza (renderuje JS) | Wolna (5–15 s/stronę) | Wysokie | Darmowe |
| API do scrapowania (ScraperAPI, ScrapFly) | Średniozaawansowany | Wbudowana | Szybka | Średnie | 30–599 USD/mies. |
| Oficjalne API Zillow (Bridge Interactive) | Początkujący–średniozaawansowany | N/D | Szybka | Niskie | ~500 USD/mies., ograniczony dostęp |
| Narzędzie no-code (Thunderbit) | Początkujący | Wbudowana (AI się adaptuje) | Szybka | Brak (AI ponownie odczytuje stronę) | Freemium |
Jeśli potrzebujesz danych od razu, bez pisania kodu, zacznij od Thunderbit. Jeśli chcesz zrozumieć, jak to działa „pod maską”, albo potrzebujesz pełnej personalizacji, czytaj dalej tutorial w Pythonie.
Najszybsza metoda: zeskrob Zillow z Thunderbit (bez kodowania)
Zanim przejdziemy do bardziej technicznej części, oto ścieżka dla każdego, kto potrzebuje danych z Zillow szybko — bez konfiguracji Pythona, bez ustawiania proxy, bez utrzymywania selektorów. Ten workflow stworzyliśmy w Thunderbit właśnie po to, by pobierać uporządkowane dane o nieruchomościach bez obciążenia po stronie inżynieryjnej.
Poziom trudności: Początkujący Czas potrzebny: około 2 minuty Czego potrzebujesz: przeglądarka Chrome, (działa darmowy plan)
Krok 1: Zainstaluj Thunderbit i otwórz Zillow
Zainstaluj rozszerzenie Thunderbit z Chrome Web Store. Wejdź na stronę wyników wyszukiwania Zillow — na przykład wyszukaj domy w Houston, TX.
Krok 2: Kliknij „AI Suggest Fields”
Otwórz panel boczny Thunderbit i kliknij „AI Suggest Fields”. AI odczyta stronę i automatycznie zaproponuje kolumny: cena, adres, liczba sypialni, łazienek, metraż, Zestimate, URL oferty i więcej. W moich testach zwykle wykrywa 20+ pól bez żadnej ręcznej konfiguracji.
Krok 3: Kliknij „Scrape”
Naciśnij przycisk Scrape. Dane pojawią się w uporządkowanej tabeli wewnątrz rozszerzenia. Thunderbit automatycznie obsłuży paginację Zillow — zarówno opartą na klikaniu, jak i infinite scroll.
Krok 4: Rozszerz dane przez scraping podstron
Chcesz danych z karty szczegółów, takich jak historia podatkowa, oceny szkół albo historia cen? Użyj funkcji „Scrape Subpages”, aby wzbogacić tabelę. Thunderbit przejdzie do każdej oferty i pobierze dodatkowe pola — bez żadnego kodu.
Krok 5: Eksportuj
Wyeksportuj dane do Google Sheets, Excela, Airtable lub Notion. Eksport jest darmowy.
Dlaczego Thunderbit dobrze działa z Zillow
Największą zaletą jest odporność. AI Thunderbit za każdym razem odczytuje strukturę strony od nowa podczas scrapowania. Gdy Zillow zmienia układ strony (a robi to często), nie trzeba poprawiać kruchych selektorów CSS. AI dostosowuje się automatycznie. To naprawdę rozwiązuje problem „z natury podatnych na awarie” scraperów kodowanych, który frustruje tak wielu użytkowników.
Jakie dane można zeskrobać z Zillow? (20+ pól)
Większość poradników pobiera cenę i adres, a potem kończy. Oferty Zillow zawierają znacznie więcej danych, niż wiele osób zakłada — poniżej tabela referencyjna:
| Pole | Gdzie występuje | Trudność pobrania |
|---|---|---|
| Cena ofertowa | Wyniki wyszukiwania + szczegóły | Łatwe |
| Adres / kod pocztowy | Wyniki wyszukiwania + szczegóły | Łatwe |
| Zestimate | Wyniki wyszukiwania + szczegóły | Łatwe |
| Historia cen (każde zdarzenie) | Szczegóły | Trudne (zagnieżdżony JSON) |
| Historia podatkowa | Szczegóły | Trudne (zagnieżdżony JSON) |
| Sypialnie / łazienki / metraż | Wyniki wyszukiwania + szczegóły | Łatwe |
| Rok budowy | Szczegóły | Łatwe |
| Opłata HOA | Szczegóły | Średnie |
| Walk Score / Transit Score | Szczegóły (iframe) | Trudne (wymaga renderowania JS) |
| Oceny szkół | Szczegóły | Średnie |
| Powierzchnia działki | Szczegóły | Łatwe |
| Dni na Zillow | Wyniki wyszukiwania | Łatwe |
| Agent / biuro pośrednictwa | Wyniki wyszukiwania + szczegóły | Średnie |
| Numer MLS | Szczegóły | Łatwe |
| Typ nieruchomości | Wyniki wyszukiwania + szczegóły | Łatwe |
| Szerokość / długość geograficzna | JSON __NEXT_DATA__ | Średnie |
| Opis tekstowy | Szczegóły | Łatwe |
| URL zdjęć | Wyniki wyszukiwania + szczegóły | Średnie |
| Rent Zestimate | Szczegóły | Średnie |
| Porównywalne sprzedaże w pobliżu | Szczegóły | Trudne |
Pola oznaczone jako „trudne” — historia cen, historia podatkowa, porównywalne sprzedaże — są ukryte w zagnieżdżonym JSON na stronach szczegółów. Sekcja o Pythonie poniżej pokazuje dokładnie, jak je wyciągnąć. A jeśli wolisz pominąć kod, AI Suggest Fields w Thunderbit wykryje większość tych kolumn automatycznie, a Scrape Subpages pobierze pola ze stron szczegółów bez Twojej ingerencji.
Przygotowanie środowiska Python do scrapowania Zillow
Poziom trudności: Średniozaawansowany Czas potrzebny: około 5 minut na konfigurację, około 30 minut na cały tutorial Czego potrzebujesz: Python 3.8+, przeglądarka Chrome (do inspekcji stron), edytor tekstu lub IDE
Zainstaluj wymagane biblioteki:
1pip install httpx beautifulsoup4 pandas lxmlCo robi każda z nich:
- httpx — klient HTTP wydajniejszy niż
requests, z obsługą async - beautifulsoup4 + lxml — parsowanie HTML
- pandas — eksport danych do CSV/Excela
- Opcjonalnie: selenium lub playwright, jeśli musisz renderować strony ciężkie od JavaScriptu
Zrozum strukturę strony Zillow, zanim zaczniesz scrapować
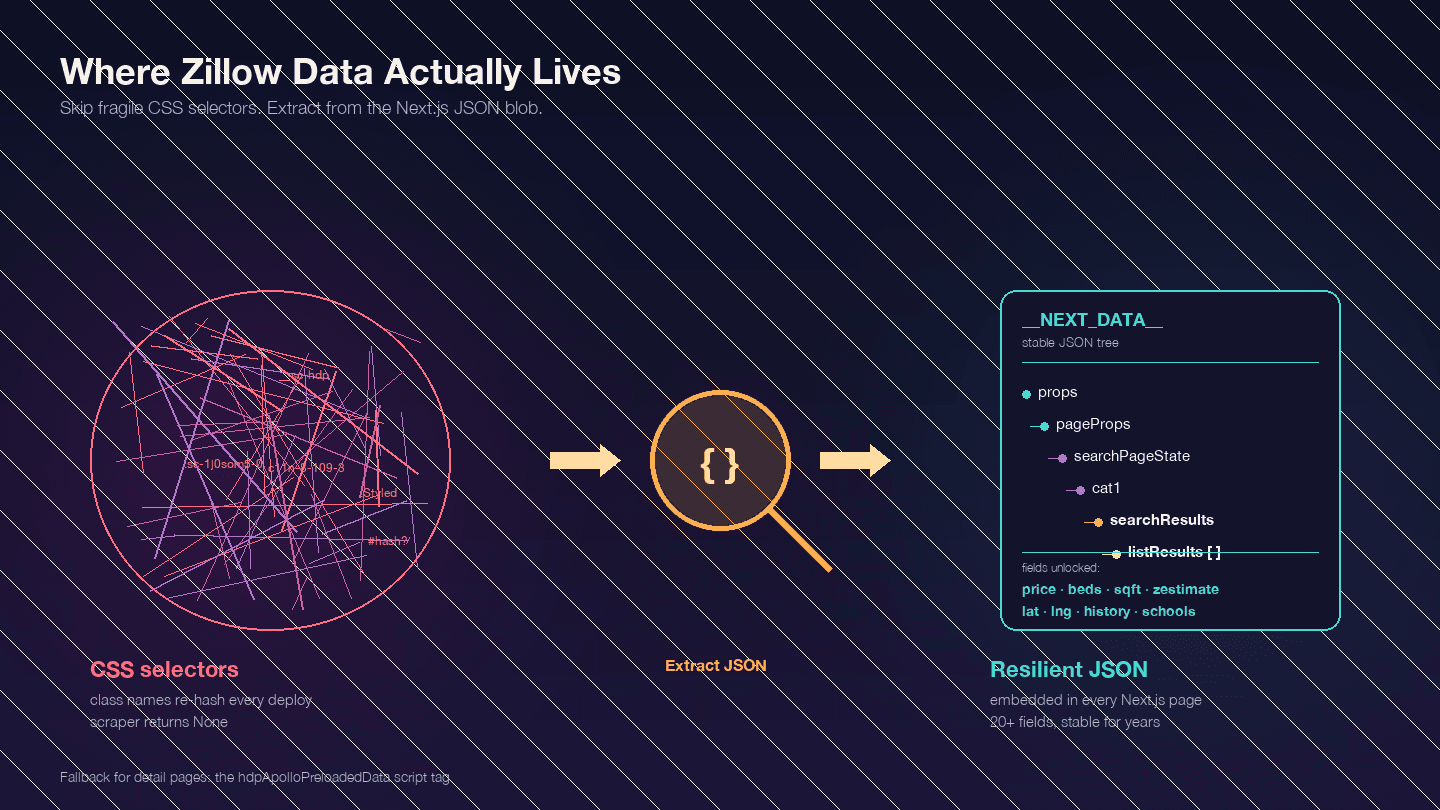
To najważniejsza rzecz, którą trzeba zrozumieć przed napisaniem jakiegokolwiek kodu. Zillow to aplikacja Next.js — potwierdzona przez . Oznacza to, że większość potrzebnych danych nie znajduje się w widocznych elementach HTML. Jest osadzona w bloku JSON w tagu <script id="__NEXT_DATA__">.
Otwórz dowolną stronę nieruchomości na Zillow, naciśnij F12, przejdź do Elements i wyszukaj __NEXT_DATA__. Znajdziesz ogromny obiekt JSON zawierający wszystkie dane oferty — ceny, współrzędne, szczegóły nieruchomości, historię cen, rekordy podatkowe, oceny szkół i wiele więcej.
Dlaczego to ważne? Nazwy klas CSS na Zillow są haszowane (generowane przez styled-components) i zmieniają się przy każdym wdrożeniu. Klasa taka jak StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 za tydzień będzie miała zupełnie inny hash. Każdy scraper oparty na selektorach CSS będzie więc regularnie przestawał działać.
Podejście oparte na JSON __NEXT_DATA__ jest dużo stabilniejsze, ponieważ nie zależy w ogóle od struktury HTML.
Kluczowe ścieżki JSON dla wyników wyszukiwania:
| Ścieżka | Zawartość |
|---|---|
props.pageProps.searchPageState.cat1.searchResults.listResults | Tablica wyników wyszukiwania |
props.pageProps.searchPageState.cat1.searchResults.mapResults | Wyniki widoku mapy |
props.pageProps.searchPageState.cat1.searchList.totalPages | Liczba dostępnych stron |
Na stronach szczegółów część używa __NEXT_DATA__, a część alternatywnego tagu skryptu hdpApolloPreloadedData. Poniższy kod obsługuje oba warianty.
Krok po kroku: jak zeskrobać Zillow w Pythonie
Krok 1: Ustaw nagłówki HTTP, aby uniknąć natychmiastowej blokady
Wysłanie zwykłego httpx.get() do Zillow zwróci stronę CAPTCHA, a nie dane ofert. Zillow używa PerimeterX (HUMAN Security) razem z Cloudflare — oba rozwiązania mają według benchmarków scrapingu. System sprawdza fingerprint TLS, nagłówki HTTP i reputację IP.
Oto minimalny zestaw nagłówków, który działa w 2025 roku:
1import httpx
2headers = {
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
5 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
6 "image/avif,image/webp,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Ch-Ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
10 "Sec-Ch-Ua-Platform": '"Windows"',
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "none",
14 "Sec-Fetch-User": "?1",
15 "Upgrade-Insecure-Requests": "1",
16}Nagłówki Sec-Ch-Ua są kluczowe. Wiele poradników je pomija — i właśnie dlatego ich kod nie działa przeciwko PerimeterX.
Krok 2: Zeskrob wyniki wyszukiwania Zillow
Adresy wyszukiwania na Zillow mają przewidywalny format. Dla Houston, TX:
- Strona 1:
https://www.zillow.com/houston-tx/ - Strona 2:
https://www.zillow.com/houston-tx/2_p/ - Strona 3:
https://www.zillow.com/houston-tx/3_p/
Każda strona zawiera około 41 ofert. Zillow ogranicza wyniki do 20 stron (~820 ofert). W przypadku większych zbiorów danych trzeba dzielić obszar geograficznie (więcej o tym później).
Oto kod do pobierania wyników wyszukiwania przez wyciągnięcie danych z JSON __NEXT_DATA__:
1from bs4 import BeautifulSoup
2import json
3import time
4import random
5def scrape_zillow_search(url):
6 """Pobiera dane ofert z wyników wyszukiwania Zillow."""
7 response = httpx.get(url, headers=headers, timeout=15)
8 if response.status_code != 200:
9 print(f"Dla {url} zwrócono status {response.status_code}")
10 return []
11 soup = BeautifulSoup(response.text, "lxml")
12 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
13 if not script_tag:
14 print("Brak __NEXT_DATA__ — prawdopodobnie blokada CAPTCHA")
15 return []
16 next_data = json.loads(script_tag.string)
17 try:
18 results = (
19 next_data["props"]["pageProps"]["searchPageState"]
20 ["cat1"]["searchResults"]["listResults"]
21 )
22 except KeyError:
23 print("Nieoczekiwana struktura JSON — Zillow mogło zmienić format")
24 return []
25 listings = []
26 for item in results:
27 listing = {
28 "zpid": item.get("zpid"),
29 "address": item.get("addressStreet"),
30 "city": item.get("addressCity"),
31 "state": item.get("addressState"),
32 "zipcode": item.get("addressZipcode"),
33 "price": item.get("unformattedPrice") or item.get("price"),
34 "beds": item.get("beds"),
35 "baths": item.get("baths"),
36 "sqft": item.get("area"),
37 "zestimate": item.get("zestimate"),
38 "days_on_zillow": item.get("daysOnZillow"),
39 "listing_url": item.get("detailUrl"),
40 "img_src": item.get("imgSrc"),
41 "property_type": item.get("hdpData", {}).get("homeInfo", {}).get("homeType"),
42 "latitude": item.get("latLong", {}).get("latitude"),
43 "longitude": item.get("latLong", {}).get("longitude"),
44 }
45 listings.append(listing)
46 return listingsAby pobrać wiele stron, użyj pętli z opóźnieniami:
1all_listings = []
2base_url = "https://www.zillow.com/houston-tx/"
3for page in range(1, 6): # Pierwsze 5 stron
4 url = base_url if page == 1 else f"{base_url}{page}_p/"
5 print(f"Scraping strony {page}...")
6 page_listings = scrape_zillow_search(url)
7 all_listings.extend(page_listings)
8 # Losowa przerwa między 3 a 7 sekund
9 delay = random.uniform(3, 7)
10 time.sleep(delay)
11print(f"Łącznie pobranych ofert: {len(all_listings)}")Powinieneś zobaczyć uporządkowane dane ofert zbierające się w all_listings. Jeśli wynik jest pusty, sprawdź sekcję „Dlaczego scrapery się psują” poniżej.
Krok 3: Zeskrob strony szczegółów nieruchomości Zillow
Wyniki wyszukiwania dają podstawowe informacje. Strony szczegółów zawierają głębsze dane: historię cen, historię podatkową, oceny szkół, informacje o agencie i opis nieruchomości. Każdy URL oferty z kroku 2 prowadzi do strony szczegółów.
Strony szczegółów Zillow używają dwóch możliwych formatów danych. Oto kod, który obsługuje oba:
1def scrape_zillow_detail(url):
2 """Pobiera szczegółowe dane nieruchomości z karty oferty Zillow."""
3 response = httpx.get(url, headers=headers, timeout=15)
4 if response.status_code != 200:
5 return None
6 soup = BeautifulSoup(response.text, "lxml")
7 # Najpierw próbujemy __NEXT_DATA__ (najczęściej)
8 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
9 if script_tag:
10 next_data = json.loads(script_tag.string)
11 try:
12 cache_str = next_data["props"]["pageProps"]["componentProps"]["gdpClientCache"]
13 cache = json.loads(cache_str)
14 first_key = next(iter(cache))
15 prop = cache[first_key]["property"]
16 return extract_property_fields(prop)
17 except (KeyError, StopIteration):
18 pass
19 # Fallback: hdpApolloPreloadedData
20 apollo_tag = soup.find("script", {"id": "hdpApolloPreloadedData"})
21 if apollo_tag:
22 raw = json.loads(apollo_tag.string)
23 api_cache = json.loads(raw["apiCache"])
24 for key, value in api_cache.items():
25 if "ForSale" in key or "property" in str(value)[:100]:
26 prop = value.get("property", value)
27 return extract_property_fields(prop)
28 return None
29def extract_property_fields(prop):
30 """Wyciąga uporządkowane pola z obiektu JSON nieruchomości Zillow."""
31 return {
32 "zpid": prop.get("zpid"),
33 "zestimate": prop.get("zestimate"),
34 "rent_zestimate": prop.get("rentZestimate"),
35 "description": prop.get("description"),
36 "year_built": prop.get("yearBuilt"),
37 "lot_size": prop.get("lotSize"),
38 "hoa_fee": prop.get("monthlyHoaFee"),
39 "mls_id": prop.get("mlsid"),
40 "broker_name": prop.get("brokerName") or prop.get("attributionInfo", {}).get("brokerName"),
41 "price_history": [
42 {
43 "date": event.get("date"),
44 "event": event.get("event"),
45 "price": event.get("price"),
46 }
47 for event in prop.get("priceHistory", [])
48 ],
49 "tax_history": [
50 {
51 "year": record.get("time"),
52 "tax_paid": record.get("taxPaid"),
53 "value": record.get("value"),
54 }
55 for record in prop.get("taxHistory", [])
56 ],
57 "schools": [
58 {
59 "name": school.get("name"),
60 "rating": school.get("rating"),
61 "distance": school.get("distance"),
62 }
63 for school in prop.get("schools", [])
64 ],
65 }Przejdź przez URL-e ofert z opóźnieniami:
1detail_data = []
2for listing in all_listings[:10]: # Zacznij od 10, żeby przetestować
3 detail_url = listing.get("listing_url")
4 if not detail_url:
5 continue
6 if not detail_url.startswith("http"):
7 detail_url = f"https://www.zillow.com{detail_url}"
8 print(f"Scraping szczegółów: {detail_url}")
9 detail = scrape_zillow_detail(detail_url)
10 if detail:
11 detail_data.append({**listing, **detail})
12 time.sleep(random.uniform(3, 8))Po tym kroku powinieneś mieć listę słowników zawierających zarówno dane z poziomu wyszukiwania, jak i dane ze stron szczegółów dla każdej nieruchomości.
Krok 4: Obsłuż paginację, aby pobierać wiele stron
W przypadku obszarów z ponad 820 ofertami (limit 20 stron) trzeba podzielić obszar geograficznie. Wewnętrzne API Zillow akceptuje parametry mapBounds. Strategia: podzielić mapę na ćwiartki i scrapować każdą osobno.
1def split_bounds(bounds):
2 """Dzieli granice mapy na 4 ćwiartki."""
3 mid_lat = (bounds["north"] + bounds["south"]) / 2
4 mid_lng = (bounds["east"] + bounds["west"]) / 2
5 return [
6 {"north": bounds["north"], "south": mid_lat, "east": bounds["east"], "west": mid_lng},
7 {"north": bounds["north"], "south": mid_lat, "east": mid_lng, "west": bounds["west"]},
8 {"north": mid_lat, "south": bounds["south"], "east": bounds["east"], "west": mid_lng},
9 {"north": mid_lat, "south": bounds["south"], "east": mid_lng, "west": bounds["west"]},
10 ]W większości zastosowań — np. monitorowania 50–200 ofert w konkretnej lokalizacji — standardowa paginacja URL wystarczy. Podejście z ćwiartkami jest przydatne przy scrapowaniu całego miasta lub stanu.
Krok 5: Wyeksportuj dane z Zillow
Zapisz wszystko do CSV za pomocą pandas:
1import pandas as pd
2df = pd.DataFrame(detail_data)
3df.to_csv("zillow_houston_listings.csv", index=False)
4print(f"Wyeksportowano {len(df)} ofert do zillow_houston_listings.csv")Eksport do JSON:
1with open("zillow_houston_listings.json", "w") as f:
2 json.dump(detail_data, f, indent=2)Jeśli chcesz pominąć etap eksportu całkowicie, Thunderbit za darmo eksportuje dane do Google Sheets, Airtable i Notion — przydatne, gdy chcesz od razu pracować na danych w formie współdzielonej.
Dlaczego scrapery Zillow się psują (i jak budować odporne rozwiązania)
To jest przewodnik przetrwania.
Z mojego doświadczenia wynika, że scrapery psują się na Zillow z trzech konkretnych powodów — i każdy ma konkretne rozwiązanie.
PerimeterX i CAPTCHA: dlaczego Twoje żądania zwracają puste dane
Integracja PerimeterX w Zillow sprawdza kilka sygnałów jednocześnie: fingerprint TLS, nagłówki HTTP, reputację IP i wzorce ruchu. Gdy wykryje automatyzację, zamiast danych ofert wyświetla stronę CAPTCHA typu „Press & Hold”.
Dokładny scenariusz awarii: wysyłasz zapytanie z domyślnymi nagłówkami Pythona. Odpowiedź HTML zawiera skrypty wyzwania PerimeterX zamiast danych nieruchomości — a parsowanie BeautifulSoup nie znajduje tagu __NEXT_DATA__.
Rozwiązanie: użyj pełnego zestawu nagłówków imitujących przeglądarkę z Kroku 1. Jeśli wykonujesz więcej niż kilkadziesiąt żądań, potrzebujesz też rotacji proxy (omówionej poniżej). Przy cięższym scrapowaniu warto rozważyć bibliotekę curl_cffi z impersonate="chrome" — to jedyny klient HTTP w Pythonie, który potrafi zbliżyć się do prawdziwego TLS fingerprintu Chrome.
Dynamiczne selektory CSS: dlaczego BeautifulSoup zwraca None
Jeśli używasz selektorów CSS typu .list-card-price albo nazw klas z hashami, scraper będzie się psuł za każdym razem, gdy Zillow wdroży nową wersję kodu.
Zillow korzysta ze styled-components, które generują nazwy klas w stylu StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0. Część z hashem zmienia się przy każdym buildzie.
Rozwiązanie: w ogóle nie używaj selektorów CSS. Wyciągaj dane z JSON __NEXT_DATA__, jak pokazano w kodzie powyżej. To podejście jest stabilne od lat, ponieważ struktura JSON zmienia się znacznie rzadziej niż znaczniki HTML.
Jeśli musisz korzystać z parsowania HTML, szukaj atrybutów data-test (np. data-test="property-card") albo używaj dopasowania fragmentu klasy, np. [class*="PropertyCard"]. Ale pobieranie z JSON pozostaje bardziej niezawodne.
Rotacja proxy i exponential backoff: kod, który przetrwa blokady IP
Adresy IP z centrów danych są przez Zillow. Potrzebujesz proxy residential, żeby mieć stabilny dostęp. Bezpieczne tempo: 1 żądanie na 3–8 sekund na IP, poniżej około 500 żądań na godzinę.
Oto dekorator retry z exponential backoff i jitterem:
1import random
2import time
3def backoff_with_jitter(attempt, base_delay=2, max_delay=60):
4 """Exponential backoff z pełnym jitterem w stylu AWS."""
5 delay = min(max_delay, base_delay * (2 ** attempt))
6 return random.uniform(0, delay)
7def fetch_with_retry(url, max_retries=5):
8 for attempt in range(max_retries):
9 try:
10 response = httpx.get(url, headers=headers, timeout=15)
11 if response.status_code == 200:
12 return response
13 if response.status_code in (403, 429):
14 delay = backoff_with_jitter(attempt, base_delay=5)
15 print(f"Blokada ({response.status_code}). Ponawiam za {delay:.1f}s...")
16 time.sleep(delay)
17 continue
18 except Exception as e:
19 if attempt == max_retries - 1:
20 raise
21 time.sleep(backoff_with_jitter(attempt))
22 return NoneI prosty pool do rotacji proxy:
1class ProxyPool:
2 def __init__(self, proxies):
3 self.proxies = proxies
4 self.index = 0
5 self.failures = {}
6 def get_next(self):
7 proxy = self.proxies[self.index % len(self.proxies)]
8 self.index += 1
9 return {"http://": proxy, "https://": proxy}
10 def report_failure(self, proxy):
11 self.failures[proxy] = self.failures.get(proxy, 0) + 1
12 if self.failures[proxy] > 3:
13 self.proxies.remove(proxy)
14# Użycie:
15pool = ProxyPool(proxies=[
16 "http://user:pass@residential1.example.com:8080",
17 "http://user:pass@residential2.example.com:8080",
18])Jeśli chodzi o dostawców proxy, oferuje proxy residential za około 1 USD/GB (najtańsza opcja), a IPRoyal i Smartproxy to solidne wybory ze średniej półki w cenie 4–7 USD/GB.
Alternatywa bez utrzymania
Jeśli regularnie scrapujesz Zillow i masz dość naprawiania uszkodzonych selektorów albo zarządzania pulami proxy, AI Thunderbit czyta strukturę strony od nowa przy każdym pobraniu. Bez selektorów do utrzymania, bez konfiguracji proxy. To naprawdę rozwiązuje problem kruchości, który sprawia, że kodowane scrapery stają się ciągłą udręką.
Automatyzacja scrapowania Zillow: harmonogram i monitorowanie cen
Każdy inwestor nieruchomości, z którym rozmawiałem, tego chce, a żaden inny przewodnik po scrapowaniu Zillow nie opisuje tego dobrze: cyklicznego, automatycznego pobierania danych do śledzenia cen.
Dla użytkowników Pythona: zadania cron i wykrywanie zmian cen
Ustaw zadanie cron, które będzie uruchamiać scraper co tydzień i oznaczać zmiany cen:
1import pandas as pd
2from datetime import datetime
3def detect_price_changes(new_data, historical_file, threshold=0.05):
4 """Porównuje nowe pobranie z danymi historycznymi i oznacza zmiany > threshold."""
5 try:
6 old = pd.read_csv(historical_file)
7 except FileNotFoundError:
8 new_data.to_csv(historical_file, index=False)
9 print("Pierwsze uruchomienie — zapisano dane bazowe.")
10 return pd.DataFrame()
11 merged = new_data.merge(old, on="zpid", suffixes=("_new", "_old"))
12 merged["price_change_pct"] = (
13 (merged["price_new"] - merged["price_old"]) / merged["price_old"]
14 )
15 alerts = merged[merged["price_change_pct"].abs() > threshold]
16 # Dopisz nowe dane ze znacznikiem czasu
17 new_data["scraped_at"] = datetime.now().isoformat()
18 new_data.to_csv(historical_file, mode="a", header=False, index=False)
19 return alertsDodaj to do crontaba, aby uruchamiało się w każdy poniedziałek o 6:00 rano:
10 6 * * 1 cd /path/to/scraper && python zillow_monitor.pyPraktyczny przykład: monitoruj co tydzień 50 ofert w Austin, TX. W każdy poniedziałek skrypt pobiera aktualne ceny, porównuje je z poprzednim tygodniem i generuje CSV z wyróżnieniem każdej obniżki ceny większej niż 5%.
Dla osób bez kodowania: Thunderbit Scheduled Scraper
Scheduled Scraper w Thunderbit pozwala opisać interwał zwykłym językiem („co poniedziałek o 9:00”), podać adresy wyszukiwania Zillow i kliknąć Schedule. Dane automatycznie eksportują się do Google Sheets przy każdym uruchomieniu. Bez Pythona, bez crona, bez serwera do utrzymania. Jest to szczególnie przydatne dla agentów nieruchomości lub zespołów operacyjnych, które potrzebują stałego monitoringu cen bez wsparcia inżynierów.
Wskazówki dotyczące odpowiedzialnego scrapowania Zillow
Kilka uwag, jak pozostać po właściwej stronie granicy:
- Scrapuj wyłącznie dane publicznie dostępne. Nie wchodź na strony za logowaniem ani autoryzacją.
- Używaj rozsądnego tempa żądań. 3–8 sekund między zapytaniami. Nie bombarduj serwera.
- Nie pobieraj danych prywatnych użytkowników. Imiona agentów i informacje o biurach są publiczne; dane kont użytkowników nie.
- Przechowuj i wykorzystuj dane etycznie. Badania rynku, analiza inwestycyjna i generowanie leadów to legalne zastosowania. Spam nie.
- Kontekst prawny: wyrok ustalił, że pobieranie publicznie dostępnych danych nie narusza CFAA. W 2024 roku wyrok Meta v. Bright Data potwierdził podobne zasady. Mimo to regulamin Zillow ogranicza dostęp automatyczny, a firma egzekwuje to przez blokady IP i CAPTCHA, a nie działania prawne. Zawsze sprawdzaj aktualne wytyczne i respektuj .
Wybierz najlepsze podejście do scrapowania Zillow w Pythonie
Najlepsza ścieżka zależy od Twojej sytuacji:
Potrzebujesz danych szybko, bez kodu? przeniesie Cię ze strony wyszukiwania Zillow do uporządkowanego arkusza w około 2 minuty. AI adaptuje się do zmian układu, obsługuje paginację i eksportuje za darmo. Zainstaluj i przetestuj je na stronie wyszukiwania Zillow.
Chcesz pełnej kontroli? Skorzystaj z kodu Pythona z tego przewodnika. Pobieraj dane z JSON __NEXT_DATA__ (a nie z selektorów CSS), aby zwiększyć stabilność. Ustaw poprawne nagłówki imitujące przeglądarkę. Rotuj proxy residential i stosuj exponential backoff, aby zapewnić niezawodność.
Skalujesz rozwiązanie? API do scrapowania, takie jak (99% skuteczności na Zillow) lub ScraperAPI, przejmą za Ciebie infrastrukturę proxy i CAPTCHA w cenie 30–599 USD miesięcznie, w zależności od wolumenu.
Śledzisz ceny w czasie? Ustaw zadanie cron z kodem wykrywania zmian cen albo użyj Scheduled Scraper w Thunderbit, jeśli chcesz podejścia bez utrzymania.
Dane tam są. Jedyna kwestia to to, ile czasu inżynieryjnego chcesz poświęcić, żeby je wydobyć. Więcej o przenoszeniu danych z internetu do arkuszy znajdziesz w naszym przewodniku albo w , gdzie znajdziesz najnowsze dane o platformie. Możesz też obejrzeć poradniki na .
FAQ
Czy można zeskrobać Zillow w Pythonie za darmo?
Tak — httpx, BeautifulSoup i pandas są darmowe oraz open source. Ceną jest czas: samodzielnie musisz zarządzać nagłówkami, rotacją proxy i utrzymaniem selektorów. Przygotowanie początkowe zajmie 4–8 godzin, a utrzymanie po zmianach w serwisie Zillow może pochłaniać 4–10 godzin miesięcznie. Thunderbit także oferuje darmowy plan, jeśli chcesz całkowicie uniknąć kosztu kodowania.
Czy Zillow ma oficjalne API?
Zillow wycofał swoje darmowe publiczne API we wrześniu 2021 roku. Dostęp odbywa się teraz przez Bridge Interactive, które wymaga akceptacji, kosztuje około 500 USD miesięcznie i jest skierowane do licencjonowanych profesjonalistów rynku nieruchomości. Dla większości użytkowników — inwestorów, badaczy, agentów analizujących rynek — scraping jest praktyczną alternatywą. Zillow nadal publikuje też darmowe dane badawcze do pobrania w formacie CSV na , w tym Zillow Home Value Index i Zillow Observed Rent Index.
Jak uniknąć blokady podczas scrapowania Zillow?
Trzy rzeczy: (1) używaj realistycznych nagłówków przeglądarki, w tym Sec-Ch-Ua — to nagłówek, którego brakuje w większości poradników i który PerimeterX sprawdza w pierwszej kolejności; (2) rotuj proxy residential — adresy IP z centrów danych są blokowane od razu; (3) pobieraj dane z JSON __NEXT_DATA__, a nie z selektorów HTML, żeby uniknąć awarii przy zmianach układu strony. Trzymaj tempo na poziomie 1 żądania na 3–8 sekund na IP. Albo użyj narzędzia takiego jak Thunderbit, które automatycznie obsługuje ochronę anty-bot.
Jaki jest najlepszy sposób na zeskrobanie Zillow bez kodowania?
Najszybszą drogą jest AI Web Scraper od Thunderbit. Zainstaluj , przejdź do strony wyszukiwania Zillow, kliknij „AI Suggest Fields”, aby automatycznie wykryć kolumny, a następnie kliknij „Scrape”. Eksport do Google Sheets, Excela, Airtable lub Notion nie wymaga pisania kodu. AI odczytuje stronę za każdym razem od nowa, więc nie psuje się, gdy Zillow zmienia układ.
Jak często Zillow zmienia strukturę swojej strony i jaki to ma wpływ na scrapery?
Zillow wdraża aktualizacje często — czasem co tydzień. Ponieważ używa styled-components, nazwy klas CSS zmieniają się przy każdym wdrożeniu, a scrapery oparte na selektorach CSS regularnie przestają działać. Najbardziej odporne podejście w Pythonie to pobieranie danych z bloku JSON __NEXT_DATA__, którego struktura zmienia się znacznie rzadziej. Jeśli chcesz podejścia bez utrzymania, AI Thunderbit ponownie odczytuje strukturę strony przy każdym scrapowaniu i automatycznie dopasowuje się do zmian układu.
Dowiedz się więcej