

Większość poradników o scrapowaniu eBay ma termin ważności mniej więcej trzech miesięcy. Wiem to, bo zespół Thunderbit widział już niejednego dewelopera błądzącego między zepsutymi kawałkami kodu, nieaktualnymi selektorami CSS i „działającymi” repozytoriami na GitHubie, które przestawały działać po dwóch kolejnych odświeżeniach interfejsu eBay.
eBay ma około 2,5 miliarda aktywnych ofert — to największy publicznie dostępny zbiór danych o cenach w długim ogonie po Amazonie. Te dane napędzają wszystko: od ustalania cen przez resellerów po analizę konkurencji. Ale dostęp programistyczny do nich to ruchomy cel: frontend eBay oparty na React stale zmienia nazwy klas CSS, testy A/B pokazują różne struktury DOM różnym użytkownikom, a Akamai Bot Manager stoi między tobą a HTML-em. Ten przewodnik pokazuje kod Pythona, który działa dziś, wyjaśnia, dlaczego scrapery się psują, żebyś mógł budować bardziej odporne rozwiązania, uczciwie porównuje eBay API i scrapowanie oraz pokazuje wyjście bez kodu na wypadek, gdy Python nie jest wart całej tej roboty.
Co to znaczy scrapować eBay w Pythonie?
Scrapowanie eBay w Pythonie oznacza pisanie skryptów, które programowo pobierają strony eBay, analizują HTML (albo ukryty JSON) i wyciągają ustrukturyzowane dane — tytuły, ceny, informacje o sprzedawcach, daty sprzedaży, warianty produktów — do formatu, z którego naprawdę możesz korzystać, np. CSV, arkusza kalkulacyjnego albo bazy danych.
Możesz scrapować kilka typów stron eBay:
- Wyniki wyszukiwania (np. wszystkie oferty „AirPods Pro”)
- Strony pojedynczych produktów (pełna specyfikacja, obrazy, dane sprzedawcy)
- Oferty sprzedane/zakończone (rzeczywiste ceny transakcyjne i daty)
- Profile sprzedawców i recenzje
Python jest tutaj najczęściej wybieranym językiem. Jego ekosystem — Requests, BeautifulSoup, lxml, pandas — ułatwia pobieranie stron, parsowanie HTML i obrabianie danych. Jest jednak ważna różnica między scrapowaniem HTML strony a korzystaniem z oficjalnego API eBay — do tego wrócę za chwilę.
Dlaczego scrapować eBay? Rzeczywiste zastosowania w zespołach biznesowych
Jeśli to czytasz, pewnie już masz swój powód. Warto jednak osadzić temat w konkretnej wartości biznesowej, bo zwrot z danych eBay potrafi być naprawdę mocny. Bain ustalił, że 1% poprawy w zrealizowanej cenie przekłada się na 11,1% wzrostu zysku w tysiącach firm. McKinsey przypisuje dynamicznemu ustalaniu cen w handlu detalicznym nawet 5% wzrostu sprzedaży i 2–7% poprawy marży.
Najczęstsze przypadki użycia, które widzę:
| Przypadek użycia | Potrzebne dane | Efekt biznesowy |
|---|---|---|
| Monitorowanie cen i repricing | Ceny aktywnych ofert, koszty dostawy, stan | Konkurencyjne ceny, ochrona marży |
| Analiza konkurencji | Asortyment, promocje, warunki dostawy | Pozycjonowanie strategiczne, luki w ofercie |
| Badania rynku i wykrywanie trendów | Tempo publikacji ofert, trendy kategorii, wzorce popytu | Identyfikacja nowych produktów, prognozowanie popytu |
| Wycena resellerska / appraisal | Ceny sprzedaży, daty sprzedaży, stan | Rynkowa wycena, decyzje buy-box |
| Analiza sentymentu | Recenzje, oceny, polityka zwrotów | Wgląd w jakość produktu, satysfakcja klienta |
| Generowanie leadów | Profile sprzedawców, dane sklepu, dane kontaktowe | Outreach B2B do sprzedawców o wysokim GMV |
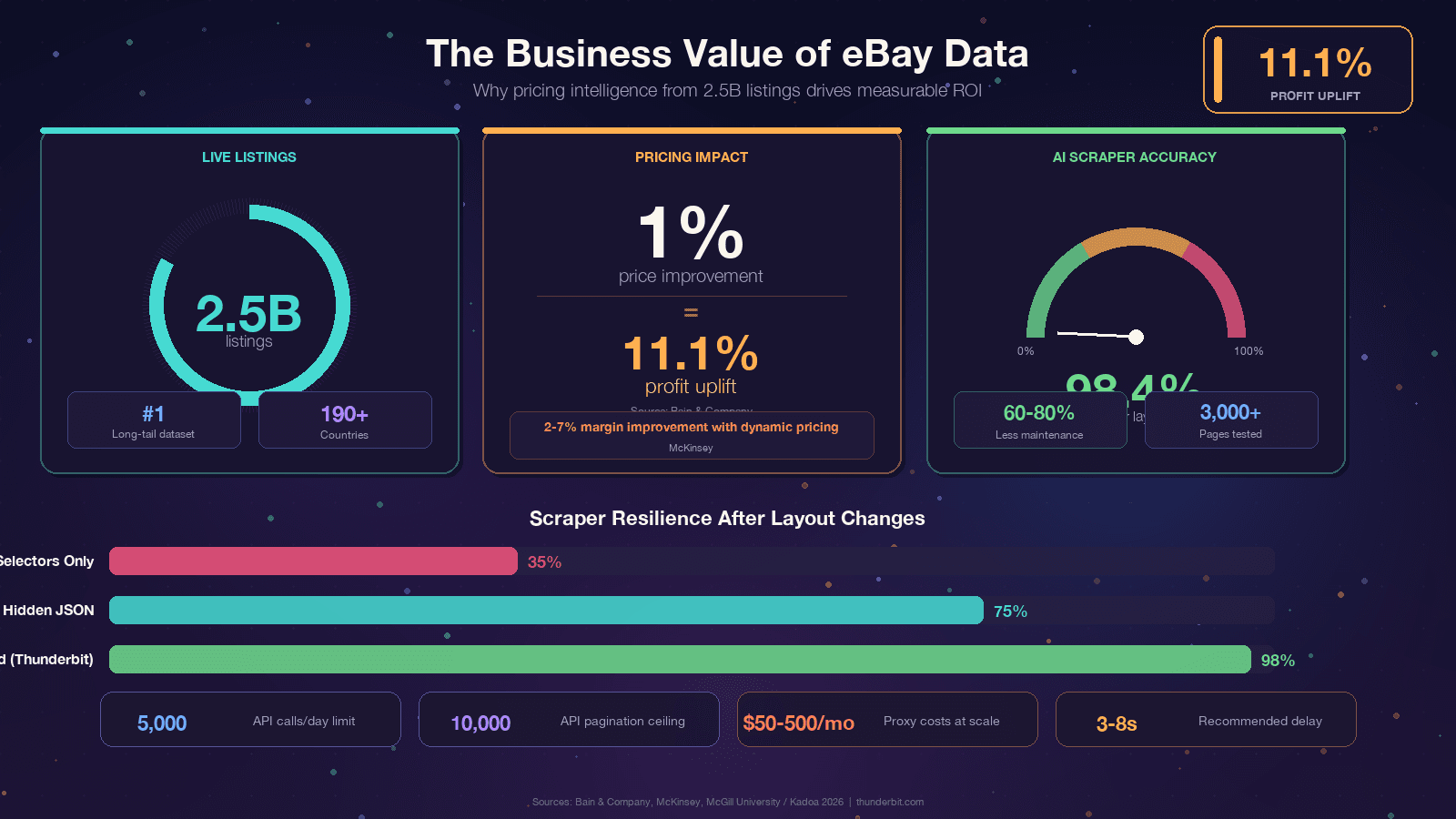
Wspólny mianownik: eBay ma te dane, ale są one zamknięte w stronach internetowych.
Scraping pozwala zamienić je w przewagę konkurencyjną.
Oficjalne API eBay kontra scrapowanie w Pythonie: co wybrać?
To pytanie, na które chciałbym częściej widzieć uczciwą odpowiedź w poradnikach. eBay udostępnia oficjalne API — przede wszystkim Browse API — i wielu użytkowników zastanawia się, czy lepiej z niego korzystać, czy scrapować bezpośrednio. Odpowiedź zależy wyłącznie od tego, jakich danych potrzebujesz.
| Kryterium | eBay Browse/Finding API | Scraping w Pythonie |
|---|---|---|
| Oferty sprzedane/zakończone | Ograniczone — istnieje Marketplace Insights API, ale dostęp jest często odrzucany | Pełny dostęp przez parametry URL LH_Sold=1&LH_Complete=1 |
| Limity zapytań | 5000 wywołań dziennie w podstawowym planie | Zarządzane samodzielnie (zależne od proxy) |
| Pola danych | Z góry zdefiniowane (tytuł, cena, kategoria, podstawowe dane sprzedawcy) | Wszystko, co widać na stronie (recenzje, pełna specyfikacja, macierz wariantów) |
| Złożoność konfiguracji | OAuth 2.0, rejestracja aplikacji, klucze API | pip install + kod |
| Stabilność | Stabilne endpointy | Psuje się, gdy zmienia się HTML |
| Koszt | Dostępny darmowy plan, płatny przy większej skali | Darmowy kod, ale przy dużej skali dochodzą koszty proxy |
| Dane wariantów/MSKU | Częściowe — często tylko SKU nadrzędne | Pełne (poprzez parsowanie ukrytego JSON) |
| Głębokość paginacji | Twardy limit 10 000 elementów | Teoretycznie bez limitu |
Krótka uwaga: stare Finding API (z findCompletedItems) zostało całkowicie wycofane w lutym 2025. Jeśli używasz ebaysdk-python albo jakiejkolwiek biblioteki, która uderza w moduł Finding, to teraz nie działa to produkcyjnie.
Moja rekomendacja: używaj Browse API do stabilnych, umiarkowanych ilościowo, ustrukturyzowanych zapytań dotyczących aktywnych ofert. Używaj scrapowania w Pythonie, gdy potrzebujesz cen sprzedaży, recenzji, danych wariantów albo dowolnego pola, którego API nie udostępnia. Wiele zespołów łączy oba podejścia.
Jakich narzędzi i bibliotek potrzebujesz, aby scrapować eBay w Pythonie?
Zanim napiszemy kod, spójrzmy na zestaw narzędzi. W przypadku większości stron eBay nie potrzebujesz headless browsera — dane są osadzone w HTML renderowanym po stronie serwera.
| Biblioteka | Zastosowanie |
|---|---|
requests lub httpx | Klient HTTP do pobierania stron eBay |
curl_cffi | Klient HTTP z prawdziwym fingerprintem TLS przeglądarki (kluczowy do obchodzenia Akamai) |
beautifulsoup4 | Parser HTML do wyciągania danych selektorami CSS |
lxml | Szybkie zaplecze parsera dla BeautifulSoup |
jmespath | Język zapytań do parsowania zagnieżdżonych bloków JSON |
pandas | Obróbka danych oraz eksport do CSV/Excel |
gspread | Integracja z Google Sheets |
Zainstaluj wszystko jedną komendą:
pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspread
Używaj Pythona 3.11+ — pandas 3.0 wymaga 3.10+, a 3.11 daje 10–60% zysku wydajności przy pracy I/O-bound.
Jedna biblioteka zasługuje na szczególne wyróżnienie: curl_cffi to najważniejsza modernizacja, jaką może zrobić scraper eBay w 2026 roku. eBay korzysta z Akamai Bot Manager, a głównym sygnałem wykrywania jest fingerprint TLS. Zwykły requests wysyła fingerprint JA3 „w kształcie Pythona”, który jest natychmiast flagowany. curl_cffi udaje handshake TLS prawdziwej przeglądarki Chrome, co pozwala obsłużyć około 90% chronionych przez Akamai celów bez potrzeby uruchamiania headless browsera.
Wypróbuj Thunderbit na dowolnej stronie
Krok po kroku: jak scrapować wyniki wyszukiwania eBay w Pythonie
To jest główny tutorial. Będziemy scrapować strony wyników wyszukiwania eBay dla ofert produktów.
- Poziom trudności: początkujący–średnio zaawansowany
- Czas potrzebny: ok. 30 minut do pierwszego działającego scrapera
- Czego potrzebujesz: Python 3.11+, biblioteki z sekcji powyżej, terminal i docelowy URL wyszukiwania eBay
Krok 1: przygotuj projekt Pythona
Utwórz katalog projektu i zainstaluj zależności:
mkdir ebay-scraper && cd ebay-scraper
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install requests curl_cffi beautifulsoup4 lxml pandas
Utwórz plik o nazwie scrape_ebay.py. To będzie twoje środowisko pracy.
Krok 2: zbuduj URL wyszukiwania eBay
Struktura URL wyszukiwania na eBay jest prosta. Najważniejszy parametr to _nkw (keyword):
import urllib.parse
keyword = "airpods pro"
base_url = "https://www.ebay.com/sch/i.html"
params = {
"_nkw": keyword,
"_ipg": "120", # liczba elementów na stronę: 60, 120 lub 240 (240 może uruchamiać flagi botowe)
"_pgn": "1", # numer strony
}
url = f"{base_url}?{urllib.parse.urlencode(params)}"
print(url)
# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1
Inne przydatne parametry:
LH_BIN=1— tylko Buy It Now_sacat=175673— konkretna kategoria_sop=12— sortowanie według najlepszego dopasowania (10 = najniższa cena + wysyłka, 13 = najnowsze)LH_Complete=1&LH_Sold=1— oferty sprzedane/zakończone (omówione w osobnej sekcji poniżej)
Krok 3: wyślij żądanie i obsłuż odpowiedź
To tutaj curl_cffi pokazuje swoją wartość. Zwykły requests.get() często zwróci 403 od Akamai. Z curl_cffi udajemy prawdziwą przeglądarkę Chrome:
from curl_cffi import requests as cffi_requests
import random, time
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
]
HEADERS = {
"User-Agent": random.choice(USER_AGENTS),
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
}
def fetch_page(url, max_retries=5):
delay = 2
for attempt in range(max_retries):
try:
r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
if r.status_code == 200:
return r.text
if r.status_code in (403, 429, 503):
retry_after = r.headers.get("Retry-After")
sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
print(f" Status {r.status_code}, ponawiam za {sleep_for:.1f}s...")
time.sleep(sleep_for)
delay *= 2
continue
r.raise_for_status()
except Exception as e:
print(f" Błąd żądania: {e}, ponawiam...")
time.sleep(delay)
delay *= 2
raise RuntimeError(f"Nie udało się po {max_retries} próbach: {url}")
Eksponencjalny backoff z losowym jitterem jest ważny — stałe odstępy czasowe same w sobie są fingerprintem bota.
Krok 4: parsuj oferty produktów ze strony wyników wyszukiwania
eBay jest obecnie w trakcie migracji między dwoma układami wyników wyszukiwania. Odporny scraper musi obsługiwać oba:
| Pole | Starszy układ | Nowy układ |
|---|---|---|
| Kontener karty | li.s-item | li.s-card lub div.su-card-container |
| Tytuł | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| Cena | span.s-item__price | .s-card__price |
Kod parsujący oba układy:
from bs4 import BeautifulSoup
def parse_search_results(html):
soup = BeautifulSoup(html, "lxml")
cards = soup.select("li.s-item, li.s-card, div.su-card-container")
results = []
for card in cards:
# Tytuł — sprawdź oba układy
title_el = card.select_one(".s-item__title, .s-card__title")
title = title_el.get_text(strip=True) if title_el else None
# Pomiń fantomową kartę zastępczą „Shop on eBay”
if not title or "Shop on eBay" in title:
continue
# Cena
price_el = card.select_one("span.s-item__price, .s-card__price")
price = price_el.get_text(strip=True) if price_el else None
# URL
link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
url = link_el["href"].split("?")[0] if link_el else None
# Obraz
img_el = card.select_one("img.s-item__image-img, .s-card__image img")
image = None
if img_el:
image = img_el.get("src") or img_el.get("data-src")
# Wysyłka
ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
shipping = ship_el.get_text(strip=True) if ship_el else None
results.append({
"title": title,
"price": price,
"url": url,
"image": image,
"shipping": shipping,
})
return results
Pułapka z pierwszą, fantomową kartą to klasyczny problem. Pierwsze li.s-item na wielu stronach wyników eBay to ukryty placeholder z tytułem „Shop on eBay” i bez realnej ceny. Zawsze go filtruj.
Krok 5: obsłuż paginację, aby scrapować wiele stron
eBay paginuje przez parametr _pgn. Link do następnej strony używa a.pagination__next:
import urllib.parse
def scrape_ebay_search(keyword, max_pages=5):
all_results = []
for page_num in range(1, max_pages + 1):
params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
print(f"Scraping page {page_num}: {url}")
html = fetch_page(url)
results = parse_search_results(html)
if not results:
print(f" Brak wyników na stronie {page_num}, zatrzymuję się.")
break
all_results.extend(results)
print(f" Znaleziono {len(results)} ofert (łącznie: {len(all_results)})")
# Uprzejma przerwa — 3 do 8 sekund z losowym jitterem
time.sleep(random.uniform(3, 8))
return all_results
Losowy jitter 3–8 sekund nie jest opcjonalny.
eBay i warstwa Akamai wykrywają ciągłe tempo powyżej 1 żądania na sekundę z jednego IP.
Krok 6: eksportuj zeskrobane dane do CSV lub JSON
import pandas as pd
results = scrape_ebay_search("airpods pro", max_pages=3)
df = pd.DataFrame(results)
df.to_csv("ebay_airpods.csv", index=False)
df.to_json("ebay_airpods.json", orient="records", indent=2)
print(f"Wyeksportowano {len(df)} ofert do CSV i JSON.")
Powinieneś teraz mieć czysty arkusz z ofertami eBay. Na moim komputerze scrapowanie 3 stron (360 ofert) zajęło około 45 sekund, łącznie z opóźnieniami.
Jak scrapować strony szczegółów produktu eBay w Pythonie
Wyniki wyszukiwania dają tylko skrót. Strony szczegółów produktu zawierają najcenniejsze informacje: pełny opis, oceny sprzedawcy, cechy przedmiotu, karuzele obrazów i dane wariantów.
Parsowanie pojedynczej strony oferty
Strony przedmiotów eBay mają adres w formacie /itm/<ITEM_ID>. Najstabilniejszą metodą wyciągania danych jest JSON-LD — eBay osadza blok schematu Product, który przetrwa niemal wszystkie zmiany CSS:
import json
def parse_item_page(html):
soup = BeautifulSoup(html, "lxml")
item = {}
# 1. JSON-LD — najstabilniejsza ścieżka ekstrakcji
for tag in soup.find_all("script", type="application/ld+json"):
try:
data = json.loads(tag.string or "")
except (json.JSONDecodeError, TypeError):
continue
if isinstance(data, dict) and data.get("@type") == "Product":
item["title"] = data.get("name")
item["brand"] = (data.get("brand") or {}).get("name")
item["images"] = data.get("image")
offers = data.get("offers") or {}
item["price"] = offers.get("price")
item["currency"] = offers.get("priceCurrency")
break
# 2. Fallbacki CSS dla pól, których nie ma w JSON-LD
def first_text(selectors):
for sel in selectors:
el = soup.select_one(sel)
if el and el.get_text(strip=True):
return el.get_text(strip=True)
return None
item.setdefault("title", first_text([
"h1.x-item-title__mainTitle",
"h1.x-item-title__mainTitle .ux-textspans--BOLD",
]))
item["condition"] = first_text([
".x-item-condition-text .ux-textspans",
])
item["seller"] = first_text([
".x-sellercard-atf__info__about-seller a .ux-textspans",
])
item["shipping"] = first_text([
"div.ux-labels-values--shipping .ux-textspans--BOLD",
])
# 3. Cechy przedmiotu
specifics = {}
for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
if k and v:
specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
item["specifics"] = specifics
return item
Ten wzorzec — najpierw JSON-LD, potem fallbacki CSS — jest kluczem do budowania scraperów, które nie psują się co kwartał. Więcej o tym poniżej.
Scrapowanie wariantów produktów eBay (dane MSKU)
Niektóre oferty eBay mają wiele wariantów — różne kolory, rozmiary, pojemności pamięci. Widoczny DOM pokazuje tylko zakres cen, np. „899 do 1099 dolarów”, dopóki użytkownik nie kliknie opcji. Faktyczna cena dla każdego wariantu znajduje się w ukrytym obiekcie JavaScript o nazwie MSKU.
To jeden z obszarów, w których API eBay daje tylko częściowe dane (SKU nadrzędne), więc scraping jest lepszym rozwiązaniem.
import re, json
def extract_variants(html):
# Nietrywialne dopasowanie niechciwe jest kluczowe — chciwe .+ pochłania całą stronę
m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
if not m:
return []
try:
msku = json.loads(m.group(1))
except json.JSONDecodeError:
return []
item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
skus = []
for combo_key, variation_id in msku.get("variationCombinations", {}).items():
option_ids = combo_key.split("_")
options = [item_labels.get(oid, oid) for oid in option_ids]
var = msku.get("variationsMap", {}).get(str(variation_id), {})
bin_model = var.get("binModel", {})
price_spans = bin_model.get("price", {}).get("textSpans", [{}])
price = price_spans[0].get("text") if price_spans else None
qty = var.get("quantity")
skus.append({
"options": options,
"price": price,
"quantity_available": qty,
"variation_id": variation_id,
})
return skus
Ten niechciwy fragment (.+?) w regexie to miejsce, na którym potyka się niemal każdy scraper eBay. Chciwe .+ pochłania wszystko aż do ostatniego "QUANTITY" na stronie, co daje uszkodzony JSON. Widziałem ten błąd w co najmniej trzech „działających” poradnikach.
Jak scrapować sprzedane i zakończone oferty eBay w Pythonie
To właśnie ten przypadek użycia najmocniej uzasadnia scrapowanie zamiast API. Dane o sprzedanych przedmiotach — co faktycznie zostało sprzedane, za ile i kiedy — to złoty standard dla badań rynku, wyceny resellerskiej i appraisal. Browse API eBay nie udostępnia tego wprost. Marketplace Insights API teoretycznie to zapewnia, ale dostęp ma status „Limited Release” i często jest odrzucany.
Potrzebne parametry URL to LH_Complete=1 (oferty zakończone) oraz LH_Sold=1 (ograniczenie do faktycznie sprzedanych). Musisz podać oba. Samo LH_Sold=1 na niektórych kategoriach po cichu wraca do aktywnych ofert — to najczęstsza pułapka społeczności.
def scrape_sold_listings(keyword, max_pages=3):
all_sold = []
for page_num in range(1, max_pages + 1):
params = {
"_nkw": keyword,
"_ipg": "120",
"_pgn": str(page_num),
"LH_Complete": "1",
"LH_Sold": "1",
}
url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
print(f"Scraping sold page {page_num}...")
html = fetch_page(url)
soup = BeautifulSoup(html, "lxml")
cards = soup.select("li.s-item")
for card in cards:
title_el = card.select_one(".s-item__title")
title = title_el.get_text(strip=True) if title_el else None
if not title or "Shop on eBay" in title:
continue
# Uwzględniaj tylko faktycznie sprzedane przedmioty (zielona, dodatnia cena)
sold_tag = card.select_one(
".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
)
if sold_tag is None:
continue # Niesprzedana zakończona oferta — pomiń
price_el = card.select_one("span.s-item__price")
price = price_el.get_text(strip=True) if price_el else None
# Parsowanie daty sprzedaży
sold_date = None
import re, datetime as dt
card_text = card.get_text()
m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
if m:
sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
link_el = card.select_one("a.s-item__link[href]")
url = link_el["href"].split("?")[0] if link_el else None
all_sold.append({
"title": title,
"sold_price": price,
"sold_date": sold_date,
"url": url,
})
if not cards:
break
time.sleep(random.uniform(3, 8))
return all_sold
Kluczowa różnica w HTML: sprzedane przedmioty pokazują cenę na zielono (w opakowaniu .POSITIVE), a niesprzedane zakończone oferty pokazują cenę na czerwono, przekreśloną. Zawsze filtruj po klasie .POSITIVE.
Dlaczego scrapery eBay się psują (i jak budować odporne rozwiązania)
Jeśli twój scraper eBay przestał działać, nie jesteś sam. To najczęstszy ból w każdym wątku na forum o scrapowaniu eBay, jaki czytałem. Pytanie nie brzmi czy scraper się zepsuje — tylko kiedy.
Dlaczego tak się dzieje:
- eBay używa renderowania opartego na React z dynamicznie generowanymi klasami, które zmieniają się przy wdrożeniach
- Testy A/B pokazują różne struktury DOM różnym użytkownikom (obecny podwójny układ
s-item/s-cardjest tego żywym przykładem) - Okresowe redesigny zmieniają zagnieżdżenie HTML, nawet jeśli same dane pozostają takie same
- Stare selektory, takie jak
#itemTitlei#prcIsum, zostały usunięte lata temu, ale nadal pojawiają się w poradnikach
Jak ujmuje to przewodnik Scrapfly z 2026 roku: „Prawdziwe wyzwanie przy scrapowaniu eBay polega na radzeniu sobie ze zmianami selektorów CSS. eBay regularnie aktualizuje frontend, przez co psuje scraperom zależnym od konkretnych nazw klas.”
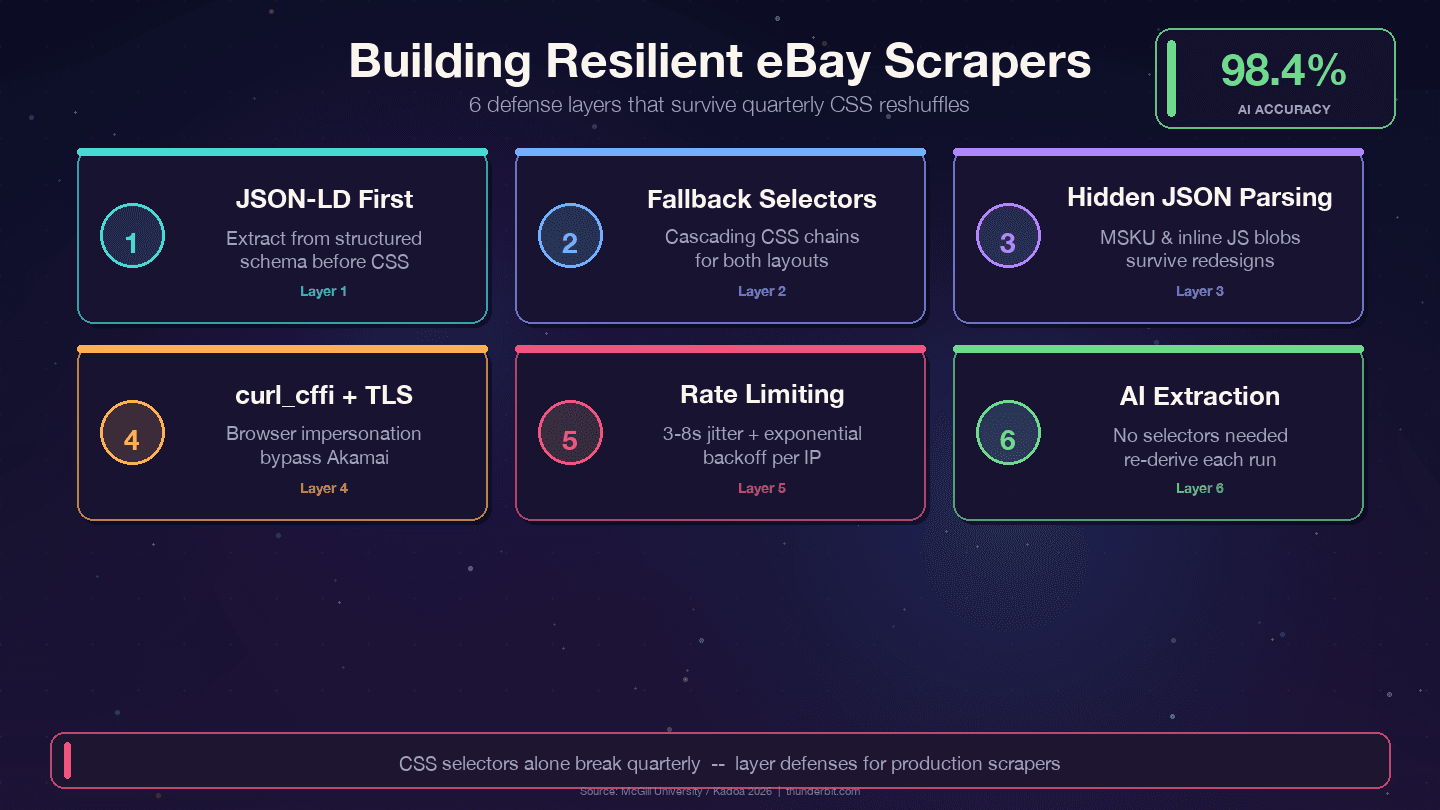
Strategie obronne dla długowiecznych scraperów eBay
Cztery strategie, które przetrwają kwartalne przetasowania w eBay:
1. Priorytet dla JSON-LD zamiast selektorów CSS. eBay osadza ustrukturyzowane dane schematu Product na każdej stronie przedmiotu. Warstwa danych zmienia się znacznie rzadziej niż warstwa prezentacji — projektanci refaktoryzują klasy CSS co kwartał, ale nazwy pól backendowych, takich jak price, name czy seller, są mapowane do wewnętrznych API i rzadko się zmieniają.
2. Używaj kaskadowych selektorów zapasowych. Nigdy nie polegaj na jednym selektorze CSS. Zawsze podawaj alternatywy:
def first_text(soup, selectors):
for sel in selectors:
el = soup.select_one(sel)
if el and el.get_text(strip=True):
return el.get_text(strip=True)
return None
title = first_text(soup, [
"h1.x-item-title__mainTitle",
"h1.x-item-title__mainTitle .ux-textspans--BOLD",
"[data-testid='x-item-title'] h1",
])
3. Parsuj ukryte bloki JSON. Obiekt wariantów MSKU i wbudowane dane JavaScript przetrwają zmiany CSS, bo są generowane po stronie serwera. Wyciąganie ich regexem z tagów <script> wymaga więcej pracy na początku, ale dramatycznie zmniejsza koszty utrzymania.
4. Loguj błędy selektorów. Dodaj monitoring, żeby wiedzieć kiedy selektor przestaje pasować, a nie tylko że dane są puste:
if title is None:
print(f"WARNING: selector tytułu nie zadziałał dla {url}")
5. Używaj curl_cffi z impersonacją przeglądarki. To pozwala obejść TLS fingerprinting Akamai bez headless browsera.
Alternatywa napędzana przez AI: bez utrzymania selektorów
Jeśli masz dość łatania selektorów co kilka miesięcy, istnieje zupełnie inne podejście. Narzędzia takie jak Thunderbit używają AI, aby za każdym razem czytać stronę na nowo i dynamicznie wyprowadzać logikę ekstrakcji. Badanie McGill University porównujące AI ze scraperami opartymi na selektorach na 3000 stron pokazało, że metody AI utrzymywały 98,4% dokładności nawet po zmianach układu, a branżowe benchmarki wskazują na 60–80% mniejszy nakład na utrzymanie scraperów.
| Podejście | Czy psuje się po zmianie HTML przez eBay? | Nakład na utrzymanie |
|---|---|---|
| Twardo zakodowane selektory CSS | Tak, co kwartał | Wysoki — ciągłe poprawki |
| Ekstrakcja ukrytego JSON / JSON-LD | Rzadko | Niski |
| Scrapowanie oparte na AI (Thunderbit) | Nie — AI odtwarza selektory przy każdym uruchomieniu | Brak |
Zbieraj dane eBay z pomocą AI Get Started Free
Workflow Thunderbit omówię szczegółowo później. Na razie najważniejsze jest to: jeśli budujesz scraper, który ma działać miesiącami, zainwestuj w ekstrakcję opartą najpierw na JSON-ie i selektory zapasowe. Jeśli w ogóle nie chcesz utrzymywać selektorów, podejście AI naprawdę warto rozważyć.
Automatyzacja cyklicznego scrapowania eBay do monitorowania cen
Jednorazowe scrapowanie jest przydatne. Ale monitorowanie cen, śledzenie stanów magazynowych i analiza konkurencji wymagają cyklicznego zbierania danych. Każdy artykuł konkurencji, który czytałem, wspomina monitoring cen jako zastosowanie, ale prawie żaden nie pokazuje, jak to faktycznie zautomatyzować.
Opcja 1: Cron joby (Linux/macOS) lub Harmonogram zadań (Windows)
Najprostsze podejście. Owiń swój skrypt Pythona w cron. Zawsze używaj pełnej ścieżki do Pythona z wirtualnego środowiska — cron działa w minimalnym środowisku:
crontab -e
# Codziennie o 08:15
15 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1
W Windows użyj PowerShell:
$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
$T = New-ScheduledTaskTrigger -Daily -At 8:15am
Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $T
To wymaga stale włączonej maszyny, a proxy i zabezpieczenia anty-botowe zarządzasz samodzielnie.
Opcja 2: funkcje chmurowe (serverless)
AWS Lambda albo Google Cloud Functions pozwalają uruchamiać scrapery bez dedykowanego serwera. To większy wysiłek konfiguracyjny — musisz spakować zależności, obsłużyć timeouty (Lambda ma limit 15 minut) i nadal zarządzać proxy. Ale nie ma utrzymania serwera.
Opcja 3: planowanie bez kodu w Thunderbit
Funkcja Scheduled Scraper Thunderbit pozwala opisać interwał zwykłym językiem (np. „co dzień o 8 rano”), wkleić URL-e eBay i kliknąć Schedule. Działa w chmurze z wbudowaną obsługą anty-bot.
| Podejście | Nakład konfiguracji | Wymaga serwera? | Obsługa anty-bota? |
|---|---|---|---|
| Cron + skrypt Pythona | Średni | Tak (maszyna zawsze włączona) | Proxy po twojej stronie |
| Funkcja chmurowa (Lambda) | Wysoki | Nie (serverless) | Proxy po twojej stronie |
| Thunderbit Scheduled Scraper | Niski (opis słowny) | Nie (w chmurze) | Wbudowana |
Do przechowywania danych z cyklicznych scrape’ów lokalna baza SQLite jest najlepszym rozwiązaniem dla historii cen. Używaj ON CONFLICT ... DO UPDATE (a nie INSERT OR REPLACE, które psuje klucze obce i nadpisuje kolumny):
CREATE TABLE IF NOT EXISTS listings (
item_id TEXT PRIMARY KEY,
title TEXT NOT NULL,
price REAL,
last_price REAL,
first_seen_at TEXT DEFAULT (datetime('now')),
last_seen_at TEXT DEFAULT (datetime('now'))
);
CREATE TABLE IF NOT EXISTS price_history (
item_id TEXT NOT NULL,
observed_at TEXT NOT NULL DEFAULT (datetime('now')),
price REAL NOT NULL,
PRIMARY KEY (item_id, observed_at)
);
Wypróbuj Scheduled Scraper Thunderbit
Nie chcesz kodować? Jak scrapować eBay w 2 minuty z Thunderbit
Poświęciłem już 2000 słów na kod Pythona. Teraz chcę uczciwie powiedzieć, kiedy nie jest on potrzebny.
Jeśli jesteś użytkownikiem biznesowym robiącym jednorazowe badanie rynku, resellerem sprawdzającym porównywalne oferty albo zespołem e-commerce, który potrzebuje danych na już bez sprintu deweloperskiego, Python to przesada. Konfiguracja, utrzymanie selektorów, zarządzanie proxy — to sporo narzutu na coś w stylu: „po prostu potrzebuję tych 200 ofert w arkuszu”.
Jak Thunderbit scrapuje eBay — krok po kroku
- Zainstaluj rozszerzenie Chrome Thunderbit — bez karty kredytowej.
- Otwórz dowolną stronę wyników wyszukiwania lub produkt na eBay w Chrome.
- Kliknij „AI Suggest Fields” w panelu bocznym Thunderbit. AI odczyta stronę i zaproponuje kolumny: Tytuł, Cena, Stan, Dostawa, Sprzedawca, Ocena.
- Kliknij „Scrape”. Rozszerzenie przejdzie przez paginację i wypełni tabelę danych. Dla eBay Thunderbit ma gotowe szablony instant scraper, które działają jednym kliknięciem.
- Wyeksportuj do Google Sheets, Airtable, Notion, CSV, JSON lub Excel — za darmo.
Cały proces zajmuje mniej niż 2 minuty.
Sprawdzałem to.
Wzbogacanie podstron: dane ze strony szczegółów bez dodatkowego kodu
Po zeskrobaniu strony wyników wyszukiwania Thunderbit może odwiedzić stronę szczegółów każdej oferty i dodać kolejne pola — pełną specyfikację, informacje o sprzedawcy, opis, wszystkie obrazy. Zastępuje to 20+ linijek kodu Pythona do scrapowania podstron, które napisaliśmy wcześniej, jednym kliknięciem.
Kiedy nadal warto używać Pythona
Python wygrywa, gdy potrzebujesz:
- Scrapowania na dużą skalę (dziesiątki tysięcy stron na jedno uruchomienie)
- Bardzo niestandardowej logiki parsowania lub transformacji danych
- Integracji z istniejącymi pipeline’ami danych (Airflow, dbt, Kafka)
- Precyzyjnej kontroli TLS/sesji do zaawansowanej walki z botami
- Ekonomiki jednostkowej — przy milionach rekordów utrzymywany stack bije SaaS oparty na kredytach
W większości jednorazowych lub średniej skali projektów Thunderbit jest szybszy i prostszy. W produkcyjnych pipeline’ach na dużą skalę Python daje pełną kontrolę.
Wskazówki, jak uniknąć blokady podczas scrapowania eBay w Pythonie
eBay i Akamai naprawdę działają. To, co w praktyce rzeczywiście pomaga:
- Używaj
curl_cffizimpersonate="chrome124"— to największa pojedyncza poprawa względem zwykłegorequests - Rotuj User-Agenty z listy aktualnych wersji przeglądarek (Chrome 143, Firefox 124, Safari 26)
- Dodawaj losowe opóźnienia 3–8 sekund między żądaniami — stałe interwały są fingerprintem
- Używaj proxy residential albo rotujących przy czymkolwiek większym niż kilka dziesiątek stron. Adresy z centrów danych (AWS, GCP, DigitalOcean) są szybko flagowane przez Akamai.
- Szanuj
robots.txt— większość filtrowanych URL-i przeglądania jest tam wprost oznaczona jako Disallowed; strony szczegółów przedmiotów (/itm/<id>) nie są - Obsługuj CAPTCHA łagodnie — wykryj ją i spróbuj ponownie z innym IP albo skorzystaj z usługi rozwiązującej CAPTCHA
- Nie bombarduj serwera. Precedens eBay v. Bidder's Edge pokazuje, że trespass to chattels ma zastosowanie, gdy scraping realnie degraduje serwery. Tempo 1 żądanie na sekundę na IP trzyma cię daleko od tego progu.
W przypadku komercyjnego użycia na dużą skalę rozważ użycie Browse API dla aktywnych ofert i targetowanego scrapowania tylko dla sprzedanych porównań oraz danych, których API nie udostępnia. Taki model hybrydowy jest czystszy zarówno technicznie, jak i prawnie.
Czy scrapowanie eBay w Pythonie jest legalne?
Nie jestem prawnikiem, a ten wpis nie stanowi porady prawnej. Ujmę to więc krótko.
Krajobraz prawny przesunął się na korzyść scrapowania publicznie dostępnych danych. Kluczowe precedensy:
- hiQ v. LinkedIn (9th Cir., 2022): scrapowanie publicznie dostępnych danych nie narusza CFAA
- Van Buren v. United States (SCOTUS, 2021): zawęziło zapis CFAA o „przekroczeniu uprawnionego dostępu”
- Meta v. Bright Data (N.D. Cal., 2024): scrapowanie bez logowania nie narusza warunków platformy, bo scraper nie jest „użytkownikiem”
Mimo to aktualizacja Warunków użytkowania eBay z lutego 2026 wprost zakazuje „agentów kupujących w imieniu użytkownika, botów opartych na LLM oraz wszelkich end-to-end flow próbujących składać zamówienia bez ludzkiej kontroli”. Granica jest jasna: tylko odczyt publicznych stron jest bezpieczny; automatyzacja checkoutu — nie.
Dobre praktyki: zbieraj wyłącznie publicznie widoczne dane. Nie twórz fałszywych kont i nie obchodź logowania. Nie odsprzedawaj hurtowo chronionych prawem autorskim obrazów ofert. W przypadku projektów komercyjnych skonsultuj się z prawnikiem.
Podsumowanie i najważniejsze wnioski
Python to najbardziej elastyczny sposób scrapowania eBay, ale wymaga stałego utrzymania, bo HTML strony się zmienia. Ramy decyzyjne są proste:
- Użyj eBay Browse API do stabilnych, umiarkowanych ilościowo, ustrukturyzowanych zapytań o aktywne oferty
- Użyj scrapowania w Pythonie do ofert sprzedanych, recenzji, wariantów i wszystkiego, czego API nie pokazuje
- Użyj Thunderbit, jeśli chcesz dane eBay bez pisania ani utrzymywania kodu
Kod w tym przewodniku stawia na odporność: najpierw ekstrakcja JSON-LD, potem kaskadowe fallbacki CSS, a dla wariantów parsowanie ukrytego JSON. Takie warstwowe podejście sprawia, że twój scraper nie padnie przy następnym redesignie frontendowym eBay.
Jeśli chcesz spróbować bezkodowej ścieżki, darmowy plan Thunderbit pozwala przetestować to na stronach eBay już teraz. A jeśli chcesz zobaczyć, jak działa szablon eBay scraper, to jest to dosłownie jedno kliknięcie.
Więcej o narzędziach do web scrapingu znajdziesz w naszych poradnikach: najlepsze automatyczne narzędzia do web scrapingu, jak zeskrobać dane ze strony do Excela oraz najlepsze narzędzia do web scrapingu w Pythonie. Możesz też obejrzeć tutoriale na kanale Thunderbit na YouTube.
Wypróbuj Thunderbit do scrapowania eBay Get Started Free
FAQ
1. Czy mogę scrapować eBay za darmo w Pythonie?
Tak. Wszystkie biblioteki (Requests, BeautifulSoup, curl_cffi, pandas) są darmowe i open source. Koszty pojawiają się przy skali — residential proxy dla dużego wolumenu scrapingu zwykle kosztują 50–500 USD miesięcznie, zależnie od transferu. W małych projektach (kilkaset stron) możesz scrapować z domowego IP, jeśli zachowasz ostrożne limity tempa.
2. Jak scrapować sprzedane przedmioty i oferty zakończone eBay w Pythonie?
Dodaj LH_Complete=1&LH_Sold=1 do parametrów URL wyszukiwania. Musisz podać oba — samo LH_Sold=1 na niektórych kategoriach po cichu wraca do aktywnych ofert. Filtruj wyniki, sprawdzając klasę CSS .POSITIVE na elemencie ceny, co oznacza faktyczną sprzedaż, a nie niesprzedaną wygasłą ofertę.
3. Czy eBay blokuje web scraping?
eBay korzysta z Akamai Bot Manager, który wykrywa scraperów głównie przez fingerprinting TLS i analizę zachowania. Zwykłe wywołania requests często kończą się odpowiedzią 403. Użycie curl_cffi z impersonacją przeglądarki, rotacją User-Agentów i losowymi opóźnieniami 3–8 sekund między żądaniami radzi sobie z większością blokad. Przy dużej skali pomagają residential proxy.
4. Czy powinienem używać API eBay, czy scrapowania?
Użyj Browse API do stabilnych zapytań o aktywne oferty o umiarkowanej skali (do 5000 wywołań dziennie). Scrapowanie stosuj, gdy potrzebujesz historii cen sprzedanych przedmiotów, pełnych danych wariantów/MSKU, recenzji lub czegokolwiek, czego API nie pokazuje. Marketplace Insights API teoretycznie dostarcza danych o sprzedaży, ale dostęp jest ograniczony i często odrzucany.
5. Jaki jest najprostszy sposób na scrapowanie eBay bez kodowania?
Rozszerzenie Chrome Thunderbit używa AI, aby czytać strony eBay, sugerować kolumny danych i wyciągać oferty jednym kliknięciem. Obsługuje paginację, wzbogacanie danych o podstrony i eksport do Google Sheets, Excela, Airtable lub Notion. Gotowe szablony eBay scraper jeszcze bardziej przyspieszają typowe zastosowania.
Dowiedz się więcej




