
Jedni kolekcjonują znaczki. Inni — sneakersy. A jeśli działasz w sprzedaży, marketingu, e-commerce albo operacjach w 2025 roku, jest spora szansa, że zbierasz coś jeszcze bardziej… cyfrowego: dane z internetu. I to nie na małą skalę — firmy wydają dziś średnio 5 mln dolarów rocznie na pozyskiwanie danych z sieci, a web scraping stał się codziennym narzędziem w wielu zespołach: od strategii po customer support ().
Wraz z tym boomem, w praktycznie każdym poradniku o scraper w pythonie i w projektach danych dla biznesu przewijają się dwa nazwiska: playwright i selenium. Oba startowały jako narzędzia do automatyzacji przeglądarki pod testy, ale dziś są jednymi z najczęściej wybieranych frameworków do zamieniania internetu w uporządkowane, użyteczne dane. Jest tylko jeden haczyk: wybór między nimi to nie wyłącznie technikalia — chodzi o dopasowanie narzędzia do realnych potrzeb web scraping. A jeśli nie jesteś developerem albo po prostu chcesz szybko dowieźć wynik, jest też prostsza ścieżka (podpowiedź: bez pisania choćby jednej linijki Pythona). Lecimy.
Od narzędzi testowych do potęg web scrapingu: czym są Playwright i Selenium
Zacznijmy od kontekstu. selenium jest z nami od 2004 roku i dla wielu to „pewniak” w automatyzacji przeglądarki. Powstało z myślą o testerach QA i pozwala sterować przeglądarkami typu Chrome, Firefox, a nawet Internet Explorer (dla odważnych). playwright wszedł na scenę w 2020 roku, wspierany przez Microsoft, i wniósł bardziej nowoczesne podejście do automatyzacji — można go traktować jak młodsze, szybsze rodzeństwo Selenium.
Oba narzędzia pozwalają pisać skrypty (często w Pythonie), które odpalają przeglądarkę, wchodzą na stronę, klikają przyciski, wypełniają formularze i — co dla nas najważniejsze — wyciągają dane. Choć ich korzenie są w testach automatycznych, stały się fundamentem web scrapingu: od monitoringu cen po generowanie leadów (). I to już nie jest zabawa wyłącznie dla programistów — coraz więcej osób z biznesu próbuje budować własne scrapery (albo przynajmniej zaczyna temat).
Jest jednak twist: w scrapingu priorytety są inne. Mniej interesuje Cię pokrycie testami, a bardziej stabilne pozyskiwanie danych, omijanie blokad i brak konieczności spędzania weekendu na debugowaniu błędów w Pythonie. I właśnie tutaj różnice między Playwright a Selenium robią się naprawdę ważne.
Kluczowe różnice: Playwright vs. Selenium w web scrapingu

Przechodząc do konkretów: playwright i selenium potrafią scrapować strony, ale najlepiej błyszczą w innych scenariuszach.
- selenium to weteran. Działa z niemal każdą przeglądarką i wieloma językami, ma ogromną społeczność i dobrze pasuje do scrapowania starszych, bardziej statycznych stron o przewidywalnym układzie.
- playwright to nowoczesny gracz z funkcjami skrojonymi pod dzisiejszy web. Świetnie ogarnia dynamiczne strony oparte o JavaScript, ma wbudowane mechanizmy do logowania, obsługi pop-upów, nieskończonego scrolla i nie tylko. Jest też szybszy i prostszy w uruchomieniu, szczególnie jeśli robisz scraper w pythonie.
Nie opierajmy się jednak na hasłach — rozbijmy to na funkcje.
Tabela porównawcza funkcji: Playwright vs. Selenium
| Funkcja | Selenium | Playwright |
|---|---|---|
| Wsparcie języków | Python, Java, C#, JS, Ruby i inne | Python, JS/TS, Java, C# |
| Wsparcie przeglądarek | Chrome, Firefox, Edge, Safari, IE, Opera | Chromium (Chrome/Edge), Firefox, WebKit |
| Złożoność konfiguracji | Wymaga drivera przeglądarki i ręcznej konfiguracji | Jedna komenda instaluje wszystko |
| Szybkość / wydajność | Wolniejsze, bardziej zasobożerne | 40–50% szybciej, asynchroniczność i współbieżność w standardzie |
| Obsługa treści dynamicznych | Ręczne waity, więcej kodu | Auto-wait, łatwa obsługa stron „JS-heavy” |
| Omijanie anty-botów | Łatwiej wykrywalne, często potrzebne dodatki | Wbudowane mechanizmy „stealth”, lepsze naśladowanie użytkownika |
| Narzędzia debugowania | Podstawowe (Selenium IDE, zrzuty ekranu) | Inspector, nagrywanie wideo, codegen |
| Wsparcie społeczności | Ogromne, dojrzałe, mnóstwo tutoriali | Szybko rośnie, nowoczesna dokumentacja, aktywny rozwój |
| Workflow Python Scraper | Więcej konfiguracji i boilerplate’u | Płynniej, mniej kodu, łatwiejsze dla początkujących |
Jak wybrać: kiedy Playwright, a kiedy Selenium do web scrapingu
Które narzędzie wybrać do kolejnego projektu? Oto moja perspektywa po latach budowania automatyzacji i pomagania zespołom „wyciągać” dane z dzikiego zachodu internetu.
- selenium będzie dobrym wyborem, jeśli:
- Strona jest „starej szkoły” — statyczny HTML, mało JavaScriptu, brak wyskakujących okienek.
- Musisz wspierać nietypowe przeglądarki (tak, Internet Explorer) albo integrować się ze starszymi systemami.
- Chcesz korzystać z komfortu ogromnej społeczności i nieskończonej liczby odpowiedzi na StackOverflow.
- Znasz Selenium z projektów testowych.
- playwright warto wybrać, jeśli:
- Strona jest nowoczesna, dynamiczna i „ciężka” w JavaScripcie (e-commerce, social media, wszystko co rozkręca wentylator w laptopie).
- Potrzebujesz logowania, klikania zakładek, obsługi nieskończonego scrolla albo pop-upów.
- Chcesz szybko wystartować — mniej konfiguracji, mniej kodu.
- Masz dość wstawiania wszędzie
time.sleep(5)i wolisz, żeby narzędzie samo ogarniało timing.
Prosta zasada: jeśli pierwsze podejście do scrapowania strony w Selenium to seria momentów „czemu to się nie ładuje?”, to znak, że warto spróbować Playwright.
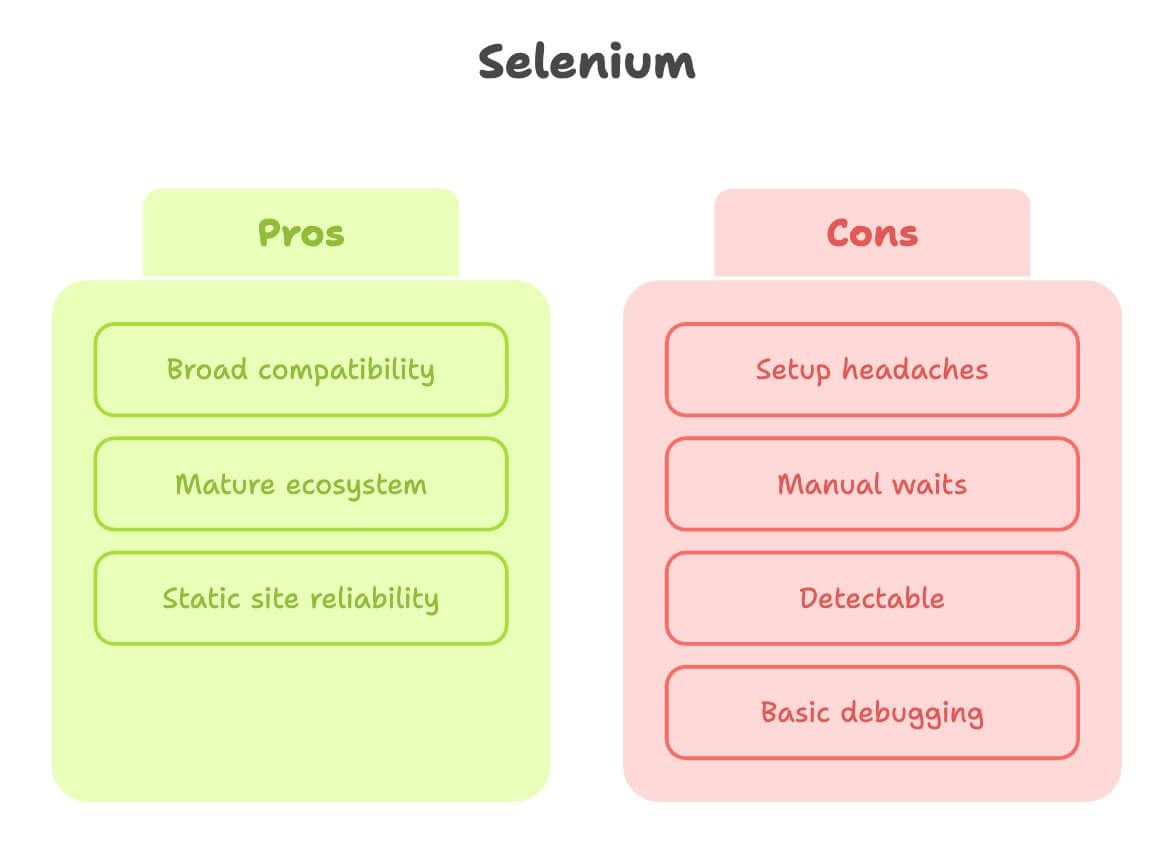
Selenium w web scrapingu: mocne strony i ograniczenia
Oddajmy Selenium, co Selenium’owe. To „dziadek” automatyzacji przeglądarki i w wielu zadaniach scrapingowych po prostu dowozi.
Mocne strony:
- Szeroka kompatybilność: działa z prawie każdą przeglądarką i wieloma językami.
- Dojrzały ekosystem: mnóstwo tutoriali, Q&A i wtyczek.
- Świetne do stron statycznych: gdy strona rzadko się zmienia, Selenium jest bardzo stabilne.
Ograniczenia:
- Problemy na starcie: trzeba pobrać i skonfigurować driver przeglądarki (np. ChromeDriver) i pilnować wersji. Początkujący często utkną właśnie tutaj ().
- Ręczne czekanie: przy dynamicznych treściach piszesz sporo explicit waitów albo — co gorsza — losowe sleepy.
- Łatwiejsze do wykrycia: wiele stron rozpoznaje przeglądarki sterowane Selenium i je blokuje, zwłaszcza w chmurze.
- Debugowanie raczej podstawowe: brak wbudowanego nagrywania wideo czy interaktywnego inspectora.
W skrócie: Selenium jest świetne do prostych, stabilnych stron — ale na nowoczesnych, interaktywnych potrafi być jak pchanie głazu pod górę.
Playwright w web scrapingu: mocne strony i ograniczenia
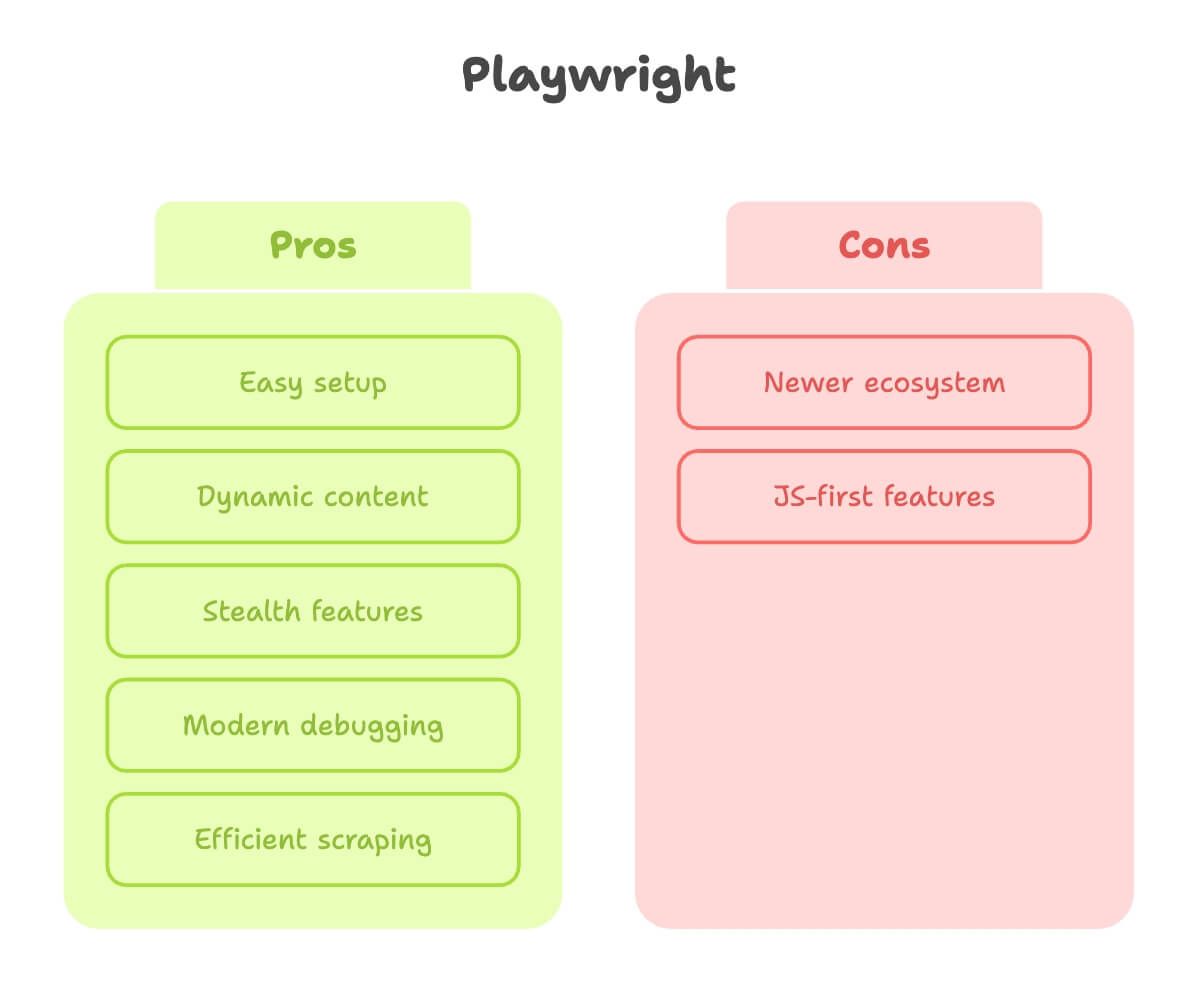
A teraz Playwright. Z perspektywy osoby, która sporo czasu spędziła z oboma narzędziami, Playwright wygląda jak narzędzie zrobione przez ludzi, którzy naprawdę przerobili ból web scrapingu.
Mocne strony:
- Prosta instalacja: jedno
pip install, jedna komenda i gotowe. Bez dramatu z driverami. - Świetna obsługa dynamicznych treści: auto-wait na elementy, więc nie musisz zgadywać, kiedy strona jest gotowa ().
- Funkcje „stealth”: lepiej udaje prawdziwego użytkownika, ma wsparcie dla wielu kontekstów przeglądarki (przydatne, gdy scrapujesz jako wielu „użytkowników” naraz).
- Nowoczesne debugowanie: Inspector, nagrywanie wideo, a nawet generowanie kodu na podstawie ręcznych kliknięć.
- Szybkość i efektywność: szczególnie przy dużej liczbie stron i pracy równoległej.
Ograniczenia:
- Młodszy ekosystem: nieco mniej materiałów, choć różnica szybko się zmniejsza.
- Część funkcji jest „JS-first”: w Pythonie działa prawie wszystko, ale czasem dokumentacja jest pełniejsza dla JS.
Wniosek: Playwright to mój pierwszy wybór dla stron choć trochę dynamicznych albo wtedy, gdy chcę szybko uzyskać wynik bez walki z konfiguracją.
Omijanie anty-botów: który Python Scraper lepiej radzi sobie z nowoczesnymi stronami?
Czas na słonia w pokoju: blokady. W web scrapingu najtrudniejsze często nie jest pisanie kodu — tylko dopilnowanie, żeby strona nie zatrzasnęła Ci drzwi przed nosem.
- selenium: w standardowej konfiguracji jest łatwiejsze do wykrycia. Strony widzą flagę
webdriver, headless user agent i inne „odciski palców”. Da się to obejść (np. undetected-chromedriver), ale wymaga to dodatkowej konfiguracji i ciągłego gonienia technologii anty-bot (). - playwright: ma wbudowane elementy „stealth”, np. ukrywanie śladów automatyzacji, wiele kontekstów przeglądarki i bardziej „ludzkie” interakcje. To nie magia, ale zwykle trudniej o blokadę na starcie.
Prawda jest taka: żadne z tych narzędzi nie jest w 100% odporne na anty-boty. Przy „wysokiej stawce” (np. dropy sneakersów czy serwisy biletowe) i tak potrzebujesz proxy, rotacji IP, a czasem rozwiązywania CAPTCHA. Playwright po prostu zmniejsza ból.
Doświadczenie developera: instalacja, próg wejścia i debugowanie
Porozmawiajmy o praktyce startu — zwłaszcza jeśli dopiero zaczynasz albo chcesz po prostu dowieźć temat bez doktoratu z Pythona.
- selenium:
- Instalacja: Python, Selenium, właściwy driver przeglądarki, PATH, zgodność wersji… (więcej osób widziałem zablokowanych na driverze niż na samym scrapingu).
- Próg wejścia: dużo materiałów, ale też sporo legacy i nieaktualnych tutoriali.
- Debugowanie: głównie printy i screenshoty. Selenium IDE istnieje, ale jest dość podstawowe.
- playwright:
- Instalacja:
pip install playwright, potemplaywright install. Koniec. - Próg wejścia: nowoczesna dokumentacja, dużo przykładów, a API jest bardziej „ludzkie” — możesz wybierać elementy po tekście, roli czy placeholderze.
- Debugowanie: Inspector pozwala przechodzić krok po kroku, obserwować przeglądarkę i nagrywać wideo z przebiegu scrapingu ().
- Instalacja:
Jeśli chcesz szybko zobaczyć efekty i spędzić mniej czasu na konfiguracji oraz gaszeniu pożarów, Playwright wygrywa. Selenium ma sens, gdy znasz jego „humory” albo potrzebujesz jego szerokiej kompatybilności.
Krok po kroku: pierwszy Python web scraper w Playwright lub Selenium
Zobaczmy, jak wygląda budowa scrapera w obu narzędziach — bez kodu, tylko etapy.
Playwright (Python):
- Zainstaluj Playwright i przeglądarki:
pip install playwright+playwright install - Uruchom przeglądarkę: Chromium, Firefox lub WebKit (headless albo z oknem).
- Wejdź na stronę:
page.goto("<https://example.com>") - Poczekaj na treść: Playwright automatycznie czeka na elementy.
- Wyciągnij dane: selektory przyjazne człowiekowi (np.
get_by_text,locator("span.price")). - Obsłuż paginację lub podstrony: pętle po stronach lub klikanie linków — łatwo też uruchamiać wiele stron równolegle.
- Wyeksportuj dane: do CSV, Excela lub bazy.
- Debuguj: Inspector lub nagrywanie wideo, gdy coś pójdzie nie tak.
Selenium (Python):
- Zainstaluj Selenium:
pip install selenium - Pobierz driver przeglądarki: (np. ChromeDriver), dodaj do PATH.
- Uruchom przeglądarkę: Chrome, Firefox lub inną.
- Wejdź na stronę:
driver.get("<https://example.com>") - Poczekaj na treść: ręcznie dodaj explicit waity (
WebDriverWait) albo — jeśli liczysz na szczęście —time.sleep. - Wyciągnij dane:
find_element/find_elements(selektory CSS/XPath). - Obsłuż paginację lub podstrony: pętle po URL-ach lub klikanie przycisków, ale timing i nawigację ogarniasz sam.
- Wyeksportuj dane: do CSV, Excela lub bazy.
- Debuguj: głównie ręcznie — obserwuj przeglądarkę, wypisuj HTML, rób screenshoty.
Widzisz różnicę? Playwright jest po prostu bardziej „plug and play” dla nowoczesnych stron.
Poza kodowaniem: no-code web scraping z Thunderbit AI Web Scraper
Bądźmy szczerzy: nie każdy ma ochotę zostać ninja od Pythona tylko po to, żeby dostać tabelę cen produktów albo listę leadów. Może pracujesz w sprzedaży, marketingu, nieruchomościach czy operacjach i po prostu potrzebujesz danych — na już. I właśnie tutaj wchodzi .
Jako współzałożyciel Thunderbit widzę to codziennie: mnóstwo osób w biznesie chce ominąć kodowanie i przejść prosto do efektu. Dlatego zbudowaliśmy , które pozwala scrapować dowolną stronę w dwa kliknięcia — bez Pythona, bez driverów, bez debugowania.
Jak działa Thunderbit
- Wejdź na stronę, z której chcesz pobrać dane.
- Kliknij „AI Suggest Fields”. AI Thunderbit skanuje stronę i proponuje pola danych (np. nazwa produktu, cena, obraz, ocena).
- Kliknij „Scrape”. Od razu dostajesz uporządkowaną tabelę danych.
- Wyeksportuj do Excel, Google Sheets, Airtable, Notion, CSV lub JSON. Gotowe.
Bez dłubania w selektorach, bez metody prób i błędów, bez kodu. Prościej się nie da — jak zamówienie jedzenia na wynos (a szczerze mówiąc, zwykle szybciej niż czekanie na dostawę).
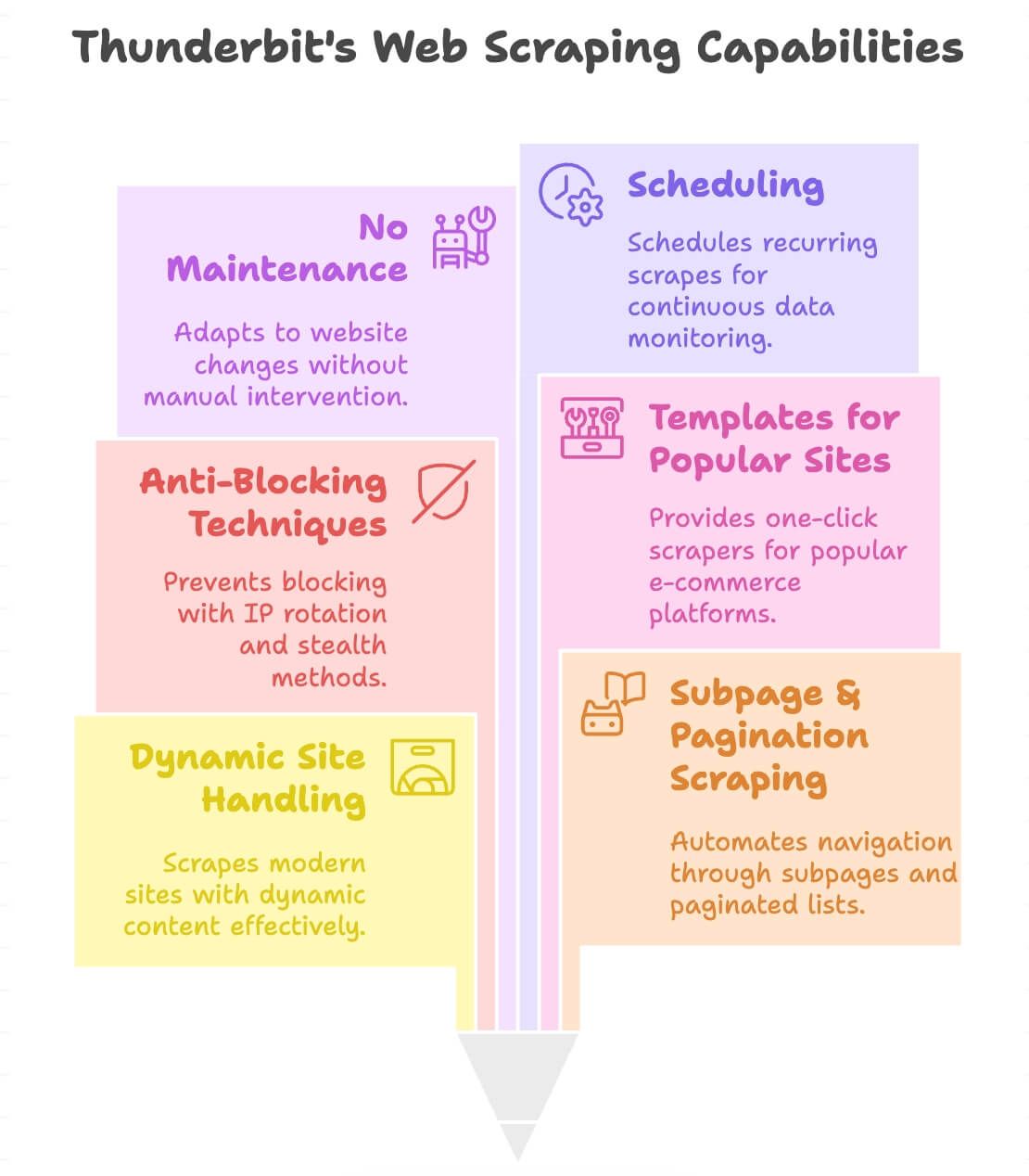
Co wyróżnia Thunderbit?
- Radzi sobie z dynamicznymi stronami: scrapuje nowoczesny e-commerce, katalogi i strony z nieskończonym scrollem czy pop-upami.
- Scraping podstron i paginacji: automatycznie przechodzi po kartach produktów lub listach stronicowanych, aby zebrać komplet danych.
- Wbudowane mechanizmy anty-blokad: rotacja IP po stronie backendu i techniki stealth, dzięki czemu rzadziej trafisz na blokadę.
- Szablony dla popularnych serwisów: scrapery „jednym kliknięciem” dla Amazon, eBay, Shopify, Zillow i innych ().
- Bez utrzymania: gdy strona się zmieni, AI Thunderbit się dostosuje — nie musisz przepisywać scrapera.
- Harmonogram: ustaw cykliczne scrapowanie do stałego monitoringu (np. codzienne sprawdzanie cen).
- Obsługa 34 języków: zbieraj i tłumacz dane praktycznie z każdego miejsca.
A najlepsze? Nie musisz znać HTML, CSS ani Pythona. Jeśli umiesz korzystać z przeglądarki, ogarniesz Thunderbit bez stresu.
Które rozwiązanie do web scrapingu jest dla Ciebie?
Na koniec szybka ściąga decyzyjna:
| Twoja sytuacja | Najlepsze narzędzie |
|---|---|
| Scraping prostej, statycznej strony; nie przeszkadza Ci konfiguracja | Selenium |
| Scraping nowoczesnej, dynamicznej strony; zależy Ci na szybkim wyniku | Playwright |
| Potrzebujesz wsparcia dla starszych przeglądarek lub języków | Selenium |
| Chcesz łatwej instalacji, nowoczesnego debugowania i mniej kodu | Playwright |
| Nie jesteś developerem; chcesz dane od razu, bez kodu i konfiguracji | Thunderbit |
| Potrzebujesz scrapować wiele stron, podstron lub uruchamiać zadania cyklicznie | Thunderbit |
| Chcesz eksportować bezpośrednio do Excel, Sheets, Notion, Airtable | Thunderbit |
| Nie znosisz debugowania błędów Pythona | Thunderbit |
Jeśli jesteś developerem albo lubisz dłubać w kodzie, playwright i selenium to mocne opcje. Ale jeśli Twoim celem jest jak najszybciej wrzucić dane do arkusza, Thunderbit oszczędzi Ci godziny — a czasem nawet dni — roboty.
Podsumowanie: szybki i niezawodny web scraping — na Twoich zasadach
Web scraping stał się mainstreamem — i trudno się dziwić: firmy potrzebują danych, żeby konkurować, i potrzebują ich teraz. Playwright i Selenium przeszły drogę od skromnych narzędzi testowych do kluczowych frameworków scrapingowych, każdy z własnymi atutami. Selenium to sprawdzony wybór dla stron statycznych i starszych środowisk; Playwright to nowoczesna, szybka opcja dla dynamicznych, interaktywnych serwisów.
Moja szczera rada po latach w SaaS, automatyzacji i AI: jeśli nie robisz tego dla samego kodowania, nie trać czasu na walkę z driverami, selektorami i sztuczkami anty-bot. Z przejdziesz od „potrzebuję tych danych” do „oto mój plik Excel” w kilka minut — nie w kilka dni.
Niezależnie od tego, czy jesteś pro w Pythonie, czy osobą z biznesu, która chce po prostu efektu, istnieje rozwiązanie dopasowane do Twoich potrzeb — i Twojej cierpliwości. Przetestuj, zobacz co pasuje do Twojego workflow i pamiętaj: najlepszy scraper to ten, który dostarcza potrzebne dane przy możliwie najmniejszym wysiłku.
A jeśli kiedykolwiek złapiesz się na debugowaniu błędu drivera w Selenium o 2 w nocy — pamiętaj, że Thunderbit nadal będzie tu czekał, gotowy do scrapowania w dwa kliknięcia.
Chcesz dowiedzieć się więcej o scrapingu no-code, ekstrakcji danych wspieranej przez AI i o tym, jak Thunderbit może pomóc Twojemu zespołowi? Zajrzyj na nasz albo od razu zacznij z .
P.S. Jeśli nadal nie wiesz, które narzędzie wybrać, albo chcesz zobaczyć Thunderbit w akcji, wpadnij na nasz po dema, tipy i okazjonalny żart o web scrapingu. (Tak, mamy takie.)
Dalsza lektura: