Tempo cyfrowych wiadomości potrafi dziś naprawdę zakręcić w głowie. Co minutę wpadają tysiące nagłówków, a kolejne są aktualizowane albo po cichu poprawiane — w mediach głównego nurtu, na niszowych blogach i w socialach. Dla skali: przerabia ponad 4 miliony artykułów dziennie, a śledzi newsy w ponad 100 językach i odświeża globalny strumień co 15 minut. Dla ludzi z mediów, badań czy business intelligence ręczne ogarnianie tego potoku to jak wybieranie wody z tonącego statku kubkiem po kawie.
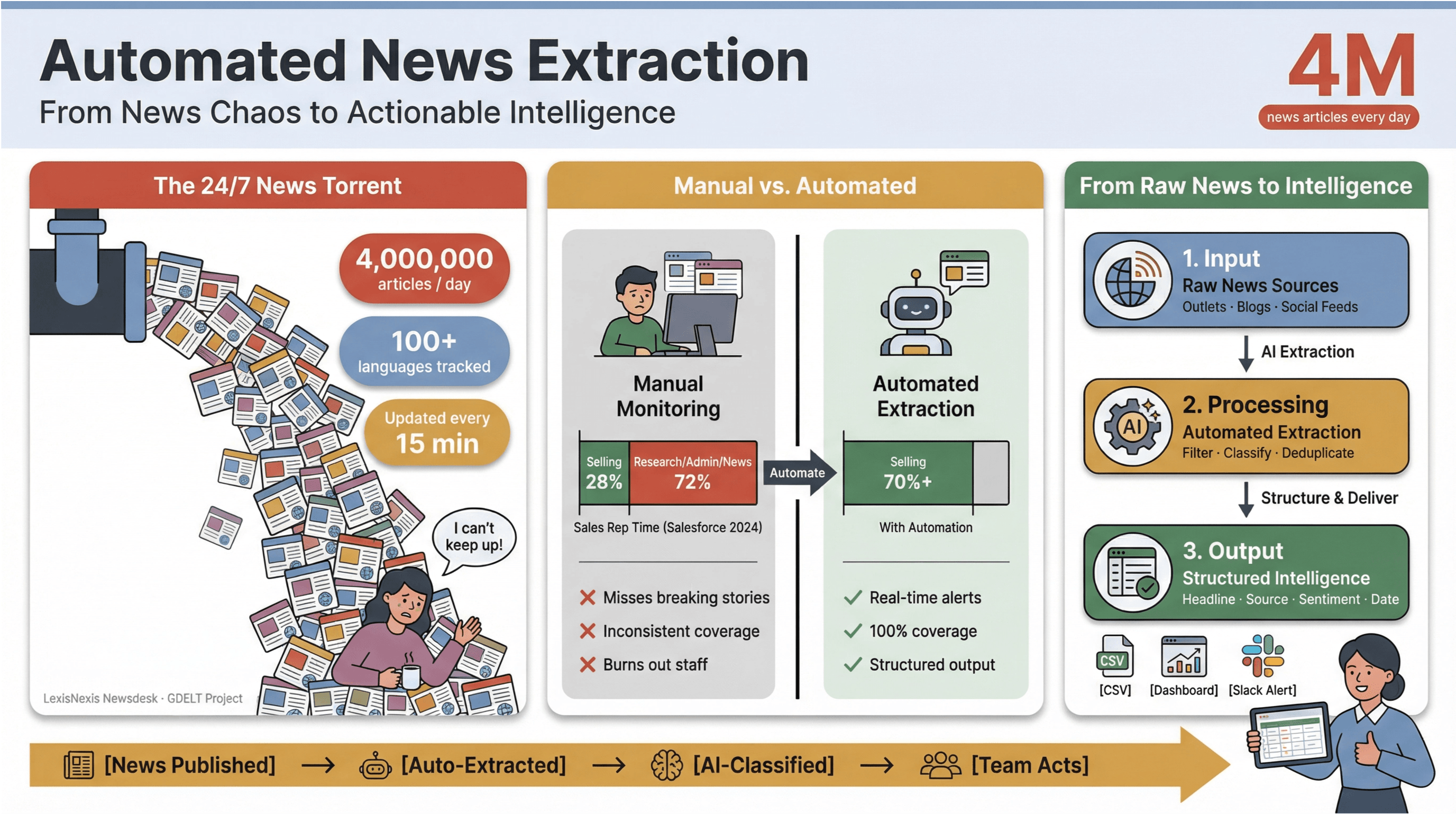
Widziałem na własne oczy, jak ręczne monitorowanie newsów zjada czas i zasoby. Zespoły sprzedażowe spędzają mniej niż jedną trzecią tygodnia na realnej sprzedaży — — a reszta ucieka na research, administrację i, tak, niekończące się przełączanie kart z wiadomościami. Dlatego automatyczne pozyskiwanie newsów stało się cichą supermocą nowoczesnych zespołów: to jedyny sposób, by zamienić chaos cyklu 24/7 w uporządkowaną, użyteczną wiedzę — bez wypalania ludzi i bez przegapiania najważniejszych historii.
Zobaczmy więc, czym w praktyce jest automatyczne pozyskiwanie newsów, dlaczego to must-have dla każdego, kto potrzebuje danych w czasie rzeczywistym, oraz jak zbudować solidny i zgodny z przepisami workflow z użyciem najlepszych narzędzi (w tym jak sprawia, że całość jest zaskakująco prosta — nawet dla nietechnicznych osób, takich jak moja mama).
Automatyczne pozyskiwanie newsów: dlaczego jest niezbędne w nowoczesnych redakcjach
Automatyczne pozyskiwanie newsów to dokładnie to, na co brzmi: użycie oprogramowania do automatycznego zbierania treści newsowych i zamiany ich w ustrukturyzowane, przeszukiwalne dane — czyli wiersze i kolumny zamiast chaotycznych stron WWW czy PDF-ów. W praktyce oznacza to, że możesz obserwować setki (a nawet tysiące) źródeł, wyciągać kluczowe pola, takie jak nagłówek, znacznik czasu, autor i treść, a potem zasilać tym dashboardy, alerty albo analitykę — bez dotykania Ctrl+C/Ctrl+V.
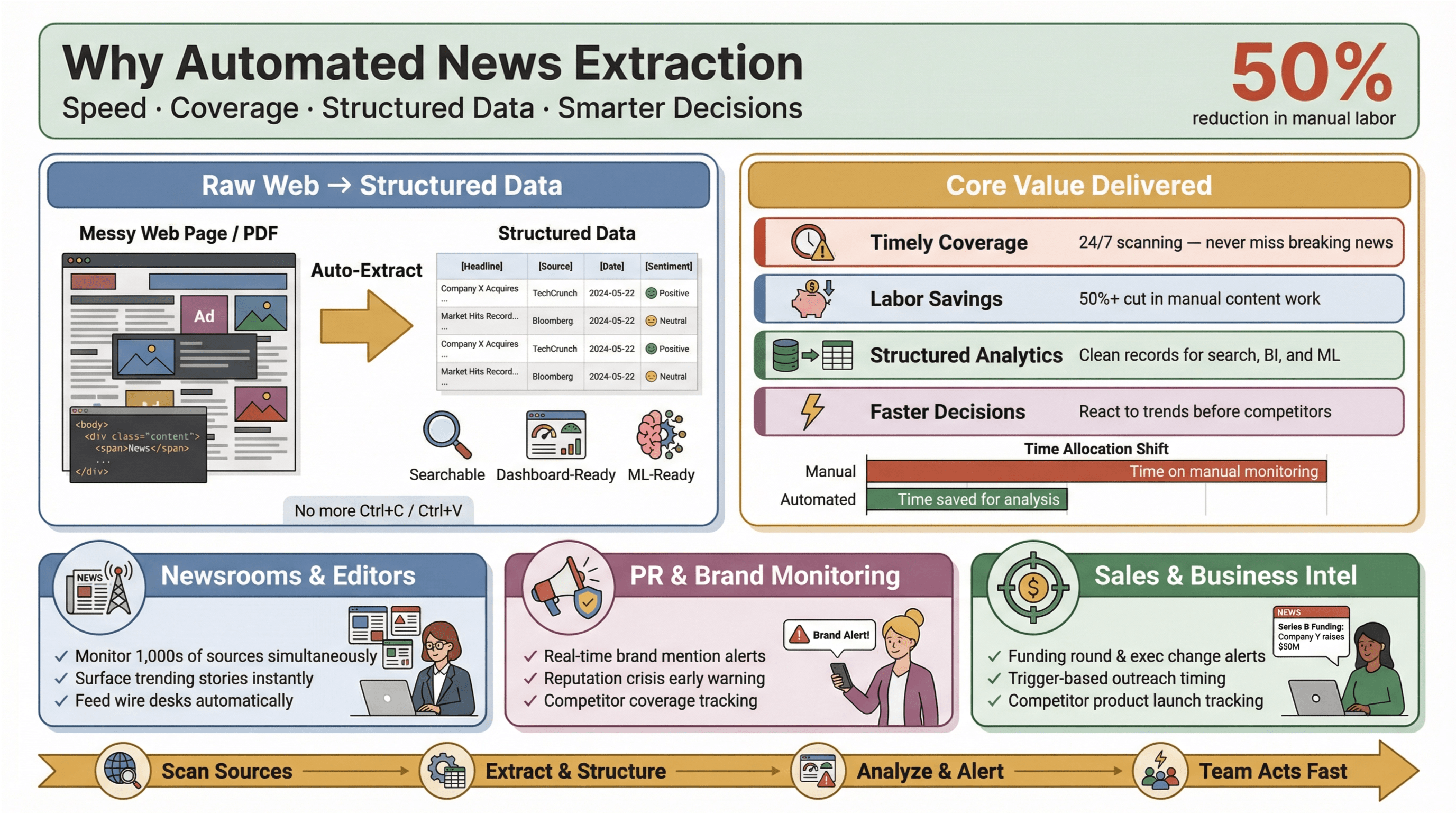
Dlaczego to ma znaczenie? Bo w dzisiejszym świecie informacji liczy się szybkość. Niezależnie od tego, czy jesteś redaktorem, PR-owcem śledzącym wzmianki o marce, czy analitykiem obserwującym ruchy konkurencji — bycie pierwszym często przesądza o tym, czy wykorzystasz okazję, czy będziesz tylko gonić innych. Narzędzia do automatycznego pozyskiwania pozwalają nawet małym zespołom działać „ponad wagę” — zbierać newsy w czasie rzeczywistym z całej sieci, ograniczać ręczną robotę i wyłapywać to, co naprawdę istotne.
A efekt da się policzyć: badania pokazują, że automatyzacja potrafi zmniejszyć ręczny nakład pracy przy aktualizacjach treści o co najmniej 50%, uwalniając czas na analizę i podejmowanie decyzji.
Kluczowa wartość automatycznego pozyskiwania newsów w branży informacyjnej
Przejdźmy do konkretów. Co realnie daje automatyczne pozyskiwanie newsów redakcjom i zespołom biznesowym?
- Szybkie i pełne pokrycie tematów: Koniec z przegapianiem pilnych informacji, bo ktoś nie zajrzał do feedu. Narzędzia skanują źródła 24/7, więc nic Ci nie umyka.
- Oszczędność pracy i kosztów: Małe i średnie zespoły mogą monitorować tyle źródeł co duzi gracze — bez zatrudniania armii stażystów.
- Ustrukturyzowane dane do analityki: Zamiast przekopywać się przez nieuporządkowane artykuły, dostajesz czyste rekordy gotowe do wyszukiwania, dashboardów i uczenia maszynowego.
- Szybsze i trafniejsze decyzje: Dane newsowe w czasie rzeczywistym pozwalają reagować na zmiany rynkowe, kryzysy PR czy trendy zanim zrobi to konkurencja.
W PR i komunikacji platformy takie jak i podkreślają, że monitoring mediów w czasie rzeczywistym jest kluczowy dla ochrony reputacji i szybkiej reakcji na szkodliwe publikacje. W sprzedaży alerty newsowe stają się „kartami kontekstu” do prospectingu — np. rundy finansowania, zmiany w zarządzie czy premiery produktów, które uruchamiają kontakt w idealnym momencie.
Wybór odpowiednich narzędzi do scrapingu newsów w różnych scenariuszach
Nie wszystkie narzędzia do scrapingu newsów są takie same. Właściwy wybór zależy od celu, komfortu technicznego i rodzaju informacji, które Cię interesują. Oto ramy, które pomogą dobrać najlepszą opcję:
Ocena łatwości użycia i dostępności
Dla większości użytkowników biznesowych i dziennikarzy łatwość obsługi jest kluczowa. Potrzebujesz narzędzia, które odpala się od razu — bez kodowania i żmudnej konfiguracji. Platformy no-code i low-code, takie jak , czy , pozwalają budować scrapery wizualnie — wskazujesz, klikasz i wyciągasz dane.
Thunderbit szczególnie wyróżnia się dwukrokowym procesem: opisujesz, czego potrzebujesz, AI podpowiada pola, a Ty klikasz „Scrape”. Nawet osoby nietechniczne potrafią uruchomić pipeline danych newsowych w kilka minut, a nie w kilka godzin.
Bezpieczeństwo i prywatność danych
Z dużą ilością danych przychodzi duża odpowiedzialność. Narzędzia do scrapingu newsów często mają dostęp do wrażliwych treści, więc bezpieczeństwo i zgodność powinny być na pierwszym miejscu. Zwróć uwagę na:
- Szyfrowanie danych (w transmisji i w spoczynku)
- Jasne zasady prywatności (Thunderbit deklaruje np., że nie sprzedaje danych użytkowników i ma dostęp tylko do treści, które wybierzesz do scrapowania)
- Szczegółowe uprawnienia (zwłaszcza w rozszerzeniach przeglądarki — zawsze sprawdzaj, do jakich danych narzędzie ma dostęp)
- Zgodność z lokalnymi przepisami (GDPR, CCPA oraz dla użytkowników w UE: )
Dla świętego spokoju wybieraj sprawdzonych dostawców, weryfikuj uprawnienia rozszerzeń i dawaj dostęp tylko tam, gdzie to naprawdę konieczne.
Dopasowanie narzędzi do typów newsów i potrzeb branżowych
Niektóre narzędzia są szczególnie mocne w konkretnych obszarach:
- Finanse: API takie jak i oferują klastrowanie, sentyment i wykrywanie zdarzeń w newsach finansowych.
- Tech i startupy: Scraping „na miarę” z Thunderbit lub Octoparse pozwala celować w niszowe blogi, komunikaty prasowe czy listy wydarzeń.
- Polityka i regulacje: Licencjonowane bazy, takie jak i , zapewniają dostęp do źródeł premium i archiwów.
Jeśli musisz monitorować miks źródeł mainstreamowych, niszowych i międzynarodowych — w tym takich bez API — elastyczne scrapery oparte o AI, jak Thunderbit, będą najlepszym wyborem.
Unikalne przewagi Thunderbit w pozyskiwaniu danych newsowych w czasie rzeczywistym
Pogadajmy o tym, co sprawia, że jest świetnym wyborem do automatycznego pozyskiwania newsów — zwłaszcza jeśli zależy Ci na danych w czasie rzeczywistym bez technicznych przepychanek.
Thunderbit to AI Web Scraper Chrome Extension stworzony dla użytkowników biznesowych, dziennikarzy i analityków, którzy potrzebują aktualnych, ustrukturyzowanych treści newsowych z dowolnej strony. Oto dlaczego to moje narzędzie „pierwszego wyboru”:
- AI Suggest Fields: Thunderbit analizuje stronę z newsami i automatycznie proponuje najlepsze kolumny do wyciągnięcia — nagłówek, czas publikacji, autor, podsumowanie i inne. Bez dłubania w selektorach czy szablonach.
- Subpage Scraping: Potrzebujesz pełnego artykułu, a nie tylko nagłówka? Thunderbit potrafi wejść w każdy link, pobrać treść, encje i tagi, a potem scalić wszystko w jedną, uporządkowaną tabelę.
- Eksport zbiorczy i szybkie aktualizacje: Jednym kliknięciem wyeksportujesz dane do Excel, Google Sheets, Airtable lub Notion. Koniec z maratonami kopiuj-wklej i walką z CSV.
- Scheduled Scraping: Ustaw cykliczne zadania (co godzinę, codziennie lub w niestandardowych odstępach), aby feed newsowy był zawsze świeży — idealne do breaking news, monitoringu rynku i badań.
- Elastyczność: AI Thunderbit lepiej znosi zmiany układu strony i „długi ogon” serwisów newsowych, więc mniej czasu tracisz na naprawianie scraperów, a więcej na analizę.
Z ponad i oceną 4,8 gwiazdki narzędzie jest zaufane na całym świecie — od monitoringu PR po wywiad konkurencyjny.
Wykrywanie pól przez AI i Subpage Scraping
Jedną z najmocniejszych funkcji Thunderbit jest wykrywanie pól oparte o AI. Wystarczy kliknąć „AI Suggest Fields”, a narzędzie przeskanuje stronę z newsami i rozpozna kluczowe elementy, takie jak tytuł, data, autor czy podsumowanie. Możesz też doprecyzować lub dodać własne pola (np. „oznacz artykuł jako ‘wyniki’ jeśli wspomina o rezultatach kwartalnych”), a AI ogarnie resztę.
Subpage Scraping to game-changer w pracy z newsami: scrapujesz stronę główną lub listę działu po nagłówkach, a potem Thunderbit odwiedza każdy URL artykułu, by pobrać pełną treść, encje, a nawet obrazy. Dzięki temu dostajesz kompletne, wzbogacone rekordy — gotowe do wyszukiwania, dashboardów lub dalszej analizy przez AI.
Eksport zbiorczy i natychmiastowe aktualizacje
Thunderbit maksymalnie upraszcza eksport danych newsowych. Jednym kliknięciem wyślesz ustrukturyzowany feed do Google Sheets, Airtable, Notion albo pobierzesz jako CSV/Excel. Dla zespołów pracujących w arkuszach i narzędziach BI to ogromna oszczędność czasu.
A ponieważ Thunderbit obsługuje Scheduled Scraping, możesz ustawić uruchamianie co godzinę, codziennie lub według własnego harmonogramu — tak, aby dane były zawsze aktualne. Koniec z czekaniem, aż Google Alerts zaindeksuje artykuły z kilkudniowym opóźnieniem.
Jak pokonać wyzwania operacyjne w rozwiązaniach newsowych w czasie rzeczywistym
Nawet najlepsze narzędzia nie zdejmują wszystkich problemów. Oto jak poradzić sobie z najczęstszymi wyzwaniami:
Zarządzanie opóźnieniami i świeżością danych
- Planuj scraping zgodnie z „prędkością” newsów: Dla breaking news ustaw uruchamianie co 15–30 minut (zgodnie z cyklem aktualizacji ). Dla spokojniejszych tematów wystarczy raz dziennie lub co godzinę.
- Mierz różnicę między publikacją a pobraniem: Monitoruj odstęp czasu między publikacją artykułu a momentem, gdy system go pobiera. Jeśli rośnie, sprawdź blokady lub spowolnienia.
- Ponawiaj scraping pod kątem „cichych edycji”: Artykuły często są poprawiane po publikacji. Zaplanuj drugi scraping po 24 godzinach, aby wyłapać korekty lub dyskretne zmiany ().
Limity API i zmienność źródeł
- Szanuj limity API: Jeśli korzystasz z API newsowych, pilnuj limitów zapytań — rozkładaj je w czasie i cache’uj wyniki, gdy to możliwe ().
- Deduplikacja i kanonikalizacja: Te same historie pojawiają się pod wieloma URL-ami lub są aktualizowane. Zapisuj canonical URL i używaj hashy (np. tytuł + data), aby unikać duplikatów ().
- Obsługa treści dynamicznych: Dla stron z nieskończonym przewijaniem lub lazy loading wybieraj narzędzia wspierające renderowanie dynamiczne i monitoruj zmiany układu ().
Inteligentna analiza danych newsowych: rola AI i uczenia maszynowego
Pozyskanie newsów to dopiero start. Prawdziwa wartość pojawia się, gdy analizujesz dane i przekładasz je na działania — i tu AI oraz uczenie maszynowe robią robotę.
- Ekstrakcja encji: NLP wyciąga osoby, organizacje i miejsca wspomniane w artykule ().
- Klasyfikacja tematyczna: Automatyczne tagowanie artykułów według tematu, sentymentu lub pilności — lepsze dashboardy i alerty ().
- Klastrowanie zdarzeń: Grupowanie duplikatów i powiązanych historii z różnych źródeł, aby widzieć szerszy obraz (a nie zalew podobnych nagłówków).
- Personalizacja i targetowanie: Dane newsowe w czasie rzeczywistym pomagają segmentować odbiorców, poprawiać targetowanie reklam lub rekomendacje treści — zwiększając zaangażowanie i ROI.
Przykładowo zespoły PR wykorzystują analitykę newsową, by wyłapać kryzysy zanim staną się viralem, a sprzedaż wzbogaca listy prospectów o „zdarzenia wyzwalające”, takie jak rundy finansowania czy zatrudnienia w zarządzie.
Checklista najlepszych praktyk automatycznego pozyskiwania newsów
Poniżej szybka checklista, która pomoże utrzymać pipeline w dobrej kondycji:
| Najlepsza praktyka | Dlaczego to ważne | Jak wdrożyć |
|---|---|---|
| Częste harmonogramy scrapingu | Mniejsze opóźnienia, szybkie wyłapywanie breaking news | Dopasuj częstotliwość do dynamiki tematu (np. co 15 min dla szybkich newsów) |
| Ekstrakcja wspierana przez AI | Odporność na zmiany układu, krótsze wdrożenie | Narzędzia takie jak Thunderbit, Diffbot, Zyte API |
| Deduplikacja i kanonikalizacja | Mniej powtórzeń w alertach, czystsze dane | Zapisuj canonical URL, używaj hashy do deduplikacji |
| Kontrola jakości ekstrakcji | Wykrywanie braków, dryfu i awarii | Monitoruj % kompletnych rekordów, opóźnienia i błędy |
| Respektowanie prawa i zgodności | Mniejsze ryzyko prawne, większe zaufanie | Preferuj oficjalne API/feed, sprawdzaj regulaminy, minimalizuj dane osobowe |
| Eksport do formatów ustrukturyzowanych | Ułatwia analitykę downstream | CSV, Excel, Sheets, Notion, Airtable |
| Ponowny scraping pod kątem edycji | Wyłapywanie zmian po publikacji | Odwiedzaj artykuły ponownie po 24h/1 tyg. (model GDELT) |
| Zabezpieczenie pipeline’u | Ochrona wrażliwych danych | Szyfrowanie, kontrola dostępu, sprawdzone narzędzia |
Jak zbudować solidny workflow automatycznego pozyskiwania newsów
Chcesz zbudować własną „czarną skrzynkę” do danych newsowych? Oto workflow krok po kroku:
- Zidentyfikuj źródła: Wypisz serwisy newsowe, blogi lub API, które chcesz monitorować.
- Skonfiguruj ekstrakcję: Użyj Thunderbit lub innego narzędzia, aby zdefiniować pola (AI Suggest Fields bardzo to ułatwia).
- Ustaw harmonogram: Dopasuj częstotliwość do dynamiki — co godzinę dla pilnych tematów, codziennie dla spokojniejszych.
- Wzbogacanie z podstron: Dla każdego nagłówka pobierz pełny artykuł: treść, encje i tagi.
- Deduplikacja i normalizacja: Zapisuj canonical URL, haszuj rekordy i ujednolicaj pola.
- Eksport i integracje: Wyślij dane do Excel, Google Sheets, Airtable lub Notion do analizy.
- Monitoring i adaptacja: Kontroluj jakość ekstrakcji, obserwuj zmiany układu stron i koryguj ustawienia.
- Zgodność: Sprawdzaj regulaminy, respektuj robots.txt i minimalizuj dane osobowe.
Wizualnie wygląda to tak:
Źródła → Ekstrakcja (pola AI) → Wzbogacanie z podstron → Deduplikacja → Eksport → Analiza/Alerty → Monitoring
Podsumowanie i najważniejsze wnioski
Automatyczne pozyskiwanie newsów przestało być „miłym dodatkiem” — to konieczność dla każdego, kto chce wyprzedzać innych w świecie, gdzie informacje pojawiają się (i zmieniają) z minuty na minutę. Stosując najlepsze praktyki i odpowiednie narzędzia, możesz zamienić hydrant cyfrowych newsów w stabilny strumień uporządkowanej, użytecznej wiedzy.
Najważniejsze wnioski:
- Skala i tempo newsów online wymuszają automatyzację — ręczny monitoring nie ma szans nadążyć.
- Narzędzia do automatycznego pozyskiwania oszczędzają czas, obniżają koszty i pozwalają małym zespołom dorównać zasięgiem dużo większym organizacjom.
- Wybór narzędzia to balans między prostotą, bezpieczeństwem i elastycznością — Thunderbit wyróżnia się prostotą opartą o AI i eksportem w czasie rzeczywistym.
- Buduj workflow wokół świeżości danych, deduplikacji, zgodności i monitoringu jakości, aby mieć wiarygodne, użyteczne dane.
- AI i uczenie maszynowe zwiększają wartość danych — umożliwiają lepsze targetowanie, personalizację i szybsze decyzje.
Jeśli nadal kopiujesz nagłówki ręcznie albo czekasz, aż Google Alerts „dogoni” rzeczywistość, czas wejść poziom wyżej. i zobacz, jak proste może być automatyczne pozyskiwanie newsów. Po więcej wskazówek, workflowów i analiz zajrzyj na .
FAQ
1. Czym jest automatyczne pozyskiwanie newsów i jak działa?
Automatyczne pozyskiwanie newsów to proces, w którym oprogramowanie zbiera artykuły i zamienia je w ustrukturyzowane dane (np. tabele lub JSON) do analizy, wyszukiwania lub alertów. Narzędzia takie jak Thunderbit wykorzystują AI do rozpoznawania kluczowych pól (nagłówek, czas, autor, treść) i automatycznego wyciągania ich ze stron WWW lub API.
2. Dlaczego dane newsowe w czasie rzeczywistym są tak ważne dla firm?
Dane w czasie rzeczywistym pozwalają szybko reagować na wydarzenia rynkowe, kryzysy PR czy ruchy konkurencji. Niezależnie od tego, czy działasz w sprzedaży, PR czy badaniach, aktualne informacje pomagają podejmować lepsze i szybsze decyzje oraz wyprzedzać rynek.
3. Jak Thunderbit ułatwia scraping newsów osobom nietechnicznym?
Thunderbit działa w prostym, dwukrokowym modelu: opisujesz, jakich danych potrzebujesz, a AI proponuje pola. Dzięki funkcjom takim jak Subpage Scraping i natychmiastowy eksport do Excel lub Google Sheets nawet osoby nietechniczne mogą zbudować solidny pipeline danych w kilka minut.
4. Jakie są kwestie prawne i zgodności przy scrapingu newsów?
Zawsze sprawdzaj regulaminy serwisów, a gdy to możliwe, korzystaj z oficjalnych API lub feedów. Respektuj robots.txt. Nie scrapuj treści wymagających logowania lub paywalla bez zgody i ograniczaj zbieranie danych osobowych, aby spełniać wymogi przepisów o prywatności.
5. Jak zapewnić niezawodność workflow pozyskiwania newsów w dłuższym czasie?
Ustaw regularny scraping, monitoruj jakość ekstrakcji i wybieraj narzędzia odporne na zmiany układu stron (np. ekstrakcja oparta o AI w Thunderbit). Deduplikuj rekordy, mierz opóźnienie między publikacją a pobraniem i ustaw alerty na wypadek błędów lub brakujących pól, aby pipeline był zdrowy i aktualny.
Dowiedz się więcej