
Badanie oparte na crawl’u pokazuje, jak witryny o dużym ruchu publikują czytelne maszynowo wskazówki dla dużych modeli językowych, jak wyglądają wczesne wdrożenia i dlaczego pomiar adopcji wymaga czegoś więcej niż liczenia odpowiedzi HTTP 200.
- Zbiór danych:
data/llms_probe_results_top_10000.csv - Lista Tranco pobrana: 6 maja 2026
- Zakres:
/llms.txti/llms-full.txtw katalogu głównym
Kluczowe wskaźniki
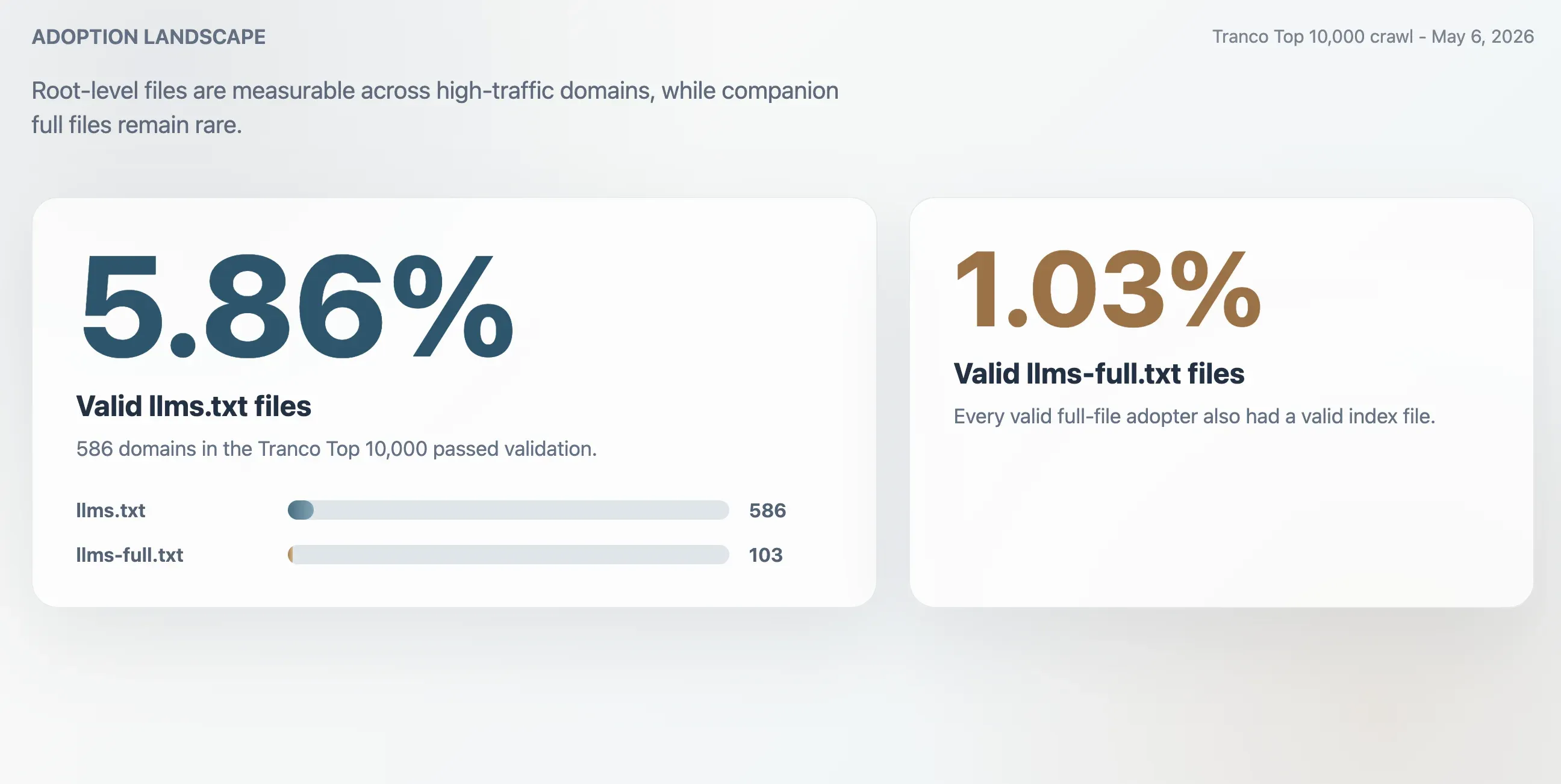
- 5,86%: poprawna adopcja
llms.txtw Tranco Top 10 000, czyli 586 domen. - 1,03%: poprawna adopcja
llms-full.txt, czyli 103 domeny. Każda domena z poprawnym plikiem pełnym miała też poprawny plik indeksowy. - 63,51%: udział odpowiedzi HTTP 200 dla
/llms.txt, które nie przeszły walidacji. - 2,74x: przybliżone zawyżenie, gdyby adopcję mierzyć wyłącznie surowymi odpowiedziami HTTP 200.
Podsumowanie wykonawcze
llms.txt nadal jest na wczesnym etapie jako standard webowy, ale przestał być marginalnym eksperymentem. W crawl’u z 6 maja 2026 obejmującym 10 000 domen z Tranco badanie znalazło 586 poprawnych plików llms.txt, co daje obserwowany poziom adopcji 5,86%. Towarzyszący plik llms-full.txt był znacznie rzadszy: poprawny pełny plik miało 103 domeny, czyli 1,03% próby.
Najważniejszy wniosek metodologiczny jest taki, że kody statusu są słabym przybliżeniem adopcji. Crawler wykrył 1606 odpowiedzi HTTP 200 dla /llms.txt, ale tylko 586 przeszło walidację. Pozostałe 1020 to głównie przekierowania na niecelowe strony, ogólne strony HTML, puste treści lub inne nieprawidłowe odpowiedzi. Naiwny crawler, który liczyłby każdą odpowiedź 200 jako adopcję, zawyżyłby rzeczywisty wynik około 2,74 razy.
Wśród poprawnych wdrożeń jakość implementacji jest wyższa, niż sugerowałaby narracja o samych „placeholderach”. Mediana poprawnego pliku wynosiła około 7,1 KB, 61,77% poprawnych plików miało ponad 5 KB, 70,82% zawierało sześć lub więcej sekcji Markdown, a 77,47% miało 11 lub więcej linków Markdown. Wśród pierwszych wdrażających są Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog i Cloudinary.
llms.txtnajlepiej rozumieć jako sygnał wyjaśniający i nawigacyjny dla systemów AI, a nie jako zamiennikrobots.txt. Liczy się nie tylko to, że plik istnieje, ale czy pomaga maszynom znaleźć autorytatywne, zwięzłe i aktualne informacje.
Kontekst: sieć dodaje sygnały dla AI
Witryny od dawna używają robots.txt, aby wyrażać preferencje dla crawlerów, sitemap.xml, by ułatwiać wykrywanie adresów URL, oraz danych strukturalnych, aby pomagać wyszukiwarkom i systemom platformowym interpretować strony. Generatywna AI wprowadza inny problem. Treści mogą być używane do treningu, wyszukiwania, podsumowywania, przeglądania agentowego, wsparcia programistycznego, obsługi klienta i generowania odpowiedzi. To tworzy dwie równoczesne potrzeby: wydawcy chcą większej kontroli nad automatycznym wykorzystaniem treści, ale jednocześnie chcą, by systemy AI potrafiły znaleźć właściwe, kanoniczne informacje, kiedy już wejdą w interakcję z ich witryną.
Oryginalna propozycja llms.txt, przedstawiona przez Jeremy’ego Howarda w 2024 roku, opisuje plik jako dokument Markdown umieszczony w katalogu głównym witryny, który ma dostarczać informacji przyjaznych LLM-om w czasie inferencji. Propozycja podkreśla, że strony HTML często zawierają nawigację, reklamy, skrypty i inne szumy, które utrudniają modelom językowym ich przetwarzanie. Zwięzły plik Markdown może wskazywać modelom najważniejsze strony, dokumentację, API, przykłady, zasady i informacje o produkcie.
Zewnętrzne badania webowe stanowią szersze tło. „Consent in Crisis” inicjatywy Data Provenance Initiative opisuje gwałtowny wzrost ograniczeń związanych z AI w robots.txt i warunkach korzystania z usług oraz argumentuje, że istniejące mechanizmy zgody w sieci nie były projektowane z myślą o wielkoskalowym ponownym wykorzystaniu danych przez AI. Cloudflare Radar AI Insights również pokazuje wzorce robotów AI i robots.txt na poziomie Top 10 000 domen. W tym otoczeniu llms.txt znajduje się po konstruktywnej stronie sygnalizacji dla AI: nie „nie crawluj tego”, lecz „jeśli chcesz zrozumieć tę witrynę, zacznij tutaj”.
Dowody zewnętrzne i spór o adopcję
Publiczna dyskusja wokół llms.txt rozdziela się na dwa stanowiska. Optymistyczne mówi, że plik daje systemom AI czystszą i bardziej efektywną drogę do autorytatywnych treści. Sceptyczne wskazuje, że żaden duży dostawca LLM publicznie nie zobowiązał się do używania go jako sygnału rankingowego, indeksującego lub cytującego, więc wydawcy nie powinni oczekiwać wzrostu ruchu wyłącznie dzięki samemu plikowi. Trzy zewnętrzne źródła przeanalizowane w tej aktualizacji prowadzą do bardziej zniuansowanego wniosku: llms.txt to użyteczna infrastruktura, ale dowody na bezpośredni wpływ na ruch są nadal ograniczone i zależne od kontekstu.
Zewnętrzne benchmarki adopcji szybko się zmieniają
Tracker adopcji Rankability podał wskaźnik adopcji 0,3% dla 1000 najpopularniejszych witryn na dzień 22 czerwca 2025, czyli 3 z 1000 stron. Opisuje miesięczne automatyczne skanowanie domain.com/llms.txt z walidacją, która wyklucza przekierowania i odpowiedzi HTML. Ta metodologia jest kierunkowo podobna do konserwatywnego podejścia walidacyjnego zastosowanego w tym badaniu.
Różnica w wynikach jest duża: to badanie znalazło 75 poprawnych plików llms.txt w Tranco Top 1000 na dzień 6 maja 2026, czyli 7,50%. Tych dwóch liczb nie należy traktować jako ścisłego szeregu czasowego, ponieważ źródło rankingu, szczegóły implementacyjne, logika walidacji i moment crawl’u mogą się różnić. Mimo to kontrast sugeruje, że adopcja zmieniła się istotnie między połową 2025 roku a majem 2026, zwłaszcza wśród stron dla programistów, SaaS, chmury, bezpieczeństwa i dokumentacji.
| Źródło | Migawka | Próba | Zgłoszona poprawna adopcja | Interpretacja |
|---|---|---|---|---|
| Rankability | 22 czerwca 2025 | 1000 najpopularniejszych witryn | 0,3% | Wczesny publiczny benchmark pokazujący minimalną adopcję w połowie 2025 r. |
| To badanie | 6 maja 2026 | Tranco Top 1000 | 7,50% | Późniejszy crawl pokazujący widoczną adopcję w witrynach o dużym ruchu. |
| To badanie | 6 maja 2026 | Tranco Top 10 000 | 5,86% | Szersza próba pokazująca, że adopcję można mierzyć, ale nie jest jeszcze mainstreamem. |
Eksperymenty ruchu pozostają niejednoznaczne
Search Engine Land opublikował w styczniu 2026 analizę 10 witryn, śledząc je przez 90 dni przed wdrożeniem i 90 dni po nim. Artykuł podał, że dwie witryny odnotowały wzrost ruchu z AI o 12,5% i 25%, osiem nie wykazało mierzalnej poprawy, a jedna spadła o 19,7%. Kluczowa interpretacja była ostrożna przyczynowo: te dwa pozorne sukcesy jednocześnie wdrożyły nowe szablony, przebudowały centra zasobów, dodały wyciągalne tabele porównawcze, zdobyły publikacje prasowe, naprawiły problemy techniczne albo opublikowały nową treść w stylu FAQ. W tym ujęciu llms.txt dokumentował silniejszą pracę nad treścią i techniką; nie wydawał się samodzielnie powodować wzrostu.
Osobisty eksperyment blogowy Renata Alimbekova doszedł do bardziej pozytywnego wniosku na podstawie mniejszej obserwacji na poziomie witryny. Porównał dwa czteromiesięczne okresy w Yandex.Metrica po dodaniu zarówno llms.txt, jak i llms-full.txt. Sesje z poleceń LLM wzrosły z 75 do 92, czyli o 23%, a liczba użytkowników z 51 do 64. Sesje z Perplexity wzrosły z 29 do 55, podczas gdy sesje z ChatGPT spadły z 31 do 26. Ten sam wpis zauważa też, że cały ruch odsyłający wzrósł szybciej — z 160 do 290 sesji — więc udział sesji LLM spadł z 47% do 32%.
| Typ dowodu | Zaobserwowany wynik | Główne zastrzeżenie | Wpływ na ten raport |
|---|---|---|---|
| 10-witrynowe badanie before/after Search Engine Land | Dwie witryny wzrosły, osiem bez mierzalnej zmiany, jedna spadła. | Pozytywne przypadki miały równolegle zmiany treści, PR i techniczne. | Wspiera traktowanie llms.txt jako infrastruktury, a nie samodzielnej dźwigni wzrostu. |
| Obserwacja before/after na osobistym blogu Alimbekova | Sesje z poleceń LLM wzrosły o 23% w okresie po wdrożeniu. | Brak grupy kontrolnej; całkowity ruch odsyłający wzrósł o 81%, a udział LLM spadł. | Sugeruje możliwy potencjał dla blogów technicznych, zwłaszcza przez Perplexity, ale bez izolacji przyczynowości. |
| To badanie adopcji oparte na crawl’u | 586 poprawnych plików i wiele ustrukturyzowanych wdrożeń. | Mierzy obecność i strukturę, nie późniejszy wpływ na ruch. | Pokazuje adopcję i dojrzałość implementacji, ale nie ROI samo w sobie. |
Co wyjaśnia spór
Zewnętrzne dowody doprecyzowują interpretację tego zbioru danych. Dobrze ustrukturyzowany plik llms.txt może zmniejszyć tarcie w parsowaniu maszynowym, szczególnie w dokumentacji dla programistów, odniesieniach do API i treściach baz wiedzy. Jednak najsilniejsze przypadki ruchu nadal wydają się zależeć od treści, które są użyteczne, możliwe do wyciągnięcia, autorytatywne i możliwe do odkrycia poza samym plikiem. Z tego powodu praktyczne pytanie nie brzmi w izolacji: „czy llms.txt ma znaczenie?”. Chodzi o to, czy plik jest częścią szerszego systemu treści czytelnego dla AI.
Zaktualizowana interpretacja:
llms.txtnależy wdrażać jako niskokosztową infrastrukturę dla AI. Nie powinien być pozycjonowany jako zamiennik lepszej dokumentacji, treści strukturalnych, dostępności technicznej, cytowań, linków czy autorytetu marki.
Wypróbuj Thunderbit do AI web scrapingu
Metodologia
Badanie oparło próbę na domenach z Tranco Top 10 000. Tranco to ranking topowych witryn nastawiony na badania, zaprojektowany tak, by był stabilniejszy i bardziej odporny na manipulacje niż wiele tradycyjnych list topowych. Plik źródłowy Tranco pobrano 6 maja 2026, a źródłowy znacznik Last-Modified miał datę 5 maja 2026, 22:17:59 GMT.
Crawler sprawdzał dwie ścieżki w katalogu głównym dla każdej domeny:
https://example.com/llms.txt, z fallbackiem HTTP, gdy było to potrzebne.https://example.com/llms-full.txt, z fallbackiem HTTP, gdy było to potrzebne.
Dla każdego zapytania crawler zapisywał kod statusu, końcowy URL, metodę pobrania, liczbę bajtów odpowiedzi, typ zawartości, komunikat o błędzie, czas wykonania i wynik walidacji. Pomyślnie pobrane treści zapisano w raw_llms_txt/ do przeglądu i analizy wtórnej.
Reguły walidacji
Odpowiedź liczono jako poprawny plik tylko wtedy, gdy zwracała poprawną treść i nie wyglądała jak ogólny webowy fallback. Końcowa ścieżka URL musiała pozostać /llms.txt lub /llms-full.txt. Puste treści odrzucano. Oczywiste dokumenty HTML i powłoki aplikacji odrzucano. Typ zawartości traktowano jako dowód wspierający, a nie jedyne kryterium, ponieważ niewielka liczba poprawnych plików tekstowych była serwowana z nietypowymi typami zawartości.
Krajobraz adopcji
Crawl znalazł 586 poprawnych plików llms.txt w Tranco Top 10 000. Daje to wskaźnik poprawnej adopcji na poziomie 5,86%. Mniejszy plik towarzyszący llms-full.txt był obecny i poprawny na 103 domenach, czyli w 1,03% próby.
| Metryka | Liczba | Udział w Top 10 000 |
|---|---|---|
| Przeskanowane domeny | 10 000 | 100,00% |
| Poprawne pliki llms.txt | 586 | 5,86% |
| Poprawne pliki llms-full.txt | 103 | 1,03% |
| Odpowiedzi HTTP 200 dla /llms.txt | 1 606 | 16,06% |
| Odpowiedzi HTTP 200 odrzucone jako niepoprawne | 1 020 | 10,20% |
Adopcja nie jest tylko domeną największych graczy
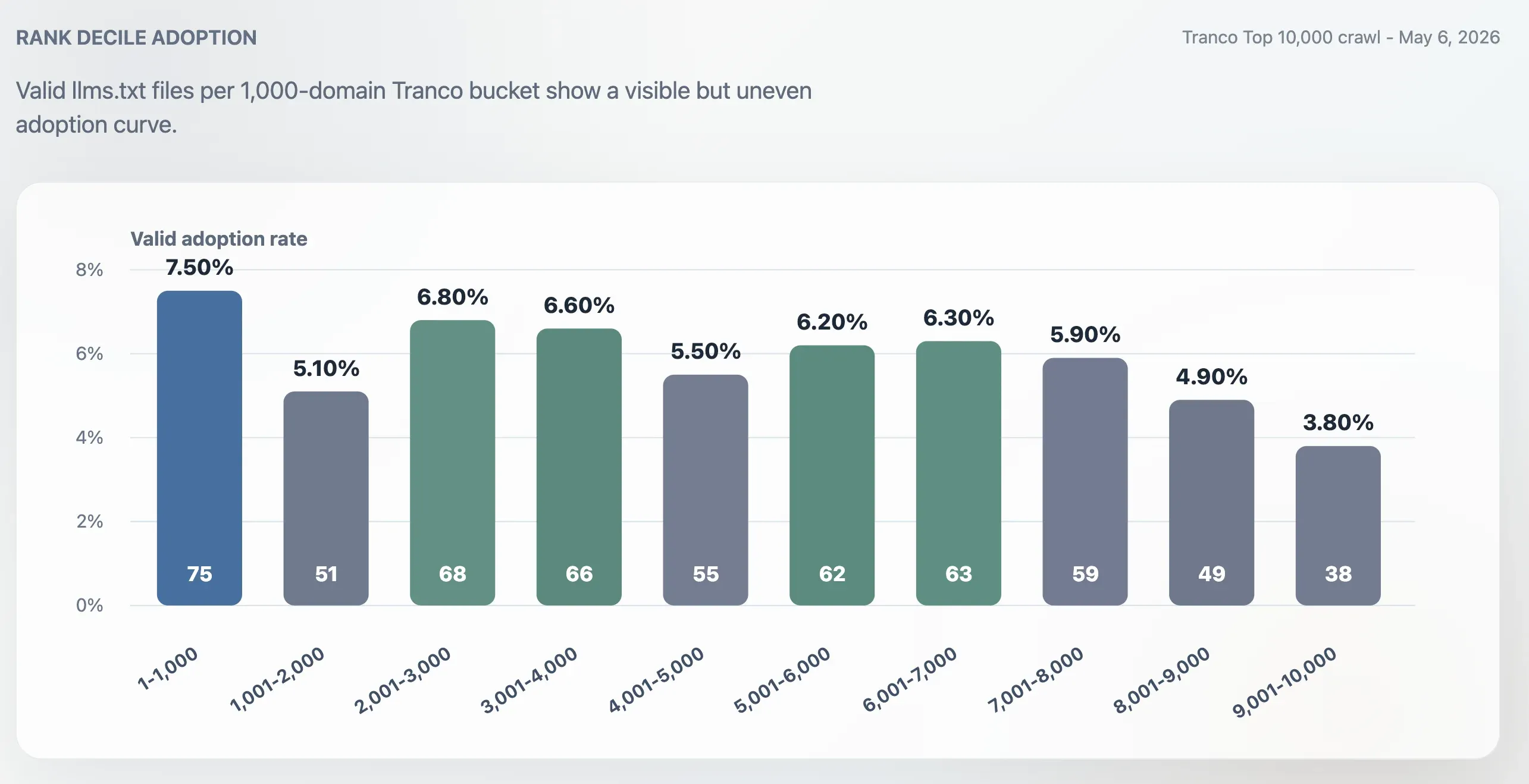
Adopcja była wyższa w Top 1000 niż w całym Top 10 000, ale nie ograniczała się do największych witryn. Wskaźnik adopcji w Top 1000 wyniósł 7,50%. Ostatni przedział 1000 domen, pozycje 9001–10 000, spadł do 3,80%. Środek rankingu pozostawał aktywny: przedziały 2001–3000, 3001–4000, 5001–6000 i 6001–7000 utrzymywały się w okolicach 6%.
Wczesni wdrażający
Najwyżej sklasyfikowaną poprawną domeną był Cloudflare na pozycji Tranco 4. Inni wysoko notowani wdrażający to Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink i OneSignal.
Ci wdrażający nie są przypadkowi. Zwykle mają rozbudowaną dokumentację, linie produktów wymagające objaśnień, API lub ekosystemy deweloperskie, treści wsparcia, strony cenowe, materiały o bezpieczeństwie i prywatności oraz wystarczający autorytet marki, by zależało im na tym, jak systemy AI interpretują ich witryny.
| Pozycja | Domena | Rozmiar pliku | Zaobserwowany wzorzec |
|---|---|---|---|
| 4 | cloudflare.com | 4 225 B | Zwięzły indeks produktu, deweloperski, firmowy i cenowy. |
| 26 | azure.com | 47 037 B | Narzędzia dla deweloperów, AI, obliczenia, magazynowanie, bezpieczeństwo, monitoring i zasoby opcjonalne. |
| 28 | github.com | 27 108 B | Dostęp programowy, Copilot, MCP, REST API, Actions, repozytoria i linki do CLI. |
| 248 | stripe.com | 64 229 B | Płatności, Connect, Checkout, Billing, Tax, Atlas, Radar i dokumentacja dla deweloperów. |
| 265 | salesforce.com | 1,02 MB | Ogromny katalog linków do produktów i Agentforce bez nagłówków sekcji Markdown. |
Kategorie wdrażających z Top 1000
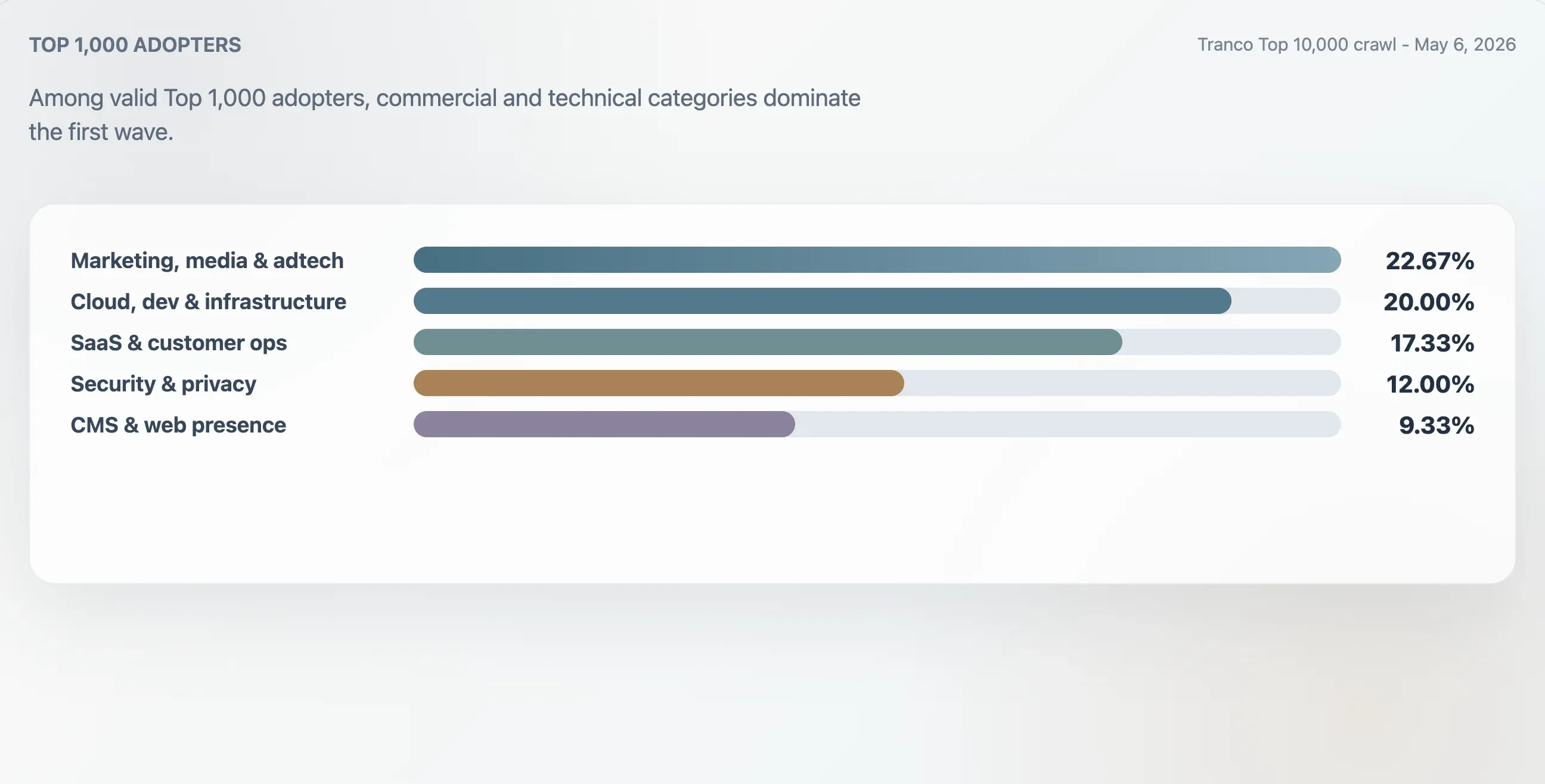
To badanie sklasyfikowało 75 poprawnych wdrażających w Tranco Top 1000, korzystając z kontekstu domeny, pierwszych nagłówków, surowej struktury pliku i słów kluczowych treści. Największą grupą były marketing, media i adtech — 22,67%. Strony cloud, deweloperskie i infrastrukturalne stanowiły 20,00%. SaaS, produktywność i operacje klientów — 17,33%. Bezpieczeństwo, tożsamość i prywatność — 12,00%.
| Kategoria | Domeny | Udział wśród wdrażających z Top 1000 | Mediana wyniku jakości | Mediana linków |
|---|---|---|---|---|
| Marketing, media i adtech | 17 | 22,67% | 94 | 25 |
| Cloud, dev i infrastruktura | 15 | 20,00% | 94 | 62 |
| SaaS, produktywność i operacje klienta | 13 | 17,33% | 94 | 46 |
| Bezpieczeństwo, tożsamość i prywatność | 9 | 12,00% | 98 | 78 |
| CMS, hosting i obecność webowa | 7 | 9,33% | 100 | 24 |
Wzorce TLD
Domeny najwyższego poziomu nie są etykietami branżowymi, ale stanowią przydatne sygnały kierunkowe. Wśród TLD, które miały w próbie co najmniej 50 domen, .io miało najwyższy wskaźnik poprawnej adopcji — 14,44%. Następne było .com z wynikiem 8,19%. Niższa adopcja w .gov, .edu i .net sugeruje, że wczesna baza wdrażających jest bardziej komercyjna i techniczna niż instytucjonalna.
Jakość wdrożeń
Poprawna adopcja nie oznacza jednolitej jakości implementacji. Niektóre pliki to zwięzłe, dobrze podzielone indeksy. Niektóre są głównie prozą. Niektóre to surowe katalogi linków. Niektóre to prawie puste placeholdery. Inne to wielomegabajtowe zrzuty treści, które mogą być kompletne, ale drogie w pobieraniu i parsowaniu.
Wśród poprawnych plików llms.txt 362 miały więcej niż 5 KB, czyli 61,77% poprawnych wdrażających. Mediana rozmiaru pliku wynosiła około 7,1 KB. P90 rozmiaru pliku wynosił 156 KB, P95 356 KB, P99 2,54 MB, a największy zaobserwowany plik miał 7,97 MB.
Typowe sygnały treści
Skan słów kluczowych w poprawnych plikach wykazał, że wiele witryn nie tylko publikuje deklarację, ale kieruje modele do materiałów rzeczywiście użytecznych operacyjnie. Terminy wsparcia lub pomocy pojawiały się w 70,31% poprawnych plików. Terminy blog, przewodnik lub tutorial — w 67,92%. Bezpieczeństwo, prywatność, zgodność lub regulaminy — w 61,43%. Cennik pojawiał się w 53,92%, dokumentacja w 52,22%, API w 33,96%, a sygnały changelog lub release w 27,30%.
Punktacja jakości i archetypy
Aby przejść od samej obecności do dojrzałości, badanie stworzyło lekki wynik implementacyjny. Wynik uwzględnia typ treści, rozmiar pliku, strukturę Markdown, liczbę linków, zakres tematów oraz sygnały ostrzegawcze, takie jak brak nagłówków, brak linków Markdown, nietypowy typ zawartości, zbyt małe pliki, bardzo duże pliki i zachowanie polegające na zrzucie linków. To nie jest formalny standard. To model oceny badawczej służący do porównywania zaobserwowanych implementacji.
Zgodnie z tym modelem 416 poprawnych plików sklasyfikowano jako silne, ustrukturyzowane indeksy, 107 jako użyteczne indeksy, 24 jako cienkie lub nieregularne, a 39 jako symboliczne lub mało użyteczne. Osobna analiza archetypów wykazała 296 ustrukturyzowanych indeksów, 113 plików tekstowych podzielonych na sekcje, 63 katalogi linków, 52 cienkie indeksy, 50 symbolicznych lub placeholderowych plików oraz 12 ogromnych zrzutów treści.
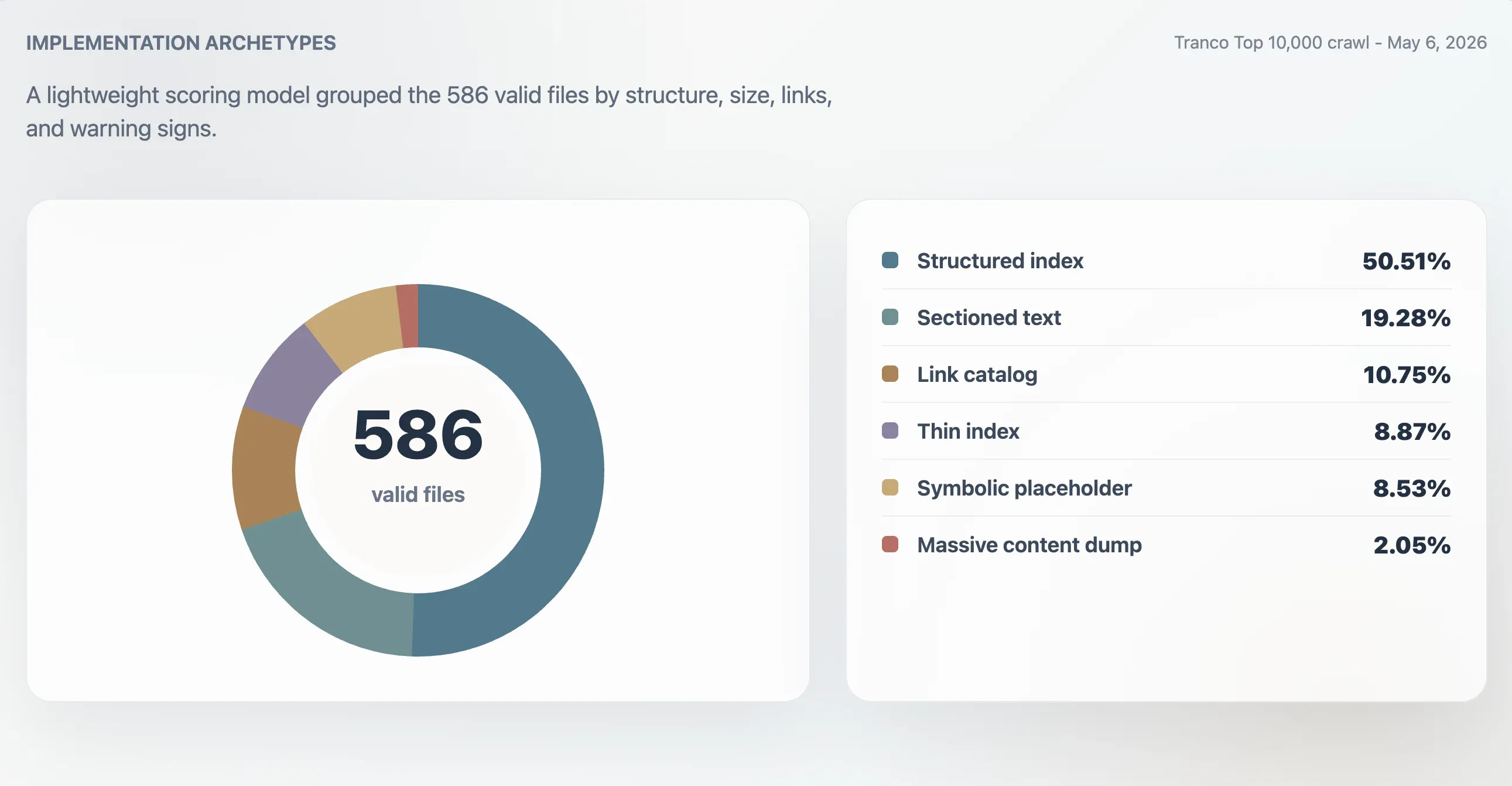
| Archetyp | Domeny | Udział wśród poprawnych plików | Mediana wyniku | Mediana rozmiaru pliku | Mediana linków |
|---|---|---|---|---|---|
| Ustrukturyzowany indeks | 296 | 50,51% | 98 | 11 241 B | 61,5 |
| Tekst podzielony na sekcje | 113 | 19,28% | 78 | 4 718 B | 0 |
| Katalog linków | 63 | 10,75% | 86 | 4 160 B | 23 |
| Cienki indeks | 52 | 8,87% | 66 | 2 814 B | 0 |
| Symboliczny lub placeholder | 50 | 8,53% | 27 | 15 B | 0 |
| Ogromny zrzut treści | 12 | 2,05% | 74 | 2,84 MB | 7 259,5 |
Najwięksi wdrażający mają gęstsze implementacje
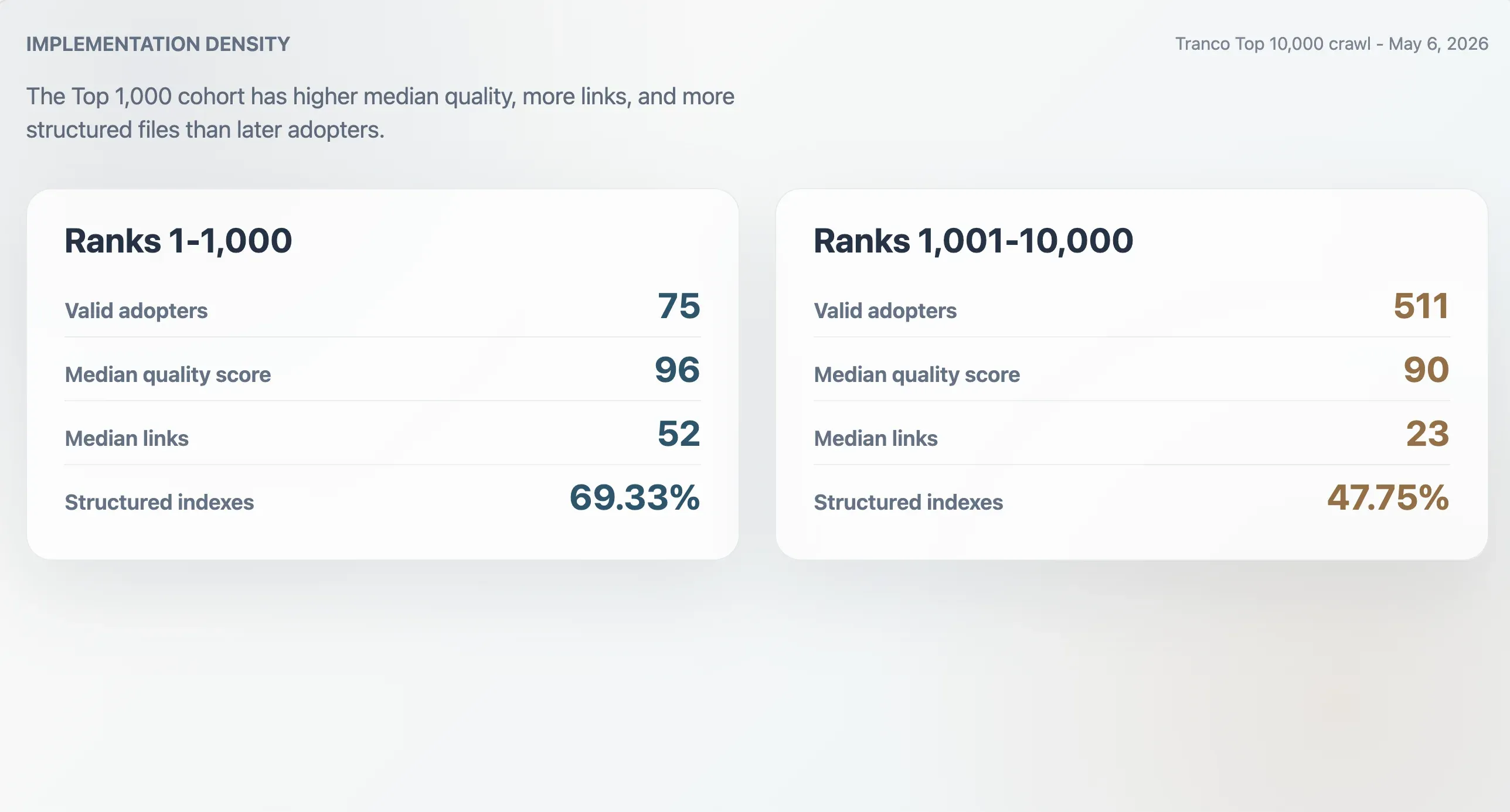
75 poprawnych wdrażających w Tranco Top 1000 miało medianę wyniku jakości 96, medianę rozmiaru pliku 9068 bajtów, medianę liczby linków Markdown 52 oraz medianę liczby sekcji 11. 511 wdrażających z pozycji 1001–10 000 miało niższe mediany: wynik 90, rozmiar pliku 6506 bajtów, 23 linki Markdown i 9 sekcji. Wdrażający z Top 1000 częściej byli też ustrukturyzowanymi indeksami: 69,33% wobec 47,75% w późniejszej kohorcie.
Problem fałszywych trafień

Największym ryzykiem pomiarowym są fałszywe trafienia. Spośród 1606 domen, które zwróciły HTTP 200 dla /llms.txt, 1020 nie przeszło walidacji. Najczęstszym powodem niepoprawności było przekierowanie na niecelową stronę — 618 przypadków. Kolejne 367 odpowiedzi to ogólne dokumenty HTML. 29 zwróciło pustą treść, a 6 miało inne lub niesklasyfikowane błędy.
Ma to znaczenie, ponieważ wiele dużych witryn kieruje nieznane ścieżki na strony logowania, stronę główną, powłoki aplikacji, strony regionalne, warstwy zgody lub marketingowe fallbacki. Takie odpowiedzi mogą wyglądać zdrowo dla crawlera opartego na kodach statusu, ale nie zawierają poprawnego sygnału llms.txt.
llms-full.txt: rzadszy i bardziej nierówny
Towarzyszący plik llms-full.txt był znacznie rzadszy niż llms.txt. Crawl znalazł 103 poprawne pliki pełne, co odpowiada 17,58% poprawnych wdrażających llms.txt i 1,03% całej próby Top 10 000.
Implementacje pełnego pliku były nierówne. Wśród 103 wdrażających z dwoma plikami 57 miało llms-full.txt większy niż plik indeksowy, ale 46 miało pełny plik nie większy od indeksowego albo pełny plik mniejszy niż 100 bajtów. Mediana stosunku rozmiaru pełnego pliku do indeksowego wynosiła 1,43, ale skrajne przypadki były znacznie wyższe. Pełny plik Supabase był około 7139,3 razy większy od pliku indeksowego. W przypadku Made-in-China.com pełny plik miał 89,89 MB.
| Domena | llms.txt | llms-full.txt | Stosunek |
|---|---|---|---|
| made-in-china.com | 4,49 MB | 89,89 MB | 20,0x |
| sendbird.com | 281,86 KB | 11,99 MB | 42,5x |
| taboola.com | 286,78 KB | 11,73 MB | 40,9x |
| supabase.co | 1,26 KB | 8,98 MB | 7139,3x |
| neon.tech | 27,44 KB | 5,01 MB | 182,7x |
Rekomendacja: publikuj
llms-full.txttylko wtedy, gdy witryna ma już stabilny pipeline dokumentacji, dyscyplinę wersjonowania i jasny powód, by ujawniać duże wolumeny treści w jednym pliku czytelnym maszynowo.
llms.txt, robots.txt i sitemap.xml
llms.txt nie powinien być traktowany jako nowe robots.txt. Oba są plikami czytelnymi maszynowo w katalogu głównym, ale komunikują różne rzeczy. robots.txt jest sygnałem preferencji crawlera i kontroli dostępu. sitemap.xml to sygnał wykrywania adresów URL. llms.txt jest sygnałem wyjaśniającym i nawigacyjnym.
| Sygnał | Główna rola | Typowy odbiorca | Interpretacja w tym badaniu |
|---|---|---|---|
robots.txt | Deklarowanie preferencji crawlerów i ograniczeń na poziomie ścieżek. | Wyszukiwarki, crawlery AI, crawlery archiwizujące, ogólne boty. | Sygnał zarządzania i dostępu. |
sitemap.xml | Lista wykrywalnych adresów URL dla systemów indeksujących. | Wyszukiwarki i pipeline’y indeksujące. | Sygnał odkrywania treści. |
llms.txt | Dostarczanie zwięzłego kontekstu witryny, ważnych linków, dokumentacji, API, przykładów i odniesień do polityk. | Aplikacje LLM, agenci AI, narzędzia dla deweloperów, systemy wyszukiwania semantycznego. | Sygnał wyjaśniający i nawigacyjny. |
Rekomendacje
Dla witryn rozważających llms.txt najsilniejsze implementacje w tym zbiorze i dowody ruchowe z zewnątrz sugerują pragmatyczny wzorzec:
- Opublikuj
/llms.txtw katalogu głównym i utrzymuj go dostępnym bez logowania, wykonywania JavaScript, ścian zgody czy przekierowań poza ścieżką. - Serwuj go jako
text/plainlubtext/markdown, jeśli to możliwe. - Zacznij od krótkiego opisu witryny, a potem pogrupuj linki według produktu, dokumentacji, API, cennika, changelogu, przykładów, wsparcia, zasad i zasobów firmowych.
- Preferuj linki kanoniczne zamiast wyczerpujących list adresów URL.
- Unikaj pustych, symbolicznych plików; w najlepszym razie są słabym sygnałem.
- Unikaj ogromnych, nieuporządkowanych zrzutów, chyba że istnieje silny przypadek użycia dla konsumpcji maszynowej i niezawodny pipeline generowania.
- Po publikacji waliduj końcowy URL, treść odpowiedzi, typ zawartości, strukturę Markdown, liczbę linków i rozmiar pliku.
Zespoły powinny też ostrożnie ustawiać oczekiwania. Dostępne publiczne eksperymenty nie dowodzą, że llms.txt samodzielnie zwiększa ruch odsyłający z AI. Jeśli zespół chce testować wpływ biznesowy, powinien śledzić razem ruch z LLM, cytowane strony, żądania botów, świeżość indeksu i zmiany treści. Przydatny eksperyment porównywałby dopasowane grupy stron, utrzymywał aktualizacje treści na stałym poziomie tam, gdzie to możliwe, i rozdzielał ruch specyficzny dla platform, takich jak Perplexity, ChatGPT, Gemini, Claude i Bing/Copilot.
Ograniczenia
To migawka oparta na crawl’u, a nie trwały stan rzeczy. Witryny mogą dodawać, usuwać lub zmieniać pliki llms.txt w dowolnym momencie. Niektóre domeny mogą blokować zautomatyzowane żądania albo zachowywać się inaczej zależnie od geolokalizacji, konfiguracji TLS, logiki przekierowań, user-agenta lub mechanizmów ochrony przed botami. Badanie testowało wyłącznie pliki w katalogu głównym i nie przeszukiwało subdomen ani niestandardowych ścieżek.
Wynik jakości i archetypy to narzędzia badawcze, a nie oficjalne etykiety zgodności. Analiza tematów opiera się na słowach kluczowych i należy ją czytać jako kierunkową. Badanie nie dowodzi, że jakakolwiek konkretna platforma AI obecnie czyta, respektuje lub wykorzystuje llms.txt produkcyjnie.
Zewnętrzne dowody ruchowe przeanalizowane w tej wersji też mają ograniczenia. Analiza Search Engine Land jest bardziej wartościowa jako ostrożna, wielowitrynowa obserwacja niż jako randomizowany eksperyment. Wynik Alimbekova jest użyteczny jako przejrzyste studium przypadku na poziomie witryny, ale nie ma grupy kontrolnej i obejmuje okres, w którym cały ruch odsyłający znacząco wzrósł. Te źródła pomagają osadzić debatę, ale nie zamieniają tego crawl’u w przyczynowe badanie ruchu.
Pliki i odtwarzalność
| Plik | Cel |
|---|---|
crawl_llms_txt.py | Crawler dla /llms.txt i /llms-full.txt. |
analyze_llms_txt.py | Główna analiza adopcji i generowanie wykresów. |
deep_analyze_llms_txt.py | Analiza wtórna dla decyli rankingu, TLD, sygnałów tematycznych, wyników jakości, archetypów i zachowania dwóch plików. |
deep_dive_early_quality.py | Klasyfikacja wczesnych wdrażających i pogłębiona analiza jakości implementacji. |
data/llms_probe_results_top_10000.csv | Główny zbiór wyników crawl’u. |
data/deep_analysis_top_10000.json | Podsumowanie analizy wtórnej. |
data/deep_early_quality_analysis.json | Kategorie wczesnych wdrażających, porównanie kohort jakości, szczegóły archetypów i studia przypadków. |
Źródła
- Plik /llms.txt, Jeremy Howard, 2024.
- Metodologia HTTP Archive Web Almanac 2024.
- Cloudflare Radar: rozszerzone informacje o AI.
- Cloudflare Radar AI Insights.
- Consent in Crisis: The Rapid Decline of the AI Data Commons, Data Provenance Initiative.
- Tranco: ranking topowych witryn dla badań, odporny na manipulacje.
- Czy llms.txt ma znaczenie?, Search Engine Land, styczeń 2026.
- Stan adopcji llms.txt, Rankability, czerwiec 2025.
- Jak LLMS.txt zwiększył ruch z czatu AI o 23%, Renat Alimbekov.
Poprawki metodologiczne, problemy ze zbiorem danych i dalsze analizy mile widziane pod adresem support@thunderbit.com. Ten raport został opublikowany niezależnie od jakiegokolwiek stanowiska handlowego Thunderbit. Dane w tym raporcie bronią się same. — Zespół badawczy Thunderbit, maj 2026.
Wypróbuj Thunderbit do scrapowania i analizy danych z sieci Get Started Free




