

Kilka miesięcy temu jeden z naszych użytkowników zadał pytanie, które sprawiło, że zatrzymałem się w pół łyka kawy: „Jeśli zeskrobię publiczne ceny produktów z Coupang, czy skończę w koreańskiej sali sądowej?”. Szczerze mówiąc, nie miałem gotowej odpowiedzi w jednym zdaniu — i większość poradników prawnych, które znalazłem w internecie, też jej nie miała.
To pytanie utkwiło mi w głowie, bo co tydzień po cichu zadają je sobie tysiące operatorów e-commerce, zespołów sprzedaży i założycieli SaaS. Globalny rynek usług web scrapingu osiągnął około 1,03 mld USD w 2024 r. i szybko rośnie. Coraz więcej firm zbiera dane z sieci — i coraz więcej z nich zastanawia się, gdzie w Korei przebiegają granice prawa. Korea nie zakazuje scrapingu wprost.
Ale mogą mieć zastosowanie cztery główne ustawy, zależnie od tego, co scrapujesz, jak to robisz i w jakim celu. Najgłośniejszą sprawą, do której wszyscy się odwołują, jest orzeczenie koreańskiego Sądu Najwyższego w sprawie Yanolja (2021Do1533, wyrok z 12 maja 2022 r.), które uniewinniło narzędzie scrapujące konkurenta w postępowaniu karnym — a następnie, w odrębnym postępowaniu cywilnym, obciążyło tę samą firmę odszkodowaniem w wysokości około 1 mld KRW. To właśnie ten podwójny wynik jest najważniejszą rzeczą, jaką laik powinien zrozumieć o koreańskim prawie dotyczącym scrapingu, i stanowi fundament tego przewodnika. Nie trzeba mieć dyplomu z prawa — wystarczy praktyczne podejście do ryzyka, którego naprawdę można użyć.
Poziom trudności: początkujący (bez wiedzy prawnej ani technicznej)
Szacowany czas: około 15 minut czytania; materiał referencyjny na później
Co będzie potrzebne: podstawowe rozumienie, czym jest web scraping (jeśli potrzebujesz przypomnienia, zobacz nasz wpis co to jest web scraping)
Czy web scraping jest legalny w Korei? Krótka odpowiedź
Sam web scraping nie jest w Korei nielegalny. To neutralna technologia — jak przeglądarka internetowa albo formuła w arkuszu kalkulacyjnym. Koreańskie sądy konsekwentnie skupiają się nie na narzędziu, ale na zachowaniu związanym z jego użyciem.
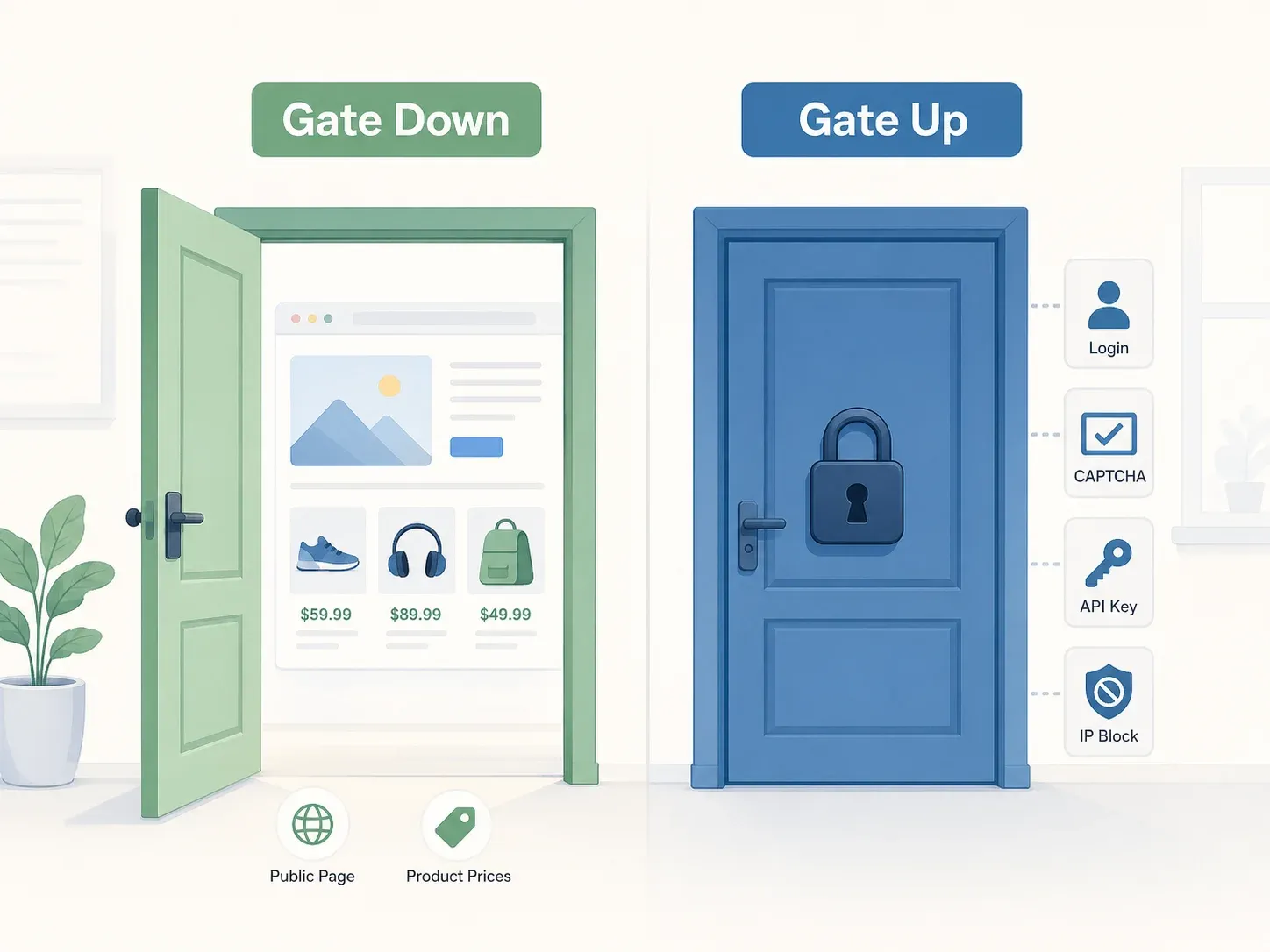
Najlepszy model myślenia daje orzeczenie Sądu Najwyższego w sprawie Yanolja: zasada „brama otwarta vs. brama zamknięta”. Jeśli strona nie ma obiektywnych ograniczeń dostępu — nie ma logowania, CAPTCHA, wymogu klucza API ani blokady IP — brama jest „otwarta”, a dostęp do publicznie dostępnych danych co do zasady nie stanowi przestępstwa na gruncie koreańskiej Ustawy o sieciach informacji i komunikacji (ICNA). Sąd badał konkretnie, czy „środki ochronne, warunki korzystania i inne obiektywnie ujawnione okoliczności” ograniczały dostęp, i uznał, że serwer API Yanolja był swobodnie osiągalny przez publiczną aplikację.
Ale „niekaralne” nie znaczy „bez ryzyka”.
Odpowiedzialność cywilna to zupełnie osobna kwestia. Można uniknąć oskarżenia, a mimo to zapłacić odszkodowanie rzędu miliarda wonów. Sprawa Yanolja pokazała to boleśnie jasno.
Na web scraping mogą wpływać cztery koreańskie akty prawne:
- ICNA (Information and Communications Network Act) — zasada „zakaz wkraczania”
- Ustawa o prawie autorskim — prawa producenta bazy danych
- PIPA (Personal Information Protection Act) — zasady zbierania danych osobowych
- UCPA (Unfair Competition Prevention Act) — ogólny zakaz „jazdy na gapę”
Reszta tego przewodnika pokazuje, jak te przepisy przekładają się na realne scenariusze, żebyś mógł ocenić, gdzie naprawdę mieści się Twój projekt scrapingu.
Ramy ryzyka dla web scrapingu w Korei: zielone, żółte i czerwone światło
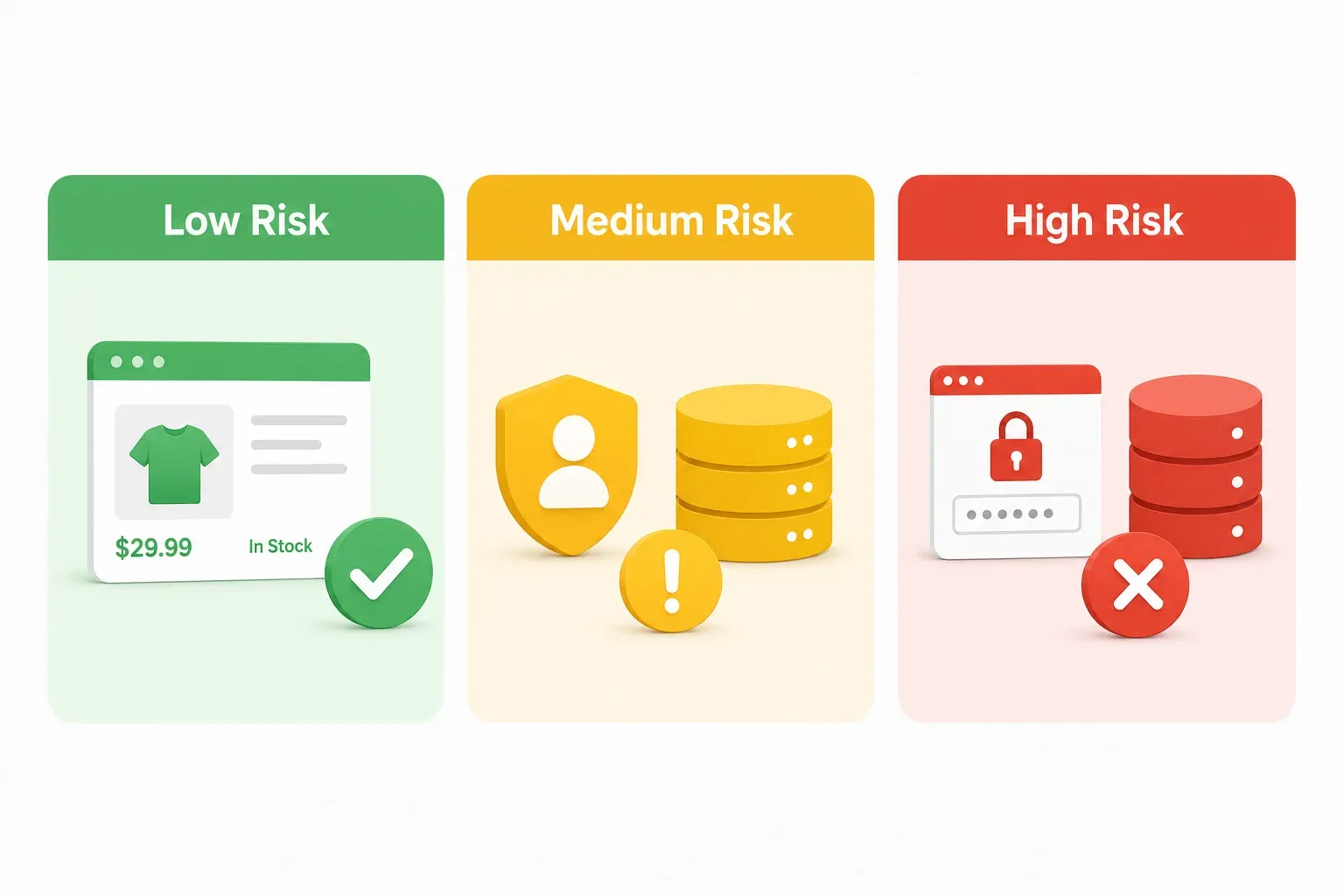
Każdy artykuł prawny, jaki znalazłem o koreańskim prawie scrapingu, wygląda tak, jakby był pisany dla adwokatów. Jeśli jesteś menedżerem operacyjnym e-commerce albo założycielem SaaS, nie potrzebujesz 40-stronicowej analizy ustawowej — potrzebujesz szybkiego sposobu oceny ryzyka przed startem projektu. Pomyśl o tym jak o sygnalizacji świetlnej. Zielone oznacza: jedź dalej (z normalną ostrożnością). Żółte: zwolnij i rozejrzyj się. Czerwone: stop i zadzwoń do prawnika.
Strefa zielona: scenariusze scrapingu o niskim ryzyku
| Scenariusz | Poziom ryzyka | Kluczowa ustawa | Dlaczego |
|---|---|---|---|
| Scraping publicznych ofert produktów (bez logowania i bez CAPTCHA) | 🟢 Niskie | ICNA, Ustawa o prawie autorskim | Orzeczenie Yanolja: brak ograniczeń dostępu = brak naruszenia ICNA; dane faktograficzne (ceny, dostępność) nie są twórczą ekspresją |
| Scraping publicznych cen wyłącznie do wewnętrznej analityki | 🟢 Niskie | UCPA, Ustawa o prawie autorskim | Dane faktograficzne, ograniczony zakres, brak konkurencyjnej redystrybucji |
| Zbieranie publicznych, nieosobowych i niechronionych prawem autorskim faktów z otwartych stron | 🟢 Niskie | ICNA, Ustawa o prawie autorskim | Nie omijano żadnej bariery dostępu; pojedyncze fakty nie podlegają ochronie |
Wyrok karny w sprawie Yanolja jest punktem odniesienia dla tej strefy. Sąd Najwyższy nie stwierdził naruszenia ICNA, ponieważ serwer API był swobodnie osiągalny — zwykli użytkownicy mogli uzyskać do niego dostęp przez aplikację z członkostwem lub bez, a żadne dodatkowe środki ochronne nie blokowały dostępu do API.
Dla użytkowników Thunderbit to najbardziej pożądany scenariusz. Jeśli scrapujesz publiczne strony e-commerce lub nieruchomości w trybie cloud scraping — pobierając nazwy produktów, ceny, dostępność lub metadane ofert, a pomijając pola z danymi osobowymi — zwykle działasz w zielonej strefie. (Ale „zwykle” nie znaczy „zawsze”, a niżej wyjaśnię niuanse.)
Wypróbuj Thunderbit do scrapingu danych publicznych
Strefa żółta: scenariusze scrapingu o średnim ryzyku
| Scenariusz | Poziom ryzyka | Kluczowa ustawa | Dlaczego |
|---|---|---|---|
| Scraping danych osobowych (imiona, e-maile, numery telefonów), nawet z publicznych stron | 🟡 Średnie | PIPA, ICNA | PIPA ma zastosowanie niezależnie od publicznej widoczności; poprawki z 2023 r. zaostrzyły zasady zgody |
| Scraping dużych wolumenów, które mogą stanowić „istotną część” bazy danych konkurenta | 🟡 Średnie | Ustawa o prawie autorskim, UCPA | Test ilościowy + jakościowy w prawie koreańskim |
| Ignorowanie sygnałów robots.txt | 🟡 Średnie | Dowód złej wiary | Samo w sobie nie jest przestępstwem, ale może działać przeciwko Tobie w sądzie |
| Scraping danych publicznych, ale wykorzystywanie ich do bezpośredniej konkurencji ze źródłem | 🟡 Średnie | UCPA | Jazda na gapę na inwestycji innej platformy |
Dane osobowe są najważniejszym wyzwalaczem strefy żółtej.
Nawet jeśli numer telefonu lub adres e-mail są widoczne na publicznej stronie, PIPA nadal ma zastosowanie. Reforma PIPA z 2023 r. rozszerzyła prawa osób, których dane dotyczą, i zaostrzyła wymogi zgody. A w 2024 r. koreańska Komisja Ochrony Danych Osobowych (PIPC) opublikowała wytyczne dotyczące publicznie dostępnych danych osobowych w kontekście AI i zbierania danych — jasno pokazując, że sama publiczna dostępność nie oznacza automatycznej zgody.
Znaczenie ma też wolumen. Sąd Najwyższy w sprawie Yanolja stwierdził, że o tym, czy skopiowano „istotną część” bazy danych, decydują zarówno czynniki ilościowe, jak i jakościowe. Porównaj skopiowaną część z całą bazą i zadaj sobie pytanie, czy odzwierciedla ona istotną inwestycję producenta.
Strefa czerwona: scenariusze scrapingu o wysokim ryzyku
| Scenariusz | Poziom ryzyka | Kluczowa ustawa | Dlaczego |
|---|---|---|---|
| Scraping za logowaniem lub omijanie kontroli dostępu | 🔴 Wysokie | ICNA Art. 48 | „Brama zamknięta” = nieuprawniony dostęp; wysokie ryzyko ścigania |
| Omijanie CAPTCHA, blokad IP lub systemów wykrywania botów | 🔴 Wysokie | ICNA Art. 48(4) | Poprawka z 2024 r. wprost celuje w narzędzia i urządzenia omijające zabezpieczenia |
| Kopiowanie i odsprzedaż pełnej bazy danych konkurenta | 🔴 Wysokie | Ustawa o prawie autorskim (prawa do bazy danych), UCPA | Istotne powielanie + komercyjna jazda na gapę |
| Zbieranie danych osobowych bez podstawy prawnej do marketingu lub outreachu | 🔴 Wysokie | PIPA | Do 5 lat / 50 mln KRW grzywny; kary administracyjne do 3% przychodu |
Dodatek do ICNA z 2024 r. — artykuł 48(4) — wprost zakazuje instalowania, przekazywania lub rozpowszechniania programów albo urządzeń technicznych, które omijają „zwykłe procedury ochrony lub uwierzytelniania” bez uzasadnionego powodu.
Niezależnie od tego, listopadowy wyrok Sądu Najwyższego z 2024 r. (2021Do5555) potwierdził, że nieuprawnione wtargnięcie do sieci może wystąpić nawet bez fizycznego uszkodzenia zabezpieczeń. Wystarczy użycie cudzych identyfikatorów lub niewłaściwych poleceń, aby ominąć ograniczenia dostępu.
Cztery koreańskie ustawy mające zastosowanie do web scrapingu
| Ustawa | Co chroni | Kiedy ma zastosowanie do scraperów | |---|---|---|---| | ICNA Art. 48 | Stabilność sieci, uprawnienia dostępu | Obejście logowania, CAPTCHA, uwierzytelniania, blokad IP, limitów kluczy API | | Ustawa o prawie autorskim (art. 93) | Utwory twórcze + prawa producenta bazy danych | Kopiowanie treści ekspresyjnych, obrazów lub całości / istotnej części bazy danych | | PIPA | Dane osobowe, prawa osób, których dane dotyczą | Zbieranie imion, numerów telefonów, e-maili, identyfikatorów — nawet z publicznych stron | | UCPA (art. 2 ust. 1 lit. k i m) | Uczciwa konkurencja, dane o wartości handlowej | Jazda na gapę na inwestycji w dane innej platformy dla własnego konkurencyjnego biznesu |
ICNA Art. 48: zasada „zakaz wkraczania”
ICNA Art. 48(1) stanowi, że nikt nie może wtargnąć do sieci informacji i komunikacji „bez uzasadnionego uprawnienia dostępu lub poza dozwolonym zakresem uprawnień dostępu”. W praktyce scrapingu: jeśli strona ma ograniczenia dostępu, które omijasz, naruszasz prawo. Jeśli ograniczeń nie ma — strona publiczna, bez logowania — prawdopodobnie jesteś bezpieczny.
Kara za naruszenie na gruncie ICNA Art. 71 to do pięciu lat pozbawienia wolności lub grzywna do 50 mln KRW.
Jedno istotne zastrzeżenie: koreański Sąd Najwyższy konsekwentnie odróżnia ograniczenia wynikające z Warunków korzystania od ograniczeń dostępu. Warunki aplikacji Yanolja ograniczały ponowne użycie komercyjne i zakazywały programów automatycznych obciążających serwer, ale Sąd uznał, że te klauzule nie ograniczały obiektywnie dostępu do samego serwera API.
Ustawa o prawie autorskim: prawa producenta bazy danych
Koreańska Ustawa o prawie autorskim chroni producentów baz danych niezależnie od praw autorskich do pojedynczych treści. Zgodnie z art. 93 kopiowanie „całości lub istotnej części” bazy danych jest nielegalne — nawet jeśli pojedyncze punkty danych są publicznymi faktami.
Test ma charakter zarówno ilościowy (ile skopiowano względem całości?), jak i jakościowy (czy skopiowana część odzwierciedla istotną inwestycję producenta w budowę, weryfikację lub utrzymanie bazy danych?). Wielokrotne lub systematyczne kopiowanie mniejszych fragmentów też może się liczyć, jeśli w praktyce daje ten sam efekt co skopiowanie istotnej części.
Kara za naruszenie praw producenta bazy danych: do trzech lat lub 30 mln KRW na podstawie art. 136(2)(3). Ustawowe odszkodowania na podstawie art. 125-2 pozwalają zasądzić do 10 mln KRW za każde dzieło, a przy umyślnym naruszeniu w celu osiągnięcia zysku — do 50 mln KRW za każde dzieło.
PIPA: Ustawa o ochronie danych osobowych
PIPA reguluje zbieranie danych osobowych — imion, danych kontaktowych, identyfikatorów — nawet jeśli są publicznie widoczne. Reforma z 2023 r. była znacząca: rozszerzyła prawa osób, których dane dotyczą, zaostrzyła wymogi zgody, wprowadziła zasady dotyczące automatycznego podejmowania decyzji i ustaliła kary administracyjne do 3% łącznej sprzedaży za wskazane naruszenia.
Wytyczne PIPC z 2024 r. dotyczące publicznych danych i AI wprost wspominają o danych uzyskanych poprzez „web crawling i scraping” w kontekście publicznie dostępnych danych osobowych. Wytyczne wyjaśniają, że uzasadniony interes może w niektórych sytuacjach stanowić podstawę, ale organizacje muszą przeprowadzić test równowagi, zastosować zabezpieczenia, chronić prawa osób i zapewnić ład zarządczy.
A trend robi się coraz ostrzejszy. W marcu 2026 r. koreańskie media poinformowały o poprawce do PIPA, która podnosi maksymalne kary za poważne, powtarzające się naruszenia związane z wyciekiem danych do 10% przychodu; zmiana ma wejść w życie później w 2026 r.
UCPA: ogólny „koszyk” dla nieuczciwej konkurencji
UCPA to ustawa, która objęła GC Company w cywilnej sprawie Yanolja. Obecna ustawa zawiera dwa istotne przepisy:
- Art. 2 ust. 1 lit. k: obejmuje nieuczciwe wykorzystywanie elektronicznie zgromadzonych i zarządzanych danych technicznych lub biznesowych, które nie są tajemnicą
- Art. 2 ust. 1 lit. m: szersza klauzula ogólna dotycząca wykorzystywania rezultatów pracy innej osoby osiągniętych dzięki znaczącym inwestycjom lub wysiłkowi, na potrzeby własnej działalności bez zgody, wbrew uczciwym praktykom handlowym
Te przepisy UCPA mają charakter wyłącznie cywilny — bez sankcji karnych — ale mogą prowadzić do nakazów sądowych na podstawie art. 4, odszkodowań na podstawie art. 5, a nawet potrójnych odszkodowań w określonych umyślnych przypadkach na podstawie art. 14-2. W sprawie cywilnej Yanolja na tej podstawie zasądzono około 1 mld KRW.
Sprawa Yanolja: dlaczego można wygrać karnie, a przegrać cywilnie
To sprawa, którą każdy biznesowy użytkownik w Korei powinien rozumieć. Opowiem ją jako jedną historię, bo tak właśnie się potoczyła — i właśnie o ten rozdzielony wynik tutaj chodzi.
Co się stało: GC Company zeskrobała dane podróżnicze Yanolja
GC Company prowadziła konkurencyjną internetową platformę turystyczną. Zbudowali własnego crawlera, który uzyskiwał dostęp do serwera API aplikacji Baro Reservation Yanolja, poznawał adresy URL API i polecenia żądań, a następnie wysyłał je do serwera. Scraper zbierał informacje o zakwaterowaniu — nazwy partnerów, adresy, ceny, dostępność i obrazy. GC Company wykorzystywała te dane wewnętrznie do marketingu i pozycjonowania konkurencyjnego.
Yanolja złożyła zarówno zawiadomienie karne, jak i pozew cywilny.
Wyrok karny: uniewinnienie ze wszystkich zarzutów (Sąd Najwyższy 2021Do1533)
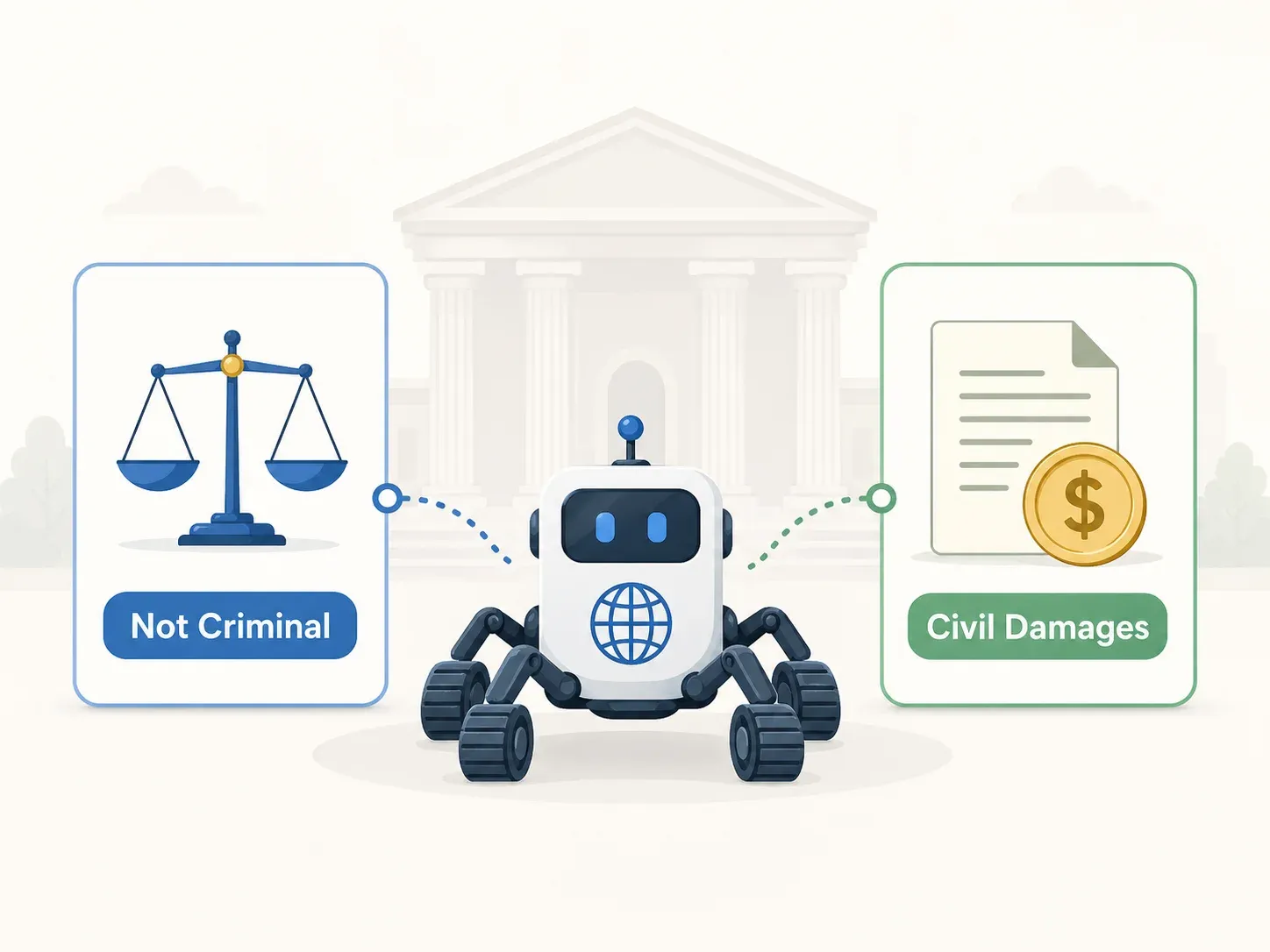
Sąd Najwyższy utrzymał w mocy uniewinnienie wydane przez sąd apelacyjny 12 maja 2022 r. w odniesieniu do wszystkich trzech zarzutów:
- ICNA Art. 48 (wtargnięcie): nie istniały ograniczenia dostępu. Serwer API był publicznie dostępny przez przeglądarkę i aplikację mobilną. Nie stosowano technicznego blokowania. Warunki korzystania ograniczały użycie, a nie dostęp.
- Ustawa o prawie autorskim (prawa producenta bazy danych): oskarżeni nie skopiowali „całości ani istotnej części” bazy danych. Skopiowane dane były już publicznie znane, a materiał dowodowy nie wykazał, że skopiowany fragment odzwierciedlał istotną inwestycję Yanolja.
- Art. 314 Kodeksu karnego (zakłócanie działalności gospodarczej): nie wykazano rzeczywistego zakłócenia działania serwera API Yanolja. Nie doszło do modyfikacji danych. Brak było zamiaru (mens rea) zakłócania działalności.
Najczęściej cytowana zasada brzmi: ograniczenia dostępu trzeba oceniać przez „środki ochronne, warunki korzystania i inne obiektywnie ujawnione okoliczności”. Jeśli brama jest otwarta, przejście przez nią nie jest wtargnięciem.
Wyrok cywilny: 1 mld KRW odszkodowania na podstawie UCPA
I tu historia skręca. Sąd Okręgowy w Seulu Centralnym, a następnie Sąd Apelacyjny w Seulu (sprawa 2021Na2034740, wyrok z 25 sierpnia 2022 r.) uznały, że GC Company naruszyła ogólną klauzulę UCPA. Sąd zasądził około 1 mld KRW (~800 tys. USD) odszkodowania kompensacyjnego i nakazał zaprzestanie dalszego powielania danych.
Uzasadnienie: baza danych o zakwaterowaniu Yanolja miała wartość komercyjną i odzwierciedlała znaczącą inwestycję — w zbieranie, weryfikację i aktualizację danych o obiektach noclegowych. GC Company jechała na gapę na tej inwestycji. Wyrok cywilny został ostatecznie utrzymany na poziomie Sądu Apelacyjnego w Seulu.
Praktyczny wniosek: uniewinnienie karne nie oznacza bezpieczeństwa cywilnego
To najtrudniejsza do intuicyjnego przyjęcia lekcja z koreańskiego prawa scrapingu. Zgodny z prawem karnym dostęp nie zwalniał z odpowiedzialności za nieuczciwe wykorzystanie komercyjne. „Czy grozi mi postępowanie karne?” i „Czy mogę zostać pozwany?” to dwa różne pytania, które mogą mieć przeciwne odpowiedzi.
Dla użytkowników biznesowych: nawet jeśli Twoja metoda scrapingu znajduje się wyraźnie w zielonej strefie pod kątem karnym, to sposób wykorzystania danych — zwłaszcza jeśli bezpośrednio konkuruje ze źródłem — decyduje o ryzyku cywilnym.
Korea vs. USA vs. UE: porównanie prawa o web scrapingu
Nie znalazłem innego przewodnika, który zebrałby to w jednej tabeli — co jest zaskakujące, biorąc pod uwagę, jak wiele firm scrapuje dane transgranicznie.
| Wymiar | Korea Południowa | Stany Zjednoczone | UE / EOG |
|---|---|---|---|
| Główna ustawa | ICNA art. 48, Ustawa o prawie autorskim | CFAA (18 U.S.C. §1030), przepisy stanowe | RODO, Dyrektywa o bazach danych (96/9/WE) |
| Przełomowa sprawa | Yanolja v GC Company (Sąd Najwyższy 2021Do1533, 2022) | hiQ v LinkedIn (9th Cir. 2022), Van Buren v. US (2021) | Ryanair v PR Aviation (TSUE C-30/14, 2015) |
| Scraping danych publicznych | Legalny, jeśli nie ma obiektywnych barier dostępu („brama otwarta”) | Legalny według logiki hiQ (dane publiczne); Van Buren zawęził CFAA | Zależy od praw do bazy danych, umowy, praw autorskich, RODO i prawa państwa członkowskiego |
| Zasady dotyczące danych osobowych | PIPA (po nowelizacji z 2023 r.) — zgoda lub podstawa prawna | Branżowe: CCPA (Kalifornia), stanowe ustawy o prywatności | RODO — ścisła zgoda / uzasadniony interes; maks. kara 20 mln € lub 4% globalnego przychodu |
| Naruszenie ToS = przestępstwo? | Nie (sądy uznają, że ToS ≠ naruszenie ICNA) | Nie (Van Buren 2021: ToS ≠ CFAA) | Zasadniczo nie, ale możliwe naruszenie umowy (Ryanair) |
| Ochrona baz danych | Ustawa o prawie autorskim — prawa producenta bazy danych | Brak federalnego prawa do baz danych | Sui generis right do bazy danych |
| Maksymalna kara karna | Do 5 lat / 50 mln KRW (ICNA) | Do 10 lat / 250 tys. USD (CFAA) | Zależy od państwa członkowskiego |
Najważniejsze różnice dla Twojego biznesu
- Korea nie ma szerokiego wyjątku dla text and data mining (TDM), takiego jak dyrektywa DSM w UE. Jeśli trenujesz modele AI na zeskrobanych koreańskich danych, nie dostajesz ustawowego wyłączenia.
- Ogólna klauzula UCPA w Korei jest szersza i mniej przewidywalna niż amerykańskie prawo o nieuczciwej konkurencji. Wynik w sprawie cywilnej Yanolja byłby znacznie trudniejszy do uzyskania w USA.
- Wszystkie trzy jurysdykcje zgadzają się co do jednego: samo naruszenie Warunków korzystania nie jest przestępstwem.
- Koreańska ochrona baz danych jest ustawowa (podobnie jak w UE), podczas gdy USA nie mają ogólnego federalnego prawa do baz danych. To daje koreańskim właścicielom platform więcej narzędzi cywilnoprawnych.
- Jeśli scrapujesz transgranicznie, obowiązuje najostrzejsze prawo mające zastosowanie. Projekt scrapingu obejmujący dane z Korei, USA i UE musi spełniać wymagania wszystkich trzech reżimów.
Scenariusze branżowe: czy web scraping jest legalny w Korei w Twojej branży?
Profil ryzyka bardzo różni się w zależności od branży, a żaden przewodnik, jaki znalazłem, nie mapuje koreańskiego prawa scrapingu na konkretne sektory. Więc złożyłem to sam.
E-commerce: monitorowanie cen i dane produktowe
Scraping publicznych cen produktów z Coupang, Gmarket lub 11Street to najczystszy przykład ze strefy zielonej — trzymaj się danych faktograficznych (cena, dostępność, nazwa produktu), unikaj obszarów wymagających logowania, nie omijaj technicznych blokad i używaj danych wewnętrznie do benchmarkingu.
Ryzyko rośnie, gdy scrapujesz opisy produktów (treści twórcze → prawa autorskie), dane kontaktowe sprzedawców (PIPA), obrazy (prawa autorskie) albo cały katalog (prawa do bazy danych + UCPA).
Nie znalazłem wiodącej koreańskiej sprawy dotyczącej scrapingu e-commerce porównywalnej z Yanolja. Bardziej rozwinięte precedensy dotyczą branży turystycznej i rekrutacji — ale brak pozwów nie oznacza braku ryzyka.
Zaplanowany scraper Thunderbit i tryb cloud scraping są stworzone dokładnie do takiego scenariusza: cykliczne sprawdzanie cen i stanów magazynowych na publicznych stronach, a funkcja AI Suggest Fields pozwala wybrać kolumny, które chcesz pobrać, i wykluczyć pola z danymi osobowymi.
Nieruchomości: ogłoszenia o nieruchomościach
Rynek nieruchomości to z natury strefa żółta. Ogłoszenia na platformach takich jak Zigbang czy Naver Real Estate łączą dane faktograficzne (cena, powierzchnia, lokalizacja) z imionami agentów, numerami telefonów biura, numerami komórkowymi, zdjęciami i kuratorowanymi bazami platform.
Scraping publicznych danych o nieruchomościach może być mniej ryzykowny. Ale zbieranie kolumn kontaktowych agentów natychmiast uruchamia PIPA — a pobieranie wszystkich ofert z jednego regionu zaczyna wyglądać jak istotne kopiowanie bazy danych.
Jak ograniczać ryzyko: wyklucz kolumny osobowe, zawęź zasięg geograficzny, udokumentuj uzasadniony cel biznesowy, respektuj limity zapytań i unikaj odtwarzania konkurencyjnej usługi ogłoszeniowej. AI w Thunderbit można skonfigurować tak, aby pobierało tylko potrzebne pola nieruchomości — cenę, metry kwadratowe, lokalizację — z pominięciem danych kontaktowych.
Rekrutacja: oferty pracy
Rekrutacja to bezdyskusyjnie sektor wysokiego ryzyka. Korea ma tu bezpośredni precedens: JobKorea v. Saramin. Saramin scrapował bazę ofert pracy JobKorea i został uznany za odpowiedzialnego za naruszenie praw do bazy danych i nieuczciwą konkurencję. Dane rekrutacyjne zwykle łączą inwestycję platformy (kuratorowane, zweryfikowane ogłoszenia), kopiowanie dużych wolumenów bazy oraz dane osobowe lub kontaktowe rekruterów.
Moja rekomendacja: generalnie unikaj scrapingu konkurencyjnej platformy pracy, jeśli celem jest budowa lub wzbogacenie rywalizującej bazy ofert. Jeśli przypadek użycia jest wąski, poproś o ocenę prawną przed zbieraniem danych, zminimalizuj wolumen, usuń kontakty osobowe i nie redystrybuuj wyników.
Pełna tabela kar: co grozi, jeśli web scraping pójdzie źle w Korei
| Koreańska ustawa | Rodzaj naruszenia | Maks. kara karna | Maks. środek cywilny/administracyjny | Najważniejsza zmiana 2023–2026 |
|---|---|---|---|---|
| ICNA art. 48 | Nieuprawniony dostęp / ingerencja | 5 lat / 50 mln KRW grzywny | Odszkodowanie + nakaz zaprzestania | 2024: dodano art. 48(4), celujący w narzędzia omijające zabezpieczenia |
| Ustawa o prawie autorskim (prawa do bazy danych, art. 93) | Istotne powielanie bazy danych | 3 lata / 30 mln KRW grzywny | Ustawowe odszkodowania do 50 mln KRW/utwór (umyślnie w celu zysku) | — |
| PIPA | Bezprawne zbieranie danych osobowych | 5 lat / 50 mln KRW grzywny | Kara administracyjna do 3% łącznej sprzedaży; możliwy pozew zbiorowy | Reforma 2023; wytyczne PIPC 2024 dot. publicznych danych i AI; trend 2026 w kierunku 10% za powtarzające się wycieki |
| UCPA art. 2(1)(k)/(m) | Nieuczciwe pozyskiwanie / wykorzystywanie danych | Wyłącznie cywilnie (bez sankcji karnych dla klauzuli ogólnej) | Odszkodowanie + nakaz zaprzestania; potrójne odszkodowanie w określonych umyślnych przypadkach | Ustawa o ramowych danych z 2022 r. wzmocniła przepisy |
| Art. 314 Kodeksu karnego | Zakłócanie działalności gospodarczej środkami technicznymi | 5 lat / 15 mln KRW grzywny | — | Yanolja: nie wykazano rzeczywistego zakłócenia |
Kluczowa kwestia: ścieżka karna i cywilna biegną niezależnie. Możesz odpowiadać w obu trybach jednocześnie — i wygrać w jednym, przegrywając w drugim.
10-punktowa lista kontrolna zgodności przed scrapingiem w Korei
Poniżej znajdziesz dziesięć pytań tak/nie, które warto przejść przed rozpoczęciem jakiegokolwiek projektu scrapingu. Wydrukuj to, dodaj do zakładek, przyklej do monitora — cokolwiek działa.
- Czy docelowa strona nie wymaga logowania, aby uzyskać dostęp do potrzebnych danych? Jeśli potrzebne jest logowanie, token lub konto, ryzyko gwałtownie przesuwa się w stronę ICNA Art. 48.
- Czy nie ma technicznych ograniczeń dostępu? CAPTCHA, blokady IP, klucze API, limity zapytań i ściany botów to mocne sygnały strefy czerwonej.
- Czy sprawdziłeś robots.txt strony? Sam w sobie nie jest prawnie wiążący w koreańskim precedensie, ale może być użytecznym dowodem oczekiwań właściciela strony i Twojej dobrej wiary.
- Czy zbierasz jakiekolwiek dane osobowe? Jeśli w zakresie są imiona, numery telefonów, e-maile, identyfikatory lub indywidualne dane kontaktowe, potrzebna jest analiza PIPA.
- Czy kopiujesz „istotną część” bazy danych strony? Zadaj pytania ilościowe i jakościowe — ile, i czy skopiowana część odzwierciedla inwestycję źródła?
- Czy zdefiniowałeś cel? Analityka wewnętrzna wiąże się z niższym ryzykiem niż redystrybucja lub budowa konkurencyjnej bazy danych. (Ale Yanolja pokazuje, że wewnętrzne wykorzystanie konkurencyjne nie jest pełną tarczą ochronną.)
- Czy udokumentowałeś na piśmie uzasadniony cel biznesowy? Dokumentacja pomaga przy ważeniu uzasadnionego interesu w PIPA i jako dowód dobrej wiary.
- Czy przed zapisem lub użyciem usunąłeś albo zanonimizowałeś pola z danymi osobowymi? Wykluczenie danych kontaktowych często przenosi scraping nieruchomości, rekrutacji i katalogów z najniebezpieczniejszego wzorca PIPA.
- Czy stosujesz rozsądne odstępy między żądaniami? Unikaj przeciążania serwera — ryzyko z art. 314 Kodeksu karnego i ICNA Art. 48(3) rośnie, gdy scraping pogarsza działanie usługi.
- Czy skonsultowałeś się z koreańskim prawnikiem przy projektach dużej skali, komercyjnych lub transgranicznych? Mogą mieć zastosowanie zarówno prawo koreańskie, jak i RODO czy amerykańskie przepisy o prywatności lub dostępie do systemów komputerowych.
⚠️ Zastrzeżenie: Ta lista służy orientacji, a nie poradzie prawnej. W konkretnych sytuacjach zawsze skonsultuj się z lokalnym koreańskim prawnikiem.
Jak Thunderbit pomaga scrapować koreańskie strony odpowiedzialnie
Pełna transparentność: pracuję w zespole marketingu Thunderbit. Ale naprawdę uważam, że dopasowanie produktu do prawa w tym przypadku jest praktyczne, a nie tylko sprzedażowe.
Thunderbit został zaprojektowany do przypadków użycia ze strefy zielonej, które opisuje ten artykuł: scrapingu publicznie dostępnych danych bez logowania. Oto jak konkretne funkcje mapują się na ramy zgodności:
- Tryb cloud scraping dla stron publicznych — bez logowania, bez lokalnej sesji, w granicach publicznie dostępnego dostępu. To odpowiada zasadzie Yanolja „brama otwarta”.
- AI Suggest Fields pozwala dokładnie określić, które kolumny danych chcesz pobrać. Potrzebujesz cen produktów i dostępności, ale nie numerów telefonów sprzedawców? Po prostu wyklucz kolumny osobowe. To najprostszy sposób na uniknięcie wyzwalaczy PIPA.
- Zaplanowany scraper do cyklicznego sprawdzania cen, stanów magazynowych lub ofert w rozsądnych odstępach — bez bombardowania serwera ciągłymi zapytaniami.
- Bezpłatny eksport danych do Excela, Google Sheets, Airtable i Notion na potrzeby wewnętrznej analityki.
- Scraping podstron do wzbogacania publicznych danych ofertowych (np. przechodzenie do indywidualnych stron produktów po specyfikacje) bez dostępu do obszarów wymagających logowania lub ograniczonych.
- Adaptacja układu przez AI — scraper odczytuje strukturę strony od nowa przy każdym uruchomieniu i dostosowuje się do zmian układu bez kruchego, ręcznie zakodowanego selektora.
Thunderbit obsługuje wiele języków, co ma znaczenie dla zespołów pracujących ze stronami po koreańsku. Możesz wypróbować go za darmo przez rozszerzenie Thunderbit do Chrome.
Żadne narzędzie nie eliminuje ryzyka prawnego. Ale odpowiednia konfiguracja — strony publiczne, dane faktograficzne, wykluczone pola osobowe, rozsądne odstępy — trzyma Cię w ramach zgodności opisanych w tym artykule.
Najważniejsze wnioski o legalności web scrapingu w Korei
Pięć rzeczy, które warto zapamiętać:
- Sama technologia web scrapingu jest w Korei legalna. Sąd Najwyższy potwierdził to w sprawie Yanolja.
- Ryzyko zależy od metody dostępu (brama otwarta vs. zamknięta), rodzaju danych (osobowe vs. faktograficzne) i sposobu użycia (wewnętrzne vs. konkurencyjna redystrybucja).
- Uniewinnienie karne ≠ bezpieczeństwo cywilne. Sprawa Yanolja pokazuje, że można uniknąć ścigania, a mimo to zapłacić odszkodowanie rzędu miliarda wonów.
- Przy scrapowaniu publicznych, nieosobowych, faktograficznych danych do użytku wewnętrznego, bez barier dostępu, zazwyczaj jesteś w bezpiecznej strefie. Ale słowo „zazwyczaj” ma znaczenie — zakres, wolumen i cel są bardzo ważne.
- W przypadku projektów dużej skali lub komercyjnych zawsze skonsultuj się z lokalnym koreańskim prawnikiem. Ten artykuł służy orientacji, a nie poradzie prawnej.
Jeśli chcesz zacząć odpowiedzialnie scrapować koreańskie strony internetowe, darmowy plan Thunderbit pozwoli Ci przetestować proces na małą skalę. Więcej o tym, jak scraping wspierany przez AI działa w praktyce, znajdziesz w naszych poradnikach o AI web scraping oraz web scrapingu bez kodowania. A jeśli chcesz zobaczyć narzędzie w akcji, na naszym kanale YouTube znajdziesz omówienia popularnych zastosowań.
FAQ
1. Czy scrapowanie publicznie dostępnych danych jest legalne w Korei?
Co do zasady tak w ujęciu karnym — zgodnie z orzeczeniem Sądu Najwyższego w sprawie Yanolja dostęp do danych na stronie bez obiektywnych ograniczeń nie narusza ICNA. Nadal jednak może mieć zastosowanie odpowiedzialność cywilna na gruncie UCPA lub Ustawy o prawie autorskim, zależnie od wolumenu, inwestycji źródła i Twojego komercyjnego wykorzystania danych.
2. Czy w Korei mogę zostać pozwany za web scraping, nawet jeśli nie jest to przestępstwo?
Tak. Postępowania karne i cywilne są niezależne. GC Company została uniewinniona ze wszystkich zarzutów karnych, ale nakazano jej zapłatę około 1 mld KRW odszkodowania cywilnego na podstawie ogólnej klauzuli UCPA. Uniewinnienie karne nie chroni przed roszczeniami cywilnymi.
3. Czy naruszenie Warunków korzystania ze strony czyni scraping nielegalnym w Korei?
Koreańskie sądy konsekwentnie uznają, że samo naruszenie ToS nie stanowi przestępstwa na gruncie ICNA — sąd odróżnia ograniczenie użycia (ToS) od ograniczenia dostępu (bariery techniczne). To powiedziawszy, naruszenie ToS może nadal wspierać cywilne roszczenie z tytułu naruszenia umowy lub służyć jako dowód złej wiary w analizie nieuczciwej konkurencji.
4. Jak koreańskie prawo dotyczące scrapingu wypada na tle USA?
Obie jurysdykcje chronią scraping danych publicznych (Yanolja w Korei, hiQ v LinkedIn w USA) i obie uznają, że samo naruszenie ToS nie jest przestępstwem (Van Buren w USA). Kluczowa różnica: Korea ma silniejszą ustawową ochronę baz danych i szerszą ogólną klauzulę nieuczciwej konkurencji niż USA, które nie mają ogólnego federalnego prawa do baz danych. Koreańscy właściciele platform mają więc więcej narzędzi cywilnoprawnych wobec scraperów.
5. Co się stanie, jeśli zeskrobię dane osobowe z koreańskich stron internetowych?
PIPA ma zastosowanie niezależnie od tego, czy informacja jest publicznie widoczna. Zbieranie danych osobowych — imion, numerów telefonów, e-maili — bez zgody lub innej podstawy prawnej stanowi naruszenie. Poprawka do PIPA z 2023 r. wzmocniła te zabezpieczenia, a wytyczne PIPC z 2024 r. dotyczące publicznie dostępnych danych osobowych wprost odnoszą się do web crawlowania i scrapingu. Kary mogą sięgać 5 lat pozbawienia wolności, 50 mln KRW grzywny oraz kar administracyjnych do 3% łącznej sprzedaży.
Wypróbuj Thunderbit do odpowiedzialnego web scrapingu Get Started Free
Dowiedz się więcej




