
Mój panel OpenRouter pokazał 47 dolarów wydane przed lunchem we wtorek. Zrobiłem może kilkanaście zadań programistycznych — nic szalonego, tylko trochę refaktoryzacji i kilka poprawek błędów. Wtedy dotarło do mnie, że domyślne ustawienia OpenClaw po cichu kierowały każdą interakcję, łącznie z pingami heartbeat w tle, do Claude Opus, czyli modelu kosztującego 15+ dolarów za milion tokenów.
Jeśli też przytrafiły Ci się podobne niespodzianki — a sądząc po forach, nie jesteś w tym sam — ten poradnik przeprowadzi Cię przez pełny audyt i optymalizację, dzięki którym obniżyłem miesięczny koszt o około 90%. To nie jest tylko proste „zamień model na tańszy”, ale systematyczne rozłożenie na czynniki pierwsze tego, gdzie naprawdę uciekają tokeny, jak je monitorować, które budżetowe modele sprawdzają się w realnej pracy agentowej oraz trzy gotowe konfiguracje do skopiowania. Całość zajęła mi jedno popołudnie.
Czym jest zużycie tokenów w OpenClaw i dlaczego domyślnie jest tak wysokie?
Tokeny są jednostką rozliczeniową dla każdej interakcji AI w OpenClaw. Najłatwiej myśleć o nich jak o małych kawałkach tekstu — mniej więcej 4 znaki angielskie na token. Każda wysłana wiadomość, każda odebrana odpowiedź, każdy uruchomiony proces w tle — wszystko jest liczone w tokenach.
Problem w tym, że domyślne ustawienia OpenClaw są zoptymalizowane pod maksymalną jakość, a nie pod minimalny koszt. „Out of the box” główny model ustawiony jest na anthropic/claude-opus-4-5 — najdroższą dostępną opcję. Pingi heartbeat? One też lecą na Opus. Sub-agenci uruchamiani do zadań pobocznych? Też Opus. Używanie Opusa do pinga heartbeat to jak zatrudnienie neurochirurga do przyklejenia plastra. Technicznie możliwe, ale absurdalnie drogie.
Większość użytkowników nie zdaje sobie sprawy, że płaci premium za drobne zadania w tle. Domyślna konfiguracja zakłada, że chcesz zawsze najlepszy model do wszystkiego — i wystawia rachunek zgodnie z tym założeniem.
Dlaczego ograniczenie zużycia tokenów w OpenClaw daje więcej niż tylko oszczędność pieniędzy
Najbardziej oczywista korzyść to niższy koszt. Ale są też dodatkowe plusy, które z czasem się kumulują.
Tańsze modele są często szybsze. Gemini 2.5 Flash-Lite działa z prędkością około wobec około 51 w przypadku Opusa — to 4x szybsza odpowiedź przy każdej interakcji. GPT-OSS-120B na Cerebras osiąga , czyli około 35x szybciej niż Opus. W pętli agentowej z 50+ iteracjami wywołań narzędzi taka różnica oznacza zakończenie pracy w kilka minut zamiast czekania na bolesne 13,6 sekundy do pierwszego tokena przy każdym obiegu Opusa.
Zyskujesz też większy zapas zanim trafisz na limity przepustowości, mniej sesji przycinanych przez throttling i przestrzeń do skalowania użycia bez skalowania nerwów związanych z rachunkiem.
Szacowane oszczędności w różnych profilach użycia:
| Profil użytkownika | Szacowany miesięczny koszt (domyślnie) | Po pełnej optymalizacji | Miesięczna oszczędność |
|---|---|---|---|
| Lekki (~10 zapytań/dzień) | ~$100 | ~$12 | ~88% |
| Średni (~50 zapytań/dzień) | ~$500 | ~$90 | ~82% |
| Intensywny (~200+ zapytań/dzień) | ~$1,750 | ~$220 | ~87% |
To nie są teoretyczne liczby. Jeden deweloper opisał zejście z — realne cięcie o 90% — dzięki połączeniu routingu modeli z ukrytymi wyciekami, które opisuję dalej w tym poradniku.
Anatomia zużycia tokenów w OpenClaw: dokąd naprawdę trafia każdy token
To jest fragment, który większość poradników pomija, a właśnie on ma największe znaczenie. Nie da się naprawić czegoś, czego nie widać.
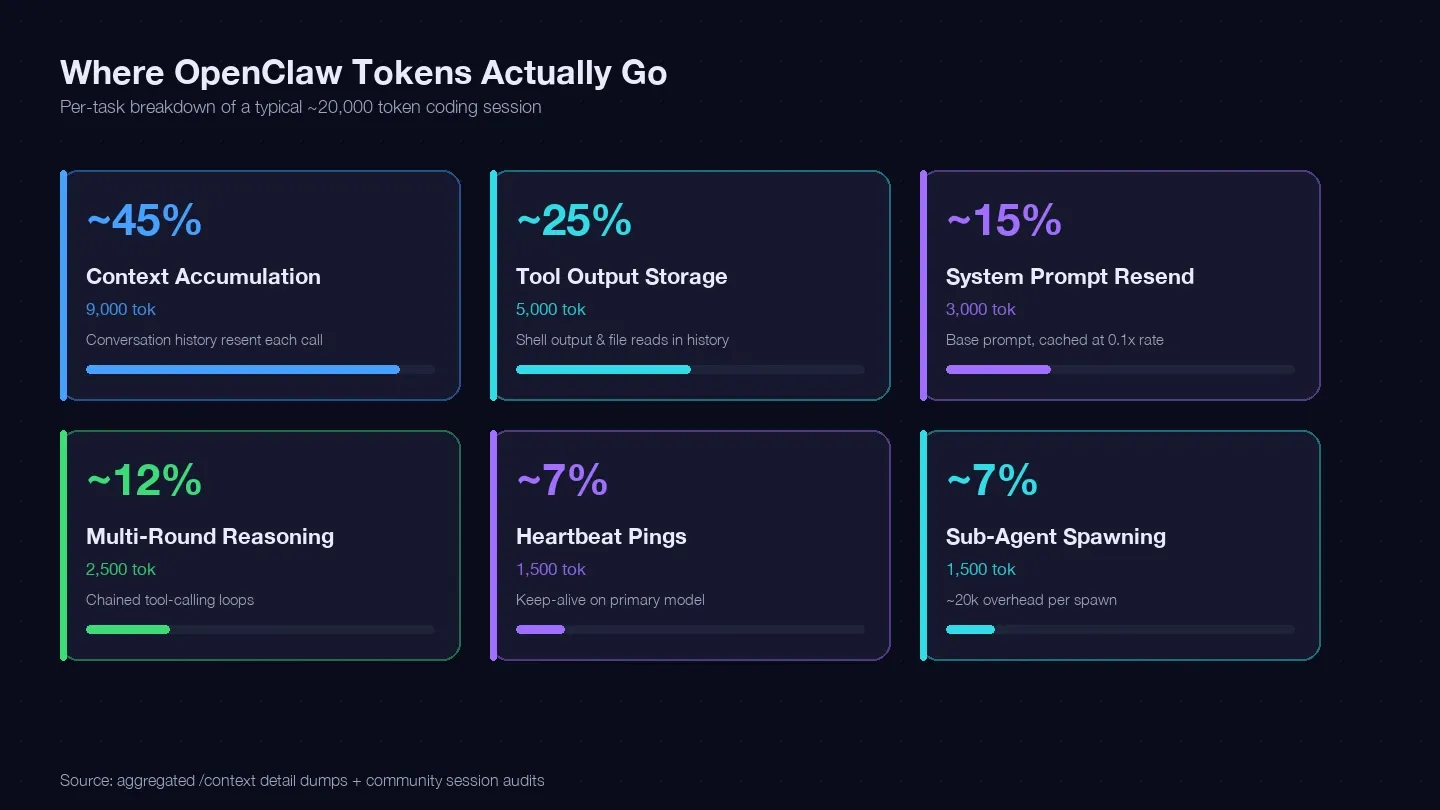
Przeanalizowałem kilka sesji i porównałem je z oraz zrzutami /context ze społeczności, żeby zbudować rejestr tokenów dla typowego pojedynczego zadania programistycznego. Oto, gdzie mniej więcej rozchodzi się około 20 000 tokenów:
| Kategoria tokenów | Typowy % całości | Przykład (1 zadanie programistyczne) | Czy masz nad tym kontrolę? |
|---|---|---|---|
| Akumulacja kontekstu (historia rozmowy dosyłana przy każdym wywołaniu) | ~40–50% | ~9,000 tokenów | Tak — /clear, /compact, krótsze sesje |
| Przechowywanie wyników narzędzi (output z shella, odczyty plików trzymane w historii) | ~20–30% | ~5,000 tokenów | Tak — mniejsze odczyty, węższy zakres narzędzi |
| Ponowne wysyłanie promptu systemowego (~15K bazowo) | ~10–15% | ~3,000 tokenów | Częściowo — odczyty cache po stawce 0.1x |
| Wieloetapowe rozumowanie (łańcuchowe pętle wywołań narzędzi) | ~10–15% | ~2,500 tokenów | Wybór modelu + lepsze prompty |
| Pingi heartbeat / keep-alive | ~5–10% | ~1,500 tokenów | Tak — zmiana konfiguracji |
| Wywołania sub-agentów | ~5–10% | ~1,500 tokenów | Tak — routing modeli |
Największa pozycja — akumulacja kontekstu — to Twoja historia rozmowy wysyłana ponownie przy każdym wywołaniu API. Jeden pokazał 185,400 tokenów tylko w bucketcie Messages, zanim model w ogóle odpowiedział. Prompt systemowy i narzędzia dorzuciły do tego kolejne ~35,800 tokenów stałego narzutu.
Wniosek: jeśli nie czyścisz sesji między niezależnymi zadaniami, płacisz za ponowne przesyłanie całej historii rozmowy przy każdej turze.
Jak monitorować zużycie tokenów w OpenClaw (nie da się ciąć tego, czego nie widać)
Zanim cokolwiek zmienisz, zyskaj wgląd w to, dokąd płyną tokeny. Skakanie od razu do „użyj tańszego modelu” bez monitoringu jest jak próba schudnięcia bez wchodzenia na wagę.
Sprawdź pulpit OpenRouter
Jeśli routujesz przez OpenRouter, strona to najprostszy pulpit bez konfiguracji. Możesz filtrować po modelu, dostawcy, kluczu API i zakresie czasu. Widok Usage Accounting rozbija prompt, completion, reasoning i cached tokens dla każdego żądania. Jest też przycisk Export (CSV lub PDF) do dłuższej analizy.
Na co patrzeć: który model zużył najwięcej tokenów oraz czy pingi heartbeat albo wywołania sub-agentów nie pojawiają się jako zaskakująco duże pozycje.
Przeanalizuj lokalne logi API
OpenClaw przechowuje dane sesji w ~/.openclaw/agents.main/sessions/sessions.json, gdzie znajduje się totalTokens dla każdej sesji. Możesz też uruchomić openclaw logs --follow --json, aby uzyskać logowanie per-request w czasie rzeczywistym.
Jedna ważna uwaga: , więc panel może pokazywać nieaktualne wartości sprzed kompaktacji. Zamiast zapisanych sum ufaj /status oraz /context detail.
Skorzystaj z narzędzi zewnętrznych do monitorowania (dla użytkowników od średniego do intensywnego)
LiteLLM proxy daje endpoint zgodny z OpenAI przed 100+ dostawcami i . Najlepsza funkcja: twarde budżety per klucz, które działają nawet po /clear — niekontrolowany sub-agent nie przebije ustalonego limitu.
Helicone jest jeszcze prostsze — wystarczy , a dostajesz widok Sessions grupujący powiązane żądania. Jeden prompt „napraw ten błąd”, który rozgałęzia się do 8+ wywołań sub-agentów, pojawia się jako jeden wiersz sesji z prawdziwym całkowitym kosztem. .
Szybkie sprawdzenia bezpośrednio w OpenClaw
Do codziennego monitoringu wystarczą cztery komendy w sesji:
/status— pokazuje użycie kontekstu, ostatnie tokeny wejścia/wyjścia, szacunkowy koszt/usage full— stopka użycia dla każdej odpowiedzi/context detail— rozbicie tokenów per plik, per skill, per narzędzie/compact [guidance]— wymusza kompakcję z opcjonalnym stringiem kierunkowym
Uruchom /context detail przed i po zmianach w konfiguracji. Dzięki temu sprawdzisz, czy Twoje optymalizacje rzeczywiście działają.
Pojedynek na najtańszy model w OpenClaw: które budżetowe LLM-y naprawdę radzą sobie z pracą agentową
Wiele poradników myli się właśnie tutaj. Pokazują tabelę cen, wskazują najtańszy wiersz i na tym kończą. Benchmarks nie przewidują realnej wydajności w pracy agentowej — społeczność podkreśla to głośno i wielokrotnie. Jak ujął to jeden użytkownik: „benchmarks w ogóle nie pomagają zrozumieć, który model najlepiej sprawdza się w agentowym AI”.
Kluczowa obserwacja: najtańszy model nie zawsze daje najtańszy efekt końcowy. Model, który się wywala i wymaga czterech prób, kosztuje więcej niż model ze średniej półki, który . W produkcyjnych systemach agentowych zakładaj — a jeśli pięć wywołań LLM jest połączonych w łańcuch i krok czwarty zawiedzie, naiwna ponowna próba uruchomi wszystkie pięć kroków od nowa.
Oto moja macierz możliwości z „Real Agentic Score” opartym na rzeczywistych raportach użytkowników, a nie na syntetycznych benchmarkach:
| Model | Wejście $/1M | Wyjście $/1M | Niezawodność wywołań narzędzi | Rozumowanie wieloetapowe | Real Agentic Score (1–5) | Najlepsze zastosowanie |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Mieszane — sporadyczne pętle | Podstawowe | ⭐2.5 | Pingi heartbeat, proste wyszukiwania |
| GPT-OSS-120B | $0.04 | $0.19 | Wystarczające | Wystarczające | ⭐3.0 | Eksperymenty budżetowe, zadania krytyczne pod kątem szybkości |
| DeepSeek V3.2 | $0.26 | $0.38 | Niespójne (6 otwartych issue) | Dobre | ⭐3.0 | Zadania mocno nastawione na rozumowanie, minimalne wywołania narzędzi |
| Kimi K2.5 | $0.38 | $1.72 | Dobre (przez :exacto) | Wystarczające | ⭐3.5 | Prostsze i średniozaawansowane kodowanie |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | Dobre | Dobre | ⭐4.0 | Codzienny model do ogólnego kodowania |
| Claude Haiku 4.5 | $1.00 | $5.00 | Doskonałe | Dobre | ⭐4.5 | Niezawodny średniopółkowy backup |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Doskonałe | Doskonałe | ⭐5.0 | Złożone zadania wieloetapowe |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | Doskonałe | Doskonałe | ⭐5.0 | Tylko do najtrudniejszych problemów |
Ostrzeżenie dotyczące DeepSeek i Gemini Flash przy wywołaniach narzędzi
DeepSeek V3.2 wygląda świetnie na papierze — 72–74% na , 11–36x taniej niż Sonnet. W praktyce w Cline, Roo Code, Continue i NVIDIA NIM dokumentuje błędne działanie tool calling. Werdykt Composio w bezpośrednim porównaniu: „.” Jednozdaniowy komentarz Zvi Mowshowitza: „.”
Gemini 2.5 Flash ma podobną lukę. Wątek na Google AI Developers Forum zatytułowany „Very frustrating experience with Gemini 2.5 function calling performance” zaczyna się od: „."
OpenRouter zwrócił uwagę na ważny niuans: „.” Jeśli routujesz tanie modele przez OpenRouter, szukaj tagu :exacto — cicha zmiana dostawcy może z dnia na dzień zamienić niezawodny tani model w kosztowną pętlę retry.
Kiedy używać którego modelu
- Gemini Flash-Lite: Pingi heartbeat, keep-alive, proste Q&A. Nigdy do wieloetapowego tool calling.
- MiniMax M2.5/M2.7: Twój codzienny model do ogólnych zadań programistycznych. za ułamek ceny Sonnet.
- Claude Haiku 4.5: Niezawodny fallback, gdy tanie modele nie radzą sobie z wywołaniami narzędzi. Doskonała niezawodność przy około 3x niższej cenie niż Sonnet.
- Claude Sonnet 4.6: Złożona, wieloetapowa praca agentowa. Tu dostajesz realny zwrot z wydanych pieniędzy.
- Claude Opus: Zostaw go do najtrudniejszych problemów. Nie pozwól, by był domyślny do czegokolwiek.
(Ceny modeli zmieniają się często — przed wdrożeniem konfiguracji sprawdź aktualne stawki na albo na stronach bezpośrednich dostawców.)
Ukryte źródła pożerania tokenów, które większość poradników pomija
Użytkownicy na forach zgłaszają, że wyłączenie konkretnych funkcji znacząco obniża koszty, ale żaden poradnik, na który trafiłem, nie daje jednego wspólnego checklistu wszystkich ukrytych drenów i ich realnego wpływu na tokeny. Pełny przegląd:
| Ukryty dren | Koszt tokenowy na wystąpienie | Jak naprawić | Klucz konfiguracji |
|---|---|---|---|
| Domyślny heartbeat na Opus | ~100,000 tokenów/uruchomienie bez izolacji | Nadpisanie na Haiku + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Uruchamianie sub-agentów | ~20,000 tokenów na uruchomienie jeszcze przed rozpoczęciem pracy | Kieruj sub-agentów do Haiku | subagents.model |
| Ładowanie pełnego kontekstu bazy kodu | ~3,000–15,000 tokenów na auto-explore | .clawignore dla node_modules, dist, lockfile’ów | .clawrules + .clawignore |
| Automatyczne podsumowanie pamięci | ~500–2,000 tokenów/sesję | Wyłącz lub zmniejsz częstotliwość | memory: false albo memory.max_context_tokens |
| Akumulacja historii rozmowy | ~500+ tokenów/turę (narastająco) | Zaczynaj nowe sesje między niezależnymi zadaniami | Dyscyplina /clear |
| Narzut narzędzi serwera MCP | ~7,000 tokenów dla 4 serwerów; 50,000+ dla 5+ | Trzymaj MCP minimalnie | Usuń nieużywane MCP |
| Inicjalizacja skilli/pluginów | 200–1,000 tokenów na załadowany skill | Wyłącz nieużywane skille | skills.entries.<name>.enabled: false |
| Agent Teams (tryb planowania) | ~7x standardowy koszt sesji | Używaj tylko do naprawdę równoległej pracy | Preferuj sekwencyjnie |
Osobnego omówienia wymaga dren związany z heartbeat. Domyślnie heartbeat odpala się na głównym modelu (Opus) co 30 minut. Ustawienie isolatedSession: true obniża to z około 100,000 tokenów na uruchomienie — czyli o 95–98% dla tej jednej kategorii.
Trzy szybkie wygrane, które oszczędzają najwięcej tokenów w mniej niż dwie minuty
Wszystkie trzy są bezpieczne i zajmują mniej niż dwie minuty:
-
/clearmiędzy niezależnymi zadaniami (5 sekund). To pojedyncza największa oszczędność tokenów. Konsensus na forach mówi o już samym wyczyszczeniem historii sesji przed nową pracą. Pamiętasz bucket Messages z 185k tokenów z dumpa/context?/cleargo usuwa. -
/model haiku-4.5do prostych zadań (10 sekund). Taktyczne przełączanie modelu daje w rutynowych zadaniach. Haiku bardzo dobrze radzi sobie z większością prostych zadań programistycznych, odczytem plików i wiadomościami commitów. -
Skróć
.clawrulesdo <200 linii + dodaj.clawignore(90 sekund). Plik z regułami ładuje się przy każdej wiadomości. Przy 200 liniach to około 1,500–2,000 tokenów na turę; przy 1,000 liniach robi się to 8,000–10,000 tokenów stałego narzutu każdego requestu. W połączeniu z.clawignore, który wykluczanode_modules/,dist/, pliki lock i wygenerowany kod, jeden deweloper twierdzi, że uzyskał wyłącznie dzięki tej dyscyplinie.
Krok po kroku: trzy gotowe do skopiowania konfiguracje, które drastycznie obniżą zużycie tokenów OpenClaw

Poniżej znajdziesz trzy kompletne, opisane konfiguracje openclaw.json — od „po prostu zacznij oszczędzać” do „pełny stos optymalizacji”. Każda zawiera komentarze w linii i szacunkowe koszty miesięczne.
Zanim zaczniesz:
- Poziom trudności: Początkujący (Config A) → Średni (Config B) → Zaawansowany (Config C)
- Czas potrzebny: ~5 minut dla Config A, ~15 minut dla Config C
- Czego potrzebujesz: zainstalowanego OpenClaw, edytora tekstu, dostępu do
~/.openclaw/openclaw.json
Config A: Początkujący — po prostu oszczędzaj pieniądze
Pięć linii. Zero komplikacji. Zastępuje domyślny model Opus modelem Sonnet, wyłącza narzut pamięci i izoluje heartbeat do Haiku.
1// ~/.openclaw/openclaw.json
2{
3 "agents": {
4 "defaults": {
5 "model": { "primary": "anthropic/claude-sonnet-4-6" }, // zamiast Opus — natychmiastowe oszczędności 3-5x
6 "heartbeat": {
7 "every": "55m", // dopasowanie do 1h cache TTL dla maks. trafień cache
8 "model": "anthropic/claude-haiku-4-5", // Haiku do pingów, nie Opus
9 "isolatedSession": true // ~100k → 2-5k tokenów na uruchomienie
10 }
11 }
12 },
13 "memory": { "enabled": false } // oszczędza ~500-2k tokenów/sesję
14}Co powinieneś zobaczyć po wdrożeniu: Uruchom /status przed i po. Koszt na request powinien zauważalnie spaść, a wpisy heartbeat w panelu OpenRouter Activity powinny pokazywać Haiku zamiast Opusa.
| Poziom użycia | Domyślnie (Opus) | Config A (Sonnet + heartbeat na Haiku) | Oszczędność |
|---|---|---|---|
| Lekki (~10 zapytań/dzień) | ~$100 | ~$35 | 65% |
| Średni (~50 zapytań/dzień) | ~$500 | ~$250 | 50% |
| Intensywny (~200 zapytań/dzień) | ~$1,750 | ~$900 | 49% |
Config B: Średni poziom — inteligentny routing w trzech warstwach
Sonnet jako główny model do prawdziwej pracy. Haiku dla sub-agentów i kompakcji. Gemini Flash-Lite jako budżetowy fallback, gdy Claude jest przeciążony. Łańcuch fallbacków automatycznie obsługuje awarie dostawców.
1{
2 "agents": {
3 "defaults": {
4 "model": {
5 "primary": "anthropic/claude-sonnet-4-6",
6 "fallbacks": [
7 "anthropic/claude-haiku-4-5", // jeśli Sonnet jest limitowany
8 "google/gemini-2.5-flash-lite" // ultra-tani ostatni ratunek
9 ]
10 },
11 "models": {
12 "anthropic/claude-sonnet-4-6": {
13 "params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
14 }
15 },
16 "heartbeat": {
17 "every": "55m", // 55 min < 1h cache TTL = trafienia cache
18 "model": "google/gemini-2.5-flash-lite", // grosze za ping
19 "isolatedSession": true,
20 "lightContext": true // minimalny kontekst w wywołaniach heartbeat
21 },
22 "subagents": {
23 "maxConcurrent": 4, // zamiast domyślnych 8
24 "model": "anthropic/claude-haiku-4-5" // sub-agenci nie potrzebują Sonneta
25 },
26 "compaction": {
27 "mode": "safeguard",
28 "model": "anthropic/claude-haiku-4-5", // podsumowania kompakcji przez Haiku
29 "memoryFlush": { "enabled": true }
30 }
31 }
32 }
33}Oczekiwany efekt: W logach wpisy sub-agentów powinny teraz pokazywać ceny Haiku. Heartbeat powinien kosztować prawie zero. Łańcuch fallbacków oznacza, że awaria Claude nie zatrzyma sesji — płynnie przełączy się na Gemini.
| Poziom użycia | Domyślnie | Config B | Oszczędność |
|---|---|---|---|
| Lekki | ~$100 | ~$20 | 80% |
| Średni | ~$500 | ~$150 | 70% |
| Intensywny | ~$1,750 | ~$500 | 71% |
Config C: Power user — pełny stos optymalizacji
Przypisanie modeli per sub-agent, kompakcja kontekstu przypięta do Haiku, routing vision do Gemini Flash, ciasne .clawrules + .clawignore, wyłączone nieużywane skille. To konfiguracja, która daje oszczędności rzędu 85–90%.
1{
2 "agents": {
3 "defaults": {
4 "workspace": "~/clawd",
5 "model": {
6 "primary": "anthropic/claude-sonnet-4-6",
7 "fallbacks": [
8 "openrouter/anthropic/claude-sonnet-4-6", // inny dostawca jako backup
9 "minimax/minimax-m2-7", // tani fallback do codziennej pracy
10 "anthropic/claude-haiku-4-5" // ostatnia deska ratunku
11 ]
12 },
13 "models": {
14 "anthropic/claude-sonnet-4-6": {
15 "params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
16 },
17 "minimax/minimax-m2-7": {
18 "params": { "maxTokens": 8192 }
19 }
20 },
21 "heartbeat": {
22 "every": "55m",
23 "model": "google/gemini-2.5-flash-lite",
24 "isolatedSession": true,
25 "lightContext": true,
26 "activeHours": "09:00-19:00" // bez heartbeatów w nocy
27 },
28 "subagents": {
29 "maxConcurrent": 4,
30 "model": "anthropic/claude-haiku-4-5"
31 },
32 "contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
33 "compaction": {
34 "mode": "safeguard",
35 "model": "anthropic/claude-haiku-4-5",
36 "identifierPolicy": "strict",
37 "memoryFlush": { "enabled": true }
38 },
39 "bootstrapMaxChars": 12000, // zamiast domyślnych 20000
40 "imageModel": "google/gemini-3-flash" // zadania vision przez tani model
41 }
42 },
43 "memory": { "enabled": true, "max_context_tokens": 800 }, // minimalna pamięć
44 "skills": {
45 "entries": {
46 "web-search": { "enabled": false },
47 "image-generation": { "enabled": false },
48 "audio-transcribe": { "enabled": false }
49 }
50 }
51}Przykład nadpisania dla pojedynczego sub-agenta — wklej do ~/.openclaw/agents/lint-runner/SOUL.md:
1---
2name: lint-runner
3description: Uruchamia lint/format i wprowadza drobne poprawki
4tools: [Bash, Read, Edit]
5model: anthropic/claude-haiku-4-5
6---Minimalny .clawignore, od którego warto zacząć — sam w sobie obcina typowe bootstraps z 150k znaków do około 30–50k:
1node_modules/
2dist/
3build/
4.next/
5coverage/
6.venv/
7vendor/
8*.lock
9package-lock.json
10yarn.lock
11pnpm-lock.yaml
12*.min.js
13*.min.css
14**/__snapshots__/
15**/*.snap| Poziom użycia | Domyślnie | Config C | Oszczędność |
|---|---|---|---|
| Lekki | ~$100 | ~$12 | 88% |
| Średni | ~$500 | ~$90 | 82% |
| Intensywny | ~$1,750 | ~$220 | 87% |
Te liczby zgadzają się z dwoma niezależnymi raportami rzeczywistych użytkowników: z dokumentacją Praney Behl o przejściu z (cięcie o 90%) oraz z case studies LaoZhang pokazującymi przy częściowej optymalizacji.
Jak używać komendy /model, by na bieżąco kontrolować zużycie tokenów w OpenClaw
Komenda /model przełącza aktywny model na następną turę, zachowując kontekst rozmowy — bez resetu i bez utraty historii. To codzienny nawyk, który z czasem kumuluje oszczędności.
Praktyczny workflow:
- Pracujesz nad trudnym refaktorem obejmującym wiele plików? Zostań na Sonnet.
- Szybkie pytanie „co robi ten regex?”?
/model haiku, zadaj pytanie, potem/model sonnet, żeby wrócić. - Wiadomość do commita albo dopracowanie dokumentacji?
/model flash-litei gotowe.
Możesz ustawić aliasy w openclaw.json w sekcji commands.aliases, aby mapować krótkie nazwy (haiku, sonnet, opus, flash) na pełne stringi dostawców. Oszczędza to kilka kliknięć przy każdej zmianie.
Matematyka: 50 zapytań dziennie na Sonnet to około 3 dolarów dziennie. Te same 50 zapytań rozłożone w 70/20/10 na Haiku/Sonnet/Opus to około 1,10 dolara dziennie. W skali miesiąca daje to $90 → $33 — 63% taniej bez zmiany narzędzi, tylko nawyków.
Bonus: śledzenie cen modeli OpenClaw u różnych dostawców z Thunderbit
Przy tak dużej liczbie modeli i dostawców — OpenRouter, bezpośrednie API Anthropic, Google AI Studio, DeepSeek, MiniMax — ceny zmieniają się bardzo często. Anthropic obniżył cenę wyjściową Opusa o około 67% z dnia na dzień. Google w grudniu 2025 przyciął limity darmowego planu Gemini . Ręczne utrzymywanie statycznego arkusza cenowego w aktualności to przegrana bitwa.
rozwiązuje to bez pisania ani jednej linijki scrapingu. To AI web scraper stworzone dokładnie do tego typu strukturalnej ekstrakcji danych.
Mój workflow:
- Otwórz stronę modeli OpenRouter w Chrome i kliknij w Thunderbit „AI Suggest Fields”. Narzędzie odczytuje stronę i proponuje kolumny — nazwę modelu, cenę wejściową, cenę wyjściową, okno kontekstu, dostawcę.
- Kliknij Scrape, a następnie wyeksportuj dane bezpośrednio do Google Sheets.
- Ustaw zaplanowany scraping prostym językiem — „w każdy poniedziałek o 9:00 ponownie zeskanuj listę modeli OpenRouter” — a całość uruchomi się automatycznie w chmurze.
Od tego momentu Twój osobisty tracker cen aktualizuje się sam. Każdy model, który nagle tanieje o 30% — albo dostawca, który dostaje tag Exacto — pojawi się w poniedziałkowym arkuszu bez żadnego ręcznego działania. Więcej pisaliśmy o na naszym blogu.
Porównujesz ceny między bezpośrednimi stronami dostawców (Anthropic, Google, DeepSeek)? Scrapowanie podstron w Thunderbit podąża za linkiem każdego modelu na jego stronę szczegółową i pobiera stawki per dostawca — przydatne, gdy chcesz sprawdzić, czy routing Kimi K2.5 przez OpenRouter jest tańszy niż bezpośrednio przez . Sprawdź , aby poznać darmowy plan i szczegóły pakietów.
Najważniejsze wnioski dotyczące ograniczania zużycia tokenów w OpenClaw
Schemat jest prosty: Zrozum → Monitoruj → Routuj → Optymalizuj.
Najbardziej wpływowe działania, uszeregowane:
- Nie ustawiaj Opusa jako domyślnego. Zmień model główny na Sonnet lub MiniMax M2.7. Sam ten krok daje 3–5x redukcję kosztów.
- Izoluj heartbeat. Ustaw
isolatedSession: truei kieruj heartbeat do Gemini Flash-Lite. To zmienia dren ~100k tokenów w ~2–5k. - Kieruj sub-agentów do Haiku. Każde uruchomienie ładuje około 20k tokenów kontekstu, zanim wykona jakąkolwiek pracę. Nie pozwól, żeby działo się to na Opusie.
- Stosuj
/clearbez wyjątku. Jest darmowe, zajmuje 5 sekund i według społeczności oszczędza więcej niż jakakolwiek inna pojedyncza czynność. - Dodaj
.clawignore. Wykluczenienode_modules, lockfile’i i artefaktów builda radykalnie zmniejsza bootstrap context. - Monitoruj przez
/context detailprzed i po zmianach. Jeśli nie możesz czegoś zmierzyć, nie możesz tego poprawić.
Najtańszy model zależy od zadania. Gemini Flash-Lite do heartbeatów. MiniMax M2.7 do codziennego kodowania. Haiku do niezawodnych wywołań narzędzi. Sonnet do złożonych, wieloetapowych zadań. Opus tylko do naprawdę najtrudniejszych problemów — i niczego więcej.
Większość czytelników może zobaczyć 50–70% oszczędności już jednego popołudnia dzięki Config A lub B. Pełne 85–90% wymaga połączenia wszystkich elementów — routingu modeli, usunięcia ukrytych drenów, .clawignore, dyscypliny sesji — ale to jest osiągalne i działa trwale.
FAQ
1. Ile kosztuje OpenClaw miesięcznie?
To zależy wyłącznie od konfiguracji, skali użycia i wyboru modeli. Lekcy użytkownicy (~10 zapytań/dzień) zwykle wydają $5–30/mies. po optymalizacji albo $100+ na ustawieniach domyślnych. Użytkownicy średni (~50 zapytań/dzień) mieszczą się zwykle w zakresie $90–400/mies. Intensywni użytkownicy mogą dochodzić do na domyślnych ustawieniach — jednym z dokumentowanych ekstremów było $5,623 w jednym miesiącu. Wewnętrzna telemetria Anthropic sugeruje medianę na poziomie .
2. Jaki jest najtańszy model OpenClaw, który nadal dobrze radzi sobie z kodowaniem?
to najlepszy ogólny model do codziennej pracy — dobra niezawodność wywołań narzędzi, SWE-Pro 56.22, przy około $0.28/$1.10 za milion tokenów. Do heartbeatów i prostych wyszukiwań trudno pobić Gemini 2.5 Flash-Lite za $0.10/$0.40. Claude Haiku 4.5 za $1/$5 to niezawodny fallback średniej klasy, gdy potrzebujesz świetnych wywołań narzędzi bez płacenia cen Sonneta.
3. Czy mogę używać modeli z darmowego planu w OpenClaw?
Technicznie tak. GPT-OSS-120B jest darmowy na tagu :free w OpenRouter i w NVIDIA Build. Gemini Flash-Lite ma darmowy plan (15 RPM, 1,000 requestów/dzień). DeepSeek daje . Ale darmowe plany mają agresywne limity, wolniejsze działanie i mniej stabilną dostępność. Tanie płatne modele — grosze za milion tokenów — są znacznie pewniejsze przy regularnym użyciu.
4. Czy przełączanie modeli w trakcie rozmowy przez /model powoduje utratę kontekstu?
Nie. /model zachowuje pełny kontekst sesji — następna tura trafia do nowego modelu z całą historią rozmowy. Potwierdza to dokumentacja konceptów OpenClaw i działa tak samo w Claude Code. Możesz swobodnie przechodzić między Haiku do szybkich pytań a Sonnet do złożonych zadań bez utraty czegokolwiek.
5. Jaki jest najszybszy sposób na zmniejszenie rachunku za OpenClaw już dziś?
Wpisuj /clear między niezależnymi zadaniami. To darmowe, zajmuje pięć sekund i usuwa historię rozmowy, która jest ponownie wysyłana przy każdym wywołaniu API. Jedna rzeczywista sesja pokazała nagromadzonej historii wiadomości — wszystko to było retransmitowane i ponownie rozliczane przy każdej turze. Wyczyszczenie tego przed rozpoczęciem nowej pracy to nawyk o najwyższym zwrocie z inwestycji, jaki możesz wyrobić.