

Optymalizacja zapytań do list Apollo to nie tylko techniczna zabawa — to wręcz umiejętność przetrwania dla każdego, kto opiera się na newsach w czasie rzeczywistym, automatycznym pozyskiwaniu informacji z wiadomości albo szybkim działaniu zespołów sprzedaży i operacji. Widziałem na własne oczy, jak powolne zapytanie do listy potrafi zamienić dopracowany dashboard w wąskie gardło, zostawiając zespoły sprzedaży z kręcącymi się loaderami, a ludzi z operacji — z desperackimi obejściami w arkuszach kalkulacyjnych. W świecie, w którym 60% czasu przedstawicieli handlowych już teraz pochłaniają zadania niezwiązane ze sprzedażą, liczy się każda milisekunda.
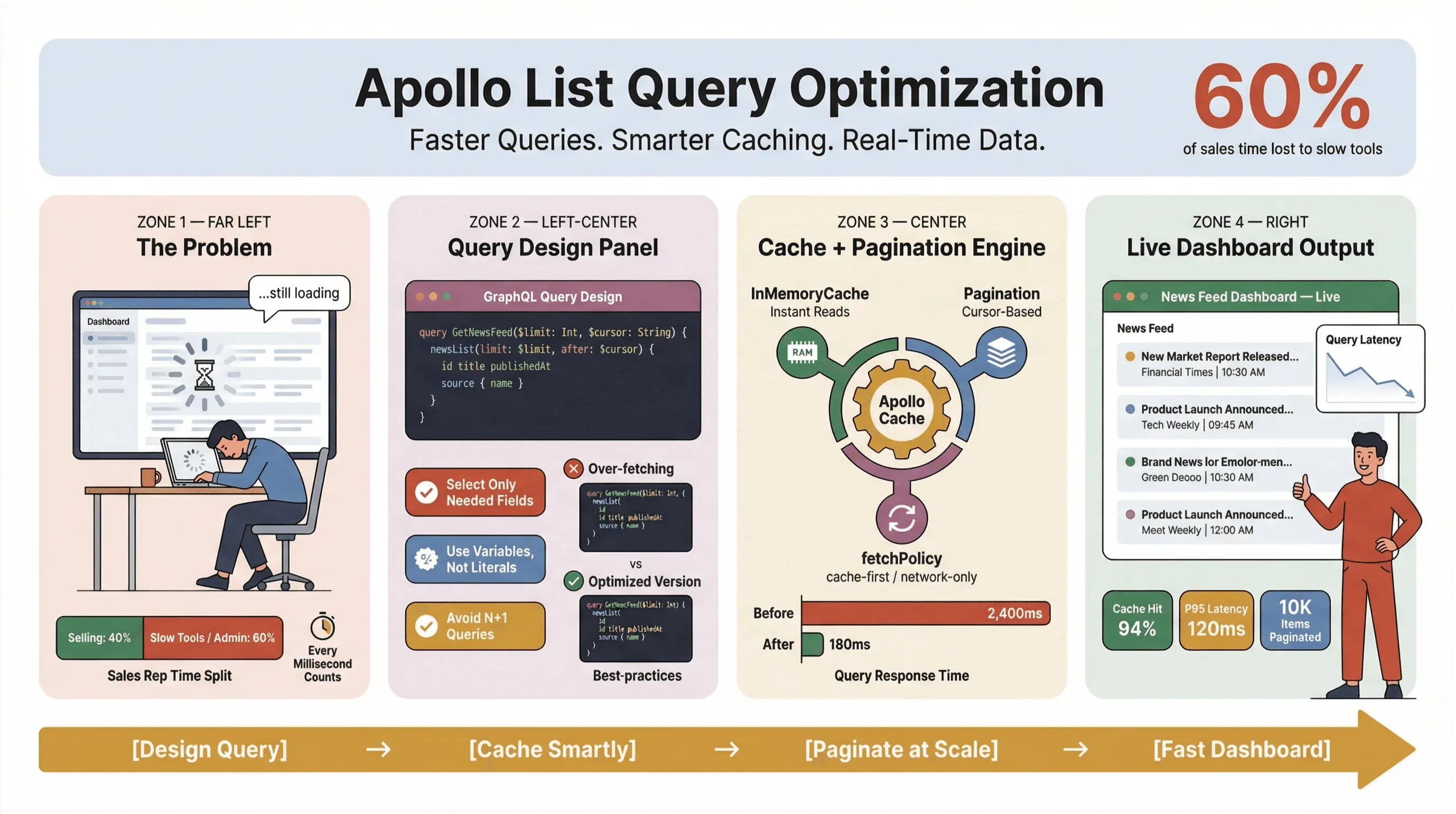
Jak więc sprawić, by zapytania list Apollo Client były szybkie, niezawodne i spójne na dużą skalę — zwłaszcza gdy chodzi o scrapowanie wiadomości, śledzenie leadów albo obsługę kluczowych dashboardów? W tym przewodniku pokażę praktyki, które naprawdę działają w produkcji: projektowanie zapytań, cache, paginację oraz integrację narzędzi no-code, takich jak Thunderbit, żeby zautomatyzować żmudne zadania związane z pozyskiwaniem newsów.
--- Niezależnie od tego, czy jesteś developerem, product managerem, czy po prostu osobą, którą wszyscy obwiniają, gdy dashboard działa wolno — to jest Twój playbook dotyczący wydajności list Apollo GraphQL.
Wypróbuj Thunderbit do automatycznego pozyskiwania wiadomości
Dlaczego warto optymalizować zapytania do list Apollo? (wydajność list Apollo Client, optymalizacja zapytań do list Apollo)
Bądźmy szczerzy: nikt nie chce czekać na załadowanie nagłówków wiadomości czy leadów sprzedażowych. W środowisku biznesowym — szczególnie tam, gdzie liczy się automatyczne pozyskiwanie wiadomości albo dane w czasie rzeczywistym — wolne zapytania do list Apollo nie tylko irytują użytkowników; one kosztują pieniądze, opóźniają decyzje i pchają ludzi z powrotem do ręcznej roboty. Powtarzające się badania Slack Workforce Lab konsekwentnie pokazują, że pracownicy biurowi spędzają około jednej trzeciej — a w nowszych raportach bliżej 40% — dnia na powtarzalnych, mało wartościowych zadaniach, często dlatego, że narzędzia rozbijają pracę między wolne interfejsy.
Tak wygląda sytuacja, gdy zapytania list nie są zoptymalizowane:
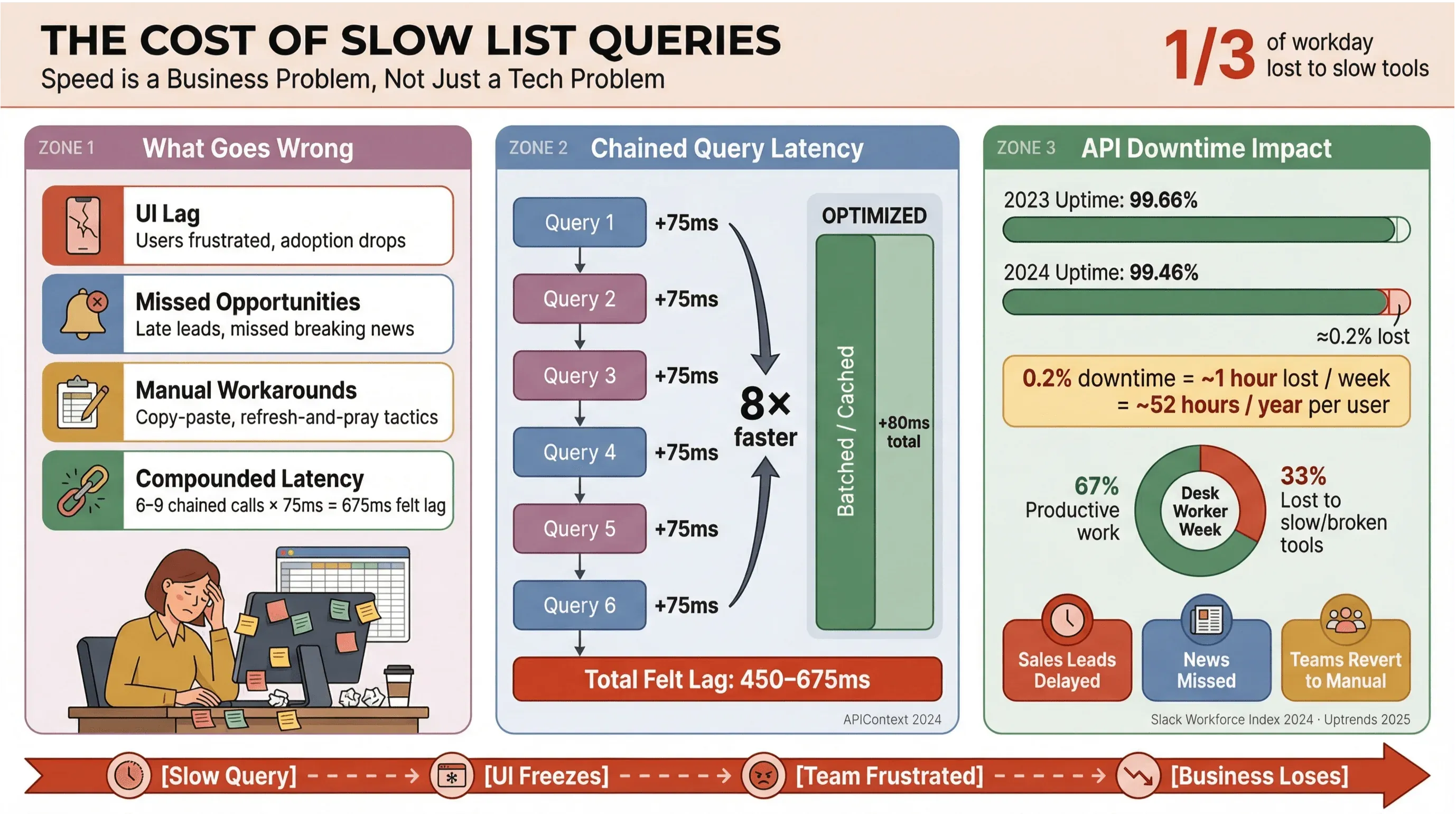
- Zacinający się interfejs: Użytkownicy czują opóźnienia, co kończy się frustracją i mniejszym wykorzystaniem produktu.
- Przegapione okazje: W sprzedaży lub monitoringu newsów nawet kilka sekund zwłoki może oznaczać utratę gorącego leada albo najświeższego newsa.
- Ręczne obejścia: Zespoły wracają do kopiowania i wklejania, arkuszy kalkulacyjnych albo strategii „odśwież i módl się”.
- Skumulowane opóźnienia: Każde wolne wywołanie API się sumuje — jeśli Twój workflow uruchamia 6–9 zależnych zapytań, umiarkowane opóźnienie 75 ms na jedno wywołanie może urosnąć do odczuwalnego laga rzędu 450–675 ms (APIContext).
I nie chodzi tylko o szybkość. Przestoje API rosną, a średni uptime spadł z 99,66% do 99,46% w zaledwie rok — co przekłada się na prawie godzinę utraconej produktywności tygodniowo w aplikacjach opartych na dużej liczbie list. Gdy Twoja firma zależy od danych newsowych w czasie rzeczywistym, to ryzyko, na które nie możesz sobie pozwolić.
Wybór właściwej struktury danych i pól (najlepsze praktyki dla list Apollo GraphQL)
Jednym z najczęstszych błędów, jakie widzę — i sam też go popełniałem — jest traktowanie każdego zapytania listy jak zapytania szczegółowego. W GraphQL masz możliwość pobrania dokładnie tego, czego potrzebujesz — więc z tego korzystaj. Nadmierne pobieranie danych to wróg wydajności, zwłaszcza w narzędziach do scrapowania newsów i dashboardach czasu rzeczywistego.
Dobór pól do automatycznego pozyskiwania wiadomości
Załóżmy, że budujesz feed newsowy. Czy naprawdę potrzebujesz pełnej treści artykułu, wszystkich tagów, komentarzy i bio autora w zapytaniu listy? Najpewniej nie. Oto różnica:
Wydajne zapytanie listy:
query NewsFeed($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
cursor
node {
id
title
url
sourceName
publishedAt
}
}
pageInfo { endCursor hasNextPage }
}
}
Nieefektywne zapytanie listy (tak nie rób):
query NewsFeedTooHeavy($after: String, $first: Int) {
newsFeed(after: $after, first: $first) {
edges {
node {
id title url publishedAt
fullText
summary
entities { ... }
relatedArticles { ... }
}
}
}
}
Pierwsze zapytanie jest lekkie i zwinne — idealne do sortowania, filtrowania i renderowania wierszy. Drugie? To zapytanie szczegółowe przebrane za listę, które pobiera ogromne ładunki danych i spowalnia wszystko (specyfikacja GraphQL, najlepsze praktyki Apollo).
Pro tip: Zastosuj podejście dwupoziomowe — w liście pobieraj tylko lekkie pola, a ciężkie dane (jak pełny tekst czy wzbogacenie NLP) ładuj dopiero wtedy, gdy użytkownik otworzy element albo najedzie na niego kursorem.
Jak wykorzystać cache Apollo Client, aby przyspieszyć zapytania (wydajność list Apollo Client)
Cache Apollo Client to najważniejsza dźwignia, jaką masz w kontekście wydajności zapytań listowych. Gdy jest dobrze skonfigurowany, pozwala:
- Natychmiast serwować powtarzalne zapytania (bez kolejnych rund do sieci)
- Zmniejszyć obciążenie serwera i koszty API
- Ułatwić płynne przechodzenie wstecz/do przodu oraz zmianę filtrów
Ale cache nie działa magicznie — wymaga odpowiedniej konfiguracji i dyscypliny.
Ustawianie skutecznych polityk cache
Apollo obsługuje kilka fetch policies:
| Polityka | Co robi | Najlepsze zastosowanie dla list newsów |
|---|---|---|
| cache-first | Czyta z cache, a z sieci pobiera tylko gdy brakuje danych | Powrót do list, zmiana filtrów, nawigacja wstecz/do przodu |
| network-only | Zawsze pobiera z sieci | Ręczne odświeżanie, „najnowsze nagłówki” |
| cache-and-network | Najpierw zwraca cache, potem aktualizuje odpowiedzią z sieci | Szybki pierwszy render + aktualizacja w tle (świetne dla feedów newsowych) |
| no-cache | Zawsze pobiera, nigdy nie zapisuje do cache | Jednorazowe, wrażliwe zapytania (rzadkie w listach) |
Dla danych newsowych w czasie rzeczywistym lubię cache-and-network — daje użytkownikom natychmiastowe wyniki, a potem aktualizuje wszystko w tle. Trzeba tylko uważać na migotanie interfejsu, jeśli dane zmieniają kolejność po odświeżeniu (GitHub issue).
Wskazówki dotyczące konfiguracji cache:
- Używaj stabilnych identyfikatorów (
idalbo_id) do normalizacji (dokumentacja cache Apollo). - Dostosuj rozmiar cache i garbage collection dla dużych list (zarządzanie pamięcią).
- Unikaj trzymania ogromnych, nienormalizowanych blobów pod
ROOT_QUERY— może to spowalniać aplikację (zgłoszenie społeczności).
Implementacja paginacji i ograniczanie liczby elementów (najlepsze praktyki dla list Apollo GraphQL)
Jeśli ładujesz setki albo tysiące artykułów newsowych lub leadów sprzedażowych naraz, sam prosisz się o kłopoty. Paginacja to nie tylko funkcja UX — to konieczność wydajnościowa.
Apollo wspiera zarówno paginację offset-based, jak i cursor-based. Oto porównanie:
| Typ paginacji | Zalety | Wady | Najlepsze dla |
|---|---|---|---|
| Offset-based | Prosta, łatwa do wdrożenia | Może pomijać lub duplikować elementy, gdy dane się zmieniają | Niewielkie lub statyczne listy |
| Cursor-based | Stabilna, dobrze radzi sobie ze zmianami danych | Nieco bardziej złożona | Feed newsowy, duże listy |
W większości list newsowych lub leadów działających w czasie rzeczywistym cursor-based pagination to najlepszy wybór. Utrzymuje spójność danych nawet wtedy, gdy pojawiają się nowe wpisy albo stare są usuwane (GraphQL Foundation).
Wskazówki dotyczące paginacji w Apollo:
- Skonfiguruj
keyArgs, aby kontrolować klucze cache dla pól stronicowanych (dokumentacja). - Dodaj funkcję
merge, aby łączyć strony w cache. - Używaj
fetchMore, aby pobierać kolejne strony bez nadpisywania wcześniejszych wyników.
Praktyczne wzorce paginacji dla narzędzi do scrapowania newsów
Typowy interfejs do scrapowania wiadomości będzie:
- Pokazywać 20–50 najnowszych nagłówków (tylko lekkie pola)
- Ładować kolejne wyniki przy przewijaniu albo kliknięciu „następna strona”
- Pobierać szczegóły tylko wtedy, gdy są potrzebne
To sprawia, że interfejs działa szybko, API nie jest przeciążone, a użytkownicy pozostają produktywni.
Integracja Thunderbit do automatycznego pozyskiwania wiadomości
Teraz porozmawiajmy o oczywistej sprawie: skąd właściwie brać te wszystkie uporządkowane dane newsowe? Właśnie tutaj pojawia się Thunderbit.
Pobierz rozszerzenie Thunderbit do Chrome Get Started Free
Thunderbit to bezkodowe, oparte na AI rozszerzenie Chrome do web scrapingu, które potrafi wyodrębniać nagłówki newsów, adresy URL, źródła, autorów, daty publikacji, streszczenia i obrazy praktycznie z każdej strony — bez konieczności pisania kodu. Widziałem zespoły, które używały Thunderbit do zautomatyzowania całego procesu pozyskiwania wiadomości, zamieniając nieustrukturyzowane strony w czyste, uporządkowane dane, gotowe do wprowadzenia do bazy danych albo GraphQL API.
Łączenie Thunderbit z Apollo dla danych newsowych w czasie rzeczywistym
Oto workflow, który szczególnie lubię dla zespołów sprzedaży i operacji potrzebujących aktualnych newsów:
- Warstwa ekstrakcji: użyj szablonu News Scraper w Thunderbit, aby cyklicznie pobierać uporządkowane dane newsowe z wybranych stron.
- Warstwa przechowywania: zapisz zeskrobane dane w bazie zoptymalizowanej pod szybkie odczyty.
- Warstwa GraphQL: wystaw przez API pole listy
newsFeedoraz szczegółowe polenewsArticle(id). - Warstwa klienta: użyj Apollo Client do pobierania listy (lekkie pola, z paginacją), a szczegóły ładuj tylko w razie potrzeby.
Ten pipeline „scrape → store → query” sprawia, że zapytania Apollo zawsze pracują na świeżych, uporządkowanych danych — bez ręcznego kopiowania i wklejania czy kruchych skryptów.
Bonus: Thunderbit może też wzbogacać listy o dodatkowe pola, takie jak sentyment czy kategoria, dzięki sugestiom pól opartym na AI, co czyni Twój feed newsowy jeszcze inteligentniejszym.
Przewodnik krok po kroku: optymalizacja zapytań do list Apollo
Gotowy, by wdrożyć to w praktyce? Oto moja sprawdzona checklista optymalizacji zapytań list Apollo:
-
Ogranicz rozmiar zapytań
- Pobieraj tylko pola potrzebne do wyrenderowania listy (tytuł, URL, znacznik czasu itp.).
- Ciężkie pola (pełny tekst, obrazy, wzbogacenie) przenieś do zapytań szczegółowych.
-
Wprowadź paginację
- Dla dużych lub dynamicznych list używaj paginacji cursor-based.
- Skonfiguruj
keyArgsi funkcjemerge, aby cache działał poprawnie.
-
Wykorzystaj cache Apollo
- Normalizuj encje przy użyciu stabilnych ID.
- Wybierz odpowiednią politykę pobierania danych (
cache-and-networkświetnie sprawdza się dla newsów). - Dopasuj rozmiar cache i garbage collection do wolumenu danych.
-
Zintegruj automatyczną ekstrakcję
- Użyj Thunderbit do automatyzacji scrapowania newsów i utrzymywania świeżych danych.
- Eksportuj uporządkowane dane bezpośrednio do bazy danych lub arkusza kalkulacyjnego.
-
Monitoruj i rozwiązuj problemy
- Korzystaj z Apollo Client Devtools, aby analizować zapytania, cache i wydajność.
- Zwracaj uwagę na duże zapisy do cache, nadmiar obserwowanych zapytań i zacinanie UI.
- Śledź opóźnienia p95/p99 i współczynniki błędów (New Relic, Uptrends).
Monitorowanie i diagnozowanie wydajności zapytań
Devtools Apollo to w tym przypadku prawdziwy ratunek. Możesz:
- Sprawdzać aktywne zapytania i stan cache
- Wykrywać duplikaty zapytań lub nadmierną liczbę watcherów
- Identyfikować duże blob-y cache albo problemy z normalizacją
Jeśli widzisz lag interfejsu albo wolne aktualizacje, sprawdź:
- Zbyt duże zapytania listowe (zmniejsz ich zakres)
- Słabą normalizację cache (napraw ID)
- Problemy z łączeniem stron paginacji (przejrzyj
keyArgsimerge)
I nie zapominaj o mierzeniu tail latency — nie tylko średnich. To właśnie tam kryje się prawdziwy ból użytkownika.
Porównanie tradycyjnych i AI-sterowanych metod scrapowania newsów
Powiedzmy sobie szczerze: kiedyś scrapowanie danych newsowych oznaczało pisanie własnych skryptów, walkę z headless browserami i modlitwę, żeby układ strony nie zmienił się z dnia na dzień. Dziś dzięki narzędziom opartym na AI, takim jak Thunderbit, możesz zautomatyzować cały proces — bez kodu, bez dramatu.
| Podejście | Mocne strony | Ograniczenia dla użytkowników biznesowych |
|---|---|---|
| Scrapowanie skryptowe | W pełni konfigurowalne, tanie przy dużej skali | Wymaga utrzymania, potrzebny czas inżynierów |
| Zarządzane platformy scrapingowe | Szybki start, odciążają z obsługi anty-botów | Nadal wymagają konfiguracji, koszty rosną wraz z użyciem |
| Ekstrakcja oparta na AI (Thunderbit) | Radzi sobie z chaotycznymi układami, nie wymaga kodu | Wynik wymaga kontroli jakości, integracji ze schematem |
| No-code visual scrapers | Dostępne dla osób nietechnicznych | Mogą się psuć przy zmianach UI, ograniczona skala |
| Infrastruktura proxy/unlocker | Obejmuje blokady, wspiera wysoki throughput | Nadal potrzebna logika ekstrakcji, ryzyka zgodności |
Uwaga prawna: Scrapowanie publicznie dostępnych danych jest zazwyczaj legalne, ale zawsze należy respektować regulaminy usług i limity zapytań (Reuters).
Najważniejsze wnioski dotyczące najlepszych praktyk dla list Apollo GraphQL
Podsumujmy najważniejsze rzeczy:
- Optymalizuj pod kątem szybkości i przejrzystości: odchudzaj zapytania listowe, stosuj paginację i agresywnie wykorzystuj cache.
- Struktura ma znaczenie: pobieraj tylko to, czego potrzebujesz — cięższe pola przenieś do zapytań szczegółowych.
- Cache to Twój sprzymierzeniec: korzystaj z normalizacji i fetch policies Apollo, aby serwować dane natychmiast.
- Automatyzuj pozyskiwanie danych: narzędzia takie jak Thunderbit sprawiają, że scrapowanie newsów i wzbogacanie list staje się dostępne dla każdego.
- Monitoruj i ulepszaj: używaj Devtools i dashboardów obserwowalności, aby wcześnie wykrywać wąskie gardła.
Dla zespołów sprzedaży, operacji i newsowych takie praktyki oznaczają mniej czekania, więcej działania — i znacznie mniej wiadomości na Slacku w stylu „dlaczego to działa tak wolno?”.
Zakończenie: kolejne kroki w optymalizacji zapytań do list Apollo
Jeśli nadal korzystasz z ciężkich, niepaginowanych albo nieprzyjaznych dla cache zapytań listowych, to najwyższy czas je przeanalizować i zmodernizować. Zacznij od małych kroków: ogranicz pola, dodaj paginację i dostrój cache. Potem wejdź poziom wyżej, integrując narzędzia do automatycznej ekstrakcji, takie jak Thunderbit, aby Twoje dane były zawsze świeże i gotowe do działania.
Chcesz wejść głębiej? Sprawdź dokumentację Apollo, blog Thunderbit albo dołącz do Apollo Community, żeby znaleźć praktyczne wskazówki i rozwiązania problemów. A jeśli chcesz od razu zautomatyzować pozyskiwanie newsów, wypróbuj szablon News Scraper od Thunderbit — to prawdziwy game changer dla każdego, kto potrzebuje danych w czasie rzeczywistym bez zbędnych komplikacji.
Użyj szablonu Thunderbit News Scraper
Jeśli po przeczytaniu tego zrobisz tylko jedną rzecz: skróć listę pobieranych pól, dodaj paginację cursor-based i wybierz sensowną politykę pobierania danych. Same te trzy zmiany zwykle zamieniają zauważalne opóźnienie zapytania listy w coś praktycznie niewyczuwalnego — i pozwalają Ci skupić się na danych, a nie na stanie ładowania.
FAQ
1. Dlaczego zapytania list Apollo zwalniają w dashboardach newsowych lub sprzedażowych działających w czasie rzeczywistym?
Zapytania list mogą działać wolno, jeśli pobierają zbyt dużo danych, nie mają paginacji albo nie są poprawnie cache’owane. W workflow o wysokiej częstotliwości, takich jak monitoring newsów, nawet niewielkie opóźnienia się kumulują, prowadząc do laga interfejsu i utraty produktywności.
2. Jaki jest najlepszy sposób strukturyzowania zapytań list Apollo do automatycznego pozyskiwania wiadomości?
Pobieraj tylko pola potrzebne do wyrenderowania listy (np. tytuł, URL, znacznik czasu). Cięższe pola, takie jak pełna treść artykułu czy obrazy, przenieś do zapytań szczegółowych, a wyniki dziel na strony, aby payload był mały i szybki.
3. W jaki sposób cache Apollo Client poprawia wydajność list?
Cache Apollo przechowuje wcześniej pobrane dane, dzięki czemu powtarzalne zapytania mogą zwracać wyniki natychmiast. Właściwa normalizacja cache i fetch policies, takie jak cache-and-network, potrafią znacząco przyspieszyć widoki list i zmniejszyć obciążenie serwera.
4. Jak Thunderbit może pomóc w scrapowaniu newsów i integracji z Apollo?
Thunderbit to bezkodowy AI web scraper, który wyodrębnia uporządkowane dane newsowe z dowolnej strony. Możesz użyć go do automatyzacji pozyskiwania wiadomości, a następnie przekazać te dane do bazy lub GraphQL API do wykorzystania w Apollo Client.
5. Jakich narzędzi użyć do monitorowania i diagnozowania wydajności zapytań list Apollo?
Apollo Client Devtools pozwala analizować zapytania, stan cache i wydajność w czasie rzeczywistym. Połącz to z dashboardami obserwowalności, takimi jak New Relic czy Uptrends, aby śledzić opóźnienia i błędy, a następnie iteracyjnie ulepszaj projekt zapytań dla najlepszych rezultatów.
Chcesz więcej wskazówek o web scrapingu, automatyzacji i workflowach danych w czasie rzeczywistym? Sprawdź blog Thunderbit, gdzie znajdziesz pogłębione analizy, poradniki i najnowsze informacje o produktywności wspieranej przez AI.
Wypróbuj Thunderbit AI Web Scraper Get Started Free
Dowiedz się więcej
- Jak zoptymalizować listy Apollo, aby skuteczniej zarządzać leadami
- Apollo Data Enrichment: funkcje, korzyści i wzmocnienie AI
- Jak opanować prospecting w Apollo: przewodnik krok po kroku
- Jak używać paginacji w web scraperze do wydajnej ekstrakcji
- Jak używać paginacji w web scraperze do wydajnej ekstrakcji




