

Pozwól, że powiem to wprost: niewiele rzeczy w cyfrowym świecie daje tak dziwną satysfakcję jak widok uporządkowanej, kompletnej listy wszystkich stron witryny — trochę jak odnalezienie wszystkich skarpet po praniu. Ale jeśli kiedykolwiek próbowałeś zebrać listę stron serwisu na potrzeby audytu treści, migracji albo po prostu po to, by sprawdzić, co kryje się w cyfrowej piwnicy, wiesz, że rzadko bywa to tak proste, jak brzmi. Widziałem zespoły, które spędzały godziny, a nawet dni, sklejając listy z map witryny, wyników Google i eksportów z CMS, a potem odkrywały, że nadal brakuje im ukrytych albo dynamicznych stron. A już nie każcie mi zaczynać opowieści o tym, jak pomagałem znajomemu wyeksportować wszystkie adresy URL z WordPressa — powiedzmy tylko, że było tam sporo kawy i odrobina egzystencjalnego niepokoju.
Dobra wiadomość? Nie musisz dalej bawić się w cyfrowe chowanego ze swoją własną witryną. W tym przewodniku pokażę Ci wszystkie najważniejsze sposoby na znalezienie adresów URL strony — od klasycznych po nowoczesne — a także pokażę, jak narzędzia oparte na AI, takie jak Thunderbit, mogą sprawić, że cały proces będzie znacznie szybszy, pełniejszy i, odważę się powiedzieć, naprawdę przyjemny. Niezależnie od tego, czy jesteś marketerem, developerem, czy po prostu nieszczęśnikiem, któremu powierzono „zdobycie wszystkich URL-i”, znajdziesz tu praktyczne kroki, przykłady z życia i uczciwe porównania, które pomogą Ci wybrać najlepsze podejście dla zespołu.
Dlaczego możesz potrzebować listy stron witryny: praktyczne zastosowania
Zanim przejdziemy do sposobu działania, porozmawiajmy o tym, po co to wszystko. Dlaczego tyle zespołów w ogóle musi wyszukiwać adresy URL witryny? Okazuje się, że nie chodzi wyłącznie o SEO — to powtarzająca się potrzeba w marketingu, sprzedaży, IT i operacjach. Oto kilka najczęstszych scenariuszy:
- Audyt treści i strategia SEO: Audyty treści są dziś standardem — 61% marketerów przeprowadza je co najmniej dwa razy w roku. Pełna lista URL-i to podstawa do oceny skuteczności, aktualizacji starych treści i poprawy pozycji. Co więcej, 49% marketerów odnotowało wzrost ruchu po odświeżeniu starych treści.
- Redesign i migracja witryny: 68% marketerów uważa, że witrynę należy przeprojektowywać co 1–3 lata), a każda migracja wymaga mapowania obecnych adresów URL, by uniknąć błędnych linków i utraty SEO.
- Zgodność i utrzymanie: Zespoły operacyjne muszą znajdować osierocone lub przestarzałe strony — czasem stare mikrowitryny kampanijne nadal są aktywne, tylko czekają, żeby kogoś zawstydzić.
- Analiza konkurencji: Zespoły sprzedaży i marketingu zgrywają strony konkurencji, by zebrać listy stron produktowych, cenników lub wpisów na blogu i znaleźć luki albo leady.
- Pozyskiwanie leadów i outreach: Zespoły sprzedaży często muszą przygotować listy lokalizatorów sklepów, katalogów dealerów lub stron dla członków, aby prowadzić działania sprzedażowe.
- Inwentaryzacja treści: Content marketerzy prowadzą bieżącą listę wszystkich wpisów blogowych, landing page’y, plików PDF i innych materiałów, aby uniknąć duplikacji i maksymalizować wartość.
Oto szybka tabela podsumowująca te scenariusze:
| Scenariusz | Kto tego potrzebuje | Dlaczego pełna lista stron ma znaczenie |
|---|---|---|
| Audyt SEO / audyt treści | Specjaliści SEO, content marketerzy | Ocena każdej treści; brakujące strony = niepełna analiza, utracone okazje optymalizacyjne |
| Migracja / redesign witryny | Programiści webowi, SEO, IT, marketing | Mapowanie starych URL-i do nowych, konfiguracja przekierowań, ochrona przed błędnymi linkami i utratą SEO |
| Analiza konkurencji | Marketing, sprzedaż | Wgląd we wszystkie strony konkurencji; ukryte strony mogą ujawnić szanse |
| Pozyskiwanie leadów | Zespoły sprzedaży | Zbieranie stron kontaktowych i zasobów do outreach; brak pominiętych potencjalnych leadów |
| Inwentaryzacja treści | Content marketing | Utrzymywanie aktualnego repozytorium, identyfikacja luk, unikanie duplikacji i przegląd starych stron |
A jaki jest wpływ brakujących lub ukrytych stron? Bardzo realny. Wyobraź sobie planowanie redesignu i pominięcie ukrytej strony landing page, która nadal konwertuje, albo przeprowadzenie audytu i brak 5% stron, bo nie są zaindeksowane. To utracony przychód, kary SEO, a czasem też kryzys PR, którego nikt nie przewidział.
Najpopularniejsze sposoby wyszukiwania adresów URL witryny: tradycyjne metody
Dobra, przejdźmy do konkretów: jak ludzie faktycznie zdobywają listy stron? Jest kilka sprawdzonych metod — niektóre są szybkie i proste, inne dokładniejsze (i czasem bardziej bolesne). Oto, jak wypadają:
Wyszukiwanie w Google i operatory wyszukiwania
Jak to działa:
Otwórz Google i wpisz site:twojastrona.com. Google pokaże wszystkie strony z tej domeny, które ma w indeksie. Możesz zawężać wynik za pomocą słów kluczowych lub podkatalogów (np. site:twojastrona.com/blog).
Co otrzymujesz:
Listę zaindeksowanych stron — w zasadzie to, co Google wie o Twojej witrynie.
Ograniczenia:
- Pokazuje tylko to, co jest zaindeksowane, a nie wszystko, co istnieje
- Przedstawiciele Google sami mówią, że operator „site:” pokazuje tylko niektóre zaindeksowane strony, a nie wszystkie
- Zwykle zatrzymuje się po kilkuset wynikach, nawet w dużych serwisach
- Pomija nowe, ukryte lub celowo niezaindeksowane strony
Kiedy używać:
Świetne do szybkiego podglądu lub małych witryn, ale nie do pełnego audytu.
Sprawdzanie robots.txt i sitemap.xml
Jak to działa:
Wejdź na twojastrona.com/robots.txt i poszukaj linii „Sitemap:”. Otwórz mapę witryny (zwykle twojastrona.com/sitemap.xml albo /sitemap_index.xml). Mapy witryny zawierają adresy URL, które właściciel serwisu chce zaindeksować.
Co otrzymujesz:
Listę kluczowych stron — często wszystkich wpisów blogowych, stron produktowych itd. Około 80% witryn ma sitemapę.
Ograniczenia:
- Sitemapy obejmują tylko strony, które właściciel chce zaindeksować — strony ukryte lub osierocone często w nich nie występują
- Sitemapy mogą być nieaktualne, jeśli nie są generowane ponownie
- Niektóre serwisy mają kilka map witryny; trzeba je najpierw odnaleźć
Kiedy używać:
Idealne, jeśli zarządzasz witryną lub chcesz szybko przejrzeć główne strony konkurenta. Pamiętaj jednak, że widzisz to, co właściciel serwisu chce Ci pokazać.
Narzędzia SEO Spider i crawlery witryn
Jak to działa:
Narzędzia takie jak Screaming Frog, Sitebulb czy DeepCrawl symulują działanie robota wyszukiwarki. Wpisujesz adres witryny, a narzędzie podąża za wszystkimi linkami wewnętrznymi, tworząc listę znalezionych stron.
Co otrzymujesz:
Potencjalnie każdą stronę, do której prowadzi link w serwisie, a także dane takie jak kody statusu i meta tagi.
Ograniczenia:
- Osierocone strony (nigdzie nielinkowane) zostaną pominięte, chyba że podasz je ręcznie
- Dynamiczne strony lub generowane przez JavaScript mogą zostać pominięte, jeśli narzędzie nie obsługuje przeglądania bezgłowego
- Crawl dużych serwisów może trwać długo i zużywać dużo pamięci komputera
- Wymaga konfiguracji technicznej i doświadczenia
Kiedy używać:
Idealne dla specjalistów SEO lub developerów robiących dogłębne audyty. Mniej przyjazne dla użytkowników nietechnicznych.
Google Search Console i Analytics
Jak to działa:
Jeśli masz dostęp do witryny, Google Search Console (GSC) i Analytics mogą eksportować listy adresów URL.
- GSC: Raporty Index Coverage i Performance pokazują zaindeksowane i wykluczone adresy URL (do 1 000 w jednym eksporcie, więcej przez API).
- Analytics: Pokazuje wszystkie strony, które otrzymały ruch w wybranym przedziale czasu (GA4 pozwala wyeksportować do 100 000 wierszy).
Ograniczenia:
- GSC i Analytics pokazują tylko strony, które Google zna, lub te, które otrzymały ruch
- Limity eksportu (1 000 wierszy dla GSC, 100 tys. dla GA4)
- Wymagają własności witryny/weryfikacji; nie nadają się do badań konkurencji
- Strony bez ruchu lub niezaindeksowane nie pojawią się w wynikach
Kiedy używać:
Świetne do własnej witryny, zwłaszcza przed migracją lub audytem. Nie nadają się do analizy konkurencji.
Panele CMS
Jak to działa:
Jeśli Twoja strona działa na WordPressie, Shopify lub innym CMS-ie, często możesz wyeksportować listę stron i wpisów bezpośrednio z panelu administracyjnego (czasem z pomocą wtyczki).
Co otrzymujesz:
Listę wszystkich wpisów treści — stron, postów, produktów itd.
Ograniczenia:
- Wymaga dostępu administracyjnego
- Może nie obejmować stron nietreściowych lub dynamicznych
- Jeśli witryna korzysta z wielu systemów (blog, sklep, dokumentacja), trzeba połączyć eksporty
Kiedy używać:
Najlepsze dla właścicieli witryn robiących inwentaryzację treści lub kopię zapasową. Nie pomaga w analizie konkurencji.
Ograniczenia tradycyjnych metod zdobywania listy stron witryny
Bądźmy szczerzy: żadna z tych metod nie jest idealna. Oto szybkie podsumowanie głównych luk:
- Złożoność techniczna: Wiele metod wymaga umiejętności technicznych lub specjalistycznych narzędzi. Dla osób nietechnicznych w zespole to bywa prawdziwa bariera. Ręczny audyt treści może zająć tygodnie, a nawet miesiące w dużym serwisie.
- Niepełny zakres: Każda metoda może pominąć część stron — indeks Google nie widzi stron niezaindeksowanych lub nowych, sitemapa pomija osierocone strony, crawlery pomijają strony nielinkowane lub dynamiczne, a eksporty z CMS nie obejmują wszystkiego poza systemem.
- Ręczna praca i czas: Często trzeba łączyć dane z wielu źródeł, usuwać duplikaty i porządkować wszystko — to żmudne i podatne na błędy. Ludzie dzielą się nawet „hackami” typu kopiuj-wklej z map witryny do Excela albo używanie skryptów z linii komend.
- Utrzymanie i świeżość: Listy szybko się dezaktualizują. Tradycyjne metody wymagają ponownego uruchamiania procesu za każdym razem, gdy witryna się zmienia.
- Dostęp i uprawnienia: Niektóre metody wymagają dostępu administratora lub własności witryny — bez szans przy badaniu konkurencji.
- Natłok danych: SEO spider potrafi zasypać Cię danymi technicznymi, gdy tak naprawdę potrzebujesz po prostu listy URL-i.
Krótko mówiąc, tradycyjny proces przypomina „próbę upieczenia ciasta, podczas gdy przepis ciągle się zmienia, a piekarnik od czasu do czasu Cię blokuje”. (Tak, to prawdziwa metafora od stratega contentowego — i ja ją rozumiem.)
Poznaj Thunderbit: sposób oparty na AI na znajdowanie adresów URL witryny
Zbierz wszystkie adresy URL witryny z pomocą Thunderbit AI Get Started Free
A teraz najlepsza część. Co by było, gdybyś mógł po prostu poprosić asystenta: „przejrzyj tę stronę i wypisz wszystkie podstrony”, a on naprawdę by to zrobił — bez kodu i bez komplikacji? Właśnie o to chodzi w Thunderbit.
Thunderbit to rozszerzenie Chrome typu AI web scraper, stworzone dla użytkowników nietechnicznych, ale wystarczająco mocne także dla profesjonalistów. Wykorzystuje AI do „czytania” stron, strukturyzowania danych i eksportowania wszystkich adresów URL — także ukrytych, dynamicznych i z podstron. Nie musisz pisać kodu ani bawić się skomplikowanymi ustawieniami. Po prostu otwórz stronę, kliknij „AI Suggest Fields” i pozwól Thunderbit wykonać ciężką pracę.
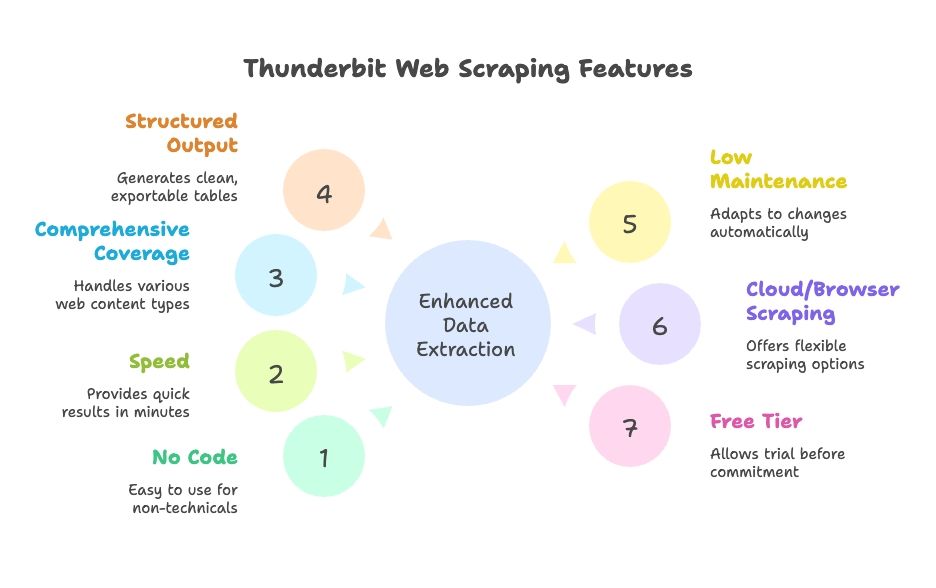
Dlaczego Thunderbit się wyróżnia:
- Bez kodowania i bez konfiguracji: Interfejs oparty na naturalnym języku, prowadzony przez AI. Każdy w zespole może z niego korzystać.
- Szybkość: Wyniki w minuty, nie w godziny.
- Kompletność: Obsługuje treści dynamiczne, paginację, nieskończone przewijanie i podstrony.
- Ustrukturyzowane dane: Czyste tabele gotowe do eksportu do Google Sheets, Excela, Airtable, Notion, CSV lub JSON.
- Niska potrzeba utrzymania: AI automatycznie dostosowuje się do zmian w serwisie; mniej ręcznego poprawiania.
- Scraping w chmurze lub w przeglądarce: Wybierz tryb najlepszy dla swojego workflow.
- Dostępny darmowy plan: Możesz przetestować bez zobowiązań.
Jak Thunderbit upraszcza zdobywanie listy stron witryny
Przejdźmy przez to, jak Thunderbit działa w praktyce. Pokażę Ci, jak przejść od „potrzebuję listy wszystkich stron mojej witryny” do „proszę, oto arkusz, szefie” w zaledwie kilku kliknięciach.
Krok 1: Zainstaluj i uruchom Thunderbit
Pobierz rozszerzenie Thunderbit do Chrome i przypnij je do przeglądarki. Wejdź na stronę, którą chcesz przetworzyć (np. stronę główną) i kliknij ikonę Thunderbit, aby otworzyć interfejs.
Pro tip: Thunderbit oferuje darmowe kredyty dla nowych użytkowników, więc możesz go przetestować bez wyciągania karty kredytowej.
Wypróbuj Thunderbit za darmo na swojej stronie
Krok 2: Wybierz źródło danych
Thunderbit domyślnie pobiera dane z bieżącej strony, ale możesz też wprowadzić listę URL-i (np. mapę witryny albo strony kategorii), jeśli chcesz zacząć od konkretnej sekcji.
- W przypadku większości serwisów zacznij od strony głównej albo strony z mapą witryny.
- W e-commerce możesz zacząć od strony kategorii lub listingu produktów.
Krok 3: Użyj „AI Suggest Fields”, aby wykryć adresy URL
Tutaj dzieje się magia AI. Kliknij „AI Suggest Fields” (albo „AI Suggest Columns”). AI Thunderbit skanuje stronę, rozpoznaje wzorce i proponuje kolumny takie jak „Page Title” i „Page URL” dla wszystkich znalezionych linków. Możesz je dowolnie dostosować.
- Na stronie głównej możesz dostać linki z menu, stopki i sekcji wyróżnionych.
- Na sitemapie otrzymasz czystą listę URL-i.
- Możesz dodawać lub usuwać kolumny albo doprecyzować, co dokładnie chcesz wyciągnąć.
AI Thunderbit wykonuje ciężką pracę — nie musisz pisać XPath-ów ani selektorów CSS. To jak mieć robota-stażystę, który naprawdę rozumie, o co Ci chodzi.
Krok 4: Włącz scraping podstron
Większość witryn nie pokazuje każdej strony na stronie głównej. I tu wchodzi Subpage Scraping w Thunderbit. Oznacz kolumnę z URL jako link typu „follow”, a Thunderbit przejdzie przez każdy znaleziony link i pobierze kolejne adresy URL z tych stron. Możesz nawet tworzyć zagnieżdżone szablony do wielopoziomowego scrapingu.
- W przypadku list z paginacją albo przycisków „load more” włącz Pagination & Scrolling, żeby Thunderbit działał dalej, aż znajdzie wszystko.
- W serwisach z subdomenami lub sekcjami (np. blog na blog.example.com) Thunderbit też może podążać za linkami, jeśli mu to wskażesz.
Krok 5: Uruchom scraping
Kliknij „Scrape” i obserwuj, jak Thunderbit działa. Wypełni tabelę adresami URL (i innymi wybranymi polami) w czasie rzeczywistym. W przypadku większych serwisów możesz zostawić go w tle i wrócić, gdy skończy.
Krok 6: Sprawdź i wyeksportuj
Po zakończeniu przejrzyj wyniki — Thunderbit pozwala sortować, filtrować i usuwać duplikaty bezpośrednio w aplikacji. Następnie wyeksportuj dane jednym kliknięciem do Google Sheets, Excela, CSV, Airtable, Notion lub JSON. Koniec z kopiowaniem, wklejaniem i bałaganem w formatowaniu.
Cały proces? Dla małej lub średniej witryny możesz przejść od zera do pełnej listy URL-i w mniej niż 10 minut. W przypadku większych serwisów i tak będzie to znacznie szybciej (i mniej stresująco) niż składanie danych z kilku źródeł.
Odkrywanie ukrytych i dynamicznych stron z Thunderbit
Jedną z moich ulubionych funkcji Thunderbit jest to, jak radzi sobie ze stronami, które tradycyjne narzędzia często pomijają:
- Treści renderowane przez JavaScript: Ponieważ Thunderbit działa w prawdziwej przeglądarce, może przechwytywać strony ładowane dynamicznie (np. oferty pracy z nieskończonym przewijaniem albo listy produktów).
- Osierocone lub nielinkowane strony: Jeśli masz jakiś trop (np. sitemapę albo wyszukiwarkę), Thunderbit może go wykorzystać, aby znaleźć strony, do których nie prowadzą żadne inne linki.
- Subdomeny lub sekcje: Thunderbit może podążać za linkami między subdomenami, jeśli jest taka potrzeba, dając pełny obraz witryny.
- Interakcja jak użytkownik: Musisz wpisać coś w pole wyszukiwania albo kliknąć filtr, by odsłonić ukryte strony? AI Autofill w Thunderbit też sobie z tym poradzi.
Przykład z życia: Zespół marketingowy musiał znaleźć wszystkie swoje stare landing page’e — wiele z nich nie było nigdzie podlinkowanych, ale nadal istniało. Zgrywając wyniki Google z Thunderbit i podając znane wzorce URL-i, odkryli dziesiątki zapomnianych stron, ratując firmę przed potencjalnym chaosem (i kilkoma bólami głowy).
Thunderbit kontra tradycyjne metody: szybkość, prostota i zakres
Zestawmy Thunderbit z tradycyjnymi metodami:
| Aspekt | Wyszukiwanie Google „site:” | XML Sitemap | SEO Crawler (Screaming Frog) | Google Search Console | Eksport z CMS | Thunderbit AI Scraper |
|---|---|---|---|---|---|---|
| Szybkość | Bardzo szybkie, ale ograniczone | Natychmiastowe, jeśli dostępne | Zależnie od skali (minuty do godzin) | Szybkie dla małych witryn | Natychmiastowe dla małych witryn | Szybkie, konfiguracja w kilka minut, automatyczny scraping |
| Łatwość użycia | Bardzo łatwe | Łatwe | Umiarkowane (wymaga konfiguracji) | Umiarkowane | Łatwe (jeśli masz uprawnienia admina) | Bardzo łatwe, bez kodowania |
| Zakres | Niski (tylko zaindeksowane) | Wysoki dla zamierzonych stron | Wysoki dla stron podlinkowanych | Wysoki dla zaindeksowanych, ograniczony eksport | Średni (tylko treści) | Bardzo wysoki, obsługuje dynamiczne treści i podstrony |
| Wynik i integracja | Ręczne kopiuj-wklej | XML (wymaga parsowania) | CSV z wieloma dodatkowymi danymi | CSV/Excel, do 1 000 wierszy | CSV/XML, może wymagać czyszczenia | Czysta tabela, eksport 1 kliknięciem do Sheets, Excela itd. |
| Utrzymanie | Ręczne ponawianie | Wymaga aktualizacji | Ponowny crawl po zmianach w serwisie | Okresowy eksport | Eksport po zmianach | Niskie — AI się dostosowuje, można planować scraping |
Thunderbit wyróżnia się łatwością użycia, kompletnością i integracją. Tradycyjne metody mają swoje mocne strony, ale wymagają więcej pracy, by połączyć wyniki i utrzymać je w aktualności. AI Thunderbit dostosowuje się do zmian w witrynie, więc nie musisz ciągle poprawiać ustawień ani ponawiać ręcznych eksportów.
Jak wybrać właściwe podejście: kto powinien używać której metody?
Jak zeskrobać dowolną stronę internetową z użyciem AI Get Started Free
No dobrze, która metoda będzie najlepsza dla Ciebie? Oto moje zdanie, oparte na latach pomagania zespołom w ogarnianiu danych z ich witryn:
- Specjaliści SEO / developerzy: Jeśli potrzebujesz głębokich danych technicznych (meta tagów, uszkodzonych linków itd.) albo audytujesz ogromny serwis korporacyjny, crawler lub własny skrypt mogą nadal mieć sens. Ale nawet wtedy Thunderbit może szybko przygotować listę URL-i do dalszego wykorzystania w innych narzędziach.
- Marketerzy, content strategist, project managerowie: Thunderbit to wybawienie. Koniec z czekaniem, aż IT uruchomi skrypt albo połączy eksporty. Jeśli potrzebujesz inwentaryzacji treści, analizy konkurencji albo szybkiego audytu, Thunderbit pozwala działać samodzielnie.
- Zespoły sprzedaży / lead gen: Thunderbit ułatwia pobieranie list lokalizacji sklepów, stron wydarzeń czy katalogów członków z dowolnej witryny — bez kodowania.
- Małe strony / szybkie zadania: W przypadku bardzo małych serwisów ręczne sprawdzenie albo sitemap może wystarczyć. Ale konfiguracja Thunderbit jest tak szybka, że często i tak warto go użyć, żeby niczego nie pominąć.
- Budżet: Tradycyjne metody są tanie — poza tym, że kosztują Twój czas. Thunderbit ma darmowy plan, a płatne pakiety są przystępne dla większości firm. Pamiętaj: Twój czas też ma wartość!
- Bardzo niestandardowe potrzeby danych: Jeśli potrzebujesz wyjątkowo specyficznych danych albo złożonej logiki, może być konieczne napisanie własnego scrapera. Ale AI Thunderbit obsłuży większość przypadków przy minimalnej konfiguracji.
Wskazówki decyzyjne:
- Jeśli masz dostęp do witryny i mniej niż 1 000 stron, spróbuj eksportu z Google Search Console — ale sprawdź kompletność.
- Jeśli nie masz dostępu do witryny albo potrzebujesz danych konkurencji, Thunderbit lub crawler będzie Twoim sprzymierzeńcem.
- Jeśli cenisz swój czas i chcesz rozwiązania, które skaluje się razem z Tobą, Thunderbit jest trudny do pobicia.
- Do pracy zespołowej bezpośredni eksport Thunderbit do Google Sheets to duży plus.
Wiele organizacji stosuje podejście hybrydowe: Thunderbit do szybkich zadań i pracy dla osób nietechnicznych, tradycyjne narzędzia do pogłębionych audytów.
Kluczowe wnioski: jak zdobywać listę stron witryny dla każdej potrzeby biznesowej
Podsumujmy:
- Posiadanie pełnej listy stron witryny jest kluczowe dla SEO, strategii treści, migracji i researchu sprzedażowego. Pomaga uniknąć niespodzianek, błędnych linków i utraconych okazji. Większość marketerów przeprowadza dziś audyty treści co najmniej raz w roku (źródło).
- Tradycyjne metody istnieją, ale każda ma luki. Żadne pojedyncze podejście nie gwarantuje pełnej i aktualnej listy. Często wymagają one umiejętności technicznych i łączenia wielu wyników.
- Scraping wspierany przez AI (Thunderbit) oferuje nowoczesne rozwiązanie. Thunderbit wykorzystuje AI do „ciężkiego myślenia” i klikania, dzięki czemu web scraping staje się dostępny dla każdego. Obsługuje treści dynamiczne, podstrony i eksportuje dane w gotowym do użycia formacie — oszczędzając czas i ograniczając błędy. W bezpośrednich porównaniach Thunderbit często robi w minuty to, co wcześniej zajmowało godziny, i to praktycznie bez krzywej uczenia się (zobacz więcej).
- Dopasuj metodę do swoich potrzeb i zespołu. Przy ogromnych serwisach używaj całego arsenału narzędzi, ale dla większości użytkowników biznesowych Thunderbit sam w sobie będzie najlepszym wyborem.
- Dbaj o aktualność. Regularne audyty pozwalają wychwycić problemy wcześnie i utrzymać witrynę lekką oraz skuteczną. Harmonogram Thunderbit sprawia, że jest to wykonalne, podczas gdy procesy ręczne często są pomijane ze względu na nakład pracy.
Ostatnia myśl: Dość już wymówek, że nie wiesz, co znajduje się na Twojej własnej stronie (albo na stronie konkurencji). Przy odpowiednim podejściu możesz uzyskać kompletną listę wszystkich stron i wykorzystać tę wiedzę do poprawy SEO, doświadczenia użytkownika i strategii biznesowej. Pracuj sprytniej, nie ciężej — pozwól AI wykonać ciężką pracę i dopilnuj, by żadna strona nie została w tyle.
Następne kroki
Jeśli jesteś gotowy przestać drżeć na myśl o zadaniu „daj mi wszystkie URL-e”, pobierz Thunderbit i przetestuj go na swojej stronie lub stronie konkurenta. Będziesz zaskoczony, ile czasu (i nerwów) zaoszczędzisz. A jeśli chcesz zgłębić temat web scrapingu, zajrzyj do naszych innych przewodników na Thunderbit Blog, takich jak Jak zeskrobać dowolną stronę internetową z użyciem AI albo 6 narzędzi do web scrapingu, których naprawdę używam: uczciwe porównanie (2026).
Dowiedz się, jak zeskrobać dowolną stronę internetową z użyciem AI
FAQ
1. Dlaczego w ogóle miałbym potrzebować listy wszystkich stron w witrynie?
Zespoły SEO, marketingu, sprzedaży i IT często potrzebują pełnych list URL-i witryny do zadań takich jak audyty treści, migracje stron, pozyskiwanie leadów i analiza konkurencji. Pełna i dokładna lista pomaga uniknąć uszkodzonych linków, zapobiega duplikacji lub pomijaniu treści i ujawnia ukryte szanse.
2. Jakie są tradycyjne sposoby znajdowania wszystkich adresów URL witryny?
Do popularnych metod należą: wyszukiwanie w Google z operatorem site:, sprawdzanie plików sitemap.xml i robots.txt, crawl za pomocą narzędzi SEO takich jak Screaming Frog, eksport danych z platform CMS typu WordPress oraz pobieranie stron zaindeksowanych lub generujących ruch z Google Search Console i Analytics. Każda z tych metod ma jednak ograniczenia dotyczące zakresu i wygody użycia.
3. Jakie są ograniczenia tradycyjnych metod znajdowania URL-i?
Tradycyjne metody często pomijają strony dynamiczne, osierocone lub niezaindeksowane. Mogą wymagać wiedzy technicznej, godzin na łączenie i czyszczenie danych oraz zwykle nie skalują się dobrze dla dużych serwisów ani cyklicznych audytów. Czasem potrzebujesz też własności witryny lub dostępu administracyjnego, a to nie zawsze jest możliwe.
4. Jak Thunderbit upraszcza proces znajdowania wszystkich stron witryny?
Thunderbit to scraper oparty na AI, który skanuje witryny jak człowiek — przechodząc przez podstrony, obsługując JavaScript i automatycznie porządkując dane. Nie wymaga kodowania, działa jako rozszerzenie Chrome i pozwala wyeksportować czyste listy URL-i do Google Sheets, Excela, CSV i innych formatów w zaledwie kilka minut.
5. Kto powinien używać Thunderbit, a kto tradycyjnych narzędzi?
Thunderbit jest idealny dla marketerów, content strategistów, zespołów sprzedaży i użytkowników nietechnicznych, którzy chcą szybko dostać pełne listy URL-i bez komplikacji. Tradycyjne narzędzia lepiej sprawdzają się w technicznych audytach wymagających głębokich metadanych lub własnych skryptów. Wiele zespołów korzysta z obu — Thunderbit dla szybkości i prostoty, a z tradycyjnych narzędzi do dogłębnej analizy.
Wypróbuj Thunderbit AI Web Scraper za darmo Get Started Free




