

Dane z sieci rosną w błyskawicznym tempie, a razem z nimi rośnie presja, żeby za nimi nadążyć. Widziałem na własne oczy, jak zespoły sprzedaży i operacji spędzają więcej czasu na przepisywaniu danych do arkuszy i kopiowaniu informacji ze stron internetowych niż na podejmowaniu decyzji. Według Salesforce przedstawiciele handlowi dziś poświęcają nawet 70% czasu na zadania inne niż sprzedaż, a Asana podaje, że 60% pracy to po prostu „praca o pracy”. To ogrom godzin traconych na ręczne zbieranie danych — godzin, które można byłoby przeznaczyć na domykanie transakcji albo uruchamianie kampanii.
Dobra wiadomość jest taka: web scraping wszedł już do głównego nurtu i nie trzeba być programistą, żeby korzystać z jego możliwości. Ruby od dawna jest cenione za automatyzację pobierania danych z internetu, ale kiedy połączysz je z nowoczesnymi narzędziami typu AI web scraper, takimi jak Thunderbit, dostajesz to, co najlepsze z obu światów — elastyczność dla osób kodujących i prostotę no-code dla wszystkich pozostałych. Niezależnie od tego, czy jesteś marketerem, managerem e-commerce, czy po prostu masz dość niekończącego się kopiowania i wklejania, ten przewodnik pokaże Ci, jak opanować web scraping w Ruby i z pomocą AI — bez konieczności pisania kodu.
Wypróbuj Thunderbit do web scrapingu bez kodu
Czym jest web scraping w Ruby? Twoja brama do automatyzacji danych
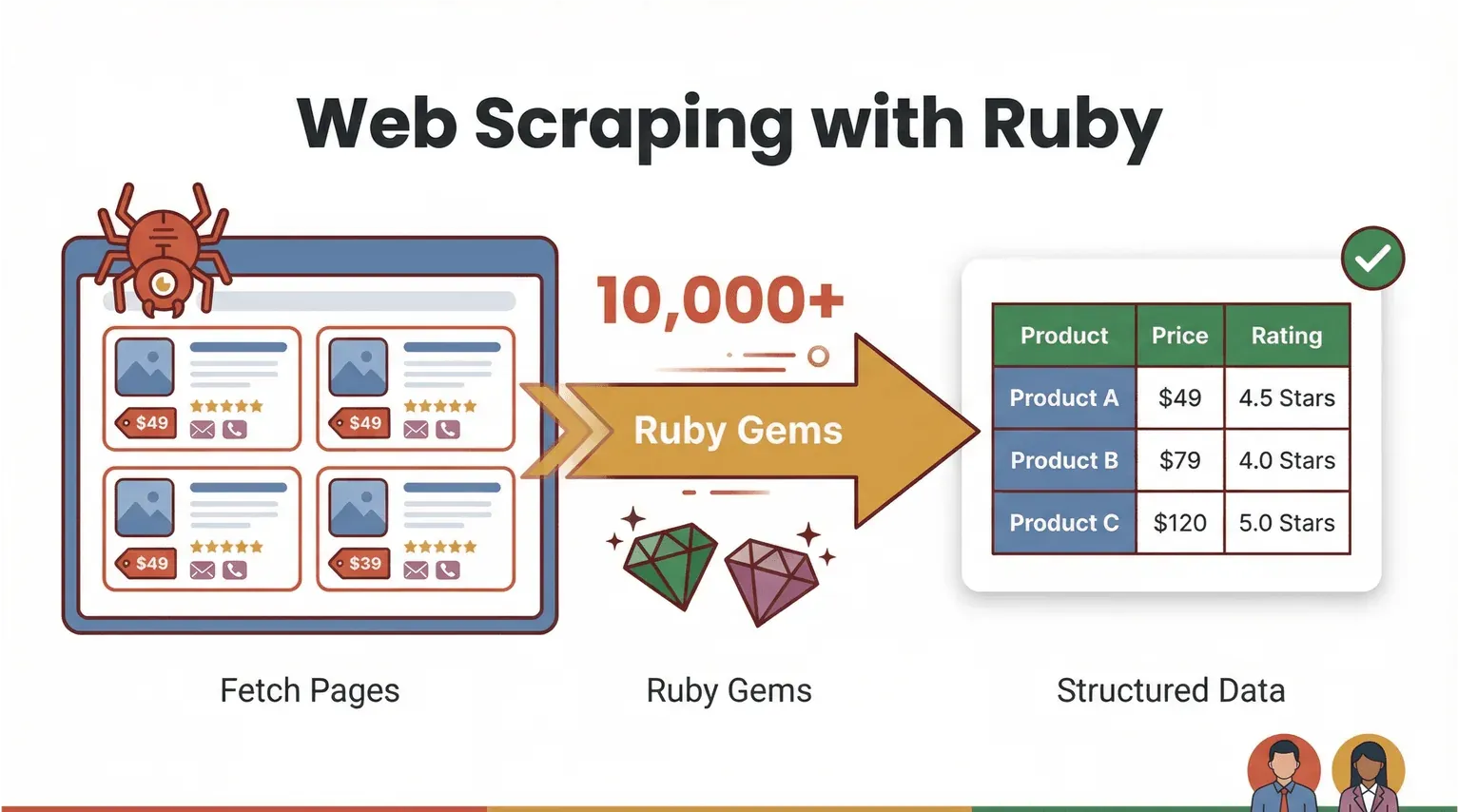
Zacznijmy od podstaw. Web scraping to po prostu proces używania oprogramowania do pobierania stron internetowych i wyodrębniania z nich konkretnych informacji — takich jak ceny produktów, dane kontaktowe czy opinie — do uporządkowanego formatu (np. CSV albo Excel). Ruby świetnie sprawdza się w takim zadaniu: jest wygodne, czytelne i ma ogromny ekosystem tzw. gemów, czyli bibliotek, które mocno ułatwiają automatyzację (Ruby Programming Language).
Jak więc wygląda „web scraping w Ruby” w praktyce? Wyobraź sobie, że chcesz pobrać wszystkie nazwy produktów i ich ceny ze sklepu internetowego. W Ruby możesz napisać skrypt, który:
- Pobiera stronę internetową (np. przy użyciu biblioteki HTTParty)
- Parsuje HTML, aby znaleźć potrzebne dane (z pomocą Nokogiri)
- Eksportuje je do arkusza kalkulacyjnego lub bazy danych
Ale tu zaczyna się najciekawsze: nie zawsze musisz pisać kod. Narzędzia AI do web scrapingu bez kodu, takie jak Thunderbit, potrafią dziś przejąć najcięższą pracę — odczytać stronę, rozpoznać pola i wyeksportować czystą tabelę danych kilkoma kliknięciami. Ruby nadal świetnie sprawdza się jako „klej automatyzacyjny” dla niestandardowych workflow, ale AI web scrapery otwierają tę technologię także dla użytkowników biznesowych.
Czym jest data scraping? Get Started Free
Dlaczego web scraping w Ruby ma znaczenie dla zespołów biznesowych

Bądźmy szczerzy: nikt nie chce spędzać dnia na ręcznym kopiowaniu danych. Zapotrzebowanie na automatyczne pozyskiwanie danych z internetu rośnie błyskawicznie — i nie bez powodu. Oto, jak web scraping w Ruby (i narzędzia AI) zmieniają sposób działania firm:
- Pozyskiwanie leadów: błyskawicznie pobieraj dane kontaktowe z katalogów lub LinkedIn do lejka sprzedażowego.
- Monitorowanie cen konkurencji: śledź zmiany cen w setkach SKU e-commerce — bez ręcznego sprawdzania.
- Tworzenie katalogów produktów: agreguj szczegóły produktów i zdjęcia do własnego sklepu lub marketplace’u.
- Badania rynku: zbieraj opinie, oceny lub artykuły newsowe do analizy trendów.
Zwrot z inwestycji jest oczywisty: zespoły, które automatyzują zbieranie danych z sieci, oszczędzają godziny tygodniowo, ograniczają błędy i pracują na świeższych, bardziej wiarygodnych danych. Na przykład w produkcji 70% firm nadal zbiera dane ręcznie, mimo że wolumen danych w zaledwie dwa lata się podwoił. To ogromna szansa na automatyzację.
Oto krótkie podsumowanie, jak web scraping w Ruby i narzędzia AI dostarczają wartości:
| Przykład użycia | Problem przy pracy ręcznej | Korzyść z automatyzacji | Typowy efekt |
|---|---|---|---|
| Pozyskiwanie leadów | Kopiowanie maili jeden po drugim | Tysiące rekordów w kilka minut | 10x więcej leadów, mniej żmudnej pracy |
| Monitorowanie cen | Codzienne sprawdzanie stron | Zaplanowane, automatyczne pobieranie cen | Wiedza o cenach w czasie rzeczywistym |
| Budowanie katalogu | Ręczne wprowadzanie danych | Masowe wyodrębnianie i formatowanie | Szybsze wdrożenia, mniej błędów |
| Badania rynku | Ręczne czytanie opinii | Scrapowanie i analiza na dużą skalę | Głębsze, świeższe wnioski |
I nie chodzi tylko o szybkość — automatyzacja oznacza mniej pomyłek i bardziej spójne dane, co ma kluczowe znaczenie, gdy 58% liderów przyznaje, że decyzje opiera na nieprecyzyjnych lub niespójnych danych.
Przegląd rozwiązań do web scrapingu: skrypty Ruby kontra AI web scraper
Więc co lepiej wybrać: własny skrypt w Ruby czy no-code’owy AI web scraper? Rozłóżmy to na czynniki pierwsze.
Skrypty Ruby: pełna kontrola, ale większa potrzeba utrzymania
Ekosystem Ruby oferuje gemy praktycznie do każdego zadania związanego ze scrapingiem:
- Nokogiri: standard do parsowania HTML i XML.
- HTTParty: do pobierania stron i pracy z API.
- Mechanize: dla stron wymagających ciasteczek, formularzy i nawigacji.
- Selenium / Watir: do automatyzacji prawdziwych przeglądarek (świetne przy stronach mocno opartych na JavaScript).
Skrypty Ruby dają pełną elastyczność — własną logikę, czyszczenie danych i integrację z Twoimi systemami. Ale to również Ty odpowiadasz za utrzymanie: gdy strona zmieni układ, skrypt może przestać działać. A jeśli nie czujesz się pewnie w kodzie, czeka Cię też krzywa uczenia.
AI web scrapery i narzędzia no-code: szybko, wygodnie i elastycznie
Nowoczesne no-code web scrapery, takie jak Thunderbit, odwracają sytuację. Zamiast pisać kod, po prostu:
- Otwierasz rozszerzenie Chrome
- Klikać „AI Suggest Fields”, aby AI wykryła, co warto wyodrębnić
- Naciskasz „Scrape” i eksportujesz dane
AI w Thunderbit potrafi dostosować się do zmieniających się układów stron, obsługuje podstrony (np. szczegóły produktów) i eksportuje dane bezpośrednio do Excel, Google Sheets, Airtable lub Notion. To idealne rozwiązanie dla użytkowników biznesowych, którzy chcą rezultatów bez zbędnych komplikacji.
Porównanie obok siebie:
| Podejście | Plusy | Minusy | Najlepsze dla |
|---|---|---|---|
| Skrypty Ruby | Pełna kontrola, własna logika, elastyczność | Wyższa krzywa uczenia, konieczność utrzymania | Programiści, zaawansowani użytkownicy |
| AI Web Scraper | Bez kodu, szybka konfiguracja, adaptacja do zmian | Mniejsza granularna kontrola, pewne ograniczenia | Użytkownicy biznesowi, zespoły operacyjne |
Trend jest jasny: wraz ze wzrostem złożoności stron internetowych — i ich mechanizmów obronnych — AI web scrapery stają się domyślnym wyborem w większości procesów biznesowych.
Jak zacząć: konfiguracja środowiska do web scrapingu w Ruby
Jeśli chcesz spróbować skryptów Ruby, zacznijmy od przygotowania środowiska. Dobra wiadomość? Ruby łatwo zainstalować i działa na Windowsie, macOS i Linuxie.
Krok 1: Zainstaluj Ruby
- Windows: pobierz RubyInstaller i postępuj zgodnie z instrukcjami. Upewnij się, że instalujesz też MSYS2, potrzebne do budowania natywnych rozszerzeń (wymaganych m.in. przez Nokogiri).
- macOS/Linux: do zarządzania wersjami użyj rbenv. W Terminalu:
brew install rbenv ruby-build
rbenv install 4.0.4
rbenv global 4.0.4
(Sprawdź stronę pobierania Ruby, aby zobaczyć najnowszą stabilną wersję.)
Krok 2: Zainstaluj Bundler i podstawowe gemy
Bundler pomaga zarządzać zależnościami:
gem install bundler
Utwórz plik Gemfile dla projektu:
source 'https://rubygems.org'
gem 'nokogiri'
gem 'httparty'
Następnie uruchom:
bundle install
Dzięki temu Twoje środowisko będzie spójne i gotowe do scrapingu.
Krok 3: Przetestuj konfigurację
Sprawdź to w IRB (interaktywnym shellu Ruby):
require 'nokogiri'
require 'httparty'
puts Nokogiri::VERSION
Jeśli zobaczysz numer wersji, wszystko działa jak należy.
Krok po kroku: budujemy pierwszy web scraper w Ruby
Przejdźmy przez realny przykład — pobieranie danych o produktach z Books to Scrape, strony stworzonej do ćwiczenia scrapingu.
Oto prosty skrypt Ruby do wyodrębnienia tytułów książek, cen i informacji o dostępności:
require "net/http"
require "uri"
require "nokogiri"
require "csv"
BASE_URL = "https://books.toscrape.com/"
def fetch_html(url)
uri = URI.parse(url)
res = Net::HTTP.get_response(uri)
raise "HTTP #{res.code} for #{url}" unless res.is_a?(Net::HTTPSuccess)
res.body
end
def scrape_list_page(list_url)
html = fetch_html(list_url)
doc = Nokogiri::HTML(html)
products = doc.css("article.product_pod").map do |pod|
title = pod.css("h3 a").first["title"]
price = pod.css(".price_color").text.strip
stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
{ title: title, price: price, stock: stock }
end
next_rel = doc.css("li.next a").first&.[]("href")
next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
[products, next_url]
end
rows = []
url = "#{BASE_URL}catalogue/page-1.html"
while url
products, url = scrape_list_page(url)
rows.concat(products)
end
CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
end
puts "Wrote #{rows.length} rows to books.csv"
Ten skrypt pobiera każdą stronę, parsuje HTML, wyciąga dane i zapisuje je do pliku CSV. Potem możesz otworzyć books.csv w Excelu lub Google Sheets.
Najczęstsze problemy:
- Jeśli pojawiają się błędy o brakujących gemach, sprawdź
Gemfilei uruchom ponowniebundle install. - W przypadku stron, które ładują dane przez JavaScript, potrzebujesz narzędzia do automatyzacji przeglądarki, takiego jak Selenium lub Watir.
Przyspieszenie scrapingu w Ruby z Thunderbit: AI web scraper w praktyce
Teraz zobaczmy, jak Thunderbit może wynieść Twoje scrapowanie na wyższy poziom — bez kodowania.
Thunderbit to AI web scraper w formie rozszerzenia Chrome, który pozwala wyodrębniać ustrukturyzowane dane z dowolnej strony internetowej w zaledwie dwa kliknięcia. Działa tak:
- Otwórz rozszerzenie Thunderbit na stronie, którą chcesz zebrać.
- Kliknij „AI Suggest Fields”. AI Thunderbit skanuje stronę i podpowiada najlepsze kolumny do pobrania (np. „Nazwa produktu”, „Cena”, „Stan magazynu”).
- Kliknij „Scrape”. Thunderbit pobiera dane, obsługuje paginację i potrafi przechodzić do podstron, jeśli potrzebujesz więcej szczegółów.
- Wyeksportuj dane bezpośrednio do Excel, Google Sheets, Airtable lub Notion.
To, co wyróżnia Thunderbit, to zdolność radzenia sobie ze złożonymi, dynamicznymi stronami — bez kruchych selektorów i bez pisania kodu. A jeśli chcesz połączyć różne workflow, możesz użyć Thunderbit do pobrania danych, a następnie przetworzyć je lub wzbogacić w Ruby.
Wskazówka pro: scrapowanie podstron w Thunderbit to zbawienie dla zespołów e-commerce i nieruchomości. Najpierw pobierz listę linków do produktów, a potem pozwól Thunderbit odwiedzić każdy z nich, by zebrać szczegółowe specyfikacje, zdjęcia lub opinie — automatycznie wzbogacając zbiór danych.
Jak zeskrobać dowolną stronę internetową z pomocą AI Get Started Free
Przykład z życia: pobieranie danych o produktach i cenach e-commerce w Ruby i Thunderbit
Połączmy wszystko w praktyczny workflow dla zespołów e-commerce.
Scenariusz: chcesz monitorować ceny konkurencji i szczegóły produktów dla setek SKU.
Krok 1: użyj Thunderbit do pobrania głównej listy produktów
- Otwórz stronę listy produktów konkurencji.
- Uruchom Thunderbit i kliknij „AI Suggest Fields” (np. Nazwa produktu, Cena, URL).
- Kliknij „Scrape” i wyeksportuj wyniki do CSV.
Krok 2: wzbogacenie danych przez scrapowanie podstron
- W Thunderbit użyj funkcji „Scrape Subpages”, aby odwiedzić stronę szczegółową każdego produktu i pobrać dodatkowe pola (np. opis, stan magazynu, zdjęcia).
- Wyeksportuj wzbogaconą tabelę.
Krok 3: obróbka lub analiza w Ruby
- Użyj skryptu Ruby, aby dalej oczyścić, przekształcić lub przeanalizować dane. Na przykład możesz:
- przeliczyć ceny na jedną walutę,
- odfiltrować produkty niedostępne,
- wygenerować statystyki podsumowujące.
Oto prosty fragment Ruby do filtrowania produktów dostępnych w magazynie:
require 'csv'
rows = CSV.read('products.csv', headers: true)
in_stock = rows.select { |row| row['stock'].include?('In stock') }
CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
in_stock.each { |row| csv << row }
end
Efekt:
Przechodzisz od surowych stron internetowych do czystej, gotowej do działania tabeli danych — idealnej do analizy cen, planowania stanów magazynowych czy kampanii marketingowych. I robisz to wszystko bez napisania choćby jednej linii kodu scrapingu.
Bez kodu? Nie ma problemu: automatyzacja pozyskiwania danych dla każdego
Jedną z rzeczy, które najbardziej lubię w Thunderbit, jest to, jak bardzo wspiera osoby nietechniczne. Nie musisz znać Ruby, HTML ani CSS — wystarczy otworzyć rozszerzenie, pozwolić AI zrobić swoje i wyeksportować dane.
Krzywa uczenia: przy skryptach Ruby trzeba opanować podstawy programowania i struktury stron. Z Thunderbit konfiguracja zajmuje minuty, a nie dni.
Integracje: Thunderbit eksportuje dane bezpośrednio do narzędzi, z których zespoły biznesowe już korzystają — Excel, Google Sheets, Airtable, Notion. Możesz też zaplanować cykliczne scrapowanie do stałego monitoringu.
Opinie użytkowników: widziałem, jak zespoły marketingowe, sales ops i managerowie e-commerce automatyzują wszystko — od budowania list leadów po śledzenie cen — bez angażowania IT.
Najlepsze praktyki: łączenie Ruby i AI Web Scraper w skalowalnej automatyzacji
Chcesz zbudować solidny, skalowalny workflow scrapingu? Oto moje najważniejsze wskazówki:
- Uwzględniaj zmiany na stronie: AI web scrapery, takie jak Thunderbit, dostosowują się automatycznie, ale jeśli korzystasz ze skryptów Ruby, musisz być gotowy na aktualizację selektorów, gdy strona się zmieni.
- Planuj cykliczne scrapowanie: użyj harmonogramu Thunderbit do regularnego pobierania danych. W Ruby możesz ustawić cron job albo skorzystać z harmonogramu zadań.
- Przetwarzanie wsadowe: przy dużych zbiorach danych dziel scraping na partie, aby uniknąć blokad i nie przeciążać systemu.
- Formatowanie danych: zawsze czyść i waliduj dane przed analizą — eksporty z Thunderbit są już uporządkowane, ale własne skrypty Ruby mogą wymagać dodatkowych kontroli.
- Zgodność z przepisami: zbieraj tylko publicznie dostępne dane, respektuj
robots.txti pamiętaj o przepisach dotyczących prywatności — szczególnie w UE, gdzie GDPR dotyczy także scrapowanych danych osobowych. - Plan awaryjny: jeśli strona staje się zbyt złożona lub blokuje scraping, poszukaj oficjalnych API albo alternatywnych źródeł danych.
Kiedy używać czego?
- Używaj skryptów Ruby, gdy potrzebujesz pełnej kontroli, własnej logiki lub integracji z systemami wewnętrznymi.
- Używaj Thunderbit, gdy zależy Ci na szybkości, prostocie i elastyczności — zwłaszcza przy jednorazowych lub cyklicznych zadaniach biznesowych.
- Łącz oba rozwiązania w bardziej zaawansowanych workflow: pozwól Thunderbit zająć się ekstrakcją, a Ruby wykorzystaj do wzbogacania, kontroli jakości lub integracji.
Podsumowanie i najważniejsze wnioski
Web scraping w Ruby od dawna był supermocą w automatyzacji zbierania danych — ale teraz, dzięki AI web scraperom takim jak Thunderbit, ta moc jest dostępna dla każdego. Niezależnie od tego, czy jesteś programistą szukającym elastyczności, czy użytkownikiem biznesowym, który po prostu chce wyników, możesz zautomatyzować pobieranie danych z internetu, zaoszczędzić godziny ręcznej pracy i podejmować lepsze, szybsze decyzje.
Oto, co mam nadzieję zapamiętasz:
- Ruby to świetne narzędzie do web scrapingu i automatyzacji — szczególnie z gemami takimi jak Nokogiri i HTTParty.
- AI web scrapery, takie jak Thunderbit, sprawiają, że ekstrakcja danych jest dostępna także dla osób bez kodowania, dzięki funkcjom takim jak „AI Suggest Fields” i scrapowanie podstron.
- Połączenie Ruby i Thunderbit daje najlepsze z obu światów: szybkie pobieranie bez kodu plus własna automatyzacja i analiza.
- Automatyzacja zbierania danych z sieci to świetny plan dla zespołów sprzedaży, marketingu i e-commerce — ogranicza ręczną pracę, zwiększa dokładność i otwiera drogę do nowych insightów.
Gotowy, by zacząć? Pobierz Thunderbit, wypróbuj prosty skrypt Ruby i zobacz, ile czasu możesz zaoszczędzić. A jeśli chcesz wejść głębiej, zajrzyj na blog Thunderbit, gdzie znajdziesz więcej poradników, wskazówek i praktycznych przykładów.
Pobierz rozszerzenie Thunderbit do Chrome
FAQ
1. Czy muszę umieć programować, aby używać Thunderbit do web scrapingu?
Nie. Thunderbit zostało stworzone z myślą o osobach nietechnicznych. Wystarczy otworzyć rozszerzenie, kliknąć „AI Suggest Fields” i pozwolić AI zrobić resztę. Dane możesz wyeksportować do Excel, Google Sheets, Airtable lub Notion — bez kodowania.
2. Jakie są główne zalety używania Ruby do web scrapingu?
Ruby oferuje mocne biblioteki, takie jak Nokogiri i HTTParty, które pozwalają tworzyć elastyczne, dopasowane do potrzeb workflow scrapingu. To świetny wybór dla programistów, którzy chcą pełnej kontroli, własnej logiki i integracji z innymi systemami.
3. Jak działa funkcja „AI Suggest Fields” w Thunderbit?
AI Thunderbit skanuje stronę, rozpoznaje najważniejsze pola danych (np. nazwy produktów, ceny, adresy e-mail) i proponuje uporządkowaną tabelę. Przed rozpoczęciem scrapingu możesz dowolnie dostosować kolumny.
4. Czy mogę połączyć Thunderbit ze skryptami Ruby w bardziej zaawansowanych workflow?
Oczywiście. Wiele zespołów używa Thunderbit do pobierania danych — zwłaszcza z bardziej złożonych lub dynamicznych stron — a następnie przetwarza je lub analizuje dalej w Ruby. Takie hybrydowe podejście świetnie sprawdza się przy niestandardowych raportach i wzbogacaniu danych.
5. Czy web scraping jest legalny i bezpieczny w zastosowaniach biznesowych?
Web scraping jest legalny, jeśli zbierasz publicznie dostępne dane i przestrzegasz regulaminu strony oraz przepisów o prywatności. Zawsze sprawdzaj robots.txt i nie pobieraj danych osobowych bez właściwej zgody — szczególnie w przypadku użytkowników z UE objętych GDPR.
Ciekawi Cię, jak web scraping może zmienić Twój workflow? Wypróbuj darmowy plan Thunderbit albo przetestuj dziś prosty skrypt Ruby. A jeśli utkniesz, blog Thunderbit i kanał Thunderbit na YouTube są pełne poradników i wskazówek, które pomogą Ci opanować automatyzację danych z sieci — bez kodowania.
Wypróbuj AI Web Scraper Thunderbit Get Started Free
Dowiedz się więcej
- Przewodnik dla początkujących po web scrapingu w Ruby
- Jak zeskrobać dowolną stronę internetową z pomocą AI
- Jak wyodrębniać dane ze strony internetowej za pomocą Thunderbit
- Jak opanować automatyczne scrapowanie danych z pomocą Thunderbit
- Octoparse vs Thunderbit: porównanie 2025 dla no-code web scraperów




