
Zdradzę Ci mały sekret: internet to w gruncie rzeczy największa biblioteka świata — tylko że większość książek jest „zaklejona”. Na co dzień rozmawiam z właścicielami firm, marketerami i zespołami sprzedaży, którzy doskonale czują, że na stronach www leży czyste złoto: specyfikacje produktów, ceny konkurencji, opinie klientów, dane kontaktowe. Schody zaczynają się wtedy, gdy trzeba zrobić wyodrębnianie tekstu ze strony. Przez lata pracy w SaaS i automatyzacji widziałem już wszystko: od „maratonów kopiuj-wklej” po „samodzielne przygody z Pythonem po godzinach”. Dobra wiadomość? Dziś wyciąganie tekstu ze strony jest prostsze (i dużo mniej bolesne) niż kiedykolwiek — dzięki nowym narzędziom typu AI 웹 스크래퍼 i sprytnym rozszerzeniom do przeglądarki.
W tym poradniku przeprowadzę Cię przez wszystkie praktyczne metody, które znam — od zwykłego kopiowania po zaawansowane rozwiązania oparte o AI, takie jak (tak, to produkt mojego zespołu, ale uczciwie omówię plusy i minusy). Niezależnie od tego, czy jesteś mistrzem arkuszy, programistą, czy po prostu masz dość gapienia się w strony, znajdziesz tu podejście krok po kroku dopasowane do Twoich potrzeb. Otwórzmy wreszcie te cyfrowe „książki” i wyciągnijmy z nich tekst, którego potrzebujesz.
Co właściwie znaczy „wyodrębnić tekst ze strony internetowej”?
Gdy mówimy o „wyodrębnianiu tekstu ze strony”, chodzi o przeniesienie informacji, które widzisz (a czasem także tych, których nie widać) na stronie www, do formatu, z którym da się realnie pracować — np. do arkusza, bazy danych albo po prostu do czystego dokumentu Word. Tyle że nie każdy „tekst na stronie” wygląda tak samo:
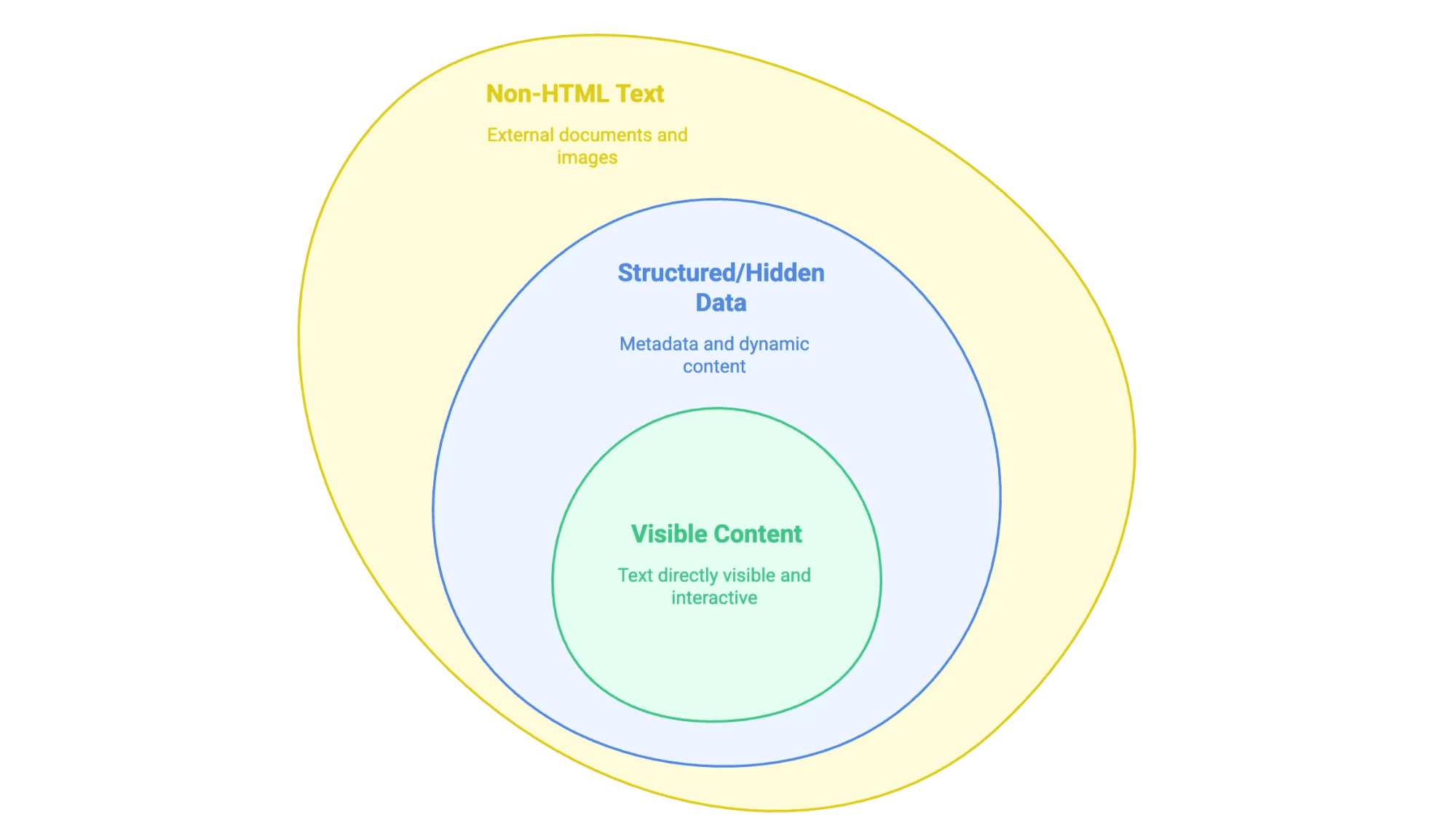
- Treść widoczna: wszystko, co możesz zaznaczyć myszką — akapity, nagłówki, listy, tabele, opisy produktów, wpisy blogowe itd.
- Dane ustrukturyzowane lub ukryte: np. metadane w tagach
<meta>, skrypty JSON-LD albo informacje ładowane przez JavaScript, które pojawiają się dopiero po kliknięciu lub przewinięciu. - Tekst poza HTML: PDF-y, dokumenty Word, a nawet obrazy z tekstem (np. skany umów czy infografiki) osadzone lub podlinkowane na stronie.
Klucz to wiedzieć, jakiego typu danych szukasz — bo każdy z nich wymaga innego podejścia.
Po co wyodrębniać tekst ze stron? Korzyści biznesowe i zastosowania
Bądźmy szczerzy: mało kto robi ekstrakcja danych ze stron „dla zabawy” (chyba że ma naprawdę nietypowe hobby). Firmy robią to, bo zwrot z inwestycji jest bardzo konkretny. Rynek oprogramowania do web scrapingu przekroczył i nadal rośnie. Oto dlaczego:
| Zespół | Przykład zastosowania | Korzyść |
|---|---|---|
| Sprzedaż | Zbieranie leadów i danych kontaktowych z katalogów | Szybsze i bogatsze prospectingowanie |
| Marketing | Wyciąganie wpisów konkurencji i danych SEO | Analiza luk w treści, wychwytywanie trendów |
| Operacje | Monitorowanie cen produktów w e-commerce | Dynamiczne ceny, śledzenie stanów |
| Nieruchomości | Agregowanie ofert i szczegółów nieruchomości | Analiza rynku, generowanie leadów |
| Obsługa klienta | Zbieranie opinii i pytań z forów | Analiza sentymentu, wczesne wykrywanie problemów |
Kilka przykładów z życia:

- Generowanie leadów: jedna firma z branży wyposażenia gastronomii w minuty zamiast w dni.
- Monitoring konkurencji: detaliści tacy jak John Lewis dzięki danym cenowym pozyskanym ze scrapingu.
- Analiza SEO: zespoły wyciągają meta tagi i słowa kluczowe, aby .
A dzięki narzędziom opartym o AI firmy oszczędzają w porównaniu do tradycyjnych metod.
Metody ręczne: podstawy kopiowania i wklejania tekstu ze strony
Zacznijmy od absolutnych podstaw. Czasem potrzebujesz tylko krótkiego fragmentu — bez instalowania czegokolwiek.
Jak ręcznie wyodrębnić tekst
- Kopiuj i wklej: otwórz stronę, zaznacz tekst i użyj Ctrl+C (albo prawy przycisk > Kopiuj). Następnie wklej do dokumentu lub arkusza.
- Zapisz stronę jako: w przeglądarce wybierz Plik > Zapisz stronę jako. Zapisz jako „Strona internetowa, tylko HTML”, aby mieć surowy HTML, albo czasem jako .txt, by dostać sam tekst.
- Drukuj do PDF: w oknie drukowania wybierz „Zapisz jako PDF”. Potem otwórz PDF i skopiuj tekst (albo użyj funkcji „Zapisz jako tekst” w czytniku PDF).
- Narzędzia deweloperskie: prawy przycisk > Zbadaj (Inspect) lub F12, aby otworzyć DevTools. Możesz podejrzeć źródło HTML, znaleźć meta tagi lub ukryty JSON i skopiować to, czego potrzebujesz.
Ograniczenia
Ręczne wyciąganie danych jest OK przy jednorazowych zadaniach, ale przy większej skali robi się z tego koszmar. Jest . Widziałem, jak stażyści przez dni przepisywali tabele wiersz po wierszu — serio, nikt nie chce takiej roboty.
Rozszerzenia przeglądarki i narzędzia online do wyodrębniania tekstu
Czas wejść poziom wyżej. Rozszerzenia i narzędzia online to dla większości osób biznesowych idealny kompromis: bez kodu, bez spiny — wskazujesz i klikasz.
Dlaczego warto z nich korzystać?

- Szybciej niż ręczne kopiowanie
- Bez programowania
- Obsługa tabel, list, a czasem także plików
- Eksport do Excel, Google Sheets, CSV itd.
Przejdźmy przez najpopularniejsze opcje.
Thunderbit: AI Web Scraper do szybkiego i precyzyjnego wyciągania tekstu
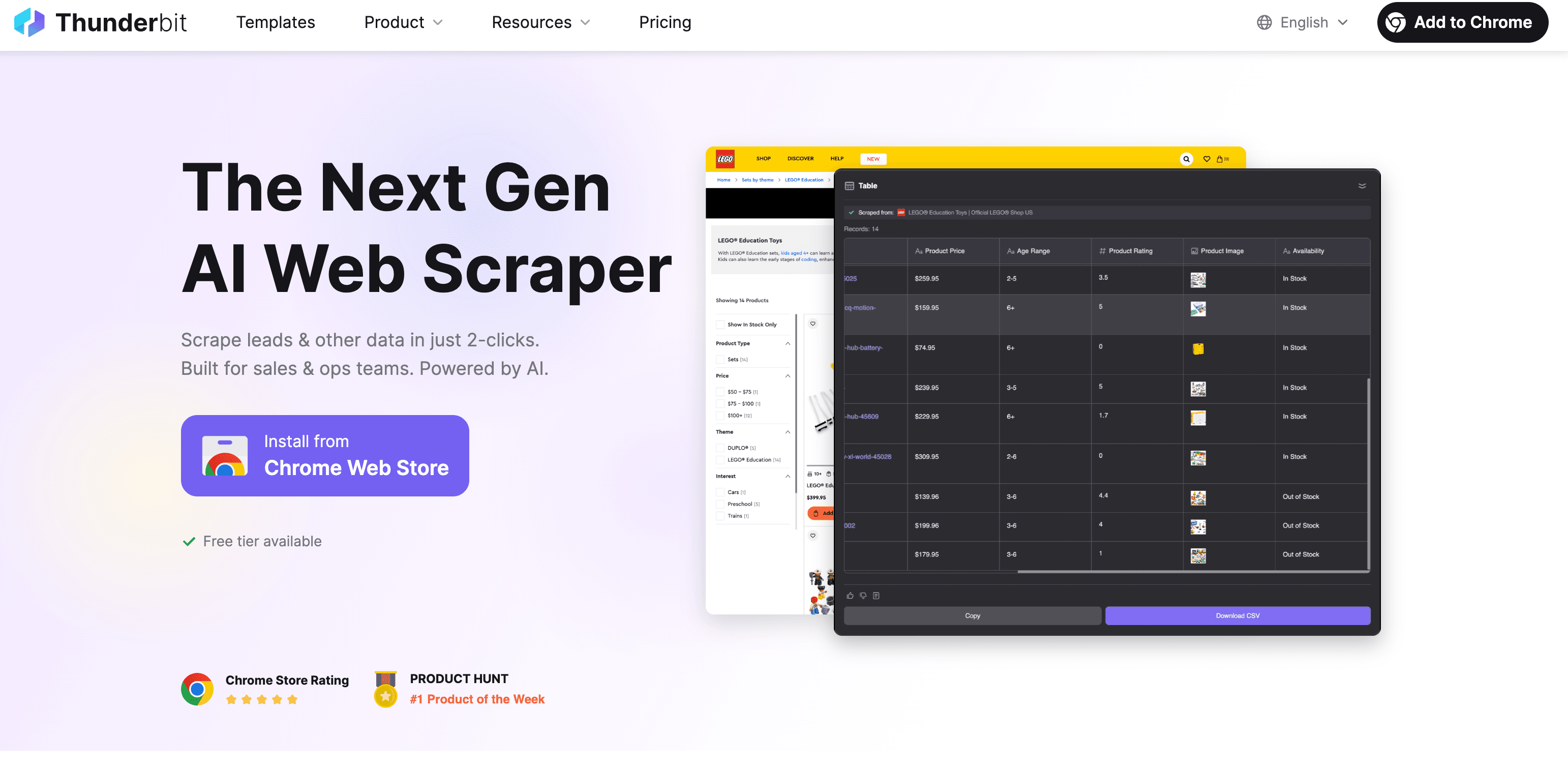
Jasne, mam tu swoje sympatie, ale powstał po to, żeby wyodrębnianie tekstu ze strony było tak proste, jak zamówienie jedzenia na wynos. Jak to działa?
Krok po kroku: wyodrębnianie tekstu w Thunderbit
- Zainstaluj rozszerzenie do Chrome: pobierz z Chrome Web Store.
- Otwórz stronę: przejdź do witryny, z której chcesz wyciągnąć tekst.
- Kliknij „AI Suggest Fields”: AI Thunderbit skanuje stronę i proponuje pola (kolumny) do pobrania — np. nazwa produktu, cena, opis itd.
- Sprawdź i dopasuj: możesz edytować propozycje lub dodać własne pola.
- Kliknij „Scrape”: Thunderbit pobiera dane — także z podstron lub list z paginacją, jeśli trzeba.
- Eksport: pobierz dane do Excel, Google Sheets, Airtable, Notion albo jako CSV/JSON. Eksport jest bez dodatkowych opłat.
Co wyróżnia Thunderbit?
- Sugestie pól oparte o AI: bez zabawy w selektory i bez kodu — AI samo rozpoznaje, co na stronie jest istotne.
- Obsługa podstron i paginacji: chcesz szczegóły z każdej karty produktu w kategorii? Thunderbit przejdzie po nich automatycznie.
- Wyciąganie tekstu z PDF-ów, obrazów i dokumentów: masz instrukcję w PDF albo obraz ze specyfikacją? Wbudowany OCR w Thunderbit też to odczyta.
- Wielojęzyczność: działa w 34 językach (na Klingoński jeszcze czekam, ale pracujemy nad tym).
- Darmowy eksport danych: bez paywalla na etapie pobierania wyników.
- Zastosowania: opisy produktów, dane kontaktowe, treści blogowe, listy leadów — co tylko chcesz.
Chcesz zobaczyć to w praktyce? Zajrzyj na — znajdziesz tam poradniki takie jak .
Inne rozszerzenia i narzędzia online
Warto też wspomnieć o kilku narzędziach, na które możesz się natknąć:
- Web Scraper (): darmowy i „klikany”, ale wymaga chwili ogarnięcia. Super dla bardziej technicznych analityków — trzeba skonfigurować „sitemapy” i selektory. Obsługuje paginację, ale nie PDF-y ani obrazy. .
- CopyTables: banalnie proste — kopiuje tabele HTML do schowka lub do Excela. Idealne do szybkiego, jednorazowego pobrania tabeli, ale działa tylko na jednej stronie naraz i wyłącznie dla tabel. .
- ScraperAPI (): opcja dla programistów. Wysyłasz URL, dostajesz HTML (z obsługą proxy, blokad itd.), ale tekst musisz już samodzielnie sparsować. .
Kiedy wybrać które narzędzie?
- Thunderbit: gdy liczy się szybkość, wsparcie AI i obsługa wielu formatów (w tym PDF/obrazy).
- Web Scraper: gdy lubisz „dłubać” i chcesz większej kontroli.
- CopyTables: gdy potrzebujesz tylko tabeli — na już.
- ScraperAPI: gdy budujesz własny scraper w kodzie.
Automatyczny web scraping: rozwiązania programistyczne do wyciągania tekstu
Jeśli jesteś programistą (albo masz go pod ręką), własny web scraper daje pełną kontrolę. Podstawowy schemat wygląda tak:
- Wyślij żądanie HTTP: użyj np.
requestsw Pythonie, aby pobrać stronę. - Sparsuj HTML: użyj
BeautifulSoup,lxmllubScrapy, aby znaleźć interesujący Cię tekst. - Wyciągnij i wyeksportuj: pobierz tekst, oczyść go i zapisz do CSV, JSON lub bazy danych.
Przykład: Python + Beautiful Soup
1import requests
2from bs4 import BeautifulSoup
3url = "<http://quotes.toscrape.com>"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
7for qt in quotes:
8 print(qt)Plusy i minusy
- Plusy: maksymalna elastyczność, możliwość obsługi dowolnej strony i typu danych, łatwa integracja z systemami.
- Minusy: wymaga umiejętności programowania, stałego utrzymania oraz ogarniania zabezpieczeń anty-bot.
Kiedy warto iść tą drogą
- Gdy musisz zebrać dane z tysięcy (albo milionów) stron.
- Gdy strona jest złożona (logowanie, wieloetapowe formularze).
- Gdy chcesz wbudować scraping bezpośrednio w aplikację lub proces.
Wyodrębnianie tekstu z formatów nie-HTML: PDF, Word i obrazy
Strony www to nie tylko HTML — często zawierają PDF-y, dokumenty Word i obrazy z cennym tekstem. Oto jak się do tego zabrać:
- PDF-y tekstowe: użyj narzędzi typu Adobe Acrobat albo bibliotek
PDFMinerczyPyPDF2, aby wyciągnąć tekst. - PDF-y skanowane: użyj OCR (Optical Character Recognition), np. Tesseract, lub .
Dokumenty Word/Excel
- Word:
python-docxdo odczytu plików .docx. - Excel:
openpyxllubpandasdla .xlsx.
Obrazy
- Narzędzia OCR: Tesseract jako open-source albo usługi chmurowe dla wyższej skuteczności. Najlepiej działają obrazy dobrej jakości (150–300 DPI).
Podejście Thunderbit
Funkcja „Image/Document Parser” pozwala wgrać plik lub podać link do PDF, obrazu czy dokumentu, a AI wyciągnie tekst (i nawet zaproponuje kolumny, jeśli wykryje tabelę). Bez żonglowania kilkoma narzędziami — pliki traktujesz jak kolejną „stronę”.
Porównanie metod: które rozwiązanie do wyodrębniania tekstu wybrać?
Szybkie zestawienie, które ułatwi decyzję:
| Metoda | Łatwość użycia | Skalowalność | Wymagane umiejętności techniczne | Obsługiwane typy danych | Najlepsze dla |
|---|---|---|---|---|---|
| Ręcznie (kopiuj-wklej) | Bardzo łatwa | Niska | Brak | Tylko widoczny tekst | Jednorazowe, małe zadania |
| Rozszerzenia/narzędzia | Łatwa–umiarkowana | Średnia | Niska–średnia | HTML, część tabel | Użytkownicy nietechniczni, małe–średnie zadania |
| Narzędzia AI (Thunderbit) | Bardzo łatwa | Wysoka | Brak | HTML, PDF, obrazy i więcej | Biznes, mieszane źródła |
| Programowanie (kod) | Trudna | Bardzo wysoka | Wysoka | Dowolne (z odpowiednimi bibliotekami) | Programiści, duża skala |
| Nie-HTML (OCR) | Umiarkowana | Niska–średnia | Średnia | PDF, obrazy, dokumenty | Gdy kluczowe są pliki/obrazy |
Jeśli zależy Ci na najszybszej, najbardziej elastycznej i najmniej stresującej opcji — szczególnie w zastosowaniach biznesowych — narzędzia AI takie jak Thunderbit są trudne do pobicia. Jeśli jednak potrzebujesz pełnej kontroli albo działasz w ogromnej skali, własny kod może mieć więcej sensu.
Najważniejsze wnioski: zacznij wyodrębniać tekst ze stron już dziś
- Internet jest pełen wartościowych danych tekstowych, ale nie zawsze łatwo je wydobyć.
- Metody ręczne sprawdzają się przy drobnych zadaniach, ale nie skalują się.
- Rozszerzenia i AI 웹 스크래퍼, takie jak , sprawiają, że wyodrębnianie tekstu jest szybkie, dokładne i dostępne dla każdego — bez kodowania.
- Przy treściach nie-HTML (PDF, obrazy) wybieraj narzędzia z wbudowanym OCR i parserem dokumentów.
- Dobierz metodę do kompetencji zespołu, skali projektu i rodzaju potrzebnych danych.
Udanych scrapów — i oby dni spędzonych na Ctrl+C było jak najmniej. Z odpowiednimi narzędziami pozyskiwanie danych z sieci może stać się płynnym, zautomatyzowanym procesem, który odda Ci czas na ważniejsze zadania. Koniec z godzinami kopiowania i wklejania — zamiast tego inteligentne, wydajne rozwiązania na wyciągnięcie ręki. Czas pożegnać ręczną harówkę i wejść w bardziej produktywną przyszłość.
FAQ
P1: Czy mogę scrapować dane z każdej strony?
O1: Nie zawsze. Niektóre serwisy blokują scrapery albo mają regulaminy, które zabraniają scrapingu. Zawsze najpierw sprawdź zasady danej strony.
P2: Jak dokładne są web scrapery oparte o AI?
O2: Narzędzia oparte o AI, takie jak Thunderbit, są bardzo dokładne, ale przy złożonych lub mocno dynamicznych stronach czasem trzeba wprowadzić drobne korekty.
P3: Czy do korzystania z narzędzi do web scrapingu potrzebuję umiejętności programowania?
O3: Nie. Thunderbit i inne rozszerzenia do przeglądarki są tworzone z myślą o osobach nietechnicznych i nie wymagają kodowania.
P4: Jakie dane mogę wyciągnąć z PDF-ów lub obrazów?
O4: Narzędzia OCR potrafią wyodrębniać tekst, tabele, a czasem także dane „ukryte” ze skanowanych PDF-ów i obrazów, co znacząco poszerza możliwości pozyskiwania danych.
Czytaj więcej