W biurach na całym świecie trwa cicha rewolucja — i wcale nie chodzi o stoły do ping-ponga ani kombuchę z kranu. Chodzi o „łatwe pozyskiwanie danych z sieci” (easy web extract): możliwość, żeby każdy — nie tylko 개발자 — potrafił w kilka minut wyciągnąć z internetu konkretne informacje, zamiast męczyć się z tym całymi dniami. Jeśli kiedykolwiek patrzyłeś na stronę i pomyślałeś: „Gdybym mógł po prostu zebrać te nazwy, ceny albo e-maile i wkleić do arkusza”, to serio — nie jesteś sam. Rozmawiałem z handlowcami, marketerami i ludźmi z operacji — wszyscy mówili to samo: „Dlaczego to wciąż jest takie trudne?”
Prawda jest taka, że zapotrzebowanie na proste metody web scrapingu rośnie w tempie, które potrafi zaskoczyć. Według 65% organizacji korzysta dziś z generatywnej AI w co najmniej jednym obszarze biznesowym, a ekstrakcja danych z internetu błyskawicznie wskakuje do topki najbardziej pożądanych zastosowań. Rynek web scrapingu ma dobić do , a użytkownicy biznesowi — szczególnie ci bez technicznego zaplecza — napędzają popyt na narzędzia, które robią z pozyskiwania danych coś tak prostego jak kopiuj-wklej. Tylko co tak naprawdę oznacza „easy web extract” i jak wykorzystać to, żeby ułatwić sobie robotę? Rozłóżmy to na czynniki pierwsze.
Easy Web Extract dla osób nietechnicznych: zero kodu, zero bólu głowy
Zacznijmy od podstaw: czym jest „easy web extract”? Najprościej mówiąc: to zamiana chaotycznej, ciągle zmieniającej się sieci w czyste, uporządkowane tabelki — bez napisania choćby jednej linijki kodu. Dla nietechnicznych użytkowników biznesowych to game changer. Koniec z proszeniem IT o pomoc, koniec z siłowaniem się ze skryptami w Pythonie i koniec z odpuszczaniem, gdy strona z dnia na dzień zmieni układ.
Dlaczego to jest dziś tak ważne? Internet jest bardziej dynamiczny niż kiedykolwiek. Strony lecą na infinite scroll, wyskakujące okienka i złożony JavaScript, który potrafi „położyć” klasyczne scrapery raz za razem. A jednocześnie presja na zespoły biznesowe, żeby dowozić wnioski szybko, nigdy nie była większa. W 98% organizacji twierdzi, że publiczne dane z internetu są kluczowe lub bardzo ważne dla ich działań, a ponad połowa korzysta z nich codziennie.
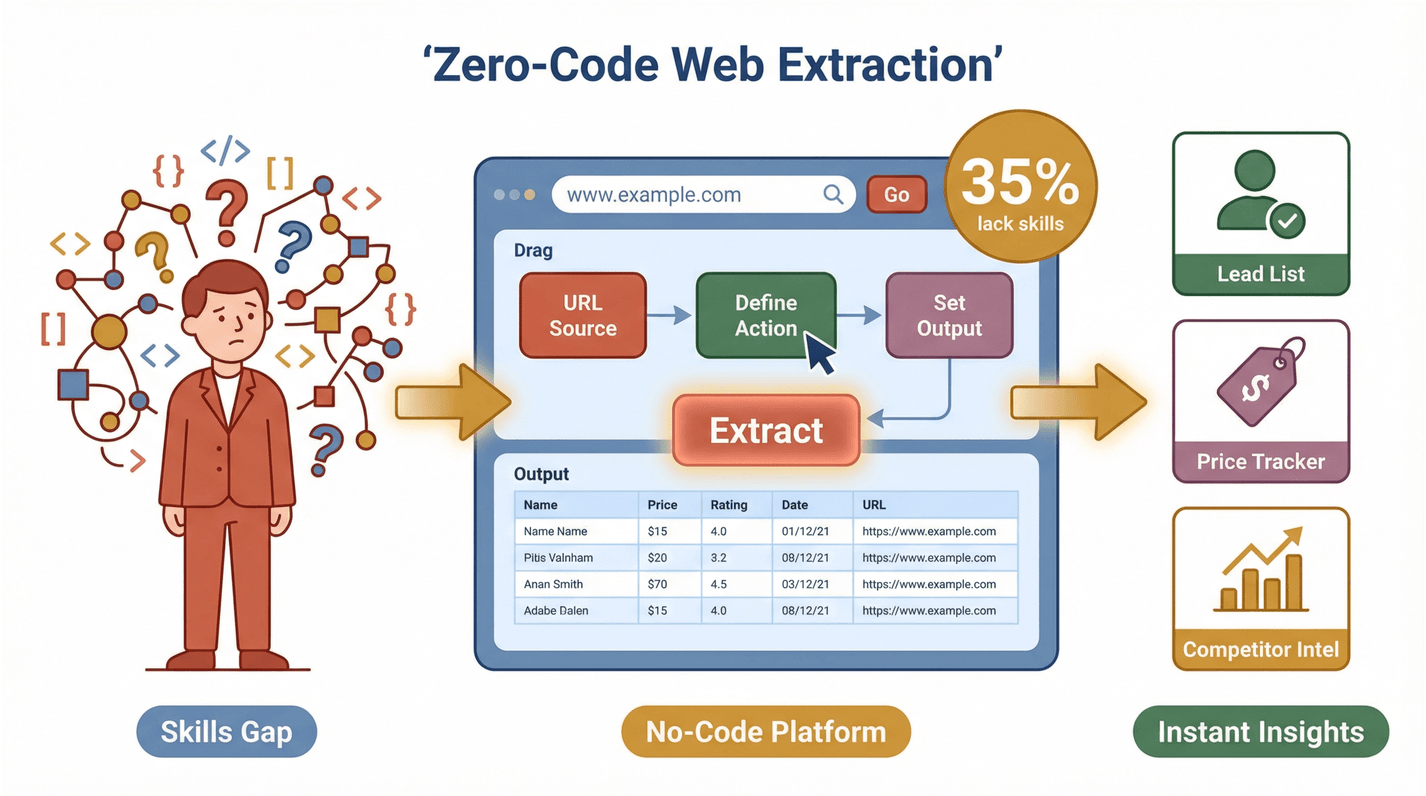
Jest jednak haczyk: większość tych zespołów nie jest techniczna. Z ostatniego badania wynika, że 35% organizacji nie ma odpowiednich kompetencji do pozyskiwania danych z sieci, a 33% nie dysponuje właściwymi narzędziami. To ogromna szansa dla rozwiązań no-code. Gdy każdy może wyciągać i wykorzystywać dane z internetu, produktywność wskakuje na nowy poziom — niezależnie od tego, czy budujesz listę leadów, śledzisz konkurencję, czy monitorujesz ceny.
Ruch no-code/low-code: dlaczego to ma znaczenie
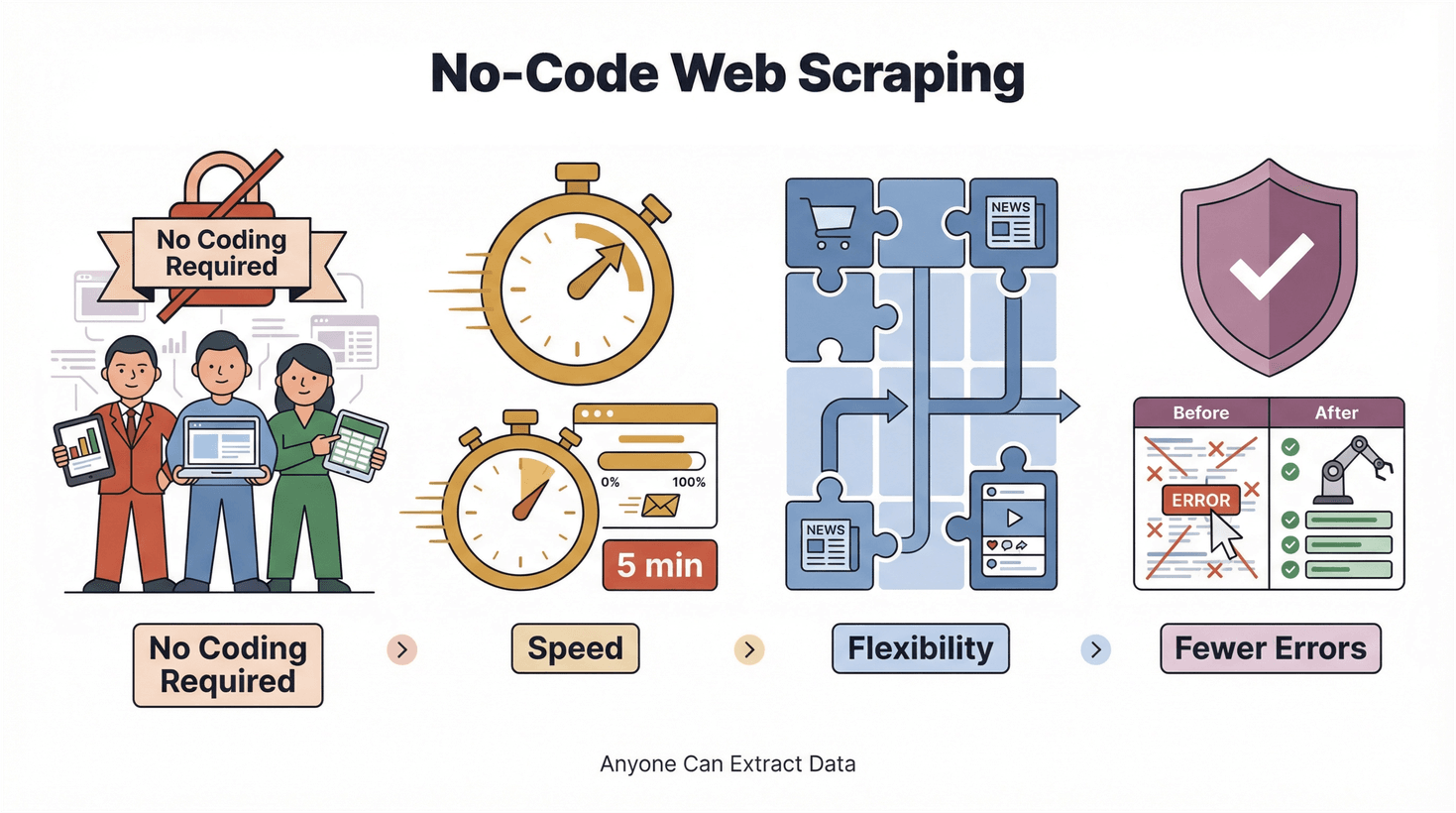
Wzrost popularności narzędzi no-code i low-code to prawdziwa demokratyzacja technologii. To nie tylko modne hasło z Doliny Krzemowej, ale realna zmiana w tym, jak wygląda praca na co dzień. W kontekście web scrapingu oznacza to:
- Bez programowania: dane może pozyskiwać każdy, nie tylko inżynierowie.
- Szybkość: wyniki w minutach, a nie w dniach.
- Elastyczność: natychmiastowe dopasowanie do nowych stron i potrzeb.
- Mniej błędów: automatyzacja ogranicza pomyłki z kopiuj-wklej.
Najlepsze jest to, że nie musisz zostać technologicznym 마법사, żeby z tego skorzystać.
Dlaczego tradycyjne narzędzia do web scrapingu tak frustrują
Bądźmy szczerzy: klasyczne narzędzia do web scrapingu często wyglądają tak, jakby były robione przez programistów i dla programistów — a nie dla użytkowników biznesowych. Widziałem to wielokrotnie: zespół nakręca się na nowy projekt, po czym rozbija się o ścianę, gdy narzędzie prosi o selektory CSS, XPath albo wyrażenia regularne. I nagle pojawiają się „szklane oczy” oraz maile w stylu „wróćmy do tego w następnym kwartale”.
Najczęściej sypie się to w kilku miejscach:
- Wymagany kod: wiele starszych rozwiązań oczekuje skryptów lub skomplikowanej konfiguracji.
- Uciążliwe wdrożenie: trzeba mapować pola, ogarniać logowanie i ustawiać proxy, żeby nie dostać blokady.
- Krucha logika: strona zmienia układ i scraper przestaje działać. Zamiast pracy — debugowanie.
- Koszt utrzymania: każda aktualizacja strony to powrót do punktu wyjścia.
Nic dziwnego, że według największe wyzwania techniczne w web scrapingu to blokowanie/bany IP (56%), dynamiczna treść (55%) oraz CAPTCHA (52%). Nawet dojrzałe zespoły mają z tym problem.
Tymczasem użytkownicy biznesowi chcą po prostu prostego i niezawodnego sposobu, by przenieść dane do arkusza lub CRM. I tu wchodzą easy web extract oraz proste metody web scrapingu.
Jak Thunderbit umożliwia easy web extract
Tu robi się ciekawie — bo dokładnie ten problem postanowiliśmy rozwiązać w . Naszym celem jest web scraping tak prosty, żeby mógł go zrobić każdy, niezależnie od doświadczenia technicznego.
Thunderbit to , które zamienia ekstrakcję danych w proces na dwa kliknięcia. Jak to działa?
- Opisz, czego potrzebujesz: użyj zwykłego języka, aby powiedzieć Thunderbit, jakie dane chcesz zebrać. Np. „Wyciągnij nazwy produktów i ceny z tej strony”.
- Kliknij „AI Suggest Fields”: AI Thunderbit analizuje stronę i proponuje najlepsze kolumny do pobrania — np. „Nazwa”, „Cena”, „E-mail” czy „Obraz”.
- Kliknij „Scrape”: Thunderbit robi resztę: obsługuje paginację, podstrony, a w razie potrzeby także treści dostępne po zalogowaniu.
I tyle. Bez kodu, bez szablonów, bez bólu konfiguracji. Interfejs jest zaprojektowany dla zespołów sprzedaży, marketingu, e-commerce czy nieruchomości — dla osób, które chcą po prostu efektu.
Przepływ pracy oparty o AI w Thunderbit: mądrzej, nie ciężej
Cała „magia” tkwi w AI. Thunderbit nie zgaduje na ślepo — czyta stronę, rozumie kontekst i automatycznie porządkuje dane. Jeśli chcesz, możesz dodać własne instrukcje dla pól (np. „skategoryzuj tę kolumnę” albo „przetłumacz na angielski”), ale większość użytkowników po prostu klika i działa.
Takie podejście oparte o AI oznacza:
- Mniej błędów: AI dopasowuje się do różnych układów, więc wyniki są spójne nawet po zmianach na stronie.
- Szybszy start: bez budowania szablonów i bez skryptów.
- Dane gotowe do działania: Thunderbit potrafi etykietować, kategoryzować i wzbogacać dane już w trakcie pobierania.
Jeśli chcesz wejść głębiej, zajrzyj do albo do naszego . Na znajdziesz też inne poradniki, np. oraz .
Unikalne funkcje Thunderbit dla prostych metod web scrapingu
Thunderbit wyróżnia nie tylko AI, ale cały przepływ pracy zaprojektowany pod realne potrzeby biznesu. Oto funkcje, które użytkownicy szczególnie cenią:
- Automatyczna paginacja: Thunderbit obsługuje strony wielostronicowe i nieskończone przewijanie bez konfiguracji.
- Scraping podstron: potrzebujesz więcej szczegółów? Thunderbit może odwiedzać podstrony (np. karty produktów czy profile LinkedIn) i automatycznie wzbogacać zestaw danych.
- Eksport gdzie chcesz: wyślij dane prosto do Excel, Google Sheets, Airtable, Notion albo pobierz jako CSV/JSON. Koniec z maratonami kopiuj-wklej.
- Działa na stronach po zalogowaniu: Thunderbit działa w przeglądarce, więc „widzi” to, co Ty.
- Etykietowanie i kategoryzacja z AI: dodaj instrukcje, aby klasyfikować, tagować lub tłumaczyć dane podczas ekstrakcji.
- Scheduled Scraper: ustaw cykliczne zadania, by dane były zawsze aktualne — idealne do monitoringu cen lub leadów.
Tak, to wszystko jest dostępne w narzędziu, któremu zaufało ponad .
Automatyczna paginacja i ekstrakcja z podstron
Jednym z największych problemów w web scrapingu jest paginacja list oraz zagnieżdżone strony ze szczegółami. Z Thunderbit nie musisz się tym przejmować. AI wykrywa paginację (przycisk „Dalej” albo infinite scroll) i automatycznie podąża za linkami do podstron. Dzięki temu możesz pobrać setki lub tysiące rekordów za jednym razem — bez ręcznego klikania.
Przykład: jeśli zbierasz listę produktów z Amazon, Thunderbit może pobrać produkty z wielu stron, a potem wejść w każdą kartę produktu, by wyciągnąć opinie, oceny czy informacje o sprzedawcy. To jak niestrudzony asystent, który nigdy się nie nudzi.
Eksport w wielu formatach i integracja z CRM
Dane mają wartość dopiero wtedy, gdy da się je wykorzystać. Thunderbit pozwala eksportować wyniki w formacie, którego potrzebuje zespół — Excel, Google Sheets, Airtable, Notion lub CSV/JSON. Możesz też przesyłać dane bezpośrednio do CRM lub narzędzi workflow, aby sprzedaż i operacje zawsze miały aktualne informacje.
Taka integracja oszczędza mnóstwo czasu. Bez czyszczenia brudnych eksportów i bez ręcznego formatowania kolumn — AI Thunderbit ogarnia to za Ciebie.
Przykłady zastosowań easy web extract w praktyce
Gdzie easy web extract daje największy efekt? Oto scenariusze, które często widzę u użytkowników Thunderbit:
Pozyskiwanie leadów dla sprzedaży
Zespoły sprzedaży żyją listami leadów. Z Thunderbit możesz w kilka minut zebrać dane kontaktowe z LinkedIn, Google Maps czy katalogów firm. Wystarczy otworzyć stronę, kliknąć „AI Suggest Fields”, a Thunderbit przeniesie imiona i nazwiska, e-maile, telefony oraz dane firmy do arkusza gotowego do użycia.
Jeden z menedżerów sprzedaży powiedział mi, że wcześniej zespół tracił co tydzień godziny na kopiowanie leadów. Teraz, dzięki Thunderbit, budują precyzyjne listy w ułamku czasu — a handlowcy skupiają się na kontakcie, nie na wklepywaniu danych.
E-commerce i monitoring rynku
Zespoły e-commerce używają Thunderbit do śledzenia SKU konkurencji, cen i opinii na Amazon, Shopify i innych platformach. Chcesz monitorować zmiany cen albo nowe premiery? Ustaw cykliczne pobieranie i dostawaj świeże dane do Google Sheet każdego ranka.
Scraping podstron jest tu szczególnie przydatny — możesz pobierać szczegóły produktu, zdjęcia, a nawet recenzje klientów bez kiwnięcia palcem.
Zbieranie danych w branży nieruchomości
Specjaliści od nieruchomości wykorzystują Thunderbit do zbierania ofert, cen i danych agentów z serwisów takich jak Zillow czy Realtor.com. AI obsługuje paginację i podstrony, więc dostajesz pełny, aktualny obraz rynku — idealny do analiz lub raportów dla klientów.
Jeden analityk nieruchomości przyznał, że to, co wcześniej zajmowało całe popołudnie, teraz wymaga kilku kliknięć. Na tym polegają proste metody web scrapingu.
Porównanie: tradycyjne podejście vs proste metody web scrapingu
Zbierzmy to w jedno zestawienie:
| Funkcja | Tradycyjne scrapery | Easy Web Extract (Thunderbit) |
|---|---|---|
| Wymagany kod | Tak (skrypty, selektory) | Nie (AI + język naturalny) |
| Czas konfiguracji | Duży (szablony, ustawienia) | Mały (2 kliknięcia) |
| Utrzymanie | Częste (psuje się po zmianach na stronie) | Minimalne (AI się dopasowuje) |
| Obsługa paginacji | Ręczna konfiguracja | Automatyczna |
| Ekstrakcja z podstron | Złożona logika | 1 kliknięcie |
| Formaty eksportu | Często ograniczone | Excel, Sheets, Airtable, Notion, CSV, JSON |
| Działa po zalogowaniu | Czasem (po konfiguracji) | Tak (w przeglądarce) |
| Etykietowanie/kategoryzacja | Ręczne po obróbce | Wbudowane, oparte o AI |
| Harmonogram/monitoring | Czasem (zaawansowane) | Tak (łatwa konfiguracja) |
Różnica jest ogromna. Z Thunderbit każdy może pozyskiwać, porządkować i wykorzystywać dane z internetu — bez umiejętności technicznych.
Trendy przyszłości: easy web extract i proste metody web scrapingu
Patrząc w przyszłość, easy web extract ma przed sobą naprawdę mocne perspektywy. AI staje się coraz bardziej 똑똑해, a popyt na narzędzia no-code rośnie bardzo szybko. Według 78% organizacji korzysta z AI w co najmniej jednym obszarze, a na znaczeniu zyskują systemy agentowe — narzędzia AI, które potrafią realizować wieloetapowe procesy w sieci.
Co to oznacza dla użytkowników biznesowych? Więcej możliwości i mniej uciążliwości. Wraz z rozwojem AI zobaczymy:
- Jeszcze lepsze wykrywanie pól: AI będzie rozumiała bardziej złożone dane i zależności.
- Lepsze integracje: bezpośrednie połączenia z większą liczbą narzędzi i platform.
- Większą niezawodność: mniej awarii i bardziej spójne wyniki, nawet na stronach dynamicznych lub chronionych.
- Większą dostępność: ekstrakcja danych z sieci stanie się standardową umiejętnością, nie tylko dla „technicznych”.
I tak — Thunderbit jest w samym centrum tego trendu.
Podsumowanie i najważniejsze wnioski
Internet to największa baza danych na świecie — ale do niedawna dostęp do niej mieli głównie programiści. To szybko się zmienia. Dzięki easy web extract i prostym metodom web scrapingu każdy może w kilka minut zamienić strony WWW w dane gotowe do działania.
Oto, co warto zapamiętać:
- Ekstrakcja danych bez kodu zostaje z nami na długo: narzędzia takie jak Thunderbit pozwalają każdemu zbierać i wykorzystywać dane z sieci — bez zaplecza technicznego.
- AI to klucz: automatyzacja doboru pól, paginacji, podstron i etykietowania oszczędza czas i ogranicza błędy.
- Wpływ na biznes jest realny: sprzedaż, e-commerce i nieruchomości już widzą wzrost produktywności, świeższe dane i lepsze decyzje.
- Przyszłość wygląda jeszcze lepiej: wraz z rozwojem AI i no-code, pozyskiwanie danych z internetu stanie się tak powszechne jak wysyłanie e-maila.
Jeśli masz dość ręcznego kopiowania, irytują Cię „psujące się” scrapery albo po prostu chcesz zobaczyć, co jest możliwe — wypróbuj . Możesz i zacząć pozyskiwać dane za darmo — bez konfiguracji, bez kodu, bez stresu.
A jeśli chcesz zgłębić temat, zajrzyj na po więcej poradników, wskazówek i przykładów z życia.
FAQ
1. Czym jest „easy web extract” i dla kogo jest przeznaczone?
Easy web extract to metody web scrapingu bez kodu, oparte o AI, które pozwalają każdemu — zwłaszcza nietechnicznym użytkownikom biznesowym — szybko i łatwo pozyskiwać uporządkowane dane ze stron internetowych. To świetne rozwiązanie dla sprzedaży, marketingu, e-commerce i zespołów operacyjnych, które potrzebują danych gotowych do działania bez technicznych komplikacji.
2. Czym Thunderbit różni się od tradycyjnych narzędzi do web scrapingu?
Thunderbit wykorzystuje AI do automatyzacji wyboru pól, paginacji i ekstrakcji z podstron. W przeciwieństwie do klasycznych scraperów, które wymagają kodu lub złożonych szablonów, Thunderbit pozwala opisać potrzeby zwykłym językiem i pobrać dane w dwóch kliknięciach.
3. Czy Thunderbit radzi sobie ze stronami dynamicznymi lub wielostronicowymi?
Tak. Thunderbit automatycznie wykrywa i obsługuje paginację (w tym infinite scroll) oraz potrafi przechodzić do podstron, aby pobierać bardziej szczegółowe dane — przy minimalnej konfiguracji.
4. Jakie opcje eksportu obsługuje Thunderbit?
Thunderbit umożliwia eksport danych bezpośrednio do Excel, Google Sheets, Airtable, Notion, CSV lub JSON. Możesz też integrować się z CRM i innymi narzędziami workflow, aby usprawnić procesy biznesowe.
5. Czy korzystanie z narzędzi easy web extract, takich jak Thunderbit, jest bezpieczne i etyczne?
Thunderbit promuje odpowiedzialny i etyczny web scraping. Zawsze przestrzegaj regulaminu serwisu, unikaj pozyskiwania danych osobowych bez zgody i stosuj ograniczanie tempa zapytań, aby nie zakłócać działania usług. Więcej o dobrych praktykach znajdziesz w .
Chcesz odblokować potencjał danych z internetu? Wypróbuj Thunderbit i zobacz, jak easy web extract może usprawnić Twoją pracę.
Dowiedz się więcej