Jeśli rozglądasz się za narzędziem do web scraping, jest spora szansa, że po drodze wpadł Ci w oko diffbot. To marka z mocną pozycją w świecie ekstrakcji danych — szczególnie dla tych, którzy muszą zamienić chaotyczny internet w czyste, uporządkowane rekordy. Tylko czy to opcja dla każdego? Niekoniecznie. Jeśli działasz po stronie biznesu, siedzisz w sprzedaży, marketingu albo po prostu chcesz zautomatyzować zbieranie danych z sieci bez kodu (serio: bez ani jednej linijki), Diffbot potrafi przytłoczyć — a czasem jest po prostu „za ciężki” jak na codzienne potrzeby. I właśnie tutaj wchodzi thunderbit.
Spędziłem sporo czasu, porównując oba podejścia: przekopałem opinie użytkowników i przetestowałem narzędzia na własnej skórze. W tym wpisie pokażę, co dokładnie daje Diffbot, w czym faktycznie jest świetny, gdzie potrafi utrudnić życie oraz dlaczego w 2025 roku Thunderbit może być dla większości osób sprytniejszą, prostszą i tańszą opcją — czyli po prostu najlepsza alternatywa.
Czym jest Diffbot?
Zacznijmy od podstaw. Diffbot to firma z Doliny Krzemowej, założona przez Mike’a Tunga, obecna na rynku od ponad dekady. Ich misja? Sprawić, żeby cała sieć była „czytelna dla maszyn”. Diffbot wykorzystuje zaawansowane AI, uczenie maszynowe i computer vision, żeby „widzieć” strony internetowe podobnie jak człowiek, a potem wyciągać z nich wartościowe informacje — np. dane o produktach, artykuły, informacje o firmach i sporo więcej — w ustrukturyzowanych formatach, które da się realnie wykorzystać.
Kluczowe produkty
- Extract API: Automatycznie analizuje praktycznie dowolną stronę (np. newsy, e-commerce, fora) i zwraca ustrukturyzowane dane w JSON. Bez ręcznego klepania reguł dla każdej witryny.
- Crawlbot: Crawler, który potrafi przejść całe domeny lub listy URL-i i wyciągać dane na dużą skalę.
- Natural Language API: Zestaw narzędzi do analizy tekstu, rozpoznawania encji, sentymentu oraz budowania własnych grafów wiedzy.
- Knowledge Graph: „Perła w koronie” Diffbota — ogromna, przeszukiwalna baza miliardów encji (ludzi, firm, produktów, artykułów) i bilionów faktów zebranych z publicznej sieci.
- Lead Intelligence (LeadGraph): Usługa do wyszukiwania i wzbogacania leadów poprzez łączenie danych o osobach i organizacjach.
Najważniejsze funkcje
- Parsowanie stron oparte na AI
- Web crawling na dużą skalę
- Przetwarzanie języka naturalnego (NLP)
- Gotowy, globalny Knowledge Graph
- Podejście „API-first” do integracji z własnymi procesami
W skrócie: Diffbot zamienia dziką, nieustrukturyzowaną sieć w wielką, przeszukiwalną bazę danych. To naprawdę potężne rozwiązanie, z którego korzystają m.in. Adobe, Cisco, DuckDuckGo, eBay i Microsoft.
Dla kogo jest Diffbot?
Tu robi się ciekawie. Diffbot jest projektowany głównie pod programistów, inżynierów danych i zespoły techniczne — zwłaszcza w średnich i dużych firmach. Jeśli masz dev team, rozbudowany pipeline danych i potrzebujesz crawlowania oraz analizy internetu na masową skalę, Diffbot będzie bardzo sensownym wyborem. Często pojawia się w monitoringu mediów, badaniach rynku, e-commerce oraz projektach AI/ML.
A jeśli nie jesteś developerem? Jeśli jesteś menedżerem sales ops, marketerem, agentem nieruchomości albo analitykiem e-commerce, który chce po prostu pobrać dane bez nauki API i języków zapytań — Diffbot może przypominać używanie rakiety do podjazdu po zakupy. Mega moc, ale mało przyjazna dla osób bez technicznego zaplecza.
To jeden z głównych powodów, dla których wielu użytkowników biznesowych szuka alternatyw: czegoś prostego, szybkiego i bez konieczności robienia „informatycznego doktoratu”. (Spoiler: dokładnie do tego stworzono .)
Cennik Diffbot
Przejdźmy do pieniędzy. Cennik Diffbota jest wyraźnie ustawiony pod klientów enterprise.
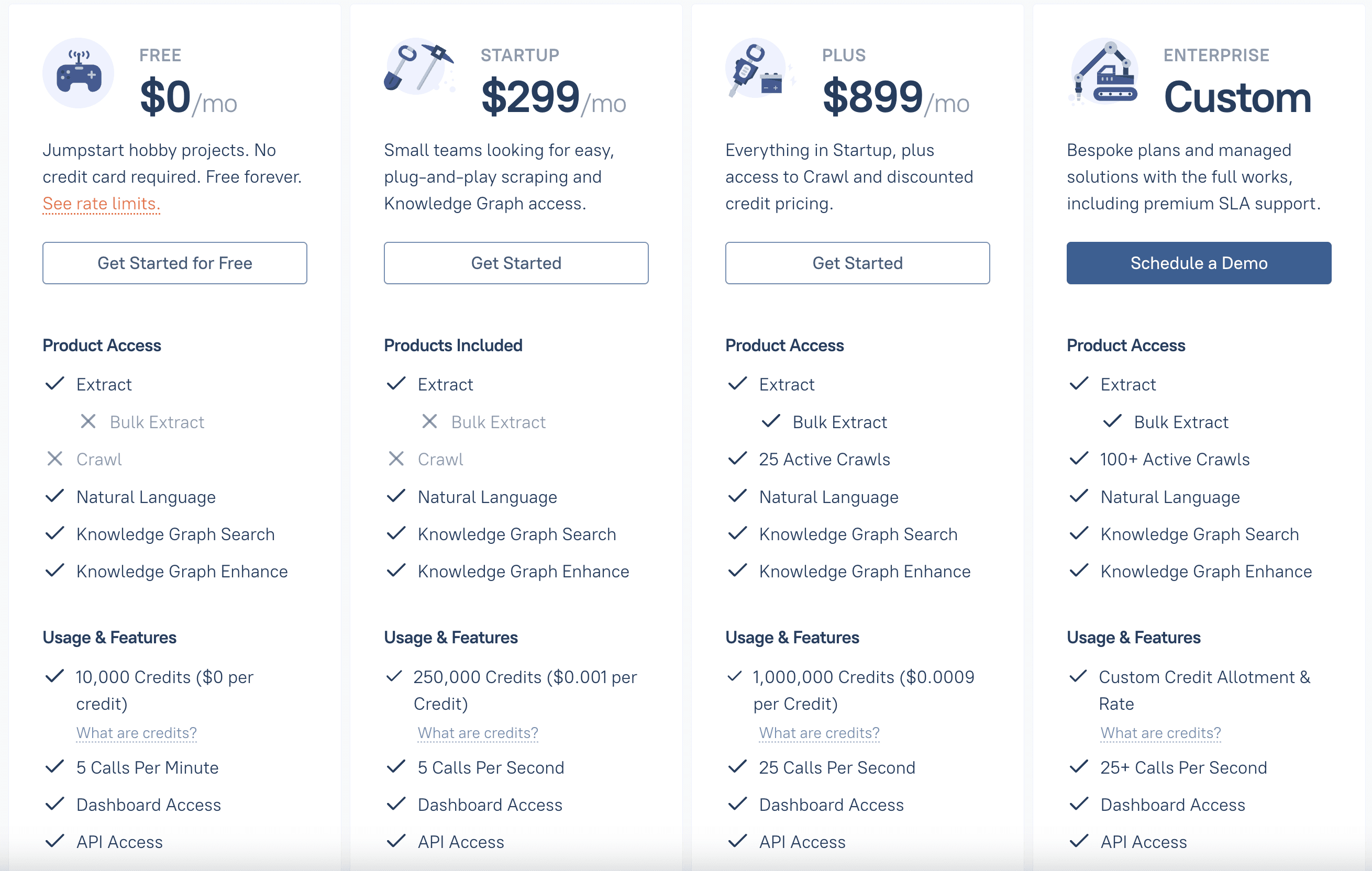
- Free Tier: Do 10 000 kredytów miesięcznie (ok. 10 000 stron) z limitami (5 wywołań API na minutę). Spoko do hobbystycznych projektów lub krótkich testów, ale raczej nic ponad to.
- Startup Plan: 299 USD/mies. za 250 000 kredytów (ok. 250 000 stron) i do 5 wywołań API na sekundę.
- Plus Plan: 899 USD/mies. za 1 000 000 kredytów i większą przepustowość (25 wywołań na sekundę).
- Enterprise Plan: Wycena indywidualna — kontakt z działem sprzedaży. Dla organizacji potrzebujących dziesiątek milionów kredytów, dedykowanego wsparcia i funkcji na zamówienie.
„Kredyt” to w praktyce jedna przetworzona strona lub jedna encja. Po przekroczeniu limitu wchodzą opłaty dodatkowe. A jeśli potrzebujesz więcej, wskakujesz na wyższy plan albo negocjujesz ze sprzedażą.
Dla wielu małych firm, startupów czy osób działających solo takie stawki są po prostu zaporowe. Nawet darmowy plan jest dość ograniczony, a przeskok do 299 USD/mies. potrafi zaboleć. Do tego rozliczenie „za użycie” bywa trudne do przewidzenia — w intensywnym miesiącu mogą wyskoczyć koszty, których nikt nie planował.
Dla porównania, jest dużo bardziej przejrzysty i przyjazny. Możesz zacząć za darmo, a płatne plany startują już od 15 USD/mies. (lub 9 USD/mies. przy rozliczeniu rocznym). Nawet wyższe pakiety kosztują ułamek tego, co Diffbot, i nie musisz gadać z handlowcem, żeby dostać wycenę. Dla większości osób po stronie biznesu to naprawdę duża ulga.
Opinie użytkowników o Diffbot
Przekopałem sporo recenzji na G2, Capterra i innych platformach. Oto, co najczęściej się przewija.
Pozytywne opinie
Na Diffbot ma imponujące 4,9/5, a 96% recenzentów daje maksymalną ocenę. ocenia go na 4,5/5. Użytkownicy chwalą moc i niezawodność platformy. Parsowanie oparte na AI jest solidne, a crawlery działają stabilnie — nawet gdy strony zmieniają wygląd. Jeden z użytkowników napisał, że Diffbot „oszczędził mnóstwo czasu”, bo nie musieli ciągle naprawiać psujących się scraperów. Inny docenił „wysoką skuteczność wykrywania i uptime”, podkreślając, że można ufać poprawności danych.
Wiele osób zwraca też uwagę na szeroki zakres danych. Globalny zasięg Diffbota to duży plus, szczególnie dla firm potrzebujących informacji spoza USA. Jeden z recenzentów zauważył, że wyniki „mogą być w dowolnym języku, ale są przetwarzane tak, by tagi i metadane były po angielsku”, co ułatwia pracę z danymi międzynarodowymi. Wsparcie techniczne też zbiera dobre noty za szybkość i pomocność.
Negatywne opinie
Nie wszystko jednak jest różowe. Najczęściej powtarzający się zarzut to stroma krzywa uczenia. Diffbot jest platformą typu API-first, czyli trzeba umieć pisać kod, robić wywołania API i ogarniać odpowiedzi JSON. Jeden z recenzentów ujął to wprost: „Diffbot Query Language ma pewną krzywą uczenia, jeśli nie jesteś przyzwyczajony do tworzenia zapytań bazodanowych”. Jeśli nie jesteś developerem, robi się pod górkę.
Inny użytkownik z marketingu przyznał, że „nie są zespołem technicznym” i nie potrafili wykorzystać zaawansowanych funkcji Diffbota bez pomocy programisty. To częsty motyw — osoby nietechniczne szybko się frustrują albo odpuszczają. Brakuje interfejsu bez kodu, drag-and-drop i prostego trybu „po prostu pobierz dane” bez technicznych przeszkód.
W efekcie wielu użytkowników biznesowych szuka łatwiejszych alternatyw. Jak ujął to : „Masz dość walki z web scrapingiem, skakania między narzędziami i szukania czegoś, co naprawdę działa… nie musisz być technicznym czarodziejem, żeby korzystać z [alternatyw].”
Drugim dużym minusem jest cena. Darmowy plan jest ograniczony, a płatne pakiety są drogie — szczególnie dla małych firm lub przy dużych wolumenach. System kredytów bywa niejasny, a część użytkowników nie lubi modelu „płacimy w miarę użycia” bez możliwości ustawienia twardego limitu. Bez kontroli rachunek potrafi urosnąć szybciej, niż się wydaje.
Podsumowując: Diffbot jest potężny, ale mało przyjazny dla początkujących i osób, które nie chcą kodować. A bez budżetu enterprise koszt może być barierą nie do przeskoczenia.
Najważniejsze wnioski z recenzji Diffbot
- Diffbot to potężne narzędzie dla developerów i firm enterprise, które muszą pozyskiwać i analizować dane z sieci na dużą skalę.
- Nie jest tworzone z myślą o użytkownikach nietechnicznych. Krzywa uczenia jest stroma, a do działania potrzebujesz kodu lub zapytań.
- Cennik jest wysoki i zależny od użycia, co bywa nieprzewidywalne i kosztowne dla mniejszych zespołów.
- Jeśli jesteś użytkownikiem biznesowym i chcesz automatyzować zbieranie danych z internetu bez kodowania, Diffbot prawdopodobnie nie będzie najlepszym wyborem.
Jaka jest alternatywa? Poznaj Thunderbit.
Thunderbit: najprostszy AI Web Scraper dla każdego
Thunderbit to rozszerzenie Chrome AI Web Scraper stworzone specjalnie dla użytkowników biznesowych — sprzedaży, marketingu, nieruchomości, e-commerce i zespołów operacyjnych — którzy chcą zbierać dane ze stron bez kodu. Liczy się szybkość, prostota i automatyzacja.
Co wyróżnia Thunderbit?
- No-code i AI w web scrapingu: Klikasz „AI Suggest Columns”, AI podpowiada najlepszy sposób wyciągnięcia danych, a potem naciskasz „Scrape”. I tyle. Bez skryptów, bez zapytań, bez bólu głowy.
- Scraping dowolnej strony, PDF-a lub obrazu: Thunderbit ogarnia strony, PDF-y, obrazy, a nawet podstrony. Chcesz pobrać dane produktów z Amazon, ogłoszenia z Zillow albo kontakty z katalogu? Dwa kliknięcia i gotowe.
- Scraping podstron: AI może automatycznie odwiedzać każdą podstronę (np. szczegóły produktu czy stronę kontaktu) i uzupełniać Twoją tabelę.
- Gotowe szablony Instant Data Scraper: Dla popularnych serwisów (Amazon, Zillow, Instagram, Shopify i inne) masz gotowe szablony do eksportu danych jednym kliknięciem.
- Darmowy eksport danych: Eksport do Excel, Google Sheets, Airtable lub Notion — bez dodatkowych opłat.
- AI Autofill (całkowicie za darmo): Wypełniaj formularze online i domykaj procesy. Wybierz kontekst i naciśnij Enter — AI zrobi resztę.
- Scheduled Scraper: Ustaw automatyczne scrapowanie w harmonogramie. Wybierz czas, wklej URL-e i pozwól Thunderbit działać.
- Ekstraktory e-maili, telefonów i obrazów: Wyciągaj e-maile, numery telefonów i obrazy z dowolnej strony jednym kliknięciem — całkowicie za darmo.
Thunderbit ma jeden cel: sprawić, żeby web scraping był dostępny dla każdego. Nie musisz być programistą. Nie musisz uczyć się nowego języka. Wystarczy, że wiesz, jakich danych potrzebujesz — a AI Thunderbit ogarnie resztę.
Thunderbit AI Web Scraper pozwala pobierać dane z dowolnej strony, PDF-a lub obrazu w zaledwie dwa kliknięcia — bez kodowania.
Plany cenowe Thunderbit
Thunderbit działa na prostym systemie kredytów — 1 kredyt = 1 wiersz wyniku. Wygląda to tak:
| Poziom | Cena miesięczna | Cena roczna (miesięcznie) | Suma roczna | Kredyty (miesięcznie) | Kredyty (rocznie) |
|---|---|---|---|---|---|
| Free | Darmowy | Darmowy | Darmowy | 6 stron | N/A |
| Starter | $15 | $9 | $108 | 500 | 5,000 |
| Pro 1 | $38 | $16.5 | $199 | 3,000 | 30,000 |
| Pro 2 | $75 | $33.8 | $406 | 6,000 | 60,000 |
| Pro 3 | $125 | $68.4 | $821 | 10,000 | 120,000 |
| Pro 4 | $249 | $137.5 | $1,650 | 20,000 | 240,000 |
Możesz zacząć za darmo (6 stron/mies.), a płatne plany są sensowne dla osób indywidualnych i małych zespołów. Bez ukrytych opłat, bez niespodziewanych dopłat i z możliwością skalowania, gdy rosną potrzeby. Szczegóły znajdziesz na stronie .
Thunderbit vs Diffbot: porównanie obok siebie
Zbierzmy to w prostą tabelę:
| Funkcja/Aspekt | Diffbot | Thunderbit |
|---|---|---|
| Umiejętności techniczne | Wysokie (wymagany kod, API, język zapytań) | ❌ (kliknij i gotowe — AI robi robotę) |
| Dla kogo | Developerzy, inżynierowie danych, duże firmy | 👨💻 (Sprzedaż, marketing, e-commerce, nieruchomości, operacje, użytkownicy nietechniczni) |
| Czas wdrożenia | Duży (integracje, skrypty) | ✅ (Minimalny (konfiguracja w 2 kliknięcia, szybkie efekty)) |
| Typy danych | Strony WWW, Knowledge Graph, NLP | Strony WWW, PDF-y, obrazy, podstrony, formularze, dokumenty |
| Szablony | ❌ | ✅ (Amazon, Zillow, Instagram, Shopify i inne) |
| Scraping podstron | Wymaga własnej konfiguracji | ✅ (Wbudowane, oparte na AI) |
| Eksport danych | JSON, API | Excel, Google Sheets, Airtable, Notion (darmowo) |
| Ekstrakcja e-mail/telefon/obrazy | ❌ | ✅ (1 kliknięcie, całkowicie za darmo) |
| Scheduled Scraper | ✅ (przez API) | ✅ (prosty interfejs, bez kodowania) |
| AI Autofill | ❌ | ✅ (całkowicie za darmo) |
| Cennik | Darmowy plan (10k kredytów), potem $299+/mies. | Darmowy plan (6 stron), płatne od $9–$15/mies. |
| Najlepsze dla | Enterprise z zespołami dev, duże projekty danych | Użytkownicy biznesowi, MŚP, każdy kto chce szybko i bez kodu scrapować dane |
| Krzywa uczenia | Stroma | ✅ (Płaska — każdy da radę) |
| Wsparcie | Dobre (dla klientów enterprise) | ✅ (Szybkie, przyjazne i nastawione na pomoc osobom nietechnicznym) |
Podsumowanie: dlaczego Thunderbit to lepszy wybór dla większości
Po dłuższym czasie spędzonym z obiema platformami moja szczera opinia jest taka: Diffbot to świetne narzędzie dla developerów i firm enterprise, które muszą crawlowąć i analizować sieć na ogromną skalę. Jeśli masz zespół inżynierów i duży budżet, trudno go przebić.
Ale dla reszty? Dla użytkowników biznesowych, zespołów sprzedaży, marketerów, agentów nieruchomości, operatorów e-commerce i wszystkich, którzy chcą automatyzować zbieranie danych z internetu bez kodu — Thunderbit wygrywa bezdyskusyjnie. Jest szybszy, prostszy i dużo tańszy. Od zera do działającego scrapera przejdziesz w kilka minut, a nie w kilka dni. I nie musisz stresować się niespodziewanymi rachunkami ani nauką nowego języka programowania.
Jeśli masz dość walki ze skomplikowanymi API albo po prostu chcesz pobrać dane i wrócić do swoich zadań, wypróbuj . Możesz i zacząć scrapować za darmo. Jestem przekonany, że zaskoczy Cię, ile czasu i nerwów potrafi oszczędzić.
FAQ
1. Jakie są główne różnice między Diffbot a konkurencją, np. Thunderbit?
Diffbot jest tworzony dla developerów i firm enterprise — wymaga kodowania i integracji przez API. Thunderbit powstał z myślą o użytkownikach nietechnicznych i oferuje interfejs bez kodu wspierany przez AI. Thunderbit jest tańszy, prostszy w obsłudze i lepiej pasuje do potrzeb biznesu, gdy liczy się szybki, bezproblemowy web scraping.
2. W jaki sposób Thunderbit ułatwia web scraping osobom nietechnicznym?
Thunderbit wykorzystuje AI, aby zautomatyzować cały proces. Klikasz „AI Suggest Columns”, pozwalasz AI skonfigurować scraper, a potem naciskasz „Scrape”. Bez kodu, bez zapytań i bez technicznej konfiguracji. Dane z dowolnej strony, PDF-a lub obrazu możesz pobrać w dwa kliknięcia.
3. Jakie unikalne funkcje Thunderbit wyróżniają go na tle innych web scraperów?
Thunderbit oferuje gotowe szablony dla popularnych serwisów, scraping podstron, darmowy eksport do Excel/Sheets/Airtable/Notion, AI Autofill do formularzy, Scheduled Scraper oraz ekstrakcję e-maili/telefonów/obrazów jednym kliknięciem — wszystko w prostym rozszerzeniu Chrome. Został zaprojektowany pod szybkość, prostotę i automatyzację.
Dowiedz się więcej