
Internet jest dosłownie napakowany wartościowymi danymi — tylko że większość stron nie powstała z myślą o tym, żeby dało się je „wyciągnąć na klik”. W 2025 roku web scraping to już nie niszowa sztuczka dla wtajemniczonych, ale normalne narzędzie pracy dla zespołów, które śledzą ceny, oferty pracy, rynek nieruchomości czy ruchy konkurencji. Jest tylko jeden haczyk: GitHub pęka w szwach od repozytoriów do scrapingu. Jedne są dopieszczone i sprawdzone, inne potrafią doprowadzić do szału, a sporo projektów wygląda jakby zatrzymało się w czasie. Jak więc wybrać coś sensownego — zwłaszcza jeśli nie jesteś devem?
W tym poradniku przeprowadzę Cię przez 15 najlepszych projektów do web scrapingu na GitHubie na 2025 rok. To nie będzie sucha lista linków: porównam je pod kątem tego, jak trudno je odpalić, do jakich zastosowań pasują, czy ogarniają dynamiczne treści, w jakiej są kondycji, jak wygląda eksport danych i dla kogo realnie są stworzone. A jeśli masz już dość walki z kodem, pokażę też, czemu narzędzia no-code oparte o AI — takie jak — zmieniają zasady gry dla zespołów biznesowych i osób nietechnicznych.
Jak wybraliśmy TOP 15 projektów do web scrapingu na GitHubie
Nie ma co się oszukiwać: nie każdy projekt na GitHubie jest równie dobry. Część to narzędzia „battle-tested” przez tysiące ludzi, a część to weekendowe prototypy, które nigdy nie wyszły poza etap „działa u mnie”. Do tego zestawienia wybrałem projekty, które spełniają te kryteria:
- Gwiazdy na GitHubie i społeczność: repozytoria z realną adopcją (od kilku tysięcy do 90k+ gwiazdek) i aktywnymi współtwórcami.
- Aktualność: narzędzia rozwijane w 2025 roku — a nie cyfrowe skamieliny.
- Dokumentacja i użyteczność: jasne instrukcje, przykłady kodu i sensowna krzywa uczenia.
- Zastosowania w praktyce: używane w prawdziwych projektach biznesowych lub badawczych, a nie tylko w demach typu „hello world”.
Ponieważ web scraping nie jest rozwiązaniem „one size fits all”, każdy projekt oceniam też pod kątem:
- Instalacji i złożoności konfiguracji: start w kilka minut czy przeprawa przez sterowniki i zależności?
- Dopasowania do zastosowań: e-commerce, newsy, badania, a może coś zupełnie innego?
- Obsługi stron dynamicznych: czy poradzi sobie z nowoczesnymi serwisami opartymi o JavaScript?
- Kondycji projektu: czy jest aktywnie utrzymywany, czy ostatni commit pamięta „stare czasy”?
- Eksportu danych: czy dostajesz dane gotowe do użycia w biznesie, czy tylko surowy HTML?
- Dla kogo: początkujący w Pythonie, inżynierowie danych, a może zespoły nietechniczne?
Każdy projekt ma szybkie tagi dla tych kryteriów, żebyś od razu wyłapał, co pasuje do Twoich potrzeb — niezależnie od tego, czy jesteś ninja od kodu, czy po prostu chcesz mieć dane w Google Sheets.

Instalacja i konfiguracja: jak szybko zaczniesz scrapować?
Nie ma co ukrywać: dla większości osób największą barierą jest samo odpalenie scrapera. Tak rozbijam poziomy trudności konfiguracji:
- Plug & Play (zero konfiguracji): instalujesz i działa. Minimum ustawień, idealne na start.
- Średni poziom (CLI, minimum kodu): trzeba coś poklikać w terminalu albo dopisać trochę kodu, ale da się to ogarnąć, jeśli masz już za sobą proste skrypty.
- Zaawansowany (sterowniki, anty-bot, głębokie kodowanie): wchodzisz w konfigurację środowiska, drivery do przeglądarki albo potrzebujesz solidnych umiejętności w Python/JS.
Tak wypadają topowe projekty:
- Plug & Play: MechanicalSoup (Python), Nokogiri (Ruby), Maxun (dla użytkowników końcowych po wdrożeniu)
- Średni poziom: Scrapy, Crawlee, Node Crawler, Selenium, Playwright, Colly, Puppeteer, Katana, Scrapling, WebMagic
- Zaawansowany: Heritrix, Apache Nutch (wymagają Javy, plików konfiguracyjnych lub „cięższych” stosów big data)
Jeśli nie jesteś programistą, „Plug & Play” albo rozwiązania no-code będą Twoimi najlepszymi ziomkami. Dla reszty „Średni poziom” oznacza, że trzeba będzie coś napisać, ale bez tragedii — chyba że masz alergię na klamry.
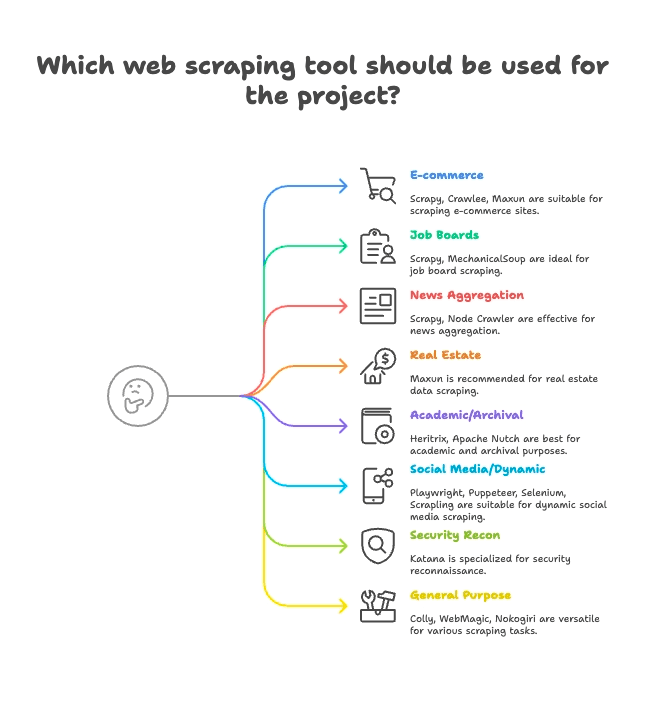
Grupowanie według zastosowań: wybierz scraper pod swoją branżę
Nie każdy scraper jest robiony do tego samego. Tak grupuję top 15 według najlepszego dopasowania:
E-commerce i monitoring cen
- Scrapy: duża skala, wielostronicowe scrapowanie produktów
- Crawlee: uniwersalne, działa na stronach statycznych i dynamicznych
- Maxun: no-code, super do szybkiego wyciągania list produktów
Portale pracy i rekrutacja
- Scrapy: dobrze ogarnia paginację i ustrukturyzowane listy
- MechanicalSoup: dobre do serwisów wymagających logowania
Newsy i agregacja treści
- Scrapy: stworzone do crawl’owania serwisów informacyjnych na dużą skalę
- Node Crawler: szybkie agregowanie statycznych stron
Nieruchomości
- Thunderbit: scrapowanie podstron oparte o AI (listingi + strony szczegółów)
- Maxun: wizualny wybór danych o ofertach
Badania naukowe i archiwizacja WWW
- Heritrix: archiwizacja całych serwisów (pliki WARC)
- Apache Nutch: rozproszony crawling do zbiorów badawczych
Social media i treści dynamiczne
- Playwright, Puppeteer, Selenium: scrapowanie dynamicznych feedów, symulacja logowania
- Scrapling: „stealth scraping” dla stron z zabezpieczeniami anty-bot
Bezpieczeństwo i rekonesans
- Katana: szybkie odkrywanie URL-i, crawling pod security
Ogólnego przeznaczenia / wielozadaniowe
- Colly: wydajny scraping w Go dla dowolnych stron
- WebMagic: Java, elastyczne podejście dla wielu domen
- Nokogiri: parsowanie w Ruby do własnych skryptów
Obsługa stron dynamicznych: czy te projekty z GitHuba poradzą sobie z nowoczesnym webem?
Współczesne strony kochają JavaScript. React, Vue, nieskończone scrollowanie, AJAX — jeśli kiedykolwiek próbowałeś scrapować stronę i dostałeś wielkie „nic”, to wiesz, o co chodzi.
Tak poszczególne projekty radzą sobie z treściami dynamicznymi:
- Pełna obsługa JS (przeglądarka headless):
- Selenium: steruje prawdziwą przeglądarką i odpala cały JS
- Playwright: wiele przeglądarek i języków, bardzo solidne wsparcie JS
- Puppeteer: headless Chrome/Firefox, pełne renderowanie JS
- Crawlee: przełącza się między HTTP a trybem przeglądarki (Puppeteer/Playwright)
- Katana: opcjonalny tryb headless do parsowania JS
- Scrapling: integruje Playwright do „cichego” scrapingu JS
- Maxun: pod spodem korzysta z przeglądarki, więc ogarnia dynamiczne treści
- Brak natywnej obsługi JS (tylko statyczny HTML):
- Scrapy: do JS potrzebuje wtyczki Selenium/Playwright
- MechanicalSoup, Node Crawler, Colly, WebMagic, Nokogiri, Heritrix, Apache Nutch: pobierają tylko HTML, bez JS „z pudełka”
Na tym tle mocno wybija się AI w Thunderbit: automatycznie wykrywa i wyciąga treści dynamiczne — bez ręcznego dłubania w konfiguracji, bez wtyczek i bez bólu z selektorami. Wystarczy kliknąć „AI Suggest Fields”, a reszta zrobi się sama, nawet na stronach mocno opartych o React. Więcej szczegółów znajdziesz w .
Kondycja projektu i niezawodność: czy ten scraper będzie działał też za rok?
Nie ma nic gorszego niż zbudować proces na narzędziu, które potem zostaje porzucone. Tak wypadają topowe projekty:
- Aktywnie rozwijane (częste aktualizacje):
- Scrapy:
- Crawlee:
- Playwright:
- Puppeteer:
- Katana:
- Colly:
- Maxun:
- Scrapling:
- Stabilne, ale aktualizowane wolniej:
- MechanicalSoup:
- Node Crawler:
- WebMagic:
- Nokogiri:
- Tryb utrzymaniowy (specjalistyczne, wolniejsze tempo):
- Heritrix:
- Apache Nutch:
Thunderbit działa jako usługa zarządzana, więc nie musisz się stresować, że kod zostanie porzucony. Nasz zespół pilnuje aktualności AI, szablonów i integracji — a do tego masz onboarding, tutoriale i wsparcie, kiedy utkniesz.
Dane i eksport: od surowego HTML do danych gotowych dla biznesu
Samo zebranie danych to dopiero połowa roboty. Potrzebujesz ich w formacie, z którego skorzysta zespół — CSV, Excel, Google Sheets, Airtable, Notion albo nawet API.
- Wbudowany eksport ustrukturyzowany:
- Scrapy: eksport do CSV, JSON, XML
- Crawlee: elastyczne datasety i storage
- Maxun: CSV, Excel, Google Sheets, JSON API
- Thunderbit:
- Ręczna obsługa danych (po stronie użytkownika):
- MechanicalSoup, Node Crawler, Selenium, Playwright, Puppeteer, Colly, WebMagic, Nokogiri, Scrapling: sam piszesz kod do zapisu/eksportu
- Eksport specjalistyczny:
- Heritrix: WARC (pliki archiwum WWW)
- Apache Nutch: surowa treść do storage/indexu
Ustrukturyzowany eksport i integracje w Thunderbit to ogromna oszczędność czasu dla ludzi z biznesu. Zamiast żonglować CSV-ami i pisać „klej” w kodzie — klikasz i masz dane gotowe do użycia.
Dla kogo jest który projekt do web scrapingu na GitHubie?
Nie oszukujmy się: nie każde narzędzie jest dla każdego. Oto moje rekomendacje:
- Początkujący w Pythonie: MechanicalSoup, Scrapling (jeśli lubisz wyzwania)
- Inżynierowie danych: Scrapy, Crawlee, Colly, WebMagic, Node Crawler
- QA i automatyzacja: Selenium, Playwright, Puppeteer
- Badacze bezpieczeństwa: Katana
- Rubyści: Nokogiri
- Programiści Java: WebMagic, Heritrix, Apache Nutch
- Użytkownicy nietechniczni / zespoły biznesowe: Maxun, Thunderbit
- Growth hackerzy, analitycy: Maxun, Thunderbit
Jeśli nie czujesz się pewnie w kodzie albo po prostu chcesz szybko dowieźć wynik, Thunderbit i Maxun będą najrozsądniejszym wyborem. W pozostałych przypadkach dobierz narzędzie do języka i zastosowania.
TOP 15 projektów do web scrapingu na GitHubie: szczegółowe porównanie
Przejdźmy do mięsa — każdy projekt w grupach zastosowań, z tagami i najważniejszymi cechami.
E-commerce, monitoring cen i crawling ogólnego przeznaczenia
— 57.1k gwiazdek, aktualizacja czerwiec 2025

- Opis: wysokopoziomowy, asynchroniczny framework w Pythonie do crawl’owania i scrapingu na dużą skalę.
- Konfiguracja: średni poziom (kod w Pythonie, asynchroniczność)
- Zastosowania: e-commerce, newsy, badania, wielostronicowe „spidery”
- Obsługa JS: nie (wymaga wtyczki Selenium/Playwright)
- Kondycja projektu: aktywnie utrzymywany
- Eksport danych: wbudowane CSV, JSON, XML
- Dla kogo: programiści, inżynierowie danych
- Wyróżniki: skalowalny, solidny, masa wtyczek. Dla początkujących krzywa uczenia jest stroma.
— 17.9k gwiazdek, 2025

- Opis: rozbudowana biblioteka Node.js do scrapingu stron statycznych i dynamicznych.
- Konfiguracja: średni poziom (kod w Node/TS)
- Zastosowania: e-commerce, social media, automatyzacja
- Obsługa JS: tak (integracja z Puppeteer/Playwright)
- Kondycja projektu: bardzo aktywny
- Eksport danych: elastyczny (datasety, storage)
- Dla kogo: zespoły developerskie w JS/TS
- Wyróżniki: narzędzia antyblokujące, łatwe przełączanie trybu HTTP/przeglądarka.
— 13k gwiazdek, czerwiec 2025

- Opis: open-source’owa platforma no-code do ekstrakcji danych z WWW z interfejsem wizualnym.
- Konfiguracja: średni poziom (wdrożenie serwera), łatwy (dla użytkowników końcowych)
- Zastosowania: ogólne, e-commerce, scraping biznesowy
- Obsługa JS: tak (działa na silniku przeglądarki)
- Kondycja projektu: aktywny i rosnący
- Eksport danych: CSV, Excel, Google Sheets, JSON API
- Dla kogo: osoby nietechniczne, analitycy, zespoły
- Wyróżniki: scraping „wskaż i kliknij”, nawigacja wielopoziomowa, możliwość self-hostingu.
Portale pracy, rekrutacja i proste interakcje
— 4.8k gwiazdek, 2024

- Opis: biblioteka Pythona do automatyzacji formularzy i prostej nawigacji.
- Konfiguracja: Plug & Play (Python, minimum kodu)
- Zastosowania: portale pracy z logowaniem, strony statyczne
- Obsługa JS: nie
- Kondycja projektu: dojrzały, lekko utrzymywany
- Eksport danych: brak wbudowanego (ręcznie)
- Dla kogo: początkujący w Pythonie, szybkie skrypty
- Wyróżniki: symuluje sesję przeglądarki w kilku linijkach. Nie nadaje się do stron dynamicznych.
Agregacja newsów i treści statyczne
— 6.8k gwiazdek, 2024

- Opis: szybki, współbieżny crawler po stronie serwera z parsowaniem przez Cheerio.
- Konfiguracja: średni poziom (callbacki/async w Node)
- Zastosowania: newsy, szybki scraping stron statycznych
- Obsługa JS: nie (tylko HTML)
- Kondycja projektu: umiarkowana aktywność (v2 beta)
- Eksport danych: brak wbudowanego (po stronie użytkownika)
- Dla kogo: programiści Node.js, potrzeby wysokiej współbieżności
- Wyróżniki: asynchroniczny crawling, limitowanie tempa, API podobne do jQuery.
Nieruchomości, listingi i scraping podstron

- Opis: no-code Web Scraper oparty o AI dla użytkowników biznesowych.
- Konfiguracja: Plug & Play (rozszerzenie Chrome, konfiguracja w 2 kliknięcia)
- Zastosowania: nieruchomości, e-commerce, sprzedaż, marketing — dowolna strona
- Obsługa JS: tak (AI automatycznie wykrywa treści dynamiczne)
- Kondycja projektu: stale aktualizowany, usługa zarządzana
- Eksport danych: jednym kliknięciem do Sheets, Airtable, Notion, CSV, JSON
- Dla kogo: osoby nietechniczne, zespoły biznesowe, sprzedaż, marketing
- Wyróżniki: AI „Suggest Fields”, scraping podstron, natychmiastowy eksport, onboarding, szablony, .
Badania naukowe i archiwizacja WWW
— 3k gwiazdek, 2023

- Opis: crawler do archiwizacji WWW na skalę Internet Archive.
- Konfiguracja: zaawansowana (aplikacja Java, pliki konfiguracyjne)
- Zastosowania: archiwizacja WWW, crawl całych domen
- Obsługa JS: nie (tylko pobieranie)
- Kondycja projektu: utrzymywany (wolniej, ale stabilnie)
- Eksport danych: WARC (pliki archiwum WWW)
- Dla kogo: archiwa, biblioteki, instytucje
- Wyróżniki: skalowalny, solidny, zgodny ze standardami. Nie jest narzędziem do precyzyjnego scrapingu.
— 3k gwiazdek, 2024

- Opis: open-source’owy crawler do big data i wyszukiwarek.
- Konfiguracja: zaawansowana (Java + Hadoop dla skali)
- Zastosowania: crawling pod wyszukiwarki, big data
- Obsługa JS: nie (tylko HTTP)
- Kondycja projektu: aktywny (Apache)
- Eksport danych: surowa treść do storage/indexu
- Dla kogo: firmy, big data, badania naukowe
- Wyróżniki: architektura wtyczek, crawling rozproszony.
Social media, treści dynamiczne i automatyzacja
— ~30k gwiazdek, 2025

- Opis: automatyzacja przeglądarki do scrapingu i testów, obsługuje wszystkie główne przeglądarki.
- Konfiguracja: średni poziom (drivery, wiele języków)
- Zastosowania: strony mocno oparte o JS, testy przepływów, social media
- Obsługa JS: tak (pełna automatyzacja przeglądarki)
- Kondycja projektu: aktywny, dojrzały
- Eksport danych: brak (ręcznie)
- Dla kogo: inżynierowie QA, programiści
- Wyróżniki: wiele języków, symulacja zachowań prawdziwego użytkownika.
— 73.5k gwiazdek, 2025

- Opis: nowoczesna automatyzacja przeglądarki do scrapingu i testów E2E.
- Konfiguracja: średni poziom (skrypty w różnych językach)
- Zastosowania: nowoczesne aplikacje webowe, social media, automatyzacja
- Obsługa JS: tak (headless lub prawdziwa przeglądarka)
- Kondycja projektu: bardzo aktywny
- Eksport danych: brak (po stronie użytkownika)
- Dla kogo: programiści potrzebujący solidnej kontroli przeglądarki
- Wyróżniki: cross-browser, auto-wait, przechwytywanie sieci.
— 90.9k gwiazdek, 2025

- Opis: wysokopoziomowe API do automatyzacji Chrome/Firefox.
- Konfiguracja: średni poziom (skrypty w Node)
- Zastosowania: scraping headless Chrome, treści dynamiczne
- Obsługa JS: tak (Chrome/Firefox)
- Kondycja projektu: aktywny (zespół Chrome)
- Eksport danych: brak (własny w kodzie)
- Dla kogo: programiści Node.js, front-end
- Wyróżniki: bogata kontrola przeglądarki, zrzuty ekranu, PDF, przechwytywanie sieci.
— 5.4k gwiazdek, czerwiec 2025

- Opis: „cichy” i wydajny scraping z funkcjami anty-bot.
- Konfiguracja: średni poziom (kod w Pythonie)
- Zastosowania: stealth scraping, omijanie anty-bot, strony dynamiczne
- Obsługa JS: tak (integracja z Playwright)
- Kondycja projektu: aktywny, bardzo nowy
- Eksport danych: brak wbudowanego (ręcznie)
- Dla kogo: programiści Pythona, „hakerzy”, inżynierowie danych
- Wyróżniki: stealth, proxy, antyblokowanie, async.
Rekonesans bezpieczeństwa
— 13.8k gwiazdek, 2025

- Opis: szybki crawler do security, automatyzacji i odkrywania linków.
- Konfiguracja: średni poziom (narzędzie CLI lub biblioteka Go)
- Zastosowania: crawling pod bezpieczeństwo, wykrywanie endpointów
- Obsługa JS: tak (opcjonalny tryb headless)
- Kondycja projektu: aktywny (ProjectDiscovery)
- Eksport danych: tekst (listy URL)
- Dla kogo: badacze bezpieczeństwa, programiści Go
- Wyróżniki: szybkość, współbieżność, parsowanie JS w trybie headless.
Ogólnego przeznaczenia / wielozadaniowy scraping
— 24.3k gwiazdek, 2025

- Opis: szybki i elegancki framework do scrapingu w Go.
- Konfiguracja: średni poziom (kod w Go)
- Zastosowania: wydajny scraping ogólnego przeznaczenia
- Obsługa JS: nie (tylko HTML)
- Kondycja projektu: aktywny, świeże commity
- Eksport danych: brak wbudowanego (po stronie użytkownika)
- Dla kogo: programiści Go, osoby stawiające na wydajność
- Wyróżniki: async, limitowanie tempa, scraping rozproszony.
— 11.6k gwiazdek, 2023

- Opis: elastyczny framework crawlera w Javie, trochę w stylu Scrapy.
- Konfiguracja: średni poziom (Java, proste API)
- Zastosowania: web scraping w Javie
- Obsługa JS: nie (można rozszerzyć o Selenium)
- Kondycja projektu: aktywna społeczność
- Eksport danych: pipeline’y wtyczkowe
- Dla kogo: programiści Java
- Wyróżniki: pule wątków, schedulery, mechanizmy antyblokujące.
— 6.2k gwiazdek, 2025

- Opis: szybki, natywny parser HTML/XML dla Ruby.
- Konfiguracja: Plug & Play (gem Ruby)
- Zastosowania: parsowanie HTML/XML w aplikacjach Ruby
- Obsługa JS: nie (tylko parsowanie)
- Kondycja projektu: aktywny, nadąża za Ruby
- Eksport danych: brak (formatowanie po stronie Ruby)
- Dla kogo: Rubyści, programiści Rails
- Wyróżniki: szybkość, zgodność, bezpieczeństwo domyślnie.
Na szybko: tabela porównawcza funkcji
Poniżej szybka tabela — z Thunderbit dla porównania:
| Projekt | Złożoność konfiguracji | Zastosowanie | Obsługa JS | Utrzymanie | Eksport danych | Dla kogo | Gwiazdy na GitHubie |
|---|---|---|---|---|---|---|---|
| Scrapy | Średnia | E-commerce, newsy | Nie | Aktywny | CSV, JSON, XML | Dev, inż. danych | 57.1k |
| Crawlee | Średnia | Uniwersalne, automatyzacja | Tak | Bardzo aktywny | Elastyczne datasety | Zespoły JS/TS | 17.9k |
| MechanicalSoup | Plug & Play | Statyczne, formularze | Nie | Dojrzały | Brak (ręcznie) | Początkujący Python | 4.8k |
| Node Crawler | Średnia | Newsy, statyczne | Nie | Umiarkowane | Brak (ręcznie) | Dev Node.js | 6.8k |
| Selenium | Średnia | Dużo JS, testy | Tak | Aktywny | Brak (ręcznie) | QA, dev | ~30k |
| Heritrix | Zaawansowana | Archiwizacja, badania | Nie | Utrzymywany | WARC | Archiwa, instytucje | 3k |
| Apache Nutch | Zaawansowana | Big data, wyszukiwanie | Nie | Aktywny | Surowa treść | Firmy, badania | 3k |
| WebMagic | Średnia | Java, ogólne | Nie | Aktywna społeczność | Pipeline’y wtyczkowe | Dev Java | 11.6k |
| Nokogiri | Plug & Play | Parsowanie Ruby | Nie | Aktywny | Brak (ręcznie) | Rubyści | 6.2k |
| Playwright | Średnia | Dynamiczne, automatyzacja | Tak | Bardzo aktywny | Brak (ręcznie) | Dev, QA | 73.5k |
| Katana | Średnia | Security, odkrywanie | Tak | Aktywny | Tekst | Security, dev Go | 13.8k |
| Colly | Średnia | Wysoka wydajność, ogólne | Nie | Aktywny | Brak (ręcznie) | Dev Go | 24.3k |
| Puppeteer | Średnia | Dynamiczne, automatyzacja | Tak | Aktywny | Brak (ręcznie) | Dev Node.js | 90.9k |
| Maxun | Łatwa (użytkownik) | No-code, biznes | Tak | Aktywny | CSV, Excel, Sheets, API | Nietechniczni, analitycy | 13k |
| Scrapling | Średnia | Stealth, anty-bot | Tak | Aktywny | Brak (ręcznie) | Dev Python, „hakerzy” | 5.4k |
| Thunderbit | Plug & Play | No-code, biznes | Tak | Zarządzany, aktualizowany | Sheets, Airtable, Notion | Nietechniczni, biznes | N/A |
Dlaczego Thunderbit to najlepszy wybór dla osób nietechnicznych i zespołów biznesowych
Większość open-source’owych projektów na GitHubie powstaje „od programistów dla programistów”. A to zwykle oznacza, że konfiguracja, utrzymanie i gaszenie pożarów są wliczone w cenę. Jeśli jesteś po stronie biznesu — marketing, sales ops, analityka — i liczy się dla Ciebie wynik, a nie dłubanie w regexach, Thunderbit jest zrobiony dokładnie pod Ciebie.
Co wyróżnia Thunderbit:
- Prostota no-code wspierana przez AI: instalujesz , klikasz „AI Suggest Fields” i jedziesz ze scrapingiem. Bez Pythona, bez selektorów, bez dramatu „pip install”.
- Obsługa stron dynamicznych: AI Thunderbit potrafi czytać i wyciągać dane z nowoczesnych stron opartych o JavaScript (React, Vue, AJAX) bez ręcznej konfiguracji.
- Scraping podstron: chcesz zebrać szczegóły z każdej oferty lub produktu? AI Thunderbit przechodzi po podstronach i scala dane w jedną tabelę — bez pisania kodu.
- Eksport gotowy dla biznesu: jednym kliknięciem do Google Sheets, Airtable, Notion, CSV lub JSON. Idealne do leadów sprzedażowych, monitoringu cen czy agregacji treści.
- Ciągłe aktualizacje i wsparcie: Thunderbit to usługa zarządzana — bez ryzyka „abandonware”. Dostajesz onboarding, tutoriale i rosnącą bibliotekę szablonów dla popularnych stron.
- Dopasowanie do odbiorcy: Thunderbit jest dla osób nietechnicznych, zespołów biznesowych i wszystkich, którzy cenią szybkość oraz niezawodność bardziej niż dłubanie w kodzie.
Nie musisz brać tego na wiarę — Thunderbit zaufało już ponad 30 000 użytkowników na całym świecie, w tym zespoły z Accenture, Grammarly i Puma. Tak, byliśmy też #1 Produktem Tygodnia na Product Hunt.
Jeśli chcesz zobaczyć, jak proste może być scrapowanie, .
Podsumowanie: jak wybrać właściwe rozwiązanie do web scrapingu w 2025 roku
Sedno jest takie: GitHub to kopalnia mocnych narzędzi do scrapingu, ale większość z nich jest projektowana pod programistów. Jeśli lubisz kodować, frameworki takie jak Scrapy, Crawlee, Playwright czy Colly dadzą Ci maksymalną kontrolę. Jeśli działasz w akademii albo security, Heritrix, Nutch i Katana będą naturalnym wyborem.
Jeśli jednak jesteś po stronie biznesu, analityki albo po prostu chcesz danych — szybko, w ustrukturyzowanej formie i gotowych do użycia — Thunderbit będzie najkrótszą drogą do celu. Bez konfiguracji, bez utrzymania, bez kodu. Po prostu rezultat.
Co dalej? Możesz przetestować projekty github dopasowane do Twoich umiejętności i zastosowania. Albo — jeśli chcesz ominąć krzywą uczenia i zobaczyć realne wyniki w kilka minut — i zacznij scrapować już dziś.
A jeśli chcesz wejść głębiej w temat web scrapingu, zajrzyj do kolejnych poradników na , np. albo .
Powodzenia w scrapowaniu — oby Twoje dane zawsze były ustrukturyzowane, czyste i gotowe do działania. A gdy utkniesz, pamiętaj: prawdopodobnie istnieje na web scraping github repo, które to ogarnia… albo możesz po prostu pozwolić, żeby AI Thunderbit zrobiło to za Ciebie.