
Mój pierwszy projekt scrapingu? Ręcznie sklejony skrypt w Pythonie, współdzielone proxy i modlitwa. Psulo się co trzy dni — klasyka gatunku.
W 2026 roku api do pozyskiwania danych biorą na siebie najgorsze kawałki roboty — proxy, renderowanie, CAPTCHY, ponawianie prób — żebyś nie musiał się w to bawić. To fundament wszystkiego: od monitoringu cen po pipeline’y danych treningowych dla AI.
Jest jednak plot twist: narzędzia oparte na AI, takie jak Thunderbit, sprawiają, że wiele zastosowań API przestaje być w ogóle potrzebnych dla osób nietechnicznych. O tym za chwilę.
Poniżej znajdziesz 10 API do scrapingu, których używałem albo które testowałem — co robią świetnie, gdzie mają ograniczenia i kiedy spokojnie możesz obejść się bez API.
Dlaczego warto rozważyć Thunderbit AI zamiast klasycznych API do web scrapingu?
Zanim przejdziemy do listy API, pogadajmy o słoniu w pokoju: automatyzacji napędzanej AI. Od lat pomagam zespołom automatyzować żmudne zadania i powiem wprost — nie bez powodu coraz więcej firm omija „ciężkie” API i idzie prosto w stronę agentów AI, takich jak Thunderbit.
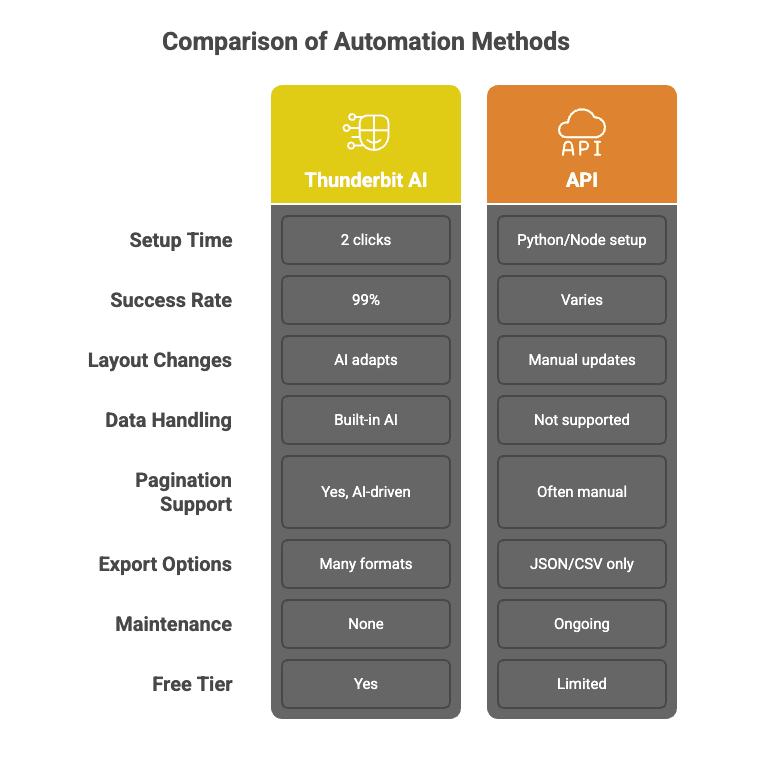
Co wyróżnia Thunderbit na tle tradycyjnych API do web scrapingu:
-
Kaskadowe wywołania API dla 99% skuteczności
AI w Thunderbit nie robi jednego strzału i nie liczy na fart. Działa kaskadowo — automatycznie dobiera najlepszą metodę scrapingu do konkretnego zadania, ponawia próby, kiedy trzeba, i dowozi 99% skuteczności. Dostajesz dane, a nie ból głowy.
-
Bez kodu, konfiguracja w dwa kliknięcia
Zapomnij o dłubaniu w Pythonie i przekopywaniu dokumentacji API. W Thunderbit klikasz „AI Suggest Fields”, potem „Scrape”. I tyle. Nawet moja mama by to ogarnęła (a ona nadal uważa, że „chmura” to po prostu zła pogoda).
-
Scraping wsadowy: szybko i precyzyjnie
Model AI Thunderbit potrafi równolegle przerabiać tysiące różnych stron, dopasowując się do układu w locie. To jak armia stażystów — tylko bez przerw na kawę.
-
Bez utrzymania
Strony zmieniają się non stop. Klasyczne API? Potrafią się wysypać. Thunderbit? AI za każdym razem „czyta” stronę od nowa, więc nie musisz aktualizować kodu, gdy serwis zmieni layout albo dorzuci nowy przycisk.
-
Spersonalizowane wydobycie danych i obróbka po ekstrakcji
Potrzebujesz wyczyszczenia danych, etykietowania, tłumaczenia albo podsumowania? Thunderbit może zrobić to w ramach ekstrakcji — jakbyś wrzucił 10 000 stron do ChatGPT i dostał idealnie ustrukturyzowany zbiór danych.
-
Scraping podstron i paginacji
AI Thunderbit potrafi podążać za linkami, ogarnia paginację i wzbogaca tabelę danymi z podstron — bez pisania niestandardowego kodu.
-
Darmowy eksport danych i integracje
Eksport do Excel, Google Sheets, Airtable, Notion albo pobranie jako CSV/JSON — bez paywalli i bez kombinowania.
Szybkie porównanie, żeby to dobrze wybrzmiało:
Chcesz zobaczyć, jak to działa w praktyce? Zajrzyj do Thunderbit Chrome Extension.
Czym jest API do pozyskiwania danych (Data Scraping API)?
Wróćmy na chwilę do podstaw. API do pozyskiwania danych to narzędzie, które pozwala programowo wyciągać dane ze stron internetowych — bez budowania własnych scraperów od zera. Pomyśl o tym jak o robocie, którego wysyłasz po aktualne ceny, opinie czy ogłoszenia, a on odsyła dane w uporządkowanej formie (zwykle JSON albo CSV).
Jak to działa? Większość API do scrapingu ogarnia brudną robotę — rotację proxy, rozwiązywanie CAPTCHA, renderowanie JavaScript — dzięki czemu możesz skupić się na tym, co naprawdę ważne: danych. Wysyłasz zapytanie (najczęściej URL i kilka parametrów), a API zwraca treść gotową do użycia w Twoim procesie biznesowym.
Główne korzyści:
- Szybkość: API potrafią scrapować tysiące stron na minutę.
- Skalowalność: Chcesz monitorować 10 000 produktów? Żaden problem.
- Integracje: Łatwo podepniesz to pod CRM, narzędzia BI czy hurtownię danych.
Jak zaraz zobaczysz, nie każde API jest takie samo — i nie każde faktycznie działa w trybie „ustaw i zapomnij”, jak obiecuje marketing.
Jak oceniałem te API
Spędziłem sporo czasu na pierwszej linii frontu — testując, psując i czasem przypadkiem robiąc DDoS na własnych serwerach (nie mówcie mojemu dawnemu działowi IT). Przy tej liście patrzyłem przede wszystkim na:
- Niezawodność: Czy to działa także na trudnych stronach?
- Szybkość: Jak szybko dowozi wyniki w skali?
- Cennik: Czy jest sensowny dla startupów i rośnie z potrzebami enterprise?
- Skalowalność: Czy wytrzyma miliony zapytań, czy pada przy setce?
- Przyjazność dla developerów: Czy dokumentacja jest jasna? Są SDK i przykłady?
- Wsparcie: Gdy coś się sypie (a będzie), czy jest pomoc?
- Opinie użytkowników: Realne recenzje, a nie tylko marketing.
Mocno opierałem się też na testach praktycznych, analizie recenzji i feedbacku społeczności Thunderbit (jesteśmy dość wybredni).
10 API, które warto rozważyć w 2026
Czas na konkrety. Oto aktualna lista najlepszych API i platform do web scrapingu dla firm i developerów w 2026 roku.
1. Oxylabs
 Przegląd:
Przegląd:
Oxylabs to ciężka artyleria do ekstrakcji danych na poziomie enterprise. Ogromna pula proxy i wyspecjalizowane API — od SERP po e-commerce — sprawiają, że to częsty wybór firm z Fortune 500 i wszystkich, którzy potrzebują niezawodności w dużej skali.
Kluczowe funkcje:
- Ogromna sieć proxy (residential, datacenter, mobile, ISP) w 195+ krajach
- API do scrapingu z anti-bot, rozwiązywaniem CAPTCHA i renderowaniem w headless browser
- Geotargetowanie, utrzymanie sesji i wysoka dokładność danych (95%+ skuteczności)
- OxyCopilot: asystent AI generujący kod parsowania i zapytania API
Cennik:
Od ok. 49 USD/mies. za pojedyncze API, 149 USD/mies. za dostęp „all-in-one”. W pakiecie 7-dniowy trial do 5 000 zapytań.
Opinie użytkowników:
Ocena 4,8/5 na G2 — chwalony za niezawodność i wsparcie. Minus? Cena, ale w tej klasie zwykle płaci się za jakość.
2. ScrapingBee
 Przegląd:
Przegląd:
ScrapingBee to najlepszy przyjaciel developera — proste, przystępne cenowo i konkretne. Podajesz URL, a narzędzie ogarnia headless Chrome, proxy i CAPTCHA, po czym zwraca wyrenderowaną stronę albo same dane.
Kluczowe funkcje:
- Renderowanie w headless browser (obsługa JavaScript)
- Automatyczna rotacja IP i rozwiązywanie CAPTCHA
- „Stealth” proxy na trudniejsze serwisy
- Minimalna konfiguracja — jedno wywołanie API
Cennik:
Darmowy plan z ok. 1 000 wywołań/mies. Płatne plany od ok. 29 USD/mies. za 5 000 zapytań.
Opinie użytkowników:
Stabilnie 4,8/5 na G2. Developerzy cenią prostotę; dla osób bez kodu może być zbyt „surowe”.
3. Apify
 Przegląd:
Przegląd:
Apify to scyzoryk szwajcarski web scrapingu. Możesz budować własne scrapery („Actors”) w JavaScript lub Pythonie albo skorzystać z ogromnej biblioteki gotowych aktorów dla popularnych serwisów. Elastyczność jest tu największą zaletą.
Kluczowe funkcje:
- Własne i gotowe scrapery (Actors) praktycznie na każdą stronę
- Chmura, harmonogramy i zarządzanie proxy w pakiecie
- Eksport do JSON, CSV, Excel, Google Sheets i innych
- Aktywna społeczność oraz wsparcie na Discordzie
Cennik:
Plan darmowy na zawsze z kredytami o wartości 5 USD/mies. Płatne plany od 39 USD/mies.
Opinie użytkowników:
4,7+ na G2/Capterra. Developerzy kochają elastyczność; początkujący muszą liczyć się z krzywą uczenia.
Zobacz porównanie Apify i Thunderbit
4. Decodo (dawniej Smartproxy)
 Przegląd:
Przegląd:
Decodo (po rebrandingu Smartproxy) stawia na opłacalność i prostotę. Łączy solidną infrastrukturę proxy z API do scrapingu dla ogólnego webu, SERP, e-commerce i social mediów — w ramach jednej subskrypcji.
Kluczowe funkcje:
- Jedno, zunifikowane API dla wszystkich endpointów (bez osobnych dodatków)
- Wyspecjalizowane scrapery dla Google, Amazon, TikTok i innych
- Przyjazny panel z „playgroundem” i generatorami kodu
- Wsparcie 24/7 na czacie
Cennik:
Od ok. 50 USD/mies. za 25 000 zapytań. Darmowy 7-dniowy trial z 1 000 zapytań.
Opinie użytkowników:
Chwalony za świetny stosunek ceny do możliwości i szybkie wsparcie. 4,7/5 na G2.
5. Octoparse
 Przegląd:
Przegląd:
Octoparse to lider wśród narzędzi no-code. Jeśli nie znosisz kodu, ale potrzebujesz danych, ta desktopowa aplikacja „kliknij i wybierz” (z funkcjami chmurowymi) pozwala budować scrapery wizualnie i odpalać je lokalnie lub w chmurze.
Kluczowe funkcje:
- Wizualny builder workflow — klikasz i wybierasz pola danych
- Ekstrakcja w chmurze, harmonogramy i automatyczna rotacja IP
- Szablony dla popularnych stron oraz marketplace z gotowymi scraperami
- Octoparse AI: łączy RPA i ChatGPT do czyszczenia danych i automatyzacji procesów
Cennik:
Darmowy plan do 10 zadań lokalnych. Płatne plany od 119 USD/mies. (funkcje chmurowe, nielimitowane zadania). 14-dniowy trial funkcji premium.
Opinie użytkowników:
4,4/5 na G2. Uwielbiany przez osoby nietechniczne, ale zaawansowani mogą odbić się od ograniczeń.
6. Bright Data
 Przegląd:
Przegląd:
Bright Data to „największy gracz” — jeśli potrzebujesz skali, szybkości i pełnego zestawu funkcji, to platforma dla Ciebie. Największa na świecie sieć proxy i rozbudowane IDE do scrapingu są skrojone pod enterprise.
Kluczowe funkcje:
- 150M+ IP (residential, mobile, ISP, datacenter)
- Web Scraper IDE, gotowe kolektory danych i zestawy danych do kupienia
- Zaawansowane anti-bot, rozwiązywanie CAPTCHA i wsparcie headless browser
- Nacisk na zgodność i aspekty prawne (inicjatywa Ethical Web Data)
Cennik:
Pay-as-you-go: ok. 1,05 USD za 1 000 zapytań, proxy od 3 do 15 USD/GB. Darmowe testy dla większości produktów.
Opinie użytkowników:
Chwalony za wydajność i funkcje, ale cena i złożoność potrafią być barierą dla mniejszych zespołów.
7. WebAutomation
 Przegląd:
Przegląd:
WebAutomation to platforma chmurowa zaprojektowana dla osób nietechnicznych. Dzięki marketplace’owi gotowych ekstraktorów i kreatorowi no-code świetnie sprawdza się tam, gdzie liczą się dane, a nie kod.
Kluczowe funkcje:
- Gotowe ekstraktory dla popularnych serwisów (Amazon, Zillow itd.)
- Kreator no-code z interfejsem „kliknij i wybierz”
- Harmonogramy w chmurze, dostarczanie danych i utrzymanie w cenie
- Rozliczanie per wiersz (płacisz za to, co wyciągasz)
Cennik:
Plan Project: 74 USD/mies. (ok. 400 tys. wierszy/rok), pay-as-you-go: 1 USD za 1 000 wierszy. 14-dniowy trial z 10 mln kredytów.
Opinie użytkowników:
Użytkownicy chwalą prostotę i przejrzysty cennik. Wsparcie jest pomocne, a utrzymanie leży po stronie zespołu.
8. ScrapeHero
 Przegląd:
Przegląd:
ScrapeHero zaczynało jako firma od projektów „na zamówienie”, a dziś oferuje też samoobsługową platformę chmurową. Możesz korzystać z gotowych scraperów dla popularnych stron albo zlecić w pełni zarządzany projekt.
Kluczowe funkcje:
- ScrapeHero Cloud: gotowe scrapery dla Amazon, Google Maps, LinkedIn i innych
- Obsługa bez kodu, harmonogramy i dostarczanie danych z chmury
- Rozwiązania szyte na miarę dla nietypowych potrzeb
- Dostęp API do integracji programistycznych
Cennik:
Plany chmurowe od 5 USD/mies. Projekty custom od 550 USD za stronę (jednorazowo).
Opinie użytkowników:
Chwalony za niezawodność, jakość danych i wsparcie. Dobry wybór, gdy chcesz przejść od DIY do rozwiązań zarządzanych.
9. Sequentum
 Przegląd:
Przegląd:
Sequentum to enterprise’owy scyzoryk szwajcarski — z naciskiem na zgodność, audytowalność i ogromną skalę. Jeśli potrzebujesz SOC-2, śladów audytu i pracy zespołowej, to narzędzie jest dla Ciebie.
Kluczowe funkcje:
- Projektant agentów low-code (kliknij i wybierz + skrypty)
- SaaS w chmurze lub wdrożenie on-premise
- Wbudowane zarządzanie proxy, rozwiązywanie CAPTCHA i headless browser
- Ślady audytu, role i uprawnienia oraz zgodność SOC-2
Cennik:
Pay-as-you-go (6 USD/godz. runtime, 0,25 USD/GB eksportu), plan Starter: 199 USD/mies. 5 USD kredytu na start po rejestracji.
Opinie użytkowników:
Firmy doceniają zgodność i skalowalność. Jest krzywa uczenia, ale wsparcie i szkolenia stoją na wysokim poziomie.
10. Grepsr
 Przegląd:
Przegląd:
Grepsr to zarządzana usługa ekstrakcji danych — mówisz, czego potrzebujesz, a oni budują, uruchamiają i utrzymują scrapery za Ciebie. Idealne dla firm, które chcą danych bez technicznej przeprawy.
Kluczowe funkcje:
- Zarządzana ekstrakcja („Grepsr Concierge”) — konfiguracja i utrzymanie po ich stronie
- Panel w chmurze do harmonogramów, monitoringu i pobierania danych
- Wiele formatów wyjściowych i integracje (Dropbox, S3, Google Drive)
- Rozliczanie za rekord danych (a nie za zapytanie)
Cennik:
Pakiet startowy 350 USD (jednorazowa ekstrakcja), subskrypcje cykliczne wyceniane indywidualnie.
Opinie użytkowników:
Klienci cenią „hands-off” i szybkie wsparcie. Świetne dla zespołów nietechnicznych i tych, którzy wolą oszczędzać czas niż dłubać w konfiguracji.
Szybka tabela porównawcza: najlepsze API do web scrapingu
Oto ściąga dla wszystkich 10 platform:
| Platforma | Obsługiwane typy danych | Cena od | Darmowy okres próbny | Łatwość użycia | Wsparcie | Wyróżniki |
|---|---|---|---|---|---|---|
| Oxylabs | Web, SERP, e-com, nieruchomości | 49 USD/mies. | 7 dni/5k zapytań | Dla devów | 24/7, enterprise | OxyCopilot AI, ogromna pula proxy, geotargetowanie |
| ScrapingBee | Ogólny web, JS, CAPTCHA | 29 USD/mies. | 1k wywołań/mies. | Proste API | E-mail, fora | Headless Chrome, stealth proxy |
| Apify | Dowolny web, gotowe/własne | Darmowe/39 USD/mies. | Zawsze darmowy | Elastyczne, złożone | Społeczność, Discord | Marketplace Actorów, chmura, integracje |
| Decodo | Web, SERP, e-com, social | 50 USD/mies. | 7 dni/1k zapytań | Przyjazne | Czat 24/7 | Jedno API, playground, świetna opłacalność |
| Octoparse | Dowolny web, no-code | Darmowe/119 USD/mies. | 14 dni | Wizualne, no-code | E-mail, forum | UI kliknij-i-wybierz, chmura, Octoparse AI |
| Bright Data | Cały web, datasety | 1,05 USD/1k zapytań | Tak | Potężne, złożone | 24/7, enterprise | Największa sieć proxy, IDE, gotowe datasety |
| WebAutomation | Dane ustrukturyzowane, e-com, nieruchomości | 74 USD/mies. | 14 dni/10M wierszy | No-code, szablony | E-mail, czat | Gotowe ekstraktory, rozliczanie per wiersz |
| ScrapeHero | E-com, mapy, praca, custom | 5 USD/mies. | Tak | No-code, zarządzane | E-mail, tickety | Scrapery w chmurze, projekty custom, dostawa do Dropbox |
| Sequentum | Dowolny web, enterprise | 0 USD/199 USD/mies. | 5 USD kredytu | Low-code, wizualne | Premium | Ślady audytu, SOC-2, on-prem/chmura |
| Grepsr | Dowolne dane ustrukturyzowane, zarządzane | 350 USD jednorazowo | Próbka | W pełni zarządzane | Dedykowany opiekun | Concierge, płatność za rekord, integracje |
Jak wybrać odpowiednie narzędzie do web scrapingu dla firmy
Które narzędzie wybrać? Tak to zwykle rozpisuję zespołom, którym doradzam:
-
Jeśli chcesz zero kodu, szybkie efekty i czyszczenie danych przez AI:
Wybierz Thunderbit. To najszybsza droga od „potrzebuję danych” do „mam dane” — bez pilnowania skryptów i API.
-
Jeśli jesteś developerem i cenisz kontrolę oraz elastyczność:
Sprawdź Apify, ScrapingBee albo Oxylabs. Dają najwięcej mocy, ale wymagają konfiguracji i trochę utrzymania.
-
Jeśli jesteś użytkownikiem biznesowym i wolisz narzędzie wizualne:
WebAutomation świetnie sprawdza się w scrapingu „kliknij i wybierz”, szczególnie w e-commerce i lead gen.
-
Jeśli potrzebujesz zgodności, audytowalności lub funkcji enterprise:
Sequentum jest stworzone pod takie wymagania. Jest droższe, ale w branżach regulowanych często się opłaca.
-
Jeśli chcesz, żeby ktoś zrobił wszystko za Ciebie:
Grepsr albo usługi zarządzane ScrapeHero to dobry kierunek. Zapłacisz trochę więcej, ale Twoje ciśnienie Ci podziękuje.
Jeśli nadal nie masz pewności — większość platform ma darmowe testy, więc warto je po prostu przetestować.
Najważniejsze wnioski
- API do web scrapingu są dziś kluczowe dla firm opartych na danych — rynek ma urosnąć do ok. 1,8 mld USD do 2030.
- Ręczny scraping odchodzi do lamusa — przy anti-botach, proxy i ciągłych zmianach stron tylko API i narzędzia AI pozwalają skalować.
- Każde API/platforma ma swoje mocne strony:
- Oxylabs i Bright Data — skala i niezawodność
- Apify — elastyczność
- Decodo — opłacalność
- WebAutomation — no-code
- Sequentum — zgodność i audyt
- Grepsr — zarządzane pozyskiwanie danych bez angażowania zespołu technicznego
- Automatyzacja oparta na AI (np. Thunderbit) zmienia zasady gry — wyższa skuteczność, brak utrzymania i wbudowane przetwarzanie danych, którego klasyczne API nie oferują.
- Najlepsze narzędzie to to, które pasuje do Twojego procesu, budżetu i kompetencji technicznych. Warto testować i porównywać.
Jeśli masz dość psujących się skryptów i niekończącego się debugowania, wypróbuj Thunderbit — albo zajrzyj po więcej poradników na Thunderbit Blog, gdzie znajdziesz m.in. przewodniki o scrapingu Amazon, Google, PDF i nie tylko.
I pamiętaj: w świecie danych z internetu jedyne, co zmienia się szybciej niż same strony, to technologia, której używamy do ich scrapowania. Bądź ciekawy, automatyzuj — i oby Twoje proxy nigdy nie dostały bana.




