Twój CRM jest tak dobry, jak dane, które do niego wpadają. A najlepsze informacje bardzo często leżą na publicznych stronach — nie w drogich, „premium” bazach od zewnętrznych vendorów.
ekstraktor danych z internetu potrafi zamienić ten webowy chaos w schludne arkusze. Te naprawdę dobre ogarniają temat w kilka minut, bez żadnego kodowania.
Używałem takich narzędzi w realnych projektach — budowanie list leadów, monitoring cen konkurencji, zaciąganie katalogów produktowych. Niżej masz 12 opcji, które faktycznie dowiozły, ułożonych według tego, jak sprawdzały się w typowych zadaniach biznesowych.
Dlaczego ekstraktory danych z internetu są dziś biznesową koniecznością
Nie ma co się czarować: internet to największa (i najbardziej rozjechana) baza danych na świecie. W 2026 roku wygrywają firmy, które potrafią przekuć ten bałagan w konkretne wnioski. Według , organizacje podejmujące decyzje na podstawie danych są o 5% bardziej produktywne i o 6% bardziej rentowne niż konkurenci. To nie jest „kosmetyka” — to przewaga, którą widać w wynikach.
Narzędzia do ekstrakcja danych z internetu (czasem nazywane ekstraktorami stron lub rozwiązaniami do web extracting) są tu kluczowym elementem układanki. Pozwalają zespołom sprzedaży pozyskiwać dane z publicznych katalogów, social mediów i stron firmowych, aby budować precyzyjne listy prospektów — bez kupowania przestarzałych baz leadów i bez ryzyka, że stażysta zniknie w połowie maratonu kopiuj-wklej (). Zespoły marketingu i e-commerce używają ekstraktorów, by śledzić ceny konkurencji, monitorować stany magazynowe i porównywać produkty w czasie rzeczywistym — John Lewis przypisuje web scrapingowi wzrost sprzedaży o 4% dzięki lepszej polityce cenowej ().
Ale to nie tylko tabelki i procenty. Ekstraktory danych oszczędzają masę czasu (jeden z użytkowników mówił o „setkach godzin” dzięki automatyzacji zbierania danych) i ograniczają błędy ludzkie (). Zespoły operacyjne ustawiają dziś scrapery tak, by stale zbierały dane, które wcześniej zajmowały stażystom tygodnie — odzyskując godziny tracone na żmudne kopiowanie i wklejanie (). A dzięki ekstraktorom wspieranym przez AI nawet osoby nietechniczne mogą zamieniać strony WWW w uporządkowane dane gotowe do analizy ().
W skrócie: jeśli w 2026 roku nie korzystasz z ekstraktor danych z internetu, to bardzo możliwe, że zostawiasz na stole insighty (i pieniądze).
Jak wybraliśmy 12 najlepszych ekstraktorów danych z internetu
Przy takiej liczbie narzędzi do web extracting łatwo się zakopać. Przeklikałem dziesiątki opcji, ale do zestawienia weszło tylko 12. Oto kryteria, na których się oparłem:
- Łatwość użycia: czy osoba nietechniczna może szybko wystartować bez pisania kodu? Najwyżej oceniałem narzędzia no-code/low-code z intuicyjnym interfejsem ().
- Możliwości AI: rozwiązania nowej generacji, które upraszczają scraping dzięki AI — np. automatyczne wykrywanie pól, obsługa nawigacji po stronie albo możliwość opisania potrzeb zwykłym językiem ().
- Automatyzacja i harmonogramy: najlepsze ekstraktory działają „na autopilocie”. Wybrałem narzędzia z harmonogramowaniem cyklicznych zaciągnięć danych i monitoringiem stron ().
- Eksport i integracje: czy łatwo wyeksportujesz dane do Excel, Google Sheets, Airtable albo Notion? Dodatkowe punkty za integracje workflow ().
- Skalowalność i niezawodność: niezależnie od tego, czy zaciągasz jedną stronę czy tysiące — narzędzie ma to udźwignąć. Brałem też pod uwagę opinie użytkowników o stabilności.
- Zastosowania biznesowe: stawiałem na narzędzia popularne w sprzedaży, marketingu, e-commerce i operacjach — nie tylko wśród developerów.
Część narzędzi to świeże, AI-first nowości, inne to branżowe klasyki. Wszystkie mają jeden cel: pomóc Ci zamienić internet w Twoją firmową bazę danych — bez bólu głowy.
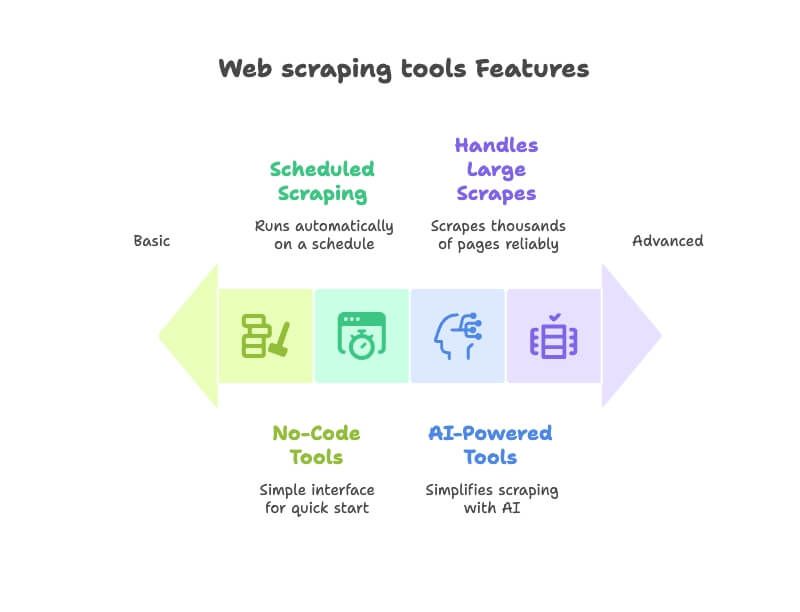
Szybkie porównanie: narzędzia do ekstrakcji danych z internetu w pigułce
Poniżej masz szybki przegląd 12 narzędzi, które omawiam — żeby od razu złapać, jak wypadają na tle siebie:
| Narzędzie | Automatyzacja AI | Łatwość użycia | Najlepsze zastosowanie |
|---|---|---|---|
| Thunderbit | Tak – AI podpowiada pola i automatycznie obsługuje strony | Bardzo łatwe (rozszerzenie Chrome, bez kodu) | Szybkie pozyskiwanie leadów, cen itp. przez osoby nietechniczne, które chcą efektów w kilka minut. |
| Octoparse | Ograniczona (szablony, bez AI) | Łatwe dla większości (wizualny interfejs „przeciągnij i upuść”) | Własne workflow scrapingu (logowanie, paginacja) dla analityków, którzy chcą kontroli bez kodowania. |
| Browse AI | Częściowa – roboty „wskaż i kliknij” | Łatwe (no-code, w chmurze) | Automatyczny monitoring danych (ceny, ogłoszenia itd.) wg harmonogramu, z alertami i integracjami. |
| WebScraper.io | Nie (konfiguracja ręczna) | Średnia (rozszerzenie przeglądarki + konfiguracja mapy strony) | Wizualny scraping wielopoziomowych serwisów dla osób gotowych skonfigurować kroki. |
| ScraperAPI | N/D (usługa API, proxy obsługiwane przez API) | Wymaga kodowania (integracja API) | Ekstrakcja danych na dużą skalę dla zespołów technicznych — proxy i CAPTCHA obsłużone przy masowych zaciągnięciach. |
| Data Miner | Nie | Bardzo łatwe (rozszerzenie przeglądarki + szablony „jednym kliknięciem”) | Szybkie, jednorazowe pobieranie danych ze stron (zwłaszcza tabele/listy) bezpośrednio do CSV/Excel. |
| Simplescraper | Nie (kilka funkcji wspieranych przez AI) | Łatwe (kreator „przepisów” wskaż i kliknij) | No-code scraping z integracjami — świetne do wysyłania danych do Google Sheets, Airtable lub API. |
| Instant Data Scraper | Tak – automatycznie wykrywa tabele danych | Bardzo łatwe (klik i działa, bez konfiguracji) | Błyskawiczny, darmowy scraping tabel i list HTML dla każdego (idealne do szybkich zaciągnięć). |
| ScrapeStorm | Tak – AI rozpoznaje elementy strony | Łatwe (wizualny interfejs; aplikacja wieloplatformowa) | Duże lub złożone projekty scrapingu bez kodu, także z harmonogramami crawlów. |
| Apify | Częściowo – dostępne gotowe boty „actor” | Średnia (panel web; kod opcjonalny) | Skalowalny scraping i automatyzacja w chmurze dzięki gotowym lub własnym skryptom. |
| ParseHub | Nie (bez skryptów, ale ręczna konfiguracja) | Łatwe w podstawach (edytor wizualny; aplikacja desktop) | Scraping dynamicznych/złożonych stron (treści AJAX) przez interfejs no-code. |
| OutWit Hub | Nie | Łatwe (desktopowa aplikacja GUI) | Prosta, lokalna ekstrakcja danych i archiwizacja treści dla mniejszych projektów. |
Większość narzędzi ma darmowy plan albo trial oraz subskrypcje w kilku wariantach. Skupiam się tu na możliwościach i zastosowaniach, a nie na cenach.
Thunderbit: ekstraktor danych z internetu z AI dla każdego

Zaczynamy od Thunderbit — tak, to „moje dziecko”, ale daj mi moment. Cała branża przesuwa się z podejścia „sam sobie skonfiguruj scraper” w stronę „powiedz AI, czego potrzebujesz”. Thunderbit to pierwsze narzędzie, jakie widziałem (i współtworzyłem), które naprawdę działa jak asystent danych oparty na AI, a nie kolejny „crawler”.
W nie bawisz się w XPath, selektory CSS ani regexy. Po prostu mówisz, jakie dane chcesz — np. „pobierz tytuł, autora i datę z tej strony” — a AI robi resztę (). Klikasz „AI Suggest Fields”, Thunderbit analizuje stronę, proponuje kolumny i automatycznie ogarnia podstrony oraz paginację ().
I to nie kończy się na samym pobraniu danych. Thunderbit potrafi czyścić, przekształcać, kategoryzować, a nawet tłumaczyć pola w trakcie scrapingu. Chcesz ujednolicić numery telefonów, streścić opisy albo przetłumaczyć nazwy produktów? Dopisujesz krótką instrukcję i AI to ogarnia. Na koniec eksportujesz dane prosto do Excel, Google Sheets, Airtable lub Notion ().
To, co naprawdę wyróżnia Thunderbit, to brak konfiguracji i praktycznie zerowa krzywa uczenia. To rozszerzenie Chrome, więc startujesz w kilka sekund. Bez dodatkowych wtyczek, bez ustawień, bez technicznego bełkotu. Dlatego Thunderbit jest ulubieńcem zespołów sprzedaży, marketingu i operacji, które potrzebują efektów — szybko (). Darmowy plan pozwala przetestować cały proces, a płatne pakiety są przystępne (dla większości zespołów to „mniej niż miesięczny budżet na kawę”).
Jeśli chcesz poczuć, jak wygląda web extracting z AI, i przetestuj. Twoje czasy kopiuj-wklej mogą właśnie przechodzić do historii.
Octoparse: wizualny ekstraktor danych do własnych workflow
Octoparse to klasyk w świecie wizualnego web scrapingu. To aplikacja desktopowa z interfejsem wskaż i kliknij — wchodzisz na stronę, zaznaczasz interesujące Cię elementy, a Octoparse buduje w tle cały workflow (). Ogarniesz logowanie, ustawisz paginację, a nawet zautomatyzujesz wysyłanie formularzy — bez kodu.
Mocną stroną Octoparse jest biblioteka ponad 500 gotowych szablonów dla popularnych serwisów (Amazon, Twitter, LinkedIn itd.), więc często wystarczy odpalić szablon i ruszyć z ekstrakcją (). Przy trudniejszych stronach przełączasz się na tryb ręczny i wizualnie ustawiasz każdy krok. Octoparse radzi sobie z treściami ładowanymi po kliknięciu lub przewinięciu, wspiera proxy i rozwiązywanie CAPTCHA. Jest też opcja chmurowa do harmonogramów i uruchamiania zadań na większą skalę.
Minus? Jest pewna krzywa uczenia, szczególnie przy bardziej zaawansowanych scenariuszach. Ale dla osób nietechnicznych i analityków danych, którzy chcą dopasowanego workflow scrapingu bez kodowania, Octoparse to naprawdę solidny wybór ().
Browse AI: automatyczna ekstrakcja danych dzięki gotowym robotom
Browse AI ma fajny koncept: „trenujesz robota”, klikając dane, które chcesz pobierać, a narzędzie uczy się wyciągać je z podobnych stron (). Wszystko działa w chmurze i bez kodu, więc nie przejmujesz się skryptami ani serwerami.
To, co wyróżnia Browse AI, to automatyzacja i monitoring. Możesz uruchamiać roboty cyklicznie i dostawać alerty, gdy dane się zmienią (np. konkurent obniży cenę albo pojawi się nowe ogłoszenie o pracę). Jest też biblioteka gotowych robotów do typowych zadań — często startujesz od gotowca i tylko go dopasowujesz ().
Browse AI integruje się z tysiącami aplikacji przez Zapier i Make oraz eksportuje dane bezpośrednio do Google Sheets albo przez API/webhooki (). To świetna opcja do ciągłego monitoringu i regularnego zbierania danych, zwłaszcza jeśli zależy Ci na alertach i integracjach bez ręcznej obsługi.
WebScraper.io: ekstraktor stron WWW w przeglądarce

WebScraper.io (często po prostu „Web Scraper”) to rozszerzenie przeglądarki, które pozwala budować „sitemapy” — wizualne plany nawigacji po stronie i wskazania, co ma zostać wyciągnięte (). Definiujesz selektory danych i linki do odwiedzenia (np. „kliknij dalej, aby przejść paginację” albo „wejdź w każdy produkt po szczegóły”).
Jest tu pewna krzywa uczenia, ale nadal bez kodowania — wybierasz elementy i ustawiasz akcje ekstrakcji. Web Scraper obsługuje nawigację wielopoziomową, paginację i nawet infinite scroll (choć kroki trzeba ustawić ręcznie). Działa w przeglądarce, więc możesz scrapować strony za logowaniem, logując się normalnie jak użytkownik.
WebScraper.io jest idealny dla „obywatelskich analityków danych”, którzy czują strukturę stron i chcą darmowego, elastycznego narzędzia. To niezawodny „koń roboczy”, jeśli nie przeszkadza Ci konfiguracja własnych sitemap.
ScraperAPI: ekstraktor danych w modelu API dla developerów i zespołów
Nie każdy zespół chce interfejs „kliknij i pobierz” — czasem potrzebujesz backendowego rozwiązania, które pcha dane prosto do aplikacji albo bazy. ScraperAPI to ekstraktor w modelu API-first: podajesz URL, a dostajesz surowy HTML lub dane, a całą trudną część (proxy, rotacja IP wg regionu, headless browser, CAPTCHA) narzędzie ogarnia za Ciebie ().
ScraperAPI utrzymuje pulę ponad 40 milionów proxy w ponad 50 krajach i przetwarza 36 miliardów zapytań miesięcznie (). Najlepiej sprawdza się w automatycznym scrapingu na dużą skalę, gdzie liczy się niezawodność i odporność na blokady. Potrzebujesz umiejętności programistycznych, ale jeśli budujesz pipeline danych albo integrujesz scraping z produktem, ScraperAPI to topowy wybór.
Data Miner: rozszerzenie Chrome do szybkiej ekstrakcji danych ze stron

Data Miner to rozszerzenie Chrome stworzone dla użytkowników biznesowych i badaczy, którzy chcą szybko pobrać dane. Oferuje scraping typu wskaż i kliknij oraz bibliotekę gotowych „receptur” dla typowych układów (tabele, listy, wybrane serwisy) ().
Instalujesz rozszerzenie, wchodzisz na stronę i klikasz ikonę Data Miner. Wybierasz recepturę albo robisz własną, zaznaczając elementy na stronie. To świetne narzędzie do jednorazowych zadań i szybkich potrzeb — np. handlowiec wyciąga listę leadów z katalogu, a manager e-commerce kopiuje ceny konkurencji.
Data Miner jest proste, działa w przeglądarce i idealnie pasuje do interaktywnego scrapingu na żądanie.
Simplescraper: no-code ekstraktor danych dla natychmiastowych efektów

Simplescraper robi dokładnie to, co sugeruje nazwa. To no-code rozszerzenie Chrome (i aplikacja webowa), które pozwala wizualnie zaznaczyć dane na stronie i stworzyć „recepturę” ekstrakcji (). Możesz podążać za linkami, scrapować podstrony, ogarnąć paginację, a nawet jednym kliknięciem wystawić scraping jako endpoint API.
Simplescraper szczególnie błyszczy w integracjach — dane możesz wysyłać bezpośrednio do Google Sheets, Airtable albo narzędzi typu Zapier (). Jest też scraping w chmurze i harmonogramy dla zadań cyklicznych oraz funkcja „AI Enhance”, która pomaga czyścić lub analizować dane z użyciem GPT.
Jeśli zależy Ci na szybkich wynikach i prostych integracjach, Simplescraper to taki scyzoryk wśród lekkich narzędzi do web scrapingu.
Instant Data Scraper: błyskawiczna ekstrakcja tabel i list
Czasem potrzebujesz danych na już i bez żadnego ustawiania. Wtedy wchodzi Instant Data Scraper (IDS). To darmowe rozszerzenie Chrome znane z scrapingu tabel jednym kliknięciem (). Odpalasz rozszerzenie, a IDS automatycznie wykrywa tabele lub listy na stronie. Potrafi też ogarnąć paginację i infinite scroll, automatycznie przechodząc przez kolejne strony.
IDS jest w 100% darmowy: bez rejestracji, bez kodu, bez czekania. Idealny do doraźnych lub pilnych potrzeb — np. szybka lista leadów dla handlowca albo dane z tabel Wikipedii dla studenta. Jeśli narzędzie rozpozna Twoje dane, masz je w kilka sekund.
ScrapeStorm: ekstraktor w chmurze z asystą AI
ScrapeStorm to narzędzie do web scrapingu wspierane przez AI, które łączy interfejs wizualny z mocnymi algorytmami (). Podajesz URL, a AI automatycznie rozpoznaje pola danych — listy, tabele, przyciski „następna strona” i inne.
ScrapeStorm działa wieloplatformowo (Windows, Mac, Linux) i oferuje scraping zarówno z desktopu, jak i w chmurze. Możesz planować zadania, uruchamiać wiele jobów równolegle i eksportować dane do Excel, CSV, JSON albo wysyłać je do bazy danych (). Jest szczególnie popularny w e-commerce i badaniach rynku, a dzięki AI potrafi też wyciągać dane z obrazów lub PDF.
Jeśli potrzebujesz inteligentnego wsparcia przy dużych lub złożonych projektach, ScrapeStorm zdecydowanie warto sprawdzić.
Apify: marketplace ekstraktorów i platforma automatyzacji

Apify to nie tylko scraper — to platforma web scrapingu i automatyzacji. Uruchamiasz tu „actors”, czyli skrypty do scrapingu lub automatyzacji przeglądarki. Największa wartość to marketplace gotowych actorów do typowych zadań (). Chcesz pobrać wszystkie opinie ze sklepu? Najpewniej istnieje actor, który to zrobi.
Dla developerów Apify pozwala pisać własne scrapery w Node.js lub Pythonie i wdrażać je w chmurze. Jest skalowalny, automatyzowalny i zintegrowany przez API. Najlepiej pasuje do power userów i organizacji, które traktują dane z internetu jako strategiczny zasób — np. stały scraping na dużą skalę albo integracja z pipeline danych.
ParseHub: wizualny ekstraktor stron dla trudnych serwisów

ParseHub to aplikacja desktopowa (z opcjami chmurowymi), znana z tego, że radzi sobie z złożonymi, dynamicznymi stronami. Poruszasz się po serwisie w interfejsie przypominającym przeglądarkę, klikasz interesujące dane, a ParseHub buduje scraper (). Obsługuje logikę warunkową, zagnieżdżony scraping, treści AJAX i więcej.
ParseHub często jest wyborem „ostatniej szansy”, gdy inne narzędzia nie potrafią poprawnie pobrać danych. Korzystają z niego badacze, analitycy i właściciele małych firm, którzy muszą ogarnąć trudne strony. Jest krzywa uczenia, ale jeśli masz skomplikowany serwis do scrapingu i nie chcesz kodować, ParseHub to świetna opcja.
OutWit Hub: desktopowy ekstraktor do archiwizacji treści

OutWit Hub jest trochę „oldschoolowy”, ale to aplikacja desktopowa, która świetnie nadaje się do zbierania różnych typów treści (linki, obrazy, adresy e-mail itd.) i porządkowania ich (). Działa jak połączenie przeglądarki i arkusza — wchodzisz na stronę, a OutWit Hub potrafi wyciągnąć tabele, listy, obrazy i inne elementy.
Jest szczególnie przydatny do archiwizacji treści i researchu — np. pobrania wszystkich postów z forum albo ściągnięcia kolekcji plików. To narzędzie lokalne, więc uruchamiasz je u siebie i zachowujesz większą prywatność danych. OutWit Hub najlepiej sprawdza się przy małych i średnich zadaniach, gdy chcesz prosty interfejs desktopowy.
Który ekstraktor danych z internetu będzie najlepszy dla Ciebie?
Dwanaście narzędzi, tysiąc scenariuszy. Co wybrać? Oto moja ściąga:
-
Dla totalnych początkujących lub jednorazowych, szybkich zadań:
Wypróbuj Instant Data Scraper do prostych tabel i list (darmowy i natychmiastowy). Data Miner to kolejna przyjazna opcja z większą liczbą szablonów, jeśli często scrapujesz podobne strony.
-
Dla osób nietechnicznych, które potrzebują cyklicznego scrapingu lub integracji:
Thunderbit daje najprostszy workflow dzięki podejściu AI — idealny dla zespołów biznesowych, które chcą szybko i często uzyskiwać wyniki. Browse AI świetnie nadaje się do ciągłego monitoringu i alertów. Simplescraper sprawdzi się, jeśli chcesz, by dane trafiały do Google Sheets lub do aplikacji wewnętrznej przez API.
-
Dla złożonych stron lub własnych workflow bez kodowania:
Wybierz wizualny scraper, np. Octoparse albo ParseHub. Octoparse jest przyjazny i ma mnóstwo szablonów. ParseHub radzi sobie z bardzo trudnymi, dynamicznymi stronami i daje dużą kontrolę. WebScraper.io też jest świetny, jeśli nie przeszkadza Ci konfiguracja własnych sitemap.
-
Dla developerów i inżynierów danych, którzy potrzebują skali:
ScraperAPI jest stworzone do osadzania web scrapingu w oprogramowaniu i projektów na dużą skalę. Apify pasuje, gdy potrzebujesz skalowalnej platformy z marketplace gotowych lub własnych skryptów.
-
Dla ekstrakcji treści i pracy offline:
OutWit Hub to dobry wybór do systematycznego zbierania i archiwizacji treści, zwłaszcza jeśli wolisz narzędzie desktopowe ze względu na prywatność lub kontrolę.
W praktyce sporo zespołów korzysta z kilku narzędzi — zależnie od zadania. Możesz zacząć od Instant Data Scraper do czegoś prostego, potem przesiąść się na Thunderbit lub Octoparse przy bardziej rozbudowanym projekcie, a ScraperAPI albo Apify wykorzystać, gdy trzeba „uprzemysłowić” proces. Dobra wiadomość: większość narzędzi ma darmowy plan lub trial, więc możesz spokojnie przetestować i wybrać to, co pasuje.
Podsumowanie: przyszłość ekstrakcji danych z internetu dla zespołów biznesowych
Narzędzia do ekstrakcja danych z internetu przeszły długą drogę. W 2026 roku to już mainstream. Największy trend? Web scraping jest coraz prostszy, bardziej zautomatyzowany i mocniej wbudowany w codzienne procesy (). Scrapery oparte na AI sprawiają, że nawet skomplikowane, dynamiczne strony da się ogarnąć bez specjalistycznych kompetencji. Jak ujął to jeden z inżynierów danych: „Gdy na rynku pojawiły się narzędzia do web scrapingu z AI, mogłem realizować zadania szybciej i na większą skalę... a dzięki AI [czyszczenie danych] jest automatycznie częścią mojego workflow.”
Druga duża zmiana to zacieranie granic między scrapingiem, monitoringiem i automatyzacją. Narzędzia takie jak Browse AI i Thunderbit nie tylko pobierają dane, ale też utrzymują je aktualne i potrafią wykonywać akcje (np. wypełniać formularze lub uruchamiać alerty). Wzrost adopcji jest wyraźny — jedna z dużych platform odnotowała wzrost miesięcznej liczby aktywnych użytkowników o ponad 140% rok do roku (). Firmy każdej wielkości widzą, że dostęp do publicznych danych z internetu (etycznie i legalnie) jest kluczowy, by utrzymać konkurencyjność.
Dla zespołów biznesowych wniosek jest prosty: sprawczość. Nie musisz czekać tygodniami na developera ani podejmować decyzji „na czuja”. Narzędzia z tej listy oddają webowe dane w Twoje ręce — z interfejsami i funkcjami dopasowanymi do realnych zastosowań w sprzedaży, marketingu, operacjach i nie tylko. A patrząc na tempo zmian, w najbliższym czasie spodziewam się jeszcze bardziej przyjaznych interfejsów, sprytniejszej AI i głębszych integracji z platformami BI oraz analityką.
Pamiętaj tylko: szanuj regulaminy stron i zasady robots.txt oraz upewnij się, że działasz zgodnie z przepisami o prywatności danych. Etyczny scraping jest ważny, jeśli te praktyki mają być trwałe.
Niezależnie od tego, czy zaczynasz od darmowego rozszerzenia, czy wdrażasz flotę scraperów klasy enterprise, to najlepszy moment, by zamienić informacje z internetu w konkretne działania. Rewolucja ekstraktorów danych już trwa — wybierz narzędzie, przetestuj i wydobądź wartość, która leży na widoku. Twoja przyszłość oparta na danych jest o jedno kliknięcie.
FAQ
1. Czym jest web extractor i dlaczego jest ważny dla firm?
Web extractor to narzędzie, które automatycznie zbiera uporządkowane dane ze stron internetowych. Jest ważne, bo pozwala firmom zamienić chaotyczne informacje online w praktyczne wnioski — zwiększając produktywność, poprawiając rentowność i eliminując ręczne zbieranie danych.
2. Kto może korzystać z ekstraktorów danych — czy potrzebuję umiejętności technicznych?
W wielu nowoczesnych narzędziach nie są potrzebne kompetencje techniczne. Thunderbit, Browse AI czy Instant Data Scraper są projektowane dla osób nietechnicznych: mają intuicyjne interfejsy, automatyzację opartą na AI i workflow no-code.
3. Jak zespoły sprzedaży, marketingu i operacji mogą skorzystać z ekstraktorów danych?
Sprzedaż może budować listy leadów z katalogów online, marketing monitorować ceny konkurencji, a operacje automatyzować procesy zbierania danych. Narzędzia oszczędzają czas, zmniejszają liczbę błędów i dostarczają świeżych, wiarygodnych insightów do decyzji strategicznych.
4. Na co zwrócić uwagę przy wyborze narzędzia do ekstrakcji danych z internetu?
Kluczowe są: łatwość użycia, funkcje AI, automatyzacja/harmonogramy, integracje (np. Google Sheets, Airtable), skalowalność oraz dopasowanie do Twojego zastosowania (np. leady sprzedażowe, monitoring cen, archiwizacja treści).
5. Czy są dostępne darmowe lub tanie narzędzia do ekstrakcji danych?
Tak. Wiele narzędzi ma darmowe plany lub przystępne pakiety. Instant Data Scraper jest całkowicie darmowy do podstawowych potrzeb, a Thunderbit, Simplescraper i Data Miner oferują rozbudowane darmowe wersje z możliwością rozszerzenia.
Chcesz dowiedzieć się więcej o web extracting, scrapingu z AI albo o tym, jak zamienić strony WWW w kolejną przewagę Twojego zespołu? Zajrzyj na — znajdziesz tam poradniki, wskazówki i historie z pierwszej linii automatyzacji danych.