Prawie połowę całego ruchu w internecie robią dziś boty. Większość z nich hurtowo zbiera linki, dane i adresy URL. Jeśli ty dalej dłubiesz to ręcznie, to po prostu zostajesz w tyle.
Przeklikałem i przetestowałem 12 narzędzi do wyciągania linków — od rozszerzeń Chrome z AI po biblioteki Pythona — żeby sprawdzić, które naprawdę dowożą, gdy trzeba szybko zgarnąć tysiące URL-i.
No i oto, co wyszło z testów.
Dlaczego ekstraktory linków są ważne
Nie ma co się oszukiwać: internet pęka w szwach od danych, a firmy ścigają się, żeby zamienić ten chaos w konkretne wnioski i decyzje. oraz stały się kluczowe dla zespołów, które chcą:
- Pozyskiwać leady: zespoły sprzedaży potrafią w kilka minut zebrać linki do profili firm z katalogów albo LinkedIn, a potem przekazać te URL-e do narzędzi wyciągających dane kontaktowe. Koniec z bezmyślnym klikaniem w kółko.
- Agregować treści i wzmacniać SEO: marketerzy mogą zebrać wszystkie adresy artykułów z bloga, monitorować linki zwrotne konkurencji albo zrobić audyt struktury strony pod kątem niedziałających odnośników.
- Monitorować konkurencję i robić research rynkowy: zespoły operacyjne mogą automatycznie zbierać linki do nowych produktów, stron z cennikiem czy informacji prasowych — bez wysiłku i bez ręcznej roboty.
- Automatyzować procesy i oszczędzać czas: nowoczesne narzędzia do zbierania linków obsługują hurtowe listy URL-i, przechodzą po podstronach i eksportują dane w uporządkowanych formatach (CSV, Excel, Google Sheets, Notion — co tylko chcesz). To oznacza koniec maratonów kopiuj-wklej i sprzątania chaotycznych plików tekstowych.
Skoro , ręczne podejście zwyczajnie nie ma sensu. Dobry ekstraktor linków działa jak turbo-asystent: nie męczy się, nie gubi odnośników i nie prosi o przerwę na kawę.
Jak wybraliśmy najlepsze ekstraktory linków
Przy takiej liczbie narzędzi wybór odpowiedniego ekstraktora linków bywa jak szybkie randki na konferencji technologicznej — każdy obiecuje, że jest „tym jedynym”, ale tylko nieliczni naprawdę dowożą. Tak zawęziłem listę do top 12:
- Łatwość użycia: czy osoba nietechniczna ogarnie temat bez doktoratu z regexów? Rozwiązania no-code i low-code dostawały dodatkowe punkty.
- Masowe i wielopoziomowe zbieranie: czy narzędzie ogarnia setki URL-i naraz? Czy potrafi automatycznie przechodzić po podstronach i podążać za linkami?
- Eksport i integracje: czy da się wyeksportować do CSV, Excela, Google Sheets, Notion, Airtable albo przez API? Im mniej ręcznej roboty, tym lepiej.
- Dla kogo i jak elastyczne: czy to narzędzie dla biznesu, analityków czy developerów? Jedne są bardziej uniwersalne, inne mocno wyspecjalizowane.
- Funkcje zaawansowane: rozpoznawanie oparte o AI, harmonogramy, skalowanie w chmurze, czyszczenie danych i szablony dla popularnych serwisów.
- Cena i skalowalność: darmowe plany, rozliczenie za użycie czy enterprise? Sprawdzałem, co realnie dostajesz za swoje pieniądze.
Wziąłem pod uwagę wszystko — od rozszerzeń przeglądarki po platformy klasy enterprise — więc niezależnie od tego, czy jesteś solo founderem, czy zespołem danych w Fortune 500, znajdziesz coś dla siebie.
Thunderbit: najinteligentniejszy ekstraktor linków dla użytkowników biznesowych
Zacznijmy od topu. to moja pierwsza rekomendacja do ekstrakcji linków — i nie tylko dlatego, że współtworzyłem to narzędzie. Thunderbit to zaprojektowane dla osób biznesowych, które chcą efektów — szybko.
Co wyróżnia Thunderbit? To jak stażysta AI, który naprawdę słucha. Wystarczy opisać po ludzku, czego potrzebujesz („Zbierz wszystkie linki do produktów i ceny z tej strony”), a AI Thunderbit ogarnie resztę. Bez dłubania w selektorach i bez pisania skryptów.
I to dopiero początek:
- Obsługa wielu URL-i: wklejasz jeden adres albo listę setek — Thunderbit przerabia wszystko za jednym podejściem.
- Nawigacja po podstronach: chcesz zebrać linki z listy, a potem wejść w każdą stronę szczegółów po kolejne URL-e? Wielowarstwowe scrapowanie w Thunderbit jest do tego stworzone.
- Uporządkowany eksport: po wyciągnięciu linków możesz zmieniać nazwy pól, kategoryzować je i eksportować bezpośrednio do Google Sheets, Notion, Airtable, Excela lub CSV. Bez bólu związanego z obróbką po fakcie.
Thunderbit jest używany przez ponad 30 000 osób na całym świecie — od zespołów sprzedaży, przez agentów nieruchomości, po niezależne sklepy e-commerce. I tak, jest też (do 6 stron, albo 10 z boostem w wersji próbnej), więc możesz przetestować bez ryzyka.
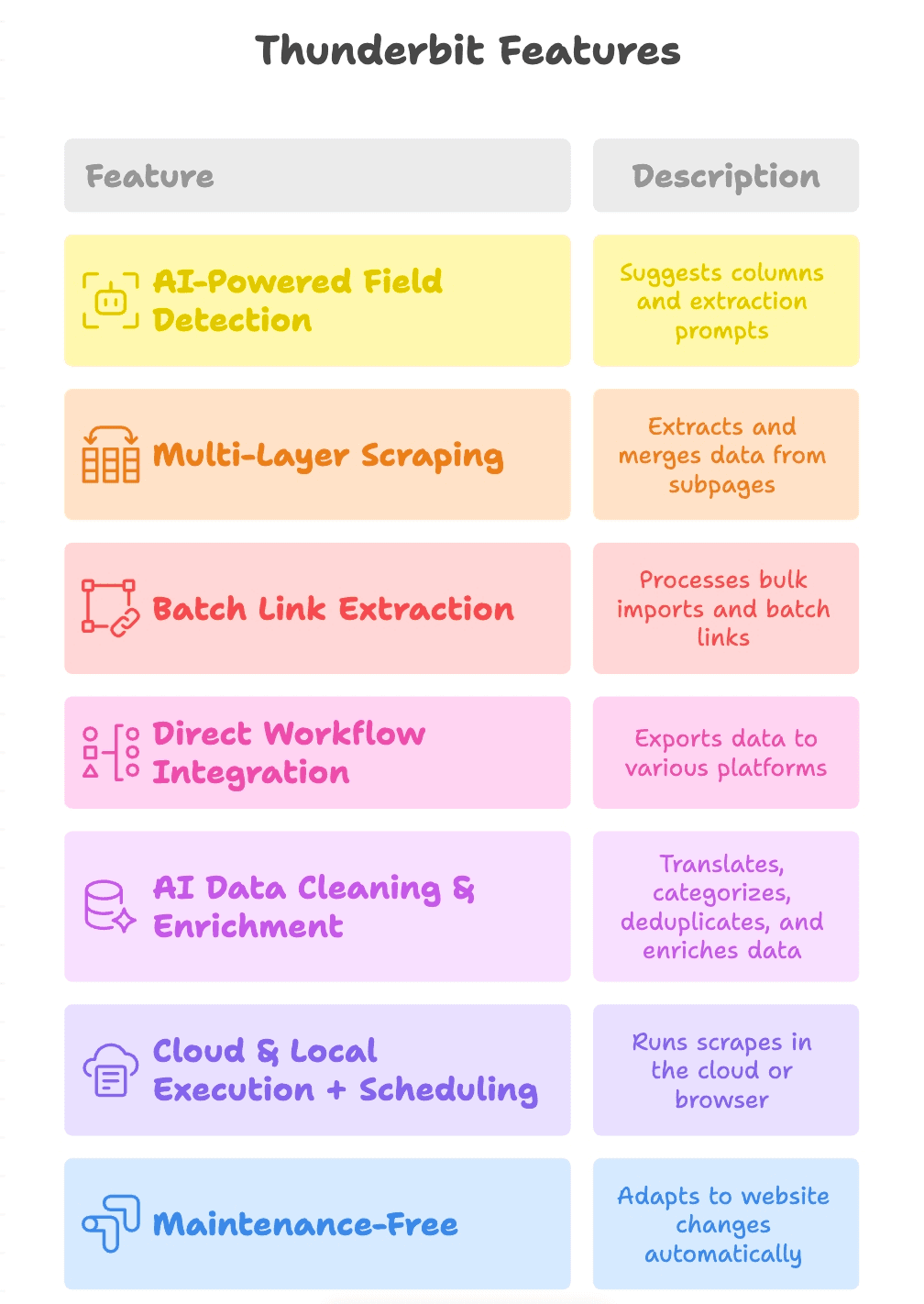
Najmocniejsze funkcje Thunderbit
Zobaczmy, co faktycznie robi różnicę:
- Wykrywanie pól oparte o AI: kliknij „AI Suggest Fields”, a Thunderbit analizuje stronę, proponuje kolumny (np. „Link do produktu”, „URL PDF”, „E-mail kontaktowy”) i tworzy prompty ekstrakcji dla każdego pola.
- Wielowarstwowe scrapowanie: Thunderbit potrafi przejść z głównej strony na podstrony (np. karty produktów lub pobrania PDF), wyciągnąć kolejne linki i scalić wszystko w jedną tabelę.
- Ekstrakcja linków w batchu: nieważne, czy zbierasz z jednej strony czy z tysiąca — Thunderbit spokojnie ogarnia import hurtowy i przetwarzanie wsadowe.
- Integracja z workflow: eksportuj wyniki do Google Sheets, Notion, Airtable albo pobierz jako CSV/Excel. Dane lądują dokładnie tam, gdzie potrzebuje ich zespół.
- Czyszczenie i wzbogacanie danych przez AI: Thunderbit potrafi tłumaczyć, kategoryzować, usuwać duplikaty, a nawet wzbogacać dane już w trakcie scrapowania — dzięki temu wynik jest gotowy do użycia, a nie tylko surowym zrzutem.
- Uruchamianie w chmurze i lokalnie + harmonogram: odpalaj scrapowanie w chmurze dla szybkości albo w przeglądarce dla stron wymagających logowania. Ustaw cykliczne zadania, by dane były zawsze aktualne.
- Bezobsługowość: AI Thunderbit dopasowuje się do zmian na stronach, więc mniej czasu tracisz na naprawianie, a więcej na wyniki.
Octoparse: no-code scraper linków dla każdego
to klasyk w świecie scrapowania bez kodu. To aplikacja desktopowa (Windows/Mac) z wizualnym interfejsem „wskaż i kliknij”. Ładujesz stronę, klikasz linki, które chcesz zebrać, a Octoparse dopina resztę.
- Świetny dla początkujących: bez programowania. Klikasz, wyciągasz, gotowe.
- Obsługa paginacji i treści dynamicznych: Octoparse potrafi klikać „Dalej”, przewijać i nawet logować się do serwisów.
- Scrapowanie w chmurze i harmonogram: płatne plany pozwalają uruchamiać zadania w chmurze i planować cykliczne pobrania.
- Opcje eksportu: pobieraj dane jako CSV, Excel, JSON albo wysyłaj do baz danych.
Darmowy plan jest hojny przy mniejszych zadaniach (do 10 zadań i 50 000 wierszy/miesiąc), ale przy większym użyciu potrzebny będzie plan płatny (od ok. 75 USD/mies.).
Apify: elastyczny ekstraktor URL do własnych workflow
to scyzoryk szwajcarski web scrapingu. Oferuje marketplace gotowych „aktorów” (narzędzi scrapujących), a także możliwość pisania własnych skryptów w JavaScript lub Python.
- Gotowe i konfigurowalne: używaj aktorów społeczności do typowych zadań albo buduj własne pod niestandardowe procesy.
- Masowe i zaplanowane scrapowanie: kolejkuj URL-e, uruchamiaj zadania równolegle i planuj cykliczne zbiory.
- API-first: eksport do JSON, CSV, Excel lub Google Sheets i integracja z pipeline’em danych.
- Rozliczenie za użycie: co miesiąc darmowe kredyty, potem płatność zależna od wykorzystania.
Apify świetnie pasuje do zespołów półtechnicznych i developerów, którzy potrzebują elastyczności i skali.
Bright Data URL Scraper: scrapowanie linków klasy enterprise
jest stworzone dla firm, które muszą scrapować na dużą skalę. Ich Data Collector ma gotowy URL Scraper do zadań wysokowolumenowych.
- Ogromna skala: tysiące lub miliony stron, z mocną infrastrukturą proxy, by unikać blokad.
- Gotowe szablony: scrapery dla e-commerce, social, nieruchomości i wielu innych.
- Funkcje enterprise: narzędzia zgodności, wsparcie ekspertów i zaawansowane omijanie blokad.
- Cena: startuje w okolicach 350 USD za 100 000 odsłon stron — zdecydowanie dla dużych graczy.
Dla startupu to może być przerost formy nad treścią. Ale do krytycznych, wysokowolumenowych zadań Bright Data to potężna opcja.
WebHarvy: wizualny ekstraktor linków „kliknij i zbierz”
to aplikacja desktopowa (Windows), która pozwala zbierać linki po prostu klikając je w wbudowanej przeglądarce.
- Banalnie proste: klikasz link, a WebHarvy podświetla podobne elementy do ekstrakcji.
- Obsługa wyrażeń regularnych: wbudowane wzorce do typowych zadań, bez kodowania.
- Eksport do Excel, CSV, JSON, XML, SQL: idealne dla biznesu, który chce dane w znanych formatach.
- Licencja jednorazowa: płacisz raz i używasz bezterminowo.
Świetne dla małych firm, badaczy i każdego, kto chce szybko pozyskać linki bez kombinowania.
Web Scraper (rozszerzenie Chrome): szybkie zbieranie linków w przeglądarce
to darmowe, open-source’owe narzędzie, które zamienia przeglądarkę w scraper.
- Definiowanie sitemap: określasz, jak ma nawigować i co ma wyciągać.
- Paginacja i wielopoziomowe crawlery: przechodzi po kategoriach, podkategoriach i stronach szczegółów.
- Eksport do CSV/XLSX: pobierasz dane bezpośrednio z przeglądarki.
- Szablony społeczności: masa udostępnionych sitemap dla popularnych stron.
Idealne do szybkich, jednorazowych zadań albo dla studentów i małych zespołów z ograniczonym budżetem.
ScraperAPI: skalowalny scraper linków dla developerów
jest dla developerów, którzy chcą pobierać strony na dużą skalę bez martwienia się o proxy, blokady czy CAPTCHA.
- Podejście API: wysyłasz URL, dostajesz HTML albo dane.
- Skala i omijanie anty-botów: rotacja proxy, renderowanie JS i rozwiązywanie CAPTCHA w pakiecie.
- Integracja z kodem: działa z Pythonem, Node.js i praktycznie każdym językiem.
- Cennik: darmowy plan (~1000 wywołań API), potem płatność za zapytania.
Świetne do własnych crawlerów i wszędzie tam, gdzie liczy się niezawodność oraz szybkość.
ParseHub: wizualny scraper linków z zaawansowanym wyborem
to aplikacja desktopowa (Windows, Mac, Linux), w której budujesz projekty scrapowania wizualnie.
- Zaawansowany wybór i nawigacja: klikasz, zapętlasz i warunkowo wyciągasz linki — nawet z elementów dynamicznych lub ukrytych.
- Obsługa zagnieżdżonych stron: kategorie → strony szczegółów → kolejne linki.
- Eksport do CSV, Excel, JSON: uruchomienia w chmurze i API w planach płatnych.
- Darmowy plan: 5 projektów, do 200 stron na jedno uruchomienie.
ParseHub to ulubieniec marketerów i badaczy, którzy chcą mocy bez kodu.
Scrapy: ekstraktor linków w Pythonie dla developerów
to złoty standard dla pythonowców, którzy chcą pełnej kontroli.
- Podejście code-first: budujesz własne „spidery” do crawl’owania i ekstrakcji linków w dowolnej skali.
- Obsługa crawl’owania rozproszonego: wydajne, asynchroniczne i mocno konfigurowalne.
- Eksport do CSV, JSON, XML lub bazy danych: Ty decydujesz o formacie.
- Open-source i darmowe: ale środowisko musisz ogarnąć samodzielnie.
Jeśli dobrze czujesz Pythona, Scrapy jest ekstremalnie mocne.
Diffbot: scraper linków oparty o AI dla danych ustrukturyzowanych
to „mózg AI” web scrapingu. Analizuje strony i zwraca ustrukturyzowane dane — w tym linki — bez ręcznej konfiguracji.
- Automatyczne rozpoznawanie treści: podajesz URL, dostajesz dane (artykuły, produkty, linki itd.).
- Crawlbot i Knowledge Graph: crawl całych serwisów albo zapytania do ich ogromnego indeksu sieci.
- Podejście API: integracja z BI i pipeline’em danych.
- Cennik enterprise: od ok. 299 USD/mies., ale w zamian dostajesz jakość.
Najlepsze dla firm, które chcą czystych, ustrukturyzowanych danych bez utrzymywania scraperów.
Cheerio: lekki scraper linków dla Node.js
to szybki parser HTML dla Node.js, podobny do jQuery.
- Bardzo szybki: parsuje HTML w milisekundach.
- Znana składnia: jeśli znasz jQuery, Cheerio będzie naturalne.
- Idealny do stron statycznych: nie renderuje JS, ale świetnie działa dla treści renderowanych po stronie serwera.
- Open-source i darmowe: połącz z axios lub fetch do pobierania stron.
Dla developerów piszących własne skrypty — szybko i prosto.
Puppeteer: automatyzacja przeglądarki do zaawansowanego zbierania linków
to biblioteka Node.js do sterowania Chrome w trybie headless.
- Pełna automatyzacja przeglądarki: ładowanie stron, klikanie, przewijanie i interakcje jak użytkownik.
- Dynamiczne treści i logowanie: idealne dla stron ciężkich od JavaScriptu i złożonych procesów.
- Precyzyjna kontrola: czekanie na elementy, zrzuty ekranu, przechwytywanie requestów.
- Open-source i darmowe: ale zasobożerne i wolniejsze niż lekkie narzędzia.
Sięgaj po Puppeteer, gdy musisz wyciągać linki ze stron, które nie współpracują z prostymi scraperami.
Porównanie w pigułce: który ekstraktor linków pasuje do Twoich potrzeb?
Szybkie zestawienie wszystkich 12 narzędzi:
| Narzędzie | Najlepsze dla | Obsługa masowa i podstron | Opcje eksportu danych | Cena |
|---|---|---|---|---|
| Thunderbit | Nietechniczni, biznes | Tak (AI, wielopoziomowo) | Excel, CSV, Sheets, Notion, Airtable | Darmowy trial, od ~9 USD/mies. |
| Octoparse | No-code, analitycy | Tak | CSV, Excel, JSON, storage w chmurze | Darmowy plan, ~75 USD/mies. |
| Apify | Półtechniczni, devs | Tak | CSV, JSON, Sheets przez API | Darmowe kredyty, za użycie |
| Bright Data | Enterprise | Tak (duży wolumen) | CSV, JSON, NDJSON przez API | ~350 USD/100k stron |
| WebHarvy | Nietechniczni, desktop | Tak | Excel, CSV, JSON, XML, SQL | Płatna licencja |
| Web Scraper Extension | Każdy, szybko/darmowo | Tak | CSV, XLSX | Darmowe, open-source |
| ScraperAPI | Developerzy, API | Tak | JSON (HTML przez API) | Darmowe 1k zapytań, płatne progi |
| ParseHub | Nietechniczni, zaawansowani | Tak | CSV, Excel, JSON, API | Darmowe 5 projektów, płatne |
| Scrapy | Developerzy, Python | Tak | CSV, JSON, XML, DB | Darmowe, open-source |
| Diffbot | Enterprise, AI | Tak (crawl AI) | JSON (dane ustrukturyzowane przez API) | ~299 USD/mies.+ |
| Cheerio | Developerzy, Node.js | Tak (własny kod) | Dowolne (JSON itd.) | Darmowe, open-source |
| Puppeteer | Developerzy, trudne strony | Tak (pełna automatyzacja) | Dowolne (wynik ze skryptu) | Darmowe, open-source |
Jak wybrać odpowiedni scraper linków dla firmy
Jak to dobrać? Oto moja szybka ściąga:
- Nie kodujesz? Zacznij od Thunderbit, Octoparse, ParseHub, WebHarvy albo rozszerzenia Web Scraper.
- Potrzebujesz własnych workflow? Apify, ScraperAPI lub Cheerio będą świetne dla developerów.
- Skala enterprise? Bright Data albo Diffbot są stworzone do tego.
- Jesteś developerem Pythona lub Node.js? Scrapy (Python) albo Cheerio/Puppeteer (Node.js) dają pełną kontrolę.
- Chcesz eksport bezpośrednio do Sheets/Notion? Thunderbit będzie najlepszym wyborem.
Dopasuj narzędzie do poziomu technicznego, wolumenu danych i potrzeb integracji. Większość ma darmowe wersje próbne — warto testować na własnych przypadkach.
Unikalna wartość Thunderbit w ekstrakcji linków w 2026
Wróćmy do tego, co realnie wyróżnia Thunderbit:
- Prostota dzięki AI: opisujesz cel zwykłym językiem — AI Thunderbit robi resztę.
- Wielowarstwowe scrapowanie: zbierasz linki z głównych stron, przechodzisz na podstrony i wyciągasz kolejne URL-e — w jednym procesie.
- Import hurtowy i przetwarzanie wsadowe: wklejasz setki URL-i, zbierasz linki masowo i od razu eksportujesz ustrukturyzowane dane.
- Integracja z workflow: eksport bezpośrednio do Google Sheets, Notion, Airtable albo pobranie CSV/Excel.
- Zero utrzymania: AI Thunderbit dopasowuje się do zmian na stronach, więc nie musisz ciągle naprawiać scraperów.
Thunderbit łączy „samo scrapowanie” z „danymi, które da się realnie wykorzystać”. To narzędzie, które chciałbym mieć lata temu, gdy tonąłem w ręcznych zadaniach związanych z danymi.
Podsumowanie: zbieraj linki mądrzej i przyspiesz pracę
Dane z internetu to paliwo wzrostu — a dobry ekstraktor linków to twój silnik. Niezależnie od tego, czy budujesz listy leadów, monitorujesz konkurencję, czy automatyzujesz research, na tej liście jest narzędzie dopasowane do twoich potrzeb i umiejętności.
Jeśli chcesz zobaczyć, jak wygląda nowoczesna ekstrakcja linków, . Zaskoczy cię, ile da się zrobić w kilka kliknięć. A jeśli Thunderbit nie będzie idealny, sprawdź kilka innych opcji z listy — nigdy nie było lepszego momentu, by zautomatyzować nudne rzeczy i skupić się na tym, co naprawdę ważne.
Powodzenia w scrapowaniu linków — i oby twoje URL-e zawsze były czyste, ustrukturyzowane i gotowe do działania. Jeśli chcesz wejść głębiej w temat web scrapingu, zajrzyj na po więcej poradników i wskazówek.
FAQ
1. Dlaczego ekstraktory linków są niezbędne?
Skoro niemal połowę ruchu w internecie generują boty, a firmy agresywnie pozyskują dane, ekstraktory linków są kluczowe, by zamienić webowy chaos w konkretne wnioski. Automatyzują m.in. pozyskiwanie leadów, agregację treści, audyty SEO i monitoring konkurencji, oszczędzając ogrom czasu i pracy.
2. Co wyróżnia Thunderbit na tle innych ekstraktorów linków?
Thunderbit upraszcza scrapowanie dzięki AI — wystarczy opisać cel zwykłym językiem, a narzędzie zajmie się resztą. Obsługuje masowe listy URL-i, wielowarstwowe scrapowanie, inteligentne wykrywanie pól oraz wygodny eksport do Google Sheets i Notion. To świetny wybór dla osób nietechnicznych i użytkowników biznesowych, którzy chcą mocnych efektów bez technicznych komplikacji.
3. Czy są narzędzia do ekstrakcji linków dla developerów i niestandardowych workflow?
Tak. Apify, ScraperAPI, Cheerio, Puppeteer i Scrapy są skierowane do developerów. Dają skrypty, integracje API i elastyczność potrzebną do złożonych zadań, dużej skali i zaawansowanej automatyzacji.
4. Które narzędzia są najlepsze dla osób bez doświadczenia w kodowaniu?
Thunderbit, Octoparse, ParseHub, WebHarvy oraz rozszerzenie Web Scraper do Chrome to najlepsze propozycje dla nietechnicznych użytkowników. Oferują interfejsy wizualne, gotowe szablony i funkcje oparte o AI, dzięki którym ekstrakcja linków jest dostępna dla każdego.
5. Jak wybrać właściwy ekstraktor linków do swoich potrzeb?
Weź pod uwagę umiejętności techniczne, wolumen danych i wymagania eksportu. Osoby nietechniczne powinny celować w Thunderbit lub Octoparse, a developerzy mogą preferować Scrapy albo Puppeteer. Firmy enterprise często wybierają Bright Data lub Diffbot do działań na dużą skalę. Najlepiej zacząć od darmowego triala i sprawdzić, co pasuje.