

Którego języka programowania użyć do web scrapingu? To zależy od Twojego projektu — i widziałem już developerów, którzy rzucali to wszystko w cholerę po wyborze złego narzędzia.
Rynek oprogramowania do web scrapingu osiągnął 1,01 mld USD w 2024 roku i według prognoz ma się ponad podwoić do 2032. Dobry język może dać szybsze efekty i mniej pracy przy utrzymaniu. Zły — połamane scrapery i zmarnowane weekendy.
Od lat tworzę narzędzia automatyzujące. Oto siedem języków, których używałem do scrapingu — wraz z przykładami kodu, uczciwym opisem kompromisów i wskazówką, kiedy lepiej odpuścić kodowanie i użyć zamiast tego Thunderbit.
Jak wybraliśmy najlepszy język do web scrapingu
Jeśli chodzi o web scraping, nie każdy język programowania jest sobie równy. Widziałem projekty, które pędziły do przodu — i takie, które runęły o ziemię — w zależności od kilku kluczowych czynników:
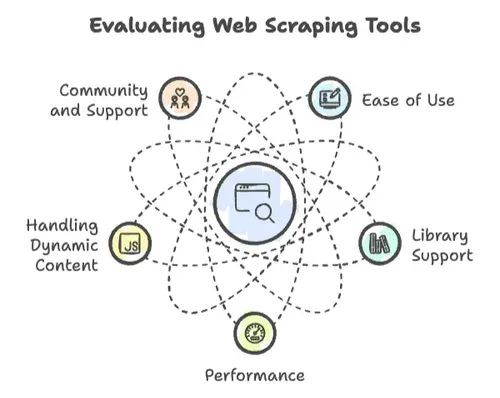
- Łatwość użycia: Jak szybko da się zacząć? Czy składnia jest przyjazna, czy trzeba doktoratu z informatyki, żeby wypisać „Hello, World”?
- Wsparcie bibliotek: Czy są solidne biblioteki do żądań HTTP, parsowania HTML i obsługi dynamicznej treści? Czy wszystko trzeba pisać od zera?
- Wydajność: Czy poradzi sobie z pobieraniem milionów stron, czy kończy się po kilkuset?
- Obsługa dynamicznej treści: Nowoczesne strony kochają JavaScript. Czy Twój język nadąża?
- Społeczność i wsparcie: Gdy trafisz na ścianę — a trafisz — czy jest społeczność, która pomoże?
Na podstawie tych kryteriów — i wielu nocnych testów — oto siedem języków, które omówię:
- Python: Pierwszy wybór zarówno dla początkujących, jak i profesjonalistów.
- JavaScript i Node.js: Królowie dynamicznej treści.
- Ruby: Czysta składnia, szybkie skrypty.
- PHP: Prostota po stronie serwera.
- C++: Gdy potrzebujesz surowej prędkości.
- Java: Gotowa na środowisko enterprise i skalowanie.
- Go (Golang): Szybki i współbieżny.
A jeśli myślisz: „Shuai, nie chcę w ogóle kodować”, zostań do końca — będzie o Thunderbit.
Web scraping w Pythonie: potęga przyjazna początkującym
Zacznijmy od ulubieńca tłumów: Pythona. Jeśli zapytasz salę pełną osób od danych: „Jaki jest najlepszy język programowania do web scrapingu?” — usłyszysz Pythona odbijającego się echem jak skandowanie na koncercie Taylor Swift.
Dlaczego Python?
- Składnia przyjazna początkującym: Kod Pythona można czytać na głos i brzmi prawie jak angielski.
- Bezkonkurencyjne wsparcie bibliotek: Od BeautifulSoup do parsowania HTML, przez Scrapy do dużych crawlów, po Requests do HTTP i Selenium do automatyzacji przeglądarki — Python ma to wszystko.
- Ogromna społeczność: Ponad 33 000 pytań na Stack Overflow tylko o web scraping.
Przykładowy kod w Pythonie: pobieranie tytułu strony
import requests
from bs4 import BeautifulSoup
response = requests.get("<https://example.com>")
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
print(f"Tytuł strony: {title}")
Mocne strony:
- Szybkie tworzenie i prototypowanie.
- Masa poradników i odpowiedzi na pytania.
- Świetny do analizy danych — scraping w Pythonie, analiza w pandas, wizualizacja w matplotlib.
- Biblioteki wciąż się rozwijają: wydanie Scrapy 2.14 (styczeń 2026) wprowadziło natywne
async/awaitw całym frameworku, więc historia asynchroniczności nie dotyczy już tylko Selenium/Playwright.
Ograniczenia:
- Wolniejszy niż języki kompilowane przy ogromnych zadaniach.
- Obsługa bardzo dynamicznych stron potrafi być nieporęczna (choć pomagają Selenium i Playwright).
- Nie jest idealny do scrapowania milionów stron w zawrotnym tempie.
Wniosek:
Jeśli dopiero zaczynasz ze scrapingiem albo po prostu chcesz szybko działać, Python to najlepszy język do web scrapingu — bez dyskusji. Więcej o tym, dlaczego Python dominuje w web scrapingu.
JavaScript i Node.js: łatwe scrapowanie dynamicznych stron
Jeśli Python jest scyzorykiem szwajcarskim, to JavaScript (i Node.js) jest wiertarką — zwłaszcza do scrapowania nowoczesnych stron naszpikowanych JavaScriptem.
Dlaczego JavaScript/Node.js?
- Natywny dla treści dynamicznej: Działa w przeglądarce, więc widzi to, co widzi użytkownik — nawet jeśli strona jest zbudowana w React, Angularze albo Vue.
- Asynchroniczny z natury: Node.js potrafi obsługiwać setki żądań naraz.
- Znajomy dla web developerów: Jeśli budowałeś stronę internetową, znasz już trochę JavaScript.
Najważniejsze biblioteki:
- Playwright: Wiele przeglądarek (Chromium, Firefox, WebKit) z automatycznym czekaniem i proxy per kontekst. Jeśli zaczynasz nowego scrapera w Node w 2026, to domyślny wybór.
- Puppeteer: Headless Chrome przez Chrome DevTools Protocol. Nadal świetny do zadań tylko dla Chrome i przy lżejszych zależnościach.
- Cheerio: Parsowanie HTML w stylu jQuery w Node, gdy nie potrzebujesz prawdziwej przeglądarki.
Przykładowy kod Node.js: pobieranie tytułu strony z Puppeteerem
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('<https://example.com>', { waitUntil: 'networkidle2' });
const title = await page.title();
console.log(`Tytuł strony: ${title}`);
await browser.close();
})();
Mocne strony:
- Natywnie obsługuje treści renderowane przez JavaScript.
- Świetny do scrapowania nieskończonego scrolla, okienek pop-up i interaktywnych stron.
- Wydajny przy dużym, współbieżnym scrapingu.
Ograniczenia:
- Asynchroniczne programowanie może być trudne dla początkujących.
- Headless browsery zjadają sporo pamięci, jeśli uruchomisz ich za dużo naraz.
- Mniej narzędzi do analizy danych niż w Pythonie.
Kiedy JavaScript/Node.js to najlepszy język do web scrapingu?
Gdy docelowa strona jest dynamiczna albo chcesz automatyzować akcje w przeglądarce. Więcej o Node.js do scrapowania dynamicznej treści.
Ruby: czysta składnia do szybkich skryptów web scrapingowych
Ruby to nie tylko aplikacje Rails i elegancka poezja kodu. To solidny wybór do web scrapingu — zwłaszcza jeśli lubisz, gdy kod czyta się jak haiku.
Dlaczego Ruby?
- Czytelna, ekspresyjna składnia: Możesz napisać scraper w Ruby, który jest prawie tak łatwy do czytania jak lista zakupów.
- Świetny do prototypowania: Szybki w pisaniu, łatwy do poprawiania.
- Kluczowe biblioteki: Nokogiri do parsowania, Mechanize do automatyzacji nawigacji.
Przykładowy kod Ruby: pobieranie tytułu strony
require 'open-uri'
require 'nokogiri'
html = URI.open("<https://example.com>")
doc = Nokogiri::HTML(html)
title = doc.at('title').text
puts "Tytuł strony: #{title}"
Mocne strony:
- Bardzo czytelny i zwięzły.
- Świetny do małych projektów, jednorazowych skryptów albo gdy i tak używasz Ruby.
Ograniczenia:
- Wolniejszy niż Python lub Node.js przy dużych zadaniach.
- Mniej bibliotek do scrapingu i słabsze wsparcie społeczności dla scrapingu.
- Nie jest idealny do stron mocno opartych na JavaScripcie (choć można użyć Watir albo Selenium).
Najlepsze zastosowanie:
Jeśli jesteś Rubyistą albo chcesz szybko sklecić skrypt, Ruby daje dużo frajdy. Do masowego, dynamicznego scrapingu lepiej szukać dalej.
PHP: prostota po stronie serwera w ekstrakcji danych z sieci
PHP może się wydawać reliktem wczesnego internetu, ale wciąż trzyma się mocno — zwłaszcza jeśli chcesz pobierać dane bezpośrednio na swoim serwerze.
Dlaczego PHP?
- Działa wszędzie: Większość serwerów WWW ma już PHP.
- Łatwo integruje się z aplikacjami webowymi: Możesz jednocześnie pobrać dane i wyświetlić je na swojej stronie.
- Kluczowe biblioteki: cURL do HTTP, Guzzle do żądań, Symfony Panther do automatyzacji headless browserów.
Przykładowy kod PHP: pobieranie tytułu strony
<?php
$ch = curl_init("<https://example.com>");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$html = curl_exec($ch);
curl_close($ch);
$dom = new DOMDocument();
@$dom->loadHTML($html);
$title = $dom->getElementsByTagName("title")->item(0)->nodeValue;
echo "Tytuł strony: $title\n";
?>
Mocne strony:
- Łatwy do wdrożenia na serwerach WWW.
- Dobry do scrapingu jako część procesu webowego.
- Szybki przy prostych zadaniach po stronie serwera.
Ograniczenia:
- Ograniczone wsparcie bibliotek dla zaawansowanego scrapingu.
- Nie jest stworzony do dużej współbieżności ani scrapingu na wielką skalę.
- Obsługa stron mocno opartych na JavaScripcie bywa trudna (choć Panther pomaga).
Najlepsze zastosowanie:
Jeśli Twój stack i tak jest w PHP albo chcesz pobierać i wyświetlać dane na stronie, PHP to praktyczny wybór. Więcej o PHP vs Python w scrapingu.
C++: wysokowydajny web scraping dla projektów na dużą skalę
C++ to sportowy samochód wśród języków programowania. Jeśli potrzebujesz surowej prędkości i kontroli, a trochę ręcznej roboty Ci nie straszne, C++ może Cię daleko zawieźć.
Dlaczego C++?
- Błyskawiczny: Wyprzedza większość języków w zadaniach obciążających procesor.
- Precyzyjna kontrola: Możesz zarządzać pamięcią, wątkami i optymalizacją wydajności.
- Kluczowe biblioteki: libcurl do HTTP, htmlcxx do parsowania.
Przykładowy kod C++: pobieranie tytułu strony
#include <curl/curl.h>
#include <iostream>
#include <string>
size_t WriteCallback(void* contents, size_t size, size_t nmemb, void* userp) {
std::string* html = static_cast<std::string*>(userp);
size_t totalSize = size * nmemb;
html->append(static_cast<char*>(contents), totalSize);
return totalSize;
}
int main() {
CURL* curl = curl_easy_init();
std::string html;
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "<https://example.com>");
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html);
CURLcode res = curl_easy_perform(curl);
curl_easy_cleanup(curl);
}
std::size_t startPos = html.find("<title>");
std::size_t endPos = html.find("</title>");
if(startPos != std::string::npos && endPos != std::string::npos) {
startPos += 7;
std::string title = html.substr(startPos, endPos - startPos);
std::cout << "Tytuł strony: " << title << std::endl;
} else {
std::cout << "Nie znaleziono tagu tytułu" << std::endl;
}
return 0;
}
Mocne strony:
- Niezrównana prędkość przy ogromnych zadaniach scrapingowych.
- Świetny do włączania scrapingu do systemów o wysokiej wydajności.
Ograniczenia:
- Stroma krzywa uczenia się (weź kawę).
- Ręczne zarządzanie pamięcią.
- Ograniczone biblioteki wysokiego poziomu; nie jest idealny do dynamicznej treści.
Najlepsze zastosowanie:
Gdy trzeba pobierać miliony stron albo wydajność jest absolutnie kluczowa. W innym wypadku możesz spędzić więcej czasu na debugowaniu niż na scrapowaniu.
Java: web scraping gotowy do zastosowań enterprise
Java to koń pociągowy świata enterprise. Jeśli budujesz coś, co ma działać wiecznie, obsługiwać tony danych i przetrwać apokalipsę zombie, Java będzie Twoim sprzymierzeńcem.
Dlaczego Java?
- Solidna i skalowalna: Świetna do dużych, długodziałających projektów scrapingowych.
- Silne typowanie i obsługa błędów: Mniej niespodzianek na produkcji.
- Kluczowe biblioteki: Jsoup do parsowania, Selenium WebDriver do automatyzacji przeglądarki, Apache HttpClient do HTTP.
Przykładowy kod Java: pobieranie tytułu strony
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class ScrapeTitle {
public static void main(String[] args) throws Exception {
Document doc = Jsoup.connect("<https://example.com>").get();
String title = doc.title();
System.out.println("Tytuł strony: " + title);
}
}
Mocne strony:
- Wysoka wydajność i współbieżność.
- Doskonała do dużych, łatwych w utrzymaniu baz kodu.
- Dobre wsparcie dla dynamicznej treści (przez Selenium lub HtmlUnit).
Ograniczenia:
- Rozgadana składnia; więcej konfiguracji niż w językach skryptowych.
- Przerost formy nad treścią przy małych, jednorazowych skryptach.
Najlepsze zastosowanie:
Scraping na poziomie enterprise albo wtedy, gdy potrzebujesz niezawodności i skalowalności bez kompromisów.
Go (Golang): szybki i współbieżny web scraping
Go to nowy gracz na rynku, ale już robi spore zamieszanie — zwłaszcza w szybkim, współbieżnym scrapingu.
Dlaczego Go?
- Szybkość kompilacji: Prawie tak szybki jak C++.
- Wbudowana współbieżność: Goroutines sprawiają, że równoległy scraping to pestka.
- Kluczowe biblioteki: Colly do scrapingu, Goquery do parsowania.
Przykładowy kod Go: pobieranie tytułu strony
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("Tytuł strony:", e.Text)
})
err := c.Visit("<https://example.com>")
if err != nil {
fmt.Println("Błąd:", err)
}
}
Mocne strony:
- Błyskawiczny i wydajny przy scrapingu na dużą skalę.
- Łatwy do wdrożenia (jeden binarny plik).
- Świetny do współbieżnego crawlowania.
Ograniczenia:
- Mniejsza społeczność niż Python czy Node.js.
- Mniej wysokopoziomowych bibliotek do scrapingu.
- Obsługa stron ciężkich od JavaScriptu wymaga dodatkowej konfiguracji (Chromedp lub Selenium).
Najlepsze zastosowanie:
Gdy trzeba scrapować na dużą skalę albo Python po prostu nie jest wystarczająco szybki. Go vs Python w scrapingu: porównanie wydajności.
Porównanie najlepszych języków programowania do web scrapingu
Złóżmy to wszystko w całość. Oto porównanie obok siebie, które pomoże Ci wybrać najlepszy język do web scrapingu w 2026 roku:
| Język/narzędzie | Łatwość użycia | Wydajność | Wsparcie bibliotek | Obsługa dynamicznej treści | Najlepsze zastosowanie |
|---|---|---|---|---|---|
| Python | Bardzo wysoka | Umiarkowana | Doskonałe | Dobre (Selenium/Playwright) | Zastosowania ogólne, początkujący, analiza danych |
| JavaScript/Node.js | Średnia | Wysoka | Mocne | Doskonała (natywna) | Dynamiczne strony, asynchroniczny scraping, web developerzy |
| Ruby | Wysoka | Umiarkowana | Przyzwoite | Ograniczona (Watir) | Szybkie skrypty, prototypowanie |
| PHP | Średnia | Umiarkowana | Zadowalające | Ograniczona (Panther) | Po stronie serwera, integracja z aplikacjami webowymi |
| C++ | Niska | Bardzo wysoka | Ograniczone | Bardzo ograniczona | Krytyczna wydajność, ogromna skala |
| Java | Średnia | Wysoka | Dobre | Dobre (Selenium/HtmlUnit) | Enterprise, długodziałające usługi |
| Go (Golang) | Średnia | Bardzo wysoka | Rozwijające się | Umiarkowana (Chromedp) | Szybki, współbieżny scraping |
Kiedy pominąć kodowanie: Thunderbit jako no-code rozwiązanie do web scrapingu
Wypróbuj AI Web Scraper Thunderbit No-code, oparte na AI web scraping dla użytkowników biznesowych, marketerów i zespołów sprzedaży. Get Started Free
Dobra, bądźmy szczerzy: czasem po prostu chcesz mieć dane — bez kodowania, debugowania i dramatu w stylu „dlaczego ten selektor nie działa?”. Właśnie wtedy wchodzi Thunderbit.
Jako współzałożyciel Thunderbit chciałem zbudować narzędzie, które sprawi, że web scraping będzie tak prosty jak zamówienie jedzenia na wynos. Oto, co wyróżnia Thunderbit:
- Konfiguracja w 2 kliknięciach: Po prostu kliknij „AI Suggest Fields” i „Scrape”. Bez grzebania przy żądaniach HTTP, proxy czy sztuczkach antybotowych.
- Inteligentne szablony: Jeden szablon scrapera może dopasować się do wielu układów stron. Nie trzeba przepisywać scrapera za każdym razem, gdy strona się zmieni.
- Scraping w przeglądarce i w chmurze: Wybierasz między scrapingiem w przeglądarce (świetne dla stron z logowaniem) a w chmurze (bardzo szybkie dla danych publicznych).
- Obsługa dynamicznej treści: AI w Thunderbit steruje prawdziwą przeglądarką — więc poradzi sobie z nieskończonym przewijaniem, pop-upami, logowaniem i wieloma innymi rzeczami.
- Eksport gdzie chcesz: Pobierz do Excel, Google Sheets, Airtable, Notion albo po prostu skopiuj do schowka.
- Brak utrzymania: Jeśli strona się zmieni, wystarczy ponownie uruchomić podpowiedzi AI. Koniec z nocnym debugowaniem.
- Harmonogram i automatyzacja: Ustaw scrapery tak, by działały według harmonogramu — bez cronów i bez konfiguracji serwera.
- Specjalistyczne ekstraktory: Potrzebujesz e-maili, numerów telefonów albo obrazów? Thunderbit ma też ekstraktory jednym kliknięciem.
A najlepsze? Nie musisz znać ani jednej linijki kodu. Thunderbit jest stworzony dla użytkowników biznesowych, marketerów, zespołów sprzedaży, specjalistów od nieruchomości — dla każdego, kto potrzebuje danych szybko.
Chcesz zobaczyć Thunderbit w akcji? Pobierz rozszerzenie do Chrome albo zajrzyj na nasz kanał YouTube, żeby zobaczyć demo.
Wypróbuj AI Web Scraper Thunderbit za darmo
Podsumowanie: wybór najlepszego języka do web scrapingu w 2026 roku
Czym jest data scraping i jak go robić Get Started Free
Web scraping w 2026 roku jest bardziej dostępny — i potężniejszy — niż kiedykolwiek. Oto, czego nauczyłem się po latach w automatyzacyjnych okopach:
- Python nadal jest najlepszym językiem do web scrapingu, jeśli chcesz szybko zacząć i mieć pod ręką mnóstwo zasobów.
- JavaScript/Node.js nie ma sobie równych w scrapowaniu dynamicznych stron ciężkich od JavaScriptu.
- Ruby i PHP świetnie nadają się do szybkich skryptów i integracji z webem, zwłaszcza jeśli już z nich korzystasz.
- C++ i Go są Twoimi sprzymierzeńcami, gdy liczą się szybkość i skala.
- Java to wybór numer jeden w projektach enterprise i długoterminowych.
- A jeśli chcesz całkiem pominąć kodowanie? Thunderbit to Twoja tajna broń.
Zanim zaczniesz, zadaj sobie kilka pytań:
- Jak duży jest mój projekt?
- Czy muszę obsługiwać dynamiczną treść?
- Jaki jest mój poziom komfortu technicznego?
- Chcę budować, czy po prostu zdobyć dane?
Wypróbuj któryś z przykładów kodu powyżej albo przetestuj Thunderbit w swoim następnym projekcie. A jeśli chcesz wejść głębiej, zajrzyj na nasz blog Thunderbit, gdzie znajdziesz więcej poradników, wskazówek i historii scrapingu z prawdziwego świata.
Miłego scrapowania — oby Twoje dane zawsze były czyste, uporządkowane i na wyciągnięcie jednego kliknięcia.
P.S. Jeśli kiedykolwiek utkniesz o 2:00 w nocy w króliczej norze web scrapingu, pamiętaj: zawsze jest Thunderbit. Albo kawa. Albo jedno i drugie.
Wypróbuj teraz AI Web Scraper Thunderbit Get Started Free
FAQ
1. Jaki jest najlepszy język programowania do web scrapingu w 2026 roku?
Python pozostaje najlepszym wyborem dzięki czytelnej składni, mocnym bibliotekom (takim jak BeautifulSoup, Scrapy i Selenium) oraz dużej społeczności. Świetnie sprawdza się zarówno u początkujących, jak i u profesjonalistów, zwłaszcza gdy łączysz scraping z analizą danych.
2. Który język najlepiej nadaje się do scrapowania stron mocno opartych na JavaScripcie?
JavaScript (Node.js) to najlepszy wybór dla dynamicznych stron. Narzędzia takie jak Puppeteer i Playwright dają pełną kontrolę nad przeglądarką, pozwalając wchodzić w interakcję z treścią ładowaną przez React, Vue czy Angular.
3. Czy istnieje opcja no-code dla web scrapingu?
Tak — Thunderbit to no-code AI web scraper, który ogarnia wszystko: od dynamicznej treści po harmonogramy. Wystarczy kliknąć „AI Suggest Fields” i zacząć scrapować. To idealne rozwiązanie dla zespołów sprzedaży, marketingu lub operacji, które szybko potrzebują uporządkowanych danych.
4. Czy nadal muszę wybierać język, jeśli agent AI do kodowania może napisać scraper za mnie?
To rozsądne pytanie w 2026 roku. Narzędzia takie jak Claude Code, Cursor i OpenAI Codex chętnie wygenerują spidera Scrapy, skrypt Playwright albo crawlera w Go + Colly na podstawie jednego akapitu promptu — więc tarcie związane z pytaniem „którego języka mam się uczyć najpierw” jest naprawdę mniejsze niż dwa lata temu. Ale agent i tak generuje kod w jakimś języku, a Ty (albo osoba, która przejmie projekt) finalnie czytasz go, debugujesz i wdrażasz. Dlatego wybór nadal ma znaczenie; po prostu bardziej dla utrzymania niż dla pierwszych 30 linii. Jeśli nie chcesz dotykać żadnego kodu, właśnie tu pasuje Thunderbit — całkiem omija pytanie o język.
Dowiedz się więcej:




