
Niedziałające linki. Osierocone podstrony. Jakaś „testowa” strona z 2019 roku, którą Google — nie wiadomo jakim cudem — jednak zaindeksował. Jeśli ogarniasz witrynę, to ten ból znasz aż za dobrze.
Dobry crawler strony internetowej wyłapie takie „kwiatki” — i rozrysuje całą strukturę serwisu tak, żeby dało się to naprawdę naprawić. Problem w tym, że sporo osób wrzuca do jednego worka „web crawler” i web scraping. A to jednak dwie różne bajki.
Przetestowałem 10 darmowych narzędzi do crawling stron na prawdziwych serwisach. Część jest świetna pod audyty SEO. Inne lepiej sprawdzają się, gdy celem jest pozyskiwanie danych. Poniżej: co działało — a co nie.
Czym jest crawler strony internetowej? Podstawy bez ściemy
Najpierw uporządkujmy pojęcia: crawler strony to nie to samo co web scraper. Wiem — te terminy fruwają po sieci jak mąka przy wyrabianiu ciasta, ale różnica jest fundamentalna. Crawler to kartograf Twojej witryny: zagląda w każdy zakamarek, idzie po linkach i buduje mapę wszystkich podstron. Jego zadaniem jest odkrywanie: znajdowanie adresów URL, odwzorowanie struktury serwisu i indeksowanie treści. Dokładnie tak działają boty wyszukiwarek (np. Google) oraz narzędzia SEO, które sprawdzają kondycję strony ().
Web scraper to z kolei górnik danych. Nie interesuje go pełna mapa — on chce wydobyć „złoto”: ceny produktów, nazwy firm, opinie, e-maile i wszystko, co da się ustrukturyzować. Scraper wyciąga konkretne pola z podstron, które crawler wcześniej znalazł ().
Czas na analogię:
- Crawler: osoba, która przechodzi każdą alejkę w sklepie i spisuje wszystkie produkty.
- Scraper: osoba, która idzie prosto do półki z kawą i zapisuje ceny wszystkich ekologicznych mieszanek.
Dlaczego to ważne? Bo jeśli chcesz po prostu znaleźć wszystkie podstrony w serwisie (np. do audytu SEO), potrzebujesz crawlera. Jeśli chcesz wyciągnąć ceny produktów z witryny konkurencji, potrzebujesz scrapera — albo najlepiej narzędzia, które potrafi jedno i drugie.
Po co używać crawlera online? Najważniejsze korzyści biznesowe
Po co w ogóle bawić się w crawling? Bo internet nie robi się mniejszy. Co więcej, ponad , żeby optymalizować swoje serwisy, a niektóre narzędzia SEO skanują nawet .
Co crawler może zrobić dla Ciebie:
- Audyty SEO: wykrywanie niedziałających linków, brakujących tytułów, duplikatów treści, osieroconych podstron i wielu innych problemów ().
- Kontrola linków i QA: wyłapywanie 404 i pętli przekierowań, zanim zrobią to użytkownicy ().
- Generowanie sitemap: automatyczne tworzenie map XML dla wyszukiwarek i planowania prac ().
- Inwentaryzacja treści: lista wszystkich podstron wraz z hierarchią i metadanymi.
- Zgodność i dostępność: sprawdzanie każdej strony pod kątem WCAG, SEO i wymogów prawnych ().
- Wydajność i bezpieczeństwo: wskazywanie wolnych podstron, zbyt dużych obrazów czy potencjalnych problemów bezpieczeństwa ().
- Dane do AI i analiz: zasilanie danymi narzędzi analitycznych lub rozwiązań AI ().
Szybka tabelka: zastosowania vs role w firmie:
| Zastosowanie | Dla kogo | Korzyść / efekt |
|---|---|---|
| SEO i audyt serwisu | Marketing, SEO, właściciele małych firm | Wykrycie problemów technicznych, lepsza struktura, wyższe pozycje |
| Inwentaryzacja treści i QA | Content managerowie, webmasterzy | Audyt lub migracja treści, wykrywanie niedziałających linków/obrazów |
| Generowanie leadów (scraping) | Sprzedaż, business development | Automatyzacja prospectingu, zasilanie CRM świeżymi leadami |
| Analiza konkurencji | E-commerce, product managerowie | Monitoring cen, nowych produktów i zmian dostępności |
| Sitemap i klonowanie struktury | Developerzy, DevOps, konsultanci | Odtworzenie struktury pod redesign lub backup |
| Agregacja treści | Badacze, media, analitycy | Zbieranie danych z wielu źródeł do analiz i trendów |
| Badania rynku | Analitycy, zespoły trenujące AI | Pozyskiwanie dużych zbiorów danych do analiz lub treningu modeli AI |
()
Jak wybraliśmy najlepsze darmowe crawlery stron
Spędziłem sporo późnych wieczorów (i wypiłem więcej kawy, niż chciałbym przyznać), przekopując narzędzia, dokumentacje i odpalając testowe skany. Oto kryteria:
- Możliwości techniczne: czy radzi sobie z nowoczesnymi stronami (JavaScript, logowanie, treści dynamiczne)?
- Wygoda użycia: czy jest przyjazny dla nietechnicznych osób, czy wymaga magii w terminalu?
- Ograniczenia wersji darmowej: czy to faktycznie „free”, czy tylko haczyk?
- Dostępność: chmura, aplikacja desktopowa czy biblioteka do kodu?
- Unikalne funkcje: coś ekstra — np. ekstrakcja AI, wizualne mapy, crawling zdarzeniowy.
Każde narzędzie przetestowałem, przejrzałem opinie użytkowników i porównałem funkcje obok siebie. Jeśli coś sprawiało, że miałem ochotę wyrzucić laptop przez okno — nie trafiało na listę.
Szybkie porównanie: 10 najlepszych darmowych crawlerów w pigułce
| Narzędzie i typ | Kluczowe funkcje | Najlepsze zastosowanie | Wymagania techniczne | Szczegóły planu darmowego |
|---|---|---|---|---|
| BrightData (Cloud/API) | Crawling klasy enterprise, proxy, renderowanie JS, omijanie CAPTCHA | Duża skala pozyskiwania danych | Przydaje się wiedza techniczna | Trial: 3 scrapery, po 100 rekordów (ok. 300 rekordów łącznie) |
| Crawlbase (Cloud/API) | Crawling przez API, anti-bot, proxy, renderowanie JS | Devowie potrzebujący infrastruktury backendowej | Integracja API | Free: ok. 5 000 wywołań API przez 7 dni, potem 1 000/mies. |
| ScraperAPI (Cloud/API) | Rotacja proxy, renderowanie JS, crawling async, gotowe endpointy | Devowie, monitoring cen, dane SEO | Minimalna konfiguracja | Free: 5 000 wywołań API przez 7 dni, potem 1 000/mies. |
| Diffbot Crawlbot (Cloud) | Crawling + ekstrakcja AI, knowledge graph, renderowanie JS | Ustrukturyzowane dane w skali, AI/ML | Integracja API | Free: 10 000 kredytów/mies. (ok. 10 tys. stron) |
| Screaming Frog (Desktop) | Audyt SEO, analiza linków/meta, sitemap, własna ekstrakcja | Audyty SEO, zarządzanie serwisem | Aplikacja desktopowa, GUI | Free: 500 URL na crawl, tylko podstawowe funkcje |
| SiteOne Crawler (Desktop) | SEO, wydajność, dostępność, bezpieczeństwo, eksport offline, Markdown | Devowie, QA, migracje, dokumentacja | Desktop/CLI, GUI | Free i open-source, 1 000 URL w raporcie GUI (konfigurowalne) |
| Crawljax (Java, OpenSrc) | Crawling zdarzeniowy dla stron JS, eksport statyczny | Devowie, QA aplikacji dynamicznych | Java, CLI/konfiguracja | Free i open-source, bez limitów |
| Apache Nutch (Java, OpenSrc) | Rozproszony crawling, wtyczki, integracja z Hadoop, własna wyszukiwarka | Własne wyszukiwarki, crawling na dużą skalę | Java, wiersz poleceń | Free i open-source, koszt tylko infrastruktury |
| YaCy (Java, OpenSrc) | P2P crawling i wyszukiwarka, prywatność, indeksowanie web/intranet | Prywatne wyszukiwanie, decentralizacja | Java, UI w przeglądarce | Free i open-source, bez limitów |
| PowerMapper (Desktop/SaaS) | Wizualne sitemap, dostępność, QA, kompatybilność przeglądarek | Agencje, QA, mapowanie wizualne | GUI, proste | Trial: 30 dni, 100 stron (desktop) lub 10 stron (online) na skan |
BrightData: chmurowy crawler klasy enterprise

BrightData to „ciężka artyleria” w świecie crawlowania. To platforma chmurowa z ogromną siecią proxy, renderowaniem JavaScript, rozwiązywaniem CAPTCHA i IDE do budowania własnych crawlów. Jeśli zbierasz dane na dużą skalę — np. monitorujesz ceny na setkach sklepów — infrastruktura BrightData jest trudna do przebicia ().
Mocne strony:
- Radzi sobie z trudnymi stronami i zabezpieczeniami anti-bot
- Skaluje się pod potrzeby enterprise
- Gotowe szablony dla popularnych serwisów
Ograniczenia:
- Brak stałego darmowego planu (jest tylko trial: 3 scrapery po 100 rekordów)
- Do prostych audytów bywa to przerost formy nad treścią
- Dla nietechnicznych użytkowników — wyraźna krzywa uczenia
Jeśli potrzebujesz crawlowania w skali, BrightData jest jak wynajęcie bolidu F1. Tylko nie zakładaj, że po jeździe próbnej dalej będzie za darmo ().
Crawlbase: darmowy crawler przez API dla developerów

Crawlbase (dawniej ProxyCrawl) stawia na crawling „pod kod”. Wywołujesz API z adresem URL, a w odpowiedzi dostajesz HTML — a proxy, geotargetowanie i CAPTCHA dzieją się w tle ().
Mocne strony:
- Wysoka skuteczność (99%+)
- Obsługa stron mocno opartych o JavaScript
- Super do integracji z własnymi aplikacjami i workflow
Ograniczenia:
- Wymaga integracji API lub SDK
- Free: ok. 5 000 wywołań API przez 7 dni, potem 1 000/mies.
Jeśli jesteś developerem i chcesz crawlowania (a często też web scraping) bez zabawy w zarządzanie proxy, Crawlbase to bardzo sensowny wybór ().
ScraperAPI: prostsze crawlowanie stron dynamicznych

ScraperAPI to API w stylu „po prostu mi to pobierz”. Podajesz URL, a narzędzie ogarnia proxy, przeglądarkę headless i zabezpieczenia anti-bot, po czym zwraca HTML (a dla części serwisów także dane ustrukturyzowane). Szczególnie dobrze wypada na stronach dynamicznych i ma całkiem hojny darmowy pakiet ().
Mocne strony:
- Bardzo proste dla developerów (jedno wywołanie API)
- Obsługa CAPTCHA, banów IP i JavaScript
- Free: 5 000 wywołań API przez 7 dni, potem 1 000/mies.
Ograniczenia:
- Brak wizualnych raportów z crawla
- Jeśli chcesz podążać za linkami, logikę crawlowania musisz napisać sam
Jeśli chcesz wpiąć crawling do kodu w kilka minut, ScraperAPI to oczywisty wybór.
Diffbot Crawlbot: automatyczne odkrywanie struktury i ekstrakcja danych

Diffbot Crawlbot robi się „inteligentny”. To nie tylko crawling — narzędzie używa AI do klasyfikowania stron i wyciągania danych ustrukturyzowanych (artykuły, produkty, wydarzenia itd.) do JSON. Taki stażysta-robot, który serio rozumie, co czyta ().
Mocne strony:
- Ekstrakcja oparta o AI, a nie tylko przechodzenie po linkach
- Obsługa JavaScript i treści dynamicznych
- Free: 10 000 kredytów/mies. (ok. 10 tys. stron)
Ograniczenia:
- Narzędzie bardziej dla developerów (integracja API)
- To nie jest wizualne narzędzie SEO — raczej pod projekty danych
Jeśli potrzebujesz ustrukturyzowanych danych w skali (zwłaszcza pod AI/analitykę), Diffbot ma naprawdę duże możliwości.
Screaming Frog: darmowy desktopowy crawler SEO

Screaming Frog to klasyk w audytach SEO. W darmowej wersji skanuje do 500 URL na jedno uruchomienie i pokazuje wszystko: niedziałające linki, meta tagi, duplikaty treści, sitemap i wiele więcej ().
Mocne strony:
- Szybki, dokładny i bardzo ceniony w branży SEO
- Bez kodowania — wpisujesz URL i jedziesz
- Free do 500 URL na crawl
Ograniczenia:
- Tylko desktop (brak wersji chmurowej)
- Zaawansowane funkcje (renderowanie JS, harmonogramy) wymagają płatnej licencji
Jeśli traktujesz SEO serio, Screaming Frog to obowiązkowa pozycja — ale nie licz, że za darmo przeskanuje serwis na 10 000 podstron.
SiteOne Crawler: eksport statyczny i dokumentacja

SiteOne Crawler to taki techniczny scyzoryk. Jest open-source, działa na wielu platformach i potrafi nie tylko crawling i audyt, ale też eksport do Markdown — mega przydatny do dokumentacji albo pracy offline ().
Mocne strony:
- SEO, wydajność, dostępność i bezpieczeństwo w jednym
- Eksport do archiwizacji lub migracji
- Free i open-source, bez limitów użycia
Ograniczenia:
- Bardziej techniczne niż część narzędzi GUI
- Raport w GUI domyślnie ograniczony do 1 000 URL (da się zmienić)
Jeśli jesteś developerem, QA albo konsultantem i lubisz open source — SiteOne to niedoceniana perełka.
Crawljax: open-source crawler Java do stron dynamicznych
Crawljax to narzędzie wyspecjalizowane: zostało stworzone do crawlowania nowoczesnych aplikacji webowych opartych o JavaScript, symulując interakcje użytkownika (kliki, wypełnianie formularzy itd.). Działa zdarzeniowo i potrafi nawet wygenerować statyczną wersję dynamicznej strony ().
Mocne strony:
- Bezkonkurencyjne przy SPA i stronach AJAX-heavy
- Open-source i łatwe do rozszerzania
- Brak limitów użycia
Ograniczenia:
- Wymaga Javy i trochę programowania/konfiguracji
- Nie dla osób nietechnicznych
Jeśli musisz crawlowąć aplikację React lub Angular „jak użytkownik”, Crawljax jest świetnym wyborem.
Apache Nutch: skalowalny, rozproszony crawler

Apache Nutch to nestor open-source’owych crawlerów. Został zaprojektowany pod ogromne, rozproszone crawl’e — np. budowę własnej wyszukiwarki lub indeksowanie milionów stron ().
Mocne strony:
- Skaluje się do miliardów stron z Hadoop
- Bardzo konfigurowalny i rozszerzalny
- Free i open-source
Ograniczenia:
- Stroma krzywa uczenia (Java, terminal, konfiguracje)
- Nie dla małych stron ani okazjonalnych użytkowników
Jeśli chcesz crawlowania w skali i nie boisz się terminala, Nutch jest dla Ciebie.
YaCy: crawler P2P i wyszukiwarka
YaCy to nietypowe, zdecentralizowane połączenie crawlera i wyszukiwarki. Każda instancja crawluje i indeksuje strony, a do tego możesz dołączyć do sieci peer-to-peer i współdzielić indeksy z innymi ().
Mocne strony:
- Prywatność: brak centralnego serwera
- Dobre do prywatnego wyszukiwania lub intranetu
- Free i open-source
Ograniczenia:
- Jakość wyników zależy od pokrycia sieci
- Wymaga konfiguracji (Java, UI w przeglądarce)
Jeśli kręci Cię decentralizacja albo chcesz własną wyszukiwarkę, YaCy jest bardzo ciekawą opcją.
PowerMapper: wizualny generator sitemap dla UX i QA

PowerMapper skupia się na wizualizacji struktury serwisu. Crawluje stronę i tworzy interaktywne mapy, a przy okazji sprawdza dostępność, kompatybilność przeglądarek i podstawy SEO ().
Mocne strony:
- Wizualne sitemap są świetne dla agencji i projektantów
- Kontrola dostępności i zgodności
- Proste GUI, bez wymagań technicznych
Ograniczenia:
- Tylko trial (30 dni, 100 stron desktop / 10 stron online na skan)
- Pełna wersja jest płatna
Jeśli musisz pokazać mapę strony klientowi albo sprawdzić zgodność, PowerMapper jest bardzo praktyczny.
Jak wybrać odpowiedni darmowy crawler do swoich potrzeb
Przy tylu opcjach łatwo się zakręcić. Oto szybka ściąga:
- Do audytów SEO: Screaming Frog (mniejsze serwisy), PowerMapper (wizualnie), SiteOne (głębokie audyty)
- Do aplikacji dynamicznych: Crawljax
- Do dużej skali lub własnej wyszukiwarki: Apache Nutch, YaCy
- Dla developerów potrzebujących API: Crawlbase, ScraperAPI, Diffbot
- Do dokumentacji lub archiwizacji: SiteOne Crawler
- Enterprise w wersji „na próbę”: BrightData, Diffbot
Na co zwrócić uwagę:
- Skalowalność: jak duża jest strona lub zadanie?
- Łatwość obsługi: kod czy klikane GUI?
- Eksport danych: CSV, JSON, integracje?
- Wsparcie: społeczność i dokumentacja, gdy utkniesz.
Gdy crawling spotyka scraping: dlaczego Thunderbit bywa lepszym wyborem
Prawda jest taka: większość osób nie robi crawling stron po to, żeby mieć ładną mapkę. Najczęściej chodzi o dane w uporządkowanej formie — listy produktów, kontakty, inwentaryzację treści. I tu wchodzi .
Thunderbit to nie tylko crawler ani tylko scraper — to rozszerzenie Chrome oparte o AI, które łączy oba podejścia. Jak to działa:
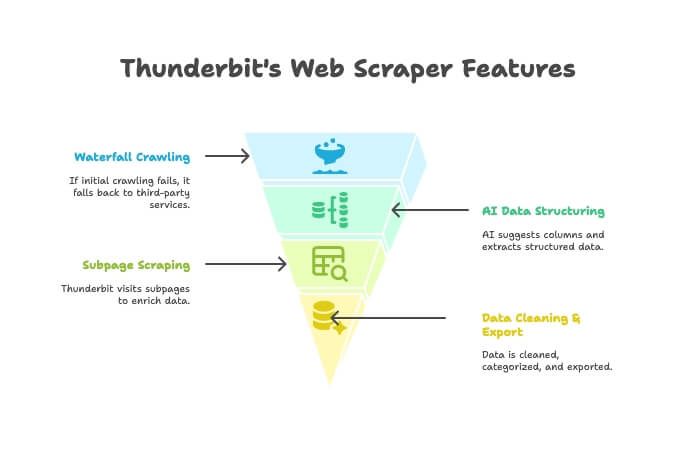
- AI Crawler: Thunderbit eksploruje witrynę jak klasyczny crawler.
- Waterfall Crawling: jeśli silnik Thunderbit nie może pobrać strony (np. przez mocne zabezpieczenia anti-bot), narzędzie automatycznie przełącza się na zewnętrzne usługi crawlingowe — bez ręcznej konfiguracji.
- AI do strukturyzacji danych: po pobraniu HTML AI podpowiada kolumny i wyciąga dane (nazwy, ceny, e-maile itd.) bez pisania selektorów.
- Scraping podstron: potrzebujesz szczegółów z każdej karty produktu? Thunderbit automatycznie odwiedzi podstrony i uzupełni tabelę.
- Czyszczenie i eksport: streszczanie, kategoryzacja, tłumaczenie oraz eksport do Excel, Google Sheets, Airtable lub Notion — jednym kliknięciem.
- No-code: jeśli umiesz korzystać z przeglądarki, poradzisz sobie z Thunderbit. Bez kodu, bez proxy, bez frustracji.
Kiedy Thunderbit ma przewagę nad klasycznym crawlerem?
- Gdy celem jest czysty, użyteczny arkusz — a nie tylko lista URL.
- Gdy chcesz zautomatyzować cały proces (crawl → ekstrakcja → porządkowanie → eksport) w jednym miejscu.
- Gdy cenisz czas i spokój.
Możesz i sprawdzić, dlaczego tylu użytkowników biznesowych przechodzi na to rozwiązanie.
Podsumowanie: jak wycisnąć maksimum z darmowych crawlerów
Crawlery stron przeszły długą drogę. Niezależnie od tego, czy jesteś marketerem, developerem, czy po prostu chcesz utrzymać stronę w dobrej kondycji — znajdziesz narzędzie darmowe (albo przynajmniej „darmowe na start”). Od platform enterprise jak BrightData i Diffbot, przez open-source’owe perełki typu SiteOne i Crawljax, po wizualne mapowanie w PowerMapper — wybór jest dziś większy niż kiedykolwiek.
Jeśli jednak szukasz sprytniejszej, bardziej zintegrowanej drogi od „potrzebuję tych danych” do „mam gotowy arkusz”, przetestuj Thunderbit. To rozwiązanie dla osób biznesowych, które chcą efektów, a nie tylko raportów.
Chcesz zacząć? Pobierz narzędzie, uruchom skan i zobacz, co do tej pory Ci umykało. A jeśli chcesz przejść od crawlowania do danych gotowych do działania w dwa kliknięcia, .
Więcej praktycznych porad i szczegółowych przewodników znajdziesz na .
FAQ
Jaka jest różnica między crawlerem strony a web scraperem?
Crawler odkrywa i mapuje wszystkie podstrony w serwisie (jak spis treści). Scraper wyciąga konkretne pola danych (np. ceny, e-maile czy opinie) z tych stron. Crawler znajduje, scraper wydobywa ().
Który darmowy crawler jest najlepszy dla osób nietechnicznych?
Do mniejszych stron i audytów SEO Screaming Frog jest dość przyjazny. Do wizualnego mapowania PowerMapper sprawdza się świetnie (w okresie próbnym). Thunderbit jest najprostszy, jeśli Twoim celem są dane ustrukturyzowane i chcesz podejście no-code w przeglądarce.
Czy są strony, które blokują crawlery?
Tak — część serwisów używa robots.txt lub zabezpieczeń anti-bot (CAPTCHA, bany IP), żeby blokować crawling. Narzędzia takie jak ScraperAPI, Crawlbase czy Thunderbit (z waterfall crawling) często potrafią sobie z tym poradzić, ale zawsze działaj odpowiedzialnie i respektuj zasady strony ().
Czy darmowe crawlery mają limity stron lub funkcji?
Zwykle tak. Przykładowo darmowy Screaming Frog ma limit 500 URL na crawl, a trial PowerMapper — 100 stron. Narzędzia API często mają miesięczne limity kredytów. Rozwiązania open-source jak SiteOne czy Crawljax zazwyczaj nie mają twardych limitów, ale ogranicza Cię sprzęt.
Czy używanie crawlera jest legalne i zgodne z prywatnością?
Zazwyczaj crawlowanie publicznych stron jest legalne, ale zawsze sprawdzaj regulamin serwisu i robots.txt. Nie crawluj danych prywatnych ani chronionych hasłem bez zgody i pamiętaj o przepisach dotyczących prywatności, jeśli pozyskujesz dane osobowe ().