

Dane z sieci to dziś podstawowy surowiec dla sprzedaży, marketingu i operacji. Jeśli nadal kopiujesz je ręcznie, zostajesz w tyle.
Jest jednak jeden problem z „darmowymi” narzędziami do scrapingu: większość z nich tak naprawdę nie jest darmowa. To tylko wersje próbne z ostrymi limitami albo narzędzia, które zamykają najważniejsze funkcje za paywallem.
Przetestowałem 12 narzędzi, żeby sprawdzić, które z nich pozwalają realnie pracować na darmowym planie. Sprawdzałem oferty Google Maps, dynamiczne strony wymagające logowania i pliki PDF. Niektóre dowiozły. Inne tylko zmarnowały mi popołudnie.
Oto uczciwe podsumowanie — zaczynając od tych, które naprawdę poleciłbym dalej.
Dlaczego darmowe scrapers są dziś ważniejsze niż kiedykolwiek
Bądźmy szczerzy: w 2026 roku web scraping nie jest już domeną hakerów czy data scientistów. To standardowe narzędzie nowoczesnych firm, a liczby mówią same za siebie. Rynek oprogramowania do web scrapingu osiągnął 1,01 mld USD w 2024 roku i ma szansę ponad dwukrotnie urosnąć do 2032 roku. Dlaczego? Bo wszyscy — od działów sprzedaży po pośredników nieruchomości — wykorzystują dane z internetu, żeby zyskać przewagę.
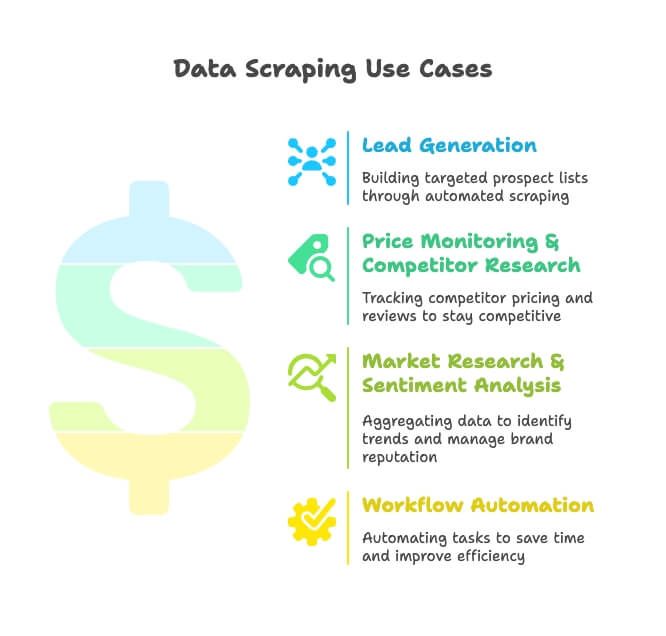
- Generowanie leadów: zespoły sprzedażowe pobierają dane z katalogów, Google Maps i mediów społecznościowych, aby budować precyzyjne listy potencjalnych klientów — bez ręcznego szukania.
- Monitorowanie cen i analiza konkurencji: zespoły e-commerce i retail śledzą SKU, ceny i opinie konkurencji, żeby nie tracić tempa (i tak, 82% firm e-commerce robi to właśnie z tego powodu).
- Badania rynku i analiza sentymentu: marketerzy agregują recenzje, newsy i wzmianki w social media, by wyłapywać trendy i dbać o reputację marki.
- Automatyzacja workflow: zespoły operacyjne automatyzują wszystko — od sprawdzania stanów magazynowych po cykliczne raportowanie — oszczędzając godziny każdego tygodnia.
A teraz ciekawostka: firmy korzystające z AI-powered web scraperów oszczędzają 30–40% czasu w porównaniu z metodami ręcznymi. To nie jest „trochę szybciej” — to różnica między wyjściem z pracy o 18:00 a 21:00.
Jak wybraliśmy najlepsze darmowe narzędzia do pozyskiwania danych
Widziałem mnóstwo list „najlepszych web scraperów”, które po prostu powielają materiały marketingowe. Tutaj tak nie będzie. Przy tworzeniu zestawienia brałem pod uwagę:
- Rzeczywistą użyteczność darmowego planu: czy darmowa wersja pozwala normalnie pracować, czy jest tylko przynętą?
- Łatwość obsługi: czy osoba bez umiejętności programowania osiągnie efekt w kilka minut, czy potrzebny jest doktorat z RegExów?
- Obsługiwane typy stron: statyczne, dynamiczne, paginowane, wymagające logowania, PDF-y, social media — czy narzędzie radzi sobie z realnymi scenariuszami?
- Opcje eksportu danych: czy da się wygodnie wysłać dane do Excela, Google Sheets, Notion lub Airtable?
- Dodatkowe funkcje: ekstrakcja wspierana przez AI, harmonogramy, szablony, post-processing, integracje.
- Dopasowanie do typu użytkownika: czy narzędzie jest dla biznesu, analityków czy programistów?
Przejrzałem też dokumentację każdego narzędzia, sprawdziłem onboarding i porównałem limity darmowych planów — bo „darmowe” nie zawsze znaczy naprawdę darmowe.
W skrócie: porównanie 12 darmowych narzędzi do pozyskiwania danych
Poniżej znajdziesz szybkie zestawienie, które pomoże Ci od razu zawęzić wybór do właściwego narzędzia.
| Narzędzie | Platforma | Ograniczenia darmowego planu | Najlepsze dla | Formaty eksportu | Unikalne funkcje |
|---|---|---|---|---|---|
| Thunderbit | Rozszerzenie Chrome | 6 stron/miesiąc | Osoby bez kodu, biznes | Excel, CSV | Prompty AI, scrapowanie PDF/obrazów, crawling podstron |
| Browse AI | Chmura | 50 kredytów/miesiąc | Użytkownicy no-code | CSV, Sheets | Roboty point-and-click, harmonogramy |
| Octoparse | Desktop | 10 zadań, 50 tys. wierszy/miesiąc | No-code, użytkownicy półtechniczni | CSV, Excel, JSON | Wizualny workflow, obsługa dynamicznych stron |
| ParseHub | Desktop | 5 projektów, 200 stron/uruchomienie | No-code, użytkownicy półtechniczni | CSV, Excel, JSON | Wizualny interfejs, obsługa dynamicznych stron |
| Webscraper.io | Rozszerzenie Chrome | Nielimitowane lokalnie | No-code, proste zadania | CSV, XLSX | Oparte na sitemapach, szablony społeczności |
| Apify | Chmura | 5 USD kredytów/miesiąc | Zespoły, półtechniczni, dev | CSV, JSON, Sheets | Marketplace actorów, harmonogramy, API |
| Scrapy | Biblioteka Python | Nielimitowane (open source) | Programiści | CSV, JSON, DB | Pełna kontrola w kodzie, skalowalność |
| Puppeteer | Biblioteka Node.js | Nielimitowane (open source) | Programiści | Własny (kod) | Headless browser, obsługa dynamicznego JS |
| Selenium | Wiele języków | Nielimitowane (open source) | Programiści | Własny (kod) | Automatyzacja przeglądarki, wsparcie wielu przeglądarek |
| Zyte | Chmura | 1 spider, 1 godz./zadanie, retencja 7 dni | Dev, zespoły operacyjne | CSV, JSON | Hosted Scrapy, zarządzanie proxy |
| SerpAPI | API | 100 wyszukiwań/miesiąc | Dev, analitycy | JSON | API wyszukiwarek, antyblokowanie |
| Diffbot | API | 10 000 kredytów/miesiąc | Dev, projekty AI | JSON | Ekstrakcja AI, knowledge graph |
Thunderbit: najlepszy wybór do przyjaznego, AI-powered scrapingu danych
Pozyskuj dane z dowolnej strony dzięki AI Get Started Free
Porozmawiajmy o tym, dlaczego Thunderbit jest na szczycie mojej listy. Nie mówię tego tylko dlatego, że jestem częścią zespołu — naprawdę uważam, że Thunderbit jest najbliższy posiadaniu AI stażysty, który naprawdę słucha (i nie prosi co chwilę o kawę).
Thunderbit nie działa jak typowe narzędzie w stylu „najpierw naucz się, potem scrapuj”. To bardziej jak wydanie polecenia inteligentnemu asystentowi: opisujesz, czego chcesz („Pobierz wszystkie nazwy produktów, ceny i linki z tej strony”), a AI w Thunderbit robi resztę. Bez XPath, bez selektorów CSS, bez bólu z Regexem. A jeśli chcesz pobrać podstrony — na przykład karty produktów albo linki kontaktowe firm — Thunderbit potrafi automatycznie przechodzić dalej i wzbogacać tabelę, znowu po prostu po kliknięciu przycisku.
Ale prawdziwa przewaga Thunderbit ujawnia się dopiero po scrapingu. Chcesz podsumować, przetłumaczyć, sklasyfikować albo oczyścić dane? Wbudowany AI post-processing załatwia to za Ciebie. Nie dostajesz tylko surowych danych — dostajesz uporządkowane, użyteczne informacje gotowe do CRM, arkusza kalkulacyjnego albo kolejnego dużego projektu.
Darmowy plan: bezpłatny trial Thunderbit pozwala pobrać do 6 stron (albo 10 z trial boostem), w tym PDF-y, obrazy, a nawet szablony do social mediów. Dane możesz eksportować bezpłatnie do Excela lub CSV i przetestować funkcje takie jak ekstrakcja e-maili, telefonów i obrazów. Przy większych zadaniach płatne plany odblokowują więcej stron, bezpośredni eksport do Google Sheets/Notion/Airtable, harmonogram scrapingu oraz gotowe szablony dla popularnych serwisów, takich jak Amazon, Google Maps czy Instagram.
Jeśli chcesz zobaczyć Thunderbit w akcji, sprawdź rozszerzenie Thunderbit do Chrome albo zajrzyj na nasz kanał YouTube, gdzie znajdziesz szybkie materiały startowe.
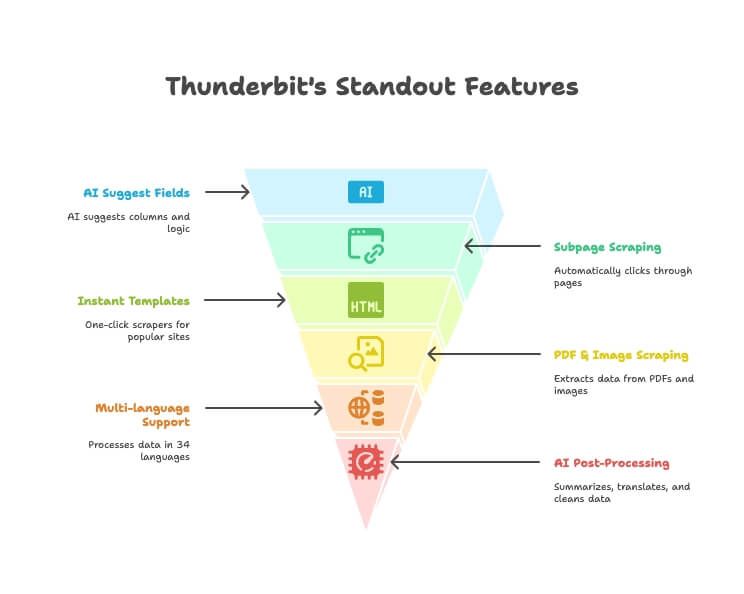
Najmocniejsze funkcje Thunderbit
- AI Suggest Fields: opisz po prostu dane, których potrzebujesz, a AI Thunderbit podpowie właściwe kolumny i logikę ekstrakcji.
- Scraping podstron: automatycznie przechodź przez strony szczegółów lub linki i wzbogacaj główną tabelę — bez ręcznej konfiguracji.
- Natychmiastowe szablony: scraping jednym kliknięciem dla Amazon, Google Maps, Instagram i wielu innych.
- Scraping PDF i obrazów: wyciągaj tabele i dane z PDF-ów oraz obrazów przy użyciu AI — bez dodatkowych narzędzi.
- Wsparcie wielu języków: pobieraj i przetwarzaj dane w 34 językach.
- Bezpośredni eksport: wysyłaj dane prosto do Excel, Google Sheets, Notion lub Airtable (plany płatne).
- AI Post-Processing: podsumowuj, tłumacz, kategoryzuj i czyść dane już w trakcie scrapingu.
- Darmowa ekstrakcja e-maili/telefonów/obrazów: wyciągaj dane kontaktowe lub obrazy z dowolnej strony jednym kliknięciem.
Thunderbit łączy „samo pobieranie danych” z „danymi, które naprawdę da się wykorzystać”. To najbliższe prawdziwemu asystentowi AI do danych, jakie widziałem dla użytkowników biznesowych.
Reszta top 12: recenzja darmowych narzędzi do pozyskiwania danych
Rozbijmy teraz pozostałe narzędzia, grupując je według tego, dla kogo są najlepsze.
Dla użytkowników no-code i biznesowych
Thunderbit
Omówione już wyżej. Najłatwiejszy start dla osób bez kodu, z funkcjami AI i gotowymi szablonami.
Webscraper.io
- Platforma: Rozszerzenie Chrome
- Najlepsze dla: Proste, statyczne strony; osoby bez kodu, którym nie przeszkadza trochę prób i błędów.
- Najważniejsze funkcje: Scrapowanie oparte na sitemapach, obsługa paginacji, eksport CSV/XLSX.
- Darmowy plan: Nielimitowane użycie lokalne, ale bez uruchomień w chmurze i bez harmonogramów. Tylko ręczna obsługa.
- Ograniczenia: Brak wbudowanej obsługi logowania, PDF-ów i złożonych dynamicznych treści. Tylko wsparcie społeczności.
ParseHub
- Platforma: Aplikacja desktopowa (Windows, Mac, Linux)
- Najlepsze dla: Osoby bez kodu i użytkownicy półtechniczni, którzy chcą poświęcić czas na naukę.
- Najważniejsze funkcje: Wizualny kreator workflow, obsługa dynamicznych stron, AJAX, logowania i paginacji.
- Darmowy plan: 5 publicznych projektów, 200 stron na uruchomienie, tylko ręczne uruchamianie.
- Ograniczenia: Projekty są publiczne na darmowym planie (uważaj na dane wrażliwe), brak harmonogramów, wolniejsze tempo ekstrakcji.
Octoparse
- Platforma: Aplikacja desktopowa (Windows/Mac), chmura (płatna)
- Najlepsze dla: Osoby bez kodu i analitycy, którzy chcą mocy i elastyczności.
- Najważniejsze funkcje: Wizualne klikanie, obsługa dynamicznych treści, szablony dla popularnych serwisów.
- Darmowy plan: 10 zadań, do 50 000 wierszy/miesiąc, tylko desktop (bez chmury i harmonogramów).
- Ograniczenia: Brak API, rotacji IP i harmonogramów w darmowej wersji. Przy złożonych stronach próg wejścia może być wysoki.
Browse AI
- Platforma: Chmura
- Najlepsze dla: Użytkownicy no-code, którzy chcą automatyzować proste scrapowanie i monitoring.
- Najważniejsze funkcje: Robot recorder point-and-click, harmonogramy, integracje (Sheets, Zapier).
- Darmowy plan: 50 kredytów/miesiąc, 1 strona internetowa, do 5 robotów.
- Ograniczenia: Ograniczona skala, przy bardziej złożonych stronach potrzebna jest chwila nauki.
Dla programistów i użytkowników technicznych
Scrapy
- Platforma: Biblioteka Python (open source)
- Najlepsze dla: Programiści, którzy chcą pełnej kontroli i skalowalności.
- Najważniejsze funkcje: Bardzo duża możliwość dostosowania, obsługa dużych crawlów, middleware, pipelines.
- Darmowy plan: Nielimitowany (open source).
- Ograniczenia: Brak GUI, wymaga kodowania w Pythonie. Nie dla osób bez kodu.
Puppeteer
- Platforma: Biblioteka Node.js (open source)
- Najlepsze dla: Programiści scrapujący dynamiczne strony z dużą ilością JavaScriptu.
- Najważniejsze funkcje: Automatyzacja headless browser, pełna kontrola nad nawigacją i ekstrakcją.
- Darmowy plan: Nielimitowany (open source).
- Ograniczenia: Wymaga kodowania w JavaScript, brak GUI.
Selenium
- Platforma: Wiele języków (Python, Java itd.), open source
- Najlepsze dla: Programiści automatyzujący przeglądarki do scrapingu lub testów.
- Najważniejsze funkcje: Wsparcie wielu przeglądarek, automatyzacja kliknięć, przewijania i logowań.
- Darmowy plan: Nielimitowany (open source).
- Ograniczenia: Wolniejsze niż biblioteki headless, wymaga skryptów.
Zyte (Scrapy Cloud)
- Platforma: Chmura
- Najlepsze dla: Programiści i zespoły operacyjne wdrażające spidery Scrapy na dużą skalę.
- Najważniejsze funkcje: Hosted Scrapy, zarządzanie proxy, harmonogram zadań.
- Darmowy plan: 1 równoległy spider, 1 godzina/zadanie, retencja danych przez 7 dni.
- Ograniczenia: Brak zaawansowanych harmonogramów w darmowej wersji, wymagana znajomość Scrapy.
Dla zespołów i zastosowań enterprise
Apify
- Platforma: Chmura
- Najlepsze dla: Zespoły, użytkownicy półtechniczni i programiści, którzy chcą gotowych lub własnych scraperów.
- Najważniejsze funkcje: Marketplace actorów (gotowe boty), harmonogramy, API, integracje.
- Darmowy plan: 5 USD kredytów/miesiąc (w sam raz do małych zadań), retencja danych 7 dni.
- Ograniczenia: Pewna krzywa uczenia się, wykorzystanie ograniczone kredytami.
SerpAPI
- Platforma: API
- Najlepsze dla: Programiści i analitycy potrzebujący danych z wyszukiwarek (Google, Bing, YouTube).
- Najważniejsze funkcje: API wyszukiwania, antyblokowanie, uporządkowany JSON.
- Darmowy plan: 100 wyszukiwań/miesiąc.
- Ograniczenia: Nie służy do dowolnych stron internetowych, tylko do użycia przez API.
Diffbot
- Platforma: API
- Najlepsze dla: Programiści, zespoły AI/ML i firmy potrzebujące uporządkowanych danych z sieci na dużą skalę.
- Najważniejsze funkcje: Ekstrakcja wspierana przez AI, knowledge graph, API do artykułów i produktów.
- Darmowy plan: 10 000 kredytów/miesiąc.
- Ograniczenia: Tylko API, wymaga umiejętności technicznych, ograniczona przepustowość.
Ograniczenia darmowych planów: co „darmowe” naprawdę oznacza dla każdego narzędzia
Bądźmy szczerzy — „darmowe” może znaczyć wszystko, od „nielimitowane dla hobbystów” po „wystarczająco, żeby Cię zachęcić”. Oto, co naprawdę dostajesz:
Wniosek: do realnych projektów Thunderbit, Browse AI i Apify oferują najbardziej użyteczne darmowe wersje próbne dla użytkowników biznesowych. Przy stałym albo dużym scrapingu szybko dojdziesz do limitów i będziesz musiał przejść na płatny plan albo rozwiązanie open-source oparte na kodzie.
Które narzędzie do pozyskiwania danych jest najlepsze dla Ciebie? (Przewodnik według typu użytkownika)
Oto ściąga, która pomoże Ci wybrać odpowiednie narzędzie w zależności od roli i obycia z technologią:
| Typ użytkownika | Najlepsze narzędzia (darmowe) | Dlaczego |
|---|---|---|
| Osoba bez kodu (sprzedaż/marketing) | Thunderbit, Browse AI, Webscraper.io | Najłatwiejsze do nauki, point-and-click, wsparcie AI |
| Użytkownik półtechniczny (ops/analityk) | Octoparse, ParseHub, Apify, Zyte | Większa moc, radzą sobie ze złożonymi stronami, możliwe skrypty |
| Programista/inżynier | Scrapy, Puppeteer, Selenium, Diffbot, SerpAPI | Pełna kontrola, nielimitowane, podejście API-first |
| Zespół/enterprise | Apify, Zyte | Współpraca, harmonogramy, integracje |
Realne scenariusze web scrapingu: porównanie adaptowalności narzędzi
Sprawdźmy, jak te narzędzia wypadają w pięciu typowych scenariuszach scrapingu:
| Scenariusz | Thunderbit | Browse AI | Octoparse | ParseHub | Webscraper.io | Apify | Scrapy | Puppeteer | Selenium | Zyte | SerpAPI | Diffbot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lista z paginacją | Łatwo | Łatwo | Średnio | Średnio | Średnio | Łatwo | Łatwo | Łatwo | Łatwo | Łatwo | N/A | Średnio |
| Oferty Google Maps | Łatwo* | Trudno | Średnio | Średnio | Trudno | Łatwo | Trudno | Trudno | Trudno | Trudno | Łatwo | N/A |
| Strony wymagające logowania | Łatwo | Średnio | Średnio | Średnio | Ręcznie | Średnio | Łatwo | Łatwo | Łatwo | Łatwo | N/A | N/A |
| Ekstrakcja danych z PDF | Łatwo | Nie | Nie | Nie | Nie | Średnio | Trudno | Trudno | Trudno | Trudno | Nie | Ograniczona |
| Treści z social media | Łatwo* | Częściowo | Trudno | Trudno | Trudno | Łatwo | Trudno | Trudno | Trudno | Trudno | YouTube | Ograniczona |
- Thunderbit i Apify oferują gotowe szablony/actorów do Google Maps i scrapingu social mediów, dzięki czemu te scenariusze są dużo prostsze dla użytkowników nietechnicznych.
Wtyczka vs desktop vs chmura: jakie jest najlepsze doświadczenie z web scraperem?
- Rozszerzenia Chrome (Thunderbit, Webscraper.io):
- Plusy: szybki start, działa w przeglądarce, minimalna konfiguracja.
- Minusy: obsługa ręczna, podatność na zmiany strony, ograniczona automatyzacja.
- Przewaga Thunderbit: AI radzi sobie ze zmianami struktury, nawigacją po podstronach, a nawet scrapowaniem PDF-ów i obrazów — dzięki czemu jest dużo bardziej odporny niż tradycyjne rozszerzenia.
- Aplikacje desktopowe (Octoparse, ParseHub):
- Plusy: duża moc, wizualne workflow, obsługa dynamicznych stron i logowania.
- Minusy: większa krzywa uczenia się, brak automatyzacji w chmurze na darmowych planach, zależność od systemu operacyjnego.
- Platformy chmurowe (Browse AI, Apify, Zyte):
- Plusy: harmonogramy, współpraca zespołowa, skalowalność, integracje.
- Minusy: darmowe plany są zwykle ograniczone kredytami, czasem wymagają konfiguracji, mogą wymagać znajomości API.
- Biblioteki open-source (Scrapy, Puppeteer, Selenium):
- Plusy: nielimitowane, mocno konfigurowalne, idealne dla devów.
- Minusy: wymagają kodowania, nie są dla użytkowników biznesowych.
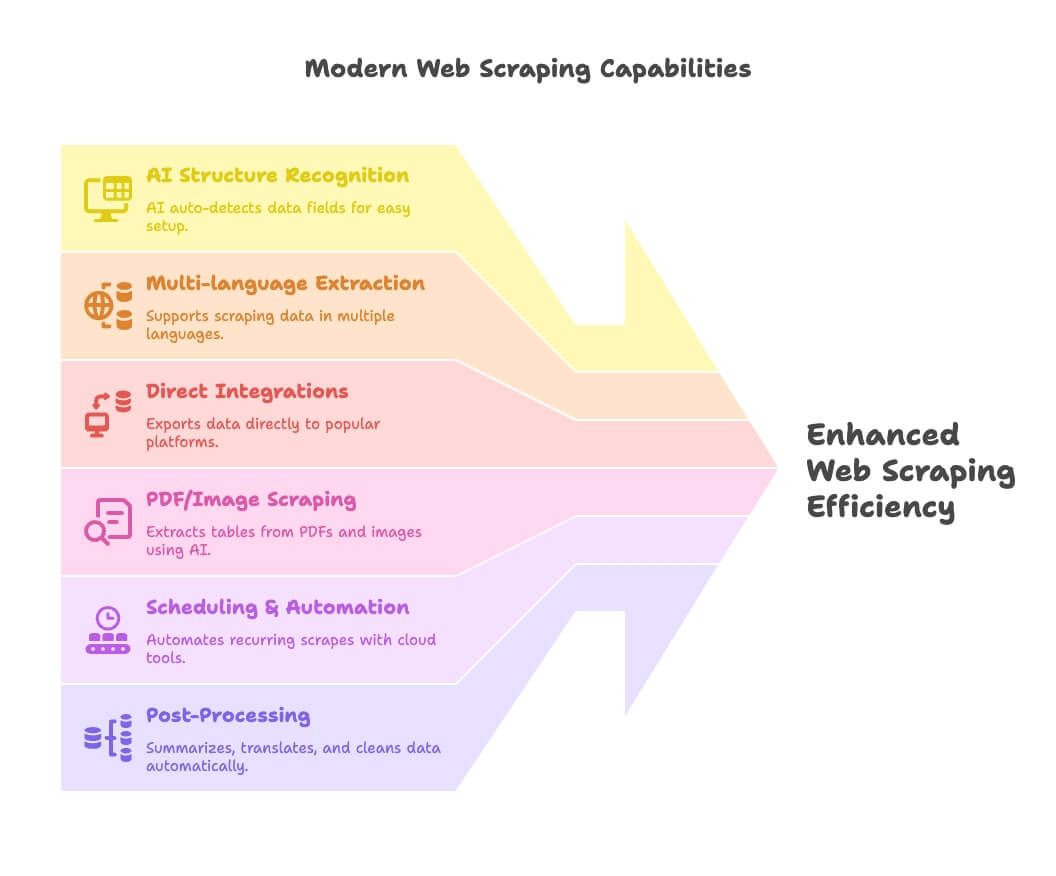
Trendy web scrapingu w 2026: co wyróżnia nowoczesne narzędzia
Web scraping w 2026 roku kręci się wokół AI, automatyzacji i integracji. Oto, co nowego:
- Rozpoznawanie struktury przez AI: narzędzia takie jak Thunderbit używają AI do automatycznego wykrywania pól danych, dzięki czemu konfiguracja jest banalnie prosta dla osób bez kodu.
- Ekstrakcja wielojęzyczna: Thunderbit i inne narzędzia obsługują pobieranie i przetwarzanie danych w dziesiątkach języków.
- Bezpośrednie integracje: eksportuj dane prosto do Google Sheets, Notion lub Airtable — koniec z przepychaniem CSV-ów.
- Scraping PDF/obrazów: Thunderbit wyznacza tu kierunek, umożliwiając ekstrakcję tabel z PDF-ów i obrazów przy pomocy AI.
- Harmonogramy i automatyzacja: narzędzia chmurowe (Apify, Browse AI) pozwalają ustawić zadanie raz i zapomnieć o nim.
- Post-processing: podsumowuj, tłumacz, kategoryzuj i czyść dane już w trakcie scrapingu — bez bałaganu w arkuszach.
Thunderbit, Apify i SerpAPI są na czele tych zmian, ale Thunderbit wyróżnia się tym, że sprawia, iż scraping wspierany przez AI jest dostępny dla każdego, nie tylko dla programistów.
Poza scrapingiem: przetwarzanie danych i funkcje dodające wartość
Nie chodzi tylko o pobranie danych — chodzi o to, żeby były użyteczne. Oto, jak czołowe narzędzia wypadają w post-processingu:
| Narzędzie | Czyszczenie | Tłumaczenie | Kategoryzacja | Podsumowanie | Uwagi |
|---|---|---|---|---|---|
| Thunderbit | Tak | Tak | Tak | Tak | Wbudowany AI post-processing |
| Apify | Częściowo | Częściowo | Częściowo | Częściowo | Zależy od użytego actora |
| Browse AI | Nie | Nie | Nie | Nie | Tylko surowe dane |
| Octoparse | Częściowo | Nie | Częściowo | Nie | Częściowe przetwarzanie pól |
| ParseHub | Częściowo | Nie | Częściowo | Nie | Częściowe przetwarzanie pól |
| Webscraper.io | Nie | Nie | Nie | Nie | Tylko surowe dane |
| Scrapy | Tak* | Tak* | Tak* | Tak* | Jeśli zaimplementuje to programista |
| Puppeteer | Tak* | Tak* | Tak* | Tak* | Jeśli zaimplementuje to programista |
| Selenium | Tak* | Tak* | Tak* | Tak* | Jeśli zaimplementuje to programista |
| Zyte | Częściowo | Nie | Częściowo | Nie | Niektóre funkcje automatycznej ekstrakcji |
| SerpAPI | Nie | Nie | Nie | Nie | Tylko uporządkowane dane z wyszukiwarek |
| Diffbot | Tak | Tak | Tak | Tak | AI-powered, ale tylko przez API |
- Programista musi zaimplementować logikę przetwarzania.
Thunderbit to jedyne narzędzie, które pozwala osobom nietechnicznym przejść od surowych danych z sieci do konkretnych, uporządkowanych wniosków — wszystko w jednym workflow.
Społeczność, wsparcie i materiały edukacyjne: jak szybko wejść na poziom
Dokumentacja i onboarding mają ogromne znaczenie. Oto porównanie:
| Narzędzie | Dokumentacja i tutoriale | Społeczność | Szablony | Krzywa uczenia się |
|---|---|---|---|---|
| Thunderbit | Doskonała | Rośnie | Tak | Bardzo niska |
| Browse AI | Dobra | Dobra | Tak | Niska |
| Octoparse | Doskonała | Duża | Tak | Średnia |
| ParseHub | Doskonała | Duża | Tak | Średnia |
| Webscraper.io | Dobra | Forum | Tak | Średnia |
| Apify | Doskonała | Duża | Tak | Średnio-wysoka |
| Scrapy | Doskonała | Ogromna | N/A | Wysoka |
| Puppeteer | Dobra | Duża | N/A | Wysoka |
| Selenium | Dobra | Ogromna | N/A | Wysoka |
| Zyte | Dobra | Duża | Tak | Średnio-wysoka |
| SerpAPI | Dobra | Średnia | N/A | Wysoka |
| Diffbot | Dobra | Średnia | N/A | Wysoka |
Thunderbit i Browse AI są najłatwiejsze dla początkujących. Octoparse i ParseHub mają świetne materiały, ale wymagają więcej cierpliwości. Apify i narzędzia dla developerów mają wyższą krzywą uczenia, ale są dobrze udokumentowane.
Podsumowanie: jak wybrać odpowiedni darmowy data scraper w 2026 roku
Zobacz najlepsze narzędzia do web scrapingu w 2026 Get Started Free
Oto sedno: nie każde „darmowe” narzędzie do pozyskiwania danych jest równie użyteczne, a wybór powinien zależeć od Twojej roli, komfortu technologicznego i realnych potrzeb scrapingu.
- Jeśli jesteś użytkownikiem biznesowym lub nie kodujesz, a chcesz szybko zdobywać dane — zwłaszcza z trudnych stron, PDF-ów czy obrazów — Thunderbit to najlepszy punkt startowy. Podejście oparte na AI, prompty w naturalnym języku i funkcje post-processingu sprawiają, że to najbliższe prawdziwemu asystentowi danych AI. Wypróbuj za darmo rozszerzenie Thunderbit do Chrome i zobacz, jak szybko przejdziesz od „potrzebuję tych danych” do „oto mój arkusz”.
- Jeśli jesteś programistą albo potrzebujesz nielimitowanego, w pełni konfigurowalnego scrapingu, najlepszym wyborem będą open-source’owe narzędzia takie jak Scrapy, Puppeteer i Selenium.
- Dla zespołów i użytkowników półtechnicznych Apify i Zyte oferują skalowalne, współdzielone rozwiązania z hojnymi darmowymi planami do małych zadań.
Niezależnie od workflow zacznij od narzędzia, które pasuje do Twoich umiejętności i potrzeb. I pamiętaj: w 2026 roku nie musisz być programistą, żeby korzystać z mocy danych z sieci — potrzebujesz tylko właściwego asystenta (i może odrobiny humoru, gdy roboty wyprzedzają Cię w tempie).
Chcesz wejść głębiej? Sprawdź więcej poradników i porównań na Thunderbit Blog, w tym:
- Czym jest data scraping i jak robić to w 2026 roku
- Jak scrapować dane ze stron internetowych do Excela przy użyciu AI
- Najlepsze narzędzia i oprogramowanie do web scrapingu w 2026
Rozpocznij scrapowanie z Thunderbit
Wypróbuj AI Web Scraper Get Started Free




