

Oprogramowanie do ekstrakcji danych w 2026 roku nie jest już jedną kategorią dla jednego typu kupującego. Niektóre zespoły potrzebują narzędzia działającego w przeglądarce, które w kilka minut zamienia witryny w arkusze kalkulacyjne. Inne potrzebują API do crawl’owania, infrastruktury proxy albo kontrolowanego potoku danych zasilającego hurtownię danych. Wrzucenie wszystkich tych zadań do jednego rankingu bez kontekstu to prosty sposób, by kupujący tracili czas i przepłacali.
Ta odświeżona coroczna lista ma jeden cel: pomóc Ci szybko zbudować shortlistę. 15 narzędzi poniżej nadal obejmuje większość realnych ścieżek zakupowych na rynku, ale każde rozwiązuje zupełnie inny problem. Jeśli potrzebujesz szybkiej ekstrakcji danych ze stron przy minimalnej konfiguracji, Twoja shortlistа powinna wyglądać zupełnie inaczej niż w przypadku zespołu kupującego ELT i narzędzia do zarządzania danymi.
Uwaga redakcyjna: Ta coroczna lista została zaktualizowana 7 maja 2026 r. Kolejny właściciel przeglądu: zespół redakcyjny Thunderbit.
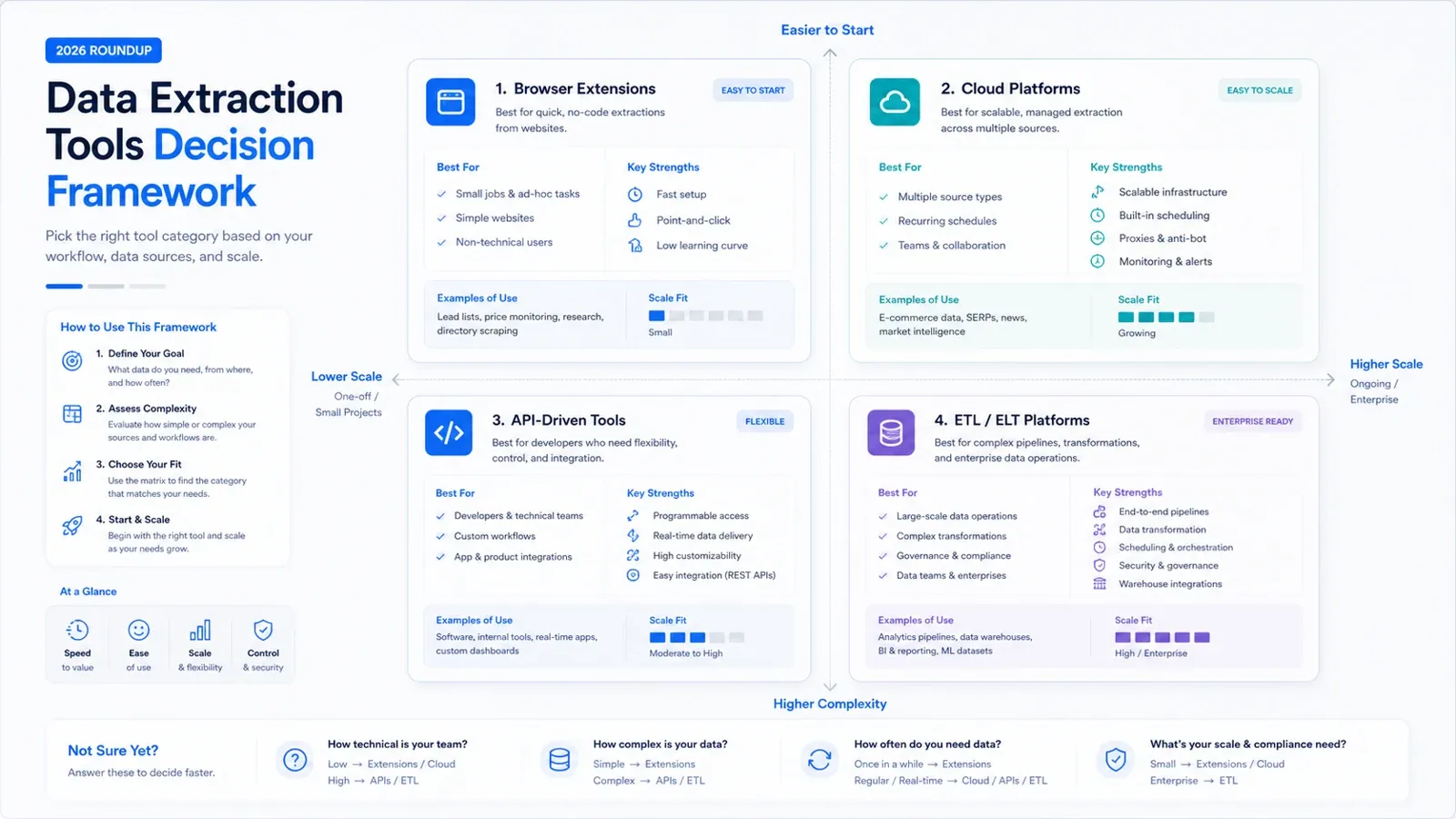
Zacznij od właściwego typu narzędzia
Zanim porównasz dostawców, zdecyduj, jakie zadanie naprawdę chcesz wykonać:
- Potrzebujesz szybko wprowadzić dane ze strony do arkusza, bez utrzymywania infrastruktury do scrapingu: zacznij od narzędzi AI albo no-code działających w przeglądarce, takich jak Thunderbit, Octoparse, Data Miner lub Browse AI.
- Potrzebujesz renderowanych stron, dostarczania przez API albo infrastruktury anty-bot dla zespołów produktowych: sprawdź ScrapingBee, Diffbot, Bright Data lub Captain Data.
- Chcesz scentralizować dane z aplikacji SaaS, API i baz danych w hurtowni danych: skup się na Airbyte, Hevo, Fivetran, Talend, Matillion lub Integrate.io.
Sprawdź, czy Thunderbit pasuje do Twojego procesu pracy
Szybkie porównanie: najlepsze narzędzia do ekstrakcji danych w 2026 roku
| Narzędzie | Najlepsze do | Co wyróżnia | Model cenowy |
|---|---|---|---|
| Thunderbit | Użytkownicy biznesowi, którzy chcą szybko pobierać dane ze stron | Sugestie pól AI, podstrony, paginacja, eksport do arkuszy | Darmowy plan; płatna subskrypcja + kredyty |
| Diffbot | Zespoły budujące uporządkowane produkty danych z sieci | API ekstrakcji, Crawlbot, Knowledge Graph | Darmowy okres próbny; płatne kredyty API; oferta enterprise na zamówienie |
| Captain Data | Zespoły growth i ops automatyzujące procesy outbound | No-code, wieloetapowe workflow między witrynami i narzędziami SaaS | Rozliczenie za użycie / sprzedażowe |
| ScrapingBee | Programiści scrapujący strony z dużą ilością JS | Renderowanie headless, rotacja proxy, proste API | Darmowy okres próbny; płatne plany API |
| Octoparse | Analitycy, którzy chcą wizualnego scrapingu i uruchomień w chmurze | Kreator zadań typu point-and-click, szablony, zaplanowane zadania w chmurze | Darmowy plan; płatne pakiety |
| Data Miner | Użytkownicy przeglądarki wyciągający listy i tabele na żądanie | Ekstrakcja oparta na recepturach z szybkimi eksportami | Darmowy plan; płatne pakiety |
| Browse AI | Zespoły skupione na monitoringu i alertach o zmianach | Wytrenowane roboty, harmonogramy monitoringu, dostarczanie do Sheets/Zapier | Darmowy plan; płatne pakiety |
| Bardeen | Użytkownicy łączący scraping z automatyzacją workflow w przeglądarce | Playbooki AI, automatyzacje przeglądarki, integracje aplikacji | Darmowy plan; płatne pakiety |
| Bright Data | Zbieranie danych na poziomie enterprise i dużej skali | Sieć proxy, narzędzie do omijania blokad, zbiory danych, platforma do scrapingu | Rozliczenie za użycie / umowa |
| Airbyte | Zespoły inżynieryjne budujące potoki danych do hurtowni | Otwarte konektory, opcja self-managed, nacisk na hurtownię danych | Darmowy self-managed; plany cloud + enterprise |
| Talend / Qlik Talend Cloud | Duże firmy potrzebujące integracji z rozbudowanym governance | Integracja, jakość, governance, kontrola enterprise | Subskrypcja wyceniana indywidualnie |
| Matillion | Zespoły danych w chmurze pracujące w nowoczesnych hurtowniach | Cloud-native ELT i transformacje wewnątrz hurtowni | Rozliczenie zależne od zużycia |
| Integrate.io | Zespoły ze średniego rynku chcące zarządzanych potoków | Zarządzane integracje między SaaS i bazami danych | Subskrypcja sprzedażowa |
| Hevo Data | Zespoły chcące zarządzanej synchronizacji niemal w czasie rzeczywistym | Zarządzane konektory, nacisk na real-time, niska konfiguracja | Darmowy plan; płatne pakiety |
| Fivetran | Zespoły stawiające niezawodność ponad personalizację | Zarządzane konektory, obsługa schematów, prostota operacyjna | Darmowy plan; cenowy model MAR oparty na użyciu |
Co zmieniło się w 2026 roku
Trzy zmiany są dziś ważniejsze niż ogólne hasła o „automatyzacji”:
- Ekstrakcja oparta na AI stała się standardem. Kupujący coraz częściej oczekują, że narzędzie samo wywnioskuje pola, poradzi sobie z podstawowymi wariantami strony i wyeksportuje czyste tabele bez ręcznego ustawiania selektorów.
- Infrastruktura oddzieliła się od narzędzi workflow. Niektóre produkty najlepiej kupować jako API albo warstwę proxy, a inne jako kompletne procesy dla użytkowników biznesowych.
- Roczni nabywcy dużo uważniej patrzą na koszt utrzymania. Narzędzie tańsze na papierze może być gorsze, jeśli Twój zespół co tydzień musi pilnować selektorów, synchronizacji z hurtownią albo obejść anty-bot.
Dlatego ta strona dzieli shortlistę według modelu działania, zamiast udawać, że wszystkie narzędzia konkurują ze sobą bezpośrednio.
Najlepsze narzędzia AI i no-code do ekstrakcji danych
1. Thunderbit
Thunderbit nadal najlepiej sprawdza się w zespołach nietechnicznych, które chcą szybko otrzymać dane ze strony w uporządkowanej tabeli. Jego główna przewaga nie polega tylko na tym, że jest no-code; produkt został zbudowany tak, aby maksymalnie ograniczyć tarcie przy konfiguracji. Otwierasz stronę, prosisz AI o sugestię pól, w razie potrzeby dopasowujesz tabelę i eksportujesz.
- Najlepsze dla: sales ops, ecommerce ops, rekrutacji, badań i wszystkich, którzy przechodzą od strony w przeglądarce do arkusza kalkulacyjnego.
- Co wyróżnia: sugestie pól AI, scrapowanie podstron, obsługa paginacji, eksport do Sheets / Excel / Airtable / Notion.
- Cennik: dostępny darmowy plan; płatne pakiety skalują się przez subskrypcję i wykorzystanie kredytów.
Wypróbuj AI Web Scraper od Thunderbit za darmo
2. Octoparse
Octoparse nadal jest jednym z najbardziej ugruntowanych produktów no-code do scrapingu dla zespołów, które chcą bardziej przejrzystego, wizualnego kreatora zadań. Wymaga więcej konfiguracji niż Thunderbit, ale w zamian daje większą kontrolę osobom, które chcą zamodelować workflow.
- Najlepsze dla: analityków, badaczy i zespołów ops scrapujących cykliczne zbiory danych na średnią skalę.
- Co wyróżnia: wizualne projektowanie zadań, harmonogramy w chmurze, szablony zadań, obsługa logowania i stron dynamicznych.
- Cennik: darmowy plan oraz płatne pakiety za pojemność chmurową i funkcje zespołowe.
3. Data Miner
Data Miner nadal dobrze sprawdza się do taktycznej ekstrakcji z poziomu przeglądarki. Jest szczególnie przydatny, gdy użytkownik chce szybko pobrać listę, katalog albo tabelę i czuje się komfortowo, korzystając z receptur lub je modyfikując.
- Najlepsze dla: natywnej w przeglądarce ekstrakcji tabel, katalogów i powtarzalnych elementów stron.
- Co wyróżnia: duża biblioteka receptur, szybki workflow w przeglądarce, znany model eksportu do CSV / arkuszy.
- Cennik: darmowy plan z płatnymi ulepszeniami dla intensywniejszego użycia.
4. Browse AI
Browse AI jest najmocniejsze tam, gdzie zadanie nie ogranicza się do ekstrakcji, ale obejmuje też monitoring. Jeśli kupujący chce robota, który wraca na stronę, obserwuje zmiany i przekazuje wyniki dalej, Browse AI pozostaje bardzo sensownym wyborem.
- Najlepsze dla: cyklicznego monitoringu, alertów o zmianach i prostych zaplanowanych ekstrakcji.
- Co wyróżnia: wytrenowane roboty, cykliczne uruchomienia, workflow w stylu alertów, dostarczanie do Sheets i narzędzi automatyzacji.
- Cennik: darmowy plan oraz płatne pakiety zależne od pojemności uruchomień.
5. Bardeen
Bardeen leży na granicy między ekstrakcją a automatyzacją workflow w przeglądarce. To mniej czysty scraper, a bardziej warstwa produktywności w przeglądarce, która może zbierać dane i przekazywać je dalej do reszty procesu.
- Najlepsze dla: zespołów automatyzujących powtarzalne zadania w przeglądarce związane ze scrapingiem, wzbogacaniem danych i przekazaniem dalej.
- Co wyróżnia: playbooki AI, automatyzacje przeglądarki, rozbudowane integracje aplikacji.
- Cennik: darmowy plan oraz płatne pakiety.
Najlepsze narzędzia API, workflow i infrastrukturalne do ekstrakcji danych
6. Diffbot
Diffbot nadal jest jednym z najczytelniejszych wyborów, gdy kupujący chce ekstrakcji jako produktu API, a nie workflow w przeglądarce. Został stworzony do strukturalnego rozumienia sieci na dużą skalę i pozostaje bardziej nastawiony na developerów oraz produkty danych niż narzędzia no-code opisane wyżej.
- Najlepsze dla: zespołów budujących produkty danych, systemy wzbogacania lub duże potoki uporządkowanych danych z sieci.
- Co wyróżnia: API ekstrakcji, Crawlbot, Knowledge Graph, produkty danych zorientowane na encje.
- Cennik: darmowy okres próbny i płatne pakiety kredytów API, z opcjami enterprise.
7. Captain Data

Captain Data pozostaje ważne, ponieważ traktuje ekstrakcję jako jeden etap szerszego workflow go-to-market. Jest najbardziej użyteczne wtedy, gdy prawdziwe zadanie nie brzmi „zeskrob stronę”, ale „pobierz leady, wzbogac je, skieruj dalej i zaktualizuj systemy downstream”.
- Najlepsze dla: zespołów growth, outbound i revenue operations.
- Co wyróżnia: wieloetapowe workflow, działania wzbogacające, przekazywanie do CRM, automatyzacja procesów outbound.
- Cennik: rozliczenie za użycie i model sprzedażowy.
8. ScrapingBee
ScrapingBee nadal jest praktycznym wyborem API dla programistów, którzy potrzebują obsługi stron renderowanych i abstrakcji infrastruktury bez budowania całego stosu do scrapingu od zera.
- Najlepsze dla: zespołów produktowych i developerów wbudowujących scraping w aplikacje lub narzędzia wewnętrzne.
- Co wyróżnia: renderowanie JavaScript, obsługa proxy, prosty model żądań, API projektowane z myślą o developerach.
- Cennik: płatne plany API z dostępem próbnym.
9. Bright Data
Bright Data nadal jest opcją na skalę enterprise, gdy wyzwaniem nie jest pojedynczy workflow, lecz wolumen zbierania, geografia, infrastruktura do omijania blokad i wymagania operacyjne związane z compliance.
- Najlepsze dla: web collection na poziomie enterprise, obciążeń mocno zależnych od proxy i zaawansowanych programów pozyskiwania danych.
- Co wyróżnia: sieć proxy, narzędzia do omijania blokad, produkty danych i infrastruktura do zbierania na skalę enterprise.
- Cennik: rozliczenie zależne od użycia i umów handlowych.
Najlepsze platformy ELT i pipeline danych z funkcjami ekstrakcji
10. Airbyte
Airbyte jest właściwym kandydatem do shortlisty, gdy zadanie wykracza poza ekstrakcję ze stron internetowych, a zespół potrzebuje konektorów, przesyłania danych do hurtowni i kontroli nad architekturą pipeline. To nie jest zamiennik web scrapera, ale jedno z lepszych rozwiązań do centralizowania danych z SaaS, API i baz danych.
- Najlepsze dla: zespołów prowadzonych przez inżynierię, które chcą otwartych konektorów i kontroli z myślą o hurtowni danych.
- Co wyróżnia: otwarty ekosystem, opcja self-managed, oferta cloud, elastyczność konektorów.
- Cennik: darmowa ścieżka self-managed oraz poziomy cloud i enterprise.
11. Talend / Qlik Talend Cloud

Talend nadal pozostaje opcją integracyjną dla organizacji, które bardziej niż na lekkiej konfiguracji zależą na kontrolowanym przepływie, jakości, lineage i kontroli.
- Najlepsze dla: firm z wymaganiami dotyczącymi governance, jakości i integracji między systemami.
- Co wyróżnia: enterprise governance, narzędzia jakości, szeroki zakres integracji, zarządzany kierunek cloud pod Qlik.
- Cennik: subskrypcja wyceniana indywidualnie.
12. Matillion
Matillion nadal dobrze pasuje do zespołów danych w chmurze, które chcą ELT ściśle powiązanego z nowoczesnymi hurtowniami i transformacjami wykonywanymi wewnątrz hurtowni.
- Najlepsze dla: zespołów pracujących na Snowflake, Databricks, BigQuery i nowoczesnych hurtowniach danych.
- Co wyróżnia: cloud-native ELT, transformacje skoncentrowane na hurtowni, procesy zespołowe dla analytics engineering.
- Cennik: rozliczenie zależne od zużycia.
13. Integrate.io
Integrate.io pozostaje istotne dla zespołów, które chcą zarządzanej warstwy integracyjnej bez samodzielnego budowania i utrzymywania rozbudowanego, ciężkiego inżynieryjnie stosu pipeline.
- Najlepsze dla: zespołów ze średniego segmentu rynku, które wolą zarządzane integracje między aplikacjami SaaS i bazami danych.
- Co wyróżnia: zarządzane wdrożenie, łączność między systemami biznesowymi, mało uciążliwy model operacyjny.
- Cennik: subskrypcja sprzedażowa.
14. Hevo Data
Hevo Data nadal przyciąga zespoły, które chcą niskokonfiguracyjnego, zarządzanego pipeline z synchronizacją niemal w czasie rzeczywistym i stosunkowo niewielkim obciążeniem operacyjnym.
- Najlepsze dla: zespołów analitycznych, które chcą szybko przenosić dane z systemów operacyjnych do hurtowni.
- Co wyróżnia: zarządzane konektory, synchronizacja near-real-time, prosta konfiguracja.
- Cennik: darmowy plan i płatne pakiety.
15. Fivetran
Fivetran nadal jest jedną z najbezpieczniejszych pozycji na shortlistę, gdy kupujący bardziej niż oszczędność albo możliwość personalizacji ceni niezawodność, utrzymanie konektorów i prostotę operacyjną.
- Najlepsze dla: zespołów danych, które chcą zarządzanego standardu konektorów i są gotowe za to zapłacić.
- Co wyróżnia: zarządzane konektory, obsługa schematów, wysoka dojrzałość operacyjna, model niskiego utrzymania.
- Cennik: darmowy plan plus cenowy model MAR oparty na użyciu.
Jak wybrać bez przepłacania
Najszybszy sposób, by wybrać dobrze, to nie rozwiązywać niewłaściwego problemu.

- Jeśli głównie potrzebujesz danych ze strony w arkuszu kalkulacyjnym, nie zaczynaj od platformy ELT.
- Jeśli potrzebujesz kontrolowanego pipeline do hurtowni, nie zmuszaj scrapera przeglądarkowego, by udawał platformę danych.
- Jeśli najtrudniejszą częścią workflow jest renderowanie JavaScript, blokady lub dostarczanie przez API, porównuj najpierw narzędzia infrastrukturalne.
- Jeśli najtrudniejsze są wdrożenie przez zespół i szybkość konfiguracji, porównuj najpierw narzędzia AI i no-code.
Przydatna zasada zakupowa w 2026 roku brzmi: wybieraj rozwiązanie o tak niskiej złożoności, jak pozwala na to Twój rzeczywisty workflow. Koszt utrzymania rośnie szybciej niż oszczędności na liście cenowej.
Ostateczna shortlistа według typu zespołu
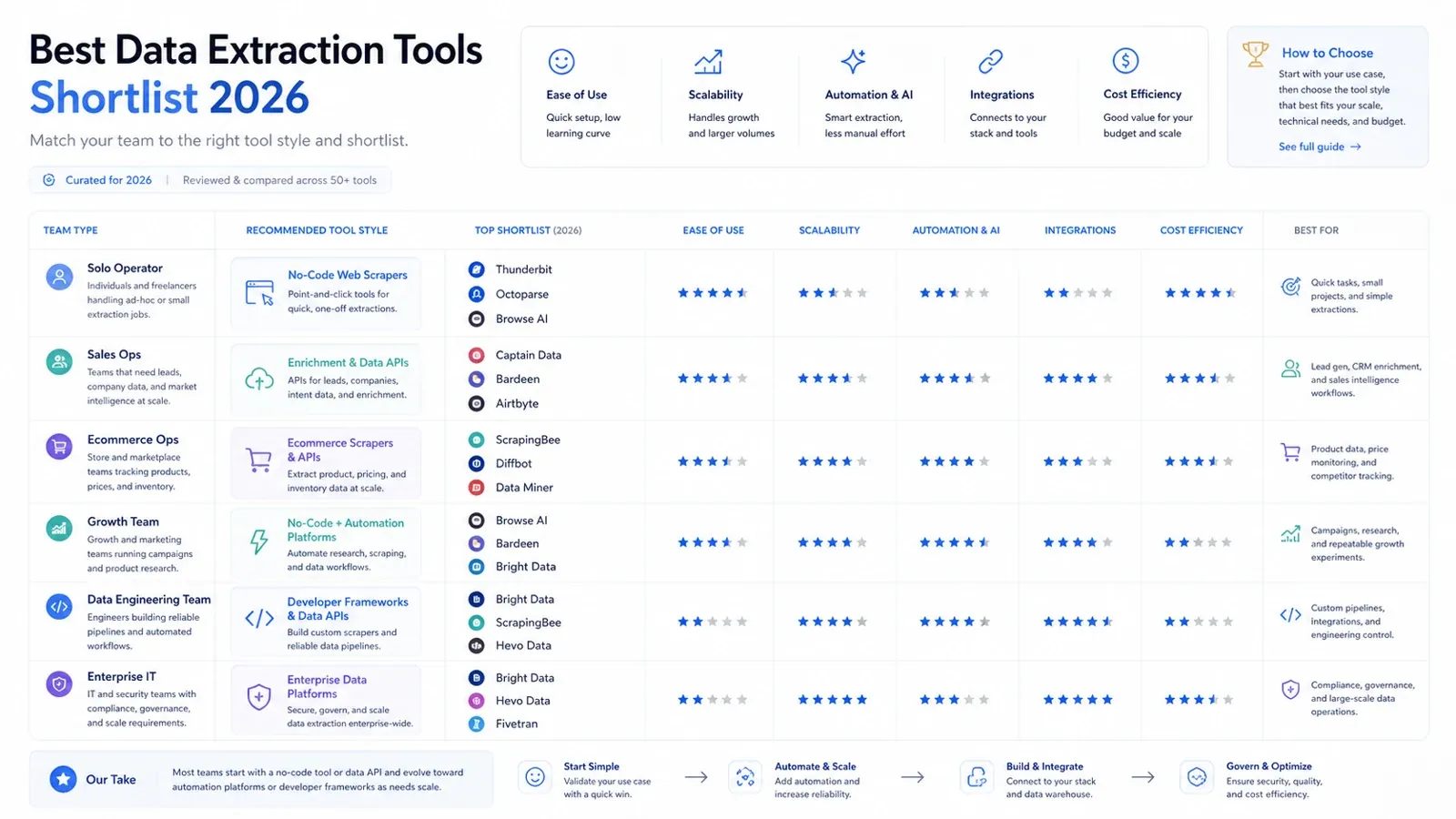
Oto praktyczna wersja shortlisty:
- Samodzielny operator lub użytkownik biznesowy: Thunderbit, Data Miner, Browse AI.
- Zespół sales ops lub workflow growth: Thunderbit, Captain Data, Bardeen.
- Zespół ecommerce ops: Thunderbit, Octoparse, Bright Data.
- Zespół data engineering: Airbyte, Fivetran, Matillion, Hevo.
- Zakup IT w enterprise / integracja z governance: Talend, Fivetran, Integrate.io, Bright Data.
- Developer budujący produkty danych: Diffbot, ScrapingBee, Bright Data.
Gdybym miał sprowadzić ten cały rynek do najkrótszej sensownej listy startowej dla większości kupujących w 2026 roku, wyglądałaby ona tak:
- Thunderbit do szybkiej, wspieranej przez AI ekstrakcji danych ze stron przez zespoły nietechniczne.
- ScrapingBee dla developerów, którzy potrzebują infrastruktury API dla stron renderowanych.
- Bright Data do zbierania danych na skalę enterprise i infrastruktury do omijania blokad.
- Airbyte do pipeline danych do hurtowni prowadzonych przez inżynierię z elastycznością.
- Fivetran do niezawodnych, zarządzanych konektorów.
Zacznij za darmo z Thunderbit Get Started Free
Najczęstsze pytania
P1: Czy narzędzia do ekstrakcji danych i narzędzia ETL to to samo?
Nie. Narzędzie do ekstrakcji danych może skupiać się na stronach internetowych, PDF-ach lub wyodrębnianiu danych ze strukturalnych elementów strony, podczas gdy platforma ETL lub ELT koncentruje się na przenoszeniu i transformowaniu danych między systemami do hurtowni. Niektórzy kupujący potrzebują obu, ale nie należy ich oceniać tak, jakby rozwiązywały ten sam pierwszy problem.
P2: Jaki jest najlepszy wybór dla nietechnicznego zespołu w 2026 roku?
Do szybkiej ekstrakcji danych ze stron przy minimalnej konfiguracji najlepszym punktem startowym nadal są narzędzia AI i no-code. Thunderbit, Octoparse, Browse AI i Data Miner to najbardziej sensowna pierwsza shortlistа, w zależności od tego, czy Twój zespół bardziej ceni kontrolę, czy szybkość.
P3: Które narzędzia są najlepsze dla zastosowań deweloperskich lub enterprise?
Dla developerów dobrymi punktami startowymi są ScrapingBee i Diffbot, zależnie od tego, czy potrzebujesz infrastruktury do renderowania, czy API do uporządkowanych danych z sieci. Do zbierania danych na skalę enterprise lub infrastruktury z dużymi wymaganiami compliance Bright Data nadal jest ważnym kandydatem do shortlisty. Do kontrolowanych wewnętrznych pipeline lepiej pasują Airbyte, Fivetran, Talend, Matillion, Hevo i Integrate.io.




