
Internet nie jest już tylko cyfrowym placem zabaw — to największy magazyn danych na świecie, a wszyscy, od zespołów sprzedaży po analityków rynku, ścigają się, by go wykorzystać. Ale bądźmy szczerzy: ręczne zbieranie danych z internetu jest mniej więcej tak samo przyjemne jak składanie mebli IKEA bez instrukcji (i z dwa razy większą liczbą śrubek, które zostają na końcu). Ponieważ firmy coraz bardziej polegają na analizie rynku w czasie rzeczywistym, monitorowaniu cen konkurencji i generowaniu leadów, zapotrzebowanie na wydajne i niezawodne narzędzia do crawlingu danych nigdy nie było większe. W rzeczywistości niemal przy podejmowaniu decyzji, a globalny rynek web scrapingu jest na dobrej drodze, by .
Jeśli masz dość kopiowania i wklejania, tracenia świeżych leadów albo po prostu chcesz zobaczyć, co da się zrobić, gdy automatyzacja przejmuje ciężką pracę, jesteś we właściwym miejscu. Przez lata budowałem i testowałem narzędzia do pozyskiwania danych z internetu (i tak, kierowałem zespołem w ), więc wiem z pierwszej ręki, jak dobre narzędzie może zamienić godziny żmudnej pracy w dwuklikową formalność. Niezależnie od tego, czy jesteś osobą nietechniczną i chcesz natychmiastowych efektów, czy deweloperem, który potrzebuje pełnej kontroli, ta lista 10 najlepszych narzędzi do crawlingu danych pomoże Ci znaleźć idealne rozwiązanie.
Dlaczego wybór właściwego narzędzia do crawlingu danych ma znaczenie
Mówiąc wprost: różnica między dobrym narzędziem do crawlingu danych a przeciętnym to nie tylko wygoda — to bezpośredni impuls dla rozwoju firmy. Gdy automatyzujesz pozyskiwanie danych z internetu, nie tylko oszczędzasz czas (choć jeden z recenzentów G2 napisał, że ), ale też ograniczasz liczbę błędów, otwierasz nowe możliwości i dbasz o to, by Twój zespół pracował zawsze na najświeższych i najbardziej precyzyjnych danych. Ręczne badanie rynku jest powolne, podatne na błędy i często nieaktualne, zanim zdążysz je skończyć. Z właściwym narzędziem możesz monitorować konkurencję, śledzić ceny albo budować listy leadów w kilka minut — nie dni.
Przykład? Jedna sieć sklepów kosmetycznych wykorzystała web scraping do monitorowania stanów magazynowych i cen konkurencji, . Tego rodzaju efektów nie da się uzyskać samymi arkuszami kalkulacyjnymi i pracą „na łokciach”.
Jak ocenialiśmy najlepsze narzędzia do crawlingu danych
Przy tylu opcjach wybór odpowiedniego narzędzia do crawlingu danych może przypominać szybkie randki na konferencji technologicznej. Oto kryteria, których użyłem, by oddzielić najlepsze rozwiązania od reszty:
- Łatwość obsługi: Czy można zacząć bez doktoratu z Pythona? Czy jest interfejs wizualny albo wsparcie AI dla osób nietechnicznych?
- Możliwości automatyzacji: Czy obsługuje paginację, podstrony, dynamiczne treści i harmonogramy? Czy może działać w chmurze przy większych zadaniach?
- Cena i skalowalność: Czy dostępny jest darmowy plan lub niedrogi pakiet startowy? Jak rosną koszty wraz z Twoimi potrzebami?
- Funkcje i integracje: Czy można eksportować do Excela, Google Sheets albo przez API? Czy są szablony, harmonogramy lub wbudowane funkcje czyszczenia danych?
- Dla kogo najlepiej: Dla użytkowników biznesowych, deweloperów czy zespołów enterprise?
Na końcu dodałem też krótką tabelę porównawczą, żeby łatwiej było zobaczyć, jak wypada każde narzędzie.
Przejdźmy więc do 10 najlepszych narzędzi do crawlingu danych do wydajnego pozyskiwania danych z internetu w 2025 roku.
1. Thunderbit
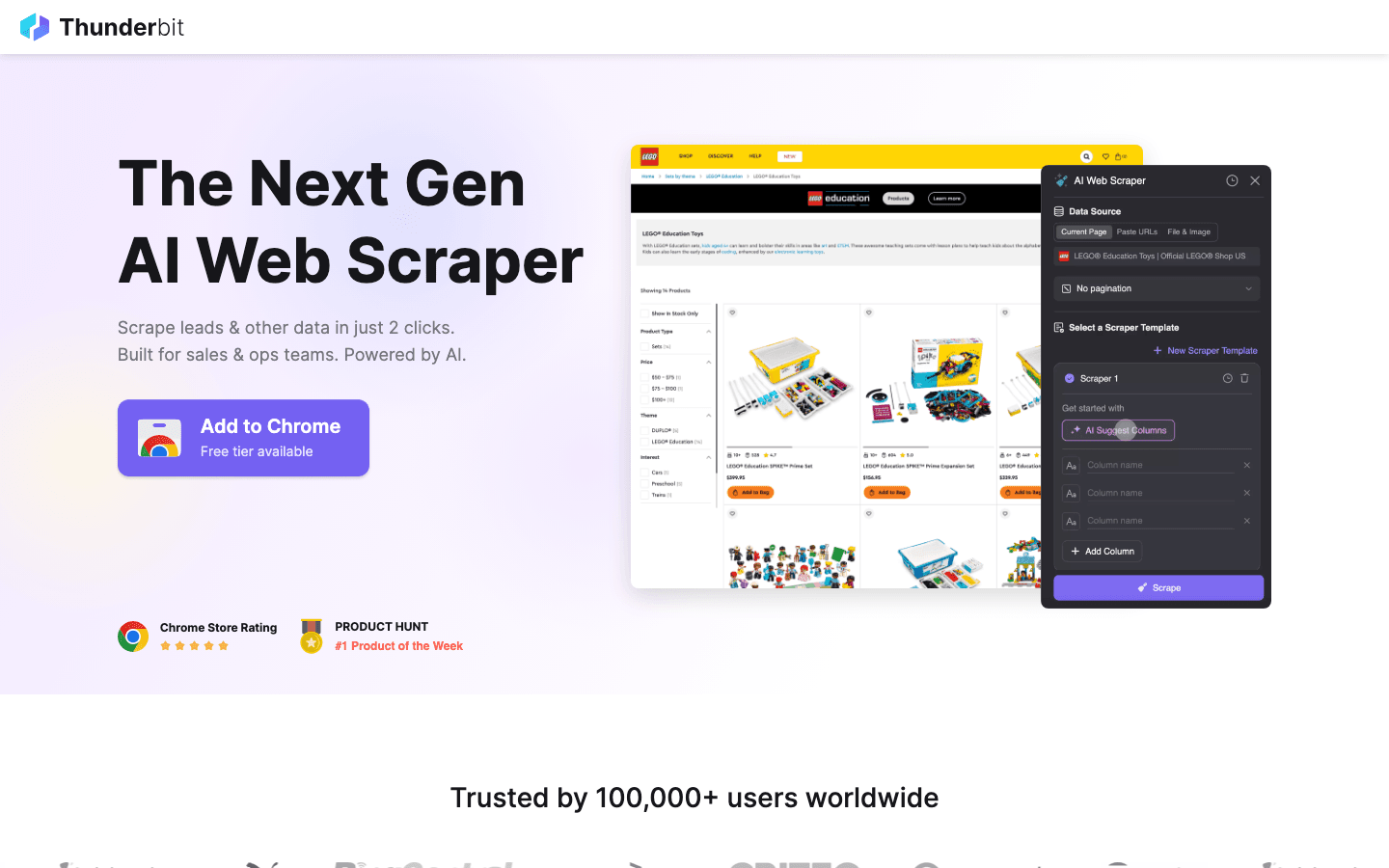 to moja pierwsza rekomendacja dla każdego, kto chce, by crawling danych był tak prosty jak zamówienie jedzenia na wynos. Thunderbit, zbudowany jako rozszerzenie do Chrome oparte na AI, stawia na scraping w 2 kliknięciach: wystarczy nacisnąć „AI Suggest Fields”, pozwolić AI rozpoznać zawartość strony, a potem kliknąć „Scrape”, aby pobrać dane. Bez kodowania, bez grzebania w selektorach — po prostu natychmiastowe efekty.
to moja pierwsza rekomendacja dla każdego, kto chce, by crawling danych był tak prosty jak zamówienie jedzenia na wynos. Thunderbit, zbudowany jako rozszerzenie do Chrome oparte na AI, stawia na scraping w 2 kliknięciach: wystarczy nacisnąć „AI Suggest Fields”, pozwolić AI rozpoznać zawartość strony, a potem kliknąć „Scrape”, aby pobrać dane. Bez kodowania, bez grzebania w selektorach — po prostu natychmiastowe efekty.
Co sprawia, że Thunderbit jest ulubieńcem zespołów sprzedaży, marketingu i e-commerce? Został zaprojektowany pod realne procesy biznesowe:
- AI Suggest Fields: AI odczytuje stronę i podpowiada najlepsze kolumny do wyciągnięcia — nazwy, ceny, e-maile, co tylko chcesz.
- Pozyskiwanie danych z podstron: Potrzebujesz więcej szczegółów? Thunderbit może automatycznie odwiedzać każdą podstronę (np. karty produktów lub profile LinkedIn) i wzbogacać tabelę.
- Natychmiastowy eksport: Przesyłaj dane bezpośrednio do Excela, Google Sheets, Airtable lub Notion. Wszystkie eksporty są bezpłatne.
- Szablony jednym kliknięciem: Dla popularnych serwisów (Amazon, Zillow, Instagram) korzystaj z gotowych szablonów, aby działać jeszcze szybciej.
- Darmowy eksport danych: Nie ma paywalla przy wyciąganiu danych.
- Zaplanowane scrapowanie: Ustaw zadania cykliczne prostym angielskim („every Monday at 9am”) — idealne do monitorowania cen lub cotygodniowych aktualizacji leadów.
Thunderbit działa w systemie kredytów (1 kredyt = 1 wiersz), a obejmuje do 6 stron (lub 10 z bonusem próbnym). Płatne plany zaczynają się od 15 USD miesięcznie za 500 kredytów, więc rozwiązanie jest przystępne cenowo dla zespołów każdej wielkości.
Jeśli chcesz zobaczyć Thunderbit w praktyce, zajrzyj na nasz albo . To narzędzie, które sam chciałbym mieć, kiedy tonąłem w ręcznym wprowadzaniu danych.
2. Octoparse
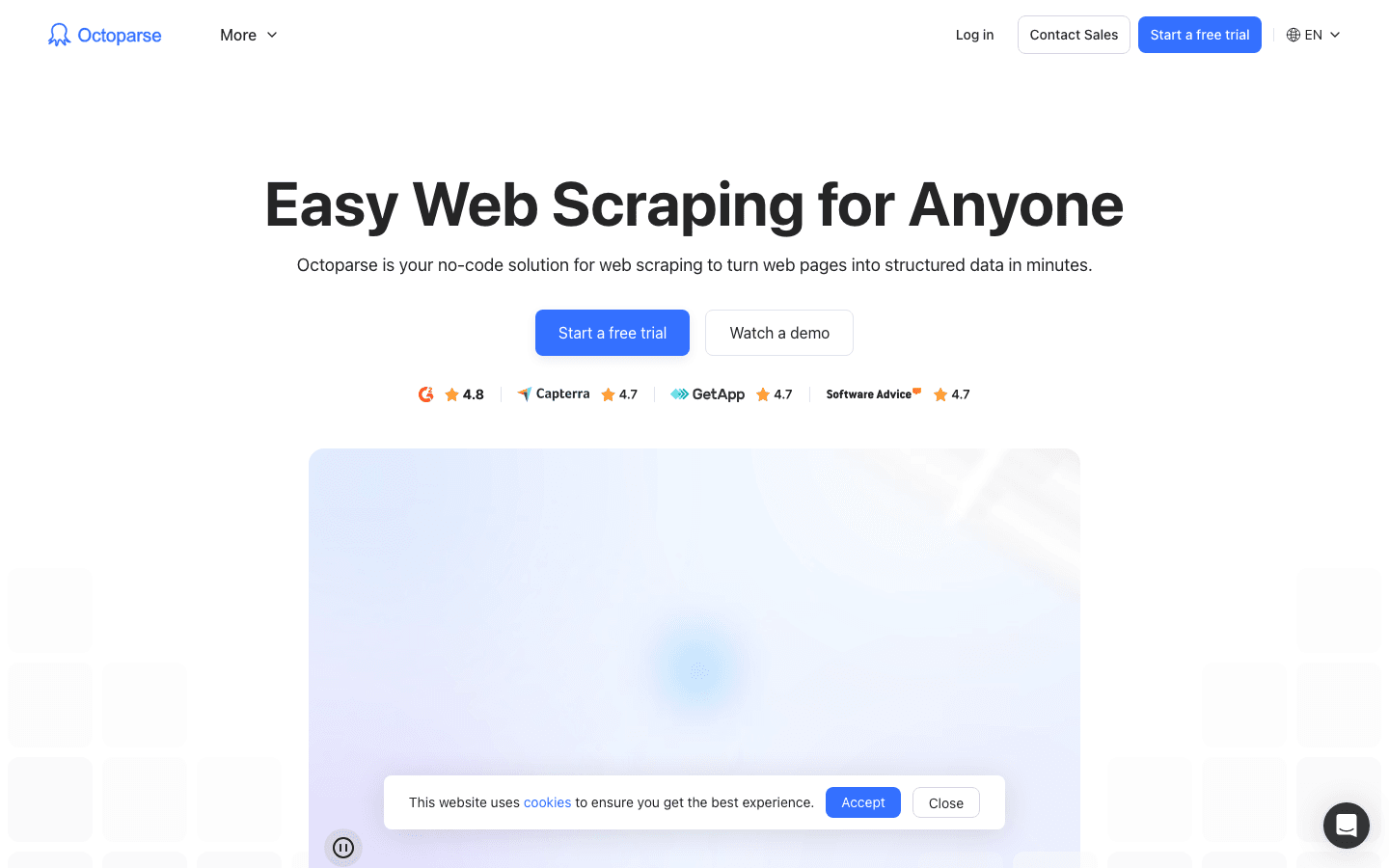 to ciężka artyleria w świecie crawlingu danych, szczególnie dla użytkowników enterprise, którzy potrzebują naprawdę dużej mocy. Oferuje wizualny interfejs desktopowy (Windows i Mac), w którym można klikać i budować przepływy ekstrakcji — bez kodowania. Ale nie daj się zwieść przyjaznemu UI: pod maską Octoparse obsługuje logowanie, nieskończone przewijanie, rotujące proxy, a nawet rozwiązywanie CAPTCHA.
to ciężka artyleria w świecie crawlingu danych, szczególnie dla użytkowników enterprise, którzy potrzebują naprawdę dużej mocy. Oferuje wizualny interfejs desktopowy (Windows i Mac), w którym można klikać i budować przepływy ekstrakcji — bez kodowania. Ale nie daj się zwieść przyjaznemu UI: pod maską Octoparse obsługuje logowanie, nieskończone przewijanie, rotujące proxy, a nawet rozwiązywanie CAPTCHA.
- 500+ gotowych szablonów: Zacznij szybko dzięki szablonom dla Amazon, Twittera, LinkedIn i wielu innych.
- Scraping w chmurze: Uruchamiaj zadania na serwerach Octoparse, planuj je i skaluj większe projekty.
- Dostęp do API: Integruj zebrane dane bezpośrednio z aplikacjami biznesowymi lub bazami danych.
- Zaawansowana automatyzacja: Obsługuje dynamiczne treści, paginację i wieloetapowe przepływy pracy.
Dostępny jest do 10 zadań, ale większość użytkowników biznesowych wybiera plan Standard (ok. 83 USD/mies.) albo Professional (ok. 299 USD/mies.). Krzywa nauki jest trochę bardziej stroma niż w Thunderbit, ale jeśli potrzebujesz niezawodnie scrapować tysiące stron, Octoparse jest bardzo mocnym kandydatem.
3. Scrapy
 to złoty standard dla deweloperów, którzy chcą mieć pełną kontrolę nad projektami crawlingu danych. To framework Python open source, który pozwala pisać własne spiders (crawler-y) dla dowolnej strony. Jeśli potrafisz to sobie wyobrazić, możesz to zbudować w Scrapy.
to złoty standard dla deweloperów, którzy chcą mieć pełną kontrolę nad projektami crawlingu danych. To framework Python open source, który pozwala pisać własne spiders (crawler-y) dla dowolnej strony. Jeśli potrafisz to sobie wyobrazić, możesz to zbudować w Scrapy.
- Pełna programowalność: Pisz kod w Pythonie, aby dokładnie zdefiniować, jak crawlować i parsować daną stronę.
- Asynchroniczny i szybki: Obsługuje tysiące stron równolegle w projektach na dużą skalę.
- Rozszerzalny: Dodawaj middleware do proxy, przeglądarek headless lub własnej logiki.
- Silna społeczność: Mnóstwo poradników, wtyczek i wsparcia dla trudnych scenariuszy scrapingu.
Scrapy jest darmowy i open source, ale wymaga umiejętności programowania. Jeśli masz zespół techniczny albo chcesz zbudować własny pipeline, trudno go przebić. Dla osób nietechnicznych to jednak spory podbój.
4. ParseHub
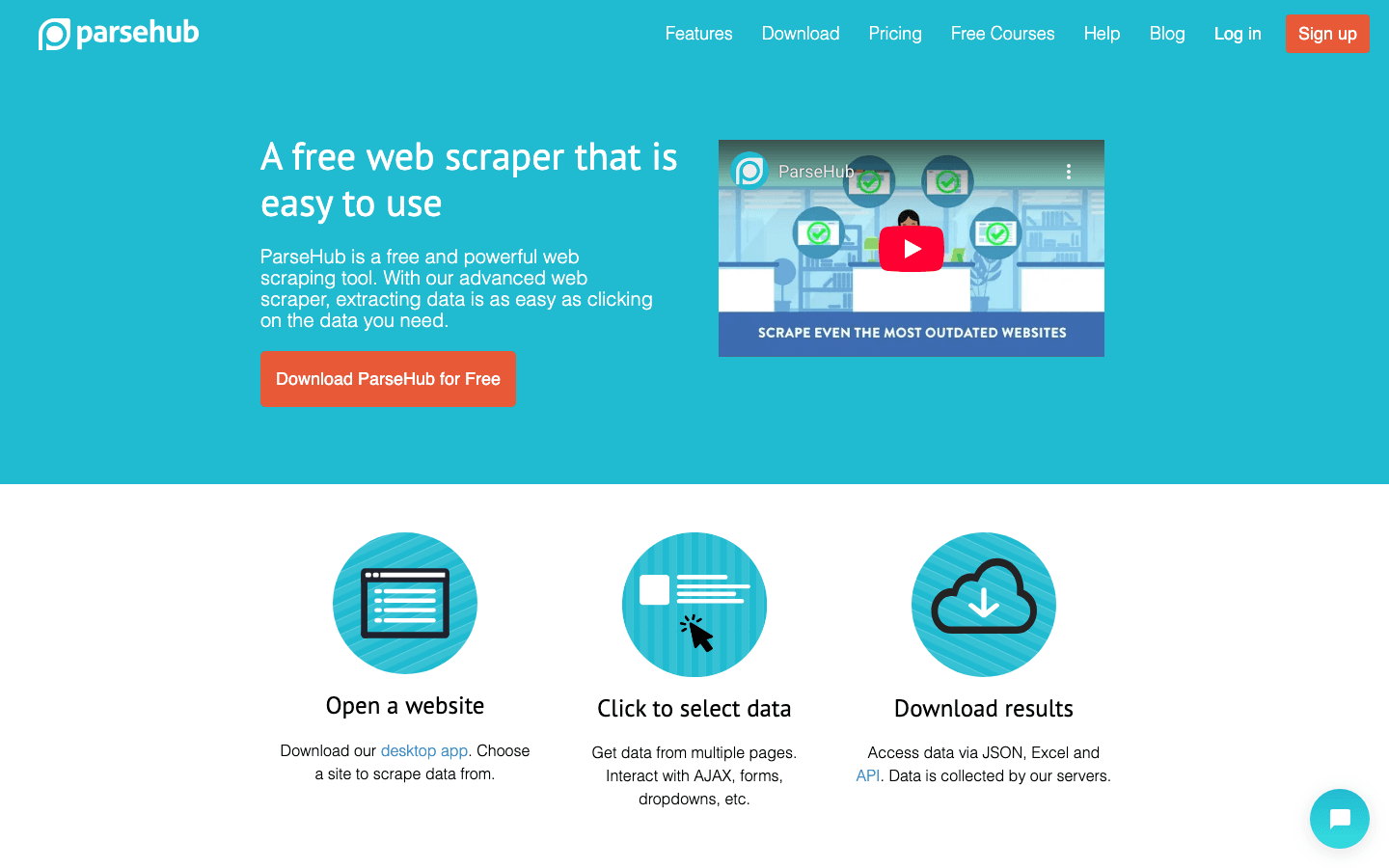 to wizualne, no-code’owe narzędzie do web scrapingu, idealne dla osób nietechnicznych pracujących z bardziej złożonymi stronami. Interfejs typu point-and-click pozwala wybierać elementy, definiować akcje i budować przepływy scrapingu — nawet dla stron z dynamicznymi treściami lub skomplikowaną nawigacją.
to wizualne, no-code’owe narzędzie do web scrapingu, idealne dla osób nietechnicznych pracujących z bardziej złożonymi stronami. Interfejs typu point-and-click pozwala wybierać elementy, definiować akcje i budować przepływy scrapingu — nawet dla stron z dynamicznymi treściami lub skomplikowaną nawigacją.
- Wizualny kreator workflow: Klikasz, aby wybrać dane, ustawić paginację i obsłużyć wyskakujące okna lub listy rozwijane.
- Obsługa dynamicznych treści: Działa ze stronami ciężkimi od JavaScriptu i interaktywnymi interfejsami.
- Uruchamianie w chmurze i harmonogramy: Odpalaj scraping w chmurze i ustawiaj zadania cykliczne.
- Eksport do CSV, Excela lub przez API: Łatwa integracja z ulubionymi narzędziami.
ParseHub oferuje darmowy plan (5 projektów), a płatne plany zaczynają się od . Jest nieco droższy niż część konkurencji, ale wizualne podejście sprawia, że jest przystępny dla analityków, marketerów i badaczy, którzy potrzebują czegoś więcej niż zwykłego rozszerzenia do Chrome.
5. Apify
 to zarówno platforma, jak i marketplace do crawlingu stron. Oferuje ogromną bibliotekę gotowych „Actorów” (gotowych scraperów) dla popularnych serwisów, a także możliwość tworzenia i uruchamiania własnych crawlerów w chmurze.
to zarówno platforma, jak i marketplace do crawlingu stron. Oferuje ogromną bibliotekę gotowych „Actorów” (gotowych scraperów) dla popularnych serwisów, a także możliwość tworzenia i uruchamiania własnych crawlerów w chmurze.
- 5000+ gotowych Actorów: Natychmiastowe pozyskiwanie danych z Google Maps, Amazon, Twittera i wielu innych.
- Własne skrypty: Deweloperzy mogą używać JavaScriptu lub Pythona do budowania zaawansowanych crawlerów.
- Skalowanie w chmurze: Uruchamiaj zadania równolegle, planuj je i zarządzaj danymi w chmurze.
- API i integracje: Wpinasz wyniki do aplikacji, workflowów lub pipeline’ów danych.
Apify ma elastyczny , a płatne plany zaczynają się od 29 USD/mies. (model pay-as-you-go za czas obliczeń). Jest tu pewna krzywa uczenia, ale jeśli chcesz mieć jednocześnie podejście plug-and-play i pełną personalizację, Apify to bardzo mocny wybór.
6. Data Miner
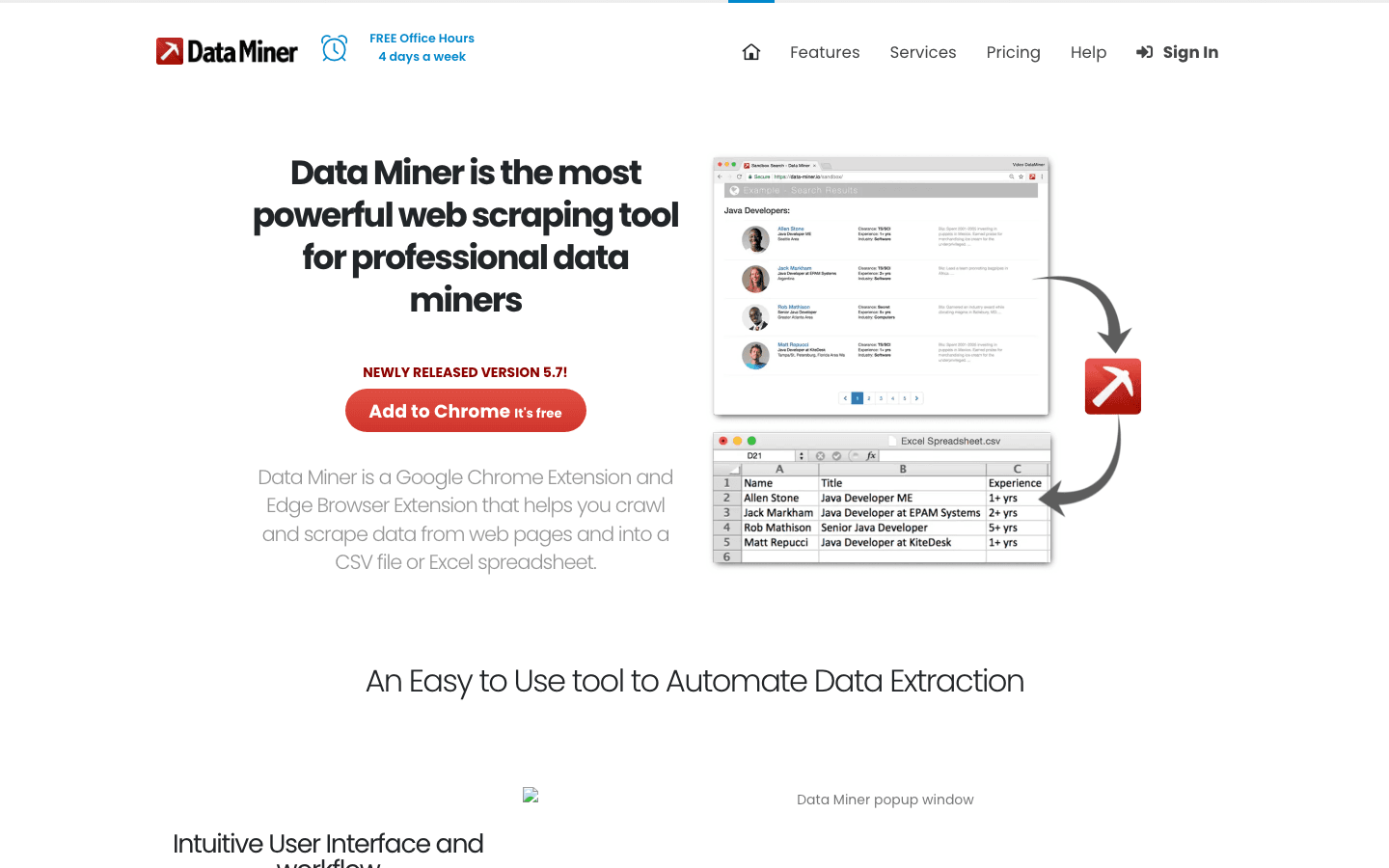 to rozszerzenie do Chrome stworzone do szybkiego, szablonowego crawlingu danych. Jest idealne dla użytkowników biznesowych, którzy chcą pobierać dane z tabel lub list bez żadnej konfiguracji.
to rozszerzenie do Chrome stworzone do szybkiego, szablonowego crawlingu danych. Jest idealne dla użytkowników biznesowych, którzy chcą pobierać dane z tabel lub list bez żadnej konfiguracji.
- Ogromna biblioteka szablonów: Ponad tysiąc gotowych receptur dla popularnych serwisów (LinkedIn, Yelp itp.).
- Ekstrakcja point-and-click: Wybierasz szablon, podglądasz dane i od razu eksportujesz.
- Działa w przeglądarce: Korzysta z bieżącej sesji — świetne do scrapingu za logowaniem.
- Eksport do CSV lub Excela: Przesyłasz dane do arkusza w kilka sekund.
obejmuje 500 stron miesięcznie, a płatne plany zaczynają się od 20 USD/mies. To dobre rozwiązanie do małych, jednorazowych zadań albo gdy potrzebujesz danych od razu — nie należy jednak oczekiwać, że poradzi sobie z ogromnymi projektami czy złożoną automatyzacją.
7. Import.io
 to platforma klasy enterprise dla organizacji, które potrzebują ciągłej i niezawodnej integracji danych z internetu. To coś więcej niż crawler — to zarządzana usługa, która dostarcza czyste, uporządkowane dane bezpośrednio do systemów biznesowych.
to platforma klasy enterprise dla organizacji, które potrzebują ciągłej i niezawodnej integracji danych z internetu. To coś więcej niż crawler — to zarządzana usługa, która dostarcza czyste, uporządkowane dane bezpośrednio do systemów biznesowych.
- Ekstrakcja bez kodowania: Wizualna konfiguracja tego, jakie dane mają być pobierane.
- Strumienie danych w czasie rzeczywistym: Przesyłanie danych do dashboardów, narzędzi analitycznych lub baz danych.
- Zgodność i niezawodność: Obsługa rotacji IP, zabezpieczeń anty-bot i zgodności prawnej.
- Usługi zarządzane: Zespół Import.io może skonfigurować i utrzymywać Twoje scrapery.
Ceny są , a platforma SaaS ma 14-dniowy darmowy okres próbny. Jeśli Twoja firma opiera się na zawsze świeżych danych z internetu (np. handel detaliczny, finanse czy badania rynku), warto przyjrzeć się Import.io.
8. WebHarvy
 to desktopowy scraper dla użytkowników Windows, którzy chcą rozwiązania point-and-click bez abonamentu. Jest szczególnie popularny wśród małych firm i osób prywatnych, które wolą jednorazowy zakup.
to desktopowy scraper dla użytkowników Windows, którzy chcą rozwiązania point-and-click bez abonamentu. Jest szczególnie popularny wśród małych firm i osób prywatnych, które wolą jednorazowy zakup.
- Wizualne wykrywanie wzorców: Klikasz elementy danych, a WebHarvy automatycznie rozpoznaje powtarzające się schematy.
- Obsługa tekstu, obrazów i nie tylko: Wyciąga wszystkie popularne typy danych, w tym e-maile i adresy URL.
- Paginacja i harmonogramy: Nawigacja po wielostronicowych serwisach i planowanie cyklicznych uruchomień.
- Eksport do Excela, CSV, XML, JSON lub SQL: Elastyczny format wyjściowy dla dowolnego workflow.
Licencja dla jednego użytkownika kosztuje , co czyni go opłacalnym wyborem do regularnego użytku — trzeba tylko pamiętać, że działa wyłącznie na Windowsie.
9. Mozenda
 to chmurowa platforma do crawlingu danych zbudowana z myślą o operacjach biznesowych i ciągłych potrzebach w zakresie danych. Łączy desktopowy kreator (Windows) z wydajnym wykonywaniem i automatyzacją w chmurze.
to chmurowa platforma do crawlingu danych zbudowana z myślą o operacjach biznesowych i ciągłych potrzebach w zakresie danych. Łączy desktopowy kreator (Windows) z wydajnym wykonywaniem i automatyzacją w chmurze.
- Wizualny kreator agentów: Projektuj procesy ekstrakcji metodą point-and-click.
- Skalowanie w chmurze: Uruchamiaj wiele agentów równolegle, planuj zadania i centralnie zarządzaj danymi.
- Konsola zarządzania danymi: Łącz, filtruj i czyść zbiory danych po ekstrakcji.
- Wsparcie enterprise: Dedykowani opiekunowie kont i usługi zarządzane dla dużych zespołów.
Plany zaczynają się od , a wyższe poziomy oferują więcej użytkowników i mocy obliczeniowej. Mozenda jest idealna dla firm, które potrzebują niezawodnych i powtarzalnych danych z internetu jako części codziennych operacji.
10. BeautifulSoup
 to klasyczna biblioteka Pythona do parsowania HTML i XML. To nie jest pełny crawler, ale deweloperzy uwielbiają ją przy małoskalowych, niestandardowych projektach scrapingu.
to klasyczna biblioteka Pythona do parsowania HTML i XML. To nie jest pełny crawler, ale deweloperzy uwielbiają ją przy małoskalowych, niestandardowych projektach scrapingu.
- Proste parsowanie HTML: Łatwe wyciąganie danych ze statycznych stron.
- Działa z Python Requests: Łącz z innymi bibliotekami do pobierania i crawlingu.
- Elastyczna i lekka: Idealna do szybkich skryptów lub projektów edukacyjnych.
- Ogromna społeczność: Mnóstwo poradników i odpowiedzi na Stack Overflow.
BeautifulSoup jest , ale trzeba samodzielnie napisać kod i obsłużyć logikę crawlingu. To najlepszy wybór dla deweloperów lub osób uczących się, które chcą zrozumieć techniczne podstawy web scrapingu.
Tabela porównawcza: narzędzia do crawlingu danych w skrócie
| Narzędzie | Łatwość obsługi | Poziom automatyzacji | Cena | Opcje eksportu | Najlepsze dla |
|---|---|---|---|---|---|
| Thunderbit | Bardzo łatwe, bez kodu | Wysoki (AI, podstrony) | Darmowy okres próbny, od 15 USD/mies. | Excel, Sheets, Airtable, Notion, CSV | Sprzedaż, marketing, e-commerce, osoby nietechniczne |
| Octoparse | Średnia, wizualny UI | Bardzo wysoki, chmura | Darmowy, 83–299 USD/mies. | CSV, Excel, JSON, API | Firmy enterprise, zespoły danych, dynamiczne strony |
| Scrapy | Niska (wymaga Pythona) | Wysoki (możliwość dostosowania) | Darmowy, open source | Dowolne (przez kod) | Deweloperzy, niestandardowe projekty na dużą skalę |
| ParseHub | Wysoka, wizualne | Wysoki (dynamiczne strony) | Darmowy, od 189 USD/mies. | CSV, Excel, JSON, API | Osoby nietechniczne, złożone struktury stron |
| Apify | Średnia, elastyczne | Bardzo wysoki, chmura | Darmowy, 29–999 USD/mies. | CSV, JSON, API, pamięć chmurowa | Deweloperzy, firmy, gotowe lub własne aktory |
| Data Miner | Bardzo łatwe, w przeglądarce | Niski (ręczny) | Darmowy, 20–99 USD/mies. | CSV, Excel | Szybkie, jednorazowe ekstrakcje, małe zbiory danych |
| Import.io | Średnia, zarządzane | Bardzo wysoki, enterprise | Indywidualna, zależna od wolumenu | CSV, JSON, API, bezpośrednia integracja | Firmy enterprise, ciągła integracja danych |
| WebHarvy | Wysoka, desktop | Średni (harmonogramy) | 129 USD jednorazowo | Excel, CSV, XML, JSON, SQL | MŚP, użytkownicy Windows, regularny scraping |
| Mozenda | Średnia, wizualne | Bardzo wysoki, chmura | 250–450+ USD/mies. | CSV, Excel, JSON, chmura, baza danych | Trwające, wielkoskalowe operacje biznesowe |
| BeautifulSoup | Niska (wymaga Pythona) | Niski (ręczne kodowanie) | Darmowy, open source | Dowolne (przez kod) | Deweloperzy, osoby uczące się, małe własne skrypty |
Jak wybrać odpowiednie narzędzie do crawlingu danych dla swojego zespołu
Wybór najlepszego narzędzia do crawlingu danych nie polega na znalezieniu „najmocniejszego” — chodzi o dopasowanie do umiejętności, potrzeb i budżetu Twojego zespołu. Oto moja krótka rada:
- Osoby nietechniczne lub użytkownicy biznesowi: Zacznij od Thunderbit, ParseHub lub Data Miner, jeśli zależy Ci na natychmiastowych efektach i prostym wdrożeniu.
- Potrzeby enterprise lub duża skala: Spójrz na Octoparse, Mozenda lub Import.io pod kątem automatyzacji, harmonogramów i wsparcia.
- Deweloperzy lub projekty niestandardowe: Scrapy, Apify lub BeautifulSoup dają pełną kontrolę i elastyczność.
- Niewielki budżet lub jednorazowe zadania: WebHarvy (Windows) albo Data Miner (przeglądarka) są opłacalne i proste.
Zawsze testuj najlepsze opcje na swoich docelowych stronach, korzystając z darmowego okresu próbnego — to, co działa na jednej stronie, może nie działać na innej. I nie zapomnij o integracji: jeśli potrzebujesz danych w Sheets, Notion albo bazie danych, upewnij się, że narzędzie obsługuje to od razu po instalacji.
Podsumowanie: odblokuj wartość biznesową dzięki najlepszym narzędziom do crawlingu danych
Dane z internetu to nowa ropa, ale tylko wtedy, gdy masz odpowiednią maszynę do ich wydobywania i rafinacji. Dzięki nowoczesnym narzędziom do crawlingu danych możesz zamienić godziny ręcznego researchu w minuty automatycznych analiz — zasilając mądrzejszą sprzedaż, skuteczniejszy marketing i bardziej zwinne operacje. Niezależnie od tego, czy budujesz listy leadów, śledzisz konkurencję, czy po prostu masz dość kopiowania i wklejania, na tej liście znajdziesz narzędzie, które znacznie ułatwi Ci życie.
Przyjrzyj się więc potrzebom swojego zespołu, przetestuj kilka z tych narzędzi i zobacz, ile więcej możesz osiągnąć, gdy automatyzacja przejmie ciężką pracę. A jeśli chcesz zobaczyć, jak wygląda scraping oparty na AI i działający w 2 kliknięciach, . Udanych crawlingów — i niech Twoje dane zawsze będą świeże, uporządkowane i gotowe do działania.
FAQ
1. Czym jest narzędzie do crawlingu danych i dlaczego miałbym go potrzebować?
Narzędzie do crawlingu danych automatyzuje proces pozyskiwania informacji ze stron internetowych. Oszczędza czas, ogranicza liczbę błędów i pomaga zespołom zbierać aktualne dane do sprzedaży, marketingu, badań i operacji — znacznie wydajniej niż ręczne kopiowanie i wklejanie.
2. Które narzędzie do crawlingu danych jest najlepsze dla użytkowników nietechnicznych?
Thunderbit, ParseHub i Data Miner to najlepsze wybory dla osób nietechnicznych. Thunderbit wyróżnia się dwuklikowym, opartym na AI workflow, a ParseHub oferuje wizualne podejście do bardziej złożonych stron.
3. Czym różnią się modele cenowe narzędzi do crawlingu danych?
Ceny bardzo się różnią: niektóre narzędzia (jak Thunderbit i Data Miner) oferują darmowe plany i niedrogie miesięczne pakiety, podczas gdy platformy enterprise (jak Import.io i Mozenda) stosują ceny indywidualne lub zależne od wolumenu. Zawsze sprawdź, czy koszt narzędzia pasuje do Twoich potrzeb danych.
4. Czy mogę używać tych narzędzi do ciągłego, planowanego pozyskiwania danych?
Tak — narzędzia takie jak Thunderbit, Octoparse, Apify, Mozenda i Import.io obsługują zaplanowane lub cykliczne crawle, dzięki czemu świetnie nadają się do bieżącego monitorowania cen, generowania leadów czy badania rynku.
5. Co powinienem wziąć pod uwagę przed wyborem narzędzia do crawlingu danych?
Weź pod uwagę umiejętności techniczne zespołu, złożoność stron, które chcesz crawlować, wolumen danych, potrzeby integracyjne i budżet. Przetestuj kilka narzędzi na rzeczywistych zadaniach, zanim zdecydujesz się na płatny plan.
Po więcej pogłębionych analiz i praktycznych poradników zajrzyj na .
Dowiedz się więcej