W ubiegłym kwartale nasz zespół operacyjny spędzał 40 godzin tygodniowo na kopiowaniu danych o konkurencji do arkuszy kalkulacyjnych. W tym kwartale zajmuje to 20 minut.
Różnica? Zautomatyzowane narzędzia do web scrapingu. Przeszły drogę od rozwiązań wyłącznie dla deweloperów do czegoś, co każdy handlowiec albo marketer może skonfigurować w trakcie lunchu.
Od lat tworzę SaaS i narzędzia do automatyzacji (i tak, jestem współzałożycielem ). Zestaw narzędzi z 2026 roku jest najmocniejszy do tej pory — natywnie oparty na AI, samonaprawiający się i naprawdę przydatny także dla osób nietechnicznych.
Oto 10 narzędzi, które oceniłem osobiście, porównując je według zastosowania i poziomu zaawansowania.
Dlaczego zautomatyzowane narzędzia do web scrapingu są ważne dla biznesu
Nie ma co się oszukiwać: czasy ręcznego kopiowania i wklejania danych ze stron internetowych minęły (chyba że ktoś lubi przeciążenia i egzystencjalny lęk). Zautomatyzowane narzędzia do web scrapingu stały się kluczowe dla firm każdej wielkości. W rzeczywistości , a web scraping jest ważnym elementem tej strategii.
Dlatego te narzędzia są tak wartościowe:
- Oszczędność czasu i mniej pracy ręcznej: Zautomatyzowane scrapery mogą przetwarzać tysiące rekordów w kilka minut, odciążając zespół i pozwalając mu skupić się na zadaniach o większej wartości. Jeden użytkownik narzędzia zgłaszał oszczędność „setek godzin” dzięki automatyzacji zbierania danych ().
- Większa dokładność danych: Koniec z literówkami i pominiętymi wpisami. Automatyczne pozyskiwanie oznacza czystsze i bardziej wiarygodne dane.
- Szybsze podejmowanie decyzji: Dzięki strumieniom danych w czasie rzeczywistym możesz monitorować konkurencję, śledzić ceny albo budować listy leadów bez czekania na comiesięczny raport praktykanta.
- Wsparcie dla zespołów nietechnicznych: Dzięki narzędziom no-code i opartym na AI nawet osoby, które myślą, że „XPath” to pozycja jogi, mogą dziś budować potoki danych webowych ().
Nic dziwnego, że , a prawie 80% twierdzi, że ich organizacja nie mogłaby skutecznie działać bez nich. W 2026 roku, jeśli nie automatyzujesz zbierania danych, prawdopodobnie zostawiasz na stole pieniądze — i wnioski.
Jak wybraliśmy najlepsze zautomatyzowane narzędzia do web scrapingu
Ponieważ rynek oprogramowania do web scrapingu ma według prognoz , wybór właściwego narzędzia może przypominać kupowanie butów w sklepie z 10 000 modeli. Oto jak zawęziłem listę:
- Łatwość użycia: Czy osoba nietechniczna może szybko zacząć? Czy nauka jest stroma?
- Możliwości AI: Czy narzędzie używa AI do automatycznego wykrywania pól danych, obsługi dynamicznych stron albo pozwala opisać potrzebę prostym językiem?
- Eksport i integracje danych: Jak łatwo przenieść dane do Excel, Google Sheets, Airtable, Notion lub CRM?
- Cena: Czy jest darmowy okres próbny? Czy płatne plany są dostępne dla osób indywidualnych i małych zespołów, czy tylko dla enterprise?
- Skalowalność: Czy narzędzie poradzi sobie zarówno z małymi, jednorazowymi zadaniami, jak i dużymi, planowanymi ekstrakcjami?
- Docelowy użytkownik: Czy jest stworzone dla biznesu, deweloperów, czy dla obu grup?
- Unikalne mocne strony: Co wyróżnia to narzędzie na tle konkurencji?
Uwzględniłem narzędzia dla każdego poziomu zaawansowania — od „chcę po prostu arkusz kalkulacyjny” po „chcę zeskrobać cały internet”. Zaczynajmy.
1. Thunderbit: Narzędzie do web scrapingu z AI dla każdego
Zacznę od narzędzia, które znam najlepiej — bo ja i mój zespół zbudowaliśmy je po to, by rozwiązać dokładnie te problemy, z którymi od lat mierzą się użytkownicy biznesowi. nie jest typowym scraperem typu „przeciągnij i upuść” ani „napisz własny selektor”. To asystent danych oparty na AI, który pozwala opisać, czego potrzebujesz, a potem wykonuje ciężką pracę — bez kodu, bez dłubania w XPath, bez łez.
Dlaczego Thunderbit jest na pierwszym miejscu
Thunderbit jest najbliżej tego, co można nazwać „zamienianiem dowolnej strony w bazę danych”. Oto jak działa:
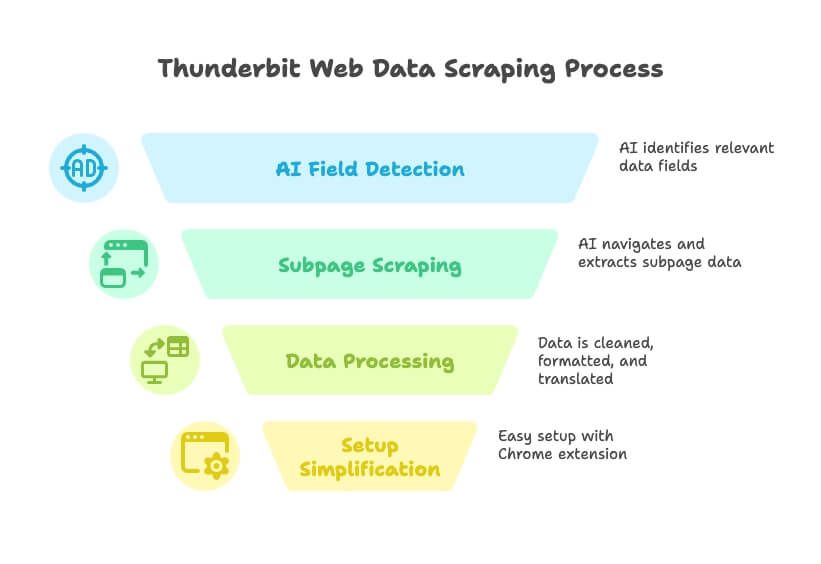
- Sterowanie językiem naturalnym: Po prostu powiedz Thunderbit, jakie dane są Ci potrzebne („Chcę wszystkie nazwy firm, adresy e-mail i numery telefonów z tego katalogu”), a AI automatycznie wykryje odpowiednie pola.
- Sugestie pól AI: Jednym kliknięciem Thunderbit analizuje stronę i podpowiada najlepsze kolumny do pobrania — bez zgadywania i prób po omacku.
- Scraping podstron i wielopoziomowy: Potrzebujesz szczegółów z podstrony każdej oferty? Thunderbit może przejść przez strony, pobrać dodatkowe informacje i dopisać je do tabeli.
- Czyszczenie, tłumaczenie i klasyfikacja danych: Thunderbit nie tylko pobiera surowe dane — może je czyścić, formatować, tłumaczyć, a nawet kategoryzować podczas scrapingu.
- Bez problemów z konfiguracją: Zainstaluj , kliknij „AI Suggest Fields” i w mniej niż minutę masz gotowy scraping.
- Darmowy okres próbny i niska cena: Hołodny darmowy plan (do 6 stron za darmo), a płatne plany zaczynają się już od 9 USD/miesiąc. To mniej niż wydaję na kawę w tydzień.
Thunderbit jest stworzone dla zespołów sprzedaży, marketingu i operacji, które potrzebują danych — szybko. Bez kodowania, bez wtyczek, bez szkolenia. To jak mieć stażystę od danych, który naprawdę słucha i nigdy nie narzeka.
Najmocniejsze funkcje Thunderbit
- Scraping sterowany AI: AI rozumie strukturę strony, dostosowuje się do zmian układu i automatycznie obsługuje paginację oraz podstrony ().
- Natychmiastowy eksport danych: Wyślij wyniki bezpośrednio do Excel, Google Sheets, Airtable, Notion albo pobierz jako CSV/JSON.
- Uruchamianie w chmurze lub lokalnie: Uruchamiaj scrapingi w chmurze dla szybkości i skali albo w przeglądarce, jeśli potrzebujesz użyć swojego logowania/sesji.
- Planowany scraping: Ustaw cykliczne zadania, aby dane były zawsze aktualne — idealne do monitorowania cen lub regularnego odświeżania leadów.
- Bezobsługowość: AI Thunderbit dostosowuje się do zmian na stronie, więc spędzasz mniej czasu na naprawianiu zepsutych scraperów ().
Dla kogo? Dla każdego, kto chce przejść od „potrzebuję tych danych” do „oto Twój arkusz” w kilka minut — zwłaszcza dla użytkowników nietechnicznych. Z i oceną 4,9★ Thunderbit szybko staje się narzędziem pierwszego wyboru dla zespołów biznesowych, które chcą wyników, a nie problemów.
Chcesz zobaczyć to w akcji? Zajrzyj na albo przejrzyj więcej .
2. Clay: Automatyczne wzbogacanie danych spotyka web scraping
Clay jest jak szwajcarski scyzoryk dla zespołów growth. To nie tylko web scraper — to arkusz automatyzacji, który łączy się z ponad 50 źródłami danych na żywo (pomyśl o Apollo, LinkedIn, Crunchbase) i wykorzystuje osadzone AI do wzbogacania leadów, pisania maili outreachowych i oceniania potencjalnych klientów.
- Automatyzacja workflow: Każdy wiersz to lead, każda kolumna może pobierać dane lub uruchamiać działanie. Chcesz zeskrobać listę firm, wzbogacić ją o profile LinkedIn i wysłać spersonalizowany e-mail? Clay to ogarnie.
- Integracja AI: Używa GPT-4 do pisania icebreakerów, podsumowywania bio i nie tylko.
- Integracje: Natywnie łączy się z HubSpot, Salesforce, Gmail, Slack i wieloma innymi narzędziami.
- Cena: Plan profesjonalny zaczyna się około 99 USD/miesiąc, a dla lekkiego użycia dostępny jest darmowy okres próbny.
Najlepsze dla: sprzedaży outbound, growth hackerów i marketerów, którzy chcą budować własne pipeline’y leadów — łącząc scraping, wzbogacanie danych i outreach w jednym miejscu. To potężne narzędzie, ale jeśli dopiero zaczynasz z automatyzacją, nauka może być trochę stroma ().
3. Bardeen: Oparty na przeglądarce scraper do automatyzacji workflow
Bardeen jest jak robot w przeglądarce, który potrafi pobierać dane i automatyzować powtarzalne zadania webowe — wszystko z poziomu rozszerzenia Chrome.
- Automatyzacja bez kodu: Ponad 500 „Playbooks” do scrapingu, wypełniania formularzy, przenoszenia danych między aplikacjami i nie tylko.
- AI Command Builder: Opisz zadanie prostym językiem, a Bardeen zbuduje workflow.
- Integracje: Działa z Notion, Trello, Slack, Salesforce i ponad 100 innymi aplikacjami.
- Cena: Darmowy dla lekkiego użycia (100 kredytów automatyzacji/miesiąc), a płatne plany zaczynają się od 99 USD/miesiąc dla zespołów.
Najlepsze dla: zaawansowanych użytkowników i zespołów GTM, które chcą automatyzować scraping i działania następcze w wielu aplikacjach. Jest tu sporo elastyczności, ale początkujący mogą uznać krzywą uczenia za dość stromą ().
4. Bright Data: zautomatyzowane narzędzie do web scrapingu klasy enterprise
Bright Data (dawniej Luminati) to ciężki sprzęt do web scrapingu — globalne sieci proxy, zaawansowane API i możliwość crawlowania tysięcy stron dziennie.
- Skala enterprise: Ponad 100 milionów IP, Web Scraper IDE, Web Unlocker do omijania zabezpieczeń anty-bot.
- Konfigurowalność: Buduj złożone, wielkoskalowe ekstrakcje z wysoką niezawodnością.
- Cena: Od 499 USD/miesiąc za Web Scraper IDE, z dostępnymi mniejszymi pakietami „micro”.
Najlepsze dla: dużych firm, agregatorów danych i zaawansowanych użytkowników, którzy potrzebują solidnych, skalowalnych rozwiązań. Jeśli codziennie crawlujesz tysiące stron i musisz unikać blokad IP, Bright Data jest stworzone właśnie dla Ciebie ().
5. Octoparse: wizualne narzędzie do web scrapingu dla użytkowników średniozaawansowanych
Octoparse to popularne narzędzie no-code z wizualnym interfejsem typu point-and-click — idealne dla osób, które chcą mocy bez programowania.
- Interfejs drag-and-drop: Klikaj elementy, aby określić, co pobrać, obsługiwać logowania, paginację i wiele więcej.
- Szablony: Ponad 500 gotowych szablonów dla popularnych serwisów (Amazon, Twitter itd.).
- Scraping w chmurze: Uruchamiaj zadania na serwerach Octoparse, planuj ekstrakcje i korzystaj z rotacji IP.
- Cena: Darmowy plan z ograniczeniami; płatne plany zaczynają się od 119 USD/miesiąc.
Najlepsze dla: osób nietechnicznych i analityków danych, którzy chcą sprawnego scrapera bez pisania kodu. Świetne do monitorowania cen, list produktów i projektów badawczych ().
6. : platforma do scrapingu danych dla firm
to jeden z pionierów web scrapingu, dziś rozwinięty do pełnej platformy ekstrakcji danych.
- Ekstrakcja typu point-and-click: Obsługuje logowania, listy rozwijane i elementy interaktywne.
- Oparty na chmurze: Przetwarza tysiące adresów URL równolegle, planuje ekstrakcje i udostępnia API.
- Ukierunkowanie na enterprise: Używany do monitorowania cen, badań rynkowych i budowania zbiorów danych do uczenia maszynowego.
- Cena: Plan Starter za 199 USD/miesiąc, Standard za 599 USD/miesiąc, Advanced za 1 099 USD/miesiąc.
Najlepsze dla: średnich i dużych firm oraz zespołów danych, które potrzebują niezawodnych, utrzymywanych rozwiązań do dużych zadań. Prawdopodobnie zbyt rozbudowane do projektów hobbystycznych, ale to prawdziwa potęga w zastosowaniach biznesowych ().
7. Parsehub: elastyczne narzędzie do web scrapingu z edytorem wizualnym
Parsehub to aplikacja desktopowa (Windows, Mac, Linux), która pozwala budować scrapery, klikając przez interfejs strony internetowej.
- Wizualny workflow: Zaznaczaj elementy, ustawiaj reguły ekstrakcji i obsługuj logowania, listy rozwijane oraz nieskończone przewijanie.
- Funkcje chmurowe: Uruchamiaj scrapingi w chmurze, planuj zadania i korzystaj z API.
- Cena: Darmowy plan do małych zadań; płatne plany zaczynają się od 149 USD/miesiąc.
Najlepsze dla: badaczy, małych firm lub osób indywidualnych, które chcą większej kontroli niż daje rozszerzenie przeglądarki, ale nie są jeszcze gotowe, by pisać własnego scrapera ().
8. Common Crawl: otwarte dane webowe dla AI i badań
Common Crawl nie jest narzędziem w tradycyjnym sensie — to ogromny otwarty zbiór danych ze zrzutów sieci, aktualizowany co miesiąc.
- Skala: Około 400 TB danych webowych obejmujących miliardy stron.
- Darmowe i otwarte: Nie trzeba uruchamiać własnego crawlера.
- Wymaga umiejętności technicznych: Do filtrowania i parsowania danych potrzebne są narzędzia big data oraz pewne umiejętności inżynierskie.
Najlepsze dla: data scientistów i inżynierów budujących modele AI lub prowadzących badania na dużą skalę. Jeśli potrzebujesz ogólnych tekstów z sieci albo długoterminowych archiwów, to prawdziwa kopalnia złota ().
9. Crawly: lekkie zautomatyzowane narzędzie do web scrapingu dla startupów
Crawly (od Diffbot) to chmurowy crawler oparty na AI, który potrafi pobierać dane z milionów stron i zwracać wyniki w uporządkowanej formie — bez potrzeby tworzenia reguł parsowania.
- Ekstrakcja AI: Wykorzystuje machine vision i NLP do identyfikacji oraz pobierania treści.
- Dostęp przez API: Odpytywanie zebranych danych i integracja z narzędziami analitycznymi lub bazami danych.
- Cena: Poziom enterprise; w sprawie cen trzeba się skontaktować.
Najlepsze dla: startupów i zespołów z pewnymi umiejętnościami technicznymi, które potrzebują wielkoskalowej, inteligentnej ekstrakcji danych webowych bez budowania własnych scraperów ().
10. Apify: przyjazne deweloperom narzędzie do web scrapingu z marketplace’em
Apify to platforma chmurowa, na której możesz budować własne scrapery („Actors”) albo korzystać z biblioteki gotowych scraperów społeczności.
- Elastyczność dla deweloperów: Obsługuje scraping w JavaScript/Python, headless Chrome, zarządzanie proxy i planowanie zadań.
- Marketplace: Rozbudowana biblioteka gotowych scraperów do popularnych serwisów.
- Cena: Darmowy plan z kredytem 5 USD/miesiąc; płatne plany zaczynają się od 49 USD/miesiąc.
Najlepsze dla: deweloperów i analityków technicznych, którzy chcą pełnej kontroli i skalowalności. Nawet osoby nieprogramujące mogą korzystać z gotowych Actors do typowych zadań ().
Tabela porównawcza zautomatyzowanych narzędzi do web scrapingu
| Narzędzie | Łatwość użycia | Funkcje AI | Cena (od) | Docelowy użytkownik | Najmocniejsze strony |
|---|---|---|---|---|---|
| Thunderbit | ★★★★★ | Język naturalny, AI Suggest Fields, scraping podstron | 9 USD/mies. | Nietechniczni użytkownicy biznesowi | Konfiguracja w 2 kliknięciach, bez kodu, natychmiastowy eksport, darmowy okres próbny |
| Clay | ★★★★☆ | Wzbogacanie AI, GPT-4 | 99 USD/mies. | Growth / sales ops | Arkusz automatyzacji, wzbogacanie danych, outreach |
| Bardeen | ★★★★☆ | AI Command Builder | 99 USD/mies. | Zaawansowani użytkownicy, zespoły GTM | Browser RPA, ponad 500 playbooków, głębokie integracje |
| Bright Data | ★★☆☆☆ | Rotacja proxy, AI anty-bot | 499 USD/mies. | Enterprise, deweloperzy | Skala, niezawodność, globalne proxy |
| Octoparse | ★★★★☆ | Wizualne wykrywanie AI | 119 USD/mies. | Analitycy, osoby bez kodowania | Drag-and-drop, szablony, scraping w chmurze |
| Import.io | ★★★☆☆ | Interaktywne ekstraktory | 199 USD/mies. | Enterprise, zespoły danych | Równoległość, planowanie, API, wsparcie |
| Parsehub | ★★★★☆ | Wizualne workflow | 149 USD/mies. | Badacze, małe i średnie firmy | Aplikacja desktopowa, obsługa dynamicznych stron |
| Common Crawl | ★☆☆☆☆ | N/D (tylko zbiór danych) | Darmowe | Data scientistci, inżynierowie | Ogromny otwarty zbiór danych, archiwa na skalę web |
| Crawly | ★★☆☆☆ | Ekstrakcja AI | Indywidualna / enterprise | Startupy, zespoły techniczne | Oparte na AI, bez reguł parsowania, dostęp przez API |
| Apify | ★★★★☆ | Marketplace Actors | 49 USD/mies. | Deweloperzy, analitycy techniczni | Budowanie/marketplace, automatyzacja w chmurze, elastyczność |
Jak wybrać odpowiednie narzędzie do web scrapingu dla swoich potrzeb
Wybór najlepszego zautomatyzowanego narzędzia do web scrapingu zależy od wielkości zespołu, umiejętności technicznych i celów biznesowych. Oto mój krótki przewodnik:
- Dla użytkowników nietechnicznych (sprzedaż, marketing, operacje): Wybierz . Jest stworzone dla Ciebie — bez kodu, bez konfiguracji, po prostu rezultaty. Idealne do generowania leadów, monitorowania cen i szybkich projektów danych.
- Dla zespołów obsesyjnie nastawionych na automatyzację: Clay i Bardeen sprawdzą się świetnie, jeśli chcesz łączyć scraping ze wzbogacaniem, outreachiem albo automatyzacją workflow.
- Dla enterprise i deweloperów: Bright Data, i Apify to najlepszy wybór do dużych, mocno konfigurowalnych projektów.
- Dla badaczy i analityków: Octoparse i Parsehub oferują wizualne interfejsy i mocne funkcje bez potrzeby kodowania.
- Dla projektów AI i data science: Common Crawl i Crawly zapewniają ogromne zbiory danych oraz ekstrakcję opartą na AI dla osób, które chcą budować albo trenować modele.
Zadaj sobie pytanie: chcesz zacząć w kilka minut, czy potrzebujesz zbudować niestandardowe rozwiązanie klasy enterprise? Jeśli nie masz pewności, zacznij od darmowego okresu próbnego — oferuje go większość narzędzi.
Unikalna wartość Thunderbit: asystent AI do danych biznesowych
Spośród wszystkich tych narzędzi Thunderbit wyróżnia się jako jedyne, które naprawdę działa jak „asystent AI” do web scrapingu i transformacji danych. Nie chodzi tylko o pobieranie danych — chodzi o zamienianie chaotycznych stron w czyste, uporządkowane wnioski bez żadnych barier technicznych.
- Interfejs języka naturalnego: Opisz, czego potrzebujesz, prostym językiem, a Thunderbit zajmie się resztą.
- Pełna automatyzacja workflow: Od ekstrakcji po czyszczenie, tłumaczenie i eksport — Thunderbit obsługuje cały proces.
- Idealne do szybkich eksperymentów: Chcesz zweryfikować nowy rynek, zbudować listę leadów albo monitorować konkurencję? Thunderbit to najszybszy i najtańszy punkt startowy.
To jak mieć analityka danych wbudowanego w przeglądarkę — takiego, który nigdy nie prosi o podwyżkę ani nie bierze urlopu.
Podsumowanie: zacznij mądrzej z odpowiednim zautomatyzowanym narzędziem do web scrapingu
Rynek scrapingu w 2026 roku jest nie do poznania w porównaniu z tym sprzed dwóch lat. Samonaprawiające się scrapery AI, natywne dla LLM potoki danych i naprawdę użyteczne narzędzia no-code całkowicie zmieniły zasady gry. Niezależnie od tego, czy jesteś solo founderem, zwinym zespołem sprzedaży, czy enterprise data scientistem, na tej liście znajdziesz narzędzie dopasowane do swoich potrzeb. Kluczem jest dopasowanie workflow i umiejętności do właściwej platformy — tak, aby przestać walczyć z kodem i zacząć wyciągać insighty.
Jeśli jesteś gotowy pożegnać ręczne kopiowanie i wklejanie oraz zacząć mądrzej, i zobacz, jak łatwy może być web scraping. Albo wybierz inne opcje z listy powyżej w zależności od swoich celów. Tak czy inaczej, przyszłość biznesu opartego na danych należy do tych, którzy automatyzują.
Chcesz dowiedzieć się więcej? Zajrzyj na , gdzie znajdziesz szczegółowe omówienia, poradniki i wskazówki, jak wycisnąć maksimum z danych webowych. Udanej pracy ze scrapingiem — i pamiętaj: niech Twoje dane zawsze będą czyste, a scrapery nigdy się nie psują (a jeśli się psują, niech AI zajmie się resztą).
FAQ
1. Dlaczego zautomatyzowane narzędzia do web scrapingu są ważne dla użytkowników biznesowych w 2026 roku?
Zautomatyzowane narzędzia do web scrapingu usprawniają zbieranie danych, oszczędzając czas i ograniczając pracę ręczną. Zwiększają dokładność danych, wspierają podejmowanie decyzji w czasie rzeczywistym i dają zespołom nietechnicznym możliwość pobierania oraz wykorzystywania danych webowych bez pisania kodu. Narzędzia te są dziś kluczowe dla sprzedaży, marketingu i operacji.
2. Co odróżnia Thunderbit od innych narzędzi do web scrapingu?
Thunderbit używa AI, aby użytkownik mógł opisać prostym językiem, jakie dane chce pobrać. Automatycznie wykrywa pola danych, obsługuje podstrony i paginację oraz natychmiast eksportuje wyniki do platform takich jak Excel i Airtable. Jest projektowany dla użytkowników nietechnicznych i oferuje mocne funkcje, takie jak czyszczenie danych i planowany scraping, w niskiej cenie.
3. Które narzędzie najlepiej nadaje się do dużych projektów enterprise związanych ze scrapingiem?
Bright Data i są idealne do zastosowań enterprise. Oferują funkcje takie jak rotacja proxy, zabezpieczenia anty-bot, duża równoległość i dostęp przez API, co czyni je odpowiednimi dla organizacji, które muszą niezawodnie i na dużą skalę przetwarzać tysiące stron internetowych.
4. Czy są narzędzia, które łączą scraping z automatyzacją i outreachiem?
Tak, narzędzia takie jak Clay i Bardeen nie tylko pobierają dane webowe, ale też włączają je do workflow. Clay wzbogaca leady i automatyzuje outreach, a Bardeen pozwala automatyzować zadania w przeglądarce i workflow za pomocą playbooków sterowanych przez AI.
5. Jaka jest najlepsza opcja dla osób bez zaplecza technicznego?
Thunderbit wyróżnia się dla użytkowników nietechnicznych dzięki interfejsowi języka naturalnego, konfiguracji sterowanej przez AI i łatwości użycia. Nie wymaga kodowania ani konfiguracji i jest idealne dla użytkowników biznesowych, którzy potrzebują szybkich, wiarygodnych danych bez technicznej złożoności.