
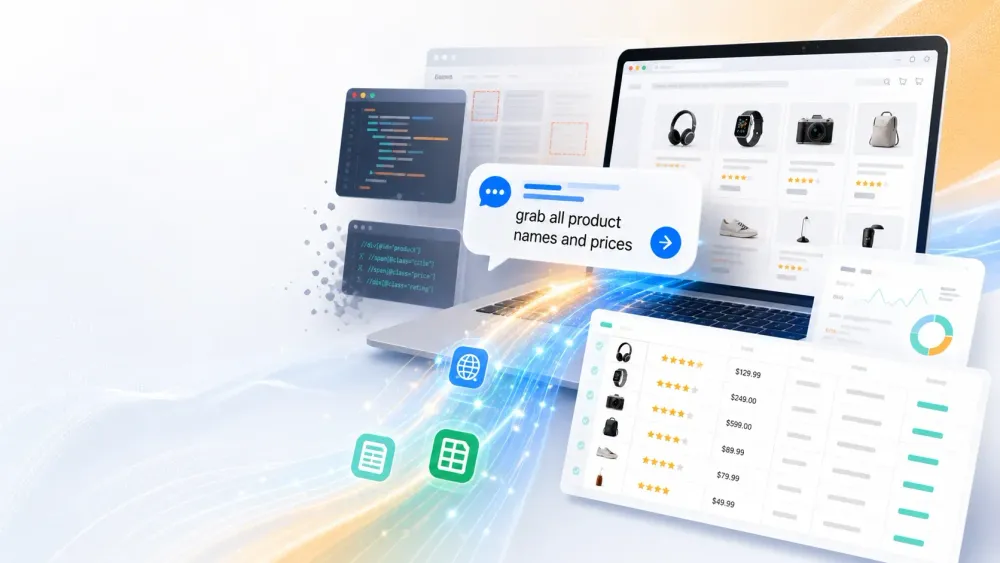
W 2015 roku scraping oznaczał proszenie dewelopera o skrypt w Pythonie albo spędzanie weekendu na nauce XPath. W 2026 wpisujesz: „pobierz wszystkie nazwy i ceny produktów”, a AI robi resztę.
Ta zmiana przyszła błyskawicznie. Z web scrapingu korzysta dziś ponad 2 miliony firm. Rynek przekroczył 1 mld USD w 2024 roku i według prognoz podwoi się do 2030 roku.
Największy motor tej zmiany? AI web crawlery. Dostosowują się do zmian w układzie strony. Rozumieją treść strony, a nie tylko tagi HTML. I działają także dla osób, które nigdy nie napisały ani jednej linijki kodu.
Spędziłem miesiące na testowaniu 15 z nich. Oto, co odkryłem — w tym dlaczego Thunderbit (tak, firma, którą współzałożyłem) zajął pierwsze miejsce.
Dlaczego AI zmienia scraping stron internetowych: nowa era narzędzi Web Scraper
Pobieraj dane z dowolnej strony dzięki AI Get Started Free
Bądźmy szczerzy: tradycyjny web scraping nigdy nie był tworzony z myślą o przeciętnym użytkowniku biznesowym. Wszystko kręciło się wokół kodu, selektorów i nadziei, że skrypt nie padnie przy kolejnej zmianie układu strony. AI i LLM-y całkowicie odwróciły ten model.
Oto jak:
- Polecenia w języku naturalnym: Zamiast walczyć z kodem, po prostu mówisz AI, czego chcesz. Narzędzia takie jak Thunderbit interpretują Twoje polecenia po angielsku i same konfigurują ekstrakcję (źródło).
- Uczenie adaptacyjne: AI scrapery potrafią dostosować się do zmian układu strony, co ogranicza problemy z utrzymaniem.
- Obsługa dynamicznej treści: Nowoczesne strony kochają JavaScript i nieskończone przewijanie. Narzędzia oparte na AI radzą sobie z tymi elementami i wyciągają dane, które stare scrapery by pominęły.
- Strukturalne wyjście dzięki parsowaniu AI: Scrapery oparte na LLM-ach naprawdę rozumieją treść strony i zwracają czyste, uporządkowane dane.
- Automatyczne obchodzenie zabezpieczeń antybotowych: AI scrapery potrafią omijać mechanizmy antyscrapingowe i korzystać z proxy / przeglądarek bezgłowych, żeby uniknąć blokad IP.
- Zintegrowane procesy danych: Najlepsze narzędzia nie tylko pobierają dane — dostarczają je tam, gdzie ich potrzebujesz, z eksportem jednym kliknięciem do Google Sheets, Airtable, Notion i wielu innych (źródło).
Efekt? Web scraping stał się doświadczeniem typu kliknij i działaj (a nawet rozmową z narzędziem), otwierając drogę nie tylko deweloperom, ale też zespołom sprzedaży, marketingu i operacji do bezpośredniego korzystania z danych z internetu.
15 AI Web Crawlerów, które warto poznać w 2026
Rozłóżmy na czynniki pierwsze 15 najlepszych AI web crawlerów, zaczynając od Thunderbit. Opowiem Ci o kluczowych funkcjach każdego narzędzia, docelowych użytkownikach, cenie i tym, co je wyróżnia. I tak — będę też uczciwy co do tego, gdzie każde z nich błyszczy, a gdzie niekoniecznie.
1. Thunderbit: AI Web Scraper dla każdego
Jasne, jestem tu trochę nieobiektywny, ale Thunderbit to AI web scraper, którego chciałbym mieć lata temu. Oto dlaczego zajmuje pierwsze miejsce na tej liście:
- Ekstrakcja w języku naturalnym: „Rozmawiasz” z Thunderbit. Po prostu opisz dane, których potrzebujesz — „pobierz wszystkie nazwy i ceny produktów z tej strony” — a AI zrobi resztę (źródło). Zero kodu, zero selektorów, zero bólu głowy.
- Crawling podstron i wielopoziomowy: Thunderbit może śledzić linki i pobierać dane z podstron. Na przykład: najpierw pobierasz listę produktów, a potem wchodzisz w każdy produkt po szczegóły — wszystko za jednym razem.
- Natychmiastowe, uporządkowane dane wyjściowe: AI formatuje i czyści dane w locie, sugerując odpowiednie pola, normalizując formaty, a nawet streszczając lub kategoryzując tekst.
- Szerokie wsparcie źródeł: Thunderbit nie działa tylko na HTML — potrafi też wyciągać dane z PDF-ów i obrazów dzięki wbudowanemu OCR i vision AI (źródło).
- Integracje biznesowe: Eksport jednym kliknięciem do Google Sheets, Airtable, Notion lub Excela (źródło). Zaplanuj scraping i wprowadzaj dane bezpośrednio do workflow swojego zespołu.
- Gotowe szablony: Dla stron takich jak Amazon, LinkedIn, Zillow itd. Thunderbit oferuje gotowe „przepisy” na scraping do pobierania danych jednym kliknięciem.
- Przyjazny i dostępny interfejs: Interfejs działa w modelu kliknij i działaj, a intuicyjny asystent sprawia, że użytkownicy zaczynają pracę w kilka minut.

Thunderbit zaufało ponad 30 000 użytkowników na całym świecie, w tym zespoły z Accenture, Grammarly i Puma. Zespoły sprzedaży używają go do tworzenia list leadów, agenci nieruchomości zbierają oferty, a marketerzy monitorują konkurencję — wszystko bez napisania choćby jednej linijki kodu.
Cena: Dostępny jest darmowy plan (do 100 kroków miesięcznie), a płatne plany zaczynają się od 14,99 USD miesięcznie. Nawet pakiety pro są przystępne dla osób indywidualnych i małych zespołów.
Thunderbit to najbliższe temu, co widziałem jako „zamianę internetu w bazę danych” — i jest zbudowany dla wszystkich, nie tylko dla inżynierów.
Wypróbuj rozszerzenie Thunderbit do Chrome
2. Crawl4AI
Dla kogo: Deweloperzy i zespoły techniczne budujące własne pipeline’y.
Crawl4AI to open-source’owy framework w Pythonie, zoptymalizowany pod kątem szybkości i crawlowania na dużą skalę, z myślą o integracji z LLM-ami. Jest błyskawiczny, obsługuje przeglądarki bezgłowe dla dynamicznej treści i potrafi strukturyzować pobrane dane tak, by łatwo podawać je do workflow AI.
- Najlepszy dla: Deweloperów potrzebujących wydajnego, konfigurowalnego silnika crawlującego.
- Cena: Za darmo (licencja MIT). Trzeba go samodzielnie hostować i uruchamiać.
3. ScrapeGraphAI
Dla kogo: Deweloperzy i analitycy budujący agentów AI lub złożone pipeline’y danych.
ScrapeGraphAI to oparty na promptach, open-source’owy projekt biblioteczny w Pythonie, który zamienia strony internetowe w uporządkowane „grafy” danych z użyciem LLM-ów. Możesz pisać prompty typu „Wyciągnij wszystkie nazwy produktów, ceny i oceny z pierwszych 5 stron”, a narzędzie samo zbuduje workflow scrapingu (źródło).
- Najlepszy dla: Użytkowników technicznych, którzy chcą elastycznego scrapingu opartego na promptach.
- Cena: Biblioteka open-source jest darmowa; chmura API zaczyna się od 20 USD miesięcznie.
4. Firecrawl
Dla kogo: Deweloperzy budujący agentów AI lub pipeline’y danych na dużą skalę.
Firecrawl to platforma i API do crawlingu zorientowane na AI, które zamieniają całe witryny w dane „gotowe dla LLM-ów” (źródło). Zwraca Markdown lub JSON, obsługuje dynamiczną treść i integruje się z frameworkami takimi jak LangChain i LlamaIndex.
- Najlepszy dla: Deweloperów, którzy chcą zasilać modele AI danymi z internetu na żywo.
- Cena: Rdzeń open-source jest darmowy; plany chmurowe zaczynają się od 19 USD miesięcznie.
5. Browse AI
Dla kogo: Użytkownicy biznesowi, growth hackerzy i analitycy.
Browse AI to platforma no-code z interfejsem typu kliknij i działaj. „Trenujesz” robota, klikając dane, które chcesz pobierać, a AI uogólnia wzorzec na przyszłe scrapingi. Obsługuje logowanie, nieskończone przewijanie i może monitorować strony pod kątem zmian.
- Najlepszy dla: Osób nietechnicznych, które chcą automatyzować zbieranie i monitorowanie danych.
- Cena: Darmowy plan (50 kredytów miesięcznie); płatne plany od 19 USD miesięcznie.
6. LLM Scraper
Dla kogo: Deweloperzy, którzy chcą, by parsowaniem zajęło się AI.
LLM Scraper to open-source’owa biblioteka JavaScript/TypeScript, która pozwala zdefiniować schemat danych i zlecić LLM-owi wyciągnięcie tych danych z dowolnej strony. Jest zbudowana na Playwright, wspiera wielu dostawców LLM i potrafi nawet generować kod wielokrotnego użytku.
- Najlepszy dla: Deweloperów, którzy chcą zamienić dowolną stronę w uporządkowane dane z pomocą LLM-ów.
- Cena: Za darmo (licencja MIT).
7. Reader (Jina Reader)
Dla kogo: Deweloperzy budujący aplikacje LLM, chatboty lub narzędzia do streszczania.
Jina Reader to API, które wyciąga czysty tekst i dane strukturalne ze stron internetowych (a nawet PDF-ów/obrazów), zwracając Markdown lub JSON gotowe dla LLM. Działa na niestandardowym modelu AI i potrafi nawet dodawać opisy do obrazów.
- Najlepszy dla: Pobierania czystej, czytelnej treści dla LLM-ów lub systemów Q&A.
- Cena: Darmowe API (do podstawowego użycia bez klucza).
8. Bright Data
Dla kogo: Firmy i użytkownicy profesjonalni potrzebujący skali, zgodności i niezawodności.
Bright Data to potężny gracz w branży danych webowych, z ogromną siecią proxy i narzędziami do scrapingu wspieranymi przez AI. Oferuje gotowe scrapery, ogólne API Web Scraper oraz kanały danych „gotowych dla LLM-ów”.
- Najlepszy dla: Organizacji potrzebujących niezawodnych danych webowych na dużą skalę.
- Cena: Model oparty na użyciu, z segmentem premium. Dostępne są darmowe wersje próbne.
9. Octoparse
Dla kogo: Użytkownicy nietechniczni i półtechniczni.
Octoparse to dobrze znane narzędzie no-code z wizualnym projektantem workflow i automatycznym wykrywaniem wspieranym przez AI. Obsługuje logowanie, nieskończone przewijanie i może eksportować dane w różnych formatach.
- Najlepszy dla: Analityków, właścicieli małych firm i badaczy.
- Cena: Dostępny darmowy plan; płatne plany od 119 USD miesięcznie.
10. Apify
Dla kogo: Deweloperzy i zespoły techniczne potrzebujące niestandardowego scrapingu/automatyzacji.
Apify to platforma chmurowa do uruchamiania skryptów scrapujących („actors”) i oferuje sklep z gotowymi actorami. Jest skalowalna, integruje się z AI i wspiera zarządzanie proxy.
- Najlepszy dla: Deweloperów, którzy chcą uruchamiać własne skrypty w chmurze.
- Cena: Darmowy plan; płatne plany oparte na użyciu zaczynają się od 49 USD miesięcznie.
11. Zyte (Scrapy Cloud)
Dla kogo: Deweloperzy i firmy potrzebujące scrapingu klasy enterprise.
Zyte to firma stojąca za Scrapy, oferująca platformę chmurową i automatyczną ekstrakcję wspieraną przez AI. Obsługuje harmonogramy, proxy i projekty na dużą skalę.
- Najlepszy dla: Zespołów developerskich prowadzących długoterminowe projekty scrapingowe.
- Cena: Od darmowych wersji próbnych po indywidualne plany enterprise.
12. Webscraper.io
Dla kogo: Początkujący, dziennikarze i badacze.
Webscraper.io to popularne rozszerzenie do Chrome do pobierania danych metodą kliknij i działaj. Jest proste, darmowe do użytku lokalnego i oferuje usługę chmurową dla większych zadań.
- Najlepszy dla: Szybkich, jednorazowych zadań scrapingowych.
- Cena: Darmowe rozszerzenie; plany chmurowe od około 50 USD miesięcznie.
13. ParseHub
Dla kogo: Użytkownicy nietechniczni, którzy potrzebują większej mocy niż podstawowe narzędzia.
ParseHub to aplikacja desktopowa z wizualnym workflow do scrapingu dynamicznej treści, w tym map i formularzy. Może uruchamiać projekty w chmurze i oferuje API.
- Najlepszy dla: Digital marketerów, analityków i dziennikarzy.
- Cena: Darmowy plan (200 stron na uruchomienie); płatne plany od 189 USD miesięcznie.
14. Diffbot
Dla kogo: Firmy i zespoły AI potrzebujące strukturalnych danych webowych na dużą skalę.
Diffbot wykorzystuje computer vision i NLP, aby automatycznie wyciągać dane z dowolnej strony, oferując API dla artykułów, produktów i ogromnego knowledge graph.
- Najlepszy dla: Intelligence rynkowej, finansów i danych treningowych dla AI.
- Cena: Premium, od około 299 USD miesięcznie.
15. DataMiner
Dla kogo: Użytkownicy nietechniczni, zwłaszcza w sprzedaży, marketingu i dziennikarstwie.
DataMiner to rozszerzenie do Chrome do szybkiego, kliknij i działaj pobierania danych z internetu. Ma bibliotekę gotowych „przepisów” i może eksportować bezpośrednio do Google Sheets.
- Najlepszy dla: Szybkich zadań, takich jak eksport tabel lub list do arkuszy kalkulacyjnych.
- Cena: Darmowy plan (500 stron dziennie); wersja Pro od około 19 USD miesięcznie.
Porównanie najlepszych narzędzi AI Web Scraper: które pasuje do Twoich potrzeb?
Oto porównanie na wysokim poziomie, które pomoże Ci znaleźć najlepszą opcję:
| Narzędzie | Użycie AI/LLM | Łatwość użycia | Wyjście/Integracje | Dla kogo najlepsze | Cena |
|---|---|---|---|---|---|
| Thunderbit | Interfejs w języku naturalnym; AI sugeruje pola | Najłatwiejsze (chat no-code) | Eksport do Sheets, Airtable, Notion | Zespoły nietechniczne | Darmowy plan; Pro ok. 30 USD/mies. |
| Crawl4AI | Crawling gotowy pod AI; integracja z LLM-ami | Trudne (kod Python) | Biblioteka/CLI; integracja przez kod | Deweloperzy potrzebujący szybkich pipeline’ów danych AI | Za darmo |
| ScrapeGraphAI | Pipeline’y promptów LLM do scrapingu | Średnio trudne (trochę kodu lub API) | API/SDK; wyjście JSON | Deweloperzy/analitycy budujący agentów AI | Darmowy OSS; API 20+ USD/mies. |
| Firecrawl | Crawluje do Markdown/JSON gotowego dla LLM | Średnio trudne (API/SDK) | SDK (Py, Node itd.); integracja z LangChain | Deweloperzy integrujący dane webowe na żywo z AI | Darmowy + płatna chmura |
| Browse AI | Wspomagany przez AI kliknij i działaj | Łatwe (no-code) | Ponad 7000 integracji aplikacji (Zapier) | Użytkownicy nietechniczni automatyzujący monitorowanie stron | Darmowe 50 uruchomień; płatne od 19+ USD/mies. |
| LLM Scraper | Używa LLM-ów do parsowania strony do schematu | Trudne (kod TS/JS) | Biblioteka kodu; wyjście JSON | Deweloperzy chcący, by AI zajęło się parsowaniem | Za darmo (z własnym API LLM) |
| Reader (Jina) | Model AI wyciąga tekst/JSON | Łatwe (proste wywołanie API) | REST API zwraca Markdown/JSON | Deweloperzy dodający web search / treść do LLM-ów | Darmowe API |
| Bright Data | API do scrapingu wspierane przez AI; duża sieć proxy | Trudne (API, techniczne) | API/SDK; strumienie danych lub zestawy danych | Skala enterprise | Oparte na użyciu |
| Octoparse | AI automatycznie wykrywa listy | Umiarkowane (aplikacja no-code) | CSV/Excel, API dla wyników | Użytkownicy półtechniczni | Darmowy, ograniczony; 59–166 USD/mies. |
| Apify | Niektóre funkcje AI (actors, tutoriale AI) | Trudne (kod skryptów) | Rozbudowane API; integracja z LangChain | Deweloperzy potrzebujący niestandardowego scrapingu w chmurze | Darmowy plan; pay-as-you-go |
| Zyte (Scrapy) | Automatyczna ekstrakcja oparta na ML; framework Scrapy | Trudne (kod Python) | API, interfejs Scrapy Cloud; JSON/CSV | Zespoły developerskie, projekty długoterminowe | Cennik indywidualny |
| Webscraper.io | Bez AI (ręczne szablony) | Łatwe (rozszerzenie przeglądarki) | Pobieranie CSV, Cloud API | Początkujący, szybkie jednorazowe scrapingi | Darmowe rozszerzenie; chmura ok. 50 USD/mies. |
| ParseHub | Brak jawnego LLM; wizualny builder | Umiarkowane (aplikacja no-code) | JSON/CSV; API dla uruchomień w chmurze | Osoby nietechniczne scrapujące złożone strony | Darmowe 200 stron; płatne od 189+ USD/mies. |
| Diffbot | AI vision/NLP dla dowolnej strony; knowledge graph | Łatwe (same wywołania API) | API (Article/Prod/...) + zapytania do Knowledge Graph | Enterprise, strukturalne dane webowe | Od ok. 299 USD/mies. |
| DataMiner | Bez LLM; społecznościowe przepisy | Najłatwiejsze (interfejs przeglądarkowy) | Eksport do Excel/CSV; Google Sheets | Użytkownicy nietechniczni scrapujący do arkuszy | Darmowy, ograniczony; Pro ok. 19 USD/mies. |
Kategorie narzędzi: od potężnych rozwiązań dla deweloperów po przyjazne dla biznesu web scrapery
Żeby lepiej zrozumieć tę listę, podzielmy te narzędzia na kilka kategorii:
1. Potęgi dla deweloperów i open source
- Przykłady: Crawl4AI, LLM Scraper, Apify, Zyte/Scrapy, Firecrawl
- Mocne strony: Wysoka elastyczność, skala i możliwość dostosowania. Świetne do budowy własnych pipeline’ów lub integracji z modelami AI.
- Wady: Wymagają umiejętności kodowania i większej konfiguracji.
- Przypadki użycia: Budowa niestandardowego pipeline’u danych, scraping złożonych stron lub integracja z systemami wewnętrznymi.
2. Agenci scrapingu zintegrowani z AI
- Przykłady: Thunderbit, ScrapeGraphAI, Firecrawl, Reader (Jina), LLM Scraper
- Mocne strony: Zmniejszają dystans między scrapingiem a rozumieniem danych. Interfejsy w języku naturalnym sprawiają, że są dostępne dla szerszego grona.
- Wady: Niektóre wciąż się rozwijają; mogą nie oferować bardzo granularnej kontroli.
- Przypadki użycia: Szybkie odpowiedzi lub zbiory danych, budowa autonomicznych agentów albo podawanie danych na żywo do LLM-ów.
3. Biznesowe scrapery no-code / low-code
- Przykłady: Thunderbit, Browse AI, Octoparse, ParseHub, Webscraper.io, DataMiner
- Mocne strony: Przyjazne w obsłudze, wymagają niewiele lub wcale kodowania, dobre do codziennych zadań biznesowych.
- Wady: Mogą mieć trudności z bardzo złożonymi stronami lub ogromną skalą.
- Przypadki użycia: Generowanie leadów, monitorowanie konkurencji, projekty badawcze i jednorazowe pobieranie danych.
4. Platformy i usługi danych dla enterprise
- Przykłady: Bright Data, Diffbot, Zyte
- Mocne strony: Kompleksowe rozwiązania, usługi zarządzane, zgodność i niezawodność na dużą skalę.
- Wady: Wyższy koszt, więcej pracy na start.
- Przypadki użycia: Zawsze aktywne pipeline’y danych na dużą skalę, intelligence rynkowa i dane treningowe dla AI.
Jak wybrać odpowiedni AI Web Crawler do swoich potrzeb scrapingu stron
Czym jest data scraping i jak go robić Get Started Free
Wybór właściwego narzędzia może przytłaczać, więc oto mój przewodnik krok po kroku:
- Określ cele i wymagania dotyczące danych: Jakich stron i jakich danych potrzebujesz? Jak często? W jakiej ilości? Do czego je wykorzystasz?
- Oceń swoje możliwości techniczne: Bez kodowania? Spróbuj Thunderbit, Browse AI lub Octoparse. Trochę skryptów? LLM Scraper lub DataMiner. Mocne umiejętności developerskie? Crawl4AI, Apify lub Zyte.
- Weź pod uwagę częstotliwość i skalę: Jednorazowy projekt? Użyj darmowych narzędzi. Powtarzalny? Szukaj funkcji harmonogramu. Duża skala? Narzędzia enterprise lub open source na dużą skalę.
- Budżet i model cenowy: Darmowe plany świetnie nadają się do testów. Wybór między subskrypcją a rozliczaniem za użycie zależy od potrzeb.
- Test i proof of concept: Przetestuj kilka narzędzi na własnych danych. Większość ma darmowe plany.
- Utrzymanie i wsparcie: Kto naprawi problem, jeśli strona się zmieni? Narzędzia no-code z AI mogą same naprawiać drobne zmiany; open source wymaga Ciebie albo społeczności.
- Dopasuj narzędzia do scenariuszy: Zespół sprzedaży zbiera leady? Thunderbit albo Browse AI. Badacz zbierający tweety? DataMiner albo Webscraper.io. Model AI potrzebujący artykułów newsowych? Jina Reader albo Zyte. Budujesz stronę porównawczą? Apify albo Zyte.
- Miej plan awaryjny: Czasami jedno narzędzie nie zadziała na konkretnej stronie. Warto mieć alternatywę.
„Właściwe” narzędzie to to, które dostarczy Ci potrzebne dane przy najmniejszym tarciu i w ramach budżetu. Czasem będzie to kombinacja kilku narzędzi.
Thunderbit vs. tradycyjne narzędzia Web Scraper: co go wyróżnia?
Przejdźmy konkretnie do tego, dlaczego Thunderbit jest inny:
- Interfejs w języku naturalnym: Bez kodu, bez gimnastyki point-and-click. Po prostu opisz, czego potrzebujesz (źródło).
- Zero konfiguracji i sugestie szablonów: Thunderbit automatycznie wykrywa paginację, podstrony, a nawet sugeruje szablony dla popularnych stron (źródło).
- Czyszczenie i wzbogacanie danych wspierane przez AI: Podsumowuj, kategoryzuj, tłumacz i wzbogacaj dane w trakcie scrapingu (źródło).
- Mniej problemów z utrzymaniem: AI w Thunderbit jest odporne na drobne zmiany na stronie, co ogranicza liczbę awarii.
- Integracja z narzędziami biznesowymi: Bezpośredni eksport do Google Sheets, Airtable, Notion — koniec z ręcznym ogarnianiem CSV (źródło).
- Szybkość do wartości: Przejdź od pomysłu do danych w kilka minut, nie dni.
- Krzywa uczenia się: Jeśli potrafisz przeglądać internet i opisać, czego potrzebujesz, poradzisz sobie z Thunderbit.
- Elastyczność: Scrapuj strony, PDF-y, obrazy i więcej — wszystko jednym narzędziem.
Thunderbit to nie tylko scraper — to asystent danych, który wpisuje się w Twój workflow, niezależnie od tego, czy pracujesz w sprzedaży, marketingu, ecommerce czy nieruchomościach.
Wypróbuj AI Web Scraper Thunderbit
Najlepsze praktyki scrapingu stron internetowych z użyciem AI Web Scraperów
Żeby wycisnąć z AI web scraperów maksimum, oto moje najważniejsze wskazówki:
- Jasno zdefiniuj potrzeby dotyczące danych: Wiedz, jakich pól chcesz, ile stron potrzebujesz i w jakim formacie.
- Korzystaj z sugestii AI: Używaj wykrywania pól i sugestii AI, by wychwycić ważne dane, które mógłbyś przegapić (źródło).
- Zacznij od małej próbki i zweryfikuj: Przetestuj na małym przykładzie, sprawdź wynik i w razie potrzeby dopasuj ustawienia.
- Obsługuj dynamiczną treść: Upewnij się, że narzędzie obsługuje dynamiczną treść i interakcje (paginację, nieskończone przewijanie itd.).
- Szanuj zasady stron internetowych: Sprawdź robots.txt, unikaj scrapowania danych wrażliwych i respektuj limity zapytań.
- Zintegruj procesy pod automatyzację: Korzystaj z eksportu i webhooków, aby podpiąć pobrane dane bezpośrednio do workflow.
- Dbaj o jakość danych: Weryfikuj dane, stosuj post-processing i monitoruj błędy.
- Bądź zwięzły w promptach: Przy narzędziach opartych na AI jasne i konkretne instrukcje dają lepsze efekty.
- Ucz się od społeczności: Dołącz do forów i społeczności po wskazówki i pomoc w rozwiązywaniu problemów.
- Bądź na bieżąco: Narzędzia AI rozwijają się błyskawicznie — śledź nowe funkcje i usprawnienia.
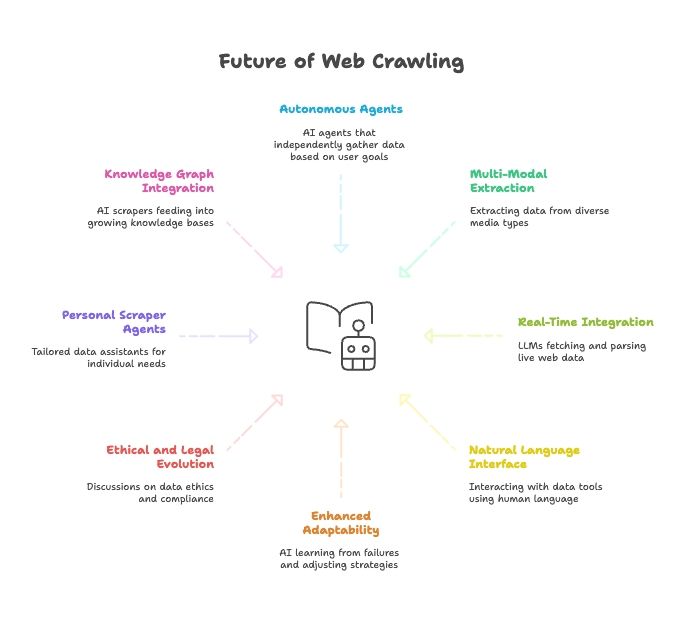
Przyszłość web scrapingu: AI, LLM-y i wzrost agentów web scraperów w języku naturalnym
Patrząc w przyszłość, zbieżność AI i web scrapingu będzie tylko przyspieszać:
- W pełni autonomiczni agenci scrapingu: Wkrótce wystarczy powiedzieć agentowi AI, jaki jest cel końcowy, a on sam wymyśli, jak zdobyć dane.
- Wielomodalna ekstrakcja danych: Scrapery będą pobierać dane z tekstu, obrazów, PDF-ów, a nawet wideo.
- Integracja w czasie rzeczywistym z modelami AI: LLM-y będą miały wbudowane moduły do pobierania i parsowania danych webowych na żywo.
- Wszędzie język naturalny: Będziemy rozmawiać z narzędziami danych tak jak z ludźmi, co sprawi, że zbieranie i przekształcanie danych stanie się dostępne dla każdego.
- Lepsza adaptacyjność: AI scrapery będą uczyć się na błędach i automatycznie dostosowywać strategie.
- Ewolucja etyczna i prawna: Można się spodziewać coraz większej dyskusji o etyce danych, zgodności i fair use.
- Osobiste agenty scrapingu: Wyobraź sobie osobistego asystenta danych, który zbiera newsy, oferty pracy i więcej — dopasowane do Twoich potrzeb.
- Integracja z knowledge graphami: AI scrapery będą stale zasilać rosnące bazy wiedzy, napędzając inteligentniejsze AI.
Wniosek? Przyszłość web scrapingu jest nierozerwalnie związana z przyszłością AI. Narzędzia stają się mądrzejsze, bardziej autonomiczne i bardziej dostępne z każdym dniem.
Podsumowanie: odblokuj wartość biznesową dzięki odpowiedniemu AI Web Crawlerowi
Web scraping przeszedł drogę od niszowej, technicznej umiejętności do kluczowej kompetencji biznesowej — dzięki AI. 15 narzędzi, które omówiłem, pokazuje to, co w 2026 roku jest najlepsze: od potężnych rozwiązań dla deweloperów po przyjaznych asystentów dla biznesu.
Prawdziwy sekret? Wybór właściwego narzędzia może dramatycznie zwiększyć wartość, jaką wyciągasz z danych webowych. Dla zespołów nietechnicznych Thunderbit to najprostszy sposób, by zamienić internet w uporządkowaną bazę danych gotową do analizy — bez kodu, bez problemów, po prostu wynik.
Więc niezależnie od tego, czy zbierasz leady, monitorujesz konkurencję, czy karmisz swój model AI nowej generacji, poświęć chwilę na ocenę potrzeb, przetestuj kilka narzędzi i sprawdź, co działa najlepiej dla Ciebie. A jeśli chcesz już dziś zobaczyć przyszłość web scrapingu, wypróbuj Thunderbit. Potrzebne Ci wnioski są na wyciągnięcie promptu.
Chcesz dowiedzieć się więcej? Sprawdź blog Thunderbit, gdzie znajdziesz pogłębione analizy, poradniki i najnowsze informacje o ekstrakcji danych wspieranej przez AI.
Dalsza lektura:
- Czym jest data scraping i jak robić go w 2026 roku
- Jak pobierać dane ze strony do Excela z użyciem AI
- Najlepsze narzędzia i oprogramowanie do web scrapingu w 2026 roku
Wypróbuj AI Web Scraper Get Started Free
FAQ
1. Czym jest AI web crawler i czym różni się od tradycyjnych web scraperów?
AI web crawler wykorzystuje przetwarzanie języka naturalnego i machine learning, aby rozumieć, wyciągać i strukturyzować dane webowe. W przeciwieństwie do tradycyjnych scraperów, które wymagają ręcznego kodowania i selektorów XPath, narzędzia AI potrafią obsługiwać dynamiczną treść, dostosowywać się do zmian układu strony i interpretować polecenia użytkownika w prostym języku angielskim.
2. Kto powinien korzystać z narzędzi do AI web scrapingu, takich jak Thunderbit?
Thunderbit jest stworzony zarówno dla użytkowników nietechnicznych, jak i technicznych. To idealne rozwiązanie dla specjalistów ze sprzedaży, marketingu, operacji, researchu i ecommerce, którzy chcą wyciągać uporządkowane dane ze stron internetowych, PDF-ów lub obrazów — bez pisania kodu.
3. Jakie funkcje wyróżniają Thunderbit na tle innych AI web crawlerów?
Thunderbit oferuje interfejs w języku naturalnym, wielopoziomowy crawling, automatyczne strukturyzowanie danych, wsparcie OCR i płynny eksport do platform takich jak Google Sheets i Airtable. Zawiera też sugestie pól wspierane przez AI oraz gotowe szablony dla popularnych stron.
4. Czy w 2026 są darmowe opcje AI web scrapingu?
Tak. Wiele narzędzi, takich jak Thunderbit, Browse AI i DataMiner, oferuje darmowe plany z ograniczonym użyciem. Dla deweloperów opcje open source, takie jak Crawl4AI i ScrapeGraphAI, zapewniają pełną funkcjonalność bez kosztów, choć wymagają technicznej konfiguracji.
5. Jak wybrać odpowiedni AI web crawler do moich potrzeb?
Zacznij od określenia celów danych, swoich umiejętności technicznych, budżetu i wymagań skali. Jeśli chcesz rozwiązania no-code, łatwego w użyciu, Thunderbit lub Browse AI będą świetnym wyborem. Do potrzeb dużej skali lub niestandardowych lepiej sprawdzą się narzędzia takie jak Apify lub Bright Data.




