

Bądźmy szczerzy — Amazon to w praktyce centrum handlowe, supermarket i sklep z elektroniką całego internetu. Jeśli zajmujesz się sprzedażą, e-commerce albo operacjami, dobrze wiesz, że to, co dzieje się na Amazonie, nie zostaje na Amazonie — wpływa na ceny, stany magazynowe, a nawet na Twój kolejny duży start produktu. Jest tylko jeden haczyk: wszystkie te cenne szczegóły produktów, ceny, oceny i recenzje są zamknięte w interfejsie stworzonym z myślą o kupujących, a nie o zespołach, które żyją danymi. Jak więc zdobyć te informacje, nie spędzając weekendów na kopiowaniu i wklejaniu jak w 1999 roku?
I tu wchodzi web scraping. W tym przewodniku pokażę Ci dwa sposoby na pobranie danych o produktach z Amazona: klasyczne podejście „zakasaj rękawy i napisz to w Pythonie” oraz nowoczesną ścieżkę „niech AI wykona ciężką pracę” z no-code web scraperem takim jak Thunderbit. Przejdę przez prawdziwy kod w Pythonie (wraz ze wszystkimi pułapkami i obejściami), a potem pokażę, jak Thunderbit może dostarczyć te same dane w zaledwie kilka kliknięć — bez kodowania. Niezależnie od tego, czy jesteś deweloperem, analitykiem biznesowym, czy po prostu masz dość ręcznego wprowadzania danych, znajdziesz tu coś dla siebie.
Dlaczego warto pobierać dane o produktach z Amazona? (amazon scraper python, web scraping with python)
Amazon to nie tylko największy sklep internetowy na świecie — to także największy na świecie otwarty rynek do analizy konkurencji. Przy ponad 600 milionach wystawionych produktów i niemal 2 milionach aktywnych sprzedawców Amazon jest kopalnią złota dla każdego, kto chce:

- Monitorować ceny (i dostosowywać własne w czasie rzeczywistym)
- Analizować konkurencję (śledzić nowe premiery, oceny i recenzje)
- Generować leady (znajdować sprzedawców, dostawców, a nawet potencjalnych partnerów)
- Prognozować popyt (obserwując stany magazynowe i pozycje sprzedaży)
- Wykrywać trendy rynkowe (na podstawie recenzji i wyników wyszukiwania)
I to nie jest tylko teoria — firmy naprawdę osiągają na tym konkretne wyniki. Na przykład jeden sprzedawca elektroniki wykorzystał pobrane dane o cenach z Amazona, aby zwiększyć marżę zysku o 15%, a inna marka odnotowała 4% wzrost sprzedaży i o 30% mniej czasu analityka po zautomatyzowaniu śledzenia cen konkurencji.
Oto krótka tabela zastosowań i typowego ROI, jakiego możesz się spodziewać:
| Przypadek użycia | Kto korzysta | Typowy ROI / korzyść |
|---|---|---|
| Monitorowanie cen | E-commerce, operacje | Wzrost marży zysku o 15%+, wzrost sprzedaży o 4%, o 30% mniej czasu analityka |
| Analiza konkurencji | Sprzedaż, produkt, operacje | Szybsze dostosowanie cen, lepsza konkurencyjność |
| Badanie rynku (recenzje) | Produkt, marketing | Szybsze iteracje produktu, lepszy copywriting reklam, wnioski SEO |
| Generowanie leadów | Sprzedaż | Ponad 3000 leadów/miesiąc, ponad 8 godzin oszczędności na handlowca tygodniowo |
| Prognozowanie zapasów i popytu | Operacje, łańcuch dostaw | 20% mniej nadwyżek magazynowych, mniej braków towaru |
| Wykrywanie trendów | Marketing, kadra zarządzająca | Wczesne wykrywanie gorących produktów i kategorii |
A oto najważniejsze: ponad 90% organizacji raportuje dziś wymierną wartość z analityki danych. Jeśli nie scrapujesz Amazona, zostawiasz wiedzę — i pieniądze — na stole.
Przegląd: Amazon Scraper Python vs. no-code web scraper tools
Są dwa główne sposoby, by wyciągnąć dane z Amazona z przeglądarki do arkuszy lub dashboardów:
-
Amazon Scraper Python (web scraping with python):
Napisz własny skrypt w Pythonie, używając bibliotek takich jak Requests i BeautifulSoup. Daje Ci to pełną kontrolę, ale musisz umieć programować, poradzić sobie z zabezpieczeniami anty-bot i utrzymywać skrypt, gdy Amazon zmienia układ strony.
-
No-code web scraper tools (takie jak Thunderbit):
Użyj narzędzia, które pozwala wskazać, kliknąć i pobrać dane — bez programowania. Nowoczesne narzędzia, takie jak Thunderbit, wykorzystują nawet AI, aby zrozumieć, jakie dane pobrać, obsłużyć podstrony i paginację oraz wyeksportować wyniki prosto do Excela albo Google Sheets.
Tak to wygląda w porównaniu:
| Kryterium | Python Scraper | No-code (Thunderbit) |
|---|---|---|
| Czas konfiguracji | Wysoki (instalacja, kod, debugowanie) | Niski (instalacja rozszerzenia) |
| Wymagana wiedza | Konieczne kodowanie | Brak (wskaż i kliknij) |
| Elastyczność | Nieograniczona | Wysoka w typowych przypadkach użycia |
| Utrzymanie | Naprawiasz kod sam | Narzędzie aktualizuje się samo |
| Obsługa anty-bot | Sam ogarniasz proxy i nagłówki | Wbudowana, załatwiona za Ciebie |
| Skalowalność | Ręczna (wątki, proxy) | Scraping w chmurze, równoległy |
| Eksport danych | Niestandardowy (CSV, Excel, baza danych) | Jedno kliknięcie do Excela, Sheets |
| Koszt | Darmowy (Twój czas + proxy) | Freemium, płatne przy większej skali |
W kolejnych sekcjach przeprowadzę Cię przez oba podejścia — najpierw jak zbudować Amazon scraper w Pythonie (z prawdziwym kodem), a potem jak zrobić to samo za pomocą AI web scrapera Thunderbit.
Pierwsze kroki z Amazon Scraper Python: wymagania i konfiguracja
Zanim wejdziemy w kod, skonfigurujmy środowisko.
Będziesz potrzebować:
- Python 3.x (pobierz z python.org)
- Edytor kodu (ja lubię VS Code, ale każdy się nada)
- Następujące biblioteki:
requests(do żądań HTTP)beautifulsoup4(do parsowania HTML)lxml(szybki parser HTML)pandas(do tabel danych / eksportu)re(wyrażenia regularne, wbudowane)
Instalacja bibliotek:
pip install requests beautifulsoup4 lxml pandas
Konfiguracja projektu:
- Utwórz nowy folder na projekt.
- Otwórz edytor, stwórz nowy plik Python (np.
amazon_scraper.py). - Jesteś gotowy do działania!
Krok po kroku: web scraping w Pythonie dla danych o produktach z Amazona
Przejdźmy przez pobieranie danych z jednej strony produktu Amazon. (Bez obaw, za chwilę pokażę też, jak scrapować wiele produktów i stron.)
1. Wysyłanie żądań i pobieranie HTML
Najpierw pobierzmy HTML strony produktu. (Zastąp adres URL dowolnym produktem z Amazona.)
import requests
url = "<https://www.amazon.com/dp/B0ExampleASIN>"
response = requests.get(url)
html_content = response.text
print(response.status_code)
Uwaga: Takie podstawowe żądanie Amazon prawdopodobnie zablokuje. Możesz zobaczyć błąd 503 albo CAPTCHA zamiast strony produktu. Dlaczego? Bo Amazon wie, że nie jesteś prawdziwą przeglądarką.
Jak radzić sobie z zabezpieczeniami anty-bot Amazona
Amazon nie przepada za botami. Żeby uniknąć blokady, musisz:
- Ustawić nagłówek User-Agent (udawać Chrome albo Firefox)
- Rotować User-Agenty (nie używać tego samego za każdym razem)
- Ograniczać tempo żądań (dodawać losowe opóźnienia)
- Korzystać z proxy (przy scrapingu na dużą skalę)
Oto jak ustawić nagłówki:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)... Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
}
response = requests.get(url, headers=headers)
Chcesz zrobić to bardziej profesjonalnie? Użyj listy User-Agentów i rotuj je przy każdym żądaniu. Przy większych projektach warto skorzystać z usługi proxy (jest ich wiele), ale przy małej skali zwykle wystarczą nagłówki i opóźnienia.
Wyodrębnianie kluczowych pól produktu
Gdy masz już HTML, pora sparsować go za pomocą BeautifulSoup.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, "lxml")
Teraz wyciągnijmy najważniejsze dane:
Tytuł produktu
title_elem = soup.find(id="productTitle")
product_title = title_elem.get_text(strip=True) if title_elem else None
Cena
Cena na Amazonie może znajdować się w kilku miejscach. Spróbuj tych opcji:
price = None
price_elem = soup.find(id="priceblock_ourprice") or soup.find(id="priceblock_dealprice")
if price_elem:
price = price_elem.get_text(strip=True)
else:
price_whole = soup.find("span", {"class": "a-price-whole"})
price_frac = soup.find("span", {"class": "a-price-fraction"})
if price_whole and price_frac:
price = price_whole.text + price_frac.text
Ocena i liczba recenzji
rating_elem = soup.find("span", {"class": "a-icon-alt"})
rating = rating_elem.get_text(strip=True) if rating_elem else None
review_count_elem = soup.find(id="acrCustomerReviewText")
reviews_text = review_count_elem.get_text(strip=True) if review_count_elem else ""
reviews_count = reviews_text.split()[0] # np. "1,554 ratings"
Adres URL głównego obrazu
Amazon czasem ukrywa obrazy w wysokiej rozdzielczości w JSON-ie wewnątrz HTML. Oto szybkie podejście z regexem:
import re
match = re.search(r'"hiRes":"(https://.*?.jpg)"', html_content)
main_image_url = match.group(1) if match else None
Albo pobierz główny tag obrazu:
img_tag = soup.find("img", {"id": "landingImage"})
img_url = img_tag['src'] if img_tag else None
Szczegóły produktu
Specyfikacje, takie jak marka, waga i wymiary, zwykle znajdują się w tabeli:
details = {}
rows = soup.select("#productDetails_techSpec_section_1 tr")
for row in rows:
header = row.find("th").get_text(strip=True)
value = row.find("td").get_text(strip=True)
details[header] = value
A jeśli Amazon używa formatu „detailBullets”:
bullets = soup.select("#detailBullets_feature_div li")
for li in bullets:
txt = li.get_text(" ", strip=True)
if ":" in txt:
key, val = txt.split(":", 1)
details[key.strip()] = val.strip()
Wypisz wyniki:
print("Tytuł:", product_title)
print("Cena:", price)
print("Ocena:", rating, "na podstawie", reviews_count, "recenzji")
print("Adres URL głównego obrazu:", main_image_url)
print("Szczegóły:", details)
Scrapowanie wielu produktów i obsługa paginacji
Jeden produkt to dobrze, ale pewnie potrzebujesz całej listy. Oto jak scrapować wyniki wyszukiwania i wiele stron.
Pobieranie linków do produktów ze strony wyszukiwania
search_url = "<https://www.amazon.com/s?k=bluetooth+headphones>"
res = requests.get(search_url, headers=headers)
soup = BeautifulSoup(res.text, "lxml")
product_links = []
for a in soup.select("h2 a.a-link-normal"):
href = a['href']
full_url = "<https://www.amazon.com>" + href
product_links.append(full_url)
Obsługa paginacji
Adresy wyszukiwania Amazona używają &page=2, &page=3 itd.
for page in range(1, 6): # scrapujemy pierwsze 5 stron
search_url = f"<https://www.amazon.com/s?k=bluetooth+headphones&page={page}>"
res = requests.get(search_url, headers=headers)
if res.status_code != 200:
break
soup = BeautifulSoup(res.text, "lxml")
# ... wyciągnij linki do produktów jak wyżej ...
Przechodzenie po stronach produktów i eksport do CSV
Zbieraj dane o produktach na liście słowników, a potem użyj pandas:
import pandas as pd
df = pd.DataFrame(product_data_list) # lista słowników
df.to_csv("amazon_products.csv", index=False)
Albo do Excela:
df.to_excel("amazon_products.xlsx", index=False)
Najlepsze praktyki dla projektów Amazon Scraper Python
Bądźmy szczerzy — Amazon ciągle zmienia stronę i walczy ze scraperami. Oto jak utrzymać projekt w działaniu:
- Rotuj nagłówki i User-Agenty (użyj biblioteki takiej jak
fake-useragent) - Korzystaj z proxy przy scrapingu na dużą skalę
- Ograniczaj tempo żądań (losowy
time.sleep()między żądaniami) - Obsługuj błędy łagodnie (ponawiaj po 503, wycofuj się, jeśli nastąpi blokada)
- Pisz elastyczną logikę parsowania (szukaj wielu selektorów dla każdego pola)
- Monitoruj zmiany HTML (jeśli skrypt nagle zwraca
Nonedla wszystkiego, sprawdź stronę) - Szanuj robots.txt (Amazon blokuje scraping wielu sekcji — scrapuj odpowiedzialnie)
- Czyść dane na bieżąco (usuwaj symbole walut, przecinki, białe znaki)
- Pozostań w kontakcie ze społecznością (fora, Stack Overflow, Reddit r/webscraping)
Lista kontrolna utrzymania scrapera:
- Rotuj User-Agenty i nagłówki
- Korzystaj z proxy przy skali
- Dodawaj losowe opóźnienia
- Modularyzuj kod, aby łatwo go aktualizować
- Monitoruj bany i CAPTCHA
- Regularnie eksportuj dane
- Dokumentuj selektory i logikę
Jeśli chcesz wejść głębiej, zajrzyj do mojego przewodnika po web scrapingu w Pythonie.
Alternatywa bez kodu: scraping Amazon z Thunderbit AI Web Scraper
Pobierz dane produktów z Amazona za pomocą AI Get Started Free
Dobrze, widziałeś już wersję w Pythonie. Ale co jeśli nie chcesz kodować — albo po prostu chcesz zdobyć dane w dwa kliknięcia i zająć się resztą życia? Wtedy wchodzi Thunderbit.
Thunderbit to rozszerzenie Chrome typu AI web scraper, które pozwala pobierać dane o produktach z Amazona (i dane praktycznie z każdej strony) bez kodowania. Oto dlaczego go lubię:
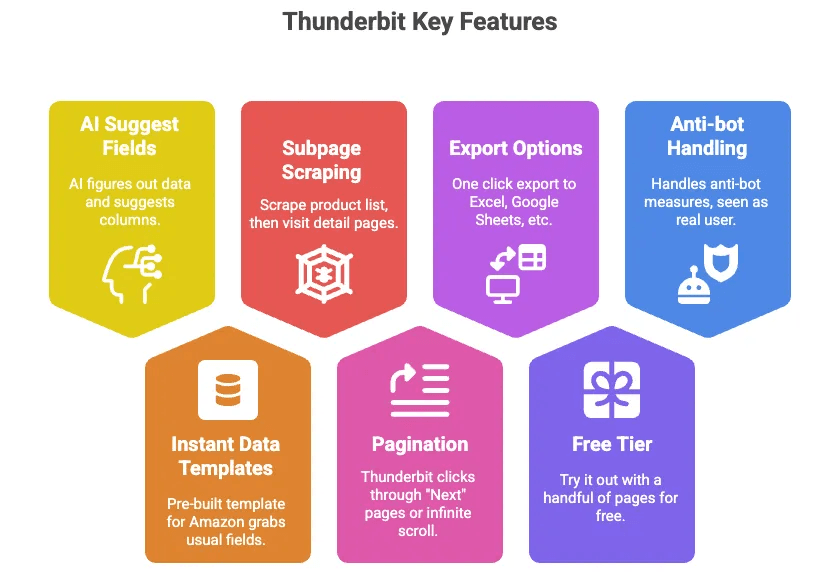
- AI Suggest Fields: Klikasz przycisk, a AI Thunderbit rozpoznaje, jakie dane są na stronie, i proponuje kolumny (np. Tytuł, Cena, Ocena itp.).
- Natychmiastowe szablony danych: Dla Amazona dostępny jest gotowy szablon, który pobiera wszystkie typowe pola — bez konfiguracji.
- Scraping podstron: Możesz zebrać listę produktów, a potem pozwolić Thunderbit odwiedzić stronę szczegółów każdego produktu i automatycznie pobrać więcej informacji.
- Paginacja: Thunderbit może sam klikać kolejne strony albo obsłużyć przewijanie nieskończone.
- Eksport do Excel, Google Sheets, Airtable, Notion: Jedno kliknięcie i dane są gotowe do użycia.
- Darmowy plan: Przetestujesz go za darmo na kilku stronach.
- Obsługa anty-bot za Ciebie: Ponieważ działa w przeglądarce (albo w chmurze), Amazon widzi go jak prawdziwego użytkownika.
Krok po kroku: jak używać Thunderbit do scrapowania danych o produktach z Amazona
To naprawdę proste:
-
Zainstaluj Thunderbit:
Pobierz rozszerzenie Thunderbit do Chrome i zaloguj się.
-
Otwórz Amazon:
Wejdź na stronę Amazona, którą chcesz scrapować (wyniki wyszukiwania, karta produktu, cokolwiek).
-
Kliknij „AI Suggest Fields” lub użyj szablonu:
Thunderbit zasugeruje kolumny do pobrania (albo możesz wybrać szablon Amazon Product).
-
Sprawdź kolumny:
W razie potrzeby dostosuj kolumny (dodaj/usuń pola, zmień nazwy itd.).
-
Kliknij „Scrape”:
Thunderbit pobierze dane ze strony i pokaże je w tabeli.
-
Obsłuż podstrony i paginację:
Jeśli scrapowałeś listę, kliknij „Scrape Subpages”, aby odwiedzić strony szczegółów każdego produktu i pobrać więcej informacji. Thunderbit może też automatycznie klikać kolejne strony.
-
Wyeksportuj dane:
Kliknij „Export to Excel” albo „Export to Google Sheets”. Gotowe.
-
(Opcjonalnie) Zaplanuj scraping:
Potrzebujesz tych danych codziennie? Użyj harmonogramu Thunderbit, aby to zautomatyzować.
To wszystko. Bez kodu, bez debugowania, bez proxy, bez bólu głowy. Jeśli chcesz zobaczyć to wizualnie, sprawdź kanał Thunderbit na YouTube albo stronę szablonu Amazon Product Scraper.
Wypróbuj szablon Amazon Product Scraper
Amazon Scraper Python vs. no-code web scraper: porównanie obok siebie
Złóżmy to wszystko w całość:
| Kryterium | Python Scraper | Thunderbit (bez kodu) |
|---|---|---|
| Czas konfiguracji | Wysoki (instalacja, kod, debugowanie) | Niski (instalacja rozszerzenia) |
| Wymagana wiedza | Konieczne kodowanie | Brak (wskaż i kliknij) |
| Elastyczność | Nieograniczona | Wysoka w typowych przypadkach użycia |
| Utrzymanie | Naprawiasz kod sam | Narzędzie aktualizuje się samo |
| Obsługa anty-bot | Sam ogarniasz proxy i nagłówki | Wbudowana, załatwiona za Ciebie |
| Skalowalność | Ręczna (wątki, proxy) | Scraping w chmurze, równoległy |
| Eksport danych | Niestandardowy (CSV, Excel, baza danych) | Jedno kliknięcie do Excela, Sheets |
| Koszt | Darmowy (Twój czas + proxy) | Freemium, płatne przy większej skali |
| Najlepsze dla | Deweloperzy, potrzeby niestandardowe | Użytkownicy biznesowi, szybkie efekty |
Jeśli jesteś deweloperem, który lubi grzebać w szczegółach i potrzebuje czegoś bardzo niestandardowego, Python będzie Twoim przyjacielem. Jeśli zależy Ci na szybkości, prostocie i zerowym kodowaniu, Thunderbit jest właściwym wyborem.
Kiedy wybrać Python, no-code albo AI web scraper do danych z Amazona
Wybierz Pythona, jeśli:
- Potrzebujesz logiki niestandardowej albo chcesz zintegrować scraping z systemami backendowymi
- Scrapujesz na bardzo dużą skalę (dziesiątki tysięcy produktów)
- Chcesz zrozumieć, jak działa scraping od środka
Wybierz Thunderbit (no-code, AI web scraper), jeśli:
- Chcesz szybko dostać dane, bez kodowania
- Jesteś użytkownikiem biznesowym, analitykiem albo marketerem
- Chcesz umożliwić swojemu zespołowi samodzielne pobieranie danych
- Chcesz uniknąć kłopotów z proxy, zabezpieczeniami anty-bot i utrzymaniem
Użyj obu, jeśli:
- Chcesz szybko zrobić prototyp w Thunderbit, a potem zbudować własne rozwiązanie w Pythonie do produkcji
- Chcesz wykorzystać Thunderbit do zbierania danych, a Python do czyszczenia i analizy danych
Dla większości użytkowników biznesowych Thunderbit pokryje 90% potrzeb związanych ze scrapingiem Amazona w ułamku czasu. Dla pozostałych 10% — tych superniestandardowych, wielkoskalowych albo mocno zintegrowanych — Python nadal jest królem.
Podsumowanie i najważniejsze wnioski
Jak w 2025 roku pobierać produkty i recenzje z Amazona z użyciem AI Get Started Free
Scraping danych o produktach z Amazona to supermoc dla każdego zespołu sprzedaży, e-commerce lub operacji. Niezależnie od tego, czy śledzisz ceny, analizujesz konkurencję, czy po prostu chcesz oszczędzić zespołowi niekończącego się kopiowania i wklejania, masz do dyspozycji odpowiednie rozwiązanie.
- Scraping w Pythonie daje pełną kontrolę, ale wiąże się z krzywą uczenia i bieżącym utrzymaniem.
- No-code web scrapery, takie jak Thunderbit, sprawiają, że pobieranie danych z Amazona jest dostępne dla każdego — bez kodowania, bez bólu głowy, po prostu wyniki.
- Najlepsze podejście? Użyj narzędzia, które pasuje do Twoich umiejętności, terminu i celów biznesowych.
Jeśli jesteś ciekawy, wypróbuj Thunderbit — start jest darmowy, a zdziwisz się, jak szybko możesz zdobyć potrzebne dane. A jeśli jesteś deweloperem, nie bój się mieszać podejść: czasem najszybszym sposobem budowy jest pozwolenie AI zrobić za Ciebie nudną część.
Pobierz rozszerzenie Thunderbit do Chrome
FAQ
1. Dlaczego firma chciałaby scrapować dane o produktach z Amazona?
Scraping Amazona pozwala firmom monitorować ceny, analizować konkurencję, zbierać recenzje do badań produktowych, prognozować popyt i generować leady sprzedażowe. Przy ponad 600 milionach produktów i niemal 2 milionach sprzedawców na Amazonie jest to bogate źródło analizy konkurencji.
2. Jakie są główne różnice między używaniem Pythona a narzędzi no-code, takich jak Thunderbit, do scrapowania Amazona?
Scrapery w Pythonie oferują maksymalną elastyczność, ale wymagają umiejętności kodowania, czasu na konfigurację i bieżącego utrzymania. Thunderbit, no-code AI web scraper, pozwala użytkownikom pobierać dane z Amazona natychmiast przez rozszerzenie Chrome — bez kodowania, z wbudowaną obsługą anty-bot i opcjami eksportu do Excela lub Sheets.
3. Czy scrapowanie danych z Amazona jest legalne?
Regulamin Amazona zazwyczaj zabrania scrapowania, a firma aktywnie stosuje zabezpieczenia anty-bot. Mimo to wiele firm nadal scrapuje publicznie dostępne dane, dbając o odpowiedzialne działanie, np. respektowanie limitów żądań i unikanie nadmiernego ruchu.
4. Jakie dane mogę wyodrębnić z Amazona za pomocą narzędzi do web scrapingu?
Typowe pola danych obejmują tytuły produktów, ceny, oceny, liczbę recenzji, obrazy, specyfikacje produktów, dostępność, a nawet informacje o sprzedawcach. Thunderbit obsługuje też scraping podstron i paginacji, aby zebrać dane z wielu ofert i stron.
5. Kiedy powinienem wybrać scraping w Pythonie zamiast narzędzia takiego jak Thunderbit — albo odwrotnie?
Wybierz Pythona, jeśli potrzebujesz pełnej kontroli, logiki niestandardowej lub planujesz zintegrować scraping z systemami backendowymi. Wybierz Thunderbit, jeśli chcesz szybkich rezultatów bez kodowania, potrzebujesz łatwego skalowania albo jesteś użytkownikiem biznesowym szukającym rozwiązania wymagającego niewielkiej obsługi.
Chcesz iść głębiej? Sprawdź te zasoby:
- Blog Thunderbit
- Czym jest data scraping i jak go zrobić w 2025 roku
- Jak w 2025 roku pobierać produkty i recenzje z Amazona z użyciem AI
- Przewodnik po web scrapingu w Pythonie
Miłego scrapowania — i niech Twoje arkusze zawsze będą aktualne.
Wypróbuj AI Web Scraper Thunderbit do Amazona Get Started Free




