Tumblr Webscraper
Vertrouwd door professionals bij toonaangevende bedrijven














Ontgrendel Tumblr-gegevens met Thunderbit
Extraheer moeiteloos Tumblr-gegevens zoals postinhoud en like-aantallen.
Krijg het volledige Tumblr-verhaal
Tumblr-overzichtspagina’s tonen alleen fragmenten. Voor het volledige beeld heb je de volledige postinhoud, auteurgegevens en alle bijbehorende data nodig. Thunderbit bezoekt automatisch elke gelinkte subpagina, haalt de details op en voegt ze toe als nieuwe kolommen, zodat je eenvoudig post_id, post_date en meer kunt verzamelen zonder handmatig te klikken.
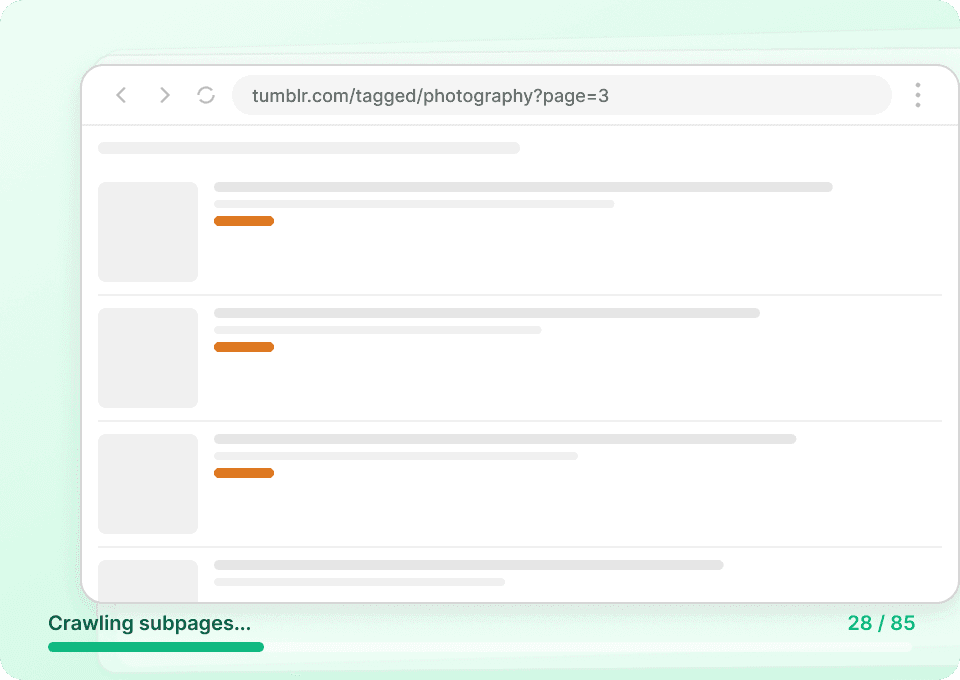
Automatiseer je Tumblr-dataverzameling
Tumblr-gegevens veranderen voortdurend. Dezelfde blogs steeds opnieuw handmatig scrapen is tijdrovend. Met Thunderbit’s geplande scraping stel je terugkerende taken in op de automatische piloot. Ontvang verse data zoals like_count en post_content direct in Google Sheets, zonder er omkijken naar te hebben.
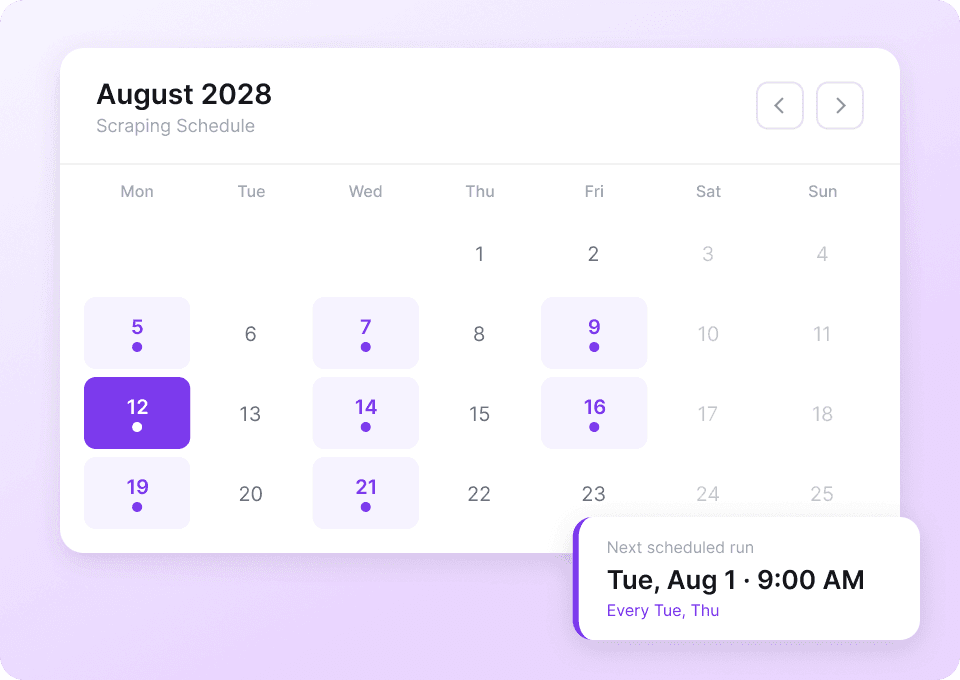
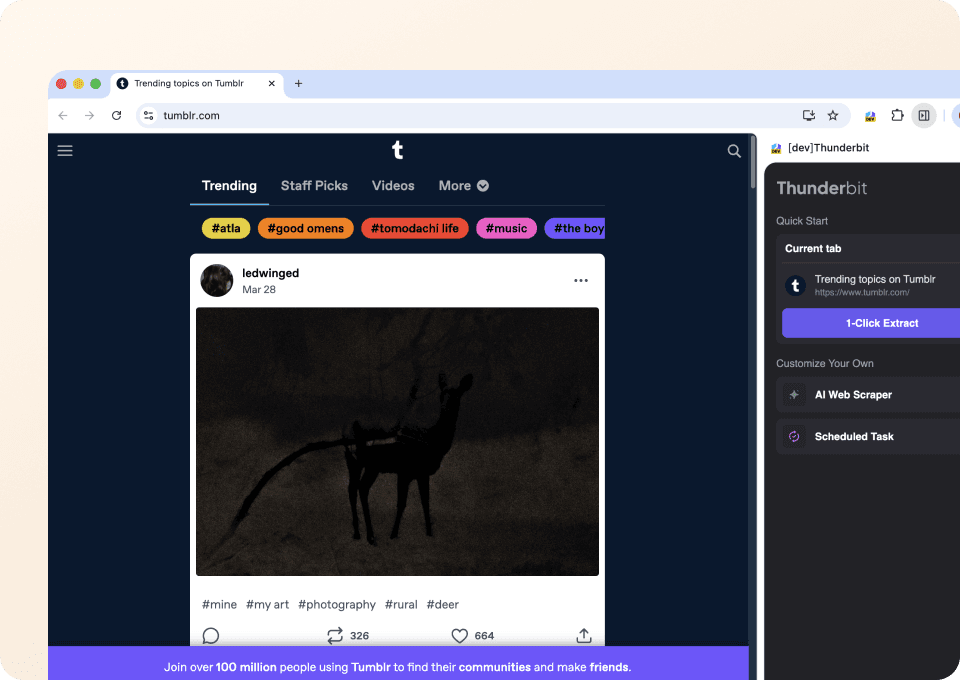
Scrape Tumblr-posts in twee klikken
Vergeet ingewikkelde code of CSS-selectors. Met Thunderbit haal je Tumblr-gegevens in slechts twee klikken op. Wijs simpelweg aan wat je wilt hebben, en Thunderbit’s semantische AI herkent de relevante velden (zoals post_type en post_author) en extraheert ze. Geen code nodig om de data van Tumblr te krijgen die je zoekt.
Waarom is Thunderbit anders dan traditionele tumblr scrapers?
Extraheer Tumblr-gegevens moeiteloos, zelfs wanneer lay-outs verschuiven of onverwacht veranderen.
Traditionele scrapers
De oude manier van werkenThunderbit AI
De slimmere aanpakNeem niet alleen ons woord ervoor
Zie wat onze gebruikers over Thunderbit zeggen.







Veelgestelde vragen
Gerelateerd use cases
Ontdek meer use cases van Thunderbit's webscraper.

Rakuten Travel Webscraper
Met de Thunderbit Rakuten Travel Webscraper kun je moeiteloos gegevens verzamelen van hotelvermeldingen en detailpagina’s op Rakuten Travel. Dankzij AI-gestuurde veldsuggesties verzamel je snel hotelnamen, prijzen, beoordelingen, kamertypes en voorzieningen – ideaal voor onderzoek of reisplanning. Perfect voor reisagenten, onderzoekers en bedrijven die gestructureerde reisdata nodig hebben.
Meer leren ->Tradera Webscraper
Met de Thunderbit Tradera Webscraper kun je eenvoudig gegevens verzamelen van Tradera-advertenties en productpagina’s. Dankzij AI-gestuurde veldsuggesties haal je moeiteloos productnamen, prijzen, categorieën, afbeeldingen en beschrijvingen op voor analyse of voorraadbeheer. Ideaal voor e-commerce verkopers, verzamelaars en onderzoekers die gestructureerde Tradera-data willen verzamelen.
Meer leren ->
Amarillas.com Webscraper
Met de Thunderbit Amarillas.com-webscraper kun je gestructureerde data van Amarillas.com verzamelen, zoals motels en restaurantvermeldingen. Dankzij AI-gestuurde veldsuggesties verzamel je razendsnel bedrijfsnamen, locaties, telefoonnummers, beoordelingen en reviews voor onderzoek, marketing of leadgeneratie.
Meer leren ->On the Beach Webscraper
Met de Thunderbit On the Beach Webscraper haal je moeiteloos vakantie- en hoteloverzichten, prijzen, beoordelingen en meer van On the Beach binnen, allemaal in slechts twee klikken. Dankzij AI-gestuurde veldsuggesties verzamel en orden je snel reisinformatie voor analyse, vergelijking of reisplanning. Perfect voor reisprofessionals, analisten en vakantieplanners.
Meer leren ->PeopleWhiz-scraper
Met de Thunderbit PeopleWhiz-scraper kun je met AI-gestuurde veldsuggesties gegevens uit PeopleWhiz-zoekresultaten en profielen halen. Verzamel namen, contactgegevens, locaties en meer voor onderzoek, marketing of leadgeneratie. Zet PeopleWhiz-data snel en efficiënt om in gestructureerde datasets.
Meer leren ->
White Pages Webscraper
Met de Thunderbit White Pages-scraper kun je moeiteloos gegevens uit White Pages-telefoon- en bedrijfsvermeldingen halen dankzij AI-gestuurde veldsuggesties. Verzamel snel namen, telefoonnummers, adressen en website-URL’s voor leadgeneratie, marketing of onderzoek – allemaal in een paar klikken.
Meer leren ->Klaar om je data-extractie een boost te geven?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
De gratis proefperiode biedt onbeperkte credits voor 8 webpagina's.