
De Reddit Post Webscraper is een krachtig hulpmiddel om uitgebreide informatie uit Reddit-berichten te halen. Met deze kant-en-klare scraper verzamel je moeiteloos data zoals posttitels, gebruikersnamen, communitydetails en betrokkenheidsstatistieken zoals het aantal reacties en upvotes.
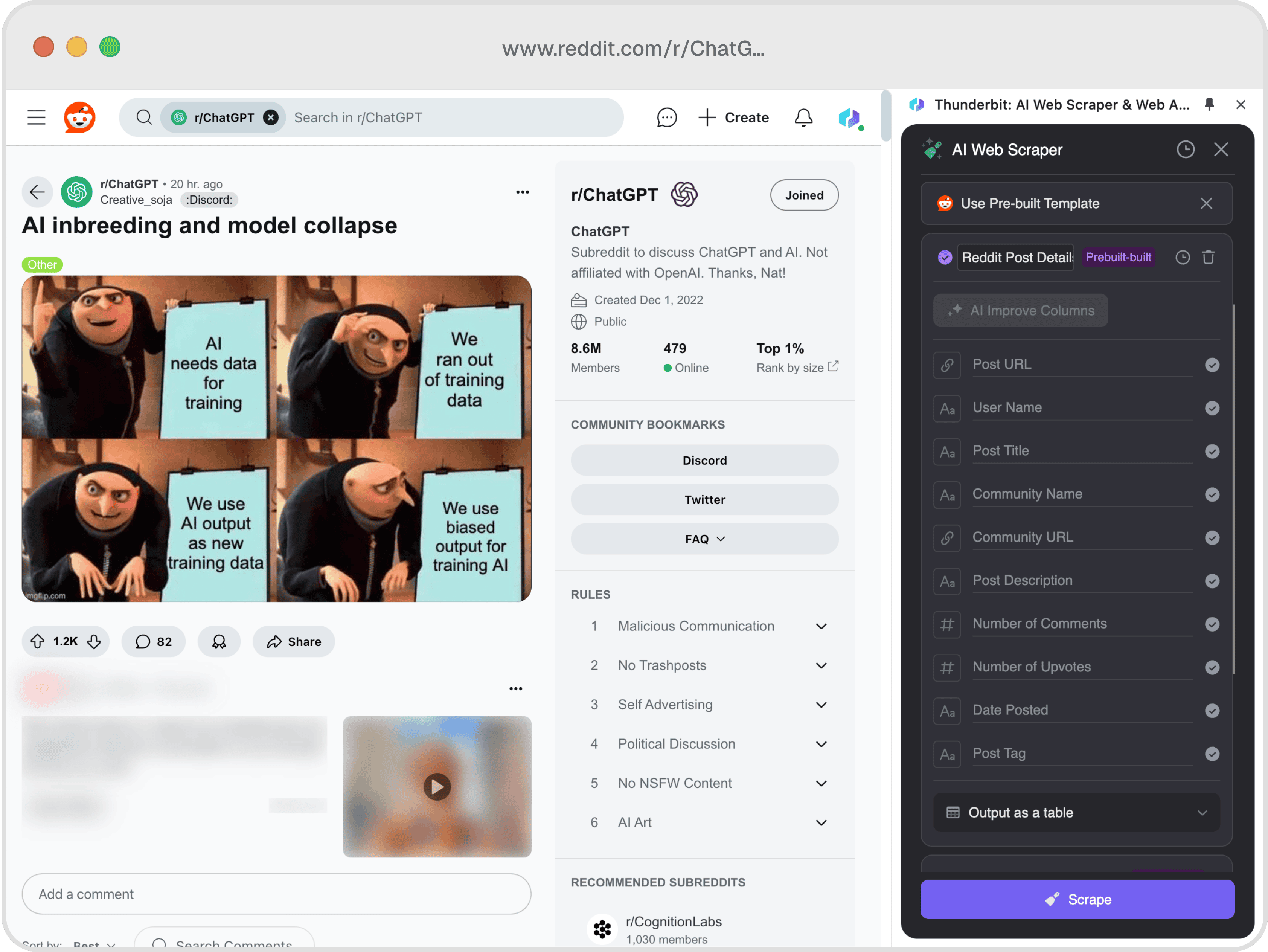
📊 Uitleg van de kolommen
| Kolom | Beschrijving |
|---|---|
| 🔗 Post URL | De directe link naar het Reddit-bericht. |
| 👤 Gebruikersnaam | De gebruikersnaam van degene die het bericht heeft geplaatst. |
| 📝 Posttitel | De titel van het Reddit-bericht. |
| 🌐 Communitynaam | De naam van de subreddit waar het bericht is geplaatst. |
| 🔗 Community URL | De URL van de subreddit. |
| 📝 Postbeschrijving | De inhoud of omschrijving van het bericht. |
| 💬 Aantal reacties | Het totale aantal reacties op het bericht. |
| 👍 Aantal upvotes | Het totale aantal upvotes dat het bericht heeft ontvangen. |
| 📅 Datum geplaatst | De datum waarop het bericht is gepubliceerd. |
| 🏷️ Post tag | Eventuele tags die aan het bericht zijn gekoppeld. |
🤔 Waarom Reddit scrapen?
Reddit scrapen biedt waardevolle kansen voor professionals in verschillende sectoren:
- Marketeers: Analyseer trends, volg consumentensentiment en ontdek opkomende onderwerpen om marketingstrategieën te verbeteren.
- Onderzoekers: Verzamel grote datasets voor onderzoek, analyseer publieke opinies en verken discussies over niche-onderwerpen voor academisch of zakelijk onderzoek.
- Contentmakers: Vind inspiratie, krijg inzicht in de voorkeuren van je doelgroep en verzamel ideeën op basis van populaire discussies en trends.
- Productontwikkelaars: Ontdek feedback van gebruikers, knelpunten en wensen om producten of diensten te verbeteren.
- Social media-analisten: Houd subreddit-activiteit in de gaten om merkvermeldingen, concurrenten of communitybetrokkenheid te monitoren.
Door Reddit te scrapen kun je efficiënt data verzamelen en analyseren, zodat je beter onderbouwde beslissingen kunt nemen en voorop blijft lopen. 🚀
🛠️ Zo gebruik je de Reddit Post Webscraper
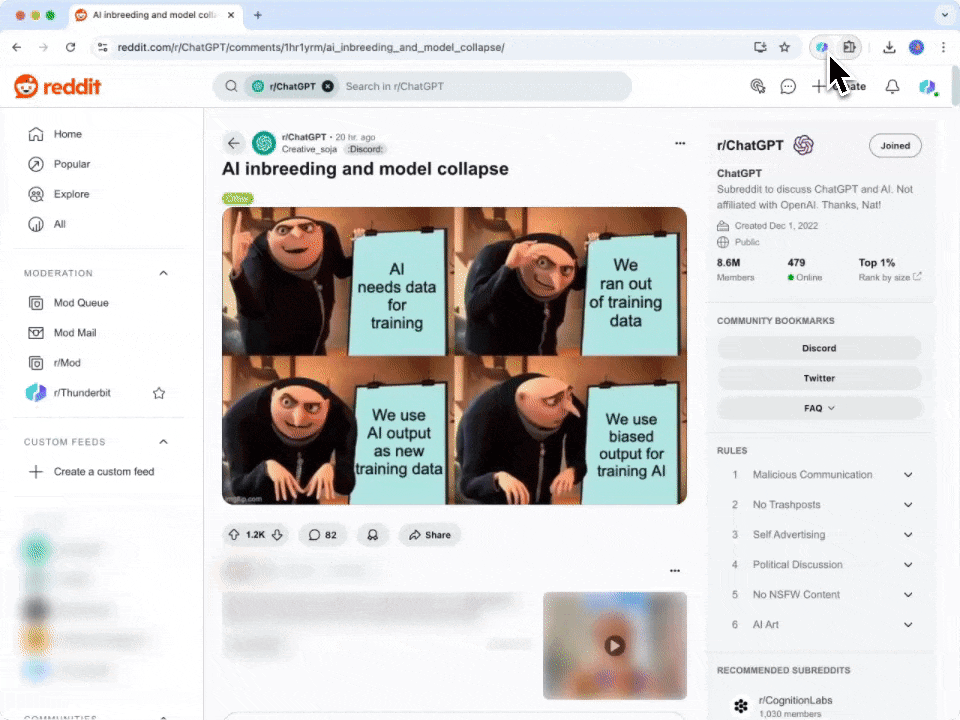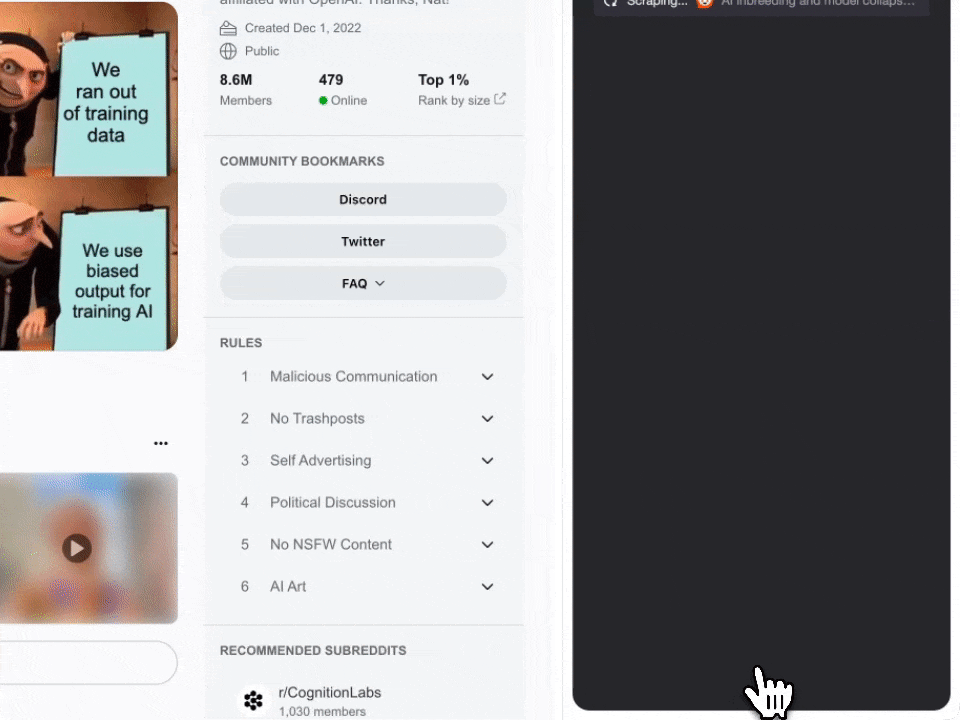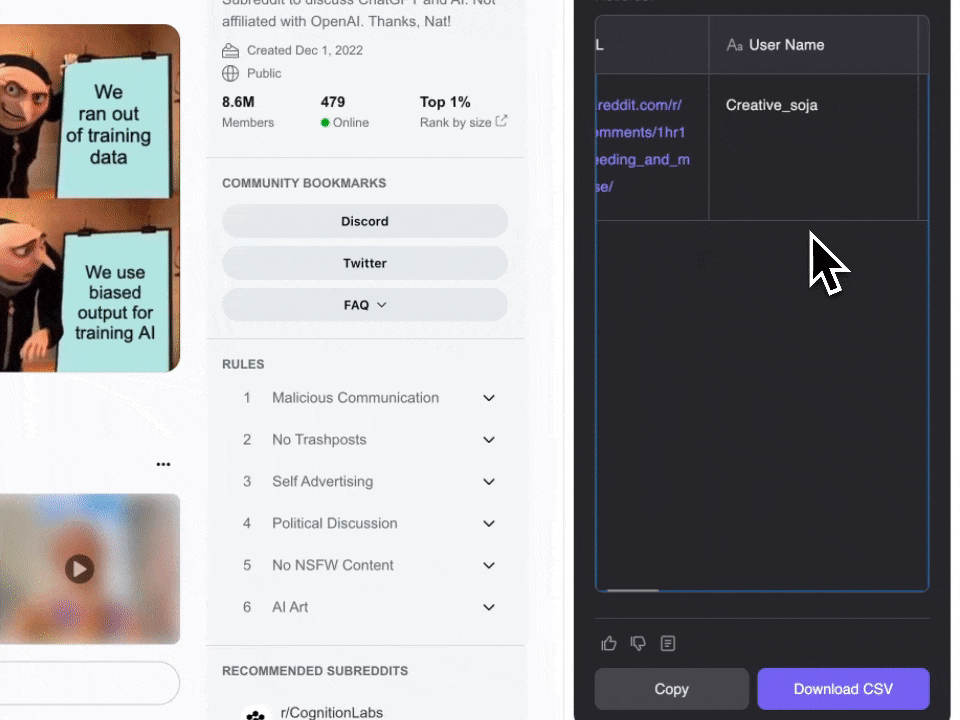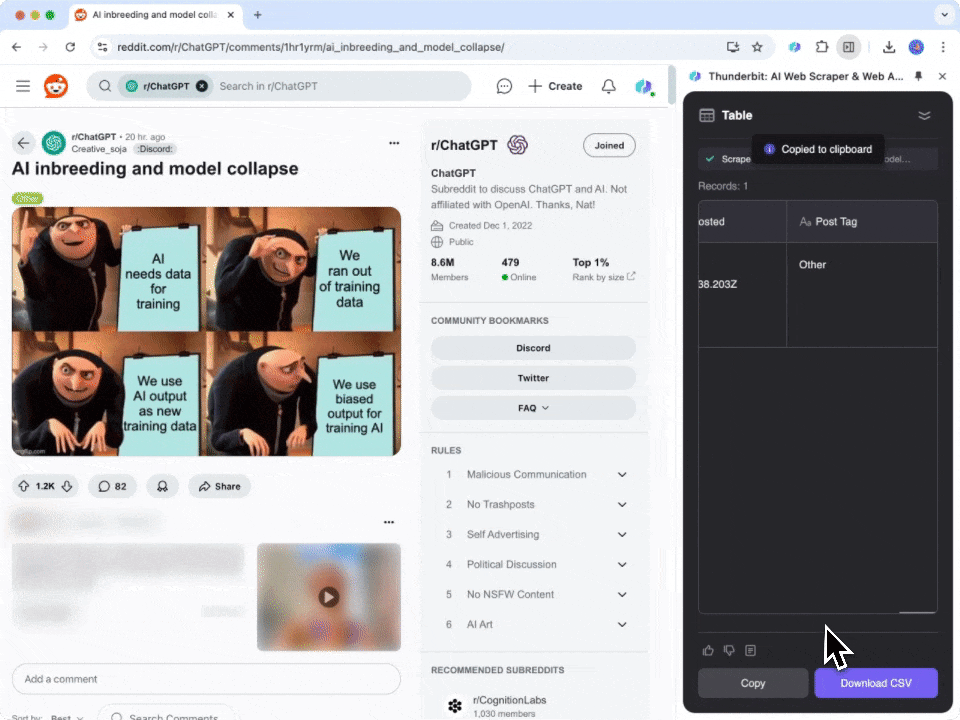
- Download en installeer: Download eerst de en maak een account aan.
- Ga naar Reddit: Navigeer naar de of subredditpagina die je wilt scrapen.
- Activeer de scraper: Er verschijnt een pop-up waarin je wordt gevraagd de kant-en-klare Reddit Post Webscraper te gebruiken. Klik om verder te gaan. Let op: deze functie is onderdeel van het betaalde abonnement, maar je kunt starten met een gratis proefperiode om alles uit te proberen.
💰 Kosten van de Reddit Post Webscraper
De Reddit Post Webscraper werkt met een creditsysteem: elke scrape kost 1 credit. Met de gratis proefperiode van Thunderbit kun je tot 10 pagina’s gratis scrapen. Eén credit staat gelijk aan één output-rij, waardoor je eenvoudig inzicht hebt in je kosten.
🤖 Reddit scrapen met AI
Met de kun je Reddit-data in slechts twee klikken verzamelen. Deze AI-tool biedt voordelen zoals automatische data-opmaak en categorisatie, ideaal voor wie snel gestructureerde data nodig heeft. In tegenstelling tot de vaste scraper past de AI-webscraper zich aan verschillende datastructuren aan, wat zorgt voor meer flexibiliteit en gebruiksgemak.
❓ Veelgestelde vragen
- Wat is een kant-en-klare webscraper?
Een kant-en-klare webscraper is een gebruiksklare tool die ontworpen is om specifieke data van websites te halen, zonder dat je zelf iets hoeft in te stellen. Het maakt het verzamelen van data eenvoudig, omdat je direct aan de slag kunt zonder technische kennis of programmeervaardigheden. - Wat is Thunderbit?
Thunderbit is een Chrome-extensie waarmee je webtaken zoals data scrapen, formulieren invullen en content samenvatten kunt automatiseren met behulp van AI. Het is ontwikkeld om je productiviteit te verhogen door tijd te besparen op repetitieve online taken, en biedt een soepele, efficiënte en gebruiksvriendelijke ervaring voor zowel beginners als professionals. - Hoe werkt de Reddit Post Webscraper?
De Reddit Post Webscraper gebruikt een vooraf ingestelde template om data uit Reddit-berichten te halen. Je navigeert simpelweg naar de gewenste Reddit-pagina en de scraper verzamelt automatisch de benodigde informatie, zodat je niet handmatig hoeft te kopiëren en plakken. - Kan ik de Reddit Post Webscraper gratis gebruiken?
Ja, Thunderbit biedt een gratis proefperiode waarmee je tot 10 pagina’s kunt scrapen zonder kosten. Zo kun je risicoloos kennismaken met de mogelijkheden. Na de proefperiode heb je een abonnement nodig om onbeperkt data te blijven scrapen. - Welke data kan ik met de Reddit Post Webscraper verzamelen?
Je kunt onder andere posttitels, gebruikersnamen, communitydetails, aantal reacties, upvotes en meer verzamelen. Deze uitgebreide data is bruikbaar voor analyses, onderzoek of contentcreatie. - Is de data die de Reddit Post Webscraper verzamelt accuraat?
Ja, de scraper is ontworpen om data nauwkeurig te verzamelen volgens de ingestelde template. Je kunt rekenen op betrouwbare en consistente resultaten voor al je data-extractiebehoeften. - Hoe beheer ik mijn credits in Thunderbit?
Credits bepalen hoeveel data je kunt scrapen. Elke run van de Reddit Post Webscraper kost 1 credit. Je beheert je credits eenvoudig via je Thunderbit-dashboard, waar je je gebruik kunt volgen, extra credits kunt kopen en je scraping-taken kunt plannen. - Kan ik de datavelden van de Reddit Post Webscraper aanpassen?
De kant-en-klare scraper heeft een vaste set datavelden voor de meest voorkomende toepassingen. Heb je meer maatwerk nodig? Gebruik dan de AI-webscraper van Thunderbit, waarmee je zelf kunt bepalen welke data je wilt verzamelen, helemaal afgestemd op jouw wensen.
📚 Meer weten
Wil je meer ontdekken over Thunderbit en alle mogelijkheden? Bezoek de of bekijk het voor tutorials en tips.