Nieuws Webscraper














Nieuwsdata sneller vastgelegd
Haal schone nieuwsdata uit artikelen, overzichten en bronnen zonder het handmatige gedoe.
Krijg alle details van het volledige artikel
Overzichtspagina's van nieuws geven je vaak alleen een teaser. Thunderbit bezoekt de volledige pagina van elk artikel en haalt alles op wat ertoe doet — kop, samenvatting, auteur, publicatiedatum, nieuwsbron en sectie. Ga van een kale lijst met links naar een complete, gestructureerde dataset zonder het tijdrovende handwerk.
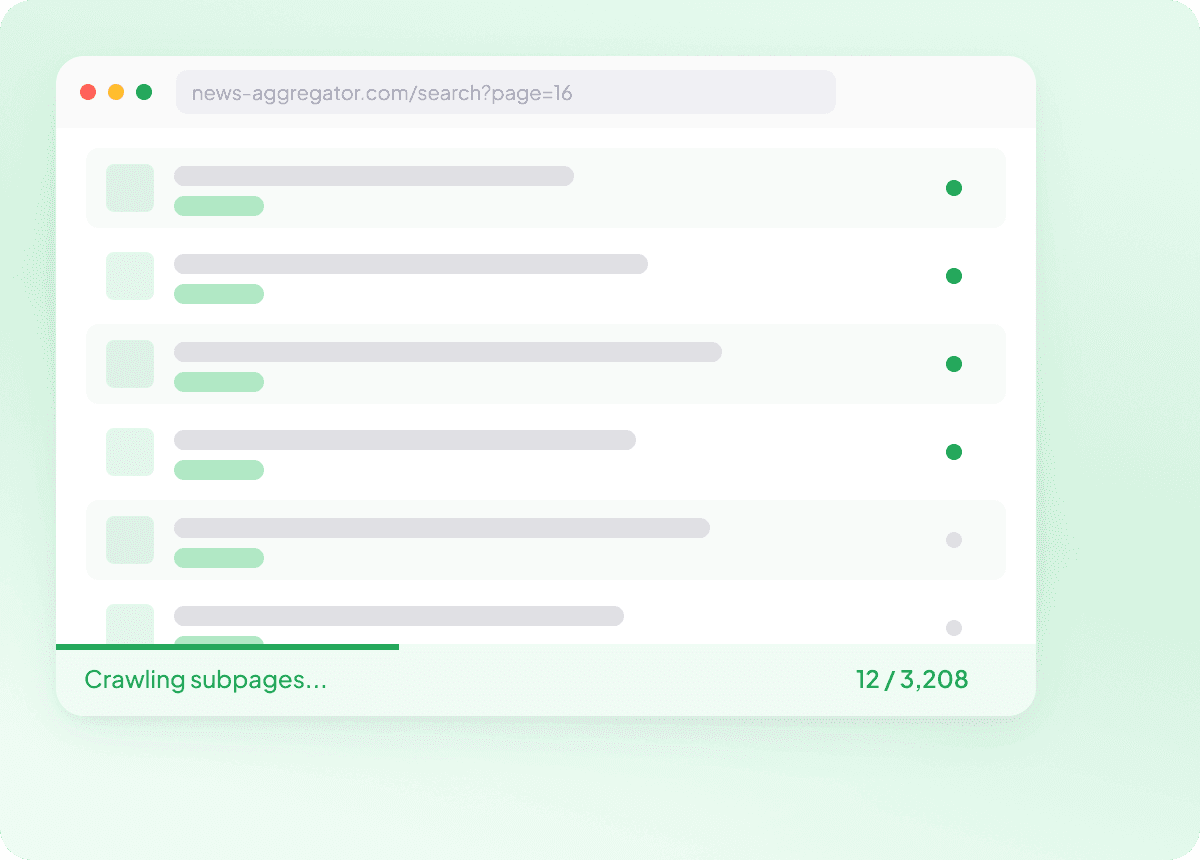
Scrape nieuws-URL-lijsten in bulk
Eén artikel per keer scrapen is geen workflow — het is een klus. Plak een lijst met artikel-URL's en Thunderbit scrape in één run honderden pagina's tegelijk, waarbij elk veld wordt vastgelegd dat je nodig hebt voor elk verhaal. Grote nieuwsdatabestanden verzamelen is nog nooit zo eenvoudig geweest.

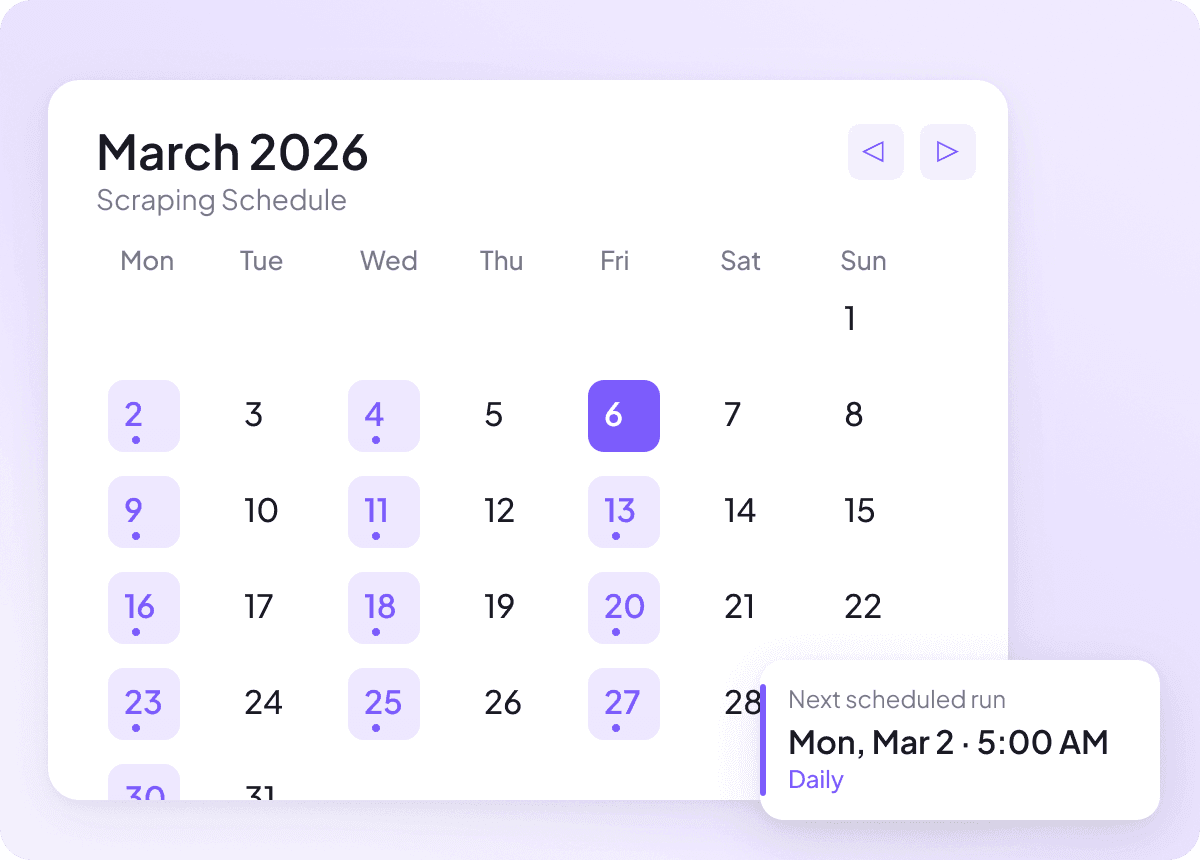
Houd nieuwsdata actueel
Nieuws verandert snel, en data van gisteren verliest al snel waarde. Plan je scrape in en Thunderbit draait automatisch — zodat je spreadsheet altijd gevuld blijft met verse koppen, samenvattingen, auteurs, publicatiedata, bronnen en secties, precies volgens jouw ritme. Terugkerende updates, zonder handmatige moeite.
Waarom is Thunderbit anders dan traditionele nieuws-scrapers?
Een snellere manier om rommelige nieuwsdata te verzamelen zonder dat het voortdurend stukgaat.
Traditionele scrapers
De oude manier van werkenThunderbit AI
De slimmere aanpakNeem niet alleen ons woord ervoor
Bekijk wat onze gebruikers over Thunderbit zeggen.







Veelgestelde vragen
Gerelateerd use cases
Ontdek meer toepassingen van Thunderbit's webscraper.
On the Beach Webscraper
Met de Thunderbit On the Beach Webscraper haal je moeiteloos vakantie- en hoteloverzichten, prijzen, beoordelingen en meer van On the Beach binnen, allemaal in slechts twee klikken. Dankzij AI-gestuurde veldsuggesties verzamel en orden je snel reisinformatie voor analyse, vergelijking of reisplanning. Perfect voor reisprofessionals, analisten en vakantieplanners.
Meer info ->
Herold Webscraper
Met de Thunderbit Herold Webscraper haal je in slechts twee klikken gegevens uit de bedrijfs- en persoonszoekresultaten van Herold. Dankzij AI-gestuurde veldsuggesties verzamel je moeiteloos bedrijfsnamen, adressen, telefoonnummers, e-mailadressen en meer voor leadgeneratie, onderzoek of marketing. Perfect voor sales, marketing en onderzoekers die gestructureerde Herold-data willen verzamelen.
Meer info ->
UNIQLO Webscraper
Haal Uniqlo-productnamen, prijzen, kleuren en maten in 2 klikken op met Thunderbit’s AI-gestuurde Chrome-extensie. Exporteer direct naar Google Sheets, Excel of Notion en houd je productonderzoek altijd actueel.
Meer info ->
HKTVmall Webscraper
Haal productnamen, prijzen, beoordelingen en meer uit HKTVmall-vermeldingen in 2 klikken — zonder te coderen. Exporteer direct naar Excel, Google Sheets of Notion en zet HKTVmall-data om in bruikbare inzichten.
Meer info ->
ReverseAustralia Webscraper
Met de Thunderbit ReverseAustralia-webscraper kun je eenvoudig gegevens verzamelen van klacht- en reactiepagina's op ReverseAustralia. Dankzij AI-gestuurde veldsuggesties verzamel je razendsnel telefoonnummers, klachtomschrijvingen, reacties, gebruikersnamen en meer voor analyse of onderzoek. Perfect voor marketeers, onderzoekers en bedrijven die gestructureerde feedbackdata zoeken.
Meer info ->
People-Search Webscraper
Met de Thunderbit People-Search Webscraper kun je gestructureerde data verzamelen van People-Search profielen en reverse phone lookup pagina’s. Dankzij AI-gestuurde veldsuggesties verzamel je razendsnel namen, locaties, telefoonnummers, e-mails en meer – ideaal voor onderzoek, marketing of leadgeneratie. Perfect voor marketeers, onderzoekers en bedrijven die op zoek zijn naar openbare gegevens en contactinformatie.
Meer info ->Klaar om je data-extractie een boost te geven?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
De gratis proefversie biedt onbeperkte credits voor 8 webpagina's.



