IDCrawl-scraper
Vertrouwd door professionals bij toonaangevende bedrijven














Idcrawl-gegevens die bruikbaar blijven
Gebruik idcrawl om sneller, schoner en op grotere schaal gegevens te extraheren met Thunderbit.
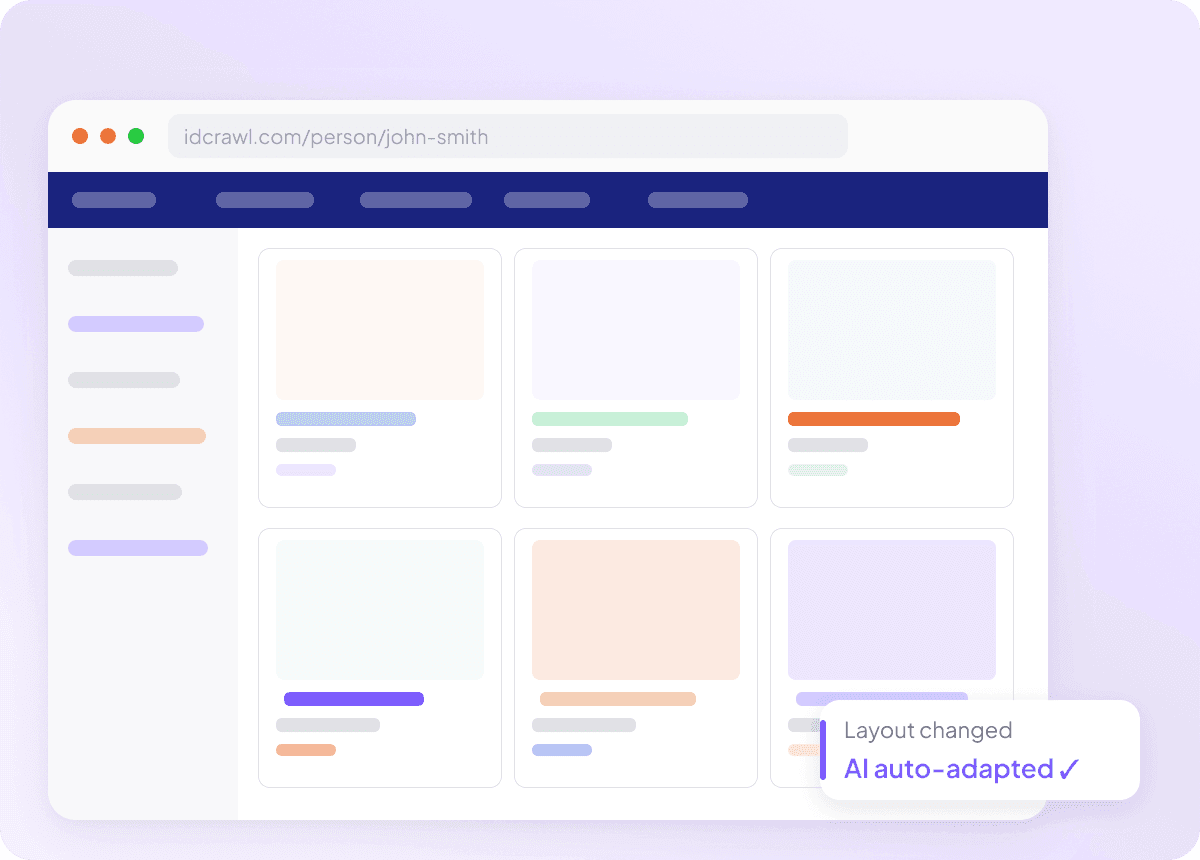
Past zich aan wanneer Idcrawl verandert
Scrapers die na elke site-update stukgaan zijn nutteloos, vooral als je volledige naam, functietitel, bedrijfsnaam, e-mailadres, telefoonnummer en LinkedIn-profiel van idcrawl wilt halen. Thunderbit leest de pagina op basis van betekenis, niet van vaste selectors, waardoor het kan meebewegen als de lay-out verandert. Je besteedt minder tijd aan het repareren van scrapers en meer tijd aan het binnenhalen van de data die je nodig hebt.
Schone data vanaf het begin
Ruwe data is pas het begin van het echte werk, en idcrawl-resultaten moeten vaak eerst worden opgeschoond voordat ze bruikbaar zijn. Thunderbit structureert en formatteert de data tijdens het extraheren, zodat wat je exporteert al schoon en direct bruikbaar is. Dat betekent minder sorteren, minder nabewerking en een soepelere overdracht aan je team.
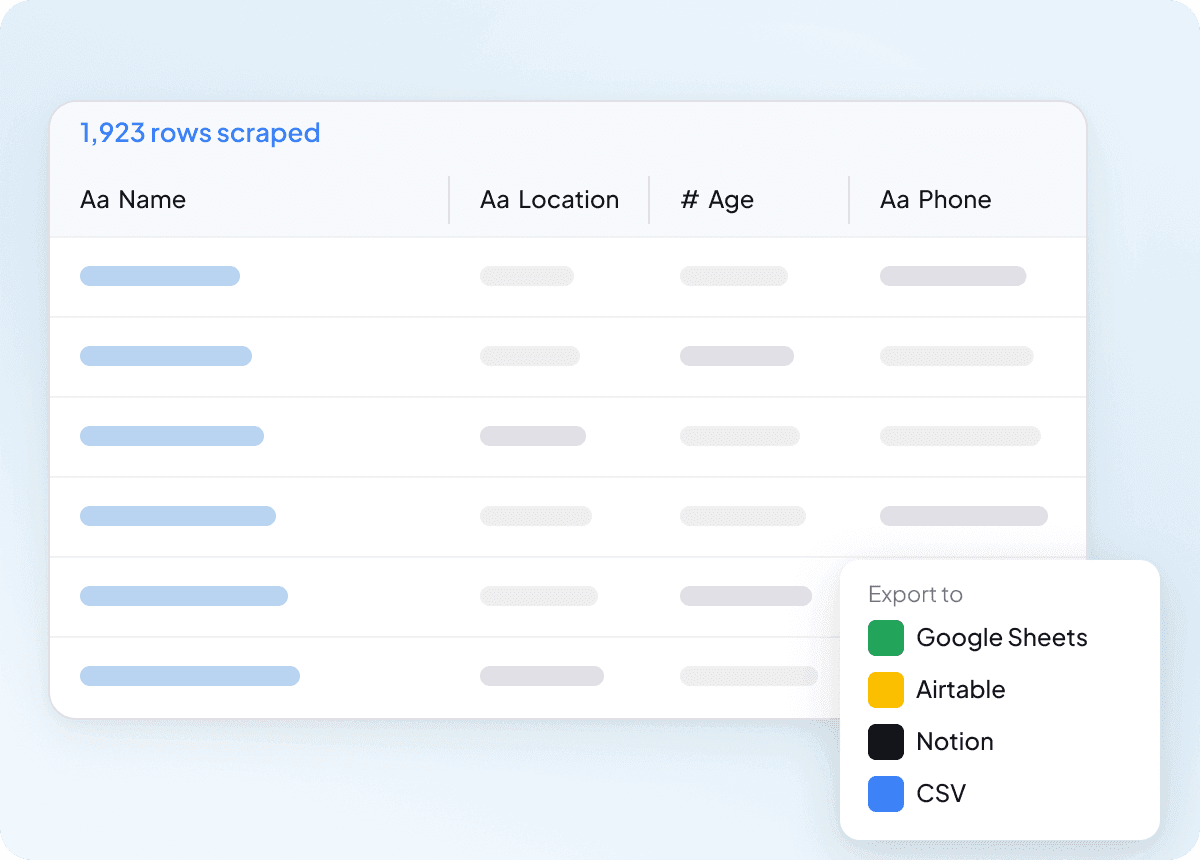
Scrape Idcrawl in bulk in één keer
Één idcrawl-pagina tegelijk scrapen schaalt niet als je een lange lijst met contacten nodig hebt. Thunderbit kan honderden pagina’s in één keer in bulk scrapen, zodat je het een lijst met URL’s kunt geven en daar volledige namen, functietitels, bedrijfsnamen, e-mailadressen, telefoonnummers en LinkedIn-profielen uit kunt halen. Het is een veel eenvoudigere manier om een grote lijst om te zetten in bruikbare data.

Waarom is Thunderbit anders dan traditionele idcrawl scrapers?
Een eenvoudigere manier om idcrawl-gegevens te extraheren zonder constante fixes.
Traditionele scrapers
De oude manier van werkenThunderbit AI
De slimmere aanpakNeem niet alleen ons woord ervoor
Zie wat onze gebruikers over Thunderbit zeggen.







Veelgestelde vragen
Gerelateerd use cases
Ontdek meer use cases van Thunderbit's webscraper.
PeopleWhiz-scraper
Met de Thunderbit PeopleWhiz-scraper kun je met AI-gestuurde veldsuggesties gegevens uit PeopleWhiz-zoekresultaten en profielen halen. Verzamel namen, contactgegevens, locaties en meer voor onderzoek, marketing of leadgeneratie. Zet PeopleWhiz-data snel en efficiënt om in gestructureerde datasets.
Meer leren ->
BestPrice GR Webscraper
Met de AI-gedreven BestPrice GR Webscraper van Thunderbit haal je eenvoudig productoverzichten, prijzen en uitgebreide productinformatie van BestPrice.gr binnen. Ideaal voor sales-, marketing- en e-commerce teams die snel en efficiënt gestructureerde data willen verzamelen.
Meer leren ->Tradera Webscraper
Met de Thunderbit Tradera Webscraper kun je eenvoudig gegevens verzamelen van Tradera-advertenties en productpagina’s. Dankzij AI-gestuurde veldsuggesties haal je moeiteloos productnamen, prijzen, categorieën, afbeeldingen en beschrijvingen op voor analyse of voorraadbeheer. Ideaal voor e-commerce verkopers, verzamelaars en onderzoekers die gestructureerde Tradera-data willen verzamelen.
Meer leren ->
White Pages Webscraper
Met de Thunderbit White Pages-scraper kun je moeiteloos gegevens uit White Pages-telefoon- en bedrijfsvermeldingen halen dankzij AI-gestuurde veldsuggesties. Verzamel snel namen, telefoonnummers, adressen en website-URL’s voor leadgeneratie, marketing of onderzoek – allemaal in een paar klikken.
Meer leren ->
Rakuten Travel Webscraper
Met de Thunderbit Rakuten Travel Webscraper kun je moeiteloos gegevens verzamelen van hotelvermeldingen en detailpagina’s op Rakuten Travel. Dankzij AI-gestuurde veldsuggesties verzamel je snel hotelnamen, prijzen, beoordelingen, kamertypes en voorzieningen – ideaal voor onderzoek of reisplanning. Perfect voor reisagenten, onderzoekers en bedrijven die gestructureerde reisdata nodig hebben.
Meer leren ->On the Beach Webscraper
Met de Thunderbit On the Beach Webscraper haal je moeiteloos vakantie- en hoteloverzichten, prijzen, beoordelingen en meer van On the Beach binnen, allemaal in slechts twee klikken. Dankzij AI-gestuurde veldsuggesties verzamel en orden je snel reisinformatie voor analyse, vergelijking of reisplanning. Perfect voor reisprofessionals, analisten en vakantieplanners.
Meer leren ->Klaar om je data-extractie een boost te geven?
Sluit je aan bij meer dan 100.000 professionals die Thunderbit al gebruiken om hun webscraping-workflows te automatiseren.
De gratis proefperiode biedt onbeperkte credits voor 8 webpagina's.