

Webscraping is tegenwoordig niet meer weg te denken voor bedrijven die vooruit willen. Of je nu in sales, operations of marketing zit: snel en slim data van het web halen kan echt het verschil maken voor je volgende project. Nu datagedreven werken steeds belangrijker wordt, zoeken organisaties naar tools die niet alleen razendsnel zijn, maar ook betrouwbaar en makkelijk op te schalen. Hier komt Rust om de hoek kijken: een moderne programmeertaal die steeds meer terrein wint bij webscraping, vooral bij teams die hoge eisen stellen aan snelheid én veiligheid.
Het is niet zomaar een trend—Rust wordt al jaren uitgeroepen tot de "meest geliefde programmeertaal" in de Stack Overflow Developer Survey, en het gebruik ervan in backend- en data-engineering groeit als kool. Maar wat betekent webscraping in Rust nu concreet voor bedrijven? En hoe verhoudt het zich tot no-code oplossingen zoals Thunderbit, die juist zijn gemaakt voor teams zonder technische achtergrond? We leggen het uit in heldere taal—je hoeft geen programmeur te zijn om het te snappen.
Wat is webscraping met Rust? De basics
Heel simpel gezegd is webscraping het automatisch verzamelen van data van websites. Zie het als een digitale assistent die honderden of duizenden webpagina’s afstruint, de info die jij nodig hebt—zoals prijzen, contactgegevens of reviews—kopieert en alles netjes gestructureerd terugbrengt. Dit bespaart bedrijven enorm veel tijd bij bijvoorbeeld leadgeneratie, marktonderzoek of prijsvergelijkingen.
Rust is een programmeertaal die bekend staat om zijn snelheid, geheugenveiligheid en betrouwbaarheid. In tegenstelling tot oudere talen die gevoelig zijn voor bugs of traagheid, is Rust zo ontworpen dat fouten al worden opgemerkt voordat je code überhaupt draait. Voor webscraping betekent dit dat je tools kunt bouwen die supersnel zijn en minder snel crashen of last hebben van geheugenlekken—ideaal als je grote hoeveelheden data wilt binnenhalen.
En het mooie is: hoewel Rust vooral populair is bij developers, profiteren zakelijke gebruikers er ook van. Snellere en veiligere scraping betekent actuelere data, minder fouten en betrouwbaardere inzichten voor je team.
Waarom kiezen voor Rust bij webscraping? De voordelen voor bedrijven
Waarom stappen steeds meer teams over op Rust voor webscraping, terwijl Python en JavaScript jarenlang de standaard waren? De belangrijkste voordelen op een rijtje:
- Supersnel: Rust wordt direct naar machinecode gecompileerd en is daardoor veel sneller dan bijvoorbeeld Python of JavaScript. Bij grootschalige scraping—denk aan miljoenen pagina’s—levert die snelheid direct voordeel op.
- Geheugenveilig: Dankzij Rust’s unieke geheugenbeheer (geen garbage collector, strikte eigendomsregels) heb je minder last van bugs en crashes. Je scraping-taken lopen minder snel vast, wat tijd en frustratie scheelt.
- Betrouwbaar: De compiler van Rust dwingt strikte typechecks en foutafhandeling af, waardoor veel problemen al worden opgemerkt voordat je code draait. Dit zorgt voor stabielere en voorspelbare scraping-processen.
- Concurrency: Rust maakt het makkelijker om code te schrijven die meerdere taken tegelijk uitvoert (hierover straks meer), wat essentieel is als je veel pagina’s parallel wilt scrapen.
Hoe verhoudt dit zich tot Python of JavaScript? Die talen zijn makkelijker om mee te starten, maar lopen bij grote projecten vaak tegen prestatie- en betrouwbaarheidsproblemen aan. Met Rust kun je sneller en met minder gedoe meer data verzamelen—en dat geeft je bedrijf een flinke voorsprong.
De kracht van asynchroon werken in Rust: efficiënt grootschalig scrapen
Hier blinkt Rust echt uit: asynchroon programmeren. Simpel gezegd: met async code kan je webscraper data van veel websites tegelijk ophalen, zonder te hoeven wachten tot elke pagina klaar is. Dit is een gamechanger als je snel grote datasets wilt verzamelen.
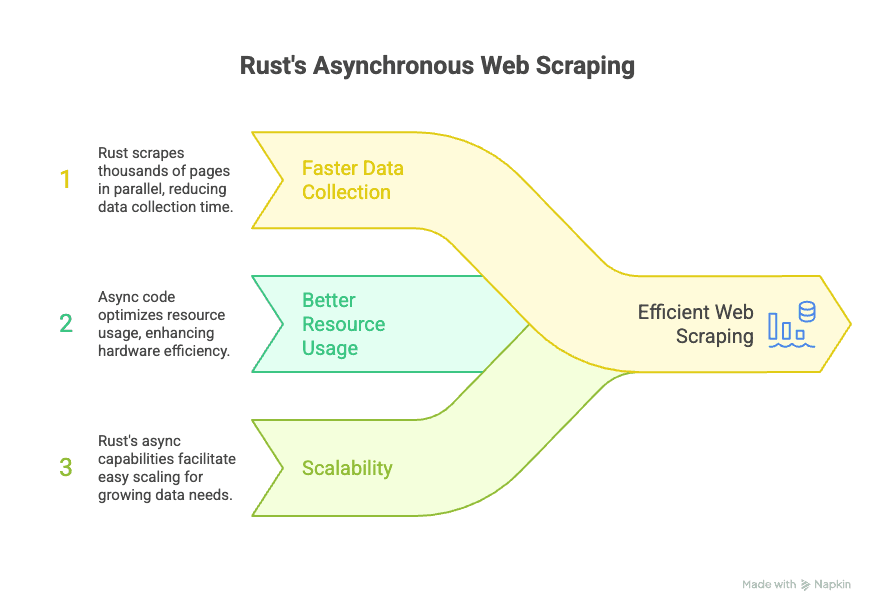
Het async-ecosysteem van Rust draait om libraries als Tokio en async-std, waarmee je webscraper duizenden verzoeken tegelijk kan verwerken zonder het hoofdproces te blokkeren. Voor bedrijven betekent dit:
- Sneller data binnenhalen: Scrape duizenden pagina’s tegelijk en bouw je dataset in een fractie van de tijd.
- Efficiënter met je resources: Async code is zuiniger, dus je hebt minder hardware nodig voor hetzelfde resultaat.
- Schaalbaar: Als je databehoefte groeit, kun je met Rust’s async-mogelijkheden makkelijk opschalen zonder je hele workflow te herschrijven.
In de praktijk betekent dit dat je team direct kan inspelen op marktontwikkelingen, concurrenten kan monitoren of leads kan genereren—zonder uren of dagen te hoeven wachten tot de data binnen is.
Hoe werkt webscraping met Rust? Een stappenplan
Benieuwd hoe een typische webscraping-workflow in Rust eruitziet? Hier een overzicht zonder technische poespas:
- Voorbereiden: Bepaal welke data je wilt verzamelen en van welke websites.
- Data ophalen: Gebruik libraries zoals Reqwest om webpagina’s te downloaden.
- Inhoud parseren: Gebruik Scraper of Select om specifieke info (zoals productnamen, prijzen, e-mails) uit de HTML te halen.
- Omgaan met paginering/subpagina’s: Schrijf logica om door meerdere pagina’s te navigeren of links naar subpagina’s te volgen (hierover meer hieronder).
- Data exporteren: Sla de verzamelde data op in een gestructureerd formaat—CSV, Excel of direct in een database—zodat je team er direct mee aan de slag kan.
Elke library heeft zijn eigen taak: Reqwest regelt het ophalen, Scraper/Select het parseren, en voor het exporteren kun je standaard Rust-functies of externe pakketten gebruiken.
Complexe websites scrapen: paginering en subpagina’s in Rust
Veel zakelijke scraping-taken zijn niet zo simpel als data van één pagina halen. Je moet bijvoorbeeld:
- Alle producten uit een meerpagina-catalogus scrapen
- Reviews verzamelen die verspreid staan over verschillende subpagina’s
- Contactgegevens uit geneste directories halen
Rust is hier ideaal voor. Dankzij het sterke type-systeem en de foutafhandeling kun je makkelijker code schrijven die:
- Automatisch “Volgende” knoppen of pagineringslinks detecteert en volgt
- Subpagina’s bezoekt (zoals productdetails of auteursprofielen) en die data samenvoegt met je hoofdset
- Onverwachte situaties (zoals ontbrekende pagina’s of kapotte links) netjes afhandelt, zodat je webscraper niet crasht
Een Rust-webscraper kan bijvoorbeeld starten op een overzichtspagina, alle pagineringslinks volgen en vervolgens elke productpagina bezoeken om prijs, beschrijving en reviews te verzamelen. Het resultaat? Een compleet en actueel databestand, klaar voor analyse.
Thunderbit versus Rust: het no-code voordeel voor bedrijven
Maar nu het belangrijkste punt: niet iedereen heeft de tijd of technische kennis om zelf een Rust-webscraper te bouwen. Daar komt Thunderbit om de hoek kijken.
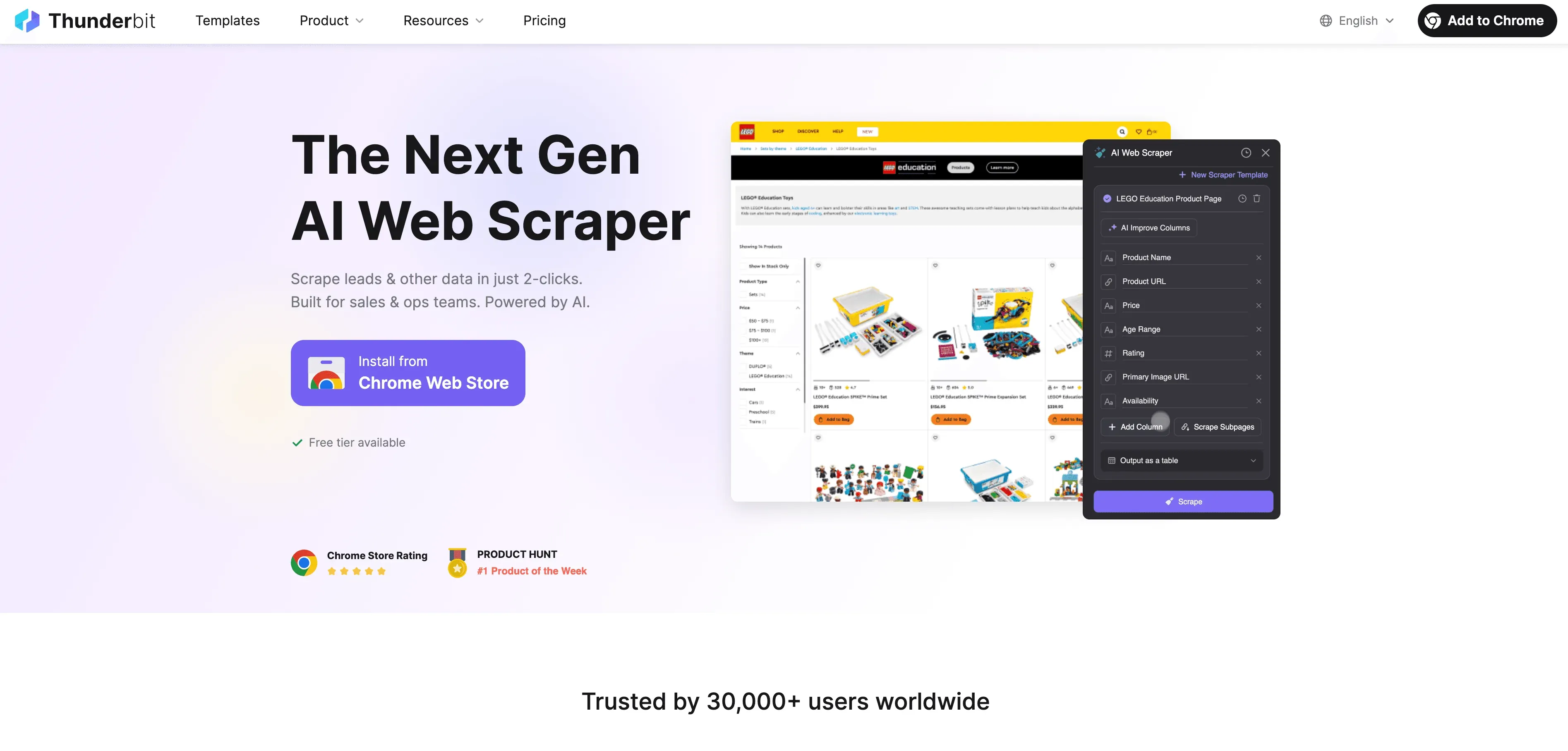
Thunderbit is een AI-webscraper zonder code speciaal voor zakelijke gebruikers. In plaats van programmeren doe je het zo:
- Open de Thunderbit Chrome-extensie
- Ga naar de website die je wilt scrapen
- Klik op “AI Suggest Fields” en laat de AI van Thunderbit voorstellen welke data je kunt verzamelen
- Klik op “Scrape” en exporteer je resultaten direct naar Excel, Google Sheets, Airtable of Notion
Geen templates, geen code, geen onderhoud. Thunderbit regelt zelfs paginering en subpagina’s automatisch—net als een custom Rust-webscraper, maar dan met een supergebruiksvriendelijke interface.
Probeer Thunderbit AI-webscraper gratis
Wanneer kies je voor Thunderbit of Rust? De juiste tool voor jouw situatie
Welke aanpak past het beste bij jouw team? Een handig overzicht:
| Situatie | Thunderbit | Rust |
|---|---|---|
| Snel leads verzamelen voor sales | ✅ Snel en eenvoudig | Mogelijk, maar vaak te complex |
| Prijsmonitoring bij concurrenten (e-commerce) | ✅ No-code, inplannen mogelijk | ✅ Voor maatwerk-integraties |
| Complexe, op maat gemaakte scraping-workflows | Mogelijk, maar beperkt | ✅ Volledige controle, zeer flexibel |
| Grootschalige, geïntegreerde datapijplijnen | Mogelijk (via API) | ✅ Beste keuze voor diepe integratie |
| Niet-technische gebruikers (sales, operations, marketing) | ✅ Speciaal voor jou | ❌ Programmeerkennis vereist |
| Snel prototypen of eenmalige taken | ✅ In 2 klikken geregeld | Mogelijk, maar trager om te starten |
Kortom: Thunderbit is ideaal voor zakelijke gebruikers die snel en betrouwbaar data willen verzamelen zonder technische drempels. Rust is perfect als je maximale controle, maatwerk of grootschalige scraping nodig hebt.
Praktijkvoorbeeld: webscraping met Rust in actie
Stel, je bent marktonderzoeker en je moet alle laptops op een grote e-commercesite in kaart brengen. De site gebruikt paginering (meerdere pagina’s met producten) en elke laptop heeft een detailpagina met specificaties en reviews.
Met Rust zou je het zo aanpakken:
- Gebruik Reqwest om de hoofdpagina op te halen
- Parseer de HTML met Scraper om productlinks te verzamelen
- Detecteer en volg de “Volgende” knop om alle pagina’s te scrapen
- Bezoek voor elk product de detailpagina en haal specificaties/reviews op
- Handel fouten (zoals ontbrekende pagina’s) netjes af en probeer opnieuw indien nodig
- Exporteer de uiteindelijke dataset naar CSV of je analyseplatform
Het resultaat? Je krijgt een volledig en actueel overzicht van de markt—ideaal voor prijsstrategie, voorraadbeheer en marketing.
Belangrijke uitdagingen en aandachtspunten bij webscraping met Rust
Ook met de voordelen van Rust is webscraping niet altijd probleemloos. Veelvoorkomende uitdagingen (en hoe Rust helpt):
- Websitewijzigingen: Als de site verandert, kan je webscraper stukgaan. Rust’s strikte typechecks helpen om dit snel te signaleren, maar je zult je code soms moeten aanpassen.
- Anti-botmaatregelen: Veel sites gebruiken CAPTCHAs of limieten. Rust’s snelheid helpt om onder de radar te blijven, maar soms zijn vertragingen of proxies nodig.
- Dataformaat: Niet alle data is netjes—met Rust’s krachtige parsing-tools kun je rommelige of inconsistente HTML beter verwerken.
- Onderhoud: Maatwerk-webscrapers vragen om regelmatig onderhoud. Voor bedrijven betekent dit nauwe samenwerking met tech-teams, of kiezen voor een no-code tool als Thunderbit voor standaardtaken.
Wat is datascraping en hoe doe je het in 2025 Get Started Free
Tip: Of je nu Rust of Thunderbit gebruikt, respecteer altijd de gebruiksvoorwaarden en privacyregels van websites bij het scrapen van data.
Conclusie: meer waarde uit data met webscraping in Rust (en daarbuiten)
Webscraping is een must-have voor elk bedrijf dat voorop wil blijven lopen in een datagedreven wereld. Rust biedt ongeëvenaarde prestaties, veiligheid en betrouwbaarheid voor teams die maatwerk en schaalbaarheid nodig hebben—vooral als snelheid en stabiliteit cruciaal zijn. Maar voor de meeste zakelijke gebruikers is de technische drempel hoog.
Daar blinkt Thunderbit uit: het maakt webscraping toegankelijk voor iedereen, met een AI-gedreven no-code interface die zelfs complexe taken als paginering en subpagina’s automatisch afhandelt. Of je nu leads verzamelt, prijzen monitort of marktanalyse doet—met Thunderbit heb je snel de data die je nodig hebt.
Belangrijkste punten:
- Rust is een krachtpatser voor maatwerk en grootschalige webscraping—ideaal voor technische teams.
- Thunderbit maakt webscraping toegankelijk voor niet-technische gebruikers.
- Kies de juiste tool: Rust voor diepgaande maatwerk, Thunderbit voor snelheid en eenvoud.
Haal data van elke website met AI Get Started Free
Wil je webscraping proberen voor jouw bedrijf? Download Thunderbit en ontdek hoe makkelijk dataverzameling kan zijn. Of duik in het Rust-ecosysteem als je een maatwerkoplossing zoekt voor high-performance scraping.
Probeer AI-webscraper Get Started Free
Veelgestelde vragen
1. Wat is webscraping met Rust en hoe verschilt het van andere talen?
Webscraping met Rust betekent dat je de Rust-programmeertaal gebruikt om automatisch data van websites te halen. Rust onderscheidt zich door zijn snelheid, geheugenveiligheid en betrouwbaarheid ten opzichte van talen als Python of JavaScript, waardoor het ideaal is voor grootschalige of kritieke scraping-taken.
2. Is Rust geschikt voor niet-technische zakelijke gebruikers die willen webscrapen?
Rust is krachtig, maar vereist programmeerkennis. Voor niet-technische gebruikers bieden tools als Thunderbit een no-code, AI-gedreven aanpak—zo wordt dataverzameling voor iedereen toegankelijk.
3. Hoe gaat Rust om met complexe scraping-taken zoals paginering of subpagina’s?
Dankzij het sterke type-systeem en asynchrone libraries kun je met Rust makkelijker code schrijven die automatisch door pagineringen navigeert, subpagina’s volgt en fouten afhandelt—wat zorgt voor completere en betrouwbaardere datasets.
4. Wanneer kies ik voor Thunderbit in plaats van een eigen Rust-webscraper?
Gebruik Thunderbit als je snel en eenvoudig data wilt verzamelen zonder te programmeren—ideaal voor sales, marketing en operations. Kies Rust voor zeer maatwerk, grootschalige of diep geïntegreerde scraping-workflows die technische kennis vereisen.
5. Wat zijn de grootste uitdagingen bij webscraping met Rust en hoe ga je daarmee om?
Veelvoorkomende uitdagingen zijn websitewijzigingen, anti-botmaatregelen en onderhoud. Rust’s veiligheid helpt fouten vroeg te signaleren, maar je zult je code moeten bijwerken als sites veranderen. Voor standaard scraping-taken kan een no-code tool als Thunderbit veel tijd en moeite besparen.
Meer weten:




