
Laten we eerlijk zijn: het web is een wilde, wilde plek. Elke dag voelt het alsof ik voor een digitale brandslang sta—nieuws, reviews, productvermeldingen, tweets, vastgoeddeals, noem maar op—alles dendert voorbij in een rommelige, ongestructureerde stroom. En als je een bedrijf runt, kan proberen daar chocola van te maken voelen als zoeken naar een speld in een hooiberg… terwijl die hooiberg in brand staat. (Been there. Niet leuk.)
Maar hier komt het: tussen al die online rommel zit pure waarde—inzichten die sales kunnen aanjagen, je een stap voor kunnen zetten op concurrenten en het saaie werk kunnen automatiseren waar niemand zin in heeft. Dáár komt webscraping om de hoek kijken. Met de juiste tools zet je die berg ongestructureerde webdata om in nette, bruikbare spreadsheets, klaar voor je volgende grote stap. En als iemand die al jaren in SaaS en automatisering werkt, kan ik je vertellen: webscraping is allang niet meer alleen voor programmeurs. Het is er voor iedereen die slimmer wil werken, niet harder.
Betekenis van Webscraping: online chaos omzetten in bruikbare data
Dus, wat is webscraping precies? Laten we de jargon even overslaan en het gewoon helder houden: webscraping is het proces waarbij software specifieke informatie van websites haalt en omzet in gestructureerde formaten—denk aan Excel, Google Sheets of een database. Zie het als een digitale assistent die onvermoeibaar precies de info kopieert die jij nodig hebt van duizenden webpagina’s en die netjes voor je ordent. Dat is webscraping in een notendop.
Je komt ook wel eens de term “data scraping” tegen. Het verschil is simpel: data scraping is een brede term voor het ophalen van data uit elke bron (websites, pdf’s, afbeeldingen, noem maar op). Webscraping gaat specifiek over het extraheren van data van websites op internet. Met andere woorden: alle webscraping is data scraping, maar niet alle data scraping is webscraping. (Een beetje zoals alle vierkanten rechthoeken zijn, maar niet alle rechthoeken vierkanten zijn.)
Als je een formelere definitie wilt: webscraping is “data scraping gebruikt voor het extraheren van data van websites” (Wikipedia). In de praktijk is het gewoon automatisering voor online onderzoek—geen eindeloos kopiëren en plakken tot je vingers eraf vallen.
Waarom webscraping belangrijk is voor moderne bedrijven
Wat is data scraping en hoe doe je het in 2025 Get Started Free
Laten we het over business hebben. Waarom is webscraping juist nu zo belangrijk? Omdat het internet overspoeld wordt door ongestructureerde data—ongeveer 80%–90% van alle nieuwe data is ongestructureerd, van social posts tot productvermeldingen. IDC voorspelt dat de wereldwijde datavolume in 2025 175 zettabyte zal bereiken—dat zijn een hoop nullen.
En hier komt de clou: 60–80% van de tijd van werknemers gaat verloren aan het alleen maar vinden en voorbereiden van data, niet aan het analyseren ervan. Dat is alsof je een chef de hele dag aardappels laat schillen in plaats van koken. Zoals Michael Shulman, Head of Machine Learning bij Kensho, het zei: “Omdat het grootste deel van de wereldwijde data ongestructureerd is, biedt het vermogen om die te analyseren en erop te handelen een grote kans.”
Webscraping draait dat om. In plaats van websites handmatig door te ploegen, automatiseer je het proces—en verzamel je live data, in realtime, van overal op het web. Geen wonder dat 71% van de financiële dienstverleners en meer dan de helft van de retail- en e-commercebedrijven al webscraping gebruikt voor externe data. Data is niet alleen het nieuwe olie—het is de nieuwe valuta, en webscraping is hoe je die verzilvert.
Veelvoorkomende toepassingen van webscraping in verschillende sectoren
Webscraping is geen eenmansactie. Het wordt overal gebruikt—van sales teams tot vastgoedanalisten. Hier zijn een paar praktijkvoorbeelden:
- Salesleads & B2B-prospectie: Scrape vacaturebanken of bedrijvengidsen om frisse, gerichte leadlijsten op te bouwen. Een SaaS-bedrijf zag een stijging van 40% in gekwalificeerde leads door dit proces te automatiseren.
- E-commerce prijs- en productmonitoring: Retailers scrapen websites van concurrenten voor prijzen en voorraad, en passen hun eigen prijzen vrijwel realtime aan. Het resultaat? Meer verkoop en loyale klanten.
- Vastgoedaanbod: Aggregators en investeerders scrapen vastgoedsites voor woningen, prijzen en trends—zodat ze ondergewaardeerde panden en kansrijke buurten kunnen spotten (case study).
- Reizen & hospitality: Scrape luchtvaart- en hotelsites voor tarieven, beschikbaarheid en reviews—de brandstof voor prijsvergelijkingstools en sentimentanalyse.
- Finance & investment: Hedgefondsen scrapen van alles, van SEC-filings tot productreviews, op zoek naar alternatieve datasignalen. 71% van de financiële bedrijven gebruikt webscraping inmiddels in hun processen.
De kern: als er waardevolle data op het web staat, is er een manier om die te scrapen en om te zetten in zakelijke waarde.
Hoe webscraping werkt: van website naar spreadsheet
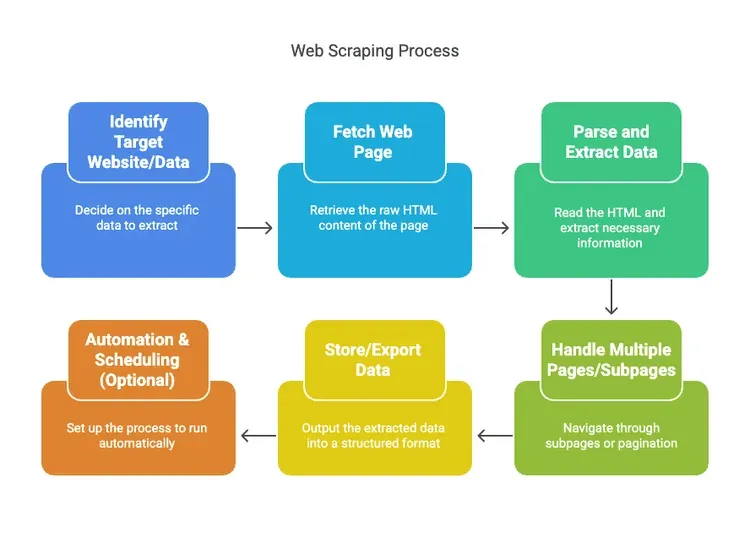
Laten we het proces ontmythologiseren. Webscraping is geen magie—het is een workflow. Zo gaat het meestal:
- Bepaal de doelwebsite/data: Kies wat je wilt (bijv. productnamen en prijzen van xyz).
- Haal de webpagina op: De scraper haalt de ruwe HTML op, net zoals je browser dat doet.
- Parse en extraheer data: De tool leest de HTML en haalt de informatie eruit die je nodig hebt (zoals prijzen, namen, reviews).
- Verwerk meerdere pagina’s/subpagina’s: Scrapers kunnen automatisch links naar subpagina’s volgen of door paginering klikken.
- Sla de data op/exports: Zet alles om naar een gestructureerd formaat—CSV, Excel, Google Sheets of een database.
- Automatisering & planning (optioneel): Stel in dat het volgens een schema draait, zodat je data vers blijft zonder dat je ernaar om hoeft te kijken.
Dit handmatig doen kost een eeuwigheid (en een hoop koffie). Met webscraping automatiseer je het hele proces—en verander je uren handwerk in minuten.
De rol van scrapingtools en webscrapingdiensten
Nu over de tools. Er is een flink buffet aan opties: van browserextensies tot cloudplatformen en desktopsoftware. Hier is een korte samenvatting:
- Browserextensies: Lichtgewicht, point-and-click tools die in je browser leven. Ideaal voor snelle, eenvoudige klussen.
- Desktopsoftware: Volwaardige apps met visuele interfaces—kunnen inloggen, infinite scroll en meer aan.
- Cloudplatformen: Draai scrapers op externe servers—perfect voor grote, continu draaiende taken.
- Aangepaste code: Voor de techneuten—schrijf je eigen scripts voor maximale controle (maar ook maximale hoofdpijn).
Waarom deze tools gebruiken in plaats van kopiëren en plakken? Drie redenen: snelheid, schaal en betrouwbaarheid. Een goede scraper kan duizenden pagina’s verwerken in de tijd die jij nodig hebt om je lunch op te warmen. Bovendien krijg je schone, gestructureerde data—geen typefouten, geen gemiste details.
Gestructureerde vs. ongestructureerde data: waarom webscraping essentieel is
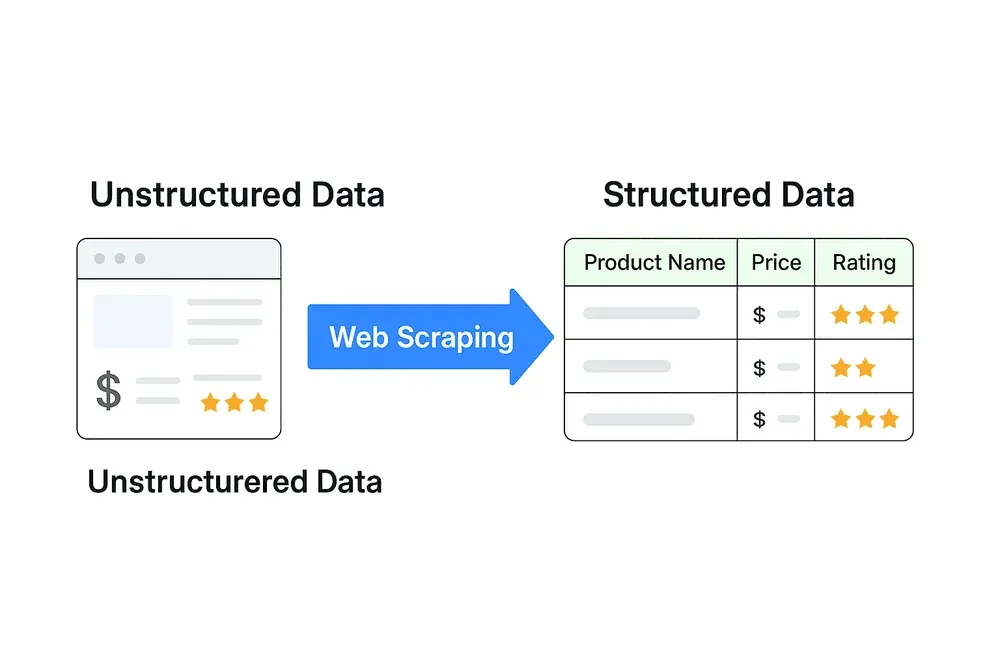
Hier zit de kern: de meeste webdata is ongestructureerd. Die is ontworpen voor mensen, niet voor machines. Denk aan een productpagina met afbeeldingen, reviews en prijzen allemaal door elkaar. Dat kun je niet zomaar in Excel plakken en beginnen met analyseren.
Gestructureerde data—zoals een spreadsheet met kolommen voor “Productnaam”, “Prijs” en “Beoordeling”—is wat analytics, dashboards en besluitvorming aandrijft. Webscraping is de brug die rommelige webcontent omzet in schone, bruikbare informatie.
En hier is een opvallende statistiek: slechts ongeveer 50% van de ongestructureerde data van een organisatie wordt überhaupt geanalyseerd. De rest? Onbenut potentieel. Webscraping helpt je die waarde vrij te spelen.
Soorten webscrapingoplossingen: code, no-code en AI-tools
Laten we je opties even uitsplitsen:
- Code-oplossingen: Schrijf scripts in Python (met libraries zoals BeautifulSoup of Scrapy), JavaScript of R. Maximale flexibiliteit, maar je hebt wel wat programmeerkennis nodig—en geduld wanneer websites veranderen en je script stukgaat.
- No-code-oplossingen: Visuele tools (browserextensies, desktopapps, cloudplatformen) waarmee je scrapes opzet met klikken, niet met code. Perfect voor zakelijke gebruikers die gewoon resultaat willen.
- AI-aangedreven scrapers: De nieuwkomers. Deze tools gebruiken AI om automatisch te bepalen wat er gescrapet moet worden, passen zich aan websiteveranderingen aan en halen zelfs data uit pdf’s of afbeeldingen. Thunderbit is hier een goed voorbeeld van.
Als iemand die beide kanten heeft gezien—coderen én no-code tools gebruiken—kan ik zeggen: voor de meeste zakelijke gebruikers zijn no-code of AI-aangedreven scrapers de beste keuze. Waarom zou je met code worstelen als je met twee klikken hetzelfde resultaat kunt krijgen?
Belangrijke functies om op te letten in een scrapingtool
Scrape data van elke website met AI Get Started Free
Niet elke scraper is hetzelfde. Hier let ik op (en dit raad ik elk bedrijfsteam aan):
- Gebruiksgemak: Kun je aan de slag zonder een handleiding van romanlengte te lezen?
- AI-veldherkenning: Stelt de tool automatisch voor wat er gescrapet moet worden?
- Ondersteuning voor subpagina’s & paginering: Kan de tool meer-pagina-lijsten aan en detailpagina’s openen?
- Exportopties: Kun je data direct naar Excel, Google Sheets, Airtable of Notion sturen?
- Planning: Kun je het instellen en vergeten—automatisch scrapen volgens jouw schema?
- Herkenning van datatypes: Herkent de tool e-mails, telefoonnummers, afbeeldingen en meer?
- Sjablonen voor populaire sites: Scrapen met 1 klik voor Amazon, Zillow, Instagram, enzovoort.
Voor sales-, e-commerce- en operationsteams betekenen deze functies minder handmatig werk, minder fouten en veel meer tijd voor wat er echt toe doet.
Thunderbit: de eenvoudigste AI-webscraper voor iedereen
Oké, even schaamteloze zelfpromotie—maar alleen omdat ik echt geloof in wat we bouwen bij Thunderbit.
Thunderbit is een AI-aangedreven webscraper Chrome-extensie, ontworpen voor zakelijke gebruikers, niet alleen voor developers. Dit maakt het anders:
- AI-velden voorstellen: Klik gewoon op “AI-velden voorstellen” en Thunderbit leest de pagina, adviseert de beste kolommen en stelt alles voor je in. Geen giswerk of gepruts met selectors meer.
- Scrapen in 2 klikken: Open de pagina, laat AI de velden voorstellen, klik op “Scrapen”. Klaar. Zo simpel is het.
- Subpagina’s & paginering: Thunderbit’s AI detecteert en scrape automatisch subpagina’s en gepagineerde lijsten—zonder extra instellingen.
- Geplande scraper: Wil je prijzen of leads dagelijks monitoren? Beschrijf gewoon het schema (“elke ochtend om 9 uur”), voeg URL’s toe en Thunderbit regelt de rest.
- Direct exporteren: Stuur je data rechtstreeks naar Excel, Google Sheets, Airtable of Notion—geen verborgen kosten, geen omwegen.
- Specialistische extractors: 1-klik-extractie voor e-mails, telefoonnummers en afbeeldingen—helemaal gratis.
- AI-autovullen: Gebruik AI om online formulieren in te vullen en workflows te automatiseren, niet alleen data te scrapen.
- Document- en afbeeldingparsing: Upload pdf’s, Word-, Excel-bestanden of afbeeldingen—Thunderbit’s AI extraheert tabellen en structureert de data voor je.
En ja, er is een gratis versie (scrape tot 6 pagina’s), dus je kunt het zonder risico proberen. Heb je meer nodig, dan beginnen betaalde abonnementen bij $15 per maand voor 500 rijen—een stuk betaalbaarder dan de meeste enterprise-tools.
Neem het niet alleen van mij aan. Gebruikers zeiden dingen als: “Thunderbit is veruit de makkelijkste webscraper die ik ooit heb gebruikt. Ik ging van uren scripts schrijven naar complete websites scrapen in minuten—met maar een paar klikken.” Dat is het soort feedback dat al die late-night code-sessies de moeite waard maakt.
Wil je Thunderbit in actie zien? Bekijk ons YouTube-kanaal of lees meer op de Thunderbit Blog.
Probeer de Thunderbit Chrome-extensie gratis
Best practices voor webscraping voor niet-technische teams
Webscraping is krachtig, maar een beetje voorzichtigheid komt een heel eind. Dit zijn mijn beste tips om te beginnen:
- Respecteer het beleid van websites: Controleer altijd de gebruiksvoorwaarden en robots.txt van de site. Houd je aan openbare data en gebruik die verantwoord.
- Overbelast servers niet: Wees beleefd—bestook een site niet met verzoeken. Bij de meeste tools kun je crawlsnelheden of vertragingen instellen.
- Begin klein: Test je scraper eerst op een paar pagina’s. Zorg dat je de data krijgt die je wilt voordat je opschaalt.
- Verwerk paginering: Vergeet niet alle pagina’s te scrapen, niet alleen de eerste.
- Controleer je data: Maak je resultaten schoon en controleer ze—verwijder dubbelen, corrigeer opmaak en kijk of er niets ontbreekt.
- Blijf georganiseerd: Leg vast wat je hebt gescrapet, wanneer en van waar. Dat scheelt later een hoop gedoe.
- Kijk of er API’s zijn: Soms is er een officiële API die je data makkelijker en betrouwbaarder levert dan HTML scrapen.
- Houd wijzigingen in de gaten: Websites veranderen. Als je scraper stopt met werken, is het misschien tijd om je setup bij te werken (of AI het te laten overnemen).
- Gebruik de juiste tool: Werkt één tool niet, probeer een andere. Wees niet bang om te experimenteren.
- Blijf ethisch: Alleen omdat je iets kunt scrapen, betekent niet altijd dat je het zou moeten doen. Respecteer privacy en eigendom van data.
Voor een diepere duik, bekijk onze gids: Wat is data scraping en hoe doe je het in 2025.
Conclusie: zakelijke waarde ontsluiten met webscraping

Laten we het afronden. Het web stroomt over van waardevolle data, maar het meeste daarvan zit opgesloten in ongestructureerde formaten. Webscraping is de sleutel die die data ontsluit—chaos verandert in helderheid en handwerk in groei.
Of je nu in sales, e-commerce, vastgoed of operations zit, webscraping kan je helpen om:
- Frissere leads van hogere kwaliteit te genereren
- Concurrenten en markten realtime te volgen
- Tijdsrovende workflows te automatiseren en elke week uren te besparen
- Slimmere, snellere, datagedreven beslissingen te nemen
En dankzij moderne tools—vooral AI-oplossingen zoals Thunderbit—hoef je geen programmeur of data scientist te zijn om te beginnen. Kies gewoon een project, probeer een tool uit (onze Chrome-extensie is een prima startpunt) en ontdek hoeveel meer je kunt doen wanneer automatisering het zware werk overneemt.
In een wereld waar “data het nieuwe olie is”, is webscraping je pomp. Dus ga ervoor—zet die brandslang van online data om in een gestage stroom inzichten en zie hoe je bedrijf groeit.
Veel scrapeplezier! En als je ooit vastloopt, weet je me te vinden (of in elk geval Thunderbit).
Begin met scrapen met Thunderbit AI
Veelgestelde vragen
1. Wat is webscraping, in gewone taal?
Webscraping is software gebruiken om automatisch specifieke data van websites te halen—zoals prijzen, reviews of vacatures—and het om te zetten in iets bruikbaars, zoals een spreadsheet. Zie het als een robotstagiair die 24/7 al het saaie kopieer- en plakwerk voor je doet.
2. Moet ik kunnen coderen om het te gebruiken?
Niet meer. Dankzij no-code en AI-aangedreven tools zoals Thunderbit kun je websites scrapen met een paar klikken—geen Python, geen debuggen, geen gedoe. Als je kunt browsen op het web, kun je het web scrapen.
3. Wat voor data kan ik scrapen?
Vrijwel alles wat openbaar online staat:
- Productvermeldingen en prijzen
- Vastgoedobjecten
- Vacatures
- Bedrijvengidsen
- Bio’s op sociale media
- Tabelgegevens uit pdf’s en afbeeldingen (ja, zelfs dat)
Als het online zichtbaar is, is er een manier om het te scrapen.
4. Is webscraping legaal?
Over het algemeen wel—zolang je verantwoord openbare data scrapt. Overbelast servers niet, respecteer de gebruiksvoorwaarden en vermijd het scrapen van afgeschermde of persoonlijke informatie. Bij twijfel: wees ethisch en houd het netjes.
Lees meer
- 3 manieren waarop webscraping bedrijfsgroei stimuleert
- Case study: hoe een retailer scraping gebruikte om de verkoop te verhogen
- Waarom externe data de toekomst is van competitieve strategie
Probeer AI-webscraper Get Started Free




