

Stel je voor: je bent online op zoek naar dat ene perfecte paar sneakers. Je scrolt door pagina na pagina, klikt steeds op “Volgende” of “Meer laden”, en ergens rond pagina 12 vraag je je af—hoeveel pagina’s zijn er eigenlijk nog? Nu, stel je voor dat je niet alleen aan het shoppen bent, maar juist álle productvermeldingen wilt verzamelen voor een prijsvergelijking, of dat je als salesmedewerker op zoek bent naar leads die diep verstopt zitten in een gigantische online directory. Op dat moment verandert webpaginering van een handige functie (of soms een frustratie) in een flinke technische uitdaging.
Na jaren ervaring in SaaS, automatisering en AI weet ik als geen ander hoe belangrijk paginering is voor het succes van een dataproject. En met de opkomst van AI-webscraper agents zoals Thunderbit verandert de manier waarop we webpaginering aanpakken razendsnel. In deze gids leg ik uit wat webpaginering precies inhoudt, waarom het zo belangrijk is voor iedereen die data wil verzamelen, en hoe moderne tools—vooral AI-gedreven oplossingen—het makkelijker dan ooit maken om complete datasets te verzamelen, hoe diep de informatie ook verstopt zit.
Wat is webpaginering? Simpel uitgelegd voor zakelijke gebruikers
Wat is data scraping en hoe doe je het in 2025 Get Started Free
Laten we bij het begin beginnen. Webpaginering betekent simpelweg dat een lange lijst met items wordt opgedeeld in kleinere, hapklare pagina’s. Heeft een website bijvoorbeeld 500 producten, dan worden die niet allemaal tegelijk geladen (tenzij je browser overuren wil draaien). In plaats daarvan zie je bijvoorbeeld 20 producten per pagina, met navigatieknoppen—zoals paginanummers, “Volgende” of “Meer laden”—zodat je stap voor stap kunt bladeren.
Waarom doen websites dit? Drie hoofdredenen:
- Gebruiksgemak: Niemand wil eindeloos door één lange pagina met 1.000 items scrollen. Paginering helpt je snel te vinden wat je zoekt, te onthouden waar je was (“Die aanbieding stond op pagina 3!”), en niet te verdwalen in de hoeveelheid informatie.
- Snelheid: Kleinere hoeveelheden content laden is veel sneller en minder zwaar voor je browser (en de servers van de website). Zeker als er veel afbeeldingen zijn, scheelt dit flink in bandbreedte.
- Overzicht & structuur: Paginering zorgt voor overzicht. Je kunt naar het begin, het einde of een specifiek deel springen. Het is alsof je een inhoudsopgave hebt in plaats van één eindeloze scroll.
Zonder paginering zouden veel websites nauwelijks bruikbaar zijn. Stel je een webshop voor die alle 10.000 producten op één pagina zet—je laptop zou het zwaar krijgen.
Waarom webpaginering belangrijk is voor webscraper-paginering
Nu wordt het interessant voor iedereen die webscraping-tools gebruikt. Als je alleen de eerste pagina met resultaten verzamelt, mis je het grootste deel van de data. En in het bedrijfsleven is onvolledige data net zo nutteloos als een pizzadoos zonder pizza.
Laten we eens kijken naar een paar praktijkvoorbeelden:
| Toepassing | Waarom verder dan pagina 1 scrapen essentieel is |
|---|---|
| Leadgeneratie (bijv. contactgegevens uit directories of LinkedIn halen) | De meeste contacten staan niet op de eerste pagina. Zonder paginering verzamel je slechts een klein deel van de beschikbare leads. |
| Prijsmonitoring (concurrenten op e-commerce sites) | Producten en prijzen van concurrenten staan vaak verspreid over tientallen pagina’s. Alleen pagina 1 scrapen betekent dat je goedkopere items of specifieke producten mist. |
| Marktonderzoek/SEO (zoekresultaten, rankings) | Een merk kan op pagina 2, 3 of verder staan. Voor een volledig beeld moet je alle resultaten verzamelen. |
| Listings verzamelen (vastgoed, vacatures, etc.) | Belangrijke vermeldingen kunnen overal in een lijst van 100+ pagina’s staan. Onvolledig scrapen betekent gemiste kansen. |
Zoals een webscraping-gids het mooi zegt: “Als je paginering niet goed afhandelt, is je dataset incompleet. En onvolledige data is waardeloos.”
De meest voorkomende pagineringsvormen op het web
Websites zijn creatief (soms té creatief) in hoe ze hun content opdelen. Dit zijn de meest voorkomende vormen:
Genummerde paginering
Dit is de klassieker: onderaan de lijst zie je paginanummers (1, 2, 3, …, 10, Volgende >). Je vindt het overal—Google, Amazon, eBay, Walmart. Je kunt naar elke pagina springen of steeds op “Volgende” klikken.
![]()
Voordelen:
- Duidelijk en makkelijk te begrijpen.
- Je kunt snel naar een specifieke pagina.
- Vaak staat het paginanummer in de URL (zoals
?page=2), wat het ideaal maakt voor webscrapers.
Nadelen:
- Veel klikken kan vermoeiend zijn voor gebruikers.
- Sommige sites verbergen paginanummers of tonen er maar een paar tegelijk.
Voor webscraping is genummerde paginering meestal het makkelijkst—je verhoogt gewoon het paginanummer in de URL of volgt de “Volgende”-link tot het einde (meer info hier).
“Meer laden”-knop
Sommige sites hebben geen pagina’s, maar een grote “Meer laden”-knop onderaan. Klik je erop, dan verschijnen er meer items—zonder dat de pagina opnieuw laadt. Dit zie je vaak op mobiele sites en social media feeds.
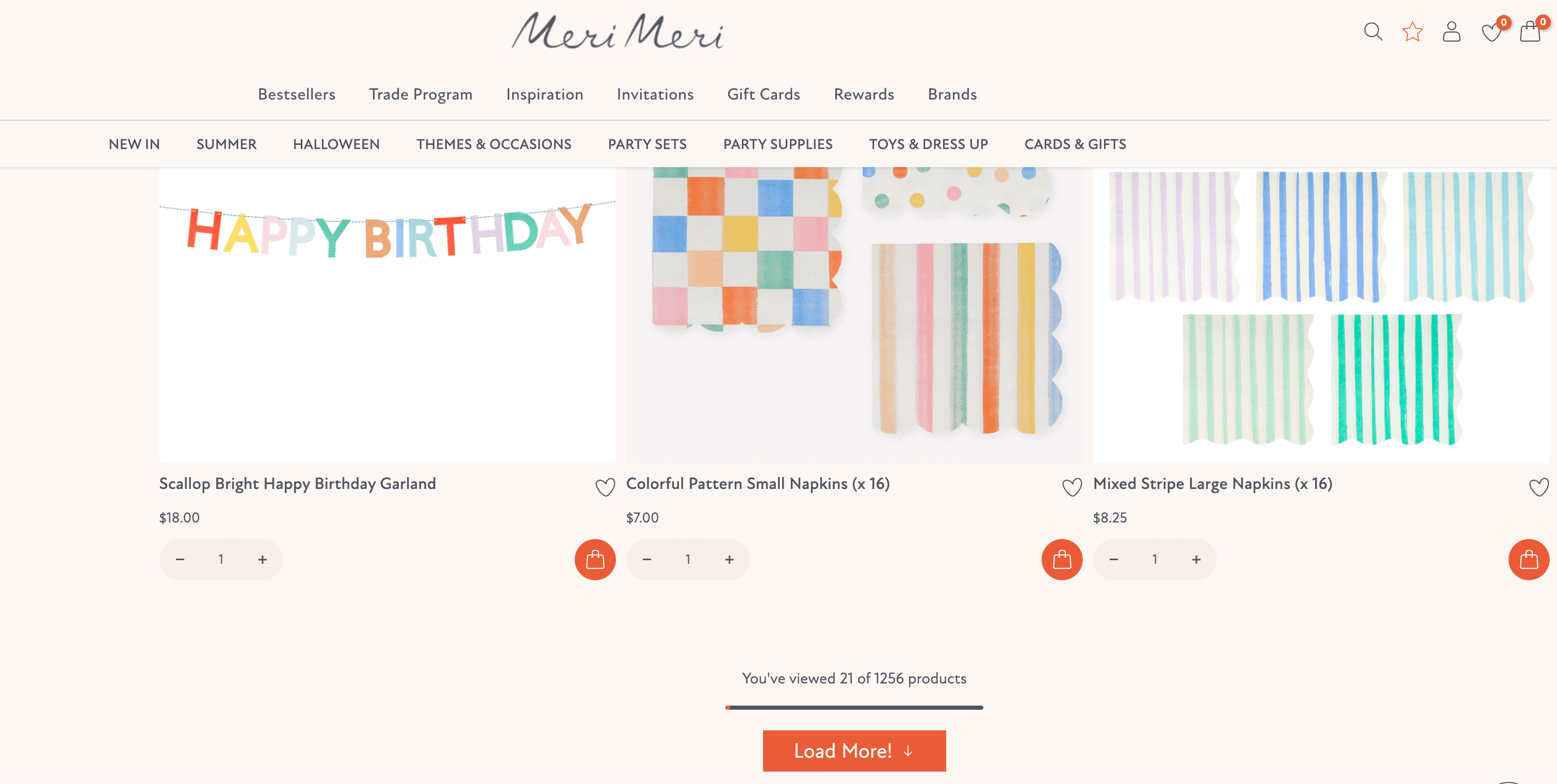
Voordelen:
- Soepelere gebruikerservaring.
- Alles blijft op één pagina.
Nadelen:
- Voor scrapers moet je het klikken van de knop nabootsen (je kunt niet alleen de URL aanpassen).
- Soms activeert de knop verborgen API-aanroepen, wat lastiger is om te imiteren.
Webscraping-tools moeten ofwel het klikken simuleren, of het netwerkverzoek achter de knop nadoen (zie hoe het werkt).
Oneindig scrollen
Oneindig scrollen—de valkuil van “nog één post” die social media zo goed beheerst. Terwijl je naar beneden scrolt, laadt er steeds meer content. Instagram, Twitter, Facebook, TikTok en zelfs sommige webshops zoals Nike gebruiken deze aanpak.
Voordelen:
- Zeer boeiend voor gebruikers (soms té).
- Ideaal voor mobiel gebruik.
Nadelen:
- Moeilijk om iets terug te vinden (geen paginanummers).
- Voor scrapers het lastigst—er is geen “Volgende”-knop, dus je moet scrollen nabootsen en wachten tot nieuwe content verschijnt.
Oneindig scrollen vereist vaak browserautomatisering of AI-webscrapers die zich als echte gebruikers gedragen (hier lees je waarom het lastig is).
Volgende/Vorige navigatie
Sommige sites houden het simpel: alleen “Volgende >” en “< Vorige”, zonder paginanummers. Je moet dus steeds één voor één bladeren, net als door een fotoalbum.
Voordelen:
- Overzichtelijk en eenvoudig voor gebruikers.
Nadelen:
- Je kunt niet direct naar een specifieke pagina.
- Voor scrapers betekent dit steeds op “Volgende” klikken tot het niet meer kan.
Dit patroon zie je vaak bij minimalistische blogs, sommige fora en oudere webapps.
Hoe werkt webscraper-paginering? De basis
Hoe pakken webscrapers paginering aan? Dit is het basisproces:
- Start op pagina 1: De scraper laadt de eerste pagina en verzamelt de data.
- Zoek pagineringsknoppen: De scraper speurt naar aanwijzingen—paginanummers, “Volgende”-knoppen, “Meer laden” of signalen van oneindig scrollen.
- Herhalen: Afhankelijk van het type paginering:
- Verhoogt de scraper het paginanummer in de URL,
- Klikt op de “Volgende” of “Meer laden”-knop,
- Of scrolt naar beneden om meer content te laden.
- Doorgaan: Dit proces herhaalt zich—scrapen, klikken of scrollen—totdat er geen nieuwe pagina’s of items meer zijn.
- Afronden: Na het verzamelen wordt de data samengevoegd, dubbele items verwijderd en het eindresultaat opgeleverd.
Voor de visueel ingestelden, een simpel schema:
[Pagina 1] → [Data scrapen] → [Is er een volgende pagina?] → Ja → [Ga naar volgende pagina] → [Data scrapen] → ... → Nee → [Klaar!]
Het lastige is dat “volgende pagina” een link, knop of scrollactie kan zijn. Moderne scrapers (vooral AI-gedreven) herkennen dit automatisch, maar het is goed om te weten wat er achter de schermen gebeurt.
Thunderbit’s aanpak: AI-gedreven webscraper-paginering
Pagineer websites automatisch met AI Get Started Free
Tijd voor het leuke deel—hoe Thunderbit paginering voor webscraping vernieuwt.
Als medeoprichter van Thunderbit heb ik gezien hoe gebruikers worstelen met allerlei pagineringsproblemen. Daarom hebben we Thunderbit’s AI zo ontwikkeld dat paginering automatisch wordt afgehandeld—je hoeft dus niet meer te knutselen met loops, selectors of code.
Zo pakt Thunderbit paginering aan:
- Automatische detectie: Thunderbit’s AI scant de pagina en herkent of er paginering is—of het nu genummerde links, een “Volgende”-knop, “Meer laden” of oneindig scrollen is. Wordt paginering gevonden, dan weet de AI hoe hiermee om te gaan.
- Scrapen in browsermodus: Thunderbit draait in Chrome en ziet dus alles wat een echte gebruiker ook ziet—ook content die via JavaScript wordt geladen. Ideaal voor oneindig scrollen en dynamische “Meer laden”-knoppen.
- Cloudscraping voor snelheid: Moet je veel pagina’s scrapen? In cloudmodus kan Thunderbit tot 50 pagina’s tegelijk ophalen. Dat is alsof je 50 stagiairs “Volgende” laat klikken—maar dan zonder koffiepauzes.
- Geen handmatig scriptwerk: Klik gewoon op “AI Suggest Fields”, laat Thunderbit de kolommen bepalen en druk op “Scrapen”. Is er paginering, dan gaat Thunderbit automatisch door tot alles binnen is. Geen code, geen XPath, geen gedoe.
- Klikken én scrollen: Of de site nu klikbare paginering of oneindig scrollen gebruikt, Thunderbit kan het aan. Je kunt de AI het laten bepalen of zelf de modus kiezen.
- Subpagina’s scrapen: Na het scrapen van een lijst kan Thunderbit zelfs elke detailpagina bezoeken voor extra informatie—ideaal voor e-commerce of vastgoed.
Kortom, Thunderbit’s AI behandelt paginering als een gewoon onderdeel van de pagina. Of het nu klikken, scrollen of iets daartussen is—de AI “bladert” voor je verder. (En raakt nooit verveeld.)
Probeer Thunderbit voor paginerende webscraping
Thunderbit versus traditionele webscraper-paginering
Laten we Thunderbit vergelijken met de klassieke aanpak:
| Functie | Traditionele scraper | Thunderbit (AI-gedreven) |
|---|---|---|
| Insteltijd | Handmatig: “Volgende”-knop selecteren, loops schrijven, selectors aanpassen | Automatisch: “AI Suggest Fields” klikken, “Scrapen” starten |
| Oneindig scrollen | Vereist browserautomatisering, eigen code | Ingebouwde AI-modus, gewoon aanzetten |
| Aanpassen aan sitewijzigingen | Werkt niet meer als de site verandert | AI analyseert de pagina telkens opnieuw |
| Snelheid | Achter elkaar (één pagina per keer) | Cloudmodus: tot 50 pagina’s tegelijk |
| Onderhoud | Veel—scripts aanpassen bij sitewijzigingen | Weinig—AI past zich aan, team update modellen |
| Anti-bot omzeiling | Handmatig: vertragingen, proxies toevoegen | Ingebouwd: menselijk klikgedrag, cloud IP’s |
| Subpagina’s scrapen | Handmatig instellen per laag | Eén klik op “Scrape Subpages” |
Thunderbit is als een slimme assistent die elke pagina weet te vinden, elke knop aanklikt en nooit verdwaalt—zelfs als de website het pad probeert te verbergen.
Best practices voor webscraper-paginering
Of je nu Thunderbit of een andere tool gebruikt, met deze tips haal je alles uit je scraping (zonder frustratie):
- Herken het pagineringspatroon: Kijk vooraf hoe de site pagineert. Genummerd? “Meer laden”? Oneindig scrollen? Dit bepaalt je aanpak.
- Gebruik het juiste gereedschap: Voor simpele paginering volstaat een basis-scraper. Voor dynamische of oneindige scrollsites gebruik je een browser- of AI-tool zoals Thunderbit.
- Voorkom gemiste pagina’s: Controleer altijd of je alle data hebt. Zegt de site “500 resultaten”? Zorg dat je er ook 500 hebt (of bijna).
- Voorkom dubbele data: Sommige sites tonen dezelfde items op meerdere pagina’s. Gebruik unieke ID’s (zoals product-URL’s) om te dedupliceren.
- Vertraag je verzoeken: Ga niet te snel—te veel verzoeken kunnen tot blokkades leiden. Thunderbit imiteert menselijk gedrag, maar als je zelf codeert, voeg dan vertragingen toe.
- Gebruik proxies bij grote klussen: Scrape je honderden pagina’s, dan helpen roterende IP’s om blokkades te voorkomen. Thunderbit’s cloudmodus regelt dit automatisch.
- Wees voorbereid op fouten: Soms laadt een pagina niet. Log fouten, probeer opnieuw en controleer altijd je resultaten.
- Maak gebruik van AI-functies: Voor lastige paginering (zoals AJAX of cursor-based) kunnen AI-scrapers de complexiteit voor je oplossen.
- Respecteer sitebeleid: Controleer altijd of scrapen is toegestaan. Overbelast servers niet en respecteer privacyregels.
Praktijkvoorbeelden van webscraper-paginering
Hoe werkt dit op echte websites?
1. Amazon (genummerde paginering, anti-bot)
Amazon gebruikt klassieke genummerde paginering, maar is streng op bots. Thunderbit herkent de “Volgende”-knop of paginalinks en klikt door, in browsermodus om als echte gebruiker over te komen. In cloudmodus kunnen meerdere pagina’s tegelijk worden opgehaald. Verschijnt er een captcha, dan helpt Thunderbit’s browsermodus (met menselijk klikgedrag) blokkades te voorkomen.
2. Zillow (genummerd, paginalimiet)
Zillow splitst woningaanbod op in pagina’s, maar stopt na 20 pagina’s (ongeveer 800 woningen). Thunderbit klikt automatisch door tot pagina 20 en stopt als er geen “Volgende” meer is. Wil je meer, dan moet je je zoekopdracht verfijnen (Thunderbit helpt je hierbij).
3. LinkedIn (hybride oneindig scrollen)
LinkedIn’s vacaturezoeker (zonder inloggen) gebruikt oneindig scrollen—meer banen verschijnen terwijl je scrolt. Thunderbit schakelt over naar oneindig scrollen en verzamelt alles tot er niets nieuws meer verschijnt. Zie je paginanummers (bij inloggen), dan past Thunderbit zich aan en klikt door.
4. Yelp (offset-paginering)
Yelp gebruikt offset-paginering (zoals start=10 in de URL). Thunderbit klikt op “Volgende” of verhoogt automatisch de offset. Vraagt Yelp om je locatie, dan kan Thunderbit’s browsermodus hiermee omgaan.
5. AliExpress (hybride: scrollen + pagina’s)
AliExpress laadt meer producten terwijl je scrolt, en toont soms een “Volgende”-knop. Thunderbit scrolt om zoveel mogelijk te laden en klikt daarna door naar de volgende pagina indien nodig. Het is de Zwitserse zakmes onder de pagineringsvormen.
Problemen oplossen bij webscraper-paginering
Zelfs met de beste tools kan er iets misgaan. Hier moet je op letten—en zo helpt Thunderbit:
- Alleen de eerste pagina opgehaald: Controleer of paginering aanstaat in je tool. In Thunderbit: check de “Paginate”-schakelaar. Of klik handmatig op “Scrape Next Page”.
- Ontbrekende data: Vergelijk het aantal resultaten met wat de site aangeeft. Mis je data, probeer dan opnieuw of scrape de ontbrekende pagina’s.
- Scraper loopt vast: Oneindig scrollen kan blijven hangen als content langzaam laadt. Gebruik in Thunderbit de browsermodus voor meer controle, of stel een maximale scrolltijd in.
- Dubbele of rommelige data: Dedupliceer op unieke ID. Thunderbit houdt meestal de volgorde aan, maar je kunt altijd sorteren in Excel.
- Herhalende of lege pagina’s: Zorg dat je scraper stopt aan het einde. Thunderbit’s AI weet wanneer het klaar is, maar als je zelf codeert: stop als er geen nieuwe data meer verschijnt.
Thunderbit’s AI is ontworpen om deze problemen automatisch te herkennen—paginering detecteren, menselijk klikgedrag nabootsen en mislukte pagina’s opnieuw proberen. En mocht je een bijzonder geval tegenkomen, dan werkt het Thunderbit-team continu aan het verbeteren van de AI.
Scrape gepagineerde data met Thunderbit AI
Samenvatting: alles uit webscraper-paginering halen
Tot slot een handige checklist voor het scrapen van gepagineerde sites:
- Begrijp het pagineringspatroon: Genummerd, “Meer laden”, oneindig scrollen of volgende/vorige? Weet wat je te wachten staat.
- Kies het juiste gereedschap: Gebruik AI-webscrapers zoals Thunderbit voor complexe of dynamische sites.
- Scrape alle pagina’s: Stop niet bij pagina één—verzamel de volledige dataset.
- Controleer op fouten: Let op ontbrekende data, dubbele items of blokkades.
- Vertraag en roteer: Voorkom blokkades door je verzoeken te spreiden en proxies te gebruiken indien nodig.
- Gebruik planning: Voor terugkerende taken kun je een planner inzetten (Thunderbit’s natuurlijke taalplanner maakt dit eenvoudig).
- Gebruik AI voor datacleanup: Thunderbit’s Field AI helpt je data te labelen, dedupliceren en organiseren tijdens het scrapen.
- Leer van praktijkvoorbeelden: Herken veelvoorkomende sitepatronen en pas je strategie aan.
- Gebruik sjablonen: Thunderbit biedt kant-en-klare sjablonen voor veel populaire sites—dat bespaart tijd.
- Blijf ethisch: Respecteer altijd het sitebeleid en privacyregels.
Webpaginering lijkt misschien een obstakel, maar met de juiste kennis en tools is het gewoon een stap richting volledige, betrouwbare data. Dankzij Thunderbit’s AI-aanpak hoef je minder te worstelen met paginering en kun je je focussen op het benutten van je data.
Veelgestelde vragen
1. Wat is webpaginering en waarom gebruiken websites het?
Webpaginering is het opdelen van lange lijsten met content (zoals producten of zoekresultaten) in meerdere kleinere pagina’s. Websites doen dit om de gebruiksvriendelijkheid, prestaties en structuur te verbeteren—zodat gebruikers makkelijk kunnen navigeren, pagina’s sneller laden en alles overzichtelijk blijft.
2. Waarom is paginering belangrijk voor webscraping?
Als je scraper alleen data van de eerste pagina verzamelt, mis je waarschijnlijk het grootste deel van de waardevolle informatie. Veel zakelijke toepassingen—zoals leadgeneratie, prijsmonitoring of marktonderzoek—vereisen dat je verder kijkt dan pagina één voor een compleet beeld.
3. Wat zijn de meest voorkomende pagineringsvormen op websites?
De belangrijkste types zijn:
- Genummerde paginering: Pagina’s met nummers 1, 2, 3, enz.
- “Meer laden”-knoppen: Meer resultaten toevoegen zonder de pagina te herladen.
- Oneindig scrollen: Nieuwe content laadt automatisch tijdens het scrollen.
- Volgende/Vorige-links: Gebruikers bladeren één pagina per keer.
Elk type vraagt om een andere scraping-aanpak.
4. Hoe pakt Thunderbit webscraper-paginering aan?
Thunderbit gebruikt AI om automatisch alle gangbare pagineringsvormen te herkennen en af te handelen—genummerde links, “Meer laden”-knoppen en oneindig scrollen. Het werkt in browsermodus voor dynamische pagina’s en kan in cloudmodus tot 50 pagina’s tegelijk verwerken, zonder dat je hoeft te programmeren.
5. Wat zijn best practices bij het scrapen van gepagineerde websites?
- Bepaal vooraf het type paginering.
- Gebruik tools die dynamische content aankunnen (zoals Thunderbit).
- Controleer altijd of je alle pagina’s hebt gescrapet (niet alleen de eerste).
- Dedupliceer data met unieke identifiers.
- Vertraag verzoeken en gebruik proxies bij grote klussen.
- Respecteer de gebruiksvoorwaarden en databeleid van de website.
Meer weten:
- De beste webscraping-tools & software in 2025
- Hoe je elke website scrapt met AI
- Mastering Pagination in Web Scraping: A Complete Guide
- Wat is paginering? En hoe implementeer je het op je website
Probeer Thunderbit AI Webscraper voor gepagineerde sites Get Started Free




