
Heb je ooit geprobeerd om het overzicht te houden van honderden websites van concurrenten, om er vervolgens achter te komen dat je daar een heel team (of een flinke voorraad koffie) voor nodig hebt om al die data handmatig te verzamelen? Je bent zeker niet de enige. In de zakenwereld van vandaag is webdata goud waard—of je nu in sales, marketing, onderzoek of operations werkt. Wist je dat webscraping inmiddels meer dan één derde van al het internetverkeer uitmaakt, en dat 81% van de Amerikaanse retailers geautomatiseerde webscrapers inzet om prijzen te monitoren (scrap.io)? Dat zijn heel wat bots die het zware werk doen.
Maar hoe werken die bots eigenlijk? En waarom kiezen zoveel teams voor Node.js—de JavaScript-motor achter veel moderne webapplicaties—om hun eigen webscrapers te bouwen? Als iemand die al jaren in SaaS en automatisering zit (en als CEO van Thunderbit), heb ik van dichtbij gezien hoe de juiste tools webdata kunnen veranderen van een hoofdpijndossier tot een concurrentievoordeel. Laten we samen kijken wat een Node webcrawler precies is, hoe het werkt, en hoe zelfs niet-programmeurs ermee aan de slag kunnen.
Node Web Crawler: De basis uitgelegd
Wat is Data Scraping en hoe doe je het in 2025 Get Started Free
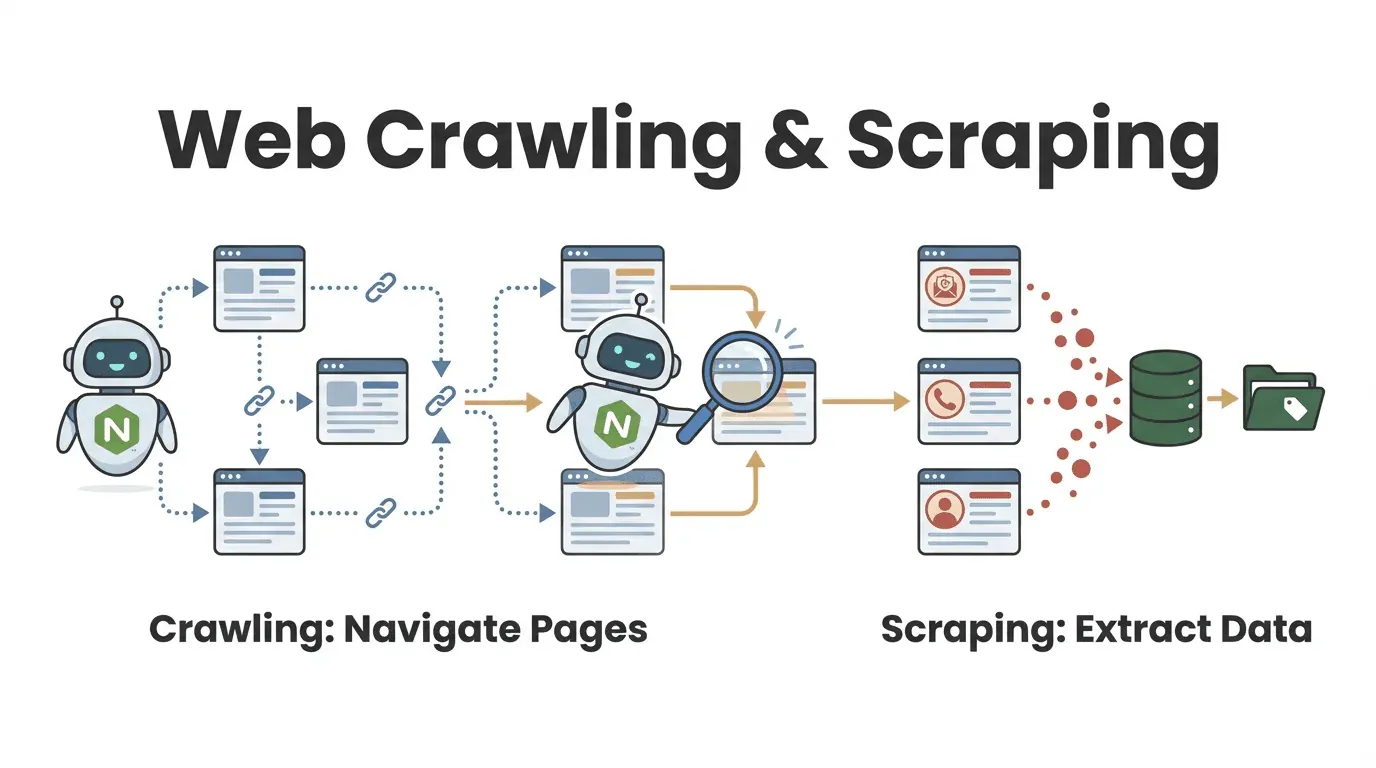
Laten we bij het begin beginnen. Een Node webcrawler is een programma—gemaakt met Node.js—dat automatisch webpagina’s bezoekt, links volgt en informatie verzamelt. Zie het als een onvermoeibare digitale stagiair: je geeft een start-URL op, en de crawler klikt zich door de site, haalt de gewenste data op en gaat door tot alles wat je nodig hebt binnen is.
Maar wat is nu eigenlijk het verschil tussen webcrawling en webscraping? Die vraag krijg ik vaak, vooral van zakelijke gebruikers:
- Webcrawling draait om het ontdekken en doorlopen van veel pagina’s. Vergelijk het met alle boeken in een bibliotheek doorbladeren om de juiste te vinden.
- Webscraping gaat om het verzamelen van specifieke informatie van die pagina’s—zoals het overschrijven van belangrijke citaten uit elk boek.
In de praktijk doen de meeste Node webcrawlers beide: ze vinden de juiste pagina’s én halen de relevante data eruit (oxylabs.io). Een salesteam kan bijvoorbeeld een bedrijvengids crawlen om alle bedrijfsprofielen te vinden, en vervolgens per profiel contactgegevens scrapen.
Hoe werkt een Node Web Crawler?
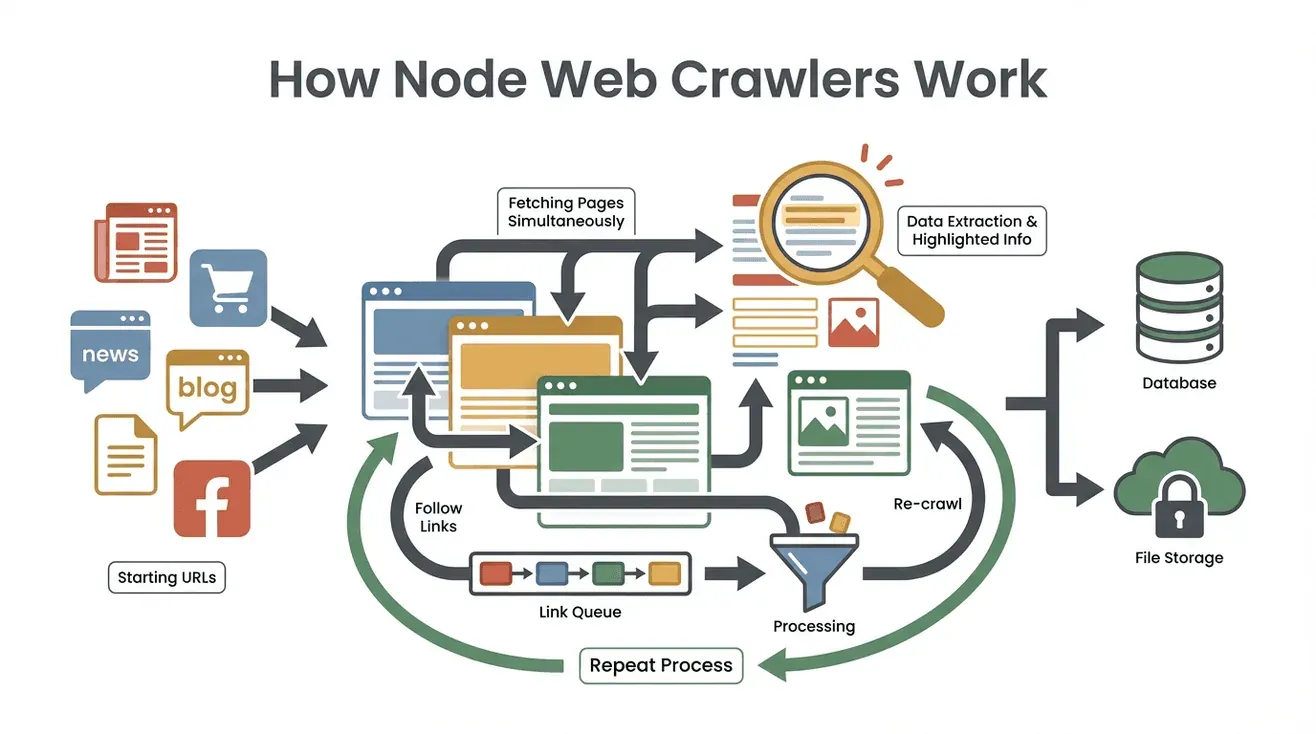 Laten we het proces ontrafelen. Zo werkt een typische Node webcrawler, stap voor stap:
Laten we het proces ontrafelen. Zo werkt een typische Node webcrawler, stap voor stap:
- Starten met Seed-URL’s: Je geeft de crawler één of meerdere startpunten (zoals een homepage of productoverzicht).
- Pagina-inhoud ophalen: De crawler downloadt de HTML van elke pagina—net als je browser, maar dan zonder de opmaak.
- Data extraheren: Met tools als Cheerio (vergelijkbaar met jQuery voor Node) haalt de crawler de gewenste info eruit—namen, prijzen, e-mails, noem maar op.
- Nieuwe links vinden en in de wachtrij zetten: De crawler zoekt op elke pagina naar links (zoals “Volgende pagina” of productdetails) en zet die op een takenlijst (de “crawl frontier”).
- Proces herhalen: De crawler blijft nieuwe links bezoeken, data verzamelen en zijn bereik uitbreiden tot alles wat je hebt opgegeven is doorlopen.
- Resultaten opslaan: Alle verzamelde data wordt opgeslagen—meestal als CSV, JSON of direct in een database.
- Stoppen als klaar: De crawler stopt als er geen nieuwe links meer zijn of als een ingestelde limiet is bereikt.
Een praktisch voorbeeld: stel je wilt alle vacatures van een carrièresite verzamelen. Je begint bij de hoofdpagina, haalt alle vacaturelinks op, bezoekt elke vacature, verzamelt de details en volgt “Volgende” tot je alles hebt.
Het geheim achter de schermen? Dankzij de event-driven, non-blocking architectuur van Node.js kan de crawler veel pagina’s tegelijk verwerken, zonder te hoeven wachten op trage websites. Het is alsof je een heel team stagiairs tegelijk aan het werk hebt—zonder de pizzakosten.
Waarom Node.js zo populair is voor webcrawlers
Waarom kiezen zoveel ontwikkelaars voor Node.js? Waarom niet Python, Java of een andere taal? Dit maakt Node.js zo geschikt voor webcrawling:
- Event-driven, non-blocking I/O: Node.js kan tientallen tot honderden paginaverzoeken tegelijk verwerken, zonder vast te lopen. Terwijl de ene pagina laadt, werkt hij al aan de volgende (blog.apify.com).
- Hoge prestaties: Node draait op Google’s V8-engine (dezelfde als Chrome), waardoor het razendsnel is—vooral bij het verwerken van grote hoeveelheden webdata.
- Rijke bibliotheek aan tools: Voor alles is een Node-bibliotheek: Cheerio voor HTML-parsing, Got voor HTTP-verzoeken, Puppeteer voor headless browsing, en frameworks als Crawlee voor grootschalige crawls (scrapingdog.com).
- JavaScript-synergie: Omdat de meeste websites JavaScript gebruiken, kan Node.js daar naadloos mee communiceren. Ook het werken met JSON-data is eenvoudig.
- Realtime mogelijkheden: Wil je tientallen sites tegelijk monitoren op prijswijzigingen of nieuws? Dankzij de asynchrone aanpak van Node kan dat bijna realtime.
Niet gek dus dat Node-tools als Crawlee en Cheerio door meer dan een derde van de webscraping-ontwikkelaars worden gebruikt.
Belangrijkste functies van een Node Web Crawler
Node webcrawlers zijn echte Zwitserse zakmessen voor webdata. Dit zijn typische functies—en hoe ze aansluiten op zakelijke behoeften:
| Functie | Hoe werkt het in Node crawlers | Zakelijk voorbeeld |
|---|---|---|
| Automatische navigatie | Volgt links en paginering automatisch | Leadgeneratie: alle pagina’s van een bedrijvengids crawlen |
| Data-extractie | Haalt specifieke velden (naam, prijs, contact) op via selectors of patronen | Prijsmonitoring: productprijzen van concurrenten verzamelen |
| Gelijktijdige verwerking | Verwerkt veel pagina’s parallel (dankzij asynchrone Node.js) | Realtime updates: meerdere nieuwssites tegelijk monitoren |
| Gestructureerde data-output | Slaat resultaten op als CSV, JSON of direct in een database | Analytics: data direct in BI-dashboards of CRM’s laden |
| Aanpasbare logica & filters | Voeg eigen regels, filters of datacleaning toe in de code | Kwaliteitscontrole: verouderde pagina’s overslaan, dataformaten aanpassen |
Een marketingteam kan bijvoorbeeld met een Node-crawler alle blogposts van branchesites verzamelen, titels en URL’s extraheren en deze exporteren naar Google Sheets voor contentplanning.
Thunderbit: No-code alternatief voor Node webcrawlers
Probeer Thunderbit AI-webscraper Haal data van elke website in 2 klikken—zonder te programmeren. Get Started Free
En nu wordt het interessant (en vooral leuker voor niet-programmeurs). Thunderbit is een AI-webscraper Chrome-extensie waarmee je webdata kunt verzamelen—zonder ook maar één regel code te schrijven.
Hoe werkt het? Je opent de extensie, klikt op “AI Velden voorstellen” en Thunderbit’s AI leest de pagina, doet suggesties voor relevante data en zet alles netjes in een tabel. Wil je alle productnamen en prijzen van een site? Geef het gewoon in gewone taal aan Thunderbit door, en de rest wordt geregeld. Subpagina’s of paginering scrapen? Ook dat kan met één klik.
Mijn favoriete Thunderbit-functies:
- Natuurlijke taalinterface: Beschrijf wat je wilt, de AI regelt de technische kant.
- AI-gegenereerde veldsuggesties: Thunderbit scant de pagina en stelt de beste kolommen voor.
- No-code subpagina crawling: Scrape detailpagina’s (zoals individuele producten of profielen) en voeg de data automatisch samen.
- Gestructureerde export: Exporteer direct naar Excel, Google Sheets, Airtable of Notion.
- Gratis data-export: Geen verborgen kosten voor het downloaden van je resultaten.
- Automatisering & planning: Stel terugkerende scrapes in met natuurlijke taal (“elke maandag om 9:00”).
- Contactextractie: Met één klik e-mails, telefoonnummers en afbeeldingen verzamelen—volledig gratis.
Voor zakelijke gebruikers betekent dit: van “ik heb deze data nodig” naar “hier is mijn spreadsheet” in een paar minuten. En op basis van gebruikersreviews bouwen zelfs niet-technische mensen leadlijsten, monitoren prijzen en doen onderzoek—zonder ooit code aan te raken.
Probeer Thunderbit gratis op Chrome
Node webcrawlers vs. Thunderbit: wat past bij jou?
Welke aanpak past het beste bij jouw situatie? Hier een vergelijking:
| Criteria | Node.js Web Crawler (eigen code) | Thunderbit (No-code AI-webscraper) |
|---|---|---|
| Installatietijd | Uren tot dagen (coderen, debuggen, instellen) | Minuten (installeren, klikken, scrapen) |
| Technische kennis | Vereist programmeren (Node.js, HTML, selectors) | Geen code nodig; natuurlijke taal & point-and-click |
| Maatwerk | Zeer flexibel; elke logica of workflow mogelijk | Beperkt tot ingebouwde functies en AI-mogelijkheden |
| Schaalbaarheid | Kan enorm opschalen (met extra werk: servers, proxies) | Ingebouwde cloud scraping voor middelgrote tot grote jobs |
| Onderhoud | Doorlopend (code bijwerken als sites veranderen) | Minimaal (Thunderbit’s AI past zich aan) |
| Anti-bot maatregelen | Zelf proxies, vertragingen, headless browsers implementeren | Automatisch geregeld door Thunderbit’s backend |
| Integratie | Diepe integratie mogelijk (API’s, databases, workflows) | Export naar Sheets, Notion, Airtable, Excel, CSV |
| Kosten | Gratis tools, maar ontwikkeltijd en serverkosten | Gratis tier, daarna per gebruik of abonnement |
Wanneer kies je voor Node.js:
- Je hebt zeer specifieke logica of integratie nodig.
- Je hebt ontwikkelaars beschikbaar en wilt volledige controle.
- Je wilt op grote schaal scrapen of een product rond webdata bouwen.
Wanneer kies je voor Thunderbit:
- Je wilt snel resultaat, met minimale setup.
- Je bent geen programmeur (of wilt dat niet zijn).
- Je wilt verschillende sites scrapen voor dagelijkse zakelijke taken.
- Je waardeert gebruiksgemak en AI-gestuurde flexibiliteit.
Veel teams starten met Thunderbit voor snelle resultaten, en stappen pas over op maatwerk met Node als hun behoeften complexer of grootschaliger worden.
Veelvoorkomende uitdagingen bij Node webcrawlers
Node webcrawlers zijn krachtig, maar niet zonder uitdagingen. Dit zijn de grootste struikelblokken (en hoe je ze aanpakt):
- Anti-scraping maatregelen: Websites gebruiken CAPTCHAs, IP-blokkades en botdetectie. Je zult proxies moeten roteren, headers randomiseren en soms headless browsers zoals Puppeteer inzetten (blog.apify.com).
- Dynamische content: Veel sites laden data met JavaScript of infinite scroll. Simpel HTML parsen is dan niet genoeg—je moet browsen simuleren of API’s aanspreken.
- Parsing en datacleaning: Niet elke webpagina is netjes opgebouwd. Je moet omgaan met inconsistente formaten, ontbrekende data en vreemde coderingen.
- Onderhoud: Websites veranderen. Je code zal soms breken. Plan voor regelmatige updates en foutafhandeling.
- Juridische en ethische kwesties: Respecteer altijd
robots.txt, de gebruiksvoorwaarden en privacywetgeving. Scrape geen gevoelige of auteursrechtelijk beschermde data.
Best practices:
- Gebruik frameworks als Crawlee die veel van deze problemen standaard oplossen.
- Bouw retries, vertragingen en foutlogging in.
- Controleer en update je crawlers regelmatig.
- Scrape verantwoord—overbelast sites niet en respecteer de regels.
Node webcrawlers koppelen aan cloudservices
Voor serieuze, doorlopende webdataprojecten is draaien op je laptop niet genoeg. Dan komt cloudintegratie om de hoek kijken:
- Serverless functies: Zet je Node-crawler als AWS Lambda of Google Cloud Function. Plan automatische runs (bijvoorbeeld dagelijks of elk uur) en sla resultaten op in cloudopslag zoals S3 of BigQuery (docs.aws.amazon.com).
- Containerized crawlers: Verpak je crawler in Docker en draai hem op AWS Fargate, Google Cloud Run of Kubernetes. Zo kun je duizenden pagina’s tegelijk scrapen.
- Geautomatiseerde workflows: Gebruik cloudplanners (zoals AWS EventBridge) om crawls te starten, resultaten op te slaan en data direct in dashboards of machine learning-modellen te laden.
De voordelen? Schaalbaarheid, betrouwbaarheid en volledige automatisering. Inmiddels vindt 68% van het webscrapen plaats in de cloud—en dat aandeel groeit alleen maar.
Node webcrawler of no-code oplossing: wanneer kies je wat?
Twijfel je nog? Hier een snelle beslischecklist:
-
Heb je diepgaande maatwerk, unieke workflows of integratie met interne systemen nodig?
→ Node.js webcrawler -
Ben je een zakelijke gebruiker die snel data wil, zonder te programmeren?
→ Thunderbit (of een andere no-code tool) -
Is het een eenmalige of zeldzame taak?
→ Thunderbit -
Is het een cruciale, doorlopende, grootschalige operatie?
→ Node.js (met cloudintegratie) -
Heb je ontwikkelaars en tijd voor onderhoud?
→ Node.js -
Wil je niet-technische teamleden zelf data laten verzamelen?
→ Thunderbit
Mijn advies? Begin met een no-code oplossing voor snelle resultaten en prototyping. Als je behoeften groeien, kun je altijd nog investeren in een eigen Node-crawler. Veel teams merken dat Thunderbit 90% van hun use cases dekt—en enorm veel tijd en frustratie bespaart.
Aan de slag met Thunderbit AI-webscraper
Conclusie: Webdata als groeimotor voor je bedrijf
 Webdata verzamelen is allang niet meer alleen voor techneuten—het is een onmisbare businessvaardigheid geworden. Of je nu je eigen Node webcrawler bouwt of een AI-tool als Thunderbit gebruikt, het doel blijft hetzelfde: van de chaos van het web gestructureerde, bruikbare inzichten maken.
Webdata verzamelen is allang niet meer alleen voor techneuten—het is een onmisbare businessvaardigheid geworden. Of je nu je eigen Node webcrawler bouwt of een AI-tool als Thunderbit gebruikt, het doel blijft hetzelfde: van de chaos van het web gestructureerde, bruikbare inzichten maken.
Node.js biedt ultieme flexibiliteit en kracht, vooral voor complexe of grootschalige projecten. Maar voor de meeste zakelijke gebruikers zorgen no-code, AI-gedreven tools ervoor dat je snel en betrouwbaar de data krijgt die je nodig hebt—zonder te programmeren.
Nu bijna 97% van de organisaties investeert in Big Data en AI, zijn het de teams die webdata beheersen die voorop lopen. Dus of je nu ontwikkelaar, marketeer of gewoon klaar bent met copy-pasten: er is nooit een beter moment geweest om de kracht van webcrawling te benutten.
Zelf proberen? Download Thunderbit gratis en ontdek hoe eenvoudig webdata verzamelen kan zijn. Meer weten? Bekijk de Thunderbit Blog voor extra tips, handleidingen en praktijkverhalen over webautomatisering.
Probeer AI-webscraper gratis Get Started Free
Veelgestelde vragen
1. Wat is het verschil tussen een Node webcrawler en een webscraper?
Een Node webcrawler ontdekt en navigeert automatisch webpagina’s (zoals een spin in een web), terwijl een webscraper specifieke data van die pagina’s verzamelt. De meeste Node-crawlers doen beide: ze vinden pagina’s en halen de gewenste informatie op.
2. Waarom is Node.js populair voor het bouwen van webcrawlers?
Node.js is event-driven en non-blocking, waardoor het veel paginaverzoeken tegelijk aankan. Het is snel, heeft een groot aanbod aan bibliotheken en is ideaal voor realtime of grootschalige data-extractie.
3. Wat zijn de grootste uitdagingen bij Node webcrawlers?
Veelvoorkomende problemen zijn anti-botmaatregelen (CAPTCHAs, IP-blokkades), dynamische content (JavaScript-rijke sites), datacleaning en onderhoud als websites veranderen. Frameworks en best practices helpen, maar vereisen technische kennis.
4. Hoe verschilt Thunderbit van een Node webcrawler?
Thunderbit is een no-code, AI-gestuurde webscraper. In plaats van te programmeren gebruik je een Chrome-extensie en natuurlijke taal om data te verzamelen. Ideaal voor zakelijke gebruikers die snel resultaat willen zonder te coderen.
5. Wanneer kies ik voor een Node webcrawler of Thunderbit?
Gebruik Node.js voor zeer maatwerk, grootschalige of diep geïntegreerde projecten—vooral als je ontwikkelaars hebt. Gebruik Thunderbit voor snelle, dagelijkse scraping-taken of als je niet-technische teamleden zelf data wilt laten verzamelen.
Klaar om je webdata-skills te verbeteren? Probeer Thunderbit of lees verder op de Thunderbit Blog. Veel succes met crawlen!
Meer weten




