Heb je wel eens op een website gezeten waar je amper info kon vinden en je eindeloos op links moest klikken om te krijgen wat je zocht? Super frustrerend, zeker nu steeds meer sites hun belangrijkste gegevens verstoppen op subpagina’s. Hierdoor wordt het verzamelen van grote hoeveelheden data een stuk ingewikkelder. Programmeurs zijn uren bezig met het schrijven van scripts om al die subpagina’s af te speuren, terwijl niet-programmeurs handmatig op elke link moeten klikken. Gelukkig zijn er oplossingen: lijst-crawling (ook wel bulk scraping genoemd) en subpagina-scraping.
Lijst-crawling en subpagina-scraping in het kort
| Tool | Gebruiksgemak | Datakwaliteit | Beste toepassing |
|---|---|---|---|
| Lijst-crawling | ★★ | ★★★ | Grote websites |
| Subpagina-scraping | ★★★★★ | ★★★★ | Snel en gericht data verzamelen, specifieke data-indelingen |
Wat is lijst-crawling?
Lijst-crawling, of bulk scraping, is een webscraping-methode waarbij je data ophaalt van een lijst met URL’s. Je begint met het samenstellen van een lijst met webadressen, vaak met behulp van een andere crawler. Het succes van lijst-crawling hangt sterk af van de kwaliteit van deze lijst. Als de URL’s naar pagina’s met verschillende opmaak verwijzen, krijg je rommelige resultaten en kost het veel tijd om alles te verwerken. Deze aanpak is ideaal voor bedrijven, onderzoekers en data-analisten die grote hoeveelheden gestructureerde en consistente webdata willen verzamelen. Vaak moet de data achteraf nog wel handmatig opgeschoond en geordend worden om bruikbaar te zijn.
Hoe werkt het?

Het proces van lijst-crawling bestaat meestal uit de volgende stappen:
- Stel een URL-lijst samen: Begin met een lijst van webpagina’s die je wilt uitlezen.
- Stuur HTTP-verzoeken: Het systeem haalt de HTML-inhoud op van deze URL’s.
- Extraheer data: Gebruik parsing-methodes zoals BeautifulSoup, XPath of reguliere expressies om de gewenste informatie (zoals tekst, afbeeldingen en links) te verzamelen.
- Sla de data op: Organiseer en bewaar de verzamelde data in een database of spreadsheet voor verdere analyse.
Na het verzamelen is het belangrijk om de data te schonen en te analyseren, bijvoorbeeld met beschrijvende statistiek, tijdreeksanalyse, correlatieanalyse of clustering. AI kan dit proces versnellen en verbeteren door taken te automatiseren en de datakwaliteit te verhogen.
Bekijk de Bulk Scraping-functie in Thunderbit AI-webscraper voor een soepele workflow.
Aanbevolen tools
-
- Voordelen: Makkelijk in gebruik, flexibele parsing, krachtige functies
- Nadelen: Draait lokaal en is afhankelijk van je browser
- Ideaal voor: Kwalitatieve dataverzameling waarbij datakwaliteit belangrijker is dan kwantiteit
- Scrapy
- Voordelen: Krachtig, heel flexibel, geschikt voor grootschalige scraping
- Nadelen: Steile leercurve, je moet kunnen programmeren
- Ideaal voor: Grote dataverzamelingsprojecten
- Beautiful Soup
- Voordelen: Simpel in gebruik, veel documentatie, flexibele parsing
- Nadelen: Gemiddelde prestaties, geen ondersteuning voor asynchrone operaties
- Ideaal voor: Kleine scraping-projecten, data-analyse
- Selenium
- Voordelen: Perfect voor dynamische pagina’s, kan gebruikersgedrag nadoen
- Nadelen: Traag, vraagt veel van je computer
- Ideaal voor: Pagina’s die met JavaScript worden geladen
Subpagina-scraping uitgelegd

Wat is subpagina-scraping?
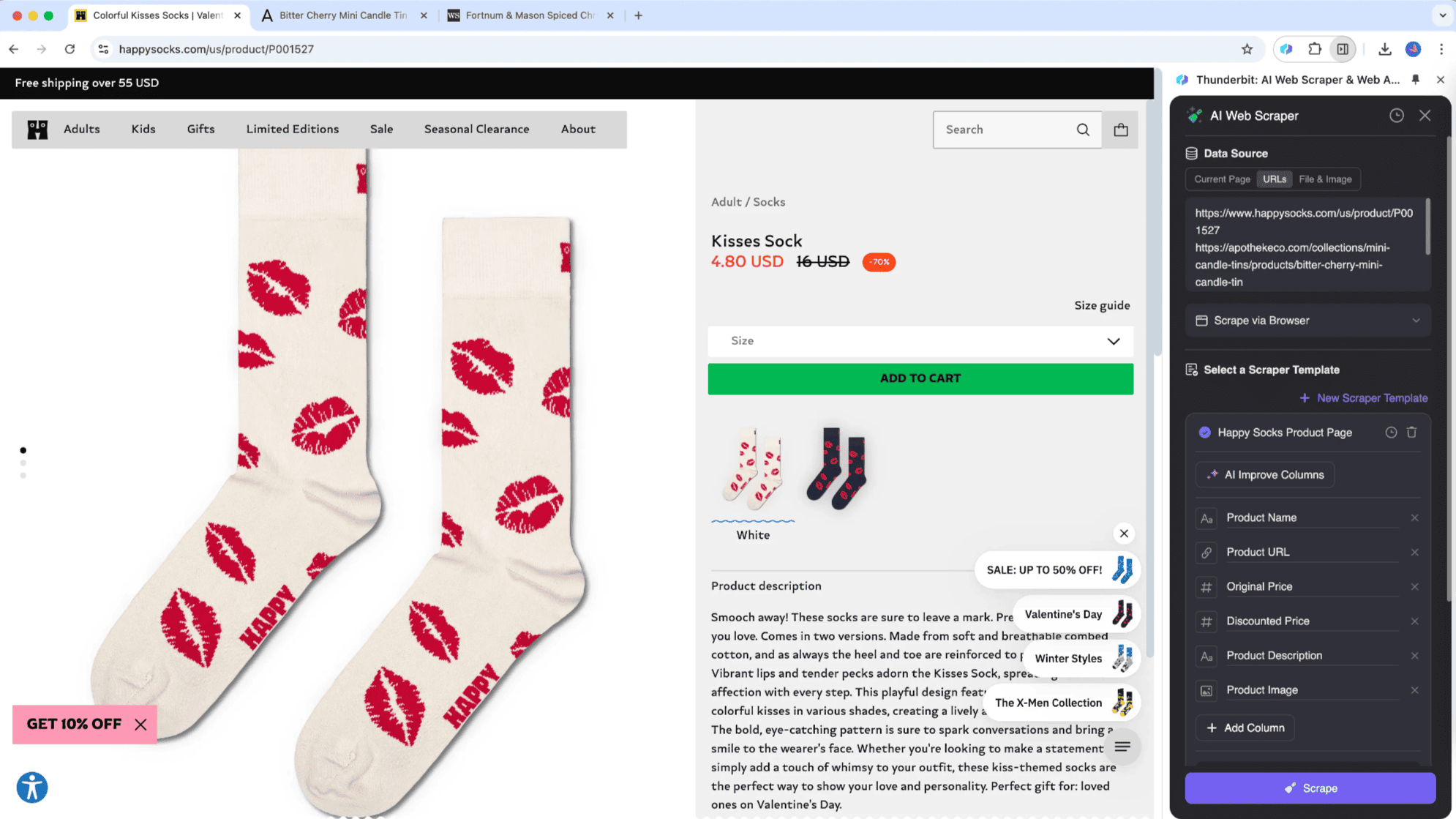
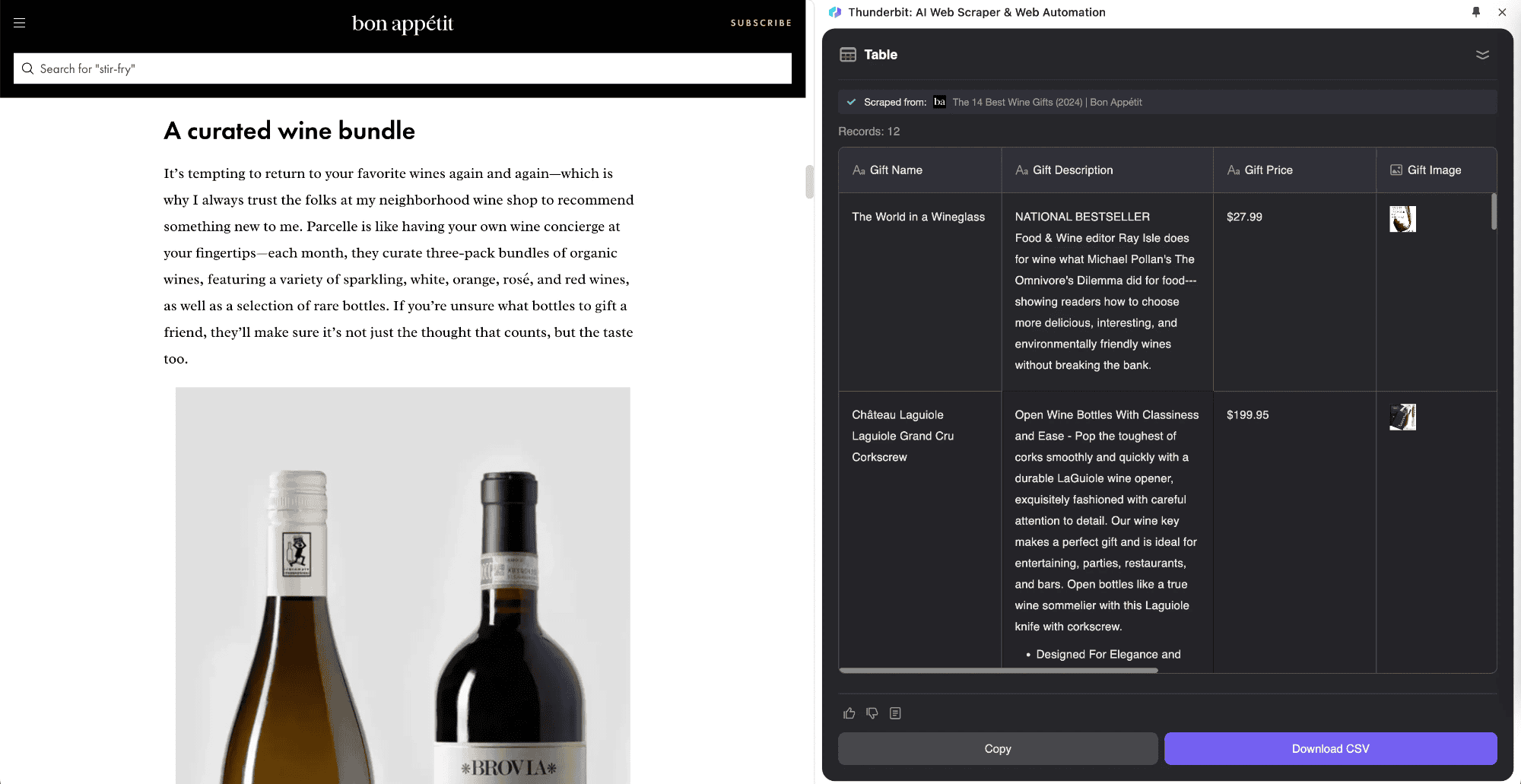
Subpagina-scraping is een webscraping-methode waarbij je lijstddata van één webpagina haalt en de informatie van subpagina’s samenvoegt in een hoofdtafel. Thunderbit heeft deze innovatieve aanpak geïntroduceerd met de AI-functies van de AI-webscraper. Het is ideaal voor pagina’s met veel subpagina’s, zoals productoverzichten, blogs en navigatiesites. Het grote voordeel is dat subpagina-scraping slim informatie van subpagina’s kan verzamelen en direct in de hoofdtafel kan plaatsen.
Stel, je leest een artikel over "Aandelenmarkt Vandaag" en wilt een lijst van alle beurskoersen verzamelen. Met de kun je je tabel definiëren, waarna de tool automatisch de koersen ophaalt en de realtime gegevens van de subpagina’s toevoegt aan je hoofdtafel. Zo kun je tijdens het lezen direct actuele informatie vastleggen. Thunderbit’s AI-webscraper past zich aan verschillende pagina’s aan, iets wat traditionele scraping-tools niet kunnen.
Waarom zou je het gebruiken?
Thunderbit AI-webscraper zit boordevol functies die het verzamelen en verwerken van data sneller en nauwkeuriger maken.
Slimme data-extractie
Thunderbit AI-webscraper gebruikt AI om data slim te extraheren en past zich automatisch aan als de structuur van een webpagina verandert. Je kunt in gewone taal aangeven welke data je wilt, waarna het systeem zelf de extractieregels opstelt. Deze slimme aanpak verhoogt de nauwkeurigheid en verlaagt de technische drempel, zodat ook niet-technische gebruikers eenvoudig data kunnen verzamelen. Thunderbit ondersteunt verschillende datatypes, zoals tekst, links en afbeeldingen, en is daarmee geschikt voor uiteenlopende toepassingen.
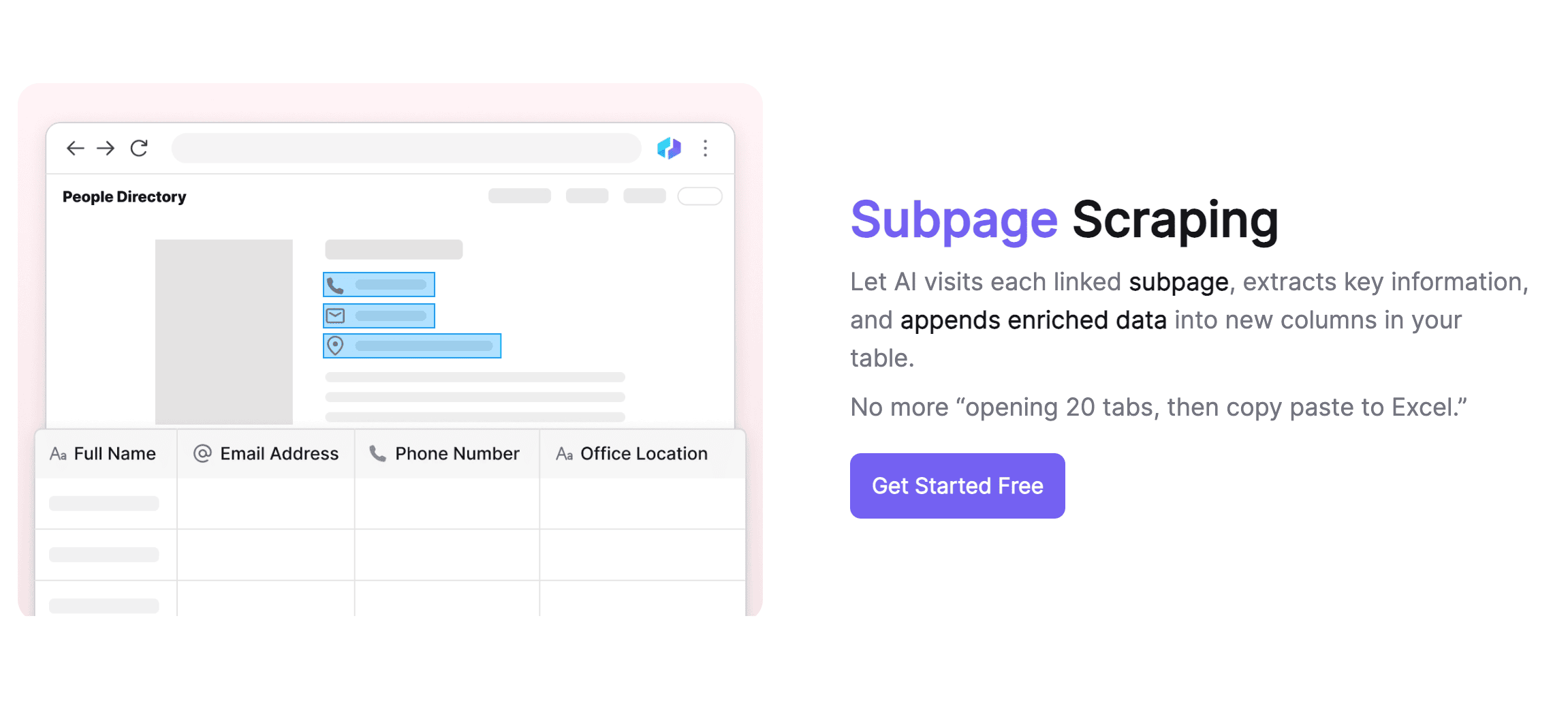
Geavanceerde subpagina-verwerking
Thunderbit blinkt uit in het verwerken van subpagina’s. De tool herkent en bezoekt subpagina’s automatisch en kan met één sjabloon verschillende layouts aan. Dankzij AI past Thunderbit zich aan als de structuur van een pagina verandert, zodat je je geen zorgen hoeft te maken over verschillende subpagina’s. De tool voegt automatisch de inhoud van subpagina’s samen in de hoofdtafel, waardoor je informatie overzichtelijk blijft. Ook op het gebied van datakwaliteit scoort Thunderbit hoog: het werkt als een AI-assistent die data opschoont, opmaakt en repeterende taken zoals labelen automatiseert.
Efficiënt databeheer
Thunderbit biedt handige functies voor databeheer, met ondersteuning voor verschillende exportformaten en koppelingen met platforms als Google Sheets, Airtable en Notion. Je kunt een scraper-sjabloon koppelen aan een Google Sheet om alle verzamelde data centraal te beheren, of aan Notion om data direct in een Notion-database te plaatsen. Dankzij deze flexibele exportopties kies je altijd de opslagmethode die bij jouw workflow past. Automatische labeling en classificatie zorgen ervoor dat de data direct aansluit op het platform waar je mee werkt, wat het beheer een stuk efficiënter maakt.
Handige vooringestelde sjablonen
Om gebruikers nog sneller op weg te helpen, biedt Thunderbit een breed scala aan vooringestelde sjablonen. Denk aan sjablonen voor e-commerce (zoals , ), vastgoeddata (zoals ), social media-analyse (zoals , ) en bedrijfsinformatie (zoals bedrijfswebsites en bedrijvengidsen). Deze sjablonen besparen tijd en zorgen voor consistente en betrouwbare dataverzameling.
Stapsgewijze implementatie
Subpagina-scraping uitvoeren
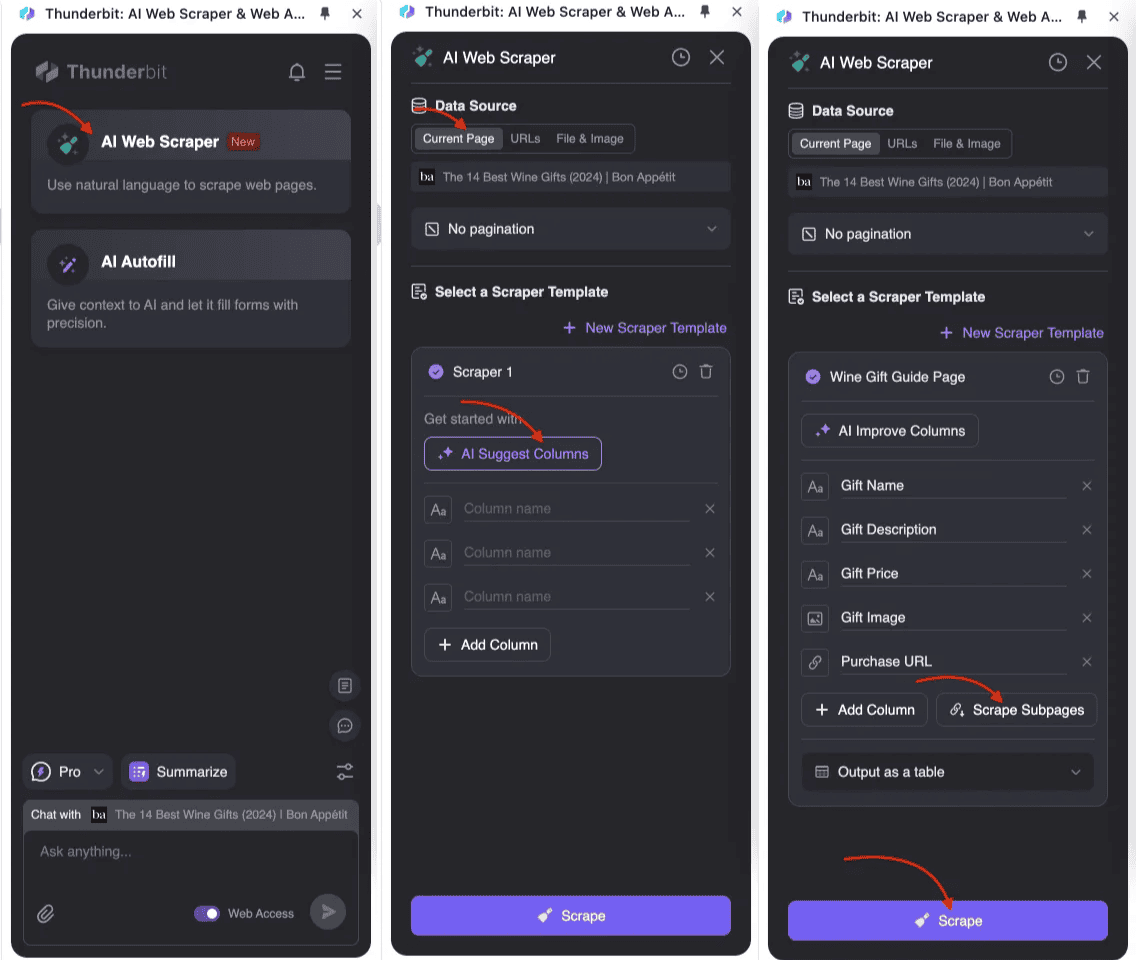
- : Open Thunderbit AI-webscraper en maak een nieuw scraper-sjabloon aan.
- Definieer de structuur van je hoofdtafel: Voeg in de tabelinstellingen de velden toe die je wilt verzamelen, zoals titel, prijs en omschrijving. Voor data van subpagina’s maak je bijbehorende velden aan en schakel je subpagina-scraping in.
- Start de scraper: Thunderbit haalt eerst de lijstdata van de hoofdpagina op, bezoekt daarna automatisch elke subpagina, verzamelt de relevante informatie en voegt deze samen in de hoofdtafel. Alles wordt aangestuurd door AI, zonder dat je hoeft te programmeren.
Lijst-crawling uitvoeren
Voor ontwikkelaars zijn er verschillende programmeertalen en tools om lijst-crawling te implementeren. Python is het populairst vanwege de eenvoud en de vele beschikbare libraries. Hieronder een basisvoorbeeld in Python met requests en BeautifulSoup:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4def scrape_urls(urls):
5 data = []
6 for url in urls:
7 response = requests.get(url)
8 soup = BeautifulSoup(response.text, 'html.parser')
9 titles = soup.find_all('h2', class_='product-title')
10 prices = soup.find_all('span', class_='product-price')
11 for title, price in zip(titles, prices):
12 data.append({
13 'title': title.get_text(),
14 'price': price.get_text()
15 })
16 return pd.DataFrame(data)
17# Voorbeeldgebruik
18urls = ['<http://example.com/product1>', '<http://example.com/product2>']
19data_frame = scrape_urls(urls)
20print(data_frame)Conclusie
Data is tegenwoordig de motor van elk bedrijf. Wie data slim weet te verzamelen en te analyseren, heeft een streepje voor. Data geeft inzicht in marktontwikkelingen en klantbehoeften, en vormt de basis voor productontwikkeling en marketing. Maar het efficiënt verzamelen en structureren van de enorme hoeveelheid verspreide data op het internet blijft een uitdaging.
Met tools als Thunderbit hoef je je daar geen zorgen meer over te maken. Het is alsof je een digitale assistent hebt die je helpt om waardevolle informatie uit grote datasets te halen, zodat je met meer vertrouwen beslissingen kunt nemen. Dankzij de slimme dataverzameling en -verwerking kun je eenvoudig concurrentie-informatie, markttrends, gebruikersreviews en andere belangrijke data verzamelen voor betere bedrijfsbeslissingen.
Thunderbit biedt niet alleen handige functies voor dataverzameling, maar ook krachtige mogelijkheden voor data-analyse. De tool kan automatisch data opschonen en structureren, en overzichtelijke rapporten genereren waarmee je snel verborgen inzichten ontdekt. Voor bedrijven die regelmatig de markt willen monitoren, is de automatische verzameloptie van Thunderbit een tijdbesparende en efficiënte keuze.
In deze data-gedreven tijd is een tool als Thunderbit onmisbaar. Het verhoogt de efficiëntie van dataverzameling en ondersteunt bedrijven bij hun digitale transformatie. Nu data steeds belangrijker wordt voor zakelijke beslissingen, zijn slimme dataverzamelingstools zoals Thunderbit een waardevol concurrentievoordeel.
Veelgestelde vragen
-
Wat is Thunderbit? is een Chrome-extensie die zakelijke gebruikers helpt om webtaken te automatiseren. Je vindt er functies als AI-webscraper, AI-klembord en AI-webchat om data te verzamelen, formulieren in te vullen en met behulp van AI. Het is een productiviteitstool die tijd bespaart en repetitieve online taken vereenvoudigt.
-
Hoe werkt de AI-webscraper van Thunderbit? De AI-webscraper van Thunderbit gebruikt AI om gestructureerde data van websites te halen. Je kunt op "AI Kolommen voorstellen" klikken zodat de AI suggesties doet voor het scrapen van de huidige website, en daarna op "Scrapen" om de data te verzamelen. Je kunt data van elke website, PDF of afbeelding ophalen in slechts twee klikken.
-
Wat is het verschil tussen lijst-crawling en subpagina-scraping? Lijst-crawling, of bulk scraping, betekent data verzamelen van een lijst met URL’s en is ideaal voor grote websites. Subpagina-scraping haalt data van één webpagina en de bijbehorende subpagina’s, en voegt alles samen in een hoofdtafel. Thunderbit’s AI-webscraper blinkt uit in beide methodes en biedt slimme data-extractie en -beheer.
-
Kunnen niet-programmeurs Thunderbit gebruiken? Zeker! Thunderbit is ontworpen voor gebruiksgemak, ook voor mensen zonder programmeerkennis. Dankzij de AI-functies kun je in gewone taal aangeven welke data je wilt, waarna het systeem zelf de extractieregels opstelt. Zo is het toegankelijk voor iedereen.
-
Welke soorten data kan Thunderbit verwerken? Thunderbit ondersteunt verschillende datatypes, zoals tekst, links en afbeeldingen. Het is geschikt voor uiteenlopende toepassingen, zoals e-commerce, vastgoeddata, social media-analyse en bedrijfsinformatie.
-
Hoe begin ik met Thunderbit? Je kunt de Thunderbit Chrome-extensie downloaden via de . Na installatie kun je de functies zoals AI-webscraper, AI-klembord en AI-webchat direct gebruiken om je webproductiviteit te verhogen.
-
Biedt Thunderbit vooringestelde sjablonen? Ja, Thunderbit heeft een ruime keuze aan om je werk te versnellen. Deze sjablonen zijn geschikt voor e-commerce, vastgoed, social media en bedrijfsinformatie, zodat je snel en consistent data kunt verzamelen.
-
Hoe waarborgt Thunderbit de datakwaliteit? Thunderbit gebruikt AI om data slim te extraheren en te verwerken, en past zich automatisch aan als de structuur van een webpagina verandert. Daarnaast zijn er functies voor het opschonen en formatteren van data, zodat repeterende taken automatisch worden uitgevoerd en de datakwaliteit hoog blijft.
-
Toepassingen van webscraping Er zijn talloze praktische toepassingen voor . Zo kun je voor marktonderzoek, of voor documentanalyse. Veel bedrijven willen voor verdere analyse. Met AI-gedreven tools kun je nu zonder ingewikkelde code te schrijven. Voor social media-analyse kun je gebruikmaken van gespecialiseerde tools zoals of om relevante data te verzamelen voor je marketingcampagnes.
Meer weten: