

Het internet is tegenwoordig een stuk chaotischer—en eerlijk gezegd ook veel boeiender—dan in de tijd dat je gewoon even 'rechtsklik, opslaan als' deed en klaar was je. Websites zijn nu echte doolhoven vol dynamische content, verborgen links, pop-ups en gelaagde menu’s. Heb je ooit geprobeerd om alle productinformatie van een moderne webshop te verzamelen, of elk aanbod van een vastgoedplatform te exporteren? Dan weet je dat simpele webscrapers niet meer voldoen. Hier komen deep crawlers om de hoek kijken—de nieuwe generatie webscrapingtools die dieper graven, verder gaan en precies die data ophalen die er écht toe doet.
Maar wat is een deep crawler nou eigenlijk? Waarom zijn bedrijven—van sales tot marktonderzoek—er ineens zo enthousiast over? En hoe zorgt een tool als Thunderbit ervoor dat deep crawling voor iedereen toegankelijk wordt, zelfs als je geen programmeur bent? We leggen het je uit: van de basis tot de impact op je business, en waarom deep crawlers razendsnel het geheime wapen worden voor moderne webdata-extractie.
Wat is een Deep Crawler? De Basis Uitgelegd
Gebruik AI om data van elke website te halen Get Started Free
Een deep crawler is in de kern een slimme webscraper die speciaal is gemaakt om data te verzamelen van complexe, gelaagde en vaak dynamische websites. In tegenstelling tot traditionele crawlers—die alleen de zichtbare info op de hoofdpagina pakken—volgt een deep crawler links, navigeert door meerdere lagen, en verwerkt alles van paginatie tot content die verstopt zit achter tabbladen of uitklapbare secties.
Zie een traditionele crawler als iemand die snel door een bibliotheek loopt en alleen de titels op de voorste planken noteert. Een deep crawler is degene die elk gangpad afstruint, boeken openslaat, de voetnoten leest en zelfs achter de deur 'Alleen personeel' kijkt (zolang die niet op slot zit).
In de praktijk betekent dit dat een deep crawler:
- Door meerdere lagen van een website navigeert (categorieën, subcategorieën, detailpagina’s)
- Dynamische content ophaalt die via JavaScript wordt geladen of pas zichtbaar wordt na interactie
- Complexe paginatie en oneindig scrollen aankan
- Interne links volgt zodat geen relevante data wordt gemist
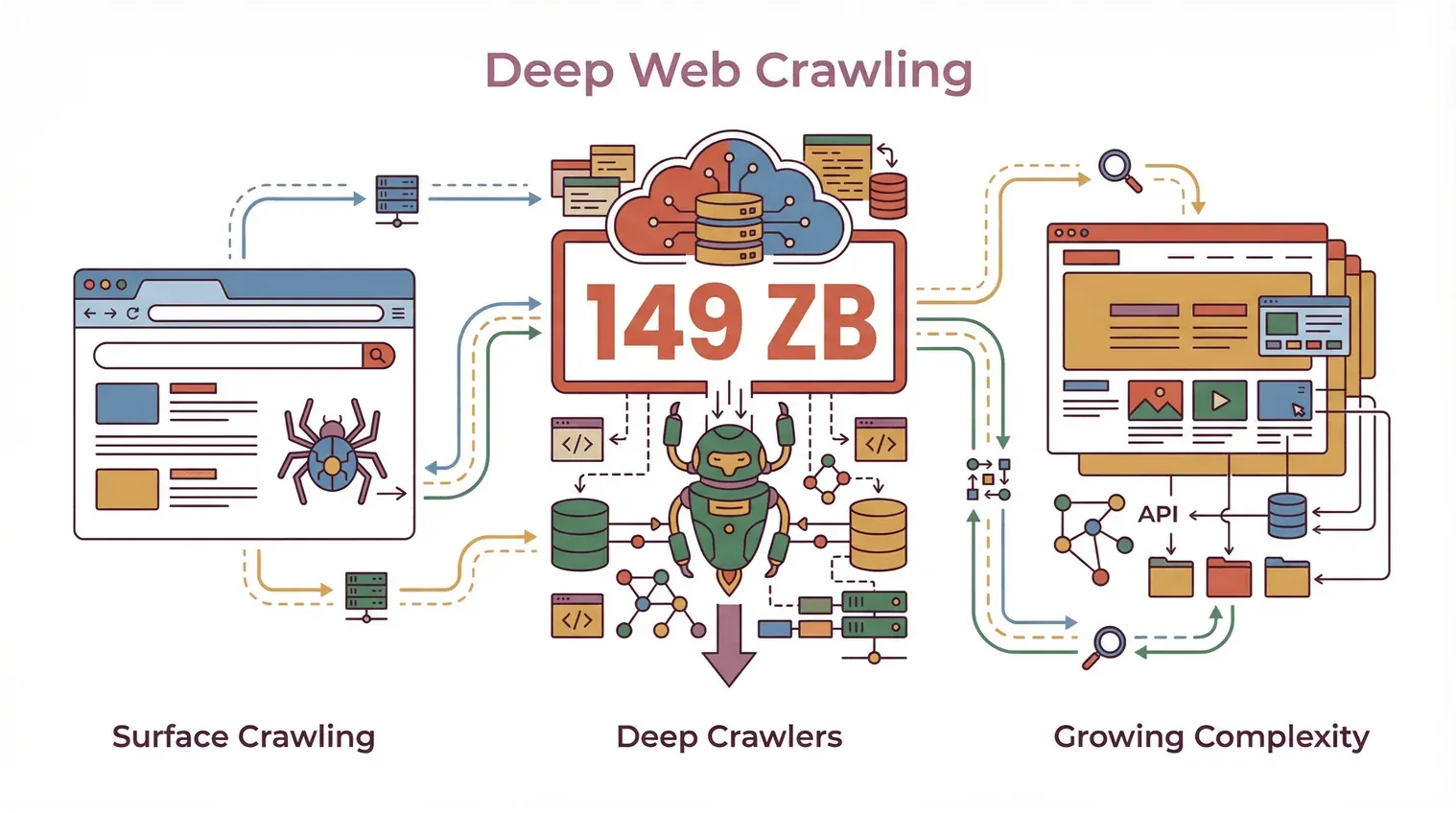 Met wereldwijd 149 zettabyte aan webdata in 2024 en websites die elk jaar ingewikkelder worden, zijn deep crawlers onmisbaar voor iedereen die meer wil dan alleen een oppervlakkige scan van het web.
Met wereldwijd 149 zettabyte aan webdata in 2024 en websites die elk jaar ingewikkelder worden, zijn deep crawlers onmisbaar voor iedereen die meer wil dan alleen een oppervlakkige scan van het web.
Deep Crawler vs. Traditionele Crawler: Wat is het Verschil?
Laten we het concreet maken. Wat maakt een deep crawler anders dan de 'gewone' crawlers?
Traditionele Crawlers: Oppervlakkig Scannen
Traditionele webcrawlers (ook wel 'shallow crawlers' genoemd) zijn gebouwd voor snelheid en bereik. Ze scannen snel een site, pakken wat er op de hoofdpagina’s staat, en gaan weer verder. Dit is hoe zoekmachines werken: ze willen zoveel mogelijk pagina’s indexeren, zo snel mogelijk, maar gaan niet diep in op elke hoek van een site.
Beperkingen van traditionele crawlers:
- Missen vaak data die verstopt zit achter navigatie, tabbladen of dynamische elementen
- Hebben moeite met sites die zwaar op JavaScript leunen of content die pas later laadt
- Kunnen niet omgaan met meerstapsnavigatie of complexe paginavormen
- Leveren vaak onvolledige of gefragmenteerde datasets op
Deep Crawlers: Verder dan het Oppervlakkige
Een deep crawler is juist gemaakt om een website volledig te doorzoeken—elke relevante link te volgen, door paginatie te klikken, en data te halen uit subpagina’s, pop-ups en dynamisch geladen content. Het draait minder om snelheid, meer om volledigheid en precisie.
Belangrijke eigenschappen van deep crawlers:
- Geavanceerde navigatie: Kan links herhaaldelijk volgen, meerlagige sitestructuren aan, en voorkomt dubbele of dode pagina’s (SEO-Wiki).
- Dynamische content extractie: Interageert met JavaScript, klapt verborgen secties uit, en haalt data op die pas na gebruikersacties zichtbaar wordt (Scientific Reports).
- Efficiëntie: Richt zich op relevante delen van de site, voorkomt dubbele of irrelevante data, en zorgt dat niets belangrijks wordt gemist (Medium).
- Volledige datasets: Zorgt dat alle lagen van informatie—hoofdvermeldingen, detailpagina’s, gerelateerde documenten—worden meegenomen.
Als je ooit alle reviews van een productpagina wilde scrapen, of elk aanbod van een vastgoedsite (inclusief de makelaarsinfo op een aparte subpagina), dan heb je vast de grenzen van traditionele crawlers ervaren. Deep crawlers lossen dat op.
Hoe Deep Crawlers Zorgen voor Volledige Data en Geavanceerde Navigatie
Hoe werkt deep crawling nu precies? Het draait om links volgen, herhaald navigeren en slim omgaan met dynamische content.
Subpagina’s Scrapen en Meerdere Lagen Doorzoeken
Een deep crawler stopt niet bij de eerste pagina. Hij:
- Herken interne links (zoals 'Bekijk details', 'Volgende pagina', of 'Meer info')
- Volgt die links naar subpagina’s, detailweergaven of zelfs pop-ups
- Haalt data uit elke laag en combineert alles tot één gestructureerde dataset
Deze aanpak heet ook wel 'recursief crawlen' of 'meerlags scraping'. Vooral handig bij sites waar informatie verspreid is over meerdere pagina’s—denk aan productoverzichten met aparte detailpagina’s, of bedrijvengidsen waar contactinfo pas na doorklikken zichtbaar wordt.
Omgaan met Paginatie en Dynamische Content
Moderne websites verstoppen data vaak achter 'Laad meer'-knoppen, oneindig scrollen of JavaScript-tabbladen. Deep crawlers zijn gemaakt om:
- Paginatie te herkennen en bedienen
- Door dynamische elementen te scrollen of klikken
- Te wachten tot content geladen is voordat data wordt opgehaald
Zo krijg je een volledige dataset, niet alleen wat er direct zichtbaar was bij het laden van de pagina (Thunderbit Blog).
Diepe Linktracking en Meerlags Scraping
Een van de lastigste onderdelen van deep crawling is zorgen dat je geen verborgen of geneste data mist. Deep crawlers gebruiken algoritmes om:
- Bij te houden welke links al bezocht zijn (om dubbele data of loops te voorkomen)
- Belangrijke pagina’s te prioriteren (zoals detailweergaven of downloadbare documenten)
- Edge cases te verwerken (zoals pop-ups, uitklapbare secties of AJAX-content)
Dit is vooral belangrijk voor zakelijke toepassingen—het missen van één contactpersoon of productspecificatie kan kansen kosten of analyses onvolledig maken (Simplescraper).
Thunderbit: Deep Crawling Simpel Gemaakt met AI
Eerlijk is eerlijk: deep crawling was vroeger alleen weggelegd voor hardcore developers en data engineers. Je moest zelf scripts schrijven, uitzonderingen afhandelen en telkens je code aanpassen als een website veranderde. Met Thunderbit wilden we deep crawling voor iedereen toegankelijk maken—ook als je nog nooit hebt geprogrammeerd.
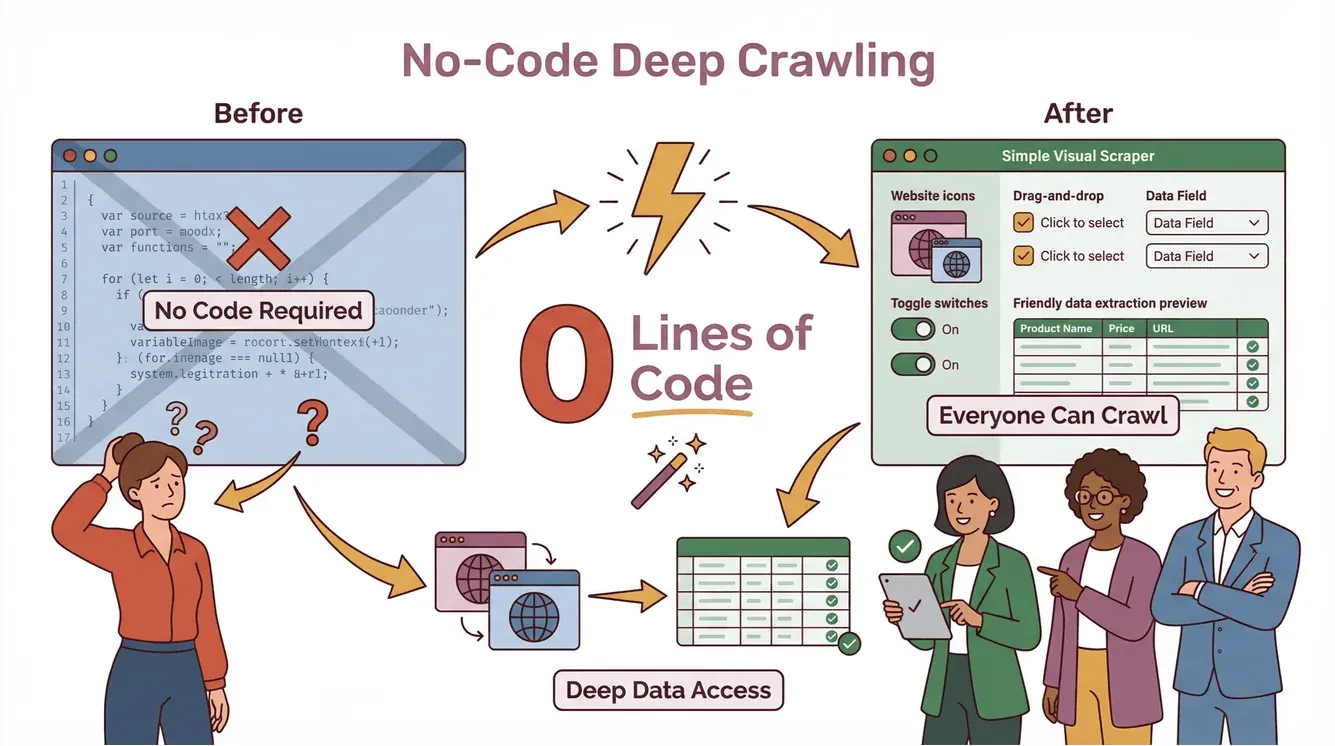
Thunderbit’s Deep Crawler in de Praktijk
Zo maakt Thunderbit deep crawling eenvoudig:
- AI Suggest Fields: Klik op 'AI Suggest Fields' en Thunderbit’s AI scant de pagina, stelt de beste kolommen voor en maakt automatisch prompts voor elk veld.
- Subpagina’s Scrapen: Meer details nodig? Thunderbit bezoekt automatisch elke subpagina (zoals productdetails, makelaarsprofielen of reviewtabbladen) en verrijkt je tabel met extra data.
- Dynamische Content: Thunderbit regelt paginatie, oneindig scrollen en dynamische elementen—zonder handmatige instellingen.
- No-code, twee stappen: Beschrijf wat je wilt, klik op 'Scrape', en Thunderbit doet de rest. Exporteer direct naar Excel, Google Sheets, Notion of Airtable—zonder extra kosten of limieten (Thunderbit Blog).
Probeer Thunderbit Deep Crawler gratis
Stapsgewijs Voorbeeld: Deep Crawling met Thunderbit
Stel, je wilt alle vastgoedaanbiedingen van een site scrapen, inclusief makelaarsgegevens die op subpagina’s staan:
- Open de aanbodpagina in Chrome.
- Klik op de Thunderbit-extensie.
- Gebruik 'AI Suggest Fields' zodat Thunderbit kolommen als 'Titel', 'Prijs', 'Adres' en 'Makelaarslink' voorstelt.
- Klik op 'Scrape'. Thunderbit haalt alle hoofdvermeldingen op.
- Klik op 'Scrape Subpages'. Thunderbit bezoekt elk makelaarsprofiel, haalt telefoonnummers, e-mails en meer op, en voegt dit samen in je hoofdtabel.
- Exporteer je data naar Google Sheets of Excel—klaar voor je sales- of operationeel team.
Geen code, geen sjablonen, geen gedoe. En als de website verandert, past Thunderbit’s AI zich automatisch aan (Thunderbit Docs).
Zakelijke Voordelen: Hoe Deep Crawlers Sales en Marketing Versterken
Klinkt goed, maar wat levert het zakelijk op? Hier wordt het interessant.
Waardevolle Inzichten uit E-commerce, Vastgoed en Concurrenten
Voor sales- en marketingteams zijn deep crawlers goud waard. Je kunt:
- Alle producten, prijzen en reviews verzamelen van webshops—zelfs als de data diep verstopt zit
- Vastgoedaanbiedingen samenvoegen (inclusief verborgen makelaarsinfo of extra details)
- Concurrenten monitoren op nieuwe producten, prijswijzigingen of markttrends (GetMonetizely)
- Rijkere leadlijsten bouwen door contactinfo te verzamelen uit bedrijvengidsen, eventsites of nicheplatforms
Met deep crawling krijg je niet alleen meer data—maar vooral betere, bruikbare data die direct bijdraagt aan je bedrijfsresultaten.
Deep Scraping voor Concurrentievoordeel
Stel, je salesafdeling wil bedrijven benaderen die net een nieuw product hebben gelanceerd. Een deep crawler kan:
- Nieuwe productpagina’s op concurrentensites vinden
- Links volgen naar persberichten of investeerdersupdates
- Belangrijke details verzamelen (lanceringsdata, prijzen, features)
- Die data direct in je CRM of analysetools zetten
Het resultaat? Snellere, slimmere beslissingen—en een voorsprong op teams die nog met oppervlakkige scraping werken.
Compliance en Best Practices: Waar Moet je op Letten bij Deep Crawling?
Met grote crawlingkracht komt grote verantwoordelijkheid. Deep crawlers kunnen veel data verzamelen—maar dat betekent niet dat je alles zomaar mag pakken. Let op het volgende:
Privacy en Auteursrecht
- Respecteer de gebruiksvoorwaarden van websites: Veel sites geven in hun TOS aan wat wel en niet mag. Overtreding kan juridische problemen opleveren (Apify Blog).
- Vermijd het scrapen van persoonlijke of vertrouwelijke data zonder expliciete toestemming.
- Let op auteursrechten: Publiceer of verkoop geen gescrapete content zonder de rechten te checken.
Verantwoord Crawlen
- Beperk het aantal verzoeken: Overbelast websites niet met te veel aanvragen tegelijk.
- Check robots.txt: Niet wettelijk bindend, maar het is netjes om de crawlvoorkeuren van sites te respecteren.
- Blijf op de hoogte van wetgeving: Regels als AVG en CCPA bepalen welke data je mag verzamelen en hoe je die gebruikt (Octoparse).
Meer weten? Lees Is Web Scraping Legaal in 2025?.
De Juiste Deep Crawler Kiezen voor Jouw Organisatie
Bekijk Thunderbit Prijzen Betaalbaar deep crawling voor teams van elke omvang. Get Started Free
Waar let je op bij het kiezen van een deep crawler? Dit zijn belangrijke punten:
- Gebruiksgemak: Kunnen niet-technische gebruikers er direct mee aan de slag? (Thunderbit: ja.)
- Schaalbaarheid: Kan het grote sites, veel pagina’s en dynamische content aan?
- Compliance-tools: Helpt het je om aan de regels te voldoen?
- Integratie: Kun je data exporteren naar de tools die je team al gebruikt (Excel, Sheets, Notion, Airtable)?
- Onderhoud: Past het zich automatisch aan bij websitewijzigingen, of moet je elke week scripts repareren?
Thunderbit is op al deze punten gebouwd. Het wordt vertrouwd door 30.000+ gebruikers wereldwijd, van solo-ondernemers tot grote teams, en is zo geprijsd dat zelfs kleine bedrijven al vanaf $15/maand kunnen starten.
Start met Deep Crawling via Thunderbit
Samenvatting: De Toekomst van Deep Crawling in Data Strategie
Kort samengevat:
- Deep crawlers zijn onmisbaar voor het verzamelen van volledige, nauwkeurige data van moderne, complexe websites.
- Ze gaan verder dan traditionele crawlers door meerlagige navigatie, dynamische content en verborgen data te verwerken.
- Bedrijfsteams gebruiken deep crawlers om inzichten te ontsluiten, sales te stimuleren, concurrenten te monitoren en sneller te beslissen.
- Compliance is belangrijk: Scrape altijd verantwoord, respecteer privacy en volg de regels.
- Thunderbit maakt deep crawling toegankelijk voor iedereen, met AI-functies, no-code setup en eenvoudige data-export.
Klaar om verder te gaan dan oppervlakkig scrapen? Download de Thunderbit Chrome-extensie en ontdek zelf hoe eenvoudig deep crawling kan zijn. Meer tips? Bekijk de Thunderbit Blog voor handleidingen, best practices en het laatste nieuws over AI-webscraping.
Veelgestelde Vragen
1. Wat is een deep crawler en hoe verschilt het van een gewone webcrawler?
Een deep crawler is een webscrapingtool die meerdere lagen van een website doorzoekt en data verzamelt van subpagina’s, dynamische content en verborgen secties. In tegenstelling tot traditionele crawlers, die alleen de oppervlakte scannen, zorgt een deep crawler voor volledige dataverzameling door links te volgen en complexe sitestructuren aan te kunnen.
2. Waarom hebben bedrijven in 2025 deep crawlers nodig?
Websites zijn complexer dan ooit, met data die vaak verstopt zit achter navigatie, tabbladen of dynamische elementen. Deep crawlers helpen bedrijven om complete datasets te verzamelen voor sales, marketing, onderzoek en concurrentieanalyse—iets wat basis crawlers niet kunnen.
3. Hoe maakt Thunderbit deep crawling eenvoudig voor niet-technische gebruikers?
Thunderbit gebruikt AI om velden voor te stellen, subpagina’s te scrapen en dynamische content te verwerken—alles via een simpele, no-code interface. Gebruikers beschrijven wat ze willen, klikken op 'Scrape' en exporteren de resultaten naar hun favoriete tools.
4. Met welke compliance-kwesties moet ik rekening houden bij het gebruik van een deep crawler?
Respecteer altijd de gebruiksvoorwaarden van websites, scrape geen persoonlijke of vertrouwelijke data zonder toestemming, en blijf op de hoogte van privacywetgeving zoals AVG en CCPA. Verantwoord crawlen en zorgvuldig omgaan met data minimaliseert juridische risico’s.
5. Kunnen deep crawlers mijn sales- en marketingteam betere resultaten opleveren?
Zeker. Deep crawlers ontsluiten rijkere, bruikbare data van e-commerce, vastgoed en concurrenten—ideaal voor leadgeneratie, marktanalyse en snellere besluitvorming. Met tools als Thunderbit kunnen zelfs niet-technische teams de inzichten verzamelen die ze nodig hebben om te groeien.
Probeer AI Deep Crawler met Thunderbit Get Started Free
Meer weten




