

Als je je ooit hebt afgevraagd hoe bedrijven een berg ruwe, verspreide data omzetten in strakke dashboards en AI-gestuurde inzichten, dan ben je niet de enige. Het geheime ingrediënt? Dat begint allemaal met data-ingestie — de onbezongen held aan het allereerste begin van elk datagedreven bedrijfsproces. In een wereld waarin we in 2025 181 zettabyte aan data genereren (dat zijn 21 nullen, als je meetelt), is data van punt A naar punt B krijgen — snel, nauwkeurig en in een bruikbaar formaat — belangrijker dan ooit.
Ik werk al jaren in SaaS en automatisering en heb uit eerste hand gezien hoe de juiste data-ingestiestrategie een bedrijf kan maken of breken. Of je nu verkoopkansen beheert, markttrends volgt of gewoon probeert je processen soepel te laten draaien, begrijpen hoe data-ingestie werkt (en hoe het evolueert) is de eerste stap naar echte bedrijfswaarde. Dus laten we erin duiken: wat is data-ingestie, waarom is het belangrijk en hoe veranderen moderne tools — zoals Thunderbit — het speelveld voor iedereen, van analisten tot ondernemers?
Wat is data-ingestie? De basis van een datagedreven bedrijf
In de kern is data-ingestie het proces van het verzamelen, importeren en laden van data uit meerdere bronnen in één centraal systeem — denk aan een database, datawarehouse of data lake — zodat die geanalyseerd, gevisualiseerd of gebruikt kan worden voor zakelijke beslissingen. Zie het als de ‘voordeur’ van je datapijplijn: het is hoe je al die ruwe ingrediënten (spreadsheets, API’s, logs, webpagina’s, sensordata) je keuken binnenbrengt voordat je inzichten gaat ‘koken’.
Data-ingestie is de allereerste fase in elke datapijplijn (Montecarlodata), waarbij silo’s worden doorbroken en ervoor wordt gezorgd dat hoogwaardige, actuele data beschikbaar is voor analytics, business intelligence en machine learning. Zonder ingestie blijft waardevolle informatie opgesloten in geïsoleerde systemen — ‘onzichtbaar voor de mensen die het nodig hebben’, zoals een expert uit de sector het verwoordde.
Zo past het in het grotere geheel:
- Data-ingestie: Verzamelt ruwe data uit verschillende bronnen en brengt die in één centrale opslag.
- Data-integratie: Combineert en harmoniseert data uit verschillende bronnen, zodat alles samenwerkt.
- Datatransformatie: Reinigt, formatteert en verrijkt data zodat die klaar is voor analyse.
Zie ingestie als al je boodschappen van verschillende winkels naar huis rijden. Integratie is ze netjes ordenen in je voorraadkast, en transformatie is het voorbereiden en koken van de maaltijd.
Waarom data-ingestie belangrijk is voor moderne organisaties
Laten we eerlijk zijn: in de huidige zakenwereld is tijdige en goed ingevoerde data een strategisch bezit. Bedrijven die data-ingestie beheersen, kunnen silo’s doorbreken, realtime inzichten mogelijk maken en sneller en slimmer beslissen. Aan de andere kant betekent slechte ingestie trage rapporten, gemiste kansen en beslissingen op basis van verouderde of onvolledige data.
Hoe je elke website met AI kunt scrapen Get Started Free
Hier zijn een paar concrete manieren waarop efficiënte data-ingestie bedrijfswaarde oplevert:
| Toepassing | Hoe efficiënte data-ingestie helpt |
|---|---|
| Sales lead-generatie | Bundelt leads uit webformulieren, sociale media en databases bijna realtime in één systeem, zodat salesteams sneller kunnen reageren en de conversie kunnen verhogen. |
| Operationele dashboards | Voedt analysetools continu met data uit productiesystemen en levert actuele KPI’s voor het management, zodat snel bijgestuurd kan worden. |
| 360° klantbeeld | Integreert klantdata uit CRM, support, e-commerce en sociale media om uniforme profielen te maken voor gepersonaliseerde marketing en proactieve service (Cake.ai). |
| Voorspellend onderhoud | Neemt sensordata en IoT-data in grote volumes op, zodat analysemodellen afwijkingen kunnen detecteren en storingen kunnen voorspellen voordat ze optreden — minder downtime en lagere kosten. |
| Financiële risicoanalyse | Streamt transactiegegevens en marktfeeds naar risicomodellen, waardoor banken en handelaren realtime zicht hebben op risico’s en direct fraude kunnen detecteren. |
En de cijfers liegen niet: 97% van de bedrijven heeft geïnvesteerd in bigdata-initiatieven, maar die investeringen leveren alleen iets op als de data ook daadwerkelijk kan worden opgenomen en vertrouwd.
Data-ingestie versus data-integratie en datatransformatie: de verwarring opgehelderd
Het is makkelijk om verstrikt te raken in jargon — dus laten we het helder maken:
- Data-ingestie: De eerste stap waarbij ruwe data uit bronsystemen wordt verzameld en geïmporteerd. Denk: ‘Alles de keuken in krijgen.’
- Data-integratie: Data uit verschillende bronnen combineren en op elkaar afstemmen, zodat er consistentie en één gezamenlijk beeld ontstaat. Denk: ‘De voorraadkast organiseren.’
- Datatransformatie: Data van ruwe naar bruikbare vorm omzetten — reinigen, formatteren, aggregeren en verrijken. Denk: ‘De maaltijd voorbereiden en koken.’
Een veelvoorkomende misvatting is dat ingestie en ETL (Extract, Transform, Load) hetzelfde zijn. In werkelijkheid is ingestie alleen het ‘extract’-deel — het binnenhalen van de ruwe data. Daarna volgen integratie en transformatie, zodat de data klaar is voor analyse (Astera).
Waarom is dat belangrijk? Als je alleen snel een dataset van een webpagina nodig hebt, kan een lichte ingestietool genoeg zijn. Maar als je data uit vijf verschillende systemen combineert en opschoont, heb je ook integratie en transformatie nodig.
Traditionele methoden voor data-ingestie: ETL en de beperkingen ervan
Decennialang was de standaardmethode voor data-ingestie ETL (Extract, Transform, Load). Data-ingenieurs schreven scripts of gebruikten gespecialiseerde software om periodiek data uit bronsystemen te halen, op te schonen en te formatteren, en vervolgens naar een datawarehouse te laden. Dit draaide meestal volgens een batchschema — denk aan nachtelijke updates.
Maar naarmate data in volume en variatie explodeerde, begon traditionele ETL zijn leeftijd te tonen:
- Complexe, tijdrovende opzet: Het bouwen en onderhouden van ETL-pijplijnen vereiste veel code en specialistische kennis. Niet-technische teams moesten wachten tot IT alles had ingericht (Medium).
- Knelpunten door batchverwerking: ETL-jobs draaiden in batches, waardoor data later beschikbaar kwam. In een wereld waarin directe inzichten tellen, is wachten van uren of dagen gewoon niet goed genoeg (SumaSoft).
- Schaal- en snelheidsproblemen: Oude pijplijnen hadden vaak moeite met de enorme datavolumes van nu en hadden voortdurend afstemming en upgrades nodig.
- Rigide en inflexibel: Nieuwe databronnen toevoegen of schemas aanpassen was lastig en kon de pijplijn breken of grote herwerking vereisen.
- Hoge onderhoudslast: Pijplijnen konden om allerlei redenen uitvallen en vroegen voortdurend aandacht van engineers.
- Beperkt tot gestructureerde data: Klassieke ETL was gebouwd voor nette rijen en kolommen — niet voor de rommelige, ongestructureerde data (zoals webpagina’s of afbeeldingen) die nu 90% van alle nieuwe data uitmaakt.
Kortom: ETL was geweldig voor eenvoudigere tijden, maar heeft moeite om de snelheid, schaal en diversiteit van moderne data bij te benen.
De opkomst van moderne data-ingestie: AI-gestuurde en geautomatiseerde oplossingen
Welkom in het nieuwe tijdperk: moderne data-ingestietools die automatisering, cloud-schaalbaarheid en AI inzetten om dataverzameling sneller, eenvoudiger en flexibeler te maken.
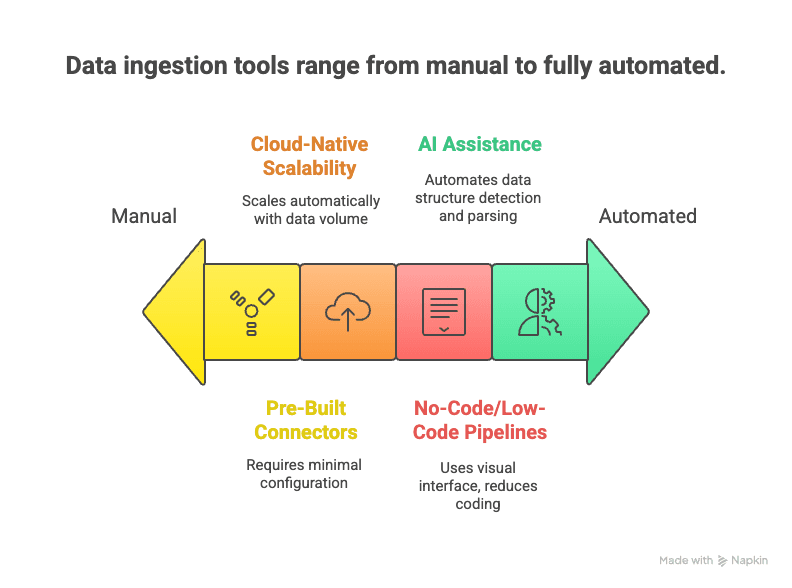
Dit is waarin ze zich onderscheiden:
- No-code/low-code pijplijnen: Met drag-and-drop interfaces en AI-assistenten kunnen gebruikers datastromen opzetten zonder code te schrijven (Medium).
- Vooraf gebouwde connectors: Honderden kant-en-klare koppelingen voor populaire databronnen — inloggen en aan de slag.
- Cloud-native schaalbaarheid: Elastische clouddiensten kunnen enorme datastromen realtime verwerken (Databricks).
- Ondersteuning voor realtime en streaming: Moderne tools ondersteunen zowel streaming- als batch-ingestie, zodat je kunt kiezen wat bij je behoeften past (Cake.ai).
- AI-ondersteuning: AI kan automatisch datastructuren herkennen, parse-regels aanbevelen en zelfs direct datakwaliteitscontroles uitvoeren (Cake.ai).
- Ondersteuning voor ongestructureerde data: NLP- en computer vision-technieken kunnen rommelige webpagina’s, pdf’s of afbeeldingen omzetten in gestructureerde tabellen.
- Minder onderhoud: Beheerde diensten regelen monitoring, schaalvergroting en updates — zodat jij je kunt richten op het gebruik van data, niet op het bewaken van pijplijnen.
Het resultaat? Data-ingestie die sneller is op te zetten, makkelijker aan te passen en geschikt is voor de onstuimige wereld van data van vandaag.
Data-ingestie in de praktijk: toepassingen per sector en uitdagingen
Laten we eens kijken hoe data-ingestie in de echte wereld werkt — en welke uitdagingen verschillende sectoren tegenkomen.
Retail en e-commerce
Retailers nemen data op uit kassasystemen, webshops, loyaliteitsapps en zelfs sensoren in de winkel. Door verkooptransacties, websiteklikstromen en voorraadlogs te consolideren, krijgen ze realtime zicht op voorraadniveaus en aankooptrends. De uitdaging? Omgaan met grote hoeveelheden snelle data (zeker tijdens piekperiodes) en data integreren over online en offline kanalen.
Finance en banking
Banken en handelsfirma’s nemen datastromen op uit transacties, marktfeeds en klantinteracties. Realtime ingestie is cruciaal voor fraudedetectie en risicobeheer. Maar met strikte compliance- en beveiligingseisen kan elke storing in het ingestieproces grote gevolgen hebben.
Technologie- en internetbedrijven
Techreuzen nemen enorme realtime eventstromen op (elke klik, like of share) om gebruikersgedrag te analyseren en aanbevelingssystemen aan te sturen. De schaal is gigantisch, en de uitdaging is om signaal van ruis te scheiden — en data kwaliteit en consistentie te waarborgen.
Gezondheidszorg
Ziekenhuizen nemen data op uit elektronische patiëntendossiers, labsystemen en medische apparaten om uniforme patiëntendossiers te maken en voorspellende analyses mogelijk te maken. De grote obstakels? Interoperabiliteit (verschillende systemen die verschillende ‘talen’ spreken) en privacy van patiënten.
Vastgoed
Vastgoedbedrijven nemen data op uit aanbodplatformen, vastgoedwebsites en openbare registers om uitgebreide databases op te bouwen. De uitdaging is data uit uiteenlopende bronnen — vaak ongestructureerd — samen te voegen en actueel te houden terwijl listings snel veranderen.
Veelvoorkomende uitdagingen in alle sectoren zijn onder meer:
- Omgaan met datavariatie (gestructureerd, semi-gestructureerd, ongestructureerd)
- Balanceren tussen realtime- en batchbehoeften
- Zorgen voor datakwaliteit en consistentie
- Voldoen aan beveiligings- en compliance-eisen
- Opschalen om groeiende datavolumes aan te kunnen
Deze uitdagingen overwinnen is essentieel om betere bedrijfsresultaten te behalen — nauwkeurigere analyses, realtime besluitvorming en sterkere compliance.
Thunderbit: data-ingestie vereenvoudigen met AI Web Scraper
Laten we het nu hebben over de rol van Thunderbit hierin. Thunderbit is een AI-gedreven webscraper-extensie voor Chrome, ontworpen om webdata-ingestie toegankelijk te maken voor iedereen — zelfs als je geen regel code kent.
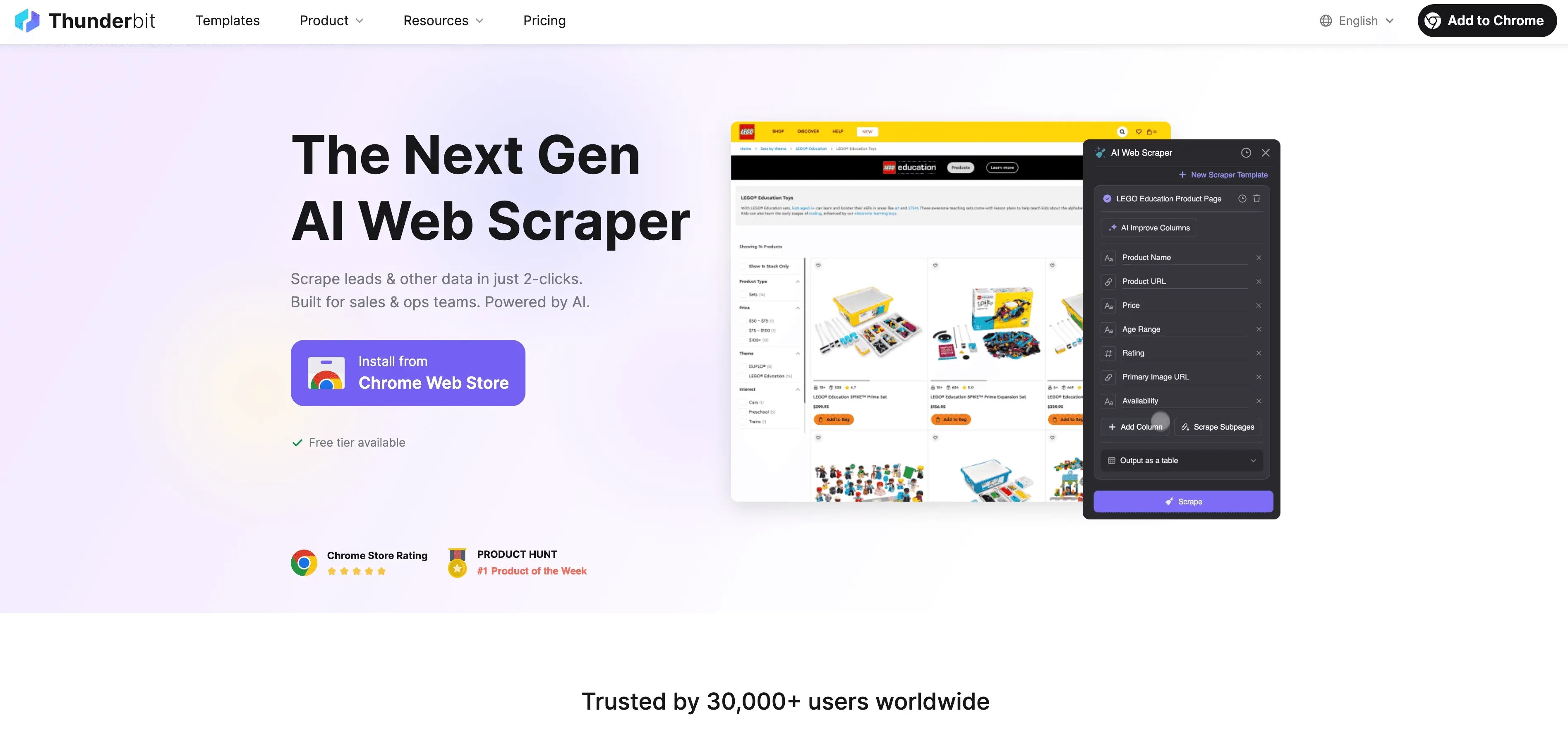
Dit is waarom Thunderbit een gamechanger is voor zakelijke gebruikers:
- Webscraping in 2 klikken: Ga van een rommelige webpagina naar een gestructureerde dataset in twee klikken. Klik op ‘AI Suggest Fields’ en daarna op ‘Scrape’ — en klaar.
- AI-gestuurde veldsuggesties: Thunderbit’s AI leest de pagina en raadt de beste kolommen aan om uit te halen, of je nu op een bedrijvengids, productoverzicht of LinkedIn-profiel zit.
- Automatische subpage-scraping: Meer details nodig? Thunderbit kan elke subpagina bezoeken (zoals productdetails of individuele profielen) en je tabel automatisch verrijken.
- Omgaan met paginering: Het kan paginagelijsten en infinite-scrollpagina’s verwerken, zodat je geen data mist.
- Vooraf gebouwde sjablonen: Voor populaire sites zoals Amazon, Zillow of Shopify biedt Thunderbit 1-klik-sjablonen — geen setup nodig.
- Gratis data-export: Exporteer je data direct naar Excel, Google Sheets, Airtable of Notion — zonder extra kosten.
- Geplande scraping: Stel scraping-taken in die automatisch op elk gewenst interval draaien (bijv. dagelijkse prijschecks van concurrenten).
- AI-autovullen: Automatiseer ook het invullen van formulieren en repetitieve webtaken.
Thunderbit is ideaal voor salesteams die leads scrapen, e-commerce-analisten die prijzen monitoren of makelaars die vastgoedaanbod verzamelen. Het draait allemaal om het snel omzetten van ongestructureerde webdata in bruikbare inzichten.
Wil je Thunderbit in actie zien? Bekijk dan ons YouTube-kanaal of lees onze blog voor meer handleidingen.
Probeer Thunderbit AI Web Scraper gratis
Data-ingestie-oplossingen vergelijken: traditionele versus moderne aanpakken
Hier is een korte vergelijking naast elkaar:
| Criteria | Traditionele ETL-tools | Moderne AI-/cloudtools | Thunderbit (AI Web Scraper) |
|---|---|---|---|
| Gebruikerskennis | Hoog (coderen/IT vereist) | Gemiddeld (low-code, enige setup) | Laag (2 klikken, geen code nodig) |
| Databronnen | Gestructureerd (databases, CSV) | Breed (databases, SaaS, API’s) | Elke website, ongestructureerde data |
| Snelheid van uitrol | Traag (weken/maanden) | Sneller (dagen) | Direct (minuten) |
| Realtime-ondersteuning | Beperkt (batch) | Sterk (streaming/batch) | Op aanvraag en gepland |
| Schaalbaarheid | Uitdagend | Hoog (cloud-native) | Gemiddeld/hoog (cloud scraping) |
| Onderhoud | Hoog (kwetsbare pijplijnen) | Gemiddeld (beheerde diensten) | Laag (AI past zich aan veranderingen aan) |
| Transformatie | Rigide, vooraf | Flexibel, na laden | Basis (AI-veldprompts) |
| Beste toepassing | Interne batch-integratie | Analytics-pijplijnen | Webdata, externe bronnen |
De kernboodschap? Stem de tool af op de taak. Voor webdata of ongestructureerde bronnen is Thunderbit vaak de snelste en makkelijkste keuze.
De toekomst van data-ingestie: automatisering en cloud-first strategieën
Vooruitkijkend wordt data-ingestie alleen maar slimmer en meer geautomatiseerd. Dit kun je verwachten:
- Standaard realtime: Het oude batch-paradigma verdwijnt steeds meer. Steeds meer pijplijnen worden gebouwd voor realtime, event-gedreven data (Cake.ai).
- Cloud-first en ‘zero ETL’: Cloudplatforms maken het makkelijker om bronnen en doelen te koppelen zonder handmatige pijplijnen.
- AI-gedreven automatisering: Machine learning zal een grotere rol spelen bij het configureren, monitoren en optimaliseren van pijplijnen — met het detecteren van afwijkingen, corrigeren van fouten en zelfs realtime verrijken van data.
- No-code en selfservice: Meer tools zullen zakelijke gebruikers in staat stellen om datastromen op te zetten met natuurlijke taal of visuele interfaces.
- Edge- en IoT-ingestie: Naarmate meer data aan de edge wordt gegenereerd, zal ingestie dichter bij de bron plaatsvinden, met slimme filtering en aggregatie.
- Governance en metadata: Geautomatiseerde tagging, lineage-tracking en compliance worden in elke stap ingebouwd.
De kern: de toekomst draait om data-ingestie sneller, toegankelijker en betrouwbaarder maken — zodat jij je kunt richten op inzichten, niet op infrastructuur.
Conclusie: belangrijkste inzichten voor zakelijke gebruikers
Hoe je geautomatiseerd data scrapen onder de knie krijgt met Thunderbit Get Started Free
- Data-ingestie is de cruciale eerste stap in elk datagedreven initiatief. Als je inzichten wilt, moet je de data erin krijgen — snel en betrouwbaar.
- Moderne, AI-gestuurde tools zoals Thunderbit maken data-ingestie toegankelijk voor iedereen, niet alleen voor IT-professionals. Met scraping in 2 klikken, AI-veld-suggesties en geplande taken kun je rommelige webdata omzetten in bedrijfswaarde.
- De juiste tool kiezen is belangrijk: Gebruik traditionele ETL voor stabiele, gestructureerde interne data; moderne cloudtools voor brede analytics; en Thunderbit voor webdata en ongestructureerde data.
- Blijf de trend voor: Automatisering, cloud en AI maken data-ingestie slimmer en eenvoudiger. Blijf niet hangen in het verleden — ontdek nieuwe oplossingen en maak je datastrategie toekomstbestendig.
Begin met het ingesteren van webdata met Thunderbit
Veelgestelde vragen
1. Wat is data-ingestie, in gewone taal?
Data-ingestie is het proces van het verzamelen en importeren van data uit verschillende bronnen (zoals websites, databases of bestanden) naar één centraal systeem, zodat die kan worden geanalyseerd of gebruikt voor zakelijke beslissingen. Het is de allereerste stap in elke datapijplijn.
2. Waarin verschilt data-ingestie van data-integratie en transformatie?
Data-ingestie gaat over het binnenhalen van ruwe data. Data-integratie combineert en harmoniseert data uit verschillende bronnen, terwijl datatransformatie de data opschoont en formatteert voor analyse. Denk: ingestie = verzamelen, integratie = organiseren, transformatie = voorbereiden en koken.
3. Wat zijn de grootste uitdagingen van traditionele methoden voor data-ingestie?
Traditionele methoden zoals ETL zijn traag op te zetten, vereisen veel codering, hebben moeite met ongestructureerde data en kunnen de realtimebehoeften van vandaag niet bijbenen. Ze vragen ook veel onderhoud en zijn inflexibel wanneer databronnen veranderen.
4. Hoe maakt Thunderbit data-ingestie eenvoudiger?
Thunderbit gebruikt AI zodat iedereen webdata in slechts twee klikken kan scrapen en structureren — zonder coderen. Het kan subpagina’s en paginering verwerken, geplande terugkerende taken uitvoeren en direct exporteren naar Excel, Google Sheets, Airtable of Notion.
5. Wat is de toekomst van data-ingestie?
De toekomst draait om automatisering, cloud-first strategieën en AI-gestuurde pijplijnen. Verwacht meer realtime datastromen, slimmere foutafhandeling en tools waarmee zakelijke gebruikers data-ingestie kunnen opzetten met natuurlijke taal of visuele interfaces.
Meer informatie:
- Hoe je elke website met AI kunt scrapen
- Hoe je geautomatiseerd data scrapen onder de knie krijgt met Thunderbit
- Wat is data-ingestie?
- Data-ingestie: 7 uitdagingen en 4 best practices
Probeer AI Web Scraper Get Started Free




