Het web groeit in een tempo dat eerlijk gezegd haast niet bij te houden is. Elke dag verschijnen er miljarden nieuwe pagina’s, producten, reviews en datasets — en die voeden alles, van marktonderzoek en AI-training tot je volgende Amazon-aankoop. Als iemand die jarenlang in SaaS en automatisering heeft gewerkt, heb ik uit eerste hand gezien hoe de juiste data een zakelijke beslissing kan maken of breken. Maar hier zit de adder onder het gras: al die webdata verzamelen, bijwerken en er betekenis uit halen wordt juist lastiger, niet makkelijker. Traditionele webscrapers kunnen het tempo nauwelijks nog bijbenen, en bedrijven zoeken een slimmere, snellere manier om van internet bruikbare inzichten te maken. Daar komt de cloud crawler om de hoek kijken — een tool die stilletjes de manier verandert waarop organisaties webdata op schaal vinden en inzetten.
Maar wat is een cloud crawler precies? Hoe verschilt die van de webscrapers die je misschien al kent? En waarom zetten teams van sales tot operations in op deze technologie om voorop te blijven in een datagedreven wereld? Laten we erin duiken, de buzzwords ontleden en kijken hoe cloud crawlers — en vooral Thunderbit’s oplossing — de spelregels veranderen voor moderne bedrijven.
Wat is een cloud crawler? De volgende stap in datavinding
Laten we het simpel houden: een cloud crawler is niet zomaar een webscraper die in de cloud draait. Zie het eerder als een motor voor datavinding — een slim, cloudgebaseerd systeem dat automatisch enorme datasets op internet kan vinden, extraheren en analyseren. Waar een traditionele webscraper informatie van een handvol pagina’s ophaalt (vaak één voor één en meestal vanaf één apparaat), werkt een cloud crawler op een totaal ander niveau. Hij draait in krachtige cloud-datacenters, crawlt tegelijk duizenden of zelfs miljoenen pagina’s, en kan alles verwerken, van tekst tot afbeeldingen en PDF’s — hoe complex of uitgestrekt de website ook is.
Zie het zo: als een webscraper lijkt op een bibliothecaris die passages uit één boek overschrijft, dan is een cloud crawler een team supercomputers dat meteen alle boeken in de bibliotheek scant, labelt, ordent en analyseert terwijl ze bezig zijn. Het resultaat? Bedrijven krijgen rijkere, actuelere en beter bruikbare data — zonder de beperkingen van lokale hardware of handmatig werk (, ).
Cloud crawler vs. traditionele webscraper: wat is nu echt het verschil?
Als je ooit een webscraper hebt gebruikt, ken je de basis: wijs hem naar een pagina, geef aan wat je wilt, en laat hem de data ophalen. Maar naarmate het web groter en ingewikkelder wordt, lopen de beperkingen van de oude aanpak steeds meer in beeld. Zo verhouden cloud crawlers en traditionele webscrapers zich tot elkaar:
| Kenmerk/Aspect | Traditionele webscraper | Cloud crawler |
|---|---|---|
| Implementatie | Draait op je lokale apparaat of server | Draait in de cloud (externe datacenters) |
| Schaal | Beperkt door de kracht van je computer | Massaal parallel — duizenden pagina’s tegelijk |
| Snelheid | Langzamer, vooral bij grote opdrachten | Snelle batchverwerking |
| Onderhoud | Regelmatig updaten, breekt bij sitewijzigingen | Cloudgebaseerd, automatisch bijgewerkt, minder kwetsbaar |
| Datatypes | Meestal tekst, soms afbeeldingen | Tekst, afbeeldingen, PDF’s, complexe layouts |
| Toegang | Gebonden aan je apparaat/netwerk | Overal toegankelijk, vanaf elk apparaat |
| Planning | Handmatig of basisautomatisering | Geavanceerde planning, terugkerende taken |
| Het meest geschikt voor | Kleine projecten, eenvoudige websites | Grote, frequente of complexe databehoeften |
Cloud crawlers zijn gebouwd voor het moderne web — waar data overal zit en snelheid en schaal geen luxe zijn maar noodzaak (, ).
Hoe cloud crawlers dataverzameling veel efficiënter maken
Hier wordt het echt interessant. Cloud crawlers gebruiken de kracht van cloud computing om duizenden webpagina’s parallel te verwerken. Dat betekent dat je in een fractie van de tijd een complete e-commercecatalogus kunt scrapen, prijzen van concurrenten op tientallen websites kunt volgen of vastgoedaanbod van alle grote portals kunt bundelen — vergeleken met een traditionele scraper.
Waarom is dat belangrijk? Omdat in sectoren zoals e-commerce, finance en vastgoed actuele data alles is. Prijzen, voorraad en markttrends kunnen per minuut veranderen. Uren — of dagen — wachten tot een lokale scraper klaar is, is simpelweg geen optie. Cloud crawlers worden niet begrensd door het RAM-geheugen van je laptop of de wifi op kantoor — ze schalen mee wanneer dat nodig is, zodat je grote klussen zonder gedoe kunt aanpakken (, ).
Sectoren die hier het meest van profiteren zijn onder andere:
- E-commerce: Prijsmonitoring, productcatalogi bundelen, reviewanalyse
- Vastgoed: Listings verzamelen, markttrends volgen, woningen vergelijken
- Finance: Nieuws- en sentimentanalyse, aandelen/crypto monitoren, regelgeving volgen
- Sales & marketing: Leadgeneratie, concurrentieonderzoek, trends signaleren
En eerlijk is eerlijk: dat is nog maar het begin. Als je webdata op schaal nodig hebt, is een cloud crawler je nieuwe beste vriend.
Thunderbit’s cloud crawler-oplossing: snel, flexibel en krachtig
Laat me heel even mijn Thunderbit-petje opzetten (oké, eigenlijk doe ik dat nooit af). ’s cloud scraping-modus is ons antwoord op de moderne data-uitdaging — een cloud crawler gebouwd voor zakelijke gebruikers die resultaat willen, geen hoofdpijn.
Dit maakt Thunderbit’s cloud crawler bijzonder:
- Snelle batch-scraping: Scrape tot 50 pagina’s tegelijk, met cloudservers in de VS, EU en Azië voor wereldwijde dekking. Geen eindeloos wachten meer tot je laptop een grote lijst heeft doorgespit.
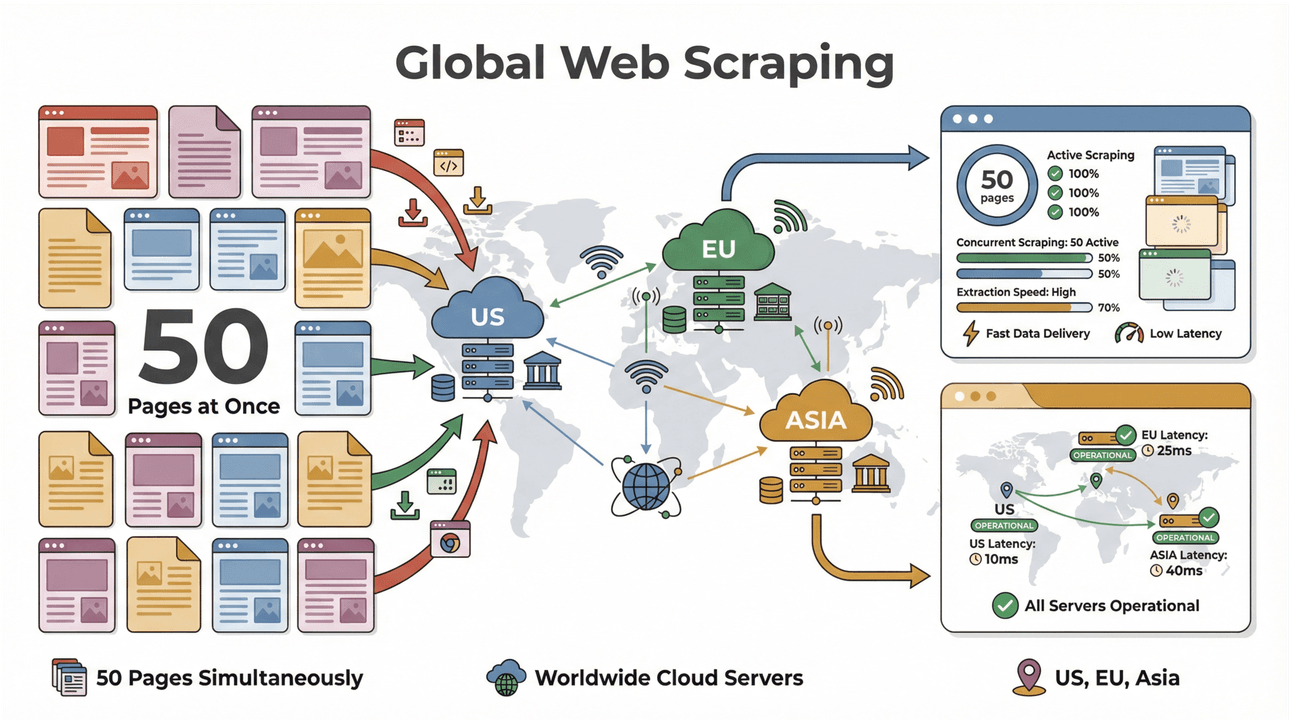
- Ondersteuning voor complexe pagina’s: Thunderbit’s AI kan overweg met alles, van dynamische e-commercesites tot lastige PDF’s en zelfs het extraheren van afbeeldingen. Staat het op internet? Dan kan Thunderbit het waarschijnlijk scrapen ().
- Crawlen van subpagina’s: Wil je je data verrijken met details van subpagina’s, zoals productspecificaties of auteursbio’s? Thunderbit’s AI kan elke subpagina bezoeken en de resultaten samenvoegen in je hoofd-dataset ().
- Slimme datastructurering: Gebruik “AI Suggest Fields” om Thunderbit de site te laten lezen en de beste kolommen te laten voorstellen — zonder code of templates bouwen.
- Export waar je maar wilt: Stuur je data rechtstreeks naar Excel, Google Sheets, Airtable of Notion. Of download gewoon als CSV/JSON — wat maar in je workflow past ().
- Geen onderhoud nodig: Thunderbit’s AI past zich aan websitewijzigingen aan, zodat je niet voortdurend kapotte scrapers hoeft te fixen ().
En ja, je kunt dit allemaal proberen met een — je hoeft me dus niet op mijn woord te geloven.
Cloud crawler-implementatie: cloud vs. lokaal — wat past bij jou?
Een van de grootste voordelen van cloud crawlers is de flexibiliteit van implementatie. Met een traditionele (lokale) crawler zit je vast aan een specifiek apparaat, netwerk en vaak een hoop installatiegedoe. Als je computer in slaapstand gaat of je internet uitvalt, stopt je scrapingtaak. Schaal je op, dan moet je extra hardware kopen of meerdere scripts draaien.
Cloud crawlers draaien dat model om:
- Geen speciale hardware nodig: Het zware werk gebeurt volledig in de cloud. Je kunt enorme scrape-taken starten vanaf een Chromebook, een Mac of zelfs je telefoon.
- Overal toegang: Onderweg? Op afstand aan het werk? Geen probleem — je cloud crawler is altijd beschikbaar.
- Makkelijk opschalen: Wil je 10.000 pagina’s scrapen in plaats van 100? Vergroot gewoon de taak — zonder tussenkomst van IT.
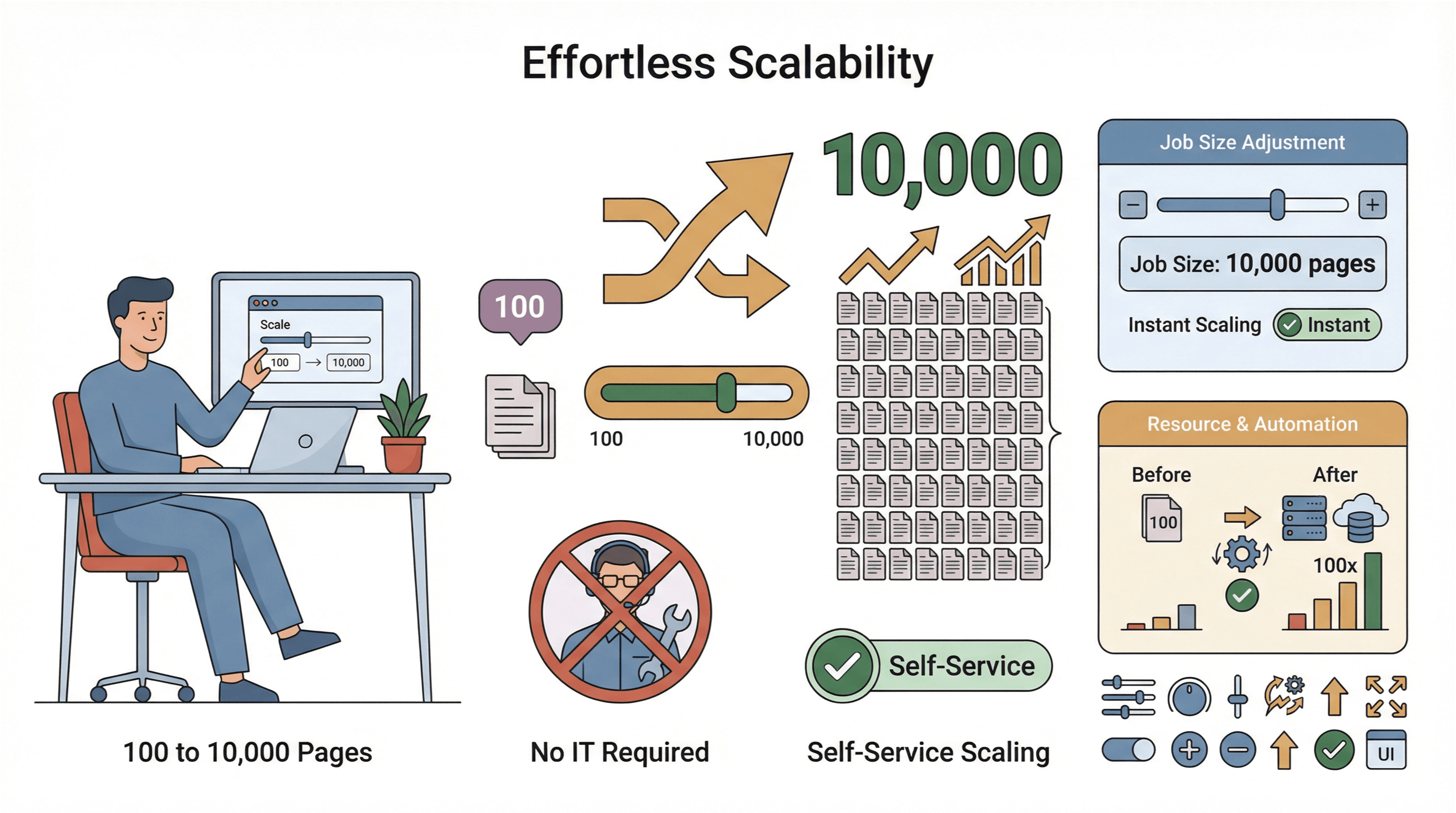
- Wereldwijde dataverzameling: Met cloudservers in meerdere regio’s kun je makkelijker geo-afgeschermde content benaderen en beter omgaan met compliance ().
Natuurlijk blijven beveiliging en compliance altijd topprioriteiten. De beste cloud crawlers (Thunderbit inbegrepen) gebruiken versleutelde verbindingen, houden rekening met de voorwaarden van websites en bieden functies om gevoelige data verantwoord te beheren.
Praktische impact: hoe cloud crawlers datagedreven strategieën veranderen
Laten we het concreet maken. Waarom stappen bedrijven over op cloud crawlers? Omdat ze echte, meetbare resultaten zien:
- Realtime marktanalyse: Retailers gebruiken cloud crawlers om prijzen en voorraad van concurrenten live te volgen, zodat ze dynamisch kunnen prijzen en sneller kunnen reageren op marktveranderingen ().
- Voorspellen van consumententrends: Merken bundelen reviews, socialmediaberichten en forumberichten om opkomende trends te signaleren en campagnes direct bij te sturen.
- Sales & leadgeneratie: Salesteams bouwen actuele leadlijsten op uit directories, eventsites en zelfs PDF’s — en voeden CRM’s met verse, gekwalificeerde contacten ().
- Operations & compliance: Financiële instellingen gebruiken cloud crawlers om regelgeving, nieuws en filings in meerdere rechtsgebieden te volgen — zo beperken ze risico’s en blijven ze veranderingen voor.
De rode draad? Cloud crawlers helpen teams sneller te handelen, betere beslissingen te nemen en concurrenten voorbij te streven die nog steeds in de file staan.
Belangrijke functies om op te letten bij een cloud crawler
Niet elke cloud crawler is hetzelfde. Als je opties vergelijkt, zijn dit de functies die er het meest toe doen — en waar Thunderbit uitblinkt:
- Schaalbaarheid: Kan het duizenden pagina’s tegelijk aan? Wordt het trager naarmate taken groter worden?
- Gebruiksgemak: Is de interface toegankelijk voor niet-technische gebruikers? Kun je binnen een paar klikken een scrape opzetten?
- Ondersteuning voor meerdere datatypes: Tekst, afbeeldingen, PDF’s, subpagina’s — kan het ze allemaal verwerken?
- Integraties: Exporteert het naar je favoriete tools (Excel, Sheets, Notion, Airtable)?
- Planning: Kun je terugkerende taken instellen voor altijd actuele data?
- AI-ondersteuning: Biedt het slimme veldsuggesties, dataverrijking en aanpassing aan sitewijzigingen?
- Beveiliging & compliance: Zijn je data en inloggegevens beschermd? Helpt het je voldoen aan privacywetgeving?
Thunderbit vinkt al deze vakjes aan en is daarmee een sterke keuze voor teams die kracht willen zonder de rompslomp.
Aan de slag: hoe gebruik je een cloud crawler voor je bedrijf
Klaar om te beginnen? Zo kan een doorsnee zakelijke gebruiker starten met een cloud crawler zoals Thunderbit:
- Installeer de : Snel opgezet, geen IT nodig.
- Kies je doel: Open de website, lijst of het document dat je wilt scrapen.
- Klik op “AI Suggest Fields”: Laat Thunderbit’s AI de pagina scannen en de beste kolommen voorstellen om uit te lezen.
- Pas aan waar nodig: Voeg velden toe, verwijder ze of hernoem ze zodat ze bij je behoefte passen.
- Selecteer cloud scraping-modus: Voor grote opdrachten of complexe sites schakel je over naar cloud mode voor maximale snelheid.
- Start de scrape: Thunderbit verwerkt tot 50 pagina’s tegelijk in de cloud.
- Controleer en exporteer: Bekijk je resultaten en exporteer daarna naar Excel, Google Sheets, Notion of Airtable.
- Plan terugkerende taken: Voor doorlopende behoeften stel je geplande scrapes in — je data wordt dan automatisch bijgewerkt ().
Pro-tip: begin klein om het gevoel te krijgen, en schaal daarna op zodra je er vertrouwd mee bent. En gebruik vooral Thunderbit’s support of documentatie — die zijn er om te helpen.
De toekomst van dataverzameling: wat komt er hierna voor cloud crawlers?
De revolutie rond cloud crawlers staat nog maar aan het begin. Dit is waar ik de komende jaren op let:
- Slimmere AI-extractie: Cloud crawlers worden steeds beter in het begrijpen van context, relaties en zelfs sentiment — waardoor de data die ze verzamelen waardevoller wordt ().
- Ondersteuning voor nieuwe datatypes: Verwacht betere verwerking van video, audio en interactieve content — niet alleen statische tekst en afbeeldingen.
- Diepere automatisering: Van automatisch plannen tot realtime meldingen: cloud crawlers worden nog meer hands-off voor zakelijke gebruikers.
- Sterkere compliance: Terwijl privacywetgeving evolueert, bouwen cloud crawlers steeds meer tools in om teams aan de juiste kant van de regels te houden.
- Integratie met BI- en AI-tools: Rechtstreekse pipelines van cloud crawlers naar analytics, dashboards en machine-learningplatforms.
Kortom: cloud crawlers staan klaar om de ruggengraat te worden van digitale bedrijfsstrategie — en alles aan te sturen, van productlanceringen tot AI-gedreven forecasting ().
Conclusie: waarom cloud crawlers essentieel zijn voor moderne bedrijven
Kort samengevat: het web explodeert van de data, en de oude manieren om die data te verzamelen kunnen simpelweg niet meer meekomen. Cloud crawlers zijn de volgende evolutiestap — met snelheid, schaal en intelligentie die traditionele scrapers gewoon niet kunnen evenaren. Tools zoals maken het mogelijk voor elk team, technisch of niet, om het volle potentieel van webdata te benutten — en zo slimmere beslissingen, snellere reacties en een echt concurrentievoordeel mogelijk te maken.
Als je klaar bent om handmatig scrapen en trage dataverwerking achter je te laten, is dit hét moment om te ontdekken wat een cloud crawler voor jouw bedrijf kan doen. Probeer Thunderbit’s cloud scraping-modus en ervaar hoe eenvoudig — en krachtig — moderne datavinding kan zijn. En als je dieper wilt gaan, bekijk dan de voor meer handleidingen, tips en praktijkvoorbeelden.
FAQ’s
1. Wat is een cloud crawler in eenvoudige woorden?
Een cloud crawler is een cloudgebaseerde tool die automatisch grote hoeveelheden data van internet ontdekt, extraheert en analyseert. In tegenstelling tot traditionele scrapers die op je lokale apparaat draaien, werken cloud crawlers in krachtige datacenters, waardoor ze enorme schaal en snelheid mogelijk maken.
2. Hoe verschilt een cloud crawler van een gewone webscraper?
Cloud crawlers draaien in de cloud, verwerken duizenden pagina’s tegelijk, ondersteunen complexe datatypes (zoals afbeeldingen en PDF’s) en hebben geen onderhoud of lokale hardware nodig. Traditionele scrapers zijn beperkt door de kracht van je apparaat en zijn vooral geschikt voor kleinere, eenvoudigere taken.
3. Wat zijn de belangrijkste voordelen van een cloud crawler gebruiken?
Cloud crawlers bieden snelle dataverzameling op grote schaal, ondersteuning voor complexe websites, eenvoudige toegang vanaf overal en geavanceerde functies zoals planning en AI-gedreven extractie. Ze zijn ideaal voor bedrijven die snel verse, bruikbare data nodig hebben.
4. Hoe werkt Thunderbit’s cloud crawler voor zakelijke gebruikers?
Met Thunderbit’s cloud crawler zet je in een paar klikken een scrape op — zonder code. Je kunt data uit websites, PDF’s en afbeeldingen halen, die verrijken met AI en direct exporteren naar Excel, Google Sheets, Notion of Airtable. Het is ontworpen voor niet-technische gebruikers die resultaat willen, niet complexiteit.
5. Is cloud crawling veilig en in lijn met privacywetgeving?
Ja, toonaangevende cloud crawlers zoals Thunderbit gebruiken versleutelde verbindingen en best practices voor databeveiliging. Zorg er altijd voor dat je alleen publiek beschikbare data scrapt en de gebruiksvoorwaarden en privacyregels van websites respecteert.
Klaar om te zien wat een cloud crawler kan doen? en ontdek vandaag nog de wereld van grootschalige, cloud-aangedreven dataverzameling.
Meer weten