
Laten we eerlijk zijn: het internet is een gigantisch, steeds uitdijend oerwoud. Elke dag komen er meer dan 252.000 nieuwe websites bij, en alleen al de zoekindex van Google bevat meer dan 30 miljard pagina’s. Heb je je ooit afgevraagd hoe zoekmachines dat allemaal bijhouden – of hoe bedrijven de juiste info vinden in die digitale hooiberg? Je bent niet de enige. Na jaren in SaaS en automatisering krijg ik nog steeds vaak de vraag: “Wat is nou eigenlijk het verschil tussen webcrawling en webscraping? Is dat niet gewoon hetzelfde?” Spoiler: nee, en als je die begrippen door elkaar haalt, kan je project flink in de soep lopen.
Of je nu als salesprofessional op zoek bent naar leads, als e-commerce manager prijzen wilt monitoren, of gewoon indruk wilt maken tijdens de volgende teammeeting: we leggen uit wat een webcrawler precies doet, hoe het verschilt van een scraper, en waarom de juiste tool (zoals Thunderbit) je een hoop frustratie – en misschien zelfs je weekend – kan besparen.
Webcrawler uitgelegd: wat doet een webcrawler?

Stel je de meest toegewijde bibliothecaris ter wereld voor, die niet alleen boeken ordent, maar elke dag langs elke plank loopt om te checken of er iets nieuws is. Dat is precies wat een webcrawler doet – maar dan met miljarden webpagina’s. Een webcrawler (ook wel spider of bot genoemd) is een geautomatiseerd programma dat systematisch het web afstruint, van link naar link springt en alles wat het tegenkomt in kaart brengt. Zo bouwen zoekmachines als Google en Bing hun enorme indexen, waardoor wij allemaal kunnen zoeken op het web.
Bekende namen als “Googlebot” of “Bingbot” zijn voorbeelden van zulke webcrawlers die op de achtergrond hun werk doen. Er zijn ook nieuwere tools zoals Firecrawl, waarmee ontwikkelaars en bedrijven complete websites kunnen crawlen en omzetten naar gestructureerde data voor AI of analyses.
Maar let op: crawlen draait om ontdekken – het vinden en indexeren van pagina’s, niet om het verzamelen van specifieke gegevens. Daar komt webscraping om de hoek kijken (daarover zo meer).
Hoe werkt webcrawling?
Laten we het leven van een webcrawler eens volgen. Zie het als een digitale ontdekkingsreiziger met een rugzak vol “seed-URL’s” – de startpunten. Zo verloopt het proces:
- Seed-URL’s: De crawler begint met een lijst bekende webadressen.
- Ophalen & Analyseren: Hij bezoekt elke URL, haalt de pagina op en zoekt naar links.
- Links volgen: Elke nieuwe link wordt toegevoegd aan de takenlijst (de URL-frontier).
- Indexeren: Tijdens het crawlen slaat de crawler informatie over elke pagina op – soms de hele inhoud, soms alleen metadata.
- Netjes blijven: De crawler checkt het robots.txt-bestand van elke site om te zien of hij welkom is, en wacht tussen verzoeken om servers niet te overbelasten.
- Blijven bijwerken: Omdat het web constant verandert, bezoekt de crawler pagina’s opnieuw om de index actueel te houden.
Het lijkt een beetje op het in kaart brengen van een stad door elke straat te bewandelen, elke nieuwe steeg en winkel te noteren, en je plattegrond steeds bij te werken als er iets verandert.
Belangrijke onderdelen van een webcrawler
Ook als je niet technisch bent, is het handig om te weten wat er onder de motorkap gebeurt:
- URL-frontier (wachtrij): De centrale takenlijst met URL’s die nog bezocht moeten worden.
- Fetcher/Downloader: Het onderdeel dat daadwerkelijk de webpagina ophaalt.
- Parser: De “lezer” die links (en soms andere info) uit de pagina haalt.
- Deduplicatie & URL-filter: Voorkomt dat de crawler in een lus terechtkomt of dezelfde pagina dubbel bezoekt.
- Dataopslag/Index: Hier wordt alle gevonden content opgeslagen voor later gebruik.
Zie het als een lopende band: de een haalt de krant, de ander markeert de koppen, een derde archiveert de knipsels, en iemand anders houdt bij welke kranten nog moeten worden opgehaald.
Hoe crawl je een website: tools en methodes
Als zakelijke gebruiker ben je misschien geneigd om zelf een crawler te bouwen. Mijn advies: doe het niet. Tenzij je de volgende Google wilt starten, zijn er genoeg tools die het zware werk voor je doen.
Populaire webcrawling-tools:
- Scrapy: Open source, gericht op ontwikkelaars, ideaal voor grote projecten.
- Apache Nutch: Wordt gebruikt voor big data-indexering en onderzoek.
- Heritrix: De tool van het Internet Archive voor webarchivering.
- Screaming Frog SEO Spider: Favoriet bij SEO-specialisten voor het crawlen en auditen van websites.
- Firecrawl: Modern, API-gedreven, laat je complete sites crawlen en gestructureerde data extraheren.
Let op: De meeste van deze tools vragen om enige technische kennis. Zelfs “no-code” tools hebben vaak een leercurve – denk aan het selecteren van HTML-elementen, omgaan met sitewijzigingen of dynamische content. Wil je alleen data van een paar pagina’s halen? Dan heb je meestal geen volledige crawler nodig.
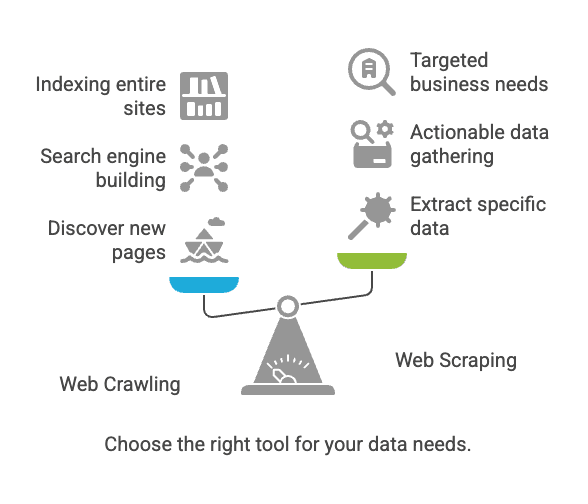
Webcrawling vs. webscraping: wat is het verschil?
Hier ontstaat vaak verwarring. Crawlen en scrapen zijn verwant, maar zeker niet hetzelfde.
| Aspect | Webcrawling | Webscraping |
|---|---|---|
| Doel | Webpagina’s ontdekken en indexeren | Specifieke data uit webpagina’s halen |
| Vergelijking | Bibliothecaris die elk boek catalogiseert | Belangrijke info uit een paar boeken kopiëren |
| Resultaat | Lijst met URL’s, paginainhoud, sitemap | Gestructureerde data (CSV, Excel, JSON, enz.) |
| Gebruikers | Zoekmachines, SEO-tools, archieven | Sales, e-commerce, analisten, onderzoekers |
| Schaal | Miljarden pagina’s (breed) | Tientallen tot duizenden pagina’s (gericht) |
Kort samengevat: Crawlen draait om vinden van pagina’s; scrapen om verzamelen van de gewenste data (nimbleway.com).
Veelvoorkomende uitdagingen en best practices bij crawlen en scrapen
Typische uitdagingen
- Wijzigingen in websitestructuur: Zelfs een kleine aanpassing kan je tool laten vastlopen (octoparse.com).
- Dynamische content: Veel sites laden data via JavaScript, wat basis-crawlers niet kunnen zien.
- Anti-botmaatregelen: CAPTCHAs, IP-blokkades en inlogvereisten kunnen je blokkeren.
- Schaalbaarheid: Duizenden pagina’s crawlen kan je computer overbelasten (of je IP laten blokkeren).
- Juridische/ethische kwesties: Publieke data scrapen mag meestal, maar check altijd de voorwaarden en privacywetgeving (web.instantapi.ai).
Best practices
- Kies de juiste tool: Geen programmeur? Begin met een no-code webscraper.
- Bepaal je datadoel: Weet precies welke data je nodig hebt en waarom.
- Respecteer sitebeleid: Check altijd
robots.txten de gebruiksvoorwaarden. - Overbelast sites niet: Voeg pauzes toe tussen verzoeken; wees netjes voor servers.
- Plan onderhoud in: Websites veranderen – houd rekening met aanpassingen.
- Houd data schoon en veilig: Sla resultaten veilig op en controleer op dubbele of foutieve data.
Typische toepassingen: crawlen vs. scrapen
Webcrawling
- Zoekmachine-indexering: Googlebot en Bingbot crawlen het web om zoekresultaten actueel te houden (en.wikipedia.org).
- Webarchivering: Het Internet Archive crawlt sites voor de Wayback Machine.
- SEO-audits: Tools crawlen je site om gebroken links of ontbrekende tags te vinden.
Webscraping
- Prijsmonitoring: Winkels scrapen productpagina’s van concurrenten voor prijsinformatie (nextgeninvent.com).
- Leadgeneratie: Sales-teams scrapen bedrijvengidsen voor contactgegevens.
- Contentaggregatie: Nieuws- of vacaturesites verzamelen lijsten van verschillende bronnen.
- Marktonderzoek: Analisten scrapen reviews of social media voor sentimentanalyse.
Leuk weetje: Meer dan 82% van de e-commercebedrijven gebruikt webscraping voor externe data. Doe je het niet, dan doet je concurrent het waarschijnlijk wel.
Wanneer kies je voor webcrawling of webscraping?
Hier is mijn snelle beslisboom:
-
Wil je nieuwe pagina’s ontdekken of een hele site indexeren?
→ Gebruik webcrawling.
-
Weet je al waar je data staat (specifieke pagina’s of secties)?
→ Gebruik webscraping.
-
Bouw je een zoekmachine of archiveer je het web?
→ Crawling is de juiste keuze.
-
Wil je bruikbare data verzamelen voor sales, prijzen of onderzoek?
→ Scraping is wat je zoekt.
-
Twijfel je?
→ Begin met scrapen. Voor de meeste zakelijke toepassingen is crawlen niet nodig.
Voor de meeste zakelijke gebruikers is scraping de beste keuze – direct bruikbare, gestructureerde data.
Webscraping voor bedrijven: het voordeel van Thunderbit
Laten we eens kijken waarom de meeste zakelijke gebruikers – zeker als je niet technisch bent – zich beter kunnen richten op scraping, en waarom Thunderbit daar speciaal voor is gemaakt.
Ik heb te vaak teams gezien die dagen (of weken) worstelen met “simpele” scrapingtools die allesbehalve eenvoudig blijken. Daarom hebben we Thunderbit ontwikkeld: webdata extraheren moet net zo makkelijk zijn als twee keer klikken.
Dit maakt Thunderbit uniek:
- Twee-kliks workflow: Klik op “AI Suggest Fields” en daarna op “Scrape”. Geen code, geen gedoe met selectors.
- Bulk-URL’s & PDF-ondersteuning: Data halen uit een lijst met URL’s of zelfs uit PDF’s? Thunderbit regelt het.
- Exporteren naar elk platform: Stuur je data direct naar Google Sheets, Airtable, Notion of download als CSV/JSON. Geen extra kosten.
- Subpagina’s scrapen: Thunderbit bezoekt automatisch subpagina’s (zoals productdetails) en verrijkt je datatabel.
- AI-autofill: Automatiseer het invullen van formulieren en repetitieve webtaken – jouw digitale assistent voor saaie klusjes.
- Gratis e-mail & telefoon extractors: Haal alle contactgegevens van een pagina met één klik.
- Cloud- of browserscraping: Kies wat bij je past – Thunderbit kan supersnel in de cloud scrapen of in je browser (ideaal voor ingelogde pagina’s).
- Geen leercurve: Ontwikkeld voor sales-, e-commerce- en marketingteams die gewoon resultaat willen.
Wil je meer weten over toepassingen? Bekijk onze handleidingen over Amazon-producten scrapen, Google Search-resultaten scrapen, of data scrapen naar Excel.
Scrape elke website met AI in 2 klikken
Thunderbit vs. traditionele webscraper
Een vergelijking voor zakelijke gebruikers:
| Functie/Behoefte | Thunderbit | Traditionele webscraper (bijv. Scrapy, Nutch) |
|---|---|---|
| Installatie | 2 klikken, geen code | Technische setup, vaak scripting nodig |
| Leercurve | Minimaal | Steil (vooral voor niet-programmeurs) |
| Subpagina’s | AI-gestuurd, automatisch | Handmatig scripten of geavanceerde instellingen |
| Bulk-URL’s/PDF’s | Standaard ondersteund | Meestal niet standaard mogelijk |
| Outputformaten | Google Sheets, Airtable, Notion, CSV | CSV, JSON (integratie vaak handmatig) |
| Aanpasbaarheid | AI past zich aan sitewijzigingen aan | Handmatige updates nodig bij sitewijzigingen |
| Zakelijke toepassingen | Sales, e-commerce, SEO, operations | Zoekmachine-indexering, onderzoek, archivering |
| Plannen | Plannen in gewone taal | Cronjobs of externe planners |
| Prijs | Vanaf €15/maand, gratis versie beschikbaar | Gratis/open source, maar hogere setup/onderhoudskosten |
| Support | Gericht op gebruikers, moderne interface | Community-based, vooral voor ontwikkelaars |
Thunderbit is er helemaal op gericht om je zo snel mogelijk van “ik heb deze data nodig” naar “hier is mijn spreadsheet” te brengen – zonder IT-afdeling.
Conclusie: kies de juiste aanpak voor jouw bedrijf

Samengevat:
- Webcrawling is bedoeld om pagina’s te ontdekken en te indexeren – denk aan zoekmachines en site-audits.
- Webscraping is bedoeld om specifieke, bruikbare data te verzamelen – denk aan leads, prijsmonitoring of contentaggregatie.
- Voor de meeste zakelijke gebruikers is scraping wat je zoekt. En je hoeft er geen programmeur voor te zijn.
Het web wordt alleen maar groter en complexer. Maar met de juiste aanpak – en de juiste tool – maak je van die chaos overzicht. Ben je klaar met ingewikkelde scrapers of wachten op IT? Probeer Thunderbit eens. Je zult versteld staan wat je in twee klikken voor elkaar krijgt (en misschien houd je eindelijk je weekend vrij).
Wil je Thunderbit in actie zien? Installeer onze Chrome-extensie, of lees meer tips en handleidingen op de Thunderbit Blog.
Installeer Thunderbit Chrome-extensie
Veel succes met scrapen (en alleen crawlen als je de volgende Google bouwt)!
Veelgestelde vragen
1. Heb ik voor mijn bedrijf zowel een webcrawler als een scraper nodig?
Niet per se. Als je al weet op welke pagina’s de data staat die je zoekt, is een webscraper zoals Thunderbit voldoende. Crawlers zijn vooral handig als je nieuwe pagina’s wilt ontdekken – bijvoorbeeld om een hele site in kaart te brengen of een SEO-audit te doen.
2. Is webscraping legaal?
In het algemeen is het scrapen van openbare data toegestaan – zeker als je geen logins omzeilt, de gebruiksvoorwaarden respecteert en geen gevoelige informatie verzamelt. Controleer altijd het robots.txt-bestand en het privacybeleid van een website, zeker voor zakelijk gebruik.
3. Waarin verschilt Thunderbit van andere webscrapingtools?
Thunderbit is speciaal ontwikkeld voor zakelijke gebruikers zonder programmeerkennis. In tegenstelling tot traditionele scrapers die HTML-kennis of handmatige setup vereisen, gebruikt Thunderbit AI om velden te herkennen, subpagina’s te bezoeken en data direct in het gewenste formaat te leveren – alles in slechts twee klikken.
4. Kan Thunderbit omgaan met dynamische websites en ingelogde pagina’s?
Ja. Thunderbit biedt scraping in de browser voor ingelogde sessies en dynamische content, én cloud-scraping voor snelheid en schaal. Je kiest zelf de beste modus voor jouw type data.
Verder lezen
- Wat is data scraping en hoe doe je het in 2025
- Hoeveel websites zijn er wereldwijd?
- Wat is een webcrawler? | Hoe webspiders werken | Cloudflare
Probeer AI-webscraper gratis Get Started Free




