
Elke keer dat je je CRM synchroniseert, verzendupdates ophaalt of twee SaaS-tools koppelt, doet een REST API achter de schermen het zware werk. De meeste mensen denken er nooit over na — tot er iets misgaat.
Wat opvallend is: zelfs onder ontwikkelaars is er serieuze verwarring over wat een API “RESTful” maakt. De term wordt zo losjes gebruikt dat een Reddit-draad het botweg verwoordde: “Ik denk niet dat ik ook maar één echt RESTful API heb gebouwd volgens de definitie van Roy Fielding.” En dat zegt een ontwikkelaar, niet een zakelijke gebruiker. Het concept kwam uit Roy Fieldings aan UC Irvine, waar hij REST beschreef als een architectural style — een set ontwerpbeperkingen — geen protocol, geen product en ook geen specificatie die je even downloadt. Toch ligt het REST-gebruik volgens het op 93% onder API-professionals. Bijna iedereen gebruikt het dus, maar verrassend veel teams begrijpen niet precies wat het vraagt. In dit artikel lopen we door de 6 kernkenmerken van een REST API in gewone taal, laten we zien welke onderdelen de meeste teams verkeerd doen, introduceren we een maturiteitsmodel om jezelf te beoordelen en vergelijken we REST met alternatieven als SOAP, GraphQL en gRPC.
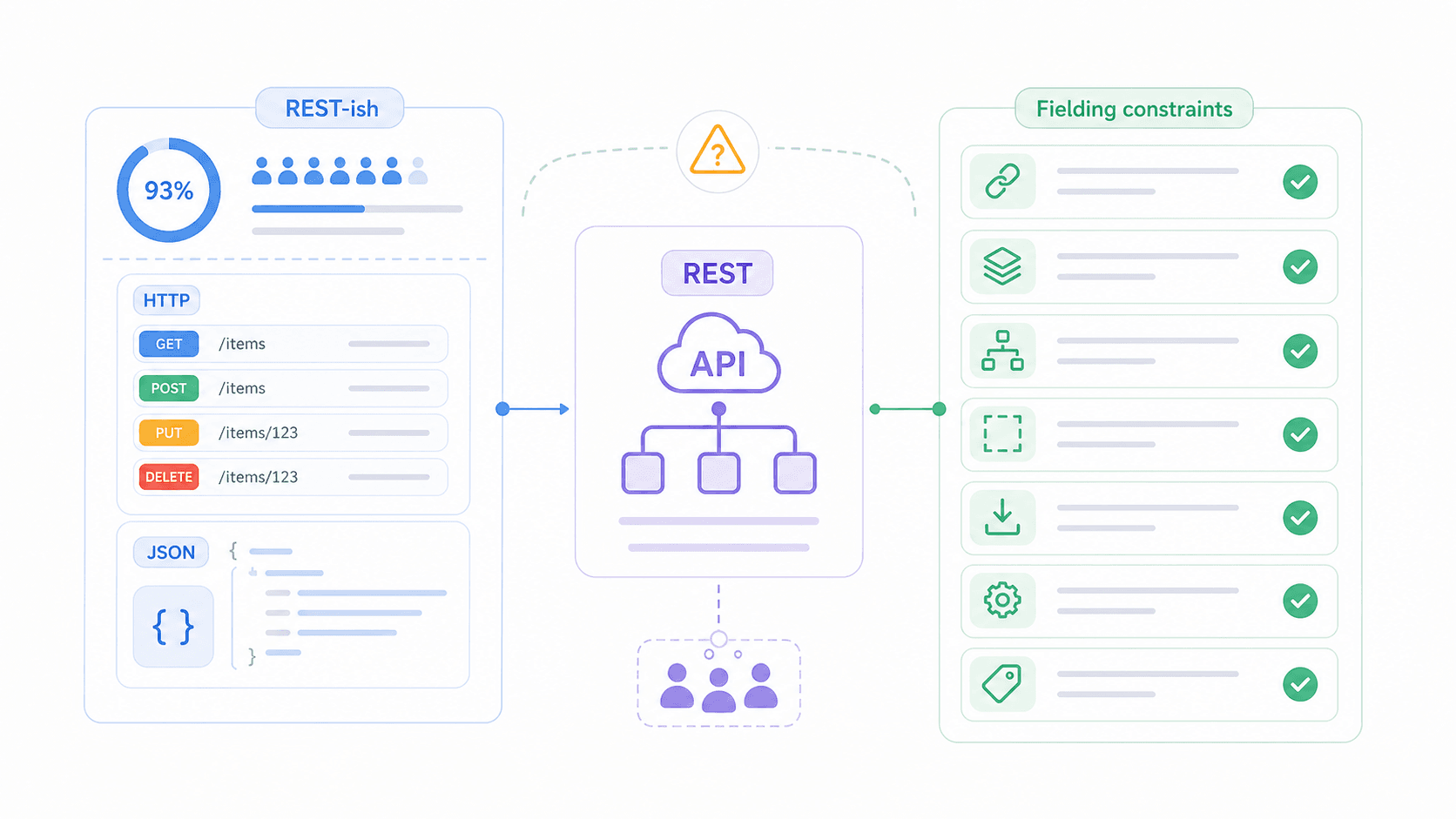
Wat is een REST API? (In gewone taal)
REST (Representational State Transfer) is een set ontwerpregels voor hoe softwaresystemen via een netwerk met elkaar communiceren.
Strikter gezegd is het een architecturale stijl die beperkingen definieert — zoals statelessness, cachebaarheid en een uniforme interface — die bepalen hoe clients (je browser, mobiele app of automatiseringstool) met servers (waar de data staat) omgaan. REST draait meestal over HTTP en geeft doorgaans JSON terug, maar REST zelf hangt niet aan een specifiek protocol of gegevensformaat.
Zie het als etiquette voor een diner. REST schrijft niet voor welk eten je serveert of welke taal je spreekt — het bepaalt hoe je schalen doorgeeft, hoe je om een tweede portie vraagt en hoe je aangeeft dat je klaar bent. Twee systemen die dezelfde etiquette volgen, kunnen voorspelbaar communiceren, ook al hebben ze elkaar nooit eerder “ontmoet”.
Wat REST NIET is: REST is geen product dat je installeert. Het is geen protocol zoals HTTP of SOAP. En een API “RESTful” noemen betekent niet automatisch dat die volledig voldoet aan Fieldings oorspronkelijke beperkingen — meestal wil het alleen zeggen dat de API resource-URL’s en HTTP-methoden gebruikt. Het verschil tussen “REST-achtig” en “echt RESTful” is een van de grootste bronnen van verwarring in de sector, en daar duiken we zo dieper in.
De 6 REST API-kenmerken in één oogopslag
Voordat we de diepte in gaan, hier de samenvatting. Fielding definieerde 6 beperkingen waaraan een API moet voldoen om RESTful te zijn. Vijf zijn verplicht; één is optioneel.
| Beperking | Kernidee | Belangrijkste voordeel | Concreet voorbeeld |
|---|---|---|---|
| Client-server | UI scheiden van data-opslag | Front-end en back-end kunnen onafhankelijk evolueren | React SPA die een REST API aanroept |
| Stateless | Elke aanvraag bevat alle benodigde context | Horizontale schaalbaarheid, geen sessie-afhankelijkheid | Authenticatietoken in elke request-header |
| Cacheable | Responses geven aan of ze gecachet mogen worden | Minder vertraging en serverbelasting | Cache-Control: max-age=3600 op een GET-response |
| Uniforme interface | Gestandaardiseerde interactie met resources | Voorspelbare, leerbare API-oppervlakte | GET /users/42, DELETE /users/42 |
| Gelaagd systeem | De client kan niet zien of hij rechtstreeks met de server praat | Maakt CDN-, gateway- en load balancer-invoeging mogelijk | Client → CDN → API Gateway → App Server |
| Code-on-demand (optioneel) | Server kan uitvoerbare code sturen om de client uit te breiden | Extra clientfunctionaliteit op afroep | API die een JavaScript-widgetsnippet teruggeeft |
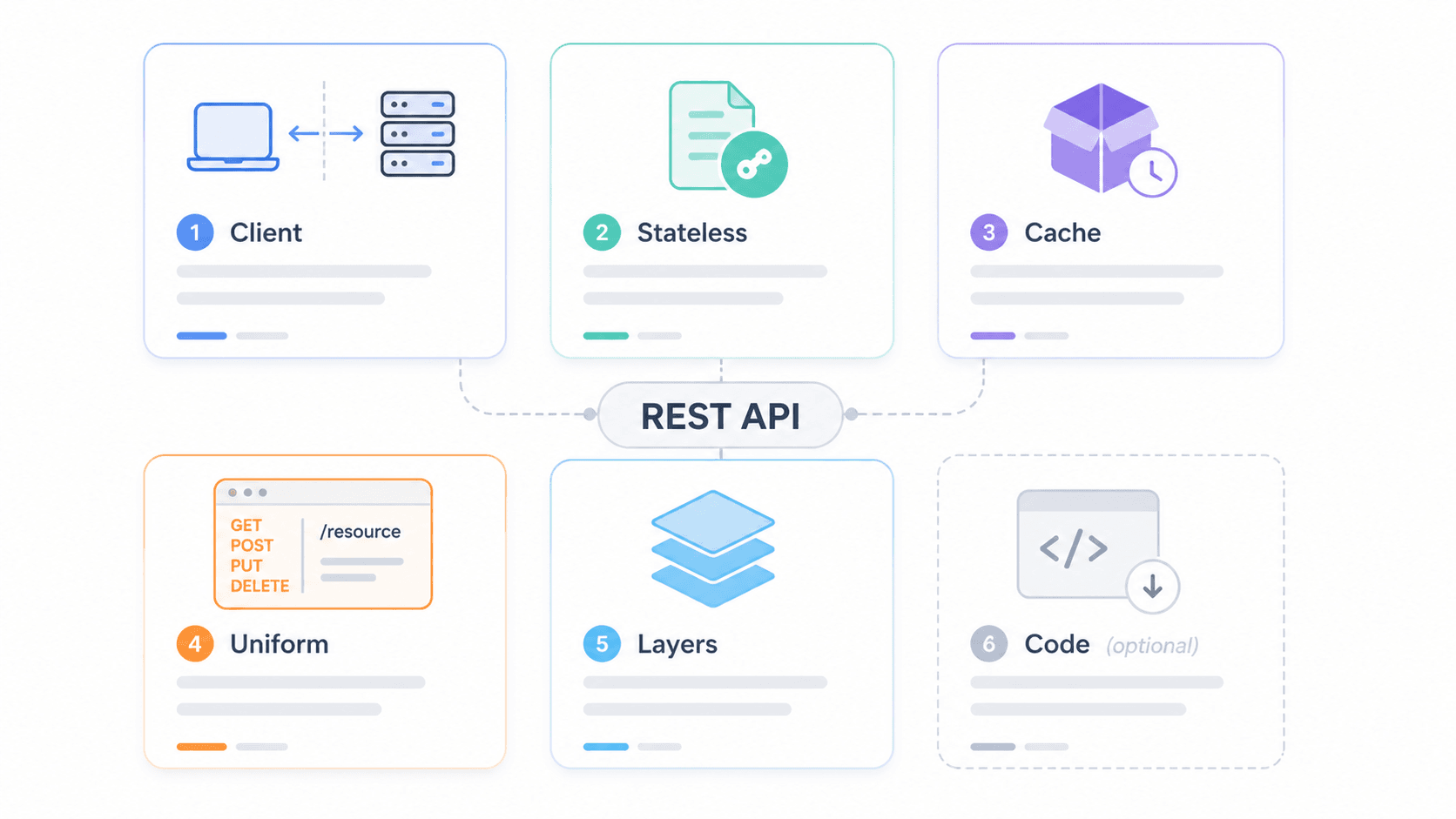
Om te visualiseren hoe deze beperkingen in een echt systeem samenwerken, kun je je deze gelaagde architectuur voorstellen:
1Client / mobiele app
2 ↓
3CDN / edge cache (bijv. Cloudflare)
4 ↓
5API Gateway (rate limiting, authenticatie, CORS)
6 ↓
7Load balancer
8 ↓
9Applicatieservers
10 ↓
11Database / interne servicesDe client praat alleen met de CDN-laag. Die weet niet hoeveel lagen erachter zitten. Dat is de gelaagde-systeembeperking in actie — en tegelijk de plek waar security, caching en schaalvergroting plaatsvinden zonder dat de client dat hoeft te weten.
Nu de gedetailleerde uitleg.
REST API-kenmerken uitgelegd, één voor één
Client-server scheiding
Fieldings eerste beperking: de client (waar gebruikers mee interacteren) en de server (waar data leeft en logica draait) moeten gescheiden zijn. Hij noemde dat separation of concerns.
Waarom is dat in de praktijk belangrijk? Omdat een mobiele bankapp daardoor volledig visueel opnieuw ontworpen kan worden zonder dat de bank de accountdatabase of transactiemotor hoeft aan te raken. De biedt bijvoorbeeld contacten, campagnes, journeys en pushmeldingen aan via resource-endpoints. Of je nu een aangepast dashboard bouwt, een mobiele app maakt of een tool van een derde partij koppelt, de back-end blijft hetzelfde.
Voor zakelijke teams betekent dit snellere iteratie. Je front-end designers en back-end engineers hoeven niet in dezelfde releasecyclus te zitten. Zolang het API-contract stabiel is, kunnen beide kanten onafhankelijk bewegen.
Statelessness
Geen geheugen tussen verzoeken. Elke call van client naar server moet alle informatie bevatten die de server nodig heeft om die te verwerken — de server bewaart niets uit eerdere interacties.
Ik zie het graag als bellen naar een helpdesk waarbij je je probleem elke keer opnieuw moet uitleggen. Irritant? Zeker. Maar het voordeel is enorm: elke beschikbare medewerker kan je helpen, en het callcenter kan 500 extra medewerkers inzetten zonder iets te herontwerpen. Dat is horizontale schaalvergroting.
Technisch gezien betekent statelessness: geen sticky sessions. Een load balancer kan je volgende verzoek naar elke gezonde server sturen. Als één server crasht, neemt een andere het zonder problemen over. Fieldings thesis merkt dat statelessness de zichtbaarheid verbetert (monitoringtools kunnen elk verzoek afzonderlijk begrijpen), de betrouwbaarheid verhoogt (storingen vervuilen geen gedeelde sessiestatus) en de schaalbaarheid vergroot (servers kunnen resources tussen verzoeken vrijmaken).
De praktische kanttekening: echte systemen hebben nog steeds authenticatietokens, winkelwagens en OAuth-flows. Het punt is niet dat er nergens state bestaat — het is dat de server geen client-sessiestatus in het eigen geheugen bewaart tussen verzoeken. Tokens, databases en gedeelde caches regelen dat in plaats daarvan.
Cachebaarheid
Kan deze response opnieuw worden gebruikt? Dat is de vraag die cachebaarheid beantwoordt. Responses moeten expliciet aangeven of ze gecachet kunnen worden, en zo ja, dan hergebruiken clients en tussenpartijen (zoals CDN’s) ze voor equivalente toekomstige verzoeken — waardoor de server minder belast wordt en de snelheid toeneemt.
Het HTTP-mechanisme is eenvoudig: headers zoals Cache-Control, ETag, Last-Modified en Expires vertellen caches hoe lang een response geldig is en wanneer opnieuw gecontroleerd moet worden. Voor een zakelijke lezer: zie het als een label op de response waarop staat “dit antwoord is het komende uur geldig” of “vraag me altijd vers op”.
De prestatie-impact is reëel. De tests van lieten 50–100 ms verbetering zien in tail cache hit response times. En Fieldings eigen thesis documenteert hoe webverkeer groeide van 100.000 requests per dag in 1994 naar 600.000.000 requests per dag in 1999 — waarbij caching een cruciale ontwerpfactor was.
Wat meestal cachebaar is: productcatalogi, openbare blogcontent, land-/valutalijsten, API-documentatie.
Wat meestal niet cachebaar is: persoonlijke dashboards, checkout-totalen, banksaldi, adminrapporten.
Uniforme interface
Dit is de beperking die Fielding zelf de centrale eigenschap noemde die REST onderscheidt van andere architecturale stijlen. Het standaardiseert hoe clients met resources omgaan, waardoor API’s voorspelbaar worden.
Vier subbeperkingen vallen hieronder:
- Resource-identificatie: Elke resource krijgt een stabiele URI.
/customers/123is een klant./orders/456is een bestelling. - Manipulatie via representaties: Clients werken met representaties (JSON, XML, HTML) van resources, niet met de interne objecten van de server.
- Zelfbeschrijvende berichten: Requests en responses bevatten genoeg metadata — methode, statuscode, contenttype, foutdetails — zodat elke tussenlaag of client ze kan begrijpen.
- HATEOAS (Hypermedia as the Engine of Application State): Responses bevatten links naar gerelateerde acties en resources, zodat clients kunnen ontdekken wat ze hierna moeten doen zonder elk endpoint hard te coderen.
De mapping van HTTP-methoden is het meest zichtbare onderdeel van de uniforme interface:
| HTTP-methode | CRUD-betekenis | Safe? | Idempotent? | Voorbeeld |
|---|---|---|---|---|
| GET | Lezen | Ja | Ja | GET /products/42 |
| POST | Maken / actie | Nee | Nee | POST /orders |
| PUT | Gehele resource vervangen | Nee | Ja | PUT /users/42 |
| PATCH | Gedeeltelijke update | Nee | Niet gegarandeerd | PATCH /users/42 |
| DELETE | Verwijderen | Nee | Ja | DELETE /sessions/abc |
De stellen expliciet dat GET safe moet zijn, en dat GET, PUT en DELETE idempotent moeten zijn. Bekende API’s van GitHub, Stripe en Spotify volgen deze patronen nauwgezet, waardoor ontwikkelaars die de ene leren, de andere snel oppakken.
Gelaagd systeem
Je client weet niet of hij met de origin server, een CDN-cache, een API-gateway of een load balancer praat. En dat is precies de bedoeling: elke component ziet alleen zijn aangrenzende laag.
Dat maakt mogelijk:
- CDN’s zoals Cloudflare voor je API, om responses te cachen en te versnellen
- API-gateways (AWS API Gateway, Kong, Apigee) voor authenticatie, rate limiting en quota
- Load balancers die stateless verzoeken verdelen over meerdere appservers
Het vermeldt dat AWS API Gateway gebruikt, 26% Azure’s gateway en 31% meerdere gateways tegelijk. Gelaagde architectuur is niet theoretisch — zo werken productiesystemen echt.
De afweging: elke laag voegt een beetje latency toe. Maar Fielding betoogde dat gedeelde caching op tussenliggende lagen die overhead in de meeste praktijksituaties ruimschoots compenseert.
Code-on-demand (optioneel)
Dit is de buitenbeentje. Code-on-demand is de enige optionele REST-beperking: de server kan uitvoerbare code — zoals JavaScript — sturen om clientfunctionaliteit dynamisch uit te breiden.
Het meest voorkomende praktijkvoorbeeld is simpelweg een webpagina die JavaScript van een server laadt. Maar voor typische JSON REST API’s die worden gebruikt door mobiele apps, backendjobs of automatiseringstools, wordt code-on-demand vrijwel nooit gebruikt. API-clients willen over het algemeen geen willekeurige code van een externe server uitvoeren.
Voor de meeste lezers is deze beperking een voetnoot. Hij staat in Fieldings model voor de volledigheid, maar speelt in de dagelijkse API-beoordeling nauwelijks een rol.
Wat de meeste mensen verkeerd doen: zijn de meeste REST API’s eigenlijk wel RESTful?
Dit is het deel waar niemand graag over praat: de meeste productie-API’s die zichzelf “RESTful” noemen, zijn in werkelijkheid HTTP JSON API’s met REST-achtige conventies. Ze gebruiken resource-URL’s, HTTP-methoden en statuscodes — en daarmee houdt het meestal op. In een Reddit-draad in r/softwarearchitecture gaven ontwikkelaars toe dat ze nog nooit een echt Fielding-conforme REST API hadden gebouwd. Een andere discussie in r/learnprogramming liep uit op een debat over de vraag of iedereen het überhaupt eens kan worden over wat “RESTful” betekent.
Een studie uit 2026 waarin 16 REST API-experts werden geïnterviewd, vond dat richtlijnen de bruikbaarheid verbeteren, maar dat ontwikkelaars duidelijke weerstand tonen tegen strikte REST-regels — onder meer vanwege de omvang van richtlijnen en een slechte aansluiting op hun specifieke organisatie.
Waar landen die beperkingen dan in de praktijk?
| Beperking | Toepassing in de praktijk | Waarom |
|---|---|---|---|
| Client-server | ✅ Bijna universeel | Fundamenteel voor webarchitectuur; moeilijk te vermijden |
| Statelessness | ✅ Bijna universeel | Nodig voor horizontale schaal; gangbare praktijk |
| Uniforme interface (basis) | ✅ Vaak | Resource-URI’s + HTTP-verbs zijn het standaardpatroon |
| Cachebaarheid | ⚠️ Inconsistent | Veel teams laten Cache-Control-headers helemaal weg |
| Gelaagd systeem | ⚠️ Impliciet | CDN’s en gateways bestaan, maar zijn niet altijd bewust ontworpen |
| HATEOAS | ❌ Zeldzaam | De meeste clients hardcoden endpoints; link-gebaseerde ontdekking voegt complexiteit toe |
| Code-on-demand | ❌ Zeer zeldzaam | Per definitie optioneel; wordt bijna nooit geïmplementeerd in JSON API’s |
Waarom teams HATEOAS overslaan: clientontwikkelaars lezen liever OpenAPI-documentatie en gebruiken SDK’s dan dat ze runtime dynamisch links volgen. HATEOAS vereist stabiele media types, definities van link-relaties en modellering van workflows — de kortetermijnkosten zijn hoog, en de opbrengst is voor de meeste teams niet duidelijk.
De praktische conclusie: een API hoeft niet 100% Fielding-conform te zijn om nuttig te zijn. Maar weten welke beperkingen je hebt overgeslagen — en wat je daarmee verliest — helpt je betere ontwerp- en integratiekeuzes te maken.
Het Richardson-maturiteitsmodel: hoe RESTful is je API echt?
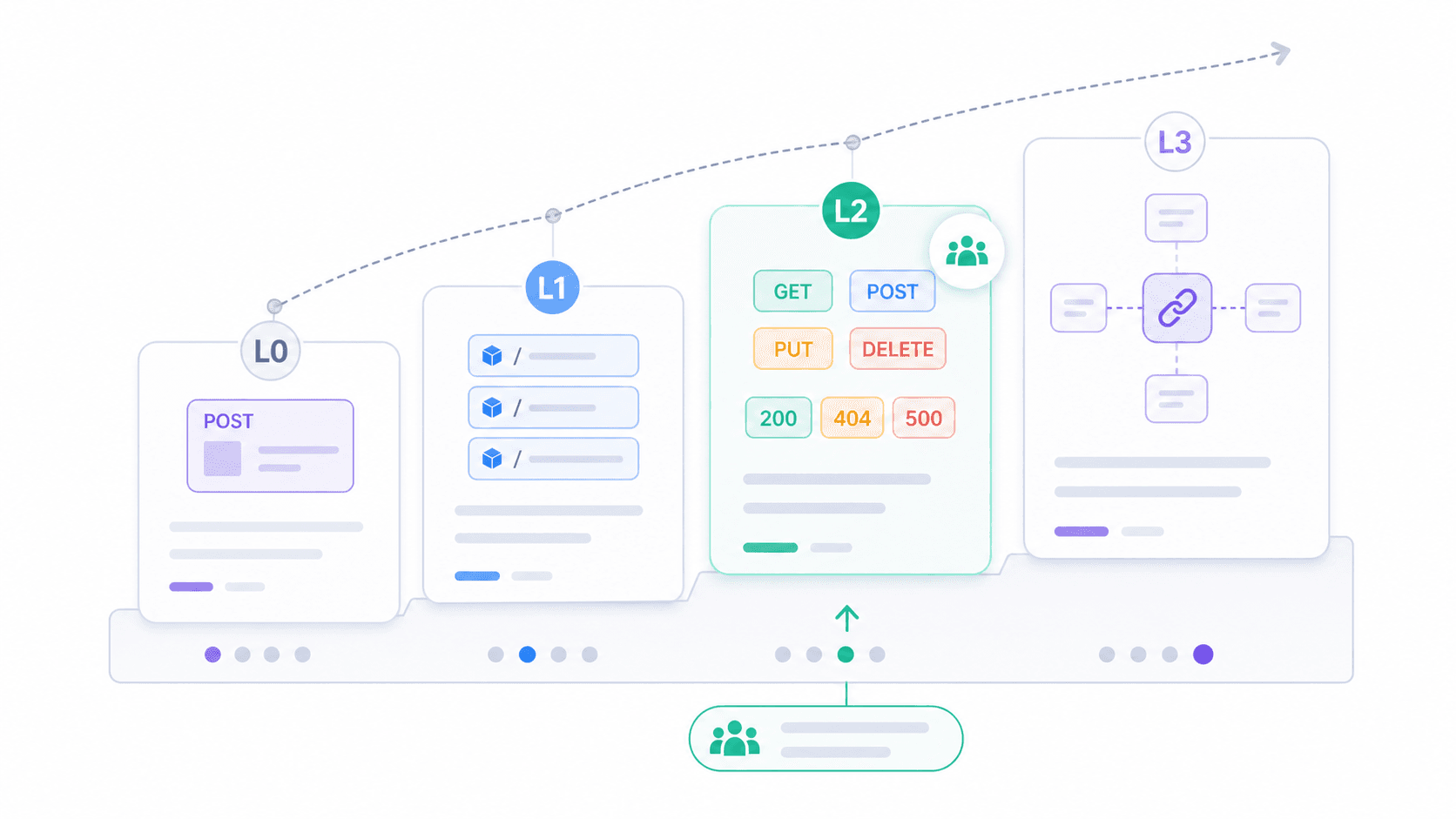
Als de binaire vraag “Is het RESTful of niet?” niet zo nuttig voelt, biedt het Richardson-maturiteitsmodel een praktischer kader. Voorgesteld door Leonard Richardson en , verdeelt het REST-adoptie in vier niveaus.
| Niveau | Naam | Beschrijving | Praktijkvoorbeeld |
|---|---|---|---|
| 0 | The Swamp of POX | Eén URI, één HTTP-verbum (meestal POST) | Legacy SOAP-over-HTTP-endpoints; POST /api met { "action": "getUser" } |
| 1 | Resources | Meerdere URI’s (één per resource), maar nog steeds vooral POST | POST /users/123/getProfile, POST /orders/456/cancel |
| 2 | HTTP-verbs | Correct gebruik van GET, POST, PUT, DELETE + juiste statuscodes | De meeste productie-“REST”-API’s van vandaag |
| 3 | Hypermedia (HATEOAS) | Responses bevatten links naar gerelateerde acties/resources | Spring Data REST, HAL-gebaseerde API’s; in de praktijk zeer weinig publieke API’s |
De meeste API’s die je in het wild tegenkomt zitten op niveau 2. Ze gebruiken resources, verbs en statuscodes correct. Dat is genoeg om praktisch, interoperabel en goed ondersteund door tooling te zijn. Niveau 3 is Fieldings volledige visie, maar de adoptie blijft beperkt.
Op welk niveau zit jouw API? Vraag jezelf af:
- Heeft de API één endpoint voor alles? (Niveau 0)
- Heeft elk bedrijfsobject zijn eigen URI? (Niveau 1+)
- Worden HTTP-methoden en statuscodes correct gebruikt? (Niveau 2)
- Vertellen responses de client wat hij hierna kan doen, zonder externe documentatie? (Niveau 3)
Dit model is veruit de nuttigste tool die ik heb gevonden om door het “is het REST of niet”-debat heen te breken. Het vervangt een binaire beoordeling door een spectrum.
Veelgemaakte REST API-fouten (en hoe je ze voorkomt)
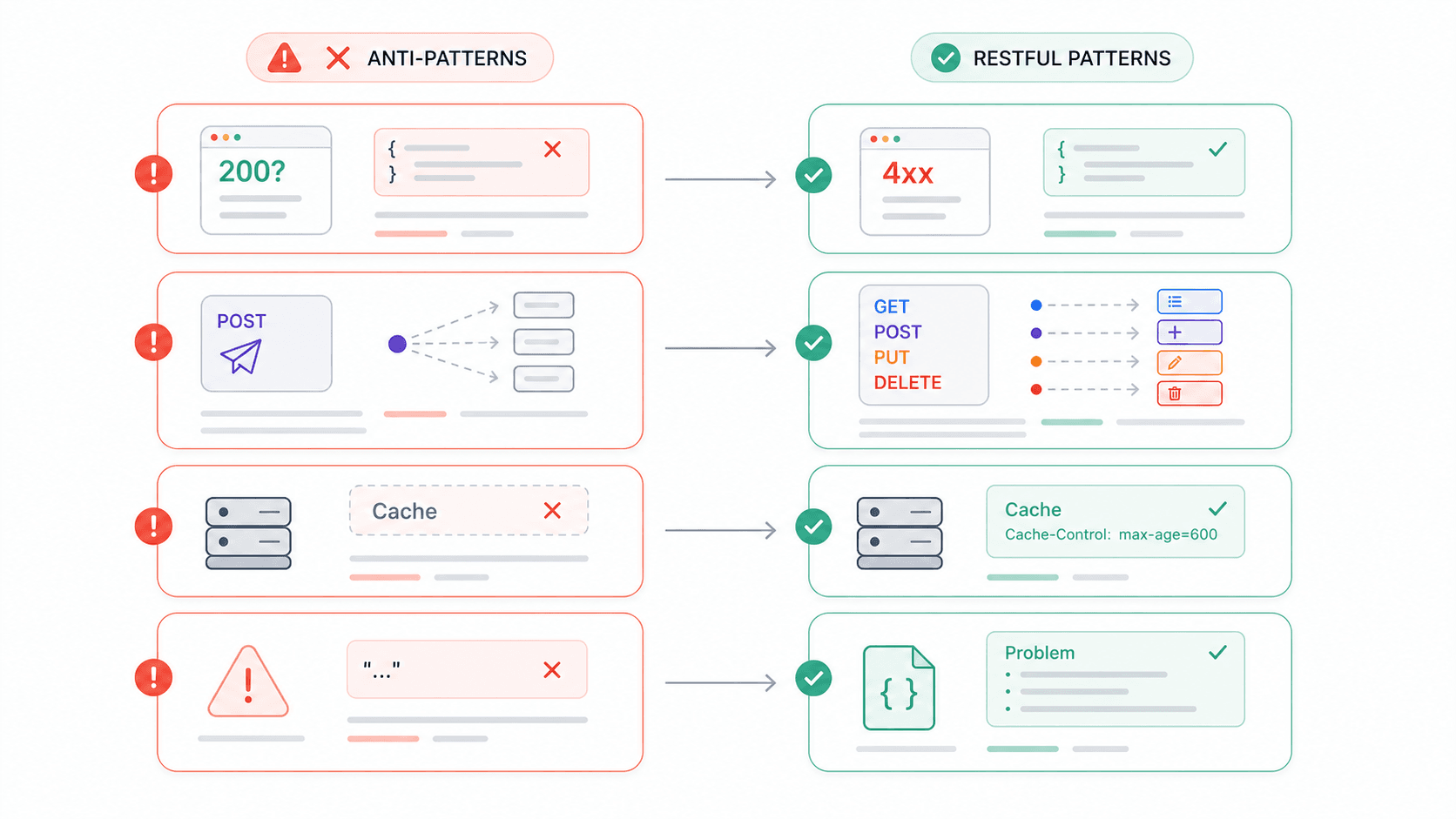
Ik heb genoeg tijd besteed aan het integreren van API’s van derden om een eigen lijstje met frustraties te hebben. En op basis van ontwikkelaarsfora ben ik niet de enige. Hier zijn de anti-patterns die het vaakst opduiken — en elk ervan is direct te koppelen aan een schending van een REST-beperking.
| Anti-pattern | Waarom het REST breekt | Wat je in plaats daarvan doet |
|---|---|---|---|
| HTTP 200 met foutbody ({ "error": "Invalid username" }) | Schendt zelfbeschrijvende berichten; clients kunnen statuscodes niet vertrouwen | Gebruik passende 4xx/5xx-codes + een gestructureerde foutbody (bijv. application/problem+json) |
| Voor alles POST gebruiken | Negeert de uniforme interface; veilige/idempotente semantiek gaat verloren | Koppel CRUD aan GET/POST/PUT(PATCH)/DELETE |
| Geen Cache-Control-headers | Gooit de cachebaarheid-beperking volledig weg | Stel expliciete cache-instructies in — zelfs no-store voor gevoelige data |
| Vage foutresponses (“409 error”) | Mens en machine kunnen niet vaststellen wat er fout ging | Voeg fouttype, een menselijk leesbare boodschap en een link naar documentatie toe |
| HTTPS niet afdwingen | Bearer tokens en API-keys reizen in platte tekst | Dwing overal TLS af; Google APIs zijn standaard alleen via HTTPS |
| Versies in de request body | Breekt resource-identificatie; gateways en caches kunnen niet goed routeren | Gebruik versionering in de URI-paths (/v1/) of versionering via de Accept-header |
De vereisen officiële HTTP-statuscodes en raden Problem JSON aan voor foutresponses. De specificeren dat Problem Detail alleen voor 4xx/5xx gebruikt mag worden, nooit gemengd met 2xx. Dit zijn geen academische voorkeuren — het zijn productiestandaarden van teams die API’s op schaal draaien.
In een Reddit-draad in r/learnprogramming vroeg een ontwikkelaar oprecht of het oké is om bij fouten altijd HTTP 200 terug te geven. Het feit dat die vraag in 2026 nog steeds terugkomt, laat zien hoe hardnekkig deze anti-patterns zijn.
REST vs SOAP vs GraphQL vs gRPC: hoe verhouden REST API-kenmerken zich?
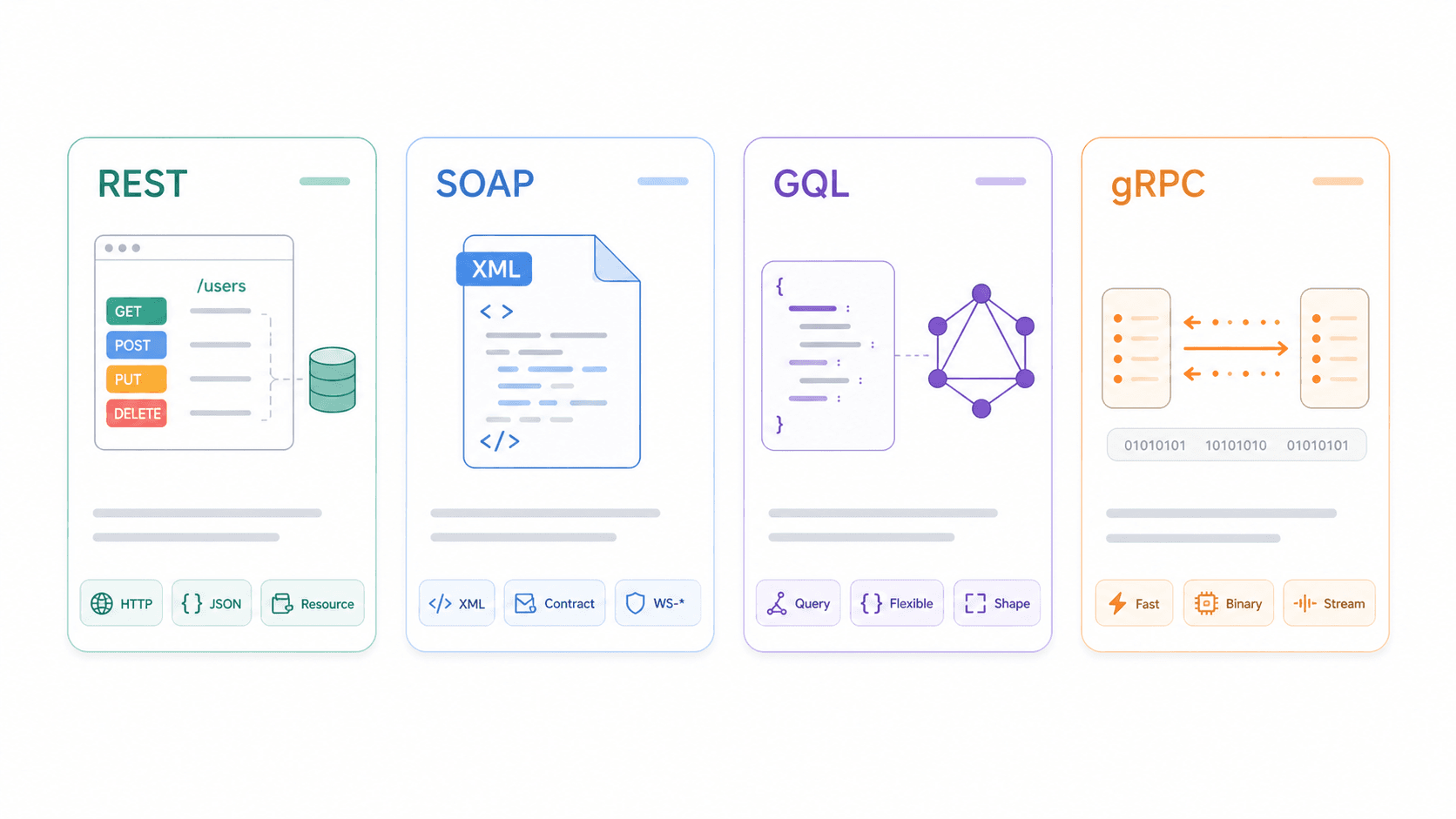
REST op zichzelf begrijpen is nuttig. Het in verhouding tot alternatieven begrijpen is beter.
| Dimensie | REST | SOAP | GraphQL | gRPC |
|---|---|---|---|---|
| Protocol / transport | Architecturale stijl, meestal HTTP | XML-gebaseerd berichtenprotocol; HTTP, SMTP, enz. | Querytaal/runtime, meestal via HTTP | RPC-framework over HTTP/2 |
| Gegevensformaat | Meestal JSON, ook XML/HTML | Alleen XML (WSDL-contracten) | JSON dat overeenkomt met de querystructuur | Protocol Buffers (binair) |
| Caching | ✅ Native HTTP-caching als het goed is ontworpen | ❌ Complex; niet HTTP-cachevriendelijk | ⚠️ Moeilijker (POST + één endpoint + variatie in queries) | ❌ Niet gericht op HTTP-caching |
| Realtime ondersteuning | ❌ Polling/webhooks | ❌ Enterprise-berichtenpatronen | ✅ Subscriptions | ✅ Streaming, lage latency |
| Leercurve | Laag tot middel | Hoog | Middel | Middel tot hoog |
| Het beste voor | Publieke API’s, CRUD, web-/mobiele integraties | Enterprise/legacy, strikte contracten, compliance | Complexe queries, flexibele frontends, mobiele apps | Microservice-naar-microservice, intern high-performance |
De raadt aan te kiezen op basis van compatibiliteit, datavorm, operaties en tooling voor gebruikers.
Wanneer kies je wat:
- REST wint wanneer je brede compatibiliteit, eenvoudige CRUD-operaties en HTTP-caching nodig hebt. Het is de standaard voor publieke API’s en web-/mobiele integraties.
- SOAP is nog steeds logisch voor enterprisesystemen met strikte contracten, WS-Security-eisen of legacy-integraties die voorlopig niet verdwijnen.
- GraphQL blinkt uit wanneer je front-end flexibele, geneste queries nodig heeft en je over- of onderfetching wilt vermijden — veelvoorkomend in complexe mobiele apps.
- gRPC is gebouwd voor interne microservicecommunicatie waar lage latency en binaire serialisatie belangrijker zijn dan browsercompatibiliteit.
Als concreet REST-voorbeeld: de gebruikt eenvoudige POST-endpoints (/distill en /extract), JSON request-/response-bodies, bearer-tokenauthenticatie en standaard HTTP-statuscodes (400, 401, 402, 408, 422, 429, 500, 502, 503, 504). Het laat REST-kenmerken zien in een productie-AI-product zonder SOAP-contracten of de complexiteit van gRPC. Geen showcase van HATEOAS — maar wel een praktische Level 2-API die eenvoudig te integreren is voor zowel zakelijke teams als ontwikkelaars.
Waarom REST API-kenmerken belangrijk zijn voor zakelijke teams
Sales, Operations, Ecommerce — geen van deze teams schrijft API-code. Maar jij kiest wel leveranciers, koppelt tools en bouwt automatiseringsworkflows — en de kwaliteit van een REST API bepaalt direct hoe pijnlijk of juist soepel die integraties zijn.
Tools koppelen: Wanneer je CRM synchroniseert met een marketing automation-platform, bepaalt het REST API-ontwerp of die synchronisatie betrouwbaar of kwetsbaar is. De beheert contacten, campagnes, journeys en pushmeldingen via voorspelbare resource-endpoints. Als die endpoints REST-conventies volgen, kan je RevOps-team automatiseren zonder maatwerkworkarounds.
E-commerce-operaties: De beheren fulfilmentorders, trackingnummers en verzendstatussen. Verzendapps en fulfilmenttools zijn afhankelijk van deze laag. Als de API goed ontworpen is — juiste statuscodes, cachebare catalogusdata, duidelijke foutmeldingen — loopt je logistieke keten soepel. Als dat niet zo is, krijg je mysterieuze storingen om 2 uur ’s nachts.
Leveranciers beoordelen: Als je de 6 beperkingen kent, heb je een praktische checklist:
- Gebruikt de API standaard statuscodes, of ziet elke fout eruit als 200 OK?
- Zijn fouten specifiek genoeg voor je automatiseringstool om te herstellen?
- Is er duidelijke documentatie voor rate limits, paginering en authenticatie?
- Kunnen veelgebruikte responses gecachet worden om belasting te verlagen?
Data-extractie en automatisering: Tools zoals gebruiken een op REST gebaseerde architectuur waarmee zakelijke gebruikers gestructureerde data uit websites, PDF’s en afbeeldingen kunnen halen — en die vervolgens exporteren naar Google Sheets, Airtable, Notion of Excel. Thunderbit’s handelt de complexiteit af achter een interface met 2 klikken, maar onder de motorkap zijn het REST-principes — stateless requests, JSON-responses, standaardfouten — die de integratielaag betrouwbaar maken.
Nog één datapunt dat het vermelden waard is: het Postman 2025-rapport vond dat slechts API’s actief ontwerpt met AI-agents in gedachten, terwijl 51% zich zorgen maakt over onbevoegde of overmatige API-aanroepen door AI-agents. Nu automatisering en AI-gestuurde workflows standaard worden in zakelijke teams, zijn voorspelbare REST-patronen, API-sleutels met minimale rechten en rate limits niet alleen een zorg voor ontwikkelaars — het zijn operationele risicofactoren.
Hoe Thunderbit REST-principes toepast voor zakelijke gebruikers
We hebben gebouwd vanuit de aanname dat de meeste gebruikers nooit een REST-specificatie zullen lezen — en dat ook niet zouden hoeven doen. Maar de ontwerpkeuzes die Thunderbit eenvoudig maken, zijn geworteld in dezelfde REST-kenmerken die in dit artikel aan bod komen.
Hier is een korte uitleg van hoe het in de praktijk werkt:
- Installeer de Chrome-extensie vanuit de en open elke website, PDF of afbeelding waaruit je data wilt halen.
- Klik op “AI Suggest Fields” en Thunderbit’s AI leest de pagina en stelt een gestructureerde tabel met kolommen voor — productnamen, prijzen, e-mails, wat de pagina ook bevat.
- Pas indien nodig kolommen aan en klik daarna op “Scrape”. Thunderbit verwerkt paginering, subpagina’s en dynamische content automatisch.
- Exporteer je data naar Google Sheets, Airtable, Notion, CSV of Excel — gratis, zonder betaalmuur.
Voor ontwikkelaars en automatiseringsworkflows biedt Thunderbit’s /distill (schone Markdown-extractie) en /extract (gestructureerde data-extractie) aan als REST-achtige POST-endpoints met JSON-bodies en standaard HTTP-foutcodes. In termen van het Richardson-maturiteitsmodel is dat een solide Level 2 — resources, correcte methoden, betekenisvolle statuscodes.
Als je breder naar web scraping of data-extractie kijkt, hebben we diepgaandere gidsen geschreven over , en .
Belangrijkste inzichten
- REST is een architecturale stijl, geen protocol. Het definieert 6 beperkingen — client-server, stateless, cacheable, uniforme interface, gelaagd systeem en optioneel code-on-demand — die API-ontwerp sturen.
- De meeste “RESTful” API’s zijn niet volledig RESTful. Het grootste deel zit op Richardson Level 2 (resources + HTTP-verbs + statuscodes). HATEOAS en code-on-demand worden zelden geïmplementeerd.
- Het Richardson-maturiteitsmodel is de beste zelfbeoordelingstool. Het vervangt de binaire vraag “REST of niet” door een praktisch spectrum (niveaus 0–3).
- Veelgemaakte fouten — 200 OK bij fouten, overal POST, ontbrekende cache-headers — komen nog steeds veel voor. Als je de beperkingen kent, herken en herstel je deze anti-patterns sneller.
- REST vs SOAP vs GraphQL vs gRPC draait niet om “de beste”, maar om fit. REST domineert publieke API’s en CRUD-integraties. GraphQL past bij complexe frontends. gRPC blinkt uit in interne microservices. SOAP blijft bestaan in enterprise- en legacy-omgevingen.
- Zakelijke teams profiteren van begrip van REST-kenmerken bij het beoordelen van leveranciers, koppelen van tools en bouwen van automatiseringsworkflows. Tools zoals passen REST-principes toe om data-extractie toegankelijk te maken zonder technische expertise.
FAQ’s
Wat zijn de 6 kenmerken van een REST API?
De 6 REST-beperkingen zijn: (1) client-server scheiding, (2) statelessness, (3) cachebaarheid, (4) uniforme interface, (5) gelaagd systeem en (6) code-on-demand (optioneel). De eerste vijf zijn verplicht om een API volgens Fieldings oorspronkelijke definitie als RESTful te beschouwen.
Wat is het verschil tussen REST en RESTful?
REST is de architecturale stijl — de set ontwerpbeperkingen die door Roy Fielding zijn gedefinieerd. “RESTful” beschrijft een API die die beperkingen volgt. In de praktijk voldoen veel API’s die als “RESTful” worden gelabeld slechts gedeeltelijk: ze implementeren meestal resources, HTTP-methoden en statuscodes, maar laten HATEOAS en code-on-demand weg.
Volgen alle REST API’s elke REST-beperking?
Nee. De meeste productie-API’s volgen client-server scheiding, statelessness en een basisvorm van de uniforme interface (resources + HTTP-verbs). Cachebaarheid en gelaagd systeemontwerp worden inconsistent toegepast. HATEOAS is zeldzaam, en code-on-demand wordt bijna nooit gebruikt in JSON API’s.
Wat is het verschil tussen REST en GraphQL?
REST stelt resources beschikbaar via meerdere endpoints met standaard HTTP-methoden (GET, POST, PUT, DELETE). GraphQL gebruikt meestal één endpoint waar clients precies aangeven welke velden ze in een query willen. REST heeft sterkere native HTTP-caching; GraphQL biedt meer flexibiliteit voor complexe, geneste databehoeften en vermindert overfetching.
Wat is HATEOAS, en gebruikt iemand het echt?
HATEOAS (Hypermedia as the Engine of Application State) betekent dat API-responses links bevatten die de client vertellen welke acties hierna beschikbaar zijn — zodat clients door de API kunnen navigeren zonder elk endpoint hard te coderen. Het staat centraal in Fieldings visie op REST (Richardson Level 3), maar in de praktijk implementeren heel weinig publieke API’s het. De meeste teams blijven steken op Level 2 en vertrouwen in plaats daarvan op documentatie en SDK’s.
Meer lezen