

Het web in 2025 is een wilde plek—de helft van het verkeer dat je ziet, is niet eens menselijk. Dat klopt: bots en crawlers zijn inmiddels goed voor meer dan 50% van alle internetactiviteit (Thales Group), en slechts een klein deel daarvan zijn de “goede” bots die je wilt: zoekmachines, social-media-previewers en analytics-hulpen. De rest? Laten we zeggen dat ze niet altijd komen helpen. Als iemand die al jaren automatiserings- en AI-tools bouwt bij Thunderbit, heb ik uit eerste hand gezien hoe de juiste — of verkeerde — crawler je SEO kan maken of breken, je analytics kan vertekenen, je bandbreedte kan opslokken of zelfs een serieus beveiligingsincident kan veroorzaken.
Als je een bedrijf runt, een website beheert of gewoon je digitale huis op orde probeert te houden, is het belangrijker dan ooit om te weten wie er op de deur van je server klopt. Daarom heb ik deze gids voor 2025 samengesteld over de belangrijkste crawlers: wat ze doen, hoe je ze herkent en hoe je je site openhoudt voor de goede bots terwijl je de slechte buiten de deur houdt.
Wat maakt een crawler “bekend”? User-Agent, IP’s en verificatie
Laten we beginnen bij de basis: wat is precies een “bekende” crawler? Simpel gezegd is het een bot die zichzelf identificeert met een consistente user-agent-string (zoals Googlebot/2.1 of bingbot/2.0) en idealiter crawlt vanaf gepubliceerde IP-bereiken of ASN-blokken die je kunt verifiëren (Googlebot-verificatie). De grote spelers — Google, Microsoft, Baidu, Yandex, DuckDuckGo — publiceren documentatie over hun bots en bieden in veel gevallen tools of JSON-bestanden met hun officiële IP’s (Googlebot-IP-lijst, Bingbot-IP-lijst, DuckDuckBot-IP’s).
Maar hier zit de adder onder het gras: alleen op user-agent vertrouwen is riskant. Spoofing komt veel voor — kwaadaardige bots doen zich vaak voor als Googlebot of Bingbot om langs je beveiliging te glippen (SecurityWeek). Daarom is de gouden standaard dubbele verificatie: controleer zowel de user-agent als het IP-adres (of ASN), met reverse-DNS-lookups of gepubliceerde lijsten. Als je een tool zoals Thunderbit gebruikt, kun je dit proces automatiseren — logs extraheren, user-agents matchen en IP’s kruislings controleren om een realtime, betrouwbare lijst te maken van wie je site crawlt.
Hoe gebruik je deze lijst met crawlers?
Wat doe je nu eigenlijk met een lijst van bekende crawlers? Zo zou ik die inzetten:
- Allowlisting: Zorg ervoor dat de bots die je wél wilt (zoekmachines, social-media-previewers) nooit per ongeluk worden geblokkeerd door je firewall, CDN of WAF. Gebruik hun officiële IP’s en user-agents voor nauwkeurige allowlisting.
- Analytics-filtering: Filter botverkeer uit je analytics, zodat je cijfers echte menselijke bezoekers weerspiegelen — en niet alleen Googlebot en AhrefsBot die rondjes over je site draaien (SecurityWeek).
- Botbeheer: Stel crawl-delay- of throttling-regels in voor agressieve SEO-tools en blokkeer of daag onbekende of kwaadaardige bots uit.
- Geautomatiseerde loganalyse: Gebruik AI-tools (zoals Thunderbit) om crawleractiviteit in je logs te extraheren, classificeren en labelen, zodat je trends kunt herkennen, imitaties kunt opsporen en je beleid actueel houdt.
Je crawlerlijst up-to-date houden is geen taak van “instellen en vergeten”. Nieuwe bots verschijnen, oude bots veranderen van gedrag en aanvallers worden elk jaar slimmer. Updates automatiseren — bijvoorbeeld door officiële documentatie of GitHub-repo’s te scrapen met Thunderbit — kan je uren en kopzorgen besparen.
1. Thunderbit: AI-gestuurde herkenning van crawlers en gegevensbeheer
AI-gestuurd crawlerbeheer met Thunderbit Get Started Free
Thunderbit is niet alleen een AI-webscraper — het is een data-assistent voor teams die crawlerverkeer willen begrijpen en beheren. Dit maakt Thunderbit anders:
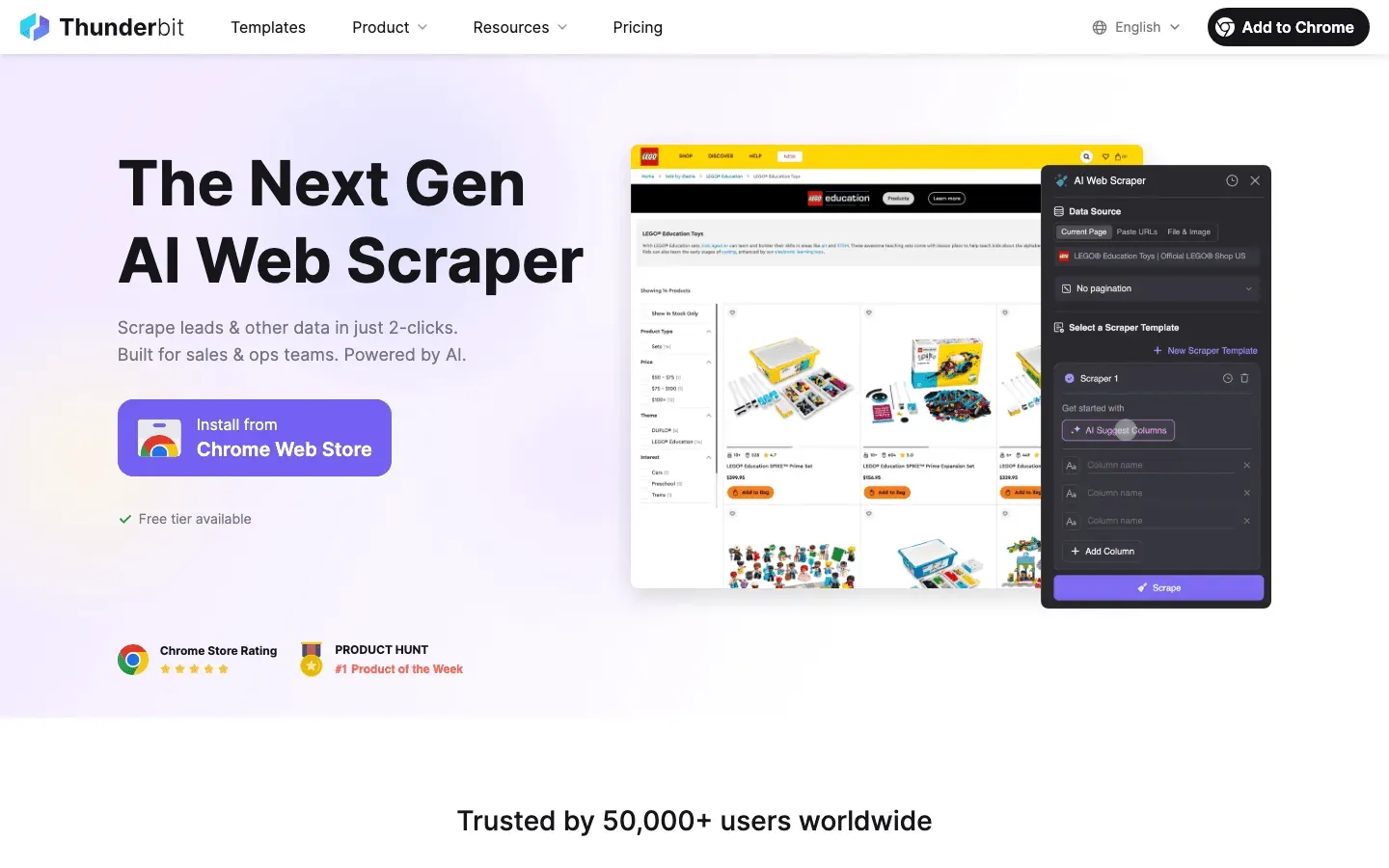
- Semantische voorbewerking: Voordat data wordt geëxtraheerd, zet Thunderbit webpagina’s en logs om in Markdown-achtige gestructureerde content. Die voorbewerking op “semantisch niveau” zorgt ervoor dat de AI daadwerkelijk de context, velden en logica begrijpt van wat het leest. Het is een uitkomst bij complexe, dynamische of JavaScript-zware pagina’s (denk aan Facebook Marketplace of lange commentaarthreads) waar traditionele DOM-gebaseerde scrapers tekortschieten.
- Dubbele verificatie: Thunderbit kan snel officiële crawler-IP-documentatie en ASN-lijsten verzamelen en die vervolgens vergelijken met je serverlogs. Het resultaat? Een “vertrouwde crawler-allowlist” waar je echt op kunt bouwen — geen handmatige controle meer.
- Geautomatiseerde logextractie: Voer je ruwe logs in Thunderbit in en het zet ze om in gestructureerde tabellen (Excel, Sheets, Airtable), met labels voor frequente bezoekers, verdachte paden en bekende bots. Daarna kun je de resultaten doorsturen naar je WAF of CDN voor automatische blokkering, throttling of CAPTCHA-uitdagingen.
- Compliance en audit: Thunderbit’s semantische extractie houdt een helder auditspoor bij — wie wat heeft geraadpleegd, wanneer en hoe je ermee bent omgegaan. Dat is enorm handig voor GDPR, CCPA en andere compliance-eisen.
Ik heb teams Thunderbit zien gebruiken om hun werk voor crawlerbeheer met 80% te verminderen — en eindelijk grip te krijgen op welke bots helpen, welke schade aanrichten en welke gewoon doen alsof.
Probeer Thunderbit voor crawlerbeheer
2. Googlebot: de standaard voor zoekmachines
Googlebot is de gouden standaard voor webcrawlers. Hij is verantwoordelijk voor het indexeren van je site voor Google Search — blokkeer hem, en je kunt net zo goed een bordje “Gesloten” op je digitale etalage hangen.
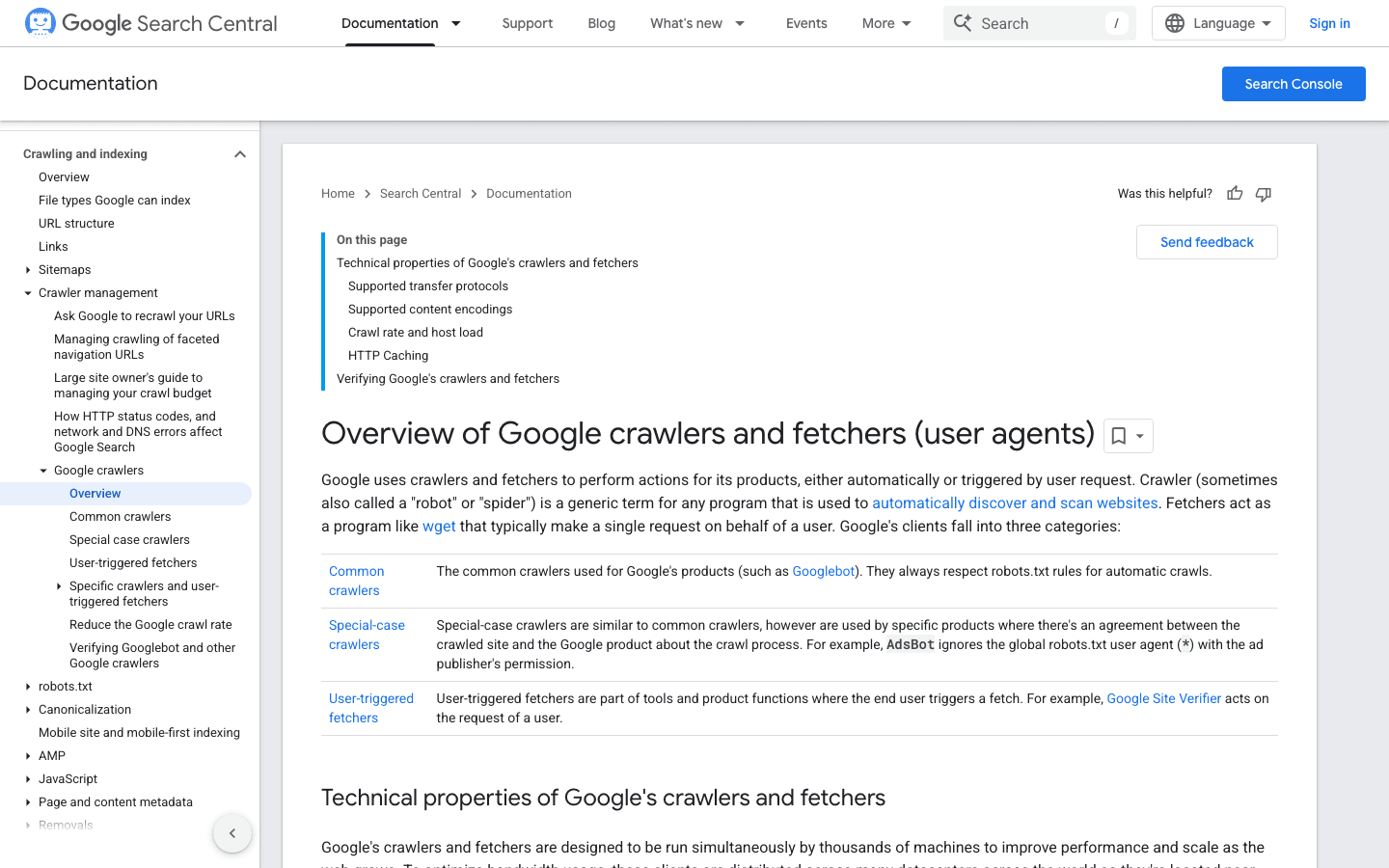
- User-Agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Verificatie: Gebruik Google’s reverse-DNS-methode of de officiële IP-lijst.
- Beheertips: Sta Googlebot altijd toe. Gebruik robots.txt om zijn crawling te sturen, niet te blokkeren, en pas indien nodig de crawl-rate aan in Google Search Console.
3. Bingbot: Microsofts webverkenner
Bingbot voedt de zoekresultaten van Bing en Yahoo. Het is voor de meeste sites de op een na belangrijkste crawler.
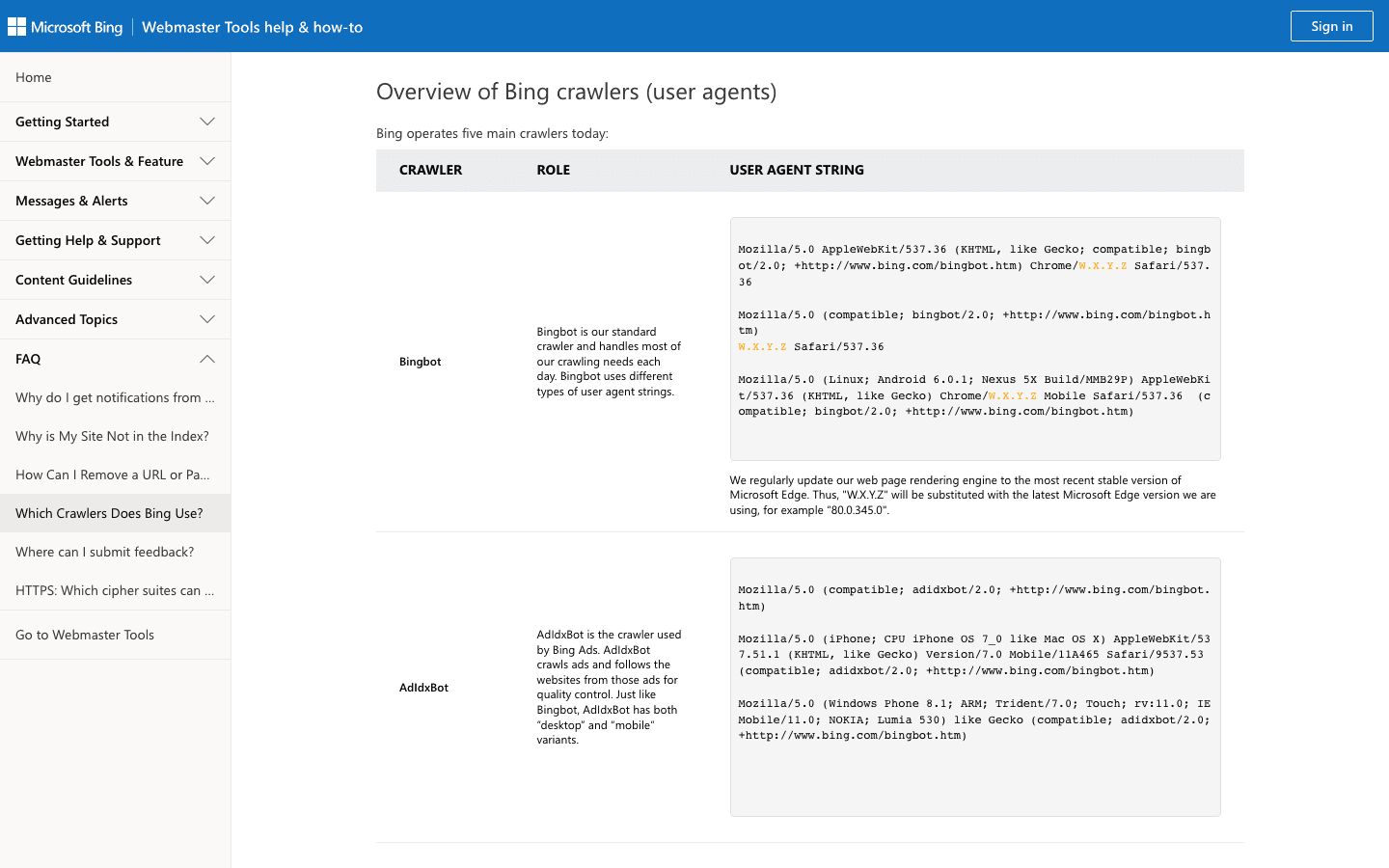
- User-Agent:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Verificatie: Gebruik Microsofts verificatietool en de officiële IP-lijst.
- Beheertips: Sta Bingbot toe, beheer de crawl-rate in Bing Webmaster Tools en gebruik robots.txt voor finetuning.
4. Baiduspider: China’s toonaangevende zoekcrawler
Baiduspider is de toegangspoort tot Chinees zoekverkeer.
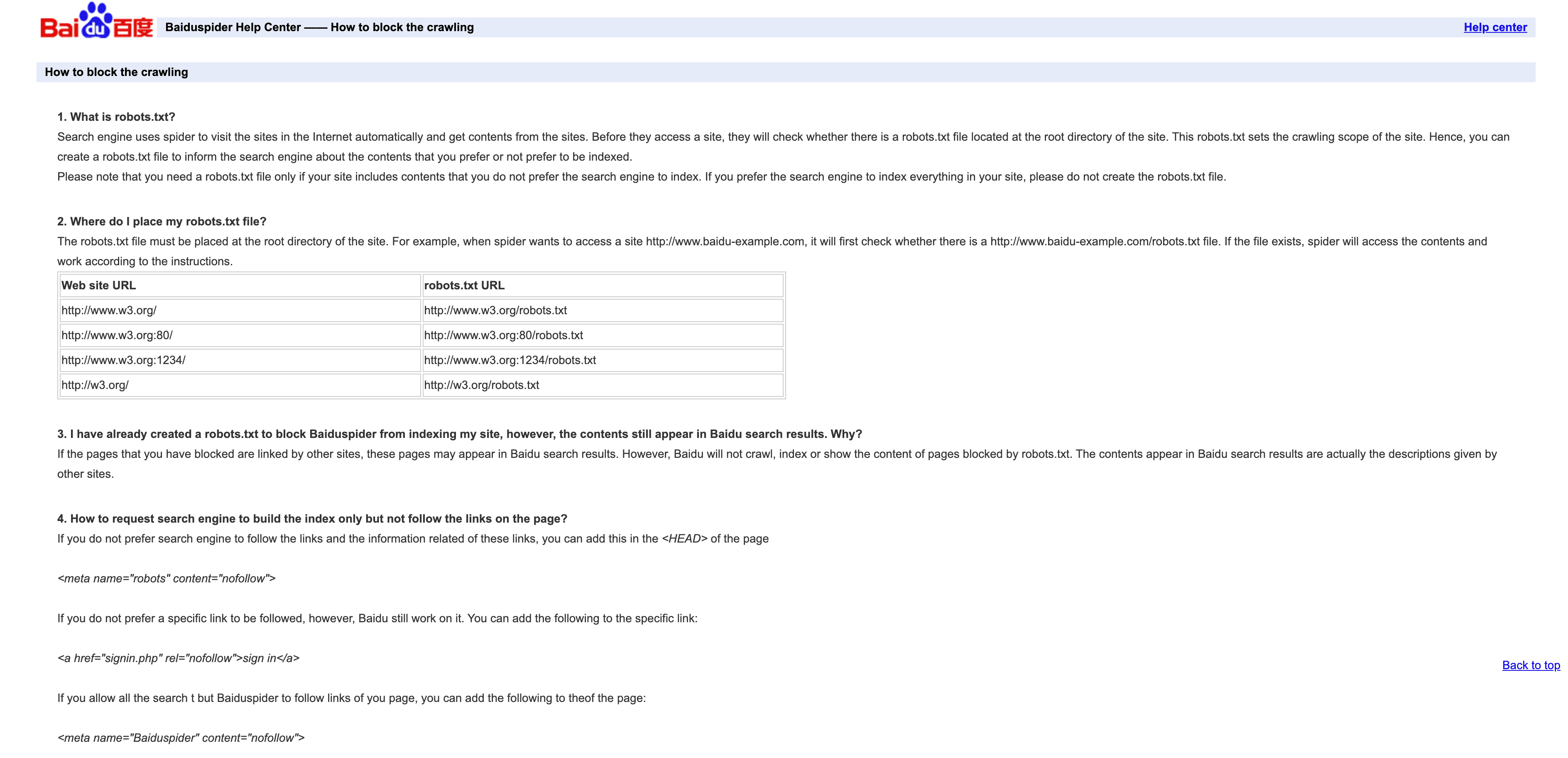
- User-Agent:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - Verificatie: Geen officiële IP-lijst; controleer op
.baidu.comin reverse DNS, maar wees je bewust van de beperkingen. - Beheertips: Sta toe als je Chinees verkeer wilt. Gebruik robots.txt om regels in te stellen, maar let op: Baiduspider negeert die soms. Als je geen Chinese SEO nodig hebt, overweeg dan throttling of blokkeren om bandbreedte te besparen.
5. YandexBot: de zoekmachinecrawler van Rusland
YandexBot is essentieel voor de Russische en CIS-markten.
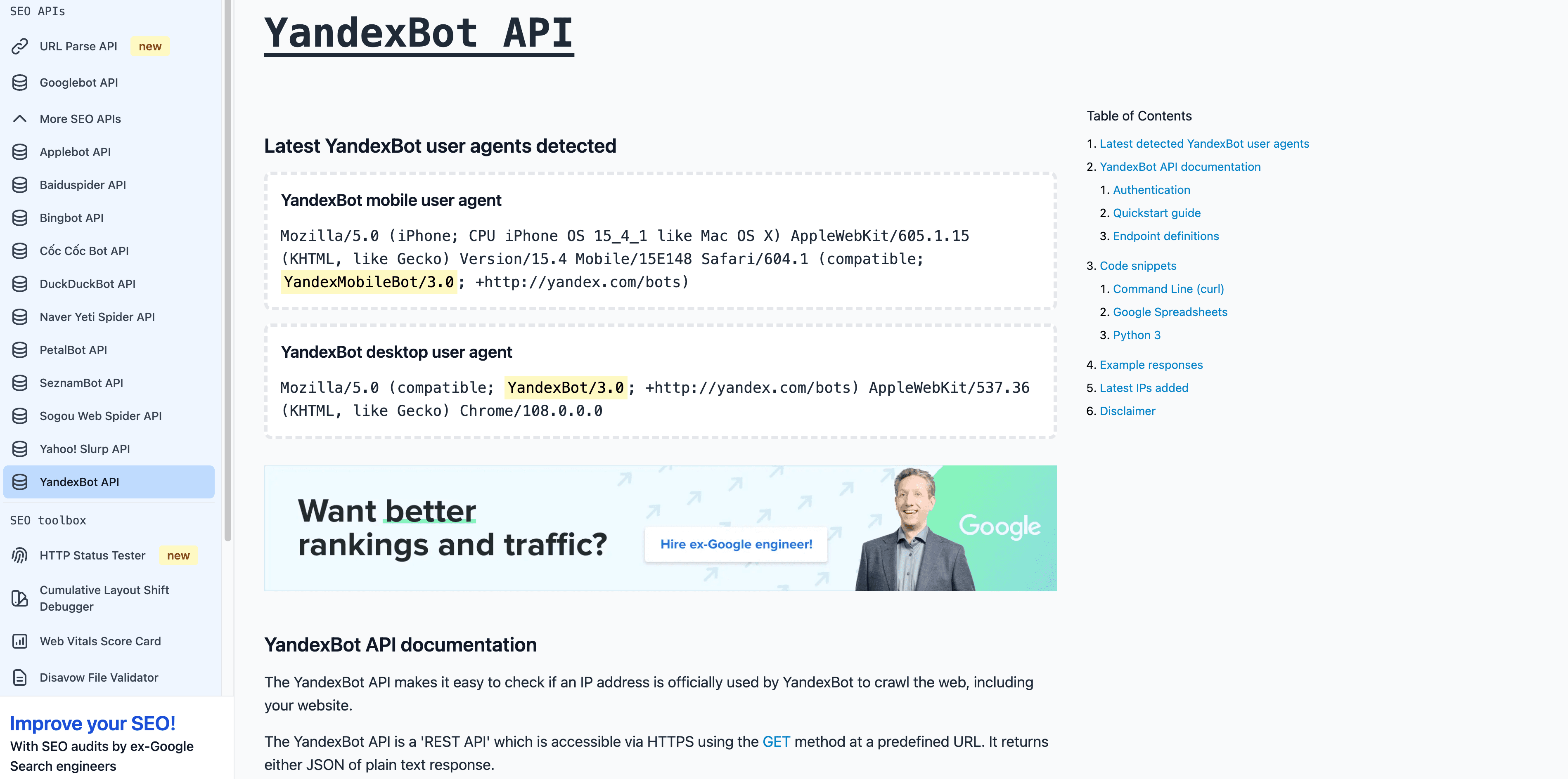
- User-Agent:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - Verificatie: Reverse DNS moet eindigen op
.yandex.ru,.yandex.netof.yandex.com. - Beheertips: Sta toe als je Russischtalige gebruikers bedient. Gebruik Yandex Webmaster voor crawlbeheer.
6. DuckDuckBot: privacygerichte zoekcrawler
DuckDuckBot ondersteunt DuckDuckGo’s privacygerichte zoekfunctie.
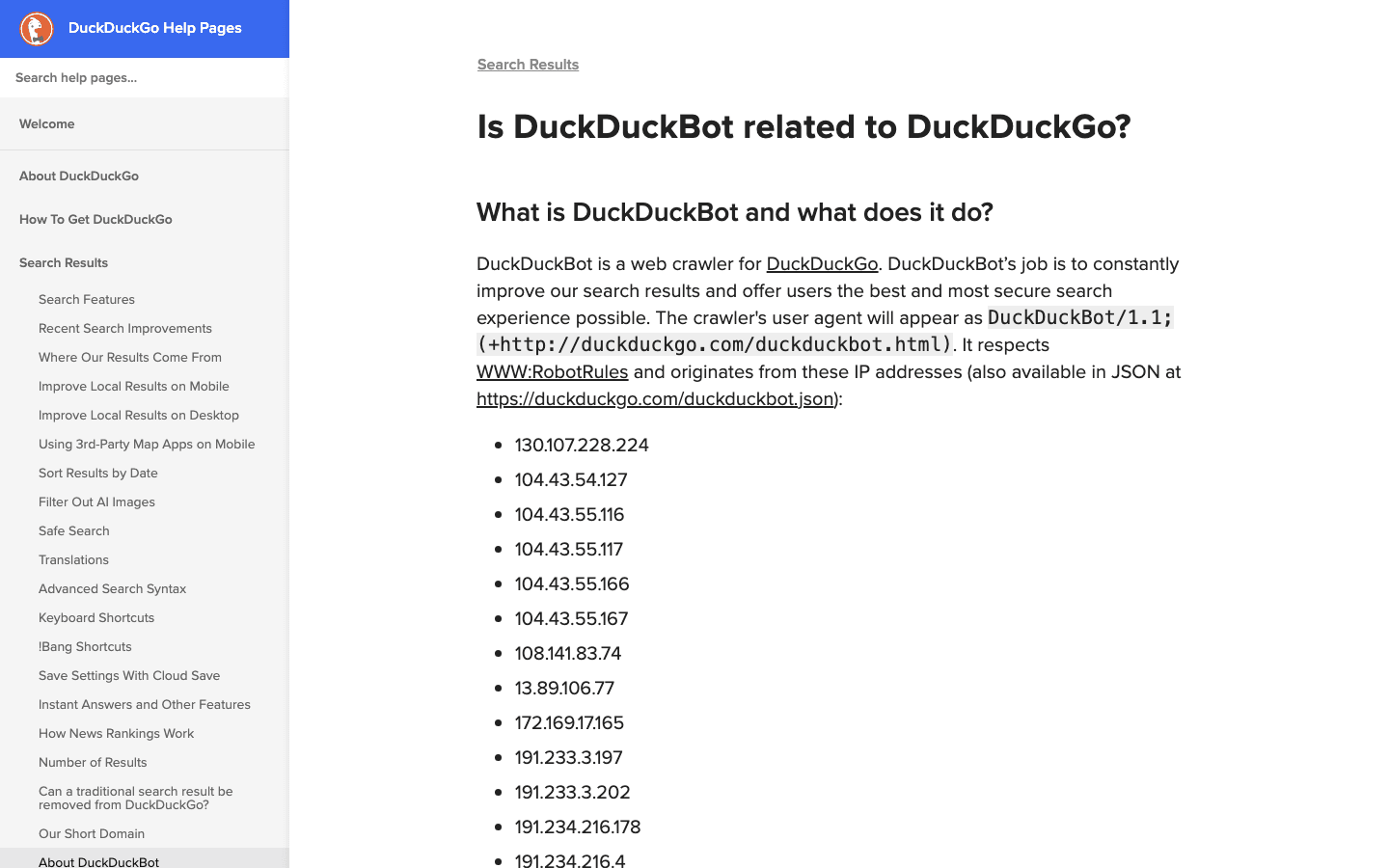
- User-Agent:
DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html) - Verificatie: Officiële IP-lijst (JSON).
- Beheertips: Sta toe, tenzij je helemaal niets met privacygerichte gebruikers te maken wilt hebben. Lage crawlbelasting, eenvoudig te beheren.
7. AhrefsBot: SEO- en backlinkanalyse
AhrefsBot is een topcrawler voor SEO-tools — ideaal voor backlinkanalyse, maar kan veel bandbreedte verbruiken.
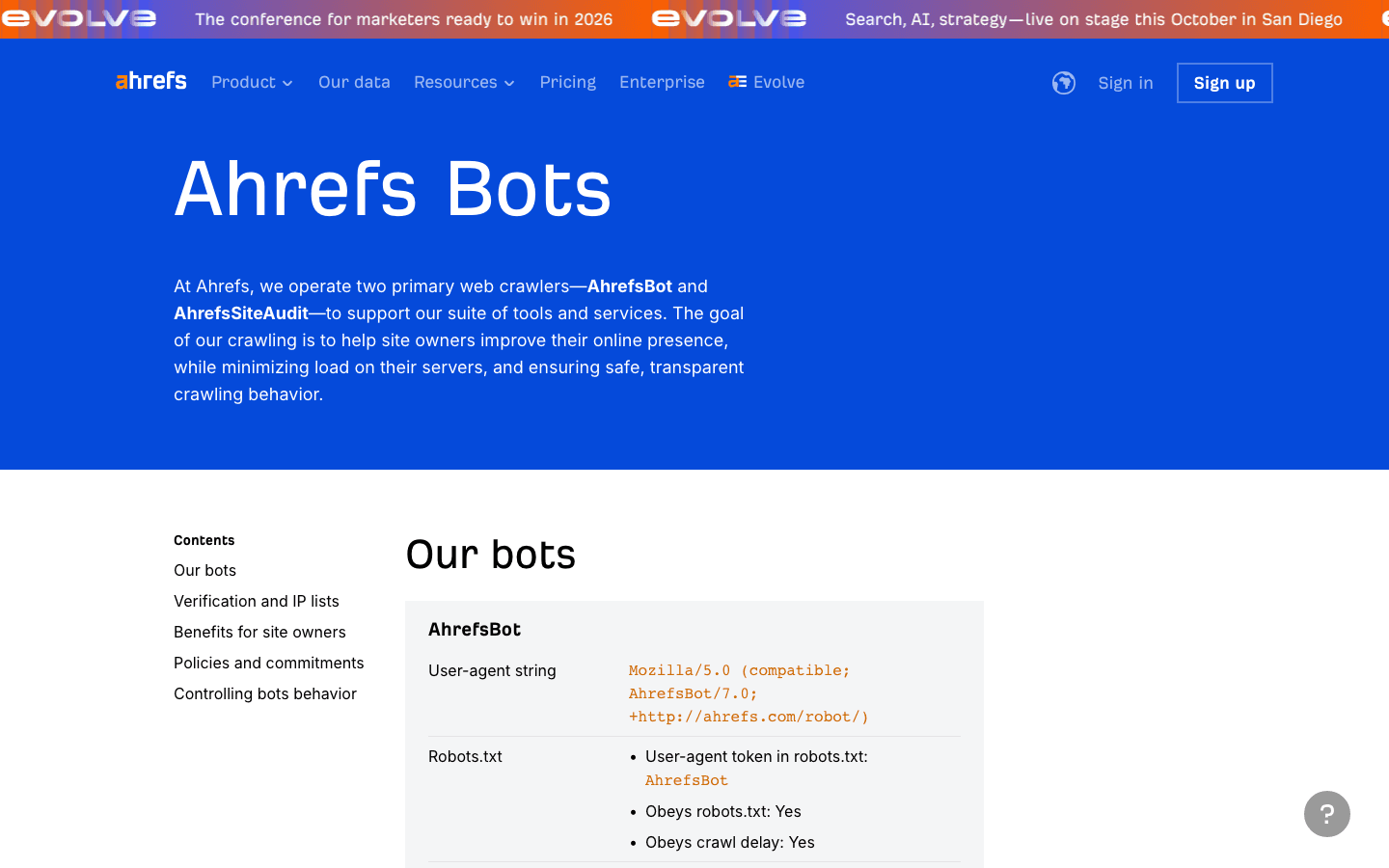
- User-Agent:
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) - Verificatie: Geen openbare IP-lijst; verifieer via UA en reverse DNS.
- Beheertips: Sta toe als je Ahrefs gebruikt. Gebruik robots.txt voor crawl-delay of blokkering. Je kunt je afmelden via e-mail.
8. SemrushBot: concurrerende SEO-inzichten
SemrushBot is nog een belangrijke SEO-crawler.
- User-Agent:
Mozilla/5.0 (compatible; SemrushBot/1.0; +http://www.semrush.com/bot.html)(plus varianten zoalsSemrushBot-BA,SemrushBot-SI, enz.) - Verificatie: Via user-agent; geen openbare IP-lijst.
- Beheertips: Sta toe als je Semrush gebruikt; anders throttle of blokkeer via robots.txt of serverregels.
9. FacebookExternalHit: previewbot voor social media
FacebookExternalHit haalt Open Graph-gegevens op voor linkvoorvertoningen op Facebook en Instagram.
- User-Agent:
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) - Verificatie: Via user-agent; de IP’s behoren tot Facebooks ASN.
- Beheertips: Sta toe voor rijke social previews. Blokkeren betekent geen thumbnails of samenvattingen op Facebook/Instagram.
10. Twitterbot: crawler voor linkvoorvertoningen van X (Twitter)
Twitterbot haalt Twitter Card-gegevens op voor X (Twitter).
- User-Agent:
Twitterbot/1.0 - Verificatie: Via user-agent; Twitter ASN (AS13414).
- Beheertips: Sta toe voor Twitter-voorvertoningen. Gebruik Twitter Card-meta-tags voor het beste resultaat.
Vergelijkingstabel: lijst met crawlers in één oogopslag
| Crawler | Doel | Voorbeeld user-agent | Verificatiemethode | Zakelijke impact | Beheertips |
|---|---|---|---|---|---|
| Thunderbit | AI-log-/crawleranalyse | N.v.t. (tool, geen bot) | N.v.t. | Databeheer, botclassificatie | Gebruik voor logextractie en het opbouwen van allowlists |
| Googlebot | Indexering voor Google Search | Googlebot/2.1 | DNS- & IP-lijst | Cruciaal voor SEO | Altijd toestaan, beheren via Search Console |
| Bingbot | Bing/Yahoo Search | bingbot/2.0 | DNS- & IP-lijst | Belangrijk voor Bing/Yahoo SEO | Toestaan, beheren via Bing Webmaster Tools |
| Baiduspider | Baidu Search (China) | Baiduspider/2.0 | Reverse DNS, UA-string | Belangrijk voor Chinese SEO | Toestaan als je op China mikt, bandbreedte monitoren |
| YandexBot | Yandex Search (Rusland) | YandexBot/3.0 | Reverse DNS naar .yandex.ru | Belangrijk voor Rusland/Oost-Europa | Toestaan als je RU/CIS target, Yandex-tools gebruiken |
| DuckDuckBot | DuckDuckGo Search | DuckDuckBot/1.1 | Officiële IP-lijst | Privacygericht publiek | Toestaan, lage impact |
| AhrefsBot | SEO-/backlinkanalyse | AhrefsBot/7.0 | UA-string, reverse DNS | SEO-tool, kan bandbreedte-intensief zijn | Toestaan/throttlen/blokkeren via robots.txt |
| SemrushBot | SEO-/concurrentieanalyse | SemrushBot/1.0 (plus varianten) | UA-string | SEO-tool, kan agressief zijn | Toestaan/throttlen/blokkeren via robots.txt |
| FacebookExternalHit | Social linkvoorvertoningen | facebookexternalhit/1.1 | UA-string, Facebook ASN | Betrokkenheid op social media | Toestaan voor previews, gebruik OG-tags |
| Twitterbot | Twitter-linkvoorvertoningen | Twitterbot/1.0 | UA-string, Twitter ASN | Betrokkenheid op Twitter | Toestaan voor previews, gebruik Twitter Card-tags |
Je lijst met crawlers beheren: best practices voor 2025
Meer weten over list crawling met AI Get Started Free
- Werk regelmatig bij: Het crawlerlandschap verandert snel. Plan elk kwartaal een review en gebruik tools zoals Thunderbit om officiële lijsten te scrapen en te vergelijken (Human Security).
- Verifieer, vertrouw niet blind: Controleer altijd zowel user-agent als IP/ASN. Laat geen imitaties binnen die je analytics vertekenen of je data scrapen (FriendlyCaptcha).
- Sta goede bots toe: Zorg dat zoek- en social crawlers nooit worden geblokkeerd door anti-botregels of firewalls.
- Throttle of blokkeer agressieve bots: Gebruik robots.txt, crawl-delay of serverregels voor SEO-tools die te hard binnenkomen.
- Automatiseer loganalyse: Gebruik AI-gestuurde tools (zoals Thunderbit) om crawleractiviteit te extraheren, classificeren en labelen — dat bespaart tijd en helpt trends te zien die je anders mist.
- Breng SEO, analytics en beveiliging in balans: Blokkeer niet de bots die je bedrijf vooruithelpen, maar laat de slechte ook niet hun gang gaan.
Download de Thunderbit Chrome-extensie
Conclusie: houd je crawlerlijst actueel en bruikbaar
In 2025 is het beheren van je crawlerlijst niet zomaar een IT-taak — het is een bedrijfskritische verantwoordelijkheid die SEO, analytics, beveiliging en compliance raakt. Nu bots het merendeel van het webverkeer vormen, moet je weten wie er langskomt, waarom en wat je ermee doet. Houd je lijst actueel, automatiseer waar je kunt en gebruik tools zoals Thunderbit om voorop te blijven lopen. Het web wordt alleen maar drukker — en een slimme, bruikbare crawlerstrategie is je beste verdediging én aanval in een bot-gedreven wereld.
Veelgestelde vragen
1. Waarom is het belangrijk om een actuele lijst met crawlers bij te houden?
Omdat bots inmiddels goed zijn voor meer dan de helft van al het webverkeer, en slechts een klein deel nuttig is. Als je lijst actueel is, sta je de goede bots toe (voor SEO en social previews) en blokkeer of throttle je de slechte, waardoor je analytics, bandbreedte en gegevensbeveiliging beschermd blijven.
2. Hoe kan ik zien of een crawler echt is of nep?
Vertrouw niet alleen op de user-agent — verifieer altijd het IP-adres of ASN met officiële lijsten of reverse-DNS-lookups. Tools zoals Thunderbit kunnen dit proces automatiseren door logs te matchen met gepubliceerde bot-IP’s en user-agents.
3. Wat moet ik doen als een onbekende bot mijn site crawlt?
Onderzoek de user-agent en het IP. Als die niet op je allowlist staat en niet overeenkomt met een bekende bot, overweeg dan om hem te throttlen, uit te dagen of te blokkeren. Gebruik AI-tools om nieuwe crawlers te classificeren en te monitoren zodra ze verschijnen.
4. Hoe helpt Thunderbit bij crawlerbeheer?
Thunderbit gebruikt AI om crawleractiviteit uit logs te extraheren, structureren en classificeren, waardoor het eenvoudig wordt om allowlists op te bouwen, imitaties op te sporen en beleid automatisch af te dwingen. De semantische voorbewerking is vooral sterk bij complexe of dynamische sites.
5. Wat is het risico van het blokkeren van een grote crawler zoals Googlebot of Bingbot?
Zoekmachinecrawlers blokkeren kan je site uit de zoekresultaten halen, waardoor je organische verkeer instort. Controleer daarom altijd je firewall, robots.txt en anti-botregels dubbel, zodat je niet per ongeluk de belangrijkste bots buitensluit.
Meer lezen:
- Hoe je elke website kunt scrapen met AI
- Gids voor webscraping in Python: leer aan de hand van echte voorbeelden
- De ultieme lijst van webcrawlers en goede bots in 2025: identificatie, voorbeelden en best practices
- De populairste webcrawler-bots
Probeer Thunderbit voor AI-gestuurd crawlerbeheer Get Started Free




