Het web stroomt over van waardevolle data—of je nu in sales, ecommerce of marktonderzoek zit, webscraping is het geheime wapen voor leadgeneratie, prijsmonitoring en concurrentieanalyse. Maar hier zit de adder onder het gras: nu steeds meer bedrijven scraping inzetten, slaan websites steeds harder terug. Sterker nog, inmiddels zetten , en zijn inmiddels de norm. Als je ooit hebt gezien hoe je Python-script 20 minuten soepel draait en daarna ineens tegen een muur van 403-fouten aanloopt, dan weet je hoe frustrerend dat is.
Ik heb jaren in SaaS en automatisering gewerkt en uit eerste hand gezien hoe scrapingprojecten in een oogwenk kunnen omslaan van “wow, dit is makkelijk” naar “waarom word ik overal geblokkeerd?”. Dus laten we praktisch worden: ik laat je zien hoe je webscraping doet zonder geblokkeerd te worden in Python, deel de beste technieken en codevoorbeelden, en laat zien wanneer het tijd is om AI-gedreven alternatieven zoals te overwegen. Of je nu een Python-pro bent of gewoon aan het scrapen bent (woordgrapje bedoeld), je loopt weg met een toolkit voor betrouwbare data-extractie zonder blokkades.
Wat betekent webscraping zonder geblokkeerd te worden in Python?
In de kern betekent webscraping zonder geblokkeerd te worden dat je data van websites haalt op een manier die hun anti-botverdediging niet activeert. In de Python-wereld gaat het daarbij om meer dan alleen een requests.get()-lus schrijven—het draait om opgaan in het geheel, echte gebruikers nadoen en detectiesystemen steeds een stap voor blijven.
Waarom Python? —dankzij de simpele syntaxis, het enorme ecosysteem (denk aan: requests, BeautifulSoup, Scrapy, Selenium) en de flexibiliteit voor alles van snelle scripts tot gedistribueerde crawlers. Maar populariteit heeft een prijs: veel anti-botsystemen zijn inmiddels afgestemd op het herkennen van Python-gebaseerde scrapingpatronen.
Als je dus betrouwbaar wilt scrapen, moet je verder gaan dan de basis. Dat betekent begrijpen hoe sites bots detecteren en hoe je ze te slim af bent—zonder ethische of juridische grenzen te overschrijden.
Waarom blokkades vermijden belangrijk is voor Python-webscrapingprojecten
Geblokkeerd worden is niet alleen een technisch hobbeltje—het kan hele bedrijfsprocessen ontregelen. Laten we het opdelen:
| Use case | Impact van een blokkade |
|---|---|
| Leadgeneratie | Onvolledige of verouderde prospectlijsten, gemiste verkoopkansen |
| Prijsmonitoring | Gemiste prijswijzigingen van concurrenten, slechte prijsbeslissingen |
| Contentaggregatie | Gaten in nieuws-, review- of onderzoeksdata |
| Marktinformatie | Blinde vlekken bij het volgen van concurrenten of sectoren |
| Vastgoedaanbod | Onnauwkeurige of verouderde objectdata, gemiste kansen |
Als een scraper wordt geblokkeerd, mis je niet alleen data—je verspilt ook middelen, loopt compliance-risico’s en neemt mogelijk slechte zakelijke beslissingen op basis van onvolledige informatie. In een wereld waarin , is betrouwbaarheid alles.
Hoe websites Python-webscrapers detecteren en blokkeren
Websites zijn behoorlijk slim geworden in het spotten van bots. Dit zijn de meest voorkomende anti-scrapingverdedigingen waar je tegenaan loopt (, ):
- IP-adresblokkering: Te veel verzoeken vanaf één IP? Geblokkeerd.
- User-Agent- en headercontroles: Verzoeken met ontbrekende of generieke headers (zoals Python’s standaard
python-requests/2.25.1) springen eruit. - Rate limiting: Te veel verzoeken in korte tijd triggert vertraging of bans.
- CAPTCHA’s: “Bewijs dat je mens bent”-puzzels die bots niet (makkelijk) oplossen.
- Gedragsanalyse: Sites letten op robotachtig gedrag—zoals steeds op dezelfde knop klikken met hetzelfde interval.
- Honeypots: Verborgen links of velden waarmee alleen bots interactie aangaan.
- Browser fingerprinting: Details over je browser en apparaat verzamelen om automatiseringstools te herkennen.
- Cookie- en sessietracking: Bots die cookies of sessies niet goed afhandelen worden gemarkeerd.
Zie het als luchthavenbeveiliging: als je eruitziet, beweegt en handelt als iedereen, loop je er zo doorheen. Kom je aan in een trenchcoat en zonnebril, dan kun je extra vragen verwachten.
Essentiële Python-technieken voor webscraping zonder geblokkeerd te worden
Nu de praktische kant: hoe voorkom je in de praktijk blokkades bij scrapen met Python? Dit zijn de kernstrategieën die elke scraper moet kennen:

Roterende proxies en IP-adressen
Waarom dit belangrijk is: Als al je verzoeken vanaf hetzelfde IP komen, ben je een makkelijk doelwit voor IP-bans. Met roterende proxies verdeel je verzoeken over meerdere IP’s, waardoor je veel moeilijker te blokkeren bent.
Hoe je dit doet in Python:
1import requests
2proxies = [
3 "<http://proxy1.example.com:8000>",
4 "<http://proxy2.example.com:8000>",
5 # ...meer proxies
6]
7for i, url in enumerate(urls):
8 proxy = {"http": proxies[i % len(proxies)]}
9 response = requests.get(url, proxies=proxy)
10 # verwerk responseJe kunt betaalde proxyservices gebruiken (zoals residential proxies of roterende proxies) voor meer betrouwbaarheid ().
User-Agent en aangepaste headers instellen
Waarom dit belangrijk is: Standaard Python-headers schreeuwen “bot”. Nadoen van echte browsers doe je door user-agent en andere headers in te stellen.
Voorbeeldcode:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4 "Accept-Encoding": "gzip, deflate, br",
5 "Connection": "keep-alive"
6}
7response = requests.get(url, headers=headers)Wissel user-agents af voor extra stealth ().
Verzoekstiming en patronen randomiseren
Waarom dit belangrijk is: Bots zijn snel en voorspelbaar; mensen zijn traag en willekeurig. Voeg vertragingen toe en wissel je navigatie af.
Python-tip:
1import time, random
2for url in urls:
3 response = requests.get(url)
4 time.sleep(random.uniform(2, 7)) # Wacht 2–7 secondenAls je Selenium gebruikt, kun je ook klikpaden en scrollpatronen randomiseren.
Cookies en sessies beheren
Waarom dit belangrijk is: Veel sites vereisen cookies of sessietokens om content te kunnen openen. Bots die dit negeren, worden geblokkeerd.
Hoe je dit in Python beheert:
1import requests
2session = requests.Session()
3response = session.get(url)
4# session verwerkt cookies automatischGebruik voor complexere flows Selenium om cookies op te vangen en opnieuw te gebruiken.
Menselijk gedrag simuleren met headless browsers
Waarom dit belangrijk is: Sommige sites gebruiken JavaScript, muisbewegingen of scrollen als signaal dat het om echte gebruikers gaat. Headless browsers zoals Selenium of Playwright kunnen die acties nabootsen.
Voorbeeld met Selenium:
1from selenium import webdriver
2from selenium.webdriver.common.action_chains import ActionChains
3import random, time
4driver = webdriver.Chrome()
5driver.get(url)
6actions = ActionChains(driver)
7actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
8time.sleep(random.uniform(2, 5))Dit helpt je gedragsanalyse en dynamische content te omzeilen ().
Geavanceerde strategieën: CAPTCHA’s en honeypots omzeilen in Python
CAPTCHA’s zijn ontworpen om bots meteen te stoppen. Hoewel sommige Python-bibliotheken eenvoudige CAPTCHA’s kunnen oplossen, vertrouwen de meeste serieuze scrapers op diensten van derden (zoals 2Captcha of Anti-Captcha) om ze tegen betaling op te lossen ().
Voorbeeldintegratie:
1# Pseudocode voor gebruik van de 2Captcha API
2import requests
3captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
4# Wacht op oplossing en dien die daarna in met je verzoekHoneypots zijn verborgen velden of links waarmee alleen bots interactie aangaan. Klik of verstuur niets dat in een echte browser niet zichtbaar is ().
Robuuste request-headers ontwerpen met Python-bibliotheken
Naast de user-agent kun je ook andere headers roteren en randomiseren (zoals Referer, Accept, Origin, enzovoort) om nog beter op te gaan in normaal verkeer.
Met Scrapy:
1class MySpider(scrapy.Spider):
2 custom_settings = {
3 'DEFAULT_REQUEST_HEADERS': {
4 'User-Agent': '...',
5 'Accept-Language': 'en-US,en;q=0.9',
6 # Meer headers
7 }
8 }Met Selenium: gebruik browserprofielen of extensies om headers in te stellen, of injecteer ze via JavaScript.
Houd je headerlijst up-to-date—kopieer echte browserverzoeken via de Developer Tools van je browser ter inspiratie.
Wanneer traditioneel Python-scrapen niet genoeg is: de opkomst van anti-bottechnologie
Dit is de realiteit: naarmate scraping populairder wordt, worden anti-botupgrades dat ook. . AI-gedreven detectie, dynamische drempels voor verzoeken en browser fingerprinting maken het voor zelfs geavanceerde Python-scripts steeds lastiger om onopgemerkt te blijven ().
Soms loop je, hoe slim je code ook is, gewoon vast. Dan is het tijd om een andere aanpak te overwegen.
Thunderbit: een AI-webscraper als alternatief voor Python-scraping
Wanneer Python zijn grenzen bereikt, springt bij als een no-code, AI-gedreven webscraper die is gebouwd voor zakelijke gebruikers—niet alleen voor ontwikkelaars. In plaats van te worstelen met proxies, headers en CAPTCHAs, leest Thunderbit’s AI-agent de website, stelt de beste velden voor om uit te lezen en regelt alles van navigatie naar subpagina’s tot data-export.
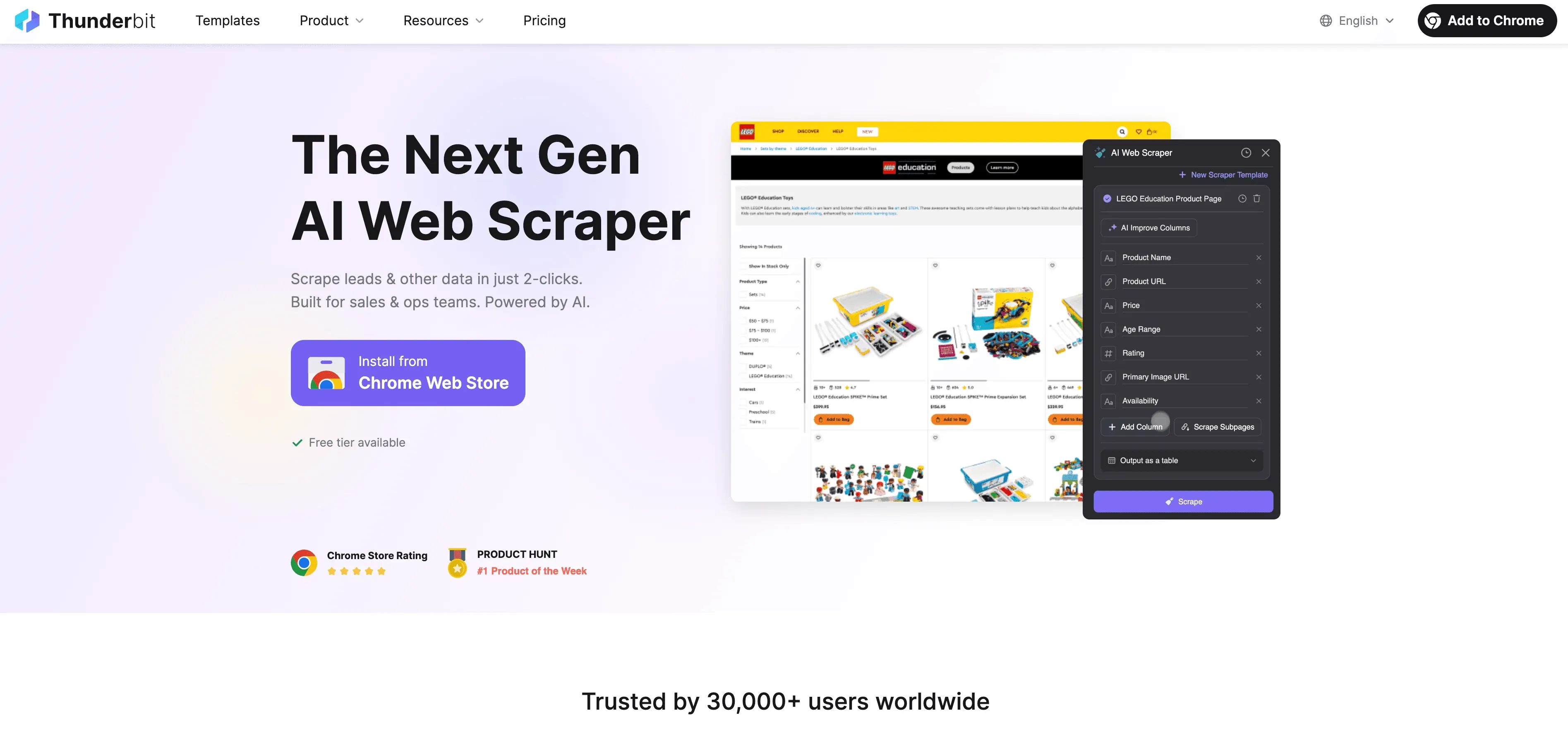
Wat maakt Thunderbit anders?
- AI-veldvoorstellen: klik op “AI-velden voorstellen” en Thunderbit scant de pagina, beveelt kolommen aan en genereert zelfs instructies voor extractie.
- Scrapen van subpagina’s: Thunderbit kan elke subpagina bezoeken (zoals productdetails of LinkedIn-profielen) en je tabel automatisch verrijken.
- Cloud- of browserscraping: kies de snelste optie—cloud voor openbare sites, browser voor pagina’s achter een login.
- Gepland scrapen: stel het in en vergeet het—Thunderbit kan op schema scrapen, zodat je data altijd actueel blijft.
- Directe sjablonen: voor populaire sites (Amazon, Zillow, Shopify, enz.) biedt Thunderbit sjablonen met één klik—geen setup nodig.
- Gratis data-export: exporteer naar Excel, Google Sheets, Airtable of Notion—zonder extra kosten.
Thunderbit wordt vertrouwd door meer dan , en je hoeft geen enkele regel code te schrijven.
Hoe Thunderbit gebruikers helpt blokkades te vermijden en data-extractie te automatiseren
Thunderbit’s AI bootst niet alleen menselijk gedrag na—het past zich in realtime aan elke site aan, waardoor de kans op blokkades afneemt. Zo werkt het:
- AI past zich aan lay-outwijzigingen aan: geen kapotte scripts meer wanneer een site het ontwerp aanpast.
- Subpagina- en pagineringafhandeling: Thunderbit volgt automatisch links en pagina-overzichten, net als een echte gebruiker.
- Cloud-scraping op schaal: scrape tot 50 pagina’s tegelijk, razendsnel.
- Geen code, geen onderhoud: besteed je tijd aan analyse in plaats van aan debuggen.
Lees voor meer verdieping .
Python-scraping vs. Thunderbit vergelijken: welke kies je?
Zet ze eens naast elkaar:
| Functie | Python-scraping | Thunderbit |
|---|---|---|
| Insteltijd | Gemiddeld–hoog (scripts, proxies, enz.) | Laag (2 klikken, de rest doet AI) |
| Technische kennis | Coderen vereist | Geen code nodig |
| Betrouwbaarheid | Wisselend (makkelijk kapot te maken) | Hoog (AI past zich aan wijzigingen aan) |
| Kans op blokkades | Gemiddeld–hoog | Laag (AI bootst gebruiker na, past zich aan) |
| Schaalbaarheid | Aangepaste code/cloud-setup nodig | Ingebouwde cloud-/batchscraping |
| Onderhoud | Regelmatig (sitewijzigingen, blokkades) | Minimaal (AI past zich automatisch aan) |
| Exportopties | Handmatig (CSV, database) | Direct naar Sheets, Notion, Airtable, CSV |
| Kosten | Gratis (maar tijdsintensief) | Gratis versie, betaalde plannen voor grotere schaal |
Wanneer gebruik je Python:
- Je wilt volledige controle, logica op maat of integratie met andere Python-workflows.
- Je scrapt sites met weinig anti-botverdediging.
Wanneer gebruik je Thunderbit:
- Je wilt snelheid, betrouwbaarheid en geen setup.
- Je scrapt complexe of vaak veranderende sites.
- Je wilt niet bezig zijn met proxies, CAPTCHA’s of code.
Stapsgewijze handleiding: webscraping zonder geblokkeerd te worden in Python instellen
Laten we een praktisch voorbeeld doorlopen: productdata scrapen van een voorbeeldsite, terwijl we anti-blokkeerbest practices toepassen.
1. Installeer de benodigde bibliotheken
1pip install requests beautifulsoup4 fake-useragent2. Bereid je script voor
1import requests
2from bs4 import BeautifulSoup
3from fake_useragent import UserAgent
4import time, random
5ua = UserAgent()
6urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Vervang door je eigen URL's
7for url in urls:
8 headers = {
9 "User-Agent": ua.random,
10 "Accept-Language": "en-US,en;q=0.9"
11 }
12 response = requests.get(url, headers=headers)
13 if response.status_code == 200:
14 soup = BeautifulSoup(response.text, "html.parser")
15 # Extraheer hier data
16 print(soup.title.text)
17 else:
18 print(f"Geblokkeerd of fout bij \{url\}: \{response.status_code\}")
19 time.sleep(random.uniform(2, 6)) # Willekeurige vertraging3. Voeg proxyrotatie toe (optioneel)
1proxies = [
2 "<http://proxy1.example.com:8000>",
3 "<http://proxy2.example.com:8000>",
4 # Meer proxies
5]
6for i, url in enumerate(urls):
7 proxy = {"http": proxies[i % len(proxies)]}
8 headers = {"User-Agent": ua.random}
9 response = requests.get(url, headers=headers, proxies=proxy)
10 # ...rest van de code4. Cookies en sessies afhandelen
1session = requests.Session()
2for url in urls:
3 response = session.get(url, headers=headers)
4 # ...rest van de code5. Tips voor probleemoplossing
- Zie je veel 403/429-fouten, vertraag je verzoeken dan of probeer nieuwe proxies.
- Loop je tegen CAPTCHA’s aan, overweeg dan Selenium of een CAPTCHA-oplosservice.
- Controleer altijd de
robots.txten de gebruiksvoorwaarden van de site.
Conclusie en belangrijkste inzichten
Webscraping in Python is krachtig—maar geblokkeerd worden blijft een constant risico nu anti-bottechnologie zich blijft ontwikkelen. De beste manier om blokkades te vermijden? Combineer technische best practices (roterende proxies, slimme headers, willekeurige vertragingen, sessie-afhandeling en headless browsers) met gezond respect voor de regels en ethiek van de site.
Maar soms zijn zelfs de beste Python-trucs niet genoeg. Dáár blinken AI-gedreven tools zoals in uit—ze bieden een no-code, blokkadebestendige en zakelijke manier om snel de data te extraheren die je nodig hebt.
Wil je zien hoe makkelijk scrapen kan zijn? en probeer het zelf — of bekijk onze voor meer scrapingtips en tutorials.
FAQ’s
1. Waarom blokkeren websites Python-webscrapers?
Websites blokkeren scrapers om hun data te beschermen, serveroverbelasting te voorkomen en te stoppen dat geautomatiseerde bots hun diensten misbruiken. Python-scripts zijn makkelijk te herkennen als ze standaardheaders gebruiken, cookies niet goed afhandelen of te snel te veel verzoeken versturen.
2. Wat zijn de meest effectieve manieren om blokkades te vermijden bij scrapen met Python?
Gebruik roterende proxies, stel realistische user-agents en headers in, randomiseer de timing van verzoeken, beheer cookies/sessies en simuleer menselijk gedrag met tools zoals Selenium of Playwright.
3. Hoe helpt Thunderbit blokkades te vermijden vergeleken met Python-scripts?
Thunderbit gebruikt AI om zich aan te passen aan lay-outs van sites, menselijk surfgedrag na te bootsen en subpagina’s en paginering automatisch af te handelen. Daardoor is de kans op blokkades kleiner, omdat het zich in realtime aanpast—zonder code of proxies.
4. Wanneer gebruik ik Python-scraping en wanneer een AI-tool zoals Thunderbit?
Gebruik Python als je logica op maat nodig hebt, wilt integreren met andere Python-code of eenvoudige sites scrape’t. Gebruik Thunderbit voor snel, betrouwbaar en schaalbaar scrapen—vooral wanneer sites complex zijn, vaak wijzigen of scripts agressief blokkeren.
5. Is webscraping legaal?
Webscraping is legaal voor openbaar beschikbare data, maar je moet wel de gebruiksvoorwaarden, privacybeleid en relevante wetgeving van elke site respecteren. Scrape nooit gevoelige of privédata en doe scraping altijd ethisch en verantwoord.
Klaar om slimmer te scrapen in plaats van harder? Probeer Thunderbit en laat de blokkades achter je.
Meer weten:
- Google Nieuws scrapen met Python: een stapsgewijze handleiding
- Bouw een Best Buy-prijstracker met Python
- 14 manieren om webscraping te doen zonder geblokkeerd te worden
- 10 beste tips om niet geblokkeerd te worden bij webscraping