

Het web is allang niet meer wat het vroeger was. Tegenwoordig draait bijna elke site die je bezoekt op JavaScript en wordt content dynamisch geladen—denk aan oneindig scrollen, pop-ups en dashboards die hun geheimen pas prijsgeven na een of twee klikken. Sterker nog: maar liefst 98,7% van alle websites gebruikt nu JavaScript. Daardoor missen de ouderwetse scrapingtools die alleen statische HTML lezen een enorme hoeveelheid waardevolle data. Heb je ooit geprobeerd productprijzen te scrapen van een moderne e-commercesite of woningaanbod uit een interactieve kaart te halen, dan ken je de frustratie: de data die je zoekt staat simpelweg niet in de broncode.
Daar komt scrapen met Selenium om de hoek kijken. Als iemand die jarenlang automatiseringstools heeft gebouwd (en ja, ook meer dan mijn eerlijke aandeel websites heeft gescrapet), kan ik je vertellen: Selenium beheersen is een superkracht voor iedereen die actuele, dynamische data nodig heeft. In deze praktische Selenium-webscrapingtutorial neem ik je stap voor stap mee—van installatie tot automatisering—en laat ik je zien hoe je Selenium combineert met Thunderbit voor gestructureerde data die direct klaar is om te exporteren. Of je nu businessanalist, salesprofessional of gewoon een nieuwsgierige Python-gebruiker bent, je gaat weg met bruikbare skills en waarschijnlijk ook een paar lachmomenten (want laten we eerlijk zijn: XPath-selectors debuggen is karaktervormend).
Probeer Thunderbit AI-webscraper
Wat is Selenium en waarom gebruiken voor webscraping?
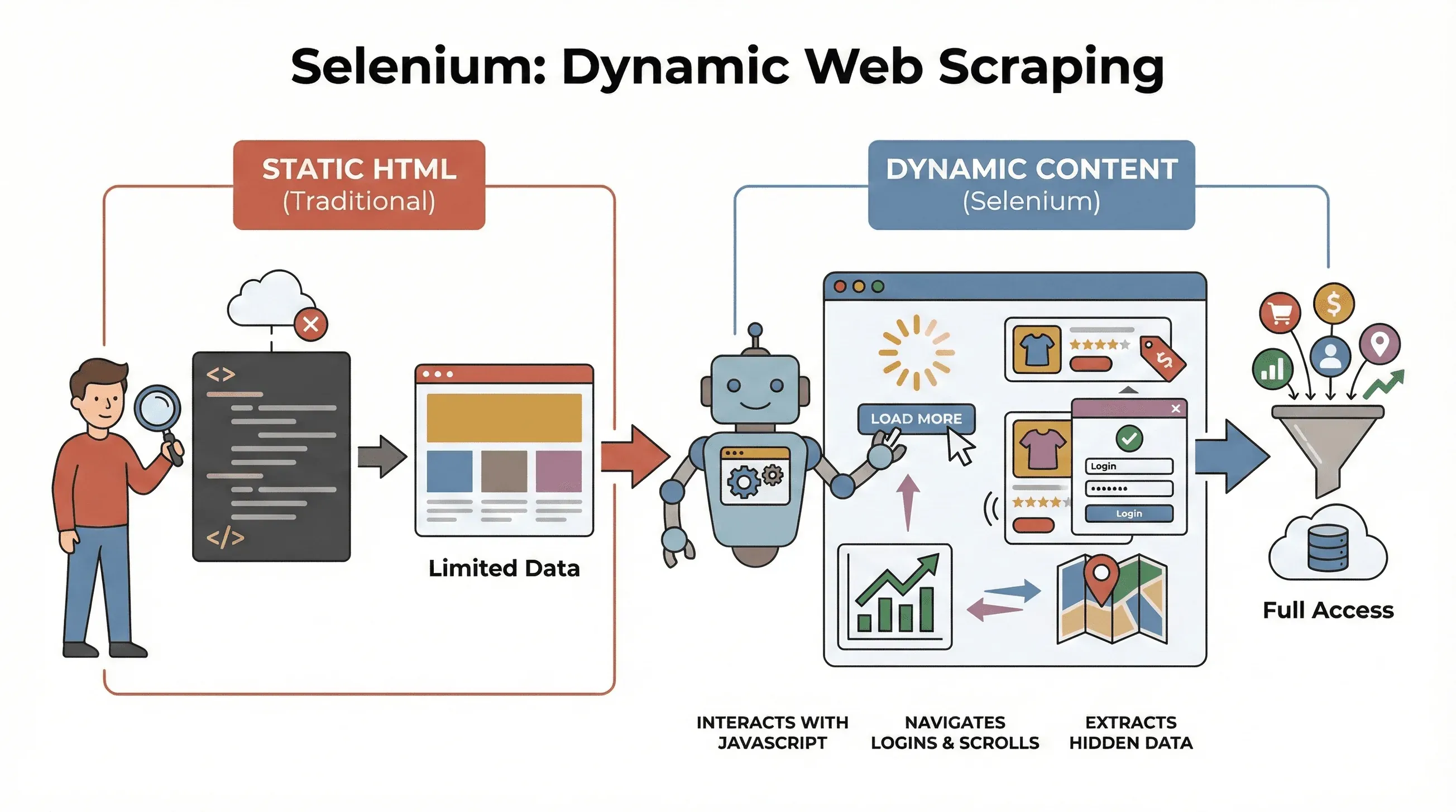 Laten we bij de basis beginnen. Selenium is een open-source framework waarmee je een echte webbrowser—zoals Chrome of Firefox—met code kunt aansturen. Zie het als een robot die pagina’s kan openen, op knoppen kan klikken, formulieren kan invullen, kan scrollen en zelfs JavaScript kan uitvoeren, net als een menselijke gebruiker. Dat is belangrijk, omdat de meeste moderne websites niet alle data meteen tonen. In plaats daarvan laden ze content dynamisch, vaak pas nadat je met de pagina hebt gewerkt.
Laten we bij de basis beginnen. Selenium is een open-source framework waarmee je een echte webbrowser—zoals Chrome of Firefox—met code kunt aansturen. Zie het als een robot die pagina’s kan openen, op knoppen kan klikken, formulieren kan invullen, kan scrollen en zelfs JavaScript kan uitvoeren, net als een menselijke gebruiker. Dat is belangrijk, omdat de meeste moderne websites niet alle data meteen tonen. In plaats daarvan laden ze content dynamisch, vaak pas nadat je met de pagina hebt gewerkt.
Wat is data scrapen en hoe doe je het in 2026 Get Started Free
Waarom is dit belangrijk voor scraping? Traditionele tools zoals BeautifulSoup of Scrapy zijn prima voor statische HTML, maar kunnen niets “zien” dat na het laden van de pagina via JavaScript verschijnt. Selenium daarentegen kan in realtime met de pagina communiceren, waardoor het perfect is voor:
- productlijsten scrapen die pas verschijnen nadat je op “Laad meer” klikt
- prijzen of reviews ophalen die dynamisch worden bijgewerkt
- navigeren door loginformulieren, pop-ups of oneindig scrollen
- data extraheren uit dashboards, kaarten of andere interactieve elementen
Kortom: Selenium is je standaardtool wanneer je data wilt scrapen die pas verschijnt nadat de pagina volledig geladen is—of na een actie van de gebruiker.
Belangrijke stappen voor Python Selenium-webscraping
Scrapen met Selenium komt neer op drie essentiële stappen:
| Stap | Wat je doet | Waarom het telt |
|---|---|---|
| 1. Omgeving instellen | Selenium, WebDriver en Python-bibliotheken installeren | Je tools klaarzetten en installatiedrama voorkomen |
| 2. Elementen lokaliseren | De data vinden met IDs, classes, XPath, enz. | De juiste info targeten, zelfs als JavaScript die verbergt |
| 3. Data extraheren en opslaan | Tekst, links of tabellen ophalen en opslaan naar CSV/Excel | Ruwe webdata omzetten in iets bruikbaars |
Laten we elke stap bekijken met praktische voorbeelden en code die je kunt kopiëren, aanpassen en trots aan je vrienden kunt laten zien.
Stap 1: Je Python Selenium-omgeving instellen
Eerst het belangrijkste: je moet Selenium en een browserdriver installeren (zoals ChromeDriver voor Chrome). Goed nieuws? Het is makkelijker dan ooit.
Selenium installeren
Open je terminal en voer uit:
pip install selenium
Een WebDriver ophalen
- Chrome: Download ChromeDriver (zorg dat hij overeenkomt met je Chrome-versie).
- Firefox: Download GeckoDriver.
Pro-tip: Met Selenium 4.6+ kun je Selenium Manager gebruiken om drivers automatisch te downloaden, dus je hoeft misschien niet eens meer te rommelen met PATH-variabelen (documentatie).
Je eerste Selenium-script
Hier is een snelle “hello world” voor Selenium:
from selenium import webdriver
driver = webdriver.Chrome() # Of webdriver.Firefox()
driver.get("https://example.com")
print(driver.title)
driver.quit()
Tips voor probleemoplossing:
- Krijg je een fout “driver not found”, controleer dan je PATH of gebruik Selenium Manager.
- Zorg dat je browser- en driverversies overeenkomen.
- Werk je op een headless server (zonder GUI), kijk dan hieronder naar de tips voor headless mode.
Stap 2: Webelementen lokaliseren voor data-extractie
Nu komt het leuke deel: Selenium vertellen welke data je wilt. Websites bestaan uit elementen—divs, spans, tabellen, noem maar op—en Selenium geeft je meerdere manieren om die te vinden.
Veelgebruikte locatorstrategieën
By.ID: een element vinden met een unieke IDBy.CLASS_NAME: elementen vinden op CSS-classBy.XPATH: XPath-expressies gebruiken (zeer flexibel, maar kan kwetsbaar zijn)By.CSS_SELECTOR: CSS-selectors gebruiken (handig voor complexe queries)
Zo kun je ze gebruiken:
from selenium.webdriver.common.by import By
# Zoeken op ID
price = driver.find_element(By.ID, "price").text
# Zoeken op XPath
title = driver.find_element(By.XPATH, "//h1").text
# Alle productafbeeldingen vinden met een CSS-selector
images = driver.find_elements(By.CSS_SELECTOR, ".product img")
for img in images:
print(img.get_attribute("src"))
Pro-tip: Gebruik altijd de simpelste en meest stabiele locator (ID > class > CSS > XPath). En als je een pagina scrapet die data pas na een vertraging laadt, gebruik dan expliciete waits:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
price_elem = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".price")))
Zo voorkom je dat je script crasht als de data een seconde nodig heeft om te verschijnen.
Stap 3: Data extraheren en opslaan
Zodra je je elementen hebt gevonden, is het tijd om de data op te halen en ergens nuttigs op te slaan.
Tekst, links en tabellen extraheren
Stel dat je een producttabel scrapet:
data = []
rows = driver.find_elements(By.XPATH, "//table/tbody/tr")
for row in rows:
cells = row.find_elements(By.TAG_NAME, "td")
data.append([cell.text for cell in cells])
Opslaan naar CSV met Pandas
import pandas as pd
df = pd.DataFrame(data, columns=["Naam", "Prijs", "Voorraad"])
df.to_csv("producten.csv", index=False)
Je kunt ook opslaan naar Excel (df.to_excel("producten.xlsx")) of zelfs naar Google Sheets pushen via hun API.
Volledig voorbeeld: producttitels en prijzen scrapen
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
driver = webdriver.Chrome()
driver.get("https://example.com/products")
data = []
products = driver.find_elements(By.CLASS_NAME, "product-card")
for p in products:
title = p.find_element(By.CLASS_NAME, "title").text
price = p.find_element(By.CLASS_NAME, "price").text
data.append([title, price])
driver.quit()
df = pd.DataFrame(data, columns=["Titel", "Prijs"])
df.to_csv("producten.csv", index=False)
Selenium versus BeautifulSoup en Scrapy: wat maakt Selenium uniek?
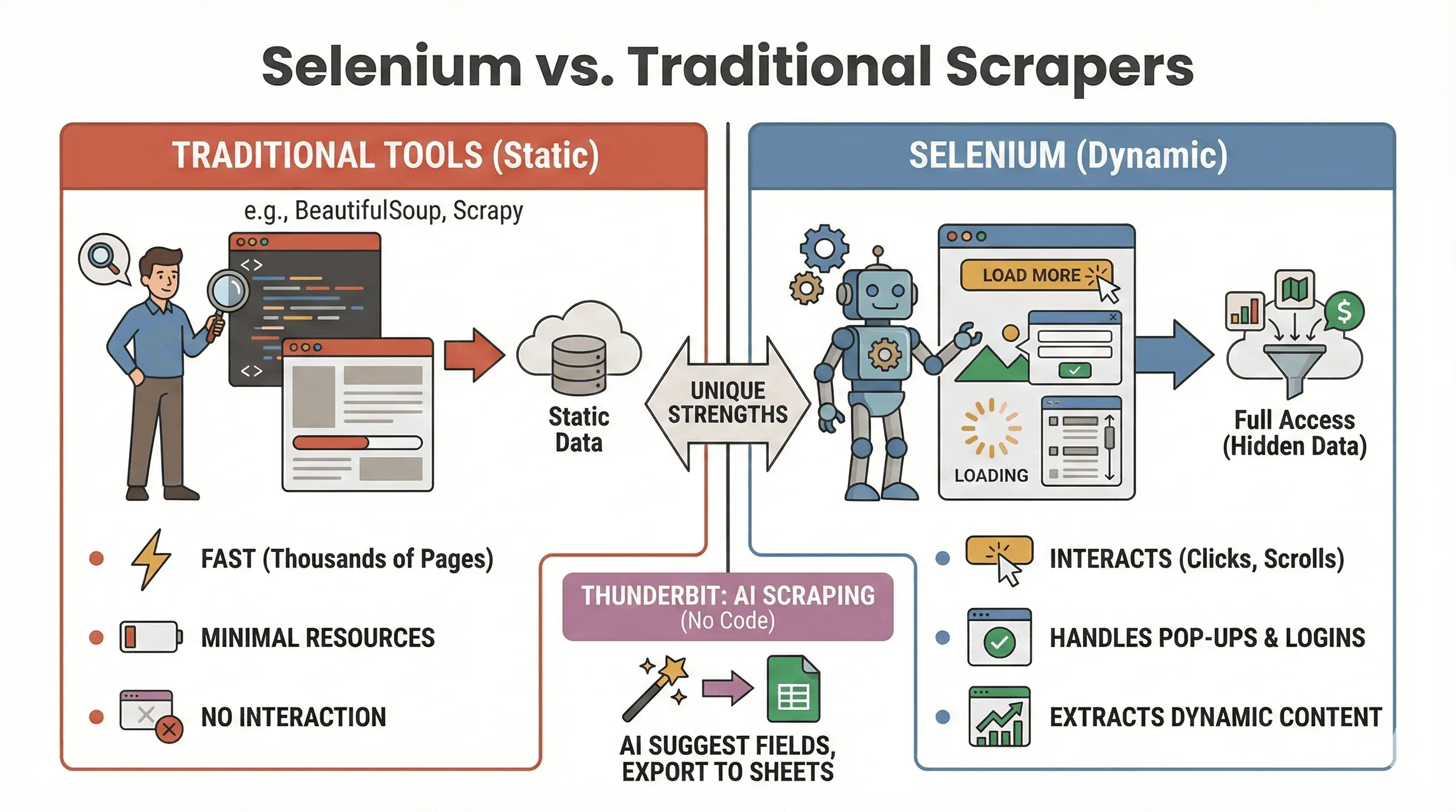 Laten we de discussie beslechten: wanneer gebruik je Selenium, en wanneer is iets als BeautifulSoup of Scrapy een betere keuze? Hier is een snelle vergelijking:
Laten we de discussie beslechten: wanneer gebruik je Selenium, en wanneer is iets als BeautifulSoup of Scrapy een betere keuze? Hier is een snelle vergelijking:
| Tool | Het beste voor | JavaScript ondersteunen? | Snelheid & resourcegebruik |
|---|---|---|---|
| Selenium | Dynamische/ interactieve sites | Ja | Langzamer, gebruikt meer geheugen |
| BeautifulSoup | Eenvoudige statische HTML-scraping | Nee | Heel snel, lichtgewicht |
| Scrapy | Crawlen van grote aantallen statische pagina’s | Beperkt* | Super snel, async, weinig RAM |
| Thunderbit | No-code, business scraping | Ja (AI) | Snel voor kleine/middelgrote jobs |
*Scrapy kan met plugins wat dynamische content aan, maar dat is niet waar het in uitblinkt (ScrapingBee).
Wanneer Selenium gebruiken:
- De data verschijnt pas na klikken, scrollen of inloggen
- Je moet interactie hebben met pop-ups, oneindig scrollen of dynamische dashboards
- Statische scrapers komen simpelweg tekort
Wanneer BeautifulSoup/Scrapy gebruiken:
- De data staat al in de initiële HTML
- Je wilt duizenden pagina’s snel scrapen
- Je wilt zo min mogelijk resources gebruiken
En als je helemaal zonder code wilt werken, laat Thunderbit je dynamische sites scrapen met AI—klik gewoon op “AI-velden voorstellen” en exporteer naar Sheets, Notion of Airtable. (Daarover straks meer.)
Hoe je elke website met AI kunt scrapen Get Started Free
Webscrapingtaken automatiseren met Selenium en Python
Laten we eerlijk zijn: niemand wordt graag om 2 uur ’s nachts wakker om een scraping script te draaien. Het goede nieuws is dat je je Selenium-taken kunt automatiseren met de planningshulpmiddelen van Python of met de planner van je besturingssysteem (zoals cron op Linux/Mac of Taakplanner op Windows).
De schedule-bibliotheek gebruiken
import schedule
import time
def job():
# Je scrapingcode hier
print("Aan het scrapen...")
schedule.every().day.at("09:00").do(job)
while True:
schedule.run_pending()
time.sleep(1)
Of met Cron (Linux/Mac)
Voeg dit toe aan je crontab om elk uur uit te voeren:
0 * * * * python /path/to/your_script.py
Tips voor automatisering:
- Draai Selenium in headless mode (zie hieronder) om GUI-pop-ups te vermijden.
- Log fouten en stuur jezelf meldingen als er iets misgaat.
- Sluit de browser altijd af met
driver.quit()om resources vrij te maken.
Efficiënter werken: tips voor snellere en betrouwbaardere Selenium-scraping
Selenium is krachtig, maar kan traag en resource-intensief zijn als je niet oplet. Zo versnel je het en voorkom je veelvoorkomende ellende:
1. Draai in headless mode
Je hoeft niet te kijken hoe Chrome honderd keer opent en sluit. Headless mode draait de browser op de achtergrond:
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.headless = True
driver = webdriver.Chrome(options=opts)
2. Blokkeer afbeeldingen en andere onnodige content
Waarom afbeeldingen laden als je alleen tekst scrapt? Blokkeer ze om pagina’s sneller te laden:
prefs = {"profile.managed_default_content_settings.images": 2}
opts.add_experimental_option("prefs", prefs)
3. Gebruik efficiënte locators
- Geef de voorkeur aan IDs of simpele CSS-selectors boven ingewikkelde XPath-paden.
- Vermijd
time.sleep()—gebruik in plaats daarvan expliciete waits (WebDriverWait).
4. Willekeurige vertragingen
Voeg willekeurige pauzes toe om menselijk surfgedrag na te bootsen en blokkades te vermijden:
import random, time
time.sleep(random.uniform(1, 3))
5. Wissel user agents en IP’s af (indien nodig)
Als je veel scrapt, roteer dan je user-agentstring en overweeg proxies te gebruiken om eenvoudige anti-botmaatregelen te omzeilen.
6. Sessies en fouten beheren
- Gebruik try/except-blokken om ontbrekende elementen netjes op te vangen.
- Log fouten en maak screenshots voor debugging.
Voor meer optimalisatietips kun je de gids van BrowserStack bekijken.
Geavanceerd: Selenium combineren met Thunderbit voor gestructureerde data-export
Hier wordt het echt interessant—vooral als je tijd wilt besparen op opschonen en exporteren van data.
Nadat je ruwe data met Selenium hebt gescrapet, kun je Thunderbit gebruiken om:
- Velden automatisch te detecteren: Thunderbit’s AI kan je gescrapete pagina’s of CSV’s lezen en kolomnamen voorstellen (“AI-velden voorstellen”).
- Subpagina’s scrapen: Als je een lijst met URL’s hebt (zoals productpagina’s), kan Thunderbit elke pagina bezoeken en je tabel verrijken met meer details—zonder extra code.
- Data verrijken: Vertaal, categoriseer of analyseer data direct.
- Overal exporteren: Met één klik exporteren naar Google Sheets, Airtable, Notion, CSV of Excel.
Workflowvoorbeeld:
- Gebruik Selenium om een lijst met product-URL’s en titels te scrapen.
- Exporteer de data naar CSV.
- Open Thunderbit, importeer je CSV en laat de AI velden voorstellen.
- Gebruik Thunderbit’s subpagina-scraping om meer details (zoals afbeeldingen of specificaties) van elke product-URL op te halen.
- Exporteer je definitieve, gestructureerde dataset naar Sheets of Notion.
Deze combinatie bespaart je uren handmatig opschonen en laat je focussen op analyse in plaats van het worstelen met rommelige data. Voor meer over deze workflow kun je Thunderbit’s Selenium-gids bekijken.
Exporteer Selenium-data met Thunderbit AI
Best practices en probleemoplossing voor Selenium-webscraping
Webscraping is een beetje als vissen: soms vang je een grote, soms raak je verstrikt in het wier. Zo houd je je scripts betrouwbaar én ethisch:
Best practices
- Respecteer robots.txt en de gebruiksvoorwaarden van de site: Controleer altijd of scrapen is toegestaan.
- Beperk je verzoeken: Overbelast servers niet—voeg vertragingen toe en let op HTTP 429-fouten.
- Gebruik API’s wanneer beschikbaar: Als de data publiek via een API beschikbaar is, gebruik die dan—veiliger en betrouwbaarder.
- Scrape alleen openbare data: Vermijd persoonlijke of gevoelige info en houd rekening met privacywetgeving.
- Hanteer pop-ups en CAPTCHA’s: Gebruik Selenium om pop-ups te sluiten, maar wees voorzichtig met CAPTCHA’s—die zijn lastig te automatiseren.
- Wissel user agents en vertragingen af: Helpt detectie en blokkering te voorkomen.
Veelvoorkomende fouten en oplossingen
| Fout | Wat het betekent | Hoe je het oplost |
|---|---|---|
NoSuchElementException | Kan het element niet vinden | Controleer je locator nog eens; gebruik waits |
| Time-outfouten | Pagina of element duurde te lang | Verhoog de wachttijd; controleer de netwerksnelheid |
| Driver/browser-mismatch | Selenium kan de browser niet starten | Werk je driver- en browserversies bij |
| Sessies crashen | Browser sloot onverwacht | Gebruik headless mode; beheer resources |
Voor meer tips voor probleemoplossing, zie Thunderbit’s Selenium-tutorial.
Conclusie en belangrijkste inzichten
Dynamisch webscrapen is niet meer alleen voor hardcore developers. Met Python Selenium kun je elke browser automatiseren, werken met de lastigste JavaScript-zware sites en de data ophalen die je bedrijf nodig heeft—of dat nu voor sales, onderzoek of simpelweg uit nieuwsgierigheid is. Onthoud:
- Selenium is de tool bij uitstek voor dynamische, interactieve sites.
- De drie belangrijkste stappen: instellen, lokaliseren, extraheren en opslaan.
- Automatiseer je scripts voor regelmatige dataverversing.
- Optimaliseer voor snelheid en betrouwbaarheid met headless mode, slimme waits en efficiënte locators.
- Combineer Selenium met Thunderbit voor eenvoudige datastructurering en export—vooral als je spreadsheethoofdpijn wilt overslaan.
Klaar om het zelf te proberen? Begin met de codevoorbeelden hierboven, en als je klaar bent om je scraping naar een hoger niveau te tillen, geef Thunderbit dan een kans voor directe, AI-gestuurde data-opruiming en export. En als je meer wilt, bekijk dan de Thunderbit Blog voor verdieping, tutorials en de nieuwste ontwikkelingen op het gebied van webautomatisering.
Veel scrapeplezier—en moge je selectors altijd vinden wat je zoekt.
Probeer Thunderbit AI-webscraper gratis Get Started Free
FAQ’s
1. Waarom zou ik Selenium gebruiken voor webscraping in plaats van BeautifulSoup of Scrapy?
Selenium is ideaal voor het scrapen van dynamische websites waar content pas laadt na gebruikersacties of JavaScript-uitvoering. BeautifulSoup en Scrapy zijn sneller voor statische HTML, maar kunnen niet met dynamische elementen omgaan of klikken en scrollen simuleren.
2. Hoe maak ik mijn Selenium-scraper sneller?
Gebruik headless mode, blokkeer afbeeldingen en onnodige resources, gebruik efficiënte locators en voeg willekeurige vertragingen toe om menselijk surfgedrag na te bootsen. Zie de gids van BrowserStack voor meer tips.
3. Kan ik Selenium-scrapingtaken automatisch laten draaien volgens een schema?
Ja! Gebruik de schedule-bibliotheek van Python of de scheduler van je besturingssysteem (cron of Taakplanner) om scripts op vaste intervallen uit te voeren. Automatisering helpt je data actueel te houden.
4. Wat is de beste manier om met Selenium gescrapete data te exporteren?
Gebruik Pandas om data op te slaan naar CSV of Excel. Voor geavanceerdere exports (Google Sheets, Notion, Airtable) importeer je je data in Thunderbit en gebruik je de exportfuncties met één klik.
5. Hoe ga ik om met pop-ups en CAPTCHA’s in Selenium?
Je kunt pop-ups sluiten door hun sluitknoppen te vinden en erop te klikken. CAPTCHA’s zijn veel lastiger—als je die tegenkomt, overweeg dan een handmatige workaround of een captchadienst voor oplossen, en respecteer altijd de gebruiksvoorwaarden van de site.
Wil je meer scrapingtutorials, AI-automatiseringstips of het laatste nieuws over tools voor bedrijfsdata? Abonneer je op de Thunderbit Blog of bekijk ons YouTube-kanaal voor praktische demo’s.
Meer ontdekken




