

Laat ik je even meenemen naar nog niet eens zo lang geleden: ik zit aan mijn bureau, koffie in de hand, en staar naar een spreadsheet die leger is dan mijn koelkast op een zondagavond. Het salesteam wil concurrentieprijsgegevens, marketing wil verse leads en operations wil productvermeldingen van een dozijn sites — en dat liefst gisteren. Ik weet dat die data er is, maar hoe krijg je die binnen? Dáár zit de echte uitdaging. Als je ooit het gevoel had dat je digitaal whack-a-mole zat te spelen met kopiëren en plakken, ben je zeker niet de enige.
Snel vooruit naar vandaag: het speelveld is totaal veranderd. Webscraping is inmiddels verschoven van een nerdy side project naar een vast onderdeel van de bedrijfsstrategie. JavaScript en Node.js staan daarbij centraal en drijven alles aan, van eenmalige scripts tot complete datapijplijnen. Maar er is wel één kanttekening: hoewel de tools krachtiger zijn dan ooit, voelt de leercurve nog steeds alsof je op slippers de Everest probeert te beklimmen. Dus of je nu een zakelijke gebruiker bent, een datafanaat of gewoon klaar bent met handmatige gegevensinvoer, deze gids is voor jou. Ik loop het ecosysteem langs, de belangrijkste libraries, de pijnpunten en de redenen waarom het soms de slimste zet is om AI het zware werk te laten doen.
Waarom webscraping met JavaScript en Node.js belangrijk is voor bedrijven
Laten we beginnen met de vraag waarom. In 2026 is webdata niet zomaar handig — het is bedrijfskritisch. Volgens recent onderzoek schrijft 73% van de bedrijven snellere en nauwkeurigere besluitvorming toe aan openbare webdata, en ongeveer 42% van de enterprise-databudgetten gaat inmiddels naar het verzamelen van webdata. De markt voor alternatieve data — waaronder webscraping valt — is al goed voor $4,9 miljard en groeit stevig door.
Wat drijft die goudkoorts? Dit zijn enkele van de meest voorkomende zakelijke toepassingen:
- Concurrerende prijzen & e-commerce: retailers scrapen sites van concurrenten voor prijzen en voorraad, en zien soms hun omzet met 4% of meer stijgen.
- Leadgeneratie & sales intelligence: salesteams automatiseren het verzamelen van e-mails, telefoonnummers en bedrijfsgegevens uit gidsen en sociale platformen.
- Marktonderzoek & contentaggregatie: analisten halen nieuws, reviews en sentimentdata op om trends te signaleren en voorspellingen te doen.
- Advertising & adtech: adtechbedrijven volgen advertentieplaatsingen en campagnes van concurrenten in realtime.
- Vastgoed & reizen: bureaus scrapen woningaanbod, prijzen en reviews voor waarderingsmodellen en marktanalyses.
- Content- & data-aggregators: platforms bundelen data uit meerdere bronnen om vergelijkingstools en dashboards aan te sturen.
JavaScript en Node.js zijn inmiddels de standaardstack voor dit soort werk, zeker nu steeds meer websites leunen op dynamische, met JavaScript gerenderde content. Node.js blinkt uit in asynchrone bewerkingen, waardoor het perfect past bij scraping op schaal. En met een bloeiend ecosysteem aan libraries kun je alles bouwen: van snelle scripts tot robuuste scrapers van productieniveau.
Wat is data scraping en hoe doe je het in 2025 Get Started Free
De kernworkflow: hoe webscraping met JavaScript en Node.js werkt
Laten we de typische webscraping-workflow even uit elkaar halen. Of je nu een simpele blog scrapt of een e-commercesite vol JavaScript, de stappen zijn meestal hetzelfde:
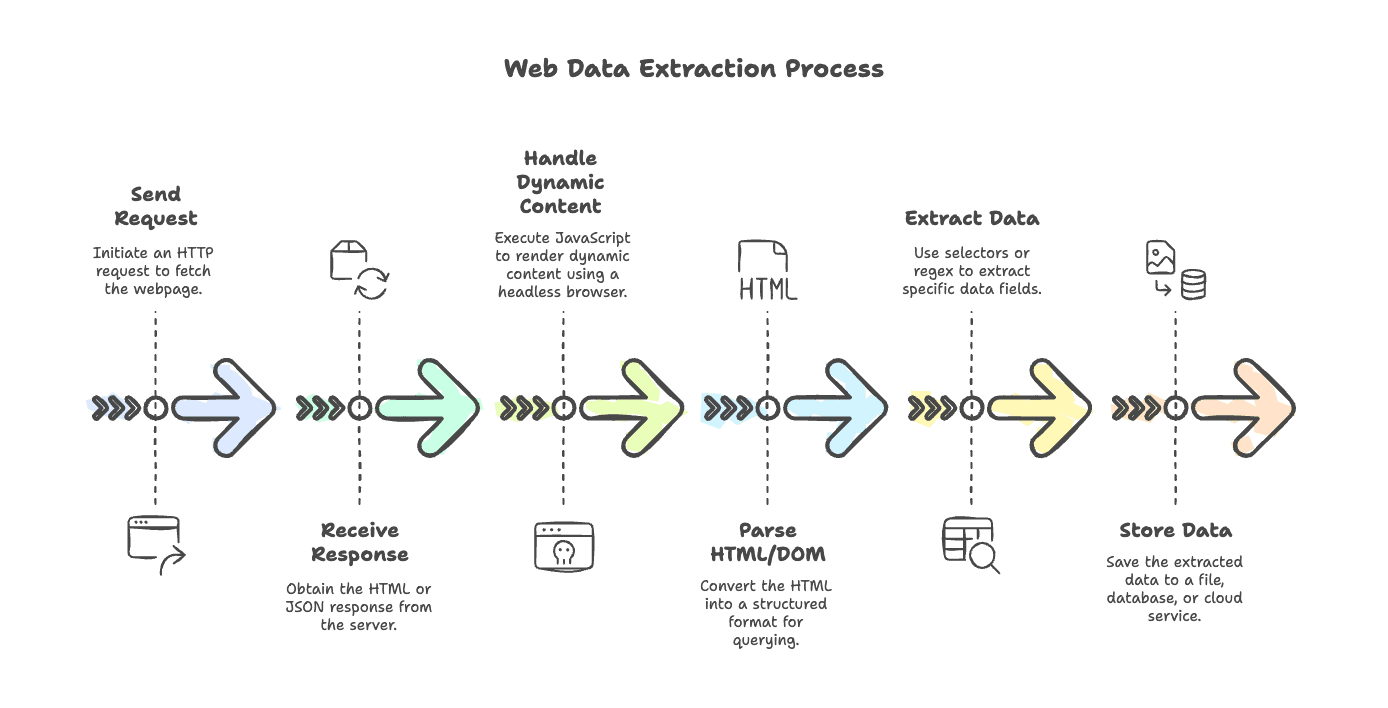
- Verzoek verzenden: gebruik een HTTP-client om de pagina op te halen (denk aan
axios,node-fetchofgot). - Respons ontvangen: je krijgt HTML terug van de server, of soms JSON.
- Dynamische content verwerken: als de pagina door JavaScript wordt gerenderd, gebruik dan een headless browser (zoals Puppeteer of Playwright) om scripts uit te voeren en de uiteindelijke content op te halen.
- HTML/DOM parsen: gebruik een parser (
cheerio,jsdom) om de HTML om te zetten in een structuur die je kunt bevragen. - Data extraheren: gebruik selectors of regex om de velden eruit te halen die je nodig hebt.
- Data opslaan: bewaar de resultaten in een bestand, database of cloudservice.
Elke stap heeft zijn eigen tools en best practices, en die lopen we hierna verder langs.
Essentiële HTTP-requestlibraries voor webscraping in JavaScript
De eerste stap in elke scraper is het doen van HTTP-verzoeken. Node.js biedt je een hele reeks opties — sommige klassiek, andere modern. Hieronder een overzicht van de populairste libraries:
1. Axios
Een op promises gebaseerde HTTP-client voor Node en browsers. Voor de meeste scrapingbehoeften is dit het Zwitsers zakmes.
const axios = require('axios');
const response = await axios.get('https://example.com/api/items', { timeout: 5000 });
console.log(response.data);
Voordelen: rijk aan functies, ondersteunt async/await, automatische JSON-parsing, interceptors en proxyondersteuning.
Nadelen: iets zwaarder, en de manier waarop het data afhandelt voelt soms bijna “magisch”.
2. node-fetch
Implementeert de browser-fetch-API in Node.js. Minimalistisch en modern.
import fetch from 'node-fetch';
const res = await fetch('https://api.github.com/users/github');
const data = await res.json();
console.log(data);
Voordelen: lichtgewicht, vertrouwde API voor mensen die van frontend-JS komen.
Nadelen: weinig extra functies, foutafhandeling moet je handmatig doen, en proxy-instelling kost wat meer regels.
3. SuperAgent
Een ervaren HTTP-library met een chainable API.
const superagent = require('superagent');
const res = await superagent.get('https://example.com/data');
console.log(res.body);
Voordelen: volwassen, ondersteunt formulieren, bestandsuploads en plugins.
Nadelen: de API voelt wat ouderwets aan, en de dependency is groter.
4. Unirest
Een eenvoudige, taalneutrale HTTP-client.
const unirest = require('unirest');
unirest.get('https://httpbin.org/get?query=web')
.end(response => {
console.log(response.body);
});
Voordelen: makkelijke syntaxis, ideaal voor snelle scripts.
Nadelen: minder functies, minder actieve community.
5. Got
Een robuuste, snelle HTTP-client voor Node.js met geavanceerde functies.
import got from 'got';
const html = await got('https://example.com/page').text();
console.log(html.length);
Voordelen: snel, ondersteunt HTTP/2, retries en streams.
Nadelen: alleen voor Node, en de API kan voor nieuwkomers wat compact overkomen.
6. De ingebouwde http/https van Node
Je kunt natuurlijk ook gewoon old school aan de slag:
const https = require('https');
https.get('https://example.com/data', (res) => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => {
console.log('Antwoordlengte:', data.length);
});
});
Voordelen: geen dependencies.
Nadelen: omslachtig, sterk op callbacks gericht en geen promises.
Bekijk hier een gedetailleerde functievergelijking en codevoorbeelden.
De juiste HTTP-client kiezen voor jouw project
Hoe kies je de juiste tool voor de klus? Hier let ik op:
- Gebruiksgemak: Axios en Got zijn ideaal voor async/await en duidelijke syntaxis.
- Prestaties: Got en node-fetch zijn licht en snel voor scraping met hoge gelijktijdigheid.
- Proxyondersteuning: Axios en Got maken het eenvoudig om proxies te roteren.
- Foutafhandeling: Axios gooit standaard fouten bij HTTP-errors; node-fetch vereist handmatige checks.
- Community: Axios en Got hebben actieve communities en veel voorbeelden.
Mijn snelle aanbevelingen:
- Snelle scripts of prototypes: node-fetch of Unirest.
- Scraping voor productie: Axios (voor de functies) of Got (voor de prestaties).
- Browserautomatisering: Puppeteer of Playwright handelen de requests intern af.
HTML-parsing en data-extractie: Cheerio, jsdom en meer
Zodra je de HTML hebt opgehaald, moet je die omzetten in iets waar je echt mee kunt werken. Daar komen parsers om de hoek kijken.
Cheerio
Zie Cheerio als jQuery voor de server. Snel, lichtgewicht en perfect voor statische HTML.
const cheerio = require('cheerio');
const $ = cheerio.load('<ul><li class="item">Item 1</li></ul>');
$('.item').each((i, el) => {
console.log($(el).text());
});
Voordelen: razendsnel, vertrouwde API, kan overweg met rommelige HTML.
Nadelen: voert geen JavaScript uit — ziet alleen wat al in de HTML staat.
Lees meer over de snelheid en toepassingen van Cheerio.
jsdom
jsdom simuleert een DOM-omgeving die in Node.js op een browser lijkt. Het kan eenvoudige scripts uitvoeren en voelt meer als een browser dan Cheerio.
const { JSDOM } = require('jsdom');
const dom = new JSDOM(`<p id="greet">Hello</p><script>document.querySelector('#greet').textContent += ", world!";</script>`);
console.log(dom.window.document.querySelector('#greet').textContent);
Voordelen: kan scripts uitvoeren, ondersteunt de volledige DOM-API.
Nadelen: trager en zwaarder dan Cheerio, en geen volwaardige browser.
Vergelijk Cheerio en jsdom in detail.
Wanneer je reguliere expressies of andere parse-methoden gebruikt
Regex bij webscraping is als hete saus — geweldig met mate, maar giet het niet overal overheen. Regex is handig voor:
- patronen uit tekst halen (e-mails, telefoonnummers, prijzen);
- gescrapete data opschonen of valideren;
- data halen uit grote blokken tekst of script-tags.
Voorbeeld: een getal uit tekst halen
const text = "Totaal aantal verkopen: 1.234 stuks";
const match = text.match(/([\d.]+)\s*stuks/);
if (match) {
const units = parseInt(match[1].replace(/\./g, ''));
console.log("Verkochte eenheden:", units);
}
Maar probeer geen volledige HTML met regex te parsen — gebruik daarvoor een DOM-parser. Meer regex-tips voor scraping.
Dynamische websites verwerken: Puppeteer, Playwright en headless browsers
Moderne websites zijn dol op JavaScript. Soms staat de data die je zoekt niet in de eerste HTML — die wordt pas door scripts gerenderd nadat de pagina is geladen. Daar komen headless browsers om de hoek kijken.
Puppeteer
Een Node.js-library van Google die Chrome/Chromium aanstuurt. Het is alsof je een robot hebt die voor jou door pagina’s klikt en scrollt.
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('h1', el => el.textContent);
console.log(title);
await browser.close();
Voordelen: volledige Chrome-rendering, eenvoudige API, uitstekend voor dynamische content.
Nadelen: alleen Chromium, en zwaarder qua resources.
Lees meer over de sterke punten van Puppeteer.
Playwright
Een nieuwere library van Microsoft. Playwright ondersteunt Chromium, Firefox en WebKit. Zie het als Puppeteer’s coolere, browseronafhankelijke neef.
const { chromium } = require('playwright');
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const content = await page.textContent('h1');
console.log(content);
await browser.close();
Voordelen: cross-browser, parallelle contexten, automatisch wachten op elementen.
Nadelen: leercurve iets steiler, grotere installatie.
Waarom Playwright terrein wint.
Nightmare
Een op Electron gebaseerde automationtool die jaren geleden populair was. De repository is verplaatst naar de GitHub-organisatie segment-boneyard — Segment’s opslagplek voor projecten die ze niet meer ondersteunen — en de laatste npm-release was in 2019. Ik zou dit in 2026 niet meer kiezen voor iets nieuws; erf je een script dat het nog gebruikt, dan prima, maar voor een nieuw project ga je beter meteen naar Playwright of Puppeteer.
Headless browseroplossingen vergelijken
| Aspect | Puppeteer (Chrome) | Playwright (meerdere browsers) | Nightmare (Electron) |
|---|---|---|---|
| Browserondersteuning | Chrome/Edge | Chrome, Firefox, WebKit | Chrome (oud) |
| Prestaties & schaal | Snel, maar zwaar | Snel, betere parallelisering | Langzamer, minder stabiel |
| Dynamische scraping | Uitstekend | Uitstekend + meer functies | Goed voor eenvoudige sites |
| Onderhoud | Goed onderhouden | Zeer actief | Gearchiveerd (segment-boneyard, laatste npm-publicatie 2019) |
| Het meest geschikt voor | Chrome-scraping | Complexe, cross-browser taken | Eenvoudige, legacy-werkzaamheden |
Mijn advies: gebruik Playwright voor nieuwe, complexe projecten. Puppeteer is nog steeds uitstekend voor taken die alleen Chrome nodig hebben. Nightmare is vooral voor nostalgie of oude scripts.
Ondersteunende tools: planning, omgeving, CLI en dataopslag
Een scraper uit de praktijk is meer dan alleen ophalen en parsen. Dit zijn een paar ondersteunende tools waar ik op vertrouw:
Planning: node-cron
Plan scrapers zodat ze automatisch draaien.
const cron = require('node-cron');
cron.schedule('0 9 * * MON', () => {
console.log('Scraping om 9:00 uur elke maandag');
});
Node-cron is perfect voor het automatiseren van repetitieve taken.
Omgevingsbeheer: dotenv
Houd secrets en configuratie buiten je code.
require('dotenv').config();
const apiKey = process.env.API_KEY;
CLI-tools: chalk, commander, inquirer
- chalk: kleur de console-uitvoer.
- commander: parse commandline-opties.
- inquirer: interactieve prompts voor gebruikersinvoer.
Dataopslag
- fs: schrijf naar bestanden (JSON, CSV).
- lowdb: lichtgewicht JSON-database.
- sqlite3: lokale SQL-database.
- mongodb: NoSQL-database voor grotere projecten.
Voorbeeld: data opslaan als JSON
const fs = require('fs');
fs.writeFileSync('output.json', JSON.stringify(data, null, 2));
De pijnpunten van traditioneel webscraping met JavaScript en Node.js
Laten we eerlijk zijn: traditioneel scrapen is niet alleen maar zonneschijn en regenbogen. Dit zijn de grootste frustraties die ik heb gezien — en gevoeld:

- Hoge leercurve: je moet DOM, selectors, async-logica en soms browsereigenaardigheden begrijpen.
- Veel onderhoud: websites veranderen, selectors breken en je bent constant code aan het repareren.
- Slechte schaalbaarheid: elke site heeft zijn eigen script nodig; niets is echt one-size-fits-all.
- Complexe datacleaning: gescrapete data is rommelig — opschonen, formatteren en dedupliceren is een klus op zich.
- Prestatiebeperkingen: browserautomatisering is traag en intensief voor resources bij grote taken.
- Blokkering en anti-botmaatregelen: sites blokkeren scrapers, gooien CAPTCHA’s op of verbergen data achter logins.
- Juridische en ethische grijze zones: je moet navigeren tussen terms of service, privacy en compliance.
Lees meer over deze pijnpunten en praktijkstatistieken.
Thunderbit versus traditioneel webscraping: een productiviteitsrevolutie
Laten we nu de olifant in de kamer benoemen: wat als je al die code, selectors en het onderhoud kon overslaan?
Daar komt Thunderbit in beeld. Als medeoprichter en CEO ben ik natuurlijk een beetje bevooroordeeld, maar hoor me even aan: Thunderbit is gebouwd voor zakelijke gebruikers die data willen, niet hoofdpijn.
Hoe Thunderbit zich verhoudt
| Aspect | Thunderbit (AI, no-code) | Traditioneel JS/Node-scraping |
|---|---|---|
| Instellen | In 2 klikken, geen code | Scripts schrijven, debuggen |
| Dynamische content | In de browser afgehandeld | Headless-browser-scripting |
| Onderhoud | AI past zich aan veranderingen aan | Handmatige code-updates |
| Data-extractie | AI Suggest Fields | Handmatige selectors |
| Subpagina-scraping | Ingebouwd, 1 klik | Per site loopen en coderen |
| Exporteren | Excel, Sheets, Notion | Handmatige integratie met bestand/db |
| Naverwerking | Samenvatten, taggen, formatteren | Extra code of tools |
| Wie kan het gebruiken | Iedereen met een browser | Alleen ontwikkelaars |
Thunderbit’s AI leest de pagina, doet veldsuggesties en scrapt data in slechts een paar klikken. Het verwerkt subpagina’s, past zich aan lay-outwijzigingen aan en kan zelfs data samenvatten, taggen of vertalen terwijl het scrapt. Je kunt exporteren naar Excel, Google Sheets, Airtable of Notion — zonder technische setup.
Gebruikssituaties waarin Thunderbit uitblinkt:
- e-commerceteams die SKU’s en prijzen van concurrenten volgen
- salesteams die leads en contactgegevens scrapen
- marktonderzoekers die nieuws of reviews bundelen
- makelaars die aanbiedingen en objectgegevens ophalen
Voor scraping met hoge frequentie en bedrijfskritische processen bespaart Thunderbit enorm veel tijd. Voor maatwerk, grootschalige of diep geïntegreerde projecten blijft traditioneel scripten zijn plek houden — maar voor de meeste teams is Thunderbit de snelste route van “ik heb data nodig” naar “ik heb data.”
Zie de Chrome-extensie van Thunderbit in actie of bekijk meer use cases op de Thunderbit Blog.
Probeer Thunderbit AI Webscraper
Snelle referentie: populaire JavaScript- en Node.js-webscrapinglibraries
Hier is je spiekbrief voor het JavaScript-scrapingecosysteem in 2026:
HTTP-verzoeken
- Axios: op promises gebaseerde, functierijke HTTP-client.
- node-fetch: Fetch API voor Node.js.
- Got: snelle, geavanceerde HTTP-client.
- SuperAgent: volwassen, chainable HTTP-verzoeken.
- Unirest: eenvoudige, taalneutrale client.
HTML-parsing
Dynamische content
- Puppeteer: headless Chrome-automatisering.
- Playwright: automatisering voor meerdere browsers.
- Nightmare: op Electron gebaseerde, legacy browserautomatisering.
Planning
- node-cron: cronjobs in Node.js.
CLI & hulpprogramma’s
- chalk: opmaak van terminaltekst.
- commander: parser voor CLI-argumenten.
- inquirer: interactieve CLI-prompts.
- dotenv: lader voor omgevingsvariabelen.
Opslag
- fs: ingebouwd bestandssysteem.
- lowdb: kleine lokale JSON-database.
- sqlite3: lokale SQL-database.
- mongodb: NoSQL-database.
Frameworks
- Crawlee: hoog niveau crawling- en scrapingframework van Apify. De JavaScript/TypeScript-versie zit in mei 2026 op v3.16 en is de meer volwassen tak (de Python-port is nieuwer). Het verpakt Puppeteer, Playwright, Cheerio en JSDOM achter één API, met ingebouwde proxyrotatie en wachtrijen — handig als je merkt dat je steeds dezelfde basis rondom je scrapers aan het herbouwen bent.
(Controleer altijd de nieuwste documentatie en GitHub-repositories voor updates.)
Aanbevolen bronnen om webscraping in JavaScript onder de knie te krijgen
Wil je dieper gaan? Hier is een zorgvuldig samengestelde lijst met bronnen om je scrapingvaardigheden naar een hoger niveau te tillen:
Officiële docs & handleidingen
- MDN Web Docs: Web Scraping
- Puppeteer-documentatie
- Playwright-documentatie
- Crawlee-documentatie
- Apify Web Scraping Academy
Tutorials & cursussen
- freeCodeCamp: De ultieme gids voor webscraping met Node.js
- YouTube: Web Scraping met Node.js (freeCodeCamp)
- DigitalOcean: hoe je een website scrapt met Node.js en Puppeteer
Open-sourceprojecten & voorbeelden
Community & forums
Boeken & uitgebreide gidsen
- O’Reilly’s “Web Scraping with Python” (voor concepten die over talen heen bruikbaar zijn)
- Udemy/Coursera-cursussen: “Web Scraping in Node.js”
(Controleer altijd de nieuwste edities en updates.)
Hoe je elke website scrapt met AI Get Started Free
Conclusie: de juiste aanpak kiezen voor jouw team
Dit is de kern: JavaScript en Node.js geven je ongelooflijk veel kracht en flexibiliteit voor webscraping. Je kunt er alles mee bouwen — van snelle en ruwe scripts tot robuuste, schaalbare crawlers. Maar grote kracht brengt ook grote… onderhoudslast met zich mee. Traditioneel scripten past het best bij maatwerkprojecten met flink wat engineeringwerk, waarbij je volledige controle nodig hebt en je accepteert dat er doorlopend onderhoud bij hoort.
Voor iedereen anders — voor zakelijke gebruikers, analisten, marketeers en iedereen die vooral gewoon data wil — zijn moderne no-code-oplossingen zoals Thunderbit een verademing. Thunderbit’s AI-aangedreven Chrome-extensie laat je data scrapen, structureren en exporteren in minuten in plaats van dagen. Geen code, geen selectors, geen hoofdpijn.
Dus, wat is de juiste aanpak? Als jouw team technische spierballen heeft en unieke eisen, duik dan in de Node.js-toolbox. Als je snelheid, eenvoud en de vrijheid wilt om je op inzichten te richten in plaats van op infrastructuur, probeer Thunderbit dan eens. Hoe dan ook: het web is jouw database — ga die data halen.
En als je ooit vastloopt, onthoud dan: zelfs de beste scrapers begonnen met een blanco pagina en een sterke kop koffie. Veel scrapeplezier.
Wil je meer leren over AI-aangedreven scraping of Thunderbit in actie zien?
- Officiële Thunderbit-website
- Download de Thunderbit Chrome-extensie
- Thunderbit Blog
- Hoe je elke website scrapt met AI
- Wat is data scraping en hoe doe je het in 2025
Heb je vragen, verhalen of je favoriete horrorverhalen over scraping? Laat ze achter in de reacties of neem contact met me op. Ik vind het geweldig om te zien hoe mensen het web omtoveren tot hun eigen dataspelplaats.
Blijf nieuwsgierig, blijf cafeïnerijk en scrape slimmer — niet harder.
Download de Thunderbit Chrome-extensie
Probeer AI Webscraper Get Started Free
FAQ:
1. Waarom JavaScript en Node.js gebruiken voor webscraping in 2025?
Omdat de meeste moderne websites met JavaScript zijn gebouwd. Node.js is snel, asynchroonvriendelijk en heeft een rijk ecosysteem (bijv. Axios, Cheerio, Puppeteer) dat alles ondersteunt: van eenvoudige fetch-verzoeken tot het op schaal scrapen van dynamische content.
2. Wat is de typische workflow voor het scrapen van een website met Node.js?
Die ziet er meestal zo uit:
Request → Response verwerken → (optioneel JS uitvoeren) → HTML parsen → Data extraheren → Opslaan of exporteren
Elke stap kan worden afgehandeld door gespecialiseerde tools zoals axios, cheerio of puppeteer.
3. Hoe scrape je dynamische, door JavaScript gerenderde pagina’s?
Gebruik headless browsers zoals Puppeteer of Playwright. Die laden de volledige pagina, inclusief JS, waardoor je kunt scrapen wat gebruikers echt zien.
4. Wat zijn de grootste uitdagingen bij traditioneel scrapen?
- veranderingen in de sitestructuur
- detectie door anti-botmaatregelen
- browserkosten qua resources
- handmatige datacleaning
- hoge onderhoudslast op lange termijn
Daardoor is grootschalig scrapen of scrapen zonder developer moeilijk vol te houden.
5. Wanneer moet ik iets als Thunderbit gebruiken in plaats van code?
Gebruik Thunderbit als je snelheid en eenvoud nodig hebt en geen code wilt schrijven of onderhouden. Het is ideaal voor teams in sales, marketing of research die snel data willen extraheren en structureren — vooral van complexe of meerpaginawebsites.




