
In 2025 is webdata niet meer zomaar een extraatje, maar echt onmisbaar voor elke bedrijfsstrategie. Of je nu een e-commercebedrijf runt dat continu de prijzen van concurrenten in de gaten wil houden, of een salesteam hebt dat zijn leadlijsten wil uitbreiden: organisaties behandelen openbare webdata als het nieuwe digitale goud. De cijfers spreken boekdelen: bijna , en meer dan . Python krijgt vaak alle aandacht, maar —vooral in enterprise-omgevingen waar betrouwbaarheid en integratie voorop staan.
 Na jaren in SaaS en automatisering heb ik van dichtbij gezien hoe Java webscraping bedrijfsprocessen compleet kan veranderen. Maar ik heb ook teams zien worstelen—verdwaald in technische details of gefrustreerd door dynamische websites en anti-botmaatregelen. Daarom deel ik graag een praktische, stap-voor-stap gids om Java webscraping in 2025 onder de knie te krijgen, met speciale aandacht voor de combinatie van code en moderne AI-tools zoals . Of je nu developer, operations manager of een zakelijke gebruiker bent die gewoon snel data wil verzamelen: deze gids is voor jou.
Na jaren in SaaS en automatisering heb ik van dichtbij gezien hoe Java webscraping bedrijfsprocessen compleet kan veranderen. Maar ik heb ook teams zien worstelen—verdwaald in technische details of gefrustreerd door dynamische websites en anti-botmaatregelen. Daarom deel ik graag een praktische, stap-voor-stap gids om Java webscraping in 2025 onder de knie te krijgen, met speciale aandacht voor de combinatie van code en moderne AI-tools zoals . Of je nu developer, operations manager of een zakelijke gebruiker bent die gewoon snel data wil verzamelen: deze gids is voor jou.
Wat is Java Webscraping? Simpel uitgelegd
Laten we het simpel houden: Java webscraping betekent dat je met Java-code automatisch info van websites haalt. Zie het als een digitale assistent die razendsnel duizenden webpagina’s kan lezen en precies de data die jij zoekt netjes in een spreadsheet zet—zonder ooit moe te worden of fouten te maken, en zo snel als je internet het toelaat.
Zo werkt het in gewone mensentaal:
- Je stuurt een verzoek naar een website (zoals je een pagina opent in je browser).
- Je downloadt de HTML-inhoud (de broncode van de pagina).
- Je parseert die HTML naar een structuur die je programma snapt.
- Je haalt de specifieke data eruit die je zoekt (denk aan productnamen, prijzen, e-mails).
- Je slaat de resultaten op in een handig formaat—CSV, Excel, een database of zelfs Google Sheets.
Je hoeft geen hardcore programmeur te zijn om de basis te snappen. Met de juiste tools en wat uitleg kan zelfs een zakelijke gebruiker webdata automatiseren en rommelige webpagina’s omtoveren tot bruikbare inzichten.
Waarom Java Webscraping zo belangrijk is voor bedrijven in 2025
Webscraping is allang geen hobby meer voor techneuten—het is een onmisbare schakel in het bedrijfsleven. Zo zetten bedrijven Java webscraping slim in om voorsprong te pakken, en zo levert het direct resultaat op:
| Toepassing van Webscraping | Zakelijke Voordelen (ROI) | Voorbeeldsectoren |
|---|---|---|
| Prijsmonitoring van concurrenten | Direct inzicht in prijswijzigingen; omzetstijgingen van 20%+ door sneller te reageren op de markt | E-commerce, Retail |
| Leadgeneratie & Sales Intelligence | Automatisch actuele prospectlijsten; 70% minder handmatig zoekwerk | B2B Sales, Marketing, Recruitment |
| Marktonderzoek & Trendanalyse | Trends vroeg signaleren; 5–15% meer omzet en 10–20% hogere marketing-ROI | Consumentenproducten, Marketingbureaus |
| Financiële & Investeringsdata | Alternatieve data voor trading; $5 miljard+ markt voor web-‘alt-data’ | Finance, Hedge Funds, Fintech |
| Workflowautomatisering & Monitoring | Routinematige dataverzameling geautomatiseerd; 73% kostenbesparing en 85% snellere implementatie | Vastgoed, Supply Chain, Overheid |
()
Waarom Java? Omdat het gebouwd is voor schaalbaarheid, betrouwbaarheid en integratie. Veel bedrijfsdatastromen draaien al op Java, dus een webscraper toevoegen is logisch. Dankzij Java’s multithreading en foutafhandeling is het perfect voor grote klussen—denk aan duizenden pagina’s per dag, niet slechts een paar.
Hoe werkt Java Webscraping? De basics en unieke voordelen
Laten we de basis van een typische Java webscraper bekijken:
- HTTP-verzoeken: Java gebruikt libraries zoals JSoup of Apache HttpClient om webpagina’s op te halen. Je kunt headers instellen, proxies gebruiken en browsers nabootsen om blokkades te voorkomen.
- HTML-parsing: Libraries zoals JSoup zetten de ruwe HTML om in een “DOM” (boomstructuur), zodat je makkelijk data vindt met CSS-selectors.
- Data-extractie: Je definieert regels (zoals “pak alle
<span class='price'>-elementen”) om de gewenste info te verzamelen. - Data-opslag: Sla de resultaten op als CSV, Excel, JSON of in een database.
Wat maakt Java zo sterk voor webscraping?
- Multithreading: Java kan veel pagina’s tegelijk verwerken, wat grootschalig scrapen supersnel maakt. Waar Python soms vastloopt door de GIL, draaien Java-threads soepel en snel.
- Prestaties: Java is gecompileerd en kan daardoor zware en geheugenvretende taken moeiteloos aan.
- Integratie met bedrijfssoftware: Java-scrapers sluiten naadloos aan op bestaande systemen—zoals CRM’s, ERP’s en databases—zonder gedoe.
- Foutafhandeling: Dankzij strikte types en exception handling zijn Java-scrapers robuust en goed te onderhouden voor langdurige projecten.
Voor bedrijfskritische datastromen is Java’s stabiliteit en schaalbaarheid ongeëvenaard.
Onmisbare Java Webscraping Libraries en Frameworks: Wat kies je en waarom?
Er zijn veel Java-libraries voor webscraping, maar drie springen eruit voor de meeste zakelijke toepassingen: JSoup, HtmlUnit en Selenium. Zo verhouden ze zich tot elkaar:
| Library | Kan JavaScript aan? | Gebruiksgemak | Prestaties | Ideaal voor |
|---|---|---|---|---|
| JSoup | ❌ (Geen JS) | Zeer eenvoudig | Hoog | Statische pagina’s, snelle taken, lichte jobs |
| HtmlUnit | ⚠️ Gedeeltelijk | Gemiddeld | Gemiddeld | Simpele JS, formulieren, headless scraping |
| Selenium | ✅ Ja (Volledig) | Gemiddeld/Moeilijk | Lager (per pagina) | JS-rijke sites, interactieve/dynamische pagina’s |
()
JSoup: Dé favoriet voor simpele HTML parsing
is mijn go-to voor de meeste scrapingklussen. Lichtgewicht, makkelijk in gebruik en perfect voor statische pagina’s waar de data direct in de HTML staat.
Voorbeeld:
1Document doc = Jsoup.connect("https://www.scrapingcourse.com/ecommerce/").get();
2String bannerTitle = doc.select("div.site-title").text();
3System.out.println("Banner: " + bannerTitle);Zo simpel is het. Voor blogs, productlijsten of directories zonder JavaScript is JSoup ideaal.
HtmlUnit: Browser-simulatie voor complexere taken
is een headless browser in Java. Het kan eenvoudige JavaScript aan, formulieren invullen en knoppen aanklikken—zonder een echte browser te openen.
Wanneer gebruiken? Als je moet inloggen of met eenvoudige dynamische content werkt, maar niet het zware Selenium wilt inzetten.
Voorbeeld:
1WebClient webClient = new WebClient();
2HtmlPage page = webClient.getPage("https://example.com/login");
3// ... formulier invullen en versturen ...Selenium: Voor JavaScript-rijke en interactieve pagina’s
is de krachtpatser. Het bestuurt een echte browser (zoals Chrome of Firefox) en kan dus alles aan wat een mens ook kan—ook sites die volledig op JavaScript draaien.
Wanneer gebruiken? Voor moderne webapps, pagina’s met infinite scroll of alles wat interactie vereist.
Voorbeeld:
1WebDriver driver = new ChromeDriver();
2driver.get("https://www.scrapingcourse.com/ecommerce/");
3List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
4// ... data extraheren ...
5driver.quit();Java Webscraping versnellen met Thunderbit: Visuele automatisering & code
Nu wordt het pas echt interessant—vooral voor teams en zakelijke gebruikers die niet de hele dag in code willen zitten. is een AI-webscraper zonder code, waarmee je scraping-taken visueel instelt (gewoon in je browser) en de data direct exporteert naar Excel, Google Sheets, Airtable of Notion.
Waarom Thunderbit combineren met Java?
- AI-Voorgestelde Velden: Thunderbit’s “AI Suggest Fields” leest de pagina en stelt automatisch voor welke data je moet extraheren—geen HTML of selectors nodig.
- Subpagina’s Scrapen: Meer details nodig? Thunderbit bezoekt automatisch subpagina’s (zoals productdetails) en verrijkt je dataset.
- Directe Templates: Voor populaire sites (Amazon, Zillow, LinkedIn) zijn er kant-en-klare templates—geen gedoe met configureren.
- Snel Exporteren: Na het scrapen exporteer je de data in seconden—klaar om in je Java-code te verwerken of te integreren.
Thunderbit bespaart enorm veel tijd bij prototyping, lastige sites of als je niet-technische collega’s snel data wilt laten verzamelen. Voor ontwikkelaars is het ideaal om het saaie of breekbare deel van scraping uit te besteden, zodat je je kunt focussen op de businesslogica.
Thunderbit en Java combineren voor complexe projecten
Zo’n workflow werkt top:
- Prototypen met Thunderbit: Gebruik de Chrome-extensie om je scraping visueel op te zetten. Laat AI velden voorstellen, paginering regelen en exporteer naar Google Sheets of CSV.
- Verwerken in Java: Schrijf Java-code om de geëxporteerde data (uit Sheets, CSV of Airtable) te lezen en verder te verwerken, analyseren of integreren met je bedrijfssoftware.
- Automatiseren & Inplannen: Gebruik de ingebouwde planner van Thunderbit om je data actueel te houden, en laat je Java-pipeline automatisch de nieuwste exports ophalen.
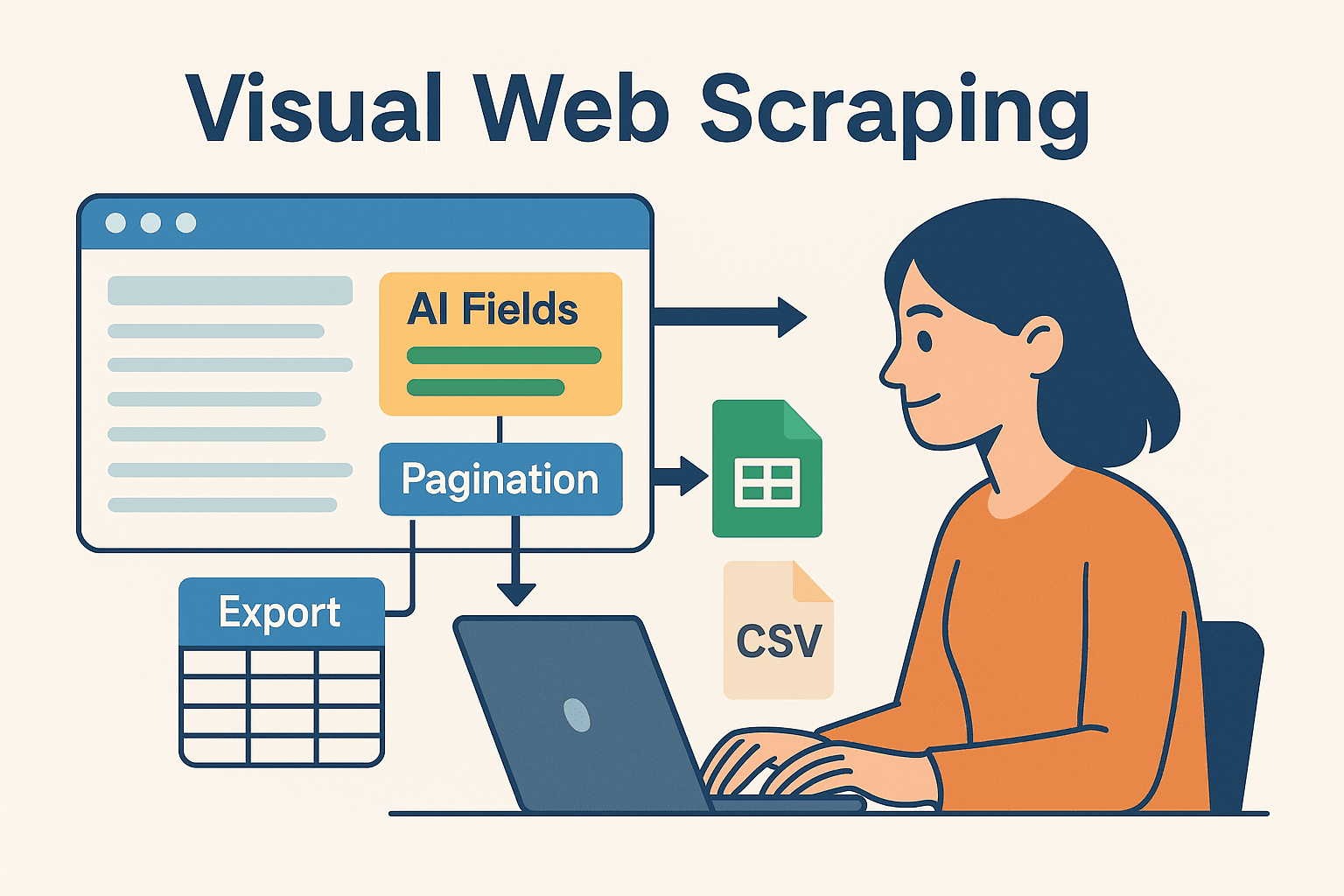 Met deze hybride aanpak profiteer je van het beste van twee werelden: de snelheid en flexibiliteit van AI-gedreven no-code scraping, én de kracht en betrouwbaarheid van Java voor verdere verwerking.
Met deze hybride aanpak profiteer je van het beste van twee werelden: de snelheid en flexibiliteit van AI-gedreven no-code scraping, én de kracht en betrouwbaarheid van Java voor verdere verwerking.
Stap-voor-stap: Je eerste Java webscraper bouwen
Tijd om praktisch aan de slag te gaan. Zo bouw je een eenvoudige Java webscraper vanaf nul.
Je Java-omgeving opzetten
- Installeer Java (JDK): Gebruik Java 17 of 21 voor de beste compatibiliteit.
- Zet Maven op: Hiermee beheer je makkelijk je dependencies.
- Kies een IDE: IntelliJ IDEA, Eclipse of VSCode zijn allemaal prima.
- Voeg JSoup toe aan je
pom.xml:1<dependency> 2 <groupId>org.jsoup</groupId> 3 <artifactId>jsoup</artifactId> 4 <version>1.16.1</version> 5</dependency>
Je scraper schrijven en uitvoeren
We gaan productnamen en prijzen scrapen van een demo e-commerce site.
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3import org.jsoup.select.Elements;
4import org.jsoup.nodes.Element;
5public class ProductScraper {
6 public static void main(String[] args) {
7 String url = "https://www.scrapingcourse.com/ecommerce/";
8 try {
9 Document doc = Jsoup.connect(url)
10 .userAgent("Mozilla/5.0")
11 .get();
12 Elements productElements = doc.select("li.product");
13 for (Element productEl : productElements) {
14 String name = productEl.selectFirst("h2").text();
15 String price = productEl.selectFirst("span.price").text();
16 System.out.println(name + " -> " + price);
17 }
18 } catch (Exception e) {
19 e.printStackTrace();
20 }
21 }
22}Tip: Stel altijd een user-agent in om een echte browser na te bootsen. Sommige sites blokkeren de standaard Java user-agent.
Je data exporteren en gebruiken
- CSV-export: Gebruik
FileWriterof een library zoals OpenCSV om resultaten naar een CSV-bestand te schrijven. - Excel-export: Gebruik Apache POI voor .xls/.xlsx-bestanden.
- Database-integratie: Gebruik JDBC om data direct in je database te zetten.
- Google Sheets: Exporteer vanuit Thunderbit en lees in met de Google Sheets API voor Java.
Veelvoorkomende uitdagingen bij Java webscraping en oplossingen
Webscraping gaat niet altijd zonder slag of stoot. Dit zijn de meest voorkomende obstakels—en hoe je ze tackelt:
- IP-blokkades & Rate Limiting: Vertraag je verzoeken (
Thread.sleep()), roteer proxies en varieer je timing. Voor grote volumes kun je proxyservices inzetten. - CAPTCHAs & Botdetectie: Gebruik Selenium om menselijk gedrag na te bootsen, of schakel anti-bot API’s in. Soms kun je met Thunderbit’s cloud scraping deze barrières omzeilen.
- Dynamische content: Geeft JSoup lege resultaten? Dan wordt de data waarschijnlijk via JavaScript geladen. Stap over op Selenium of HtmlUnit, of zoek naar de onderliggende API van de site.
- Wijzigingen in website-structuur: Schrijf flexibele code met robuuste selectors. Monitor je scrapers en wees klaar om ze aan te passen als sites veranderen. Thunderbit’s AI past zich snel aan—gewoon “AI Suggest Fields” opnieuw uitvoeren.
- Sessiebeheer: Voor scraping achter een login moet je cookies en sessies goed beheren. Selenium en Thunderbit (als je in Chrome bent ingelogd) kunnen met beveiligde pagina’s omgaan.
Geavanceerde tips om Java webscraping slimmer te maken
Klaar voor de volgende stap? Probeer deze expert-tips:
- Multithreading: Gebruik Java’s
ExecutorServiceom meerdere pagina’s tegelijk te scrapen. Let wel op dat je niet te agressief bent en geblokkeerd wordt! - Plannen: Gebruik Quartz Scheduler in Java, of laat Thunderbit het plannen in de cloud regelen met natuurlijke taal (“elke maandag om 9:00”).
- Cloud Schalen: Voor grote projecten kun je headless browsers in de cloud draaien of taken verdelen over meerdere machines.
- Hybride Workflows: Gebruik Thunderbit voor lastige, onderhoudsgevoelige sites en Java-code voor de rest. Combineer de resultaten in je datawarehouse.
- Monitoring & Logging: Gebruik Java’s logging-frameworks om de gezondheid van je scraper te volgen, fouten snel te detecteren en meldingen te krijgen als er iets misgaat.
Conclusie & belangrijkste inzichten
Webdata is het nieuwe goud, en Java blijft een van de krachtigste tools—vooral voor teams die betrouwbaarheid, schaal en integratie nodig hebben. De basisworkflow is simpel: ophalen, parsen, extraheren en exporteren. Met libraries als JSoup, HtmlUnit en Selenium kun je alles aan, van simpele directories tot de meest complexe JavaScript-sites.
Maar je hoeft niet alles zelf te coderen. Tools als brengen AI en visuele automatisering in het spel, zodat je sneller kunt prototypen, aanpassen en opschalen dan ooit. Mijn tip? Combineer code en no-code. Gebruik Thunderbit voor snelle opzet en onderhoud, en laat je Java-pipeline het zware werk doen.
Benieuwd hoe Thunderbit jouw workflow kan versnellen? en scrape je eerste site binnen een paar minuten. Meer weten? Check de voor diepgaande artikelen, tutorials en het laatste nieuws over webscraping-automatisering.
Veel succes met scrapen—en moge je data altijd gestructureerd, actueel en direct bruikbaar zijn.
Veelgestelde vragen
1. Is Java nog relevant voor webscraping in 2025?
Zeker weten. Hoewel Python populair is voor snelle scripts, blijft Java de standaard voor grootschalige, betrouwbare en langdurige scrapingprojecten—vooral als integratie en multithreading belangrijk zijn.
2. Wanneer gebruik ik JSoup, HtmlUnit of Selenium?
Gebruik JSoup voor statische pagina’s, HtmlUnit voor eenvoudige dynamische content of formulieren, en Selenium voor JavaScript-rijke of interactieve sites. Kies de tool die past bij de complexiteit van de site.
3. Hoe voorkom ik blokkades tijdens het scrapen?
Vertraag je verzoeken, gebruik roterende proxies, stel realistische user-agents in en boots menselijk gedrag na. Voor lastige sites kun je Thunderbit’s cloud scraping of anti-bot API’s inzetten.
4. Kunnen Thunderbit en Java samenwerken?
Absoluut. Gebruik Thunderbit om scrapes visueel te definiëren en te plannen, exporteer de data en verwerk of integreer deze vervolgens met je Java-code. Het is een krachtige combinatie voor zowel zakelijke gebruikers als ontwikkelaars.
5. Wat is de snelste manier om te starten met Java webscraping?
Installeer Java en Maven, voeg JSoup toe en probeer een eenvoudige site te scrapen. Voor complexere klussen of snelle prototypes: installeer en laat AI het zware werk doen—verwerk de resultaten daarna in je Java-workflow.
Meer tips, codevoorbeelden of automatiseringstrucs? Duik in de of abonneer je op ons voor praktische tutorials en het laatste nieuws over webscraping. Meer weten