Ik weet het nog goed: de allereerste keer dat ik probeerde productinformatie van een website te plukken. Ik zat naar een pagina vol hardloopschoenen te kijken en dacht: “Hoe lastig kan het zijn om al die namen en prijzen in een Excelletje te krijgen?” Een paar uur later zat ik tot over mijn oren in JavaScript-fouten, vage selectors en kreeg ik steeds meer respect voor iedereen die ooit zelf een webscraper heeft gebouwd.
Klinkt bekend? Of je nu in sales, e-commerce of operations werkt en gewoon snel actuele data wilt verzamelen om betere keuzes te maken: je bent zeker niet de enige. De vraag naar webscraping is de afgelopen jaren enorm toegenomen. De wereldwijde en zal naar verwachting verdubbelen tegen 2030. Maar er zit een addertje onder het gras: de meeste traditionele scrapingtools vragen om flink wat technische kennis. Daarom laat ik je graag twee routes zien: een technische, codegerichte aanpak met Cypress, en een snelle, no-code AI-oplossing met . We gebruiken de als voorbeeld.
Of je nu een developer bent die zijn JavaScript-skills wil inzetten, of een zakelijke gebruiker die liever geen code aanraakt: met deze gids haal je de data binnen die je nodig hebt—zonder stress of verloren weekenden.
Wat is Webscraping en Waarom is het Belangrijk voor Bedrijven?
Laten we bij het begin beginnen: webscraping is het automatisch verzamelen van gegevens van websites. In plaats van handmatig productnamen, prijzen of contactgegevens te kopiëren, laat je software het zware werk doen.
Waarom is dit zo waardevol voor bedrijven? Data is het nieuwe goud (of havermelk, als je dat liever hebt). Bedrijven in sales, e-commerce en operations gebruiken webscraping om:
- Leads te genereren door contactgegevens uit online bedrijvengidsen of sociale profielen te halen.
- Concurrentieprijzen en producttrends te volgen—.
- Klantsentiment te analyseren door reviews en beoordelingen te verzamelen.
- Tijdrovend onderzoek te automatiseren dat anders uren of zelfs dagen zou kosten.
En het werkt echt: zegt dat openbare webdata hen helpt sneller en beter te beslissen. Kortom: als je geen webscraping inzet, laat je kansen én inzichten liggen.
Kennismaken met Cypress: Een Populaire Tool voor Webscraping
Tijd voor de tools. Cypress is een open-source framework dat oorspronkelijk is ontwikkeld voor het automatisch testen van webapplicaties. Zie het als een robot die knoppen aanklikt, formulieren invult en checkt of je website werkt zoals het hoort. Maar hier komt het leuke: omdat Cypress in een echte browser draait en goed overweg kan met JavaScript-rijke sites, is het ook een verrassend handige (zij het wat ongebruikelijke) tool voor webscraping.
Hoe verhoudt Cypress zich tot andere scrapingtools, zoals die in Python (denk aan BeautifulSoup of Scrapy)? Even kort op een rijtje:
- Cypress: Ideaal voor het scrapen van dynamische, JavaScript-gegenereerde content. Je moet wel JavaScript kennen en met Node.js kunnen werken. Het is krachtig en flexibel, maar vooral geschikt voor ontwikkelaars.
- Python-scrapers: Tools als BeautifulSoup of Scrapy zijn geoptimaliseerd voor grootschalig crawlen van statische HTML. Ze hebben een groot ecosysteem, maar kunnen moeite hebben met sites die een echte browser nodig hebben om content te laden.
Ben je al bekend met JavaScript of testautomatisering? Dan is Cypress een verrassend effectieve manier om data te scrapen. Maar als je liever geen code schrijft, geen zorgen—er is ook een no-code alternatief.
Stapsgewijs: Webscraping met Cypress (Adidas Hardloopschoenen Voorbeeld)
Laten we aan de slag gaan en een Cypress-scraper bouwen voor de . Doel: productnamen, prijzen, afbeeldingen en links verzamelen in een overzichtelijk bestand.
1. Je Cypress-omgeving opzetten
Eerst heb je en npm nodig. Installeer deze, open je terminal en voer uit:
1mkdir adidas-scraper
2cd adidas-scraper
3npm init -y
4npm install cypress --save-devHiermee maak je een nieuw project aan en installeer je Cypress lokaal. Start Cypress voor het eerst met:
1npx cypress openCypress maakt een cypress/-map aan met voorbeeldtests. Die kun je verwijderen en je eigen testbestand aanmaken, bijvoorbeeld cypress/e2e/adidas-scraper.cy.js.
2. De website inspecteren en te scrapen data bepalen
Tijd om onderzoek te doen. Open de in je browser, klik met rechts op een product en kies “Inspecteren.” Je ziet dat elk product in een kaart zit, met elementen voor naam, prijs, afbeelding en link.
Bijvoorbeeld:
1<div class="product-card">
2 <a href="/us/adizero-sl2-running-shoes/XYZ123.html">
3 <img src="..." alt="Adizero SL2 Running Shoes"/>
4 <div class="product-price">$130</div>
5 <div class="product-name">Adizero SL2 Running Shoes -- Men's Running</div>
6 </a>
7</div>Let op klassenamen zoals .gl-price voor prijzen en zoek naar consistente patronen in de HTML. Hier geef je Cypress aan wat het moet verzamelen.
3. Cypress-code schrijven om data te verzamelen
Een voorbeeldscript om je op weg te helpen:
1// cypress/e2e/adidas-scraper.cy.js
2describe('Scrape Adidas Running Shoes', () => {
3 it('collects product name, price, image, and link', () => {
4 cy.visit('<https://www.adidas.com/us/men-running-shoes>');
5 const products = [];
6 cy.get('a[href*="/us/"][href*="running-shoes"]').each(($el) => {
7 const name = $el.find('*:contains("Running Shoes")').text().trim();
8 const price = $el.find('.gl-price').text().trim();
9 const imageUrl = $el.find('img').attr('src');
10 const link = $el.attr('href');
11 products.push({ name, price, image: imageUrl, link: `https://www.adidas.com$\{link\}` });
12 }).then(() => {
13 cy.writeFile('cypress/output/adidas_products.json', products);
14 });
15 });
16});Wat gebeurt hier?
cy.visit()laadt de pagina.cy.get()selecteert alle productlinks die passen bij het Adidas-URL-patroon..each()loopt door elk product en haalt naam, prijs, afbeelding en link op.- De data wordt in een array gezet en als JSON-bestand opgeslagen.
Je zult de selectors moeten aanpassen als Adidas hun site wijzigt, maar hiermee kom je al een heel eind.
4. De gescrapete data exporteren en gebruiken
Na het uitvoeren van het script (via de Cypress GUI of npx cypress run), vind je in cypress/output/adidas_products.json een array met productobjecten zoals:
1[
2 {
3 "name": "Adizero SL2 Running Shoes Men's Running",
4 "price": "$130",
5 "image": "<https://assets.adidas.com/images/w_280,h_280,f_auto,q_auto:sensitive/.../adizero-SL2-shoes.jpg>",
6 "link": "<https://www.adidas.com/us/adizero-sl2-running-shoes/XYZ123.html>"
7 },
8 ...
9]Vanaf hier kun je de JSON omzetten naar CSV, analyseren in Excel of inladen in je favoriete BI-tool. Je kunt het proces zelfs automatiseren om bijvoorbeeld dagelijks prijzen te monitoren.
Veelvoorkomende Uitdagingen bij Webscraping met Cypress
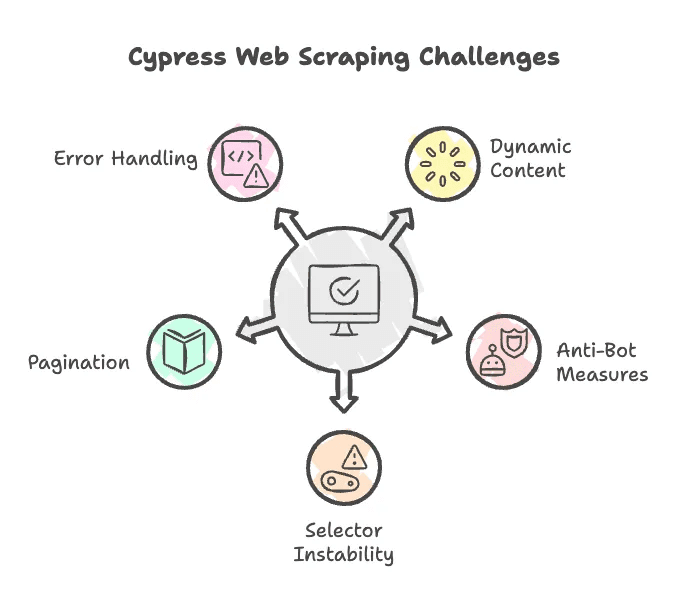
Eerlijk is eerlijk: webscraping verloopt niet altijd vlekkeloos. Dit zijn veelvoorkomende obstakels bij Cypress (en tips om ze te omzeilen):
- JavaScript-gegenereerde content: Cypress kan goed overweg met dynamische content, maar soms moet je wachten tot elementen geladen zijn of scrollen om lazy loading te activeren. Gebruik
cy.wait()of scroll-commando’s waar nodig. - Anti-botmaatregelen: Sommige sites weren bots door user agents te controleren of verzoeken te beperken. Cypress draait in een echte browser, wat helpt, maar hardnekkige blokkades vragen soms om geavanceerdere trucs (zoals proxies of aangepaste headers).
- Onstabiele selectors: Als Adidas hun HTML-structuur of klassenamen aanpast, werkt je script mogelijk niet meer. Houd je selectors dus up-to-date.
- Paginering: Veel productpagina’s hebben meerdere pagina’s. Je moet logica toevoegen om op “Volgende” te klikken en resultaten te verzamelen.
- Foutafhandeling: Cypress is bedoeld voor testen en stopt snel als er iets ontbreekt. Voeg checks toe om ontbrekende elementen netjes af te handelen.
Krijg je het gevoel dat je een informaticadiploma nodig hebt om een lijstje schoenen te verzamelen? Je bent niet de enige. Precies daarom hebben we Thunderbit ontwikkeld.
Te ingewikkeld? Probeer Thunderbit: Webscraping in 2 Klikken
Geen zin in Node.js, selectors of JavaScript-debugging? Maak kennis met , onze AI-webscraper Chrome-extensie. Speciaal voor zakelijke gebruikers die gewoon snel data willen—zonder code, zonder gedoe.
Wat maakt Thunderbit anders?
- Geen code of selector-gedoe: Gewoon aanwijzen, klikken en de AI doet de rest.
- Eén template, meerdere sites: Thunderbit’s AI past zich aan verschillende paginalay-outs aan, dus je hoeft niet telkens opnieuw te configureren.
- Scrapen in browser of cloud: Kies de modus die past bij jouw snelheid en nauwkeurigheid.
- Automatische paginering en subpagina’s: Thunderbit klikt zelf door meerdere pagina’s en bezoekt zelfs productdetailpagina’s voor extra data.
- Gratis export: Download je data naar Excel, Google Sheets, Airtable of Notion—zonder verborgen kosten.
Laten we samen de Adidas-pagina scrapen met Thunderbit.
Stapsgewijs: Webscraping met Thunderbit (Adidas Voorbeeld)
1. Thunderbit Chrome-extensie installeren
Installeer eerst . Dit duurt minder dan een minuut—sneller dan ik mijn koffiemok kan vinden.
Maak een gratis account aan—Thunderbit biedt een gratis proefperiode (10 pagina’s) en een gratis plan (6 pagina’s per maand), dus je kunt het direct uitproberen zonder creditcard.
2. Data scrapen met AI Suggest Fields
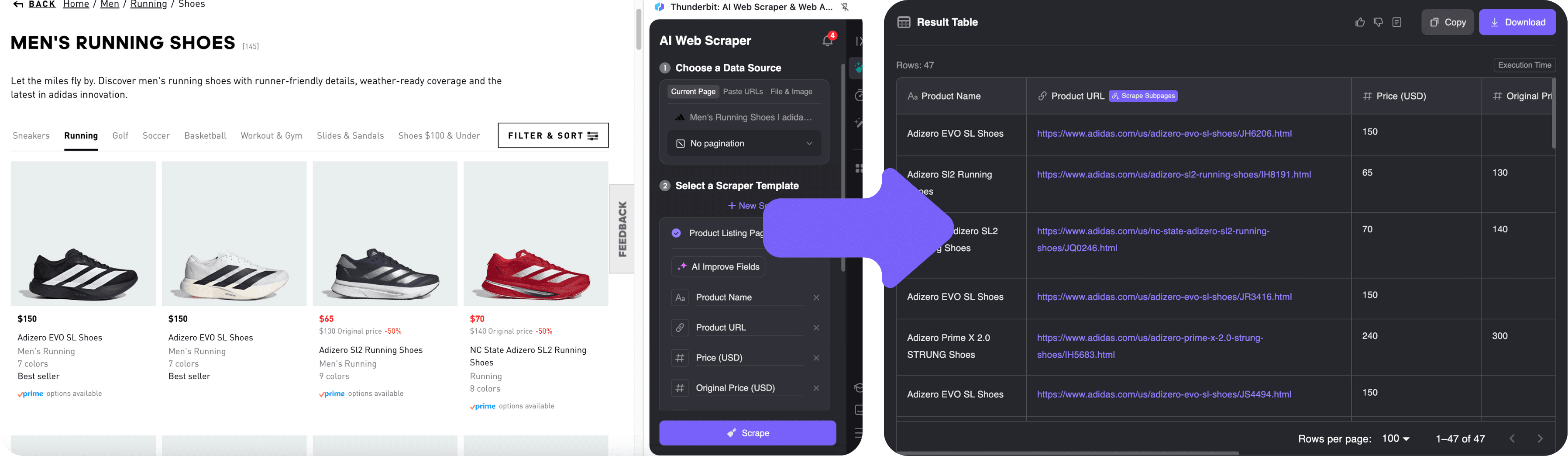
- Open de .
- Klik op het Thunderbit-icoon in je browser. De zijbalk verschijnt.
- Klik op “AI Suggest Fields”. Thunderbit’s AI scant de pagina en herkent automatisch de velden voor productnaam, prijs, afbeelding en link. Je ziet direct een voorbeeldtabel.
- Wil je kolommen aanpassen? Je kunt ze eenvoudig hernoemen of nieuwe velden toevoegen. Je kunt zelfs in gewone taal aangeven wat je extra wilt, zoals “haal ook het aantal beschikbare kleuren op.”
- Klik op “Scrape”. Thunderbit verzamelt alle data, klikt automatisch door paginering als er meerdere pagina’s zijn. Wil je meer details van elke productpagina? Gebruik de subpagina-functie—Thunderbit bezoekt elk product en verrijkt je tabel.
3. Je data exporteren en gebruiken
Na het scrapen bekijk je de tabel in de Thunderbit-zijbalk. Je kunt:
- Exporteren naar Excel, Google Sheets, Airtable of Notion met één klik.
- Downloaden als CSV of JSON.
- Afbeeldingen, e-mails, telefoonnummers en meer exporteren—Thunderbit ondersteunt alle gangbare datatypes.
En ja, exporteren is helemaal gratis. Geen onverwachte betaalmuur.
Meer tips? Bekijk onze of lees de voor meer scraping-tutorials.
Cypress vs. Thunderbit: Welke Webscraping Tool Past bij Jou?
Laten we Cypress en Thunderbit naast elkaar zetten. Hier een handig overzicht:
| Aspect | Cypress (Code Scraper) | Thunderbit (No-Code AI Scraper) |
|---|---|---|
| Setup Moeilijkheid | Vereist Node.js, npm en JavaScript-kennis. Opzetten kan tijdrovend zijn voor niet-developers. | Installeer de Chrome-extensie, log in en je kunt direct aan de slag. Geen code nodig. |
| Benodigde Technische Kennis | Je moet JavaScript en DOM/CSS-selectors begrijpen. Hoge instapdrempel voor niet-programmeurs. | Geen programmeerkennis vereist. Gewoon aanwijzen en klikken, of in gewone taal aangeven wat je wilt. |
| Snelheid van Implementatie | Scripts schrijven en debuggen kost vaak uren, zeker bij complexe pagina’s of paginering. | Binnen enkele klikken een scrape opzetten en uitvoeren. Paginering en subpagina’s worden automatisch afgehandeld. |
| Flexibiliteit | Zeer flexibel—je kunt elke logica coderen, inloggen, captchas oplossen en API’s integreren. | Gericht op standaardpatronen. AI verwerkt de meeste sites, maar heel unieke of complexe workflows vragen soms handmatig werk. |
| Robuustheid bij Wijzigingen | Scripts zijn kwetsbaar—als de HTML van de site verandert, moet je je code aanpassen. | Robuuster—AI past zich aan kleine lay-outwijzigingen aan. Thunderbit’s modellen worden continu verbeterd. |
| Schaalbaarheid | Kan een redelijk volume aan, maar browser-based scraping is trager op grote schaal. | Cloud-scraping kan honderden pagina’s aan. Creditsysteem houdt het beheersbaar voor zakelijk gebruik. |
| Ideaal Voor | Ontwikkelaars of technische gebruikers die precisie en maatwerk willen. Perfect voor eenmalige dataverzameling of complexe workflows. | Zakelijke gebruikers die snel, zonder code, data willen scrapen voor bijvoorbeeld prijsmonitoring, leadgeneratie of het verzamelen van lijsten. Ideaal voor prototyping en standaard e-commerce-, directory- of reviewsites. |
Kortom: Cypress geeft je maximale controle, Thunderbit biedt snelheid en gemak. Ben je een ontwikkelaar die graag sleutelt? Dan is Cypress jouw speeltuin. Wil je gewoon snel data (en wil je baas het vóór de lunch)? Dan is Thunderbit je beste vriend.
Belangrijkste Inzichten: Kies de Beste Webscraping-aanpak voor Jouw Doel
- Webscraping is onmisbaar voor moderne bedrijven—of je nu concurrenten volgt, leads genereert of markttrends analyseert.
- Cypress is krachtig en flexibel voor ontwikkelaars die hun eigen scrapers willen bouwen. Ideaal voor dynamische sites en maatwerk, maar vraagt wel technische kennis en onderhoud.
- Thunderbit is er voor iedereen. Het is een waarmee je in twee klikken data kunt scrapen—zonder code, zonder installatiegedoe. Paginering, subpagina’s en export naar je favoriete tools zijn gratis inbegrepen.
- Kies Cypress als je maximale flexibiliteit wilt en niet bang bent voor code.
- Kies Thunderbit als je tijd wilt besparen, technische rompslomp wilt vermijden en snel schone data nodig hebt—vooral als je in sales, e-commerce, marketing of operations werkt.
Meer weten? Bekijk de voor tutorials over , en meer.
En als je ooit weer naar een pagina vol hardloopschoenen staart en je afvraagt hoe je die data in een spreadsheet krijgt—weet dan dat je opties hebt. Veel succes met scrapen!
Veelgestelde Vragen
1. Wat is Cypress en hoe kun je het gebruiken voor webscraping?
Cypress is een op JavaScript gebaseerde testtool die kan omgaan met dynamische websites, waardoor het geschikt is voor het scrapen van JavaScript-gegenereerde content.
2. Wat zijn de grootste uitdagingen bij het scrapen van websites met Cypress?
Veelvoorkomende problemen zijn veranderende HTML-structuren, lazy loading, anti-botmaatregelen en het omgaan met paginering of ontbrekende elementen op complexe pagina’s.
3. Is er een eenvoudigere manier om websites te scrapen zonder te coderen?
Ja, Thunderbit is een AI-webscraper Chrome-extensie waarmee je met een paar klikken data kunt verzamelen—zonder code, installatie of gedoe met selectors.
Meer weten: