

Er zit iets tijdloos in een terminal openen, één commando typen en zien hoe ruwe webdata binnenkomt alsof je net de Matrix hebt opengebroken. Voor developers en technische power users is cURL precies zo’n toverstaf: een bescheiden command-line tool die stilletjes op miljarden apparaten draait, van cloudservers tot je slimme koelkast. En zelfs in 2026, met alle glanzende no-code- en AI-scrapingtools, blijft webscraping met cURL voor veel mensen de logische keuze als je snelheid, controle en scriptbaarheid wilt.
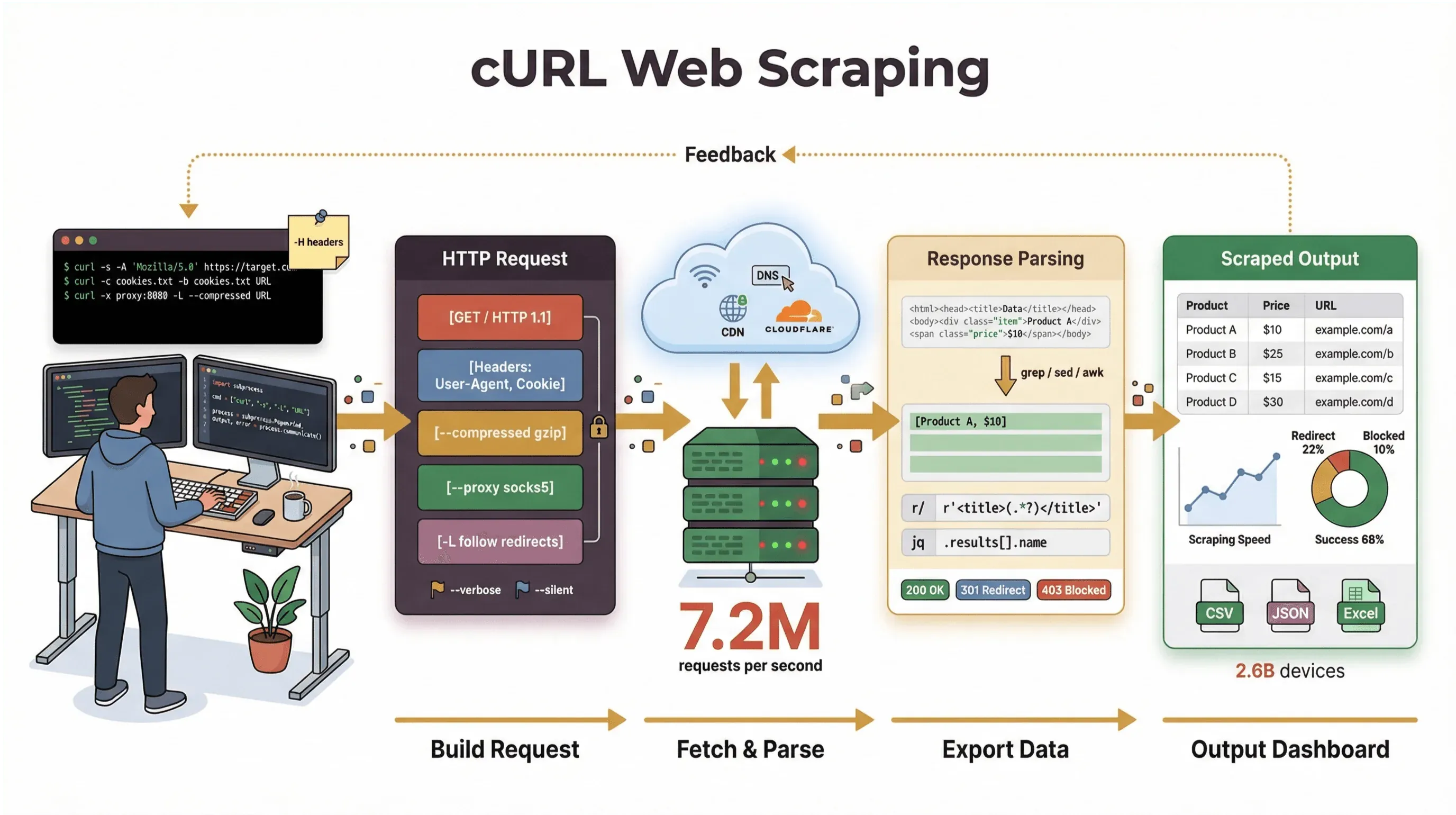
Ik heb jaren besteed aan het bouwen van automatiseringstools en het helpen van teams met het verwerken van webdata, en ik pak nog steeds cURL erbij als ik een pagina moet ophalen, een API wil debuggen of een scraping-workflow wil prototypen. In deze gids neem ik je mee door een cURL web scraping-tutorial met zowel de basis als geavanceerde trucs — inclusief echte commandovoorbeelden, praktische tips en een nuchtere blik op waar cURL uitblinkt (en waar het vastloopt). En ben je meer een zakelijke gebruiker die liever niet aan de command-line komt, dan laat ik je zien hoe Thunderbit, onze AI-aangedreven webscraper, je in twee klikken van “ik heb deze data nodig” naar “hier is mijn spreadsheet” brengt — zonder code.
Laten we erin duiken en kijken waarom cURL in 2026 nog steeds relevant is voor webscraping, hoe je het effectief gebruikt en wanneer het tijd is om iets nog krachtigers in te zetten.
Wat is cURL? De basis van webscraping met cURL
In de kern is cURL een command-line tool en library om data via URL’s over te dragen. Het bestaat al bijna 30 jaar (ja, echt) en is overal te vinden: ingebouwd in besturingssystemen, gebruikt in scripts en stilletjes verantwoordelijk voor dataoverdracht in meer dan twintig miljard installaties. Als je ooit snel een webpagina hebt opgehaald, een API hebt getest of een bestand hebt gedownload, is de kans groot dat je cURL hebt gebruikt.
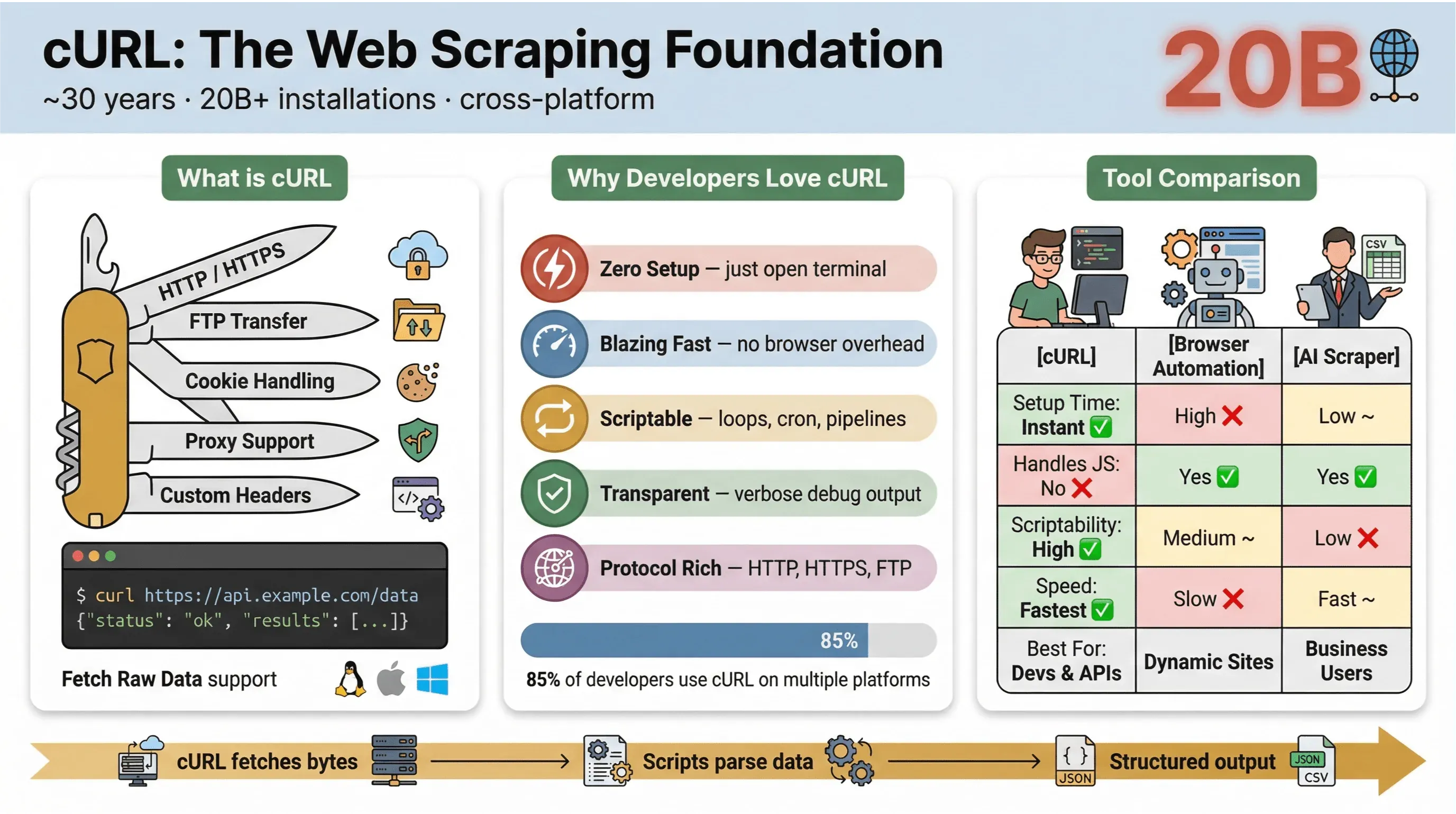
Dit maakt cURL zo populair voor webscraping:
- Lichtgewicht en multiplatform: Werkt op Linux, macOS, Windows en zelfs ingebedde apparaten.
- Ondersteuning voor protocollen: Kan overweg met HTTP, HTTPS, FTP en meer.
- Scriptbaar: Perfect voor automatisering, cronjobs en glue code.
- Geen gebruikersinteractie nodig: Ontworpen voor niet-interactief gebruik — ideaal voor batchtaken en pipelines.
Maar laten we duidelijk zijn: de hoofdtaak van cURL is het ophalen van ruwe data — HTML, JSON, afbeeldingen, noem maar op. Het parseert, rendert of structureert die data niet voor je. Zie cURL als de “eerste mijl” van webscraping: het haalt de bytes op, maar je hebt andere tools nodig (zoals Python-scripts, grep/sed/awk of een AI-webscraper) om daar gestructureerde informatie van te maken.
Als je de officiële documentatie wilt zien, bekijk dan de HTTP scripting-gids van cURL.
Waarom cURL gebruiken voor webscraping? (cURL web scraping tutorial)
Waarom blijven developers en technische gebruikers cURL dan gebruiken voor webscraping, ondanks al die nieuwe tools? Dit maakt cURL bijzonder:
- Minimale setup: Geen installaties, geen dependencies — gewoon je terminal openen en gaan.
- Snelheid: Data direct ophalen zonder te wachten tot een browser laadt.
- Scriptbaarheid: Gemakkelijk URL’s in lussen verwerken, requests automatiseren en commando’s aan elkaar koppelen.
- Ondersteuning voor protocollen en functies: Werkt met cookies, proxies, redirects, custom headers en meer.
- Transparantie: Met verbose/debug-output zie je precies wat er gebeurt.
In de cURL-gebruikersenquête van 2025 gaf 85,7% van de respondenten aan de cURL command-line tool te gebruiken, en 96,2% zei dat ze cURL op Linux gebruiken — nog altijd veruit het belangrijkste platform voor cURL.
--- Het blijft gewoon het Zwitsers zakmes voor HTTP-requests, snelle data-opvraging en troubleshooting.
Hier is een snelle vergelijking tussen cURL en andere scrapingmethoden:
| Functie | cURL | Browserautomatisering (bijv. Selenium) | AI-webscraper (bijv. Thunderbit) |
|---|---|---|---|
| Insteltijd | Direct | Hoog | Laag |
| Scriptbaarheid | Hoog | Gemiddeld | Laag (geen code nodig) |
| JavaScript verwerken | Nee | Ja | Ja (Thunderbit: via browser) |
| Cookie-/sessieondersteuning | Handmatig | Automatisch | Automatisch |
| Datastructurering | Handmatig (later parsen) | Handmatig (later parsen) | AI-/templategebaseerd |
| Best voor | Devs, snelle pulls | Complexe, dynamische sites | Zakelijke gebruikers, gestructureerde export |
Kort gezegd: cURL is onovertroffen voor snelle, scriptbare data-opvragingen — vooral voor statische pagina’s, API’s of wanneer je eenvoudige workflows wilt automatiseren. Maar zodra je complexe HTML moet parsen, JavaScript moet verwerken of gestructureerde data wilt exporteren, heb je iets nodig dat daar beter voor is gemaakt.
Aan de slag: basisvoorbeelden van cURL webscraping-commando’s
Laten we praktisch worden. Hier lees je stap voor stap hoe je cURL gebruikt voor basistaken rond webscraping.
Ruwe HTML ophalen met cURL
Het simpelste gebruik: de HTML van een webpagina ophalen.
curl https://books.toscrape.com/
Dit commando haalt de homepage op van Books to Scrape, een publieke demowebsite voor webscraping. Je ziet de ruwe HTML-uitvoer in je terminal — let op tags zoals <title> of stukjes tekst zoals “In stock.”
Uitvoer opslaan in een bestand
Wil je die HTML bewaren om later te parsen? Gebruik de -o-vlag:
curl -o page.html https://books.toscrape.com/
Nu heb je een page.html-bestand met de volledige HTML-inhoud. Ideaal voor verdere analyse of parsing met andere tools.
POST-requests verzenden met cURL
Moet je een formulier versturen of met een API communiceren? Gebruik de -d-vlag voor POST-requests. Hier is een voorbeeld met httpbin, een site die is gebouwd voor HTTP-tests:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
Je krijgt dan een JSON-respons terug waarin je verzonden data wordt gespiegeld — handig om te testen en te prototypen.
Headers bekijken en debuggen
Soms wil je de response-headers zien of de request debuggen:
-
Alleen headers (HEAD-request):
curl -I https://books.toscrape.com/ -
Headers meenemen met de body:
curl -i https://httpbin.org/get -
Verbose/debug-output:
curl -v https://books.toscrape.com/
Deze vlaggen helpen je begrijpen wat er onder de motorkap gebeurt — essentieel bij troubleshooting.
Hier is een snelle referentietabel voor deze commando’s:
| Taak | Commando-voorbeeld | Opmerkingen |
|---|---|---|
| HTML ophalen | curl URL | Geeft HTML weer in de terminal |
| Opslaan in bestand | curl -o bestand.html URL | Schrijft uitvoer naar een bestand |
| Headers bekijken | curl -I URL of curl -i URL | -I alleen HEAD, -i inclusief headers met body |
| Formulierdata posten | curl -d "a=1&b=2" URL | Verstuurt form-gecodeerde data |
| Request/response debuggen | curl -v URL | Toont gedetailleerde request/response-informatie |
Voor meer voorbeelden kun je de officiële cURL-scriptingdocumentatie bekijken.
Naar een hoger niveau: geavanceerde webscraping met cURL (webscraping met cURL)
Als je de basis onder de knie hebt, opent cURL een wereld aan geavanceerde functies voor complexere scrapingtaken.
Cookies en sessies beheren
Veel sites gebruiken cookies om inlogsessies vast te houden of gebruikers te volgen. Met cURL kun je cookies opslaan en hergebruiken tussen requests:
# Cookies opslaan na inloggen
curl -c cookies.txt https://example.com/login
# Cookies gebruiken voor volgende requests
curl -b cookies.txt https://example.com/account
Zo kun je browsersessies nabootsen en pagina’s achter een loginwall bereiken (zolang er geen JavaScript-challenge is).
User-Agent en custom headers nabootsen
Sommige websites tonen andere content op basis van je User-Agent of headers. Standaard identificeert cURL zich als “curl/VERSION”, wat blokkades of afwijkende content kan triggeren. Om een browser na te bootsen:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
Je kunt ook custom headers instellen, zoals taalvoorkeuren:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
Zo krijg je dezelfde content te zien als een echte browser.
Proxies gebruiken voor webscraping
Moeten je requests via een proxy lopen (bijvoorbeeld voor geo-tests of om IP-blokkades te omzeilen)? Gebruik de -x-vlag:
curl -x http://proxy.example.org:4321 https://remote.example.org/
Zorg er wel voor dat je proxies verantwoord gebruikt en binnen de servicevoorwaarden van de site blijft.
Meerdere pagina’s automatiseren
Wil je meerdere pagina’s scrapen, zoals productlijsten met paginering? Gebruik een simpele shell-lus:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
Dit haalt pagina 2 tot en met 5 op van de Books to Scrape-catalogus en slaat elke pagina op in een apart bestand. (Pagina 1 is de homepage.)
Beperkingen van webscraping met cURL: wat je moet weten
Hoe graag ik cURL ook gebruik, het is geen wondermiddel. Hier schiet het tekort:
- Geen JavaScript-uitvoering: cURL kan geen pagina’s verwerken die JavaScript nodig hebben om content te renderen of anti-botuitdagingen op te lossen (developers.cloudflare.com).
- Handmatige parsing nodig: Je krijgt ruwe HTML of JSON, maar je moet het zelf parsen — vaak met extra scripts of tools.
- Beperkte sessieafhandeling: Complexe logins, tokens of meerstapsformulieren kunnen snel omslachtig worden.
- Geen ingebouwde datastructurering: cURL zet webpagina’s niet automatisch om in rijen, tabellen of spreadsheets.
- Gevoelig voor anti-botdetectie: Veel sites gebruiken inmiddels geavanceerde botbeveiliging (JavaScript, fingerprinting, CAPTCHA’s) die cURL simpelweg niet kan omzeilen (datadome.co).
Hier is een snelle vergelijkingstabel:
| Beperking | cURL alleen | Moderne scrapingtools (bijv. Thunderbit) |
|---|---|---|
| JavaScript-ondersteuning | Nee | Ja |
| Datastructurering | Handmatig | Automatisch (AI/template) |
| Sessieafhandeling | Handmatig | Automatisch |
| Anti-botomzeiling | Beperkt | Geavanceerd (browsergebaseerd/AI) |
| Gebruiksgemak | Technisch | Niet-technisch |
Voor statische pagina’s en API’s is cURL fantastisch. Voor alles wat dynamischer of beter beveiligd is, wil je een stap verder in de toolchain gaan.
Thunderbit vs. cURL: de beste webscrapingaanpak voor niet-technische gebruikers
Laten we het nu hebben over Thunderbit, onze AI-aangedreven Chrome-extensie voor webscraping. Als je een salesmedewerker, marketeer of operations-professional bent die gewoon data van een website naar Excel, Google Sheets of Notion wil krijgen — zonder de command-line aan te raken — dan is Thunderbit voor jou gemaakt.
Zo verhoudt Thunderbit zich tot cURL:
| Functie | cURL | Thunderbit |
|---|---|---|
| Gebruikersinterface | Command-line | Point-and-click (Chrome-extensie) |
| AI-veldsuggestie | Nee | Ja (AI leest de pagina en stelt kolommen voor) |
| Paginering/subpagina’s verwerken | Handmatig scripten | Automatisch (AI detecteert en scrapt) |
| Data-export | Handmatig (parsen + opslaan) | Direct naar Excel, Google Sheets, Notion, Airtable |
| JavaScript/beveiligde pagina’s | Nee | Ja (browsergebaseerde scraping) |
| Geen code nodig | Nee (vereist scripting) | Ja (iedereen kan het gebruiken) |
| Gratis laag | Altijd gratis | Gratis tot 6 pagina’s (10 met proefboost) |
Met Thunderbit open je gewoon de extensie, klik je op “AI Suggest Fields” en laat je de AI uitzoeken welke data moet worden opgehaald. Je kunt tabellen, lijsten, productdetails en zelfs subpagina’s automatisch scrapen. Daarna exporteer je je data direct naar je favoriete zakelijke tools — zonder parsing, zonder gedoe.
Thunderbit wordt vertrouwd door meer dan 100.000 gebruikers wereldwijd en is vooral populair bij sales-, ecommerce- en vastgoedteams die snel gestructureerde data nodig hebben.
Probeer de Thunderbit Chrome-extensie voor webscraping
Wil je het proberen? Download de Chrome-extensie hier.
cURL en Thunderbit combineren: flexibele webscrapingstrategieën
Als je technisch bent, hoef je niet maar één tool te kiezen. Sterker nog: veel teams gebruiken cURL en Thunderbit samen voor maximale flexibiliteit:
- Prototypen met cURL: Gebruik cURL om snel endpoints te testen, headers te inspecteren en te begrijpen hoe een site reageert.
- Opschalen met Thunderbit: Wanneer je gestructureerde data, scraping over meerdere pagina’s of een herhaalbare workflow nodig hebt, schakel je over naar Thunderbit voor point-and-click-extractie en directe exports.
Hier is een voorbeeldworkflow voor marktonderzoek:
- Gebruik cURL om een paar pagina’s op te halen en de HTML-structuur te bekijken.
- Bepaal welke gegevensvelden je wilt (bijv. productnamen, prijzen, reviews).
- Open Thunderbit, klik op “AI Suggest Fields” en laat de AI de scraper opzetten.
- Scrape alle pagina’s (inclusief subpagina’s of lijsten met paginering) en exporteer naar Google Sheets.
- Analyseer, deel en gebruik je data — zonder handmatige parsing.
Hier is een snelle beslissingstabel:
| Scenario | Gebruik cURL | Gebruik Thunderbit | Gebruik beide |
|---|---|---|---|
| Snelle API- of statische pagina-opvraag | ✅ | ||
| Gestructureerde data in een spreadsheet nodig | ✅ | ||
| Headers/cookies debuggen | ✅ | ||
| Dynamische/JavaScript-zware pagina’s scrapen | ✅ | ||
| Een herhaalbare no-code workflow bouwen | ✅ | ||
| Prototypen en daarna opschalen | ✅ | ✅ | Hybride workflow |
Veelvoorkomende uitdagingen en valkuilen bij webscraping met cURL
Voordat je helemaal losgaat met cURL, laten we het hebben over de praktijkproblemen die je waarschijnlijk tegenkomt:
- Anti-botsystemen: Veel sites gebruiken inmiddels geavanceerde verdediging (JavaScript-challenges, CAPTCHA’s, fingerprinting) die cURL niet kan omzeilen (developers.cloudflare.com).
- Problemen met datakwaliteit: HTML-wijzigingen, ontbrekende velden of inconsistente lay-outs kunnen je scripts breken.
- Onderhoudslast: Elke keer dat een site verandert, moet je je parsinglogica bijwerken.
- Juridische en compliance-risico’s: Controleer altijd de servicevoorwaarden, robots.txt en relevante wetgeving van een site voordat je gaat scrapen. Alleen omdat data openbaar is, betekent nog niet dat je die vrij mag gebruiken (calawyers.org, polsinelli.com).
- Schaalbeperkingen: cURL is geweldig voor kleine taken, maar voor grootschalige scraping moet je proxies, rate limits en foutafhandeling beheren.
Tips voor troubleshooting en naleving:
- Begin altijd met toegestane of demo-sites (zoals Books to Scrape).
- Respecteer rate limits — ga endpoints niet overbelasten.
- Vermijd het scrapen van persoonlijke data, tenzij je daar een wettelijke grondslag voor hebt.
- Loop je tegen JavaScript- of CAPTCHA-muren aan, overweeg dan over te stappen op een browsergebaseerde tool zoals Thunderbit.
Stapsgewijze samenvatting: websites scrapen met cURL
Hier is je snelreferentie-checklist voor webscraping met cURL:
- Bepaal je doel-URL’s: Begin met een statische pagina of API-endpoint.
- Haal de pagina op:
curl URL - Sla de uitvoer op in een bestand:
curl -o bestand.html URL - Inspecteer headers/debug:
curl -I URL,curl -v URL - Verstuur POST-data:
curl -d "a=1&b=2" URL - Beheer cookies/sessies:
curl -c cookies.txt ...,curl -b cookies.txt ... - Stel custom headers/User-Agent in:
curl -A "..." -H "..." URL - Volg redirects:
curl -L URL - Gebruik proxies (indien nodig):
curl -x proxy:poort URL - Automatiseer scraping over meerdere pagina’s: Gebruik shell-lussen of scripts.
- Parse en structureer data: Gebruik indien nodig extra tools/scripts.
- Schakel over naar Thunderbit voor gestructureerde, no-code scraping of dynamische pagina’s.
Conclusie en belangrijkste inzichten: de juiste webscrapingtool kiezen
Scrape data van elke website met AI Get Started Free
Webscraping met cURL is in 2026 nog steeds een krachtige vaardigheid voor technische gebruikers — vooral voor snelle data-opvragingen, prototypen en automatisering. De snelheid, scriptbaarheid en alomtegenwoordigheid van cURL maken het een vaste waarde in de gereedschapskist van elke developer. Maar nu het web dynamischer en beter beveiligd wordt, en zakelijke gebruikers gestructureerde data willen zonder code, herdefiniëren tools zoals Thunderbit wat er mogelijk is.
Belangrijkste inzichten:
- Gebruik cURL voor statische pagina’s, API’s en snelle prototypes — vooral wanneer je volledige controle wilt.
- Schakel over naar Thunderbit (of vergelijkbare AI-webscrapers) wanneer je gestructureerde data nodig hebt, dynamische/JavaScript-zware pagina’s wilt verwerken of een no-code, zakelijke workflow zoekt.
- Combineer beide voor maximale flexibiliteit: prototypeer met cURL, schaal op en structureer met Thunderbit.
- Scrape altijd verantwoord — respecteer sitevoorwaarden, rate limits en juridische grenzen.
Nieuwsgierig hoe eenvoudig webscraping kan zijn? Probeer de gratis Chrome-extensie van Thunderbit en ervaar zelf AI-aangedreven data-extractie. En als je dieper wilt gaan, bekijk dan de Thunderbit Blog voor meer tutorials, tips en branche-inzichten. Misschien vind je dit ook interessant:
- Hoe je elke website kunt scrapen met AI
- Hoe je websitegegevens naar Excel scrapt met AI
- Wat is data scraping en hoe doe je het in 2025
Veel scrapeplezier — en moge je data altijd schoon, gestructureerd en slechts één commando (of klik) verwijderd zijn.
Ontdek Thunderbit-abonnementen voor schaalbare webscraping
FAQ’s
1. Kan cURL webpagina’s met JavaScript renderen verwerken?
Nee, cURL kan JavaScript niet uitvoeren. Het haalt ruwe HTML op zoals die door de server wordt aangeleverd. Als een pagina JavaScript nodig heeft om content te renderen of anti-botuitdagingen op te lossen, kan cURL die data niet bereiken. Gebruik in die gevallen browsergebaseerde tools zoals Thunderbit.
2. Hoe sla ik cURL-uitvoer direct op in een bestand?
Gebruik de -o-vlag: curl -o bestandsnaam.html URL. Daarmee schrijf je de response body naar een bestand in plaats van die in je terminal te tonen.
3. Wat is het verschil tussen cURL en Thunderbit voor webscraping?
cURL is een command-line tool voor het ophalen van ruwe webdata — ideaal voor technische gebruikers en automatisering. Thunderbit is een AI-aangedreven Chrome-extensie voor zakelijke gebruikers die gestructureerde data van elke website willen halen, dynamische pagina’s willen verwerken en direct willen exporteren naar tools zoals Excel of Google Sheets — zonder code.
4. Is het legaal om websites te scrapen met cURL?
Het scrapen van openbare data is in de VS over het algemeen legaal na recente rechterlijke uitspraken, maar controleer altijd de servicevoorwaarden, robots.txt en relevante wetgeving van de website. Vermijd het scrapen van persoonlijke of beschermde data zonder toestemming en respecteer rate limits en ethische richtlijnen (calawyers.org, polsinelli.com).
5. Wanneer moet ik overstappen van cURL naar een geavanceerdere tool zoals Thunderbit?
Als je dynamische/JavaScript-zware pagina’s moet scrapen, gestructureerde data in een spreadsheet wilt of liever een no-code workflow gebruikt, dan is Thunderbit de betere keuze. Gebruik cURL voor snelle, technische taken; gebruik Thunderbit voor zakelijke, herhaalbare data-extractie.
Voor meer webscrapingtips en tutorials kun je de Thunderbit Blog bezoeken of ons YouTube-kanaal bekijken.
Probeer Thunderbit AI-webscraper Get Started Free




