
Laten we eerlijk zijn: als je ooit hebt geprobeerd om bedrijfsdata te verzamelen, ben je waarschijnlijk de discussie ‘web scraping vs. data mining’ al eens tegengekomen. Ik heb teams daar eindeloos over zien discussiëren — de ene kant wil elk stukje informatie van het web halen, de andere wil het juist analyseren voor diepere inzichten. En soms zit iedereen uiteindelijk alleen nog naar een spreadsheet te staren met de vraag: ‘Wacht even, wat doen we hier eigenlijk?’ Herkenbaar? Dan ben je zeker niet de enige.
Als iemand die jarenlang SaaS- en automatiseringstools heeft gebouwd (en nu medeoprichter is van ), heb ik deze verwarring overal zien opduiken: van salesafdelingen tot boardrooms. Dus laten we door de jargonlaag heen prikken en het praktisch maken: wat is nu echt het verschil tussen web scraping en data mining, wie gebruikt wat, en — belangrijker nog — hoe laat je ze samenwerken zodat je team er echt resultaat mee boekt?
Web scraping vs. data mining: snelle definities voor drukke teams
Laten we het simpel houden, geen techwoordenboek nodig.
- Web scraping: het verzamelen van gegevens van websites. Zie het als een geautomatiseerde manier om informatie van het web naar een spreadsheet te kopiëren en plakken. Webscrapingtools scannen webpagina’s, halen specifieke informatie eruit (zoals productprijzen, bedrijfsnamen of artikelen) en zetten die om in een gestructureerd formaat (rijen en kolommen). In dit stadium gebeurt nog geen analyse — het draait puur om het verzamelen van de ruwe data die je nodig hebt.
- Data mining: hier begint de echte waarde, zodra je de data hebt. Data mining betekent datasets analyseren — met statistiek, algoritmen of AI — om trends, patronen en inzichten bloot te leggen. Het is alsof je die grote spreadsheet pakt en uitzoekt wat die eigenlijk vertelt: klanten segmenteren, omzet voorspellen of fraude opsporen.
De vergelijking die ik altijd gebruik:
Web scraping is ingrediënten halen in de supermarkt; data mining is er een maaltijd van maken. Je hebt beide nodig als je meer wilt dan alleen een stapel boodschappen.
Wie gebruikt web scraping vs. data mining — en waarom?
Hier wordt het interessant. Het verschil is niet alleen ‘verzamelen vs. analyseren’ — het gaat erom wie wat doet, en waarom.
Wie gebruikt web scraping?
Typische gebruikers:
- Verkoopteams (leadlijsten opbouwen, contactgegevens verzamelen)
- Marketingteams (marktinformatie, concurrentiemonitoring)
- Operations (prijsmonitoring, inzichten in de supply chain)
- Onderzoeksteams (vastgoed, finance, enz.)
Hun doel:
Snel verse, externe data binnenhalen. Of het nu gaat om duizenden productprijzen ophalen, LinkedIn scrapen voor leads, of lanceringen van concurrenten volgen: deze mensen hebben actuele info nodig voor hun dagelijkse beslissingen (, ).
Wie gebruikt data mining?
Typische gebruikers:
- Data-analisten en business intelligence-(BI)-teams
- Data scientists
- Productmanagers en strategieteams
Hun doel:
Betekenis vinden in de data. Deze mensen nemen ruwe informatie — of die nu van het web is gescrapet of uit interne systemen komt — en zoeken naar patronen, trends en bruikbare inzichten. Ze zijn minder bezig met hoe de data is verzameld en meer met wat die hen kan vertellen ().
Scenario-overzicht: wie doet wat?
| Rol | Voorbeeld van web scraping | Voorbeeld van data mining |
|---|---|---|
| Sales | Bedrijvengidsen scrapen voor leads | Analyseren welke leads het best converteren |
| Marketing | Productlanceringen van concurrenten scrapen | Klanten segmenteren op koopgedrag |
| Operations | Dagelijks prijzen van leveranciers scrapen | Vraag voorspellen, voorraad optimaliseren |
| BI/Data Science | (Scrapen meestal niet zelf) | Voorspellende modellen bouwen, trends vinden |
| Productmanagement | App-storebeoordelingen scrapen voor feedback | Functiegaten identificeren, roadmap prioriteren |
Web scraping: websites omzetten in bedrijfsklare data
Laten we eerlijk zijn: het internet is een goudmijn aan bedrijfsdata, maar het grootste deel zit verstopt in rommelige, ongestructureerde webpagina’s. Web scraping is de sleutel waarmee je die data ontsluit en omzet in iets waar je team echt iets aan heeft.
Waarom web scraping belangrijk is, vooral voor niet-technische teams
- Bespaart tijd: geen stagiairs meer die dagenlang zitten te kopiëren en plakken. Een scraper haalt in minuten duizenden datapunten op.
- Schaalbaar: wil je elke dag 50 websites van concurrenten monitoren? Met scraping kan dat.
- Houdt je actueel: krijg realtime-updates over prijzen, voorraad of nieuws — zonder handmatig werk.
Het grotere plaatje: schat de webscrapingmarkt op USD 1,17 miljard in 2026, oplopend naar USD 2,23 miljard in 2031. En volgens een BrowserCat-enquête uit 2024 die in dat rapport wordt aangehaald, gebruikte 65% van de ondernemingen web scraping al om AI- en machinelearningprojecten te voeden — precies het deel van de workflow dat adoptie uit IT trekt en naar sales-, marketing- en operationele teams brengt.
Praktische use cases
- Leadgeneratie: openbare gidsen of sociale netwerken scrapen voor namen, e-mails en telefoonnummers.
- Prijsmonitoring: prijzen of productbeschikbaarheid van concurrenten realtime volgen. De adoptie is inmiddels mainstream: meldt dat 81% van de Amerikaanse retailers nu geautomatiseerde prijs-scraping gebruikt voor dynamische herprijzing, tegenover 34% in 2020 (oorspronkelijk onderzocht door Actowiz Solutions).
- Marktonderzoek: online reviews bundelen, sociale media scrapen op sentiment of nieuwssites monitoren op trends.
- Data-anrijking: je CRM verrijken met verse info van bedrijfswebsites of LinkedIn.
- Vastgoed & finance: vastgoedaanbiedingen, financieel nieuws of alternatieve data scrapen voor beleggingsonderzoek ().
En hier komt de clou: je hoeft geen programmeur meer te zijn. Een groeiend aantal nieuwere scrapingtools — Octoparse, Browse AI, Bardeen, Thunderbit — wordt standaard geleverd met drag-and-drop- of point-and-click-instellingen, en niet als extra coderingsmodus. Alleen al daardoor is scraping verschoven van de engineering-backlog naar de bureaus van sales en operations.
Hoe Thunderbit web scraping voor iedereen eenvoudiger maakt
Ik geef toe: toen we begonnen met bouwen aan , was ons doel simpel: web scraping net zo makkelijk maken als een stagiair vragen om data te kopiëren en plakken — alleen is die ‘stagiair’ een AI-agent die nooit slaapt, nooit moppert en nooit wordt afgeleid door kattenfilmpjes.
Zo overbrugt Thunderbit de kloof tussen dataverzameling en bedrijfsanalyse:
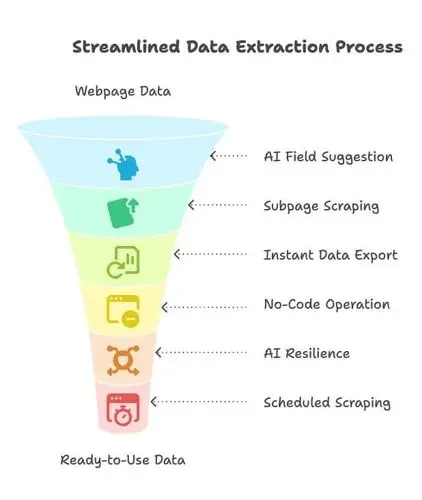
- AI Suggest Fields: klik gewoon op “AI Suggest Fields” en Thunderbit’s AI scant de pagina, adviseert welke datavelden je moet extraheren en stelt kolomnamen voor. Geen gedoe meer met HTML of selectors — je kiest gewoon wat je nodig hebt ().
- Subpage Scraping: meer details nodig van subpagina’s (zoals productdetails of functiebeschrijvingen)? Thunderbit kan automatisch doorklikken, de extra info ophalen en aan je dataset toevoegen.
- Directe data-export: met één klik exporteren naar Excel, Google Sheets, Airtable, Notion of CSV/JSON. Geen verborgen kosten, geen omwegen — je data is direct bruikbaar.
- No-code, point-and-click: Thunderbit draait in je browser. Selecteer wat je wilt, en klaar. Zelfs als je nog nooit hebt gescrapet, ben je binnen enkele minuten aan de slag.
- AI-gedreven robuustheid: websites veranderen voortdurend, maar Thunderbit’s AI past zich automatisch aan veel layoutwijzigingen aan. Minder onderhoud, minder frustratie.
- Gepland scrapen & AI Autofill: laat scrapes volgens een schema draaien of laat AI formulieren en logins voor je invullen. Thunderbit verwerkt zelfs pdf’s, afbeeldingen, e-mails en telefoonnummers in één klik.
De winst? Thunderbit verkleint de skill gap. Sales operations, marketing of zelfs je CEO kan nu zelf een scrape opzetten zonder IT te bellen. Het is de “tussenlaag” die rommelige webdata verbindt met de tools die je echt gebruikt voor analyse.
Wil je het in actie zien? Bekijk onze of duik in meer use cases op de .
Data mining: inzichten halen uit je verzamelde data
Oké, je hebt een berg data gescrapet. En nu? Hier komt data mining in beeld.
Wat is data mining? In gewoon Nederlands
Data mining is het analyseren van grote datasets om verborgen patronen, verbanden of afwijkingen te vinden die zakelijke inzichten opleveren. Het gaat om het omzetten van ruwe cijfers in bruikbare kennis — zoals ontdekken dat klanten die product A kopen ook vaak product B kopen, of dat bepaald gedrag wijst op een hoog risico op churn.
Veelvoorkomende zakelijke doelen
- Trendontdekking & voorspelling: verkooptrends, seizoenspatronen of marktverschuivingen herkennen — en voorspellen wat er daarna komt.
- Klantsegmentatie: klanten groeperen op gedrag of demografie voor gerichte marketing.
- Anomaliedetectie: uitschieters vinden die kunnen wijzen op fraude, risico of nieuwe kansen.
- Strategisch inzicht: meerdere datasets combineren (intern + gescrapet) om grote beslissingen te ondersteunen — zoals een nieuwe markt betreden of prijzen aanpassen.
Maar er is een addertje onder het gras: data mining is zo goed als de data die je erin stopt. Het oude gezegde “garbage in, garbage out” is pijnlijk waar. Analisten besteden vaak wel aan het opschonen en voorbereiden van data voordat ze die echt kunnen analyseren.
Daarom is gestructureerd web scraping (zoals Thunderbit dat oplevert) zo waardevol — het levert je een schone dataset op die klaar is voor analyse, zodat je analisten meteen aan de slag kunnen met het interessante werk.
Web scraping vs. data mining: een vergelijking naast elkaar
Laten we de twee direct naast elkaar zetten, zodat je precies ziet waar ze verschillen — en waar ze overlappen.
| Aspect | Web scraping | Data mining |
|---|---|---|
| Hoofddoel | Ruwe data verzamelen van websites (data-extractie) | Datasets analyseren om patronen en inzichten te ontdekken (data-analyse) |
| Typische gebruikers | Sales, marketing, operations, onderzoek (vaak niet-technisch, domeinexperts) | Data-analisten, BI-teams, data scientists, strategiemanagers (analytische/technische rollen) |
| Databronnen | Webpagina’s, online bronnen, openbare gidsen, API’s | Gestructureerde datasets: gescrapete data, interne databases, CSV’s, datawarehouses |
| Proces & tools | Crawlen, extraheren (no-code tools zoals Thunderbit, browserextensies) | Data-analyse (BI-tools, Python/R, SQL, machinelearningplatforms) |
| Output | Gestructureerde dataset (CSV, spreadsheet, databasetabel) | Inzichten, rapporten, dashboards, voorspellende modellen |
| Voorbeeld-use cases | Prijzen van concurrenten samenstellen, sociale vermeldingen scrapen, aanbiedingen ophalen | Klanten segmenteren, churn voorspellen, leads scoren |
| Grote uitdagingen | Wijzigingen op websites, anti-scrapingmaatregelen, datakwaliteit, juridisch/ethisch | Vervuilde/onvolledige data, juiste modellen kiezen, privacy, resultaten interpreteren |
Belangrijkste conclusie:
Web scraping is de “brandstof” (data), data mining is de “motor” (inzicht). Je hebt beide nodig om ergens heen te rijden.
Hoe web scraping en data mining samenwerken in het bedrijfsleven
Hier gebeurt de echte magie: web scraping en data mining zijn geen concurrenten — ze zijn teamgenoten. Zie ze als de upstream en downstream van je dataworkflow.
Scenario 1: marktinformatie
- Stap 1: scrape productvermeldingen, prijzen en reviews van concurrenten op meerdere sites.
- Stap 2: mine de data op trends — kijk waar marktkansen liggen, identificeer veelvoorkomende klachten van klanten of volg prijswijzigingen door de tijd heen.
- Resultaat: bruikbare inzichten voor productstrategie of prijsstelling.
Scenario 2: scoringsmodel voor salesleads
- Stap 1: scrape LinkedIn of bedrijvengidsen om je lead-database te verrijken met bedrijfsomvang, sector en recent nieuws.
- Stap 2: analyseer welke kenmerken samenhangen met hoge conversieratio’s en prioriteer leads daarop.
- Resultaat: je salesteam richt zich op de beste prospects, niet alleen op de langste lijst.
Scenario 3: prijsoptimalisatie
- Stap 1: scrape realtime prijzen en voorraadniveaus van concurrenten.
- Stap 2: voer die data in je prijsalgoritmen in om je eigen prijzen dynamisch aan te passen.
- Resultaat: je blijft concurrerend en maximaliseert je omzet.
Het risico van ze als losse activiteiten te behandelen?
Als je alleen scrapt en nooit analyseert, verdrink je in data maar blijf je hongerig naar inzicht. Als je alleen interne data analyseert, mis je de bredere marktcontext. De beste teams gebruiken beide — scraping voor een complete dataset, mining voor betekenisvolle inzichten ().
Veelvoorkomende uitdagingen bij web scraping en data mining oplossen
Laten we realistisch zijn: zowel web scraping als data mining brengen hun eigen hoofdpijn met zich mee. Zo pak je de grootste problemen aan (en zo helpt Thunderbit):
1. Datakwaliteit en opschoning
- Probleem: gescrapete data kan rommelig zijn — ontbrekende velden, inconsistente formaten, duplicaten.
- Oplossing: gebruik tools waarmee je tijdens het extraheren kunt opschonen. Thunderbit kan data direct formatteren en categoriseren met AI, zodat je output direct klaar is voor analyse (). Controleer je data altijd steekproefsgewijs voordat je de analyse induikt.
2. Wijzigingen op websites en anti-scrapingmaatregelen
- Probleem: websites veranderen hun layout, voegen CAPTCHA’s toe of blokkeren bots.
- Oplossing: gebruik AI-gedreven scrapers zoals Thunderbit die zich automatisch aanpassen aan layoutwijzigingen. Respecteer
robots.txt, belast sites niet te zwaar en overweeg proxies indien nodig ().
3. Juridische en ethische zorgen
- Probleem: openbare data scrapen is in het algemeen legaal, maar privacywetgeving en voorwaarden van websites zijn wel degelijk van belang.
- Oplossing: bekijk altijd de gebruiksvoorwaarden van de site, richt je op openbare data, anonimiseer waar mogelijk en houd je aan de AVG/CCPA. Wees een “ethische databurger” — je reputatie is meer waard dan welke dataset dan ook ().
4. Van data naar bruikbare inzichten
- Probleem: teams verzamelen data maar krijgen die lastig omgezet in beslissingen.
- Oplossing: begin met heldere zakelijke vragen, gebruik visualisatie en betrek domeinexperts bij het interpreteren van de resultaten. Integreer inzichten in workflows (bijvoorbeeld door risicovolle klanten in je CRM te markeren).
5. Tooling- en skills-gap
- Probleem: niet elk team heeft programmeurs of data scientists.
- Oplossing: benut gebruiksvriendelijke no-code tools zoals Thunderbit voor scraping, en moderne BI-platformen voor mining. Investeer in basiskennis datageletterdheid — soms is een simpele draaitabel al genoeg.
De juiste aanpak kiezen: web scraping, data mining of allebei?
Hoe bepaal je nu wat je nodig hebt? Hier is een snelle beslisgids:
- Heb je de data die je nodig hebt al?
- Nee: begin met web scraping om die te verzamelen.
- Ja: ga verder met data mining om inzichten te halen.
- Gaan je vragen over de buitenwereld of interne patronen?
- Extern (concurrenten, markt, leads): web scraping.
- Intern (klantgedrag, verkooptrends): data mining.
- Heb je beide nodig?
- Dat is in de meeste praktijkprojecten zo! Scrape externe data en mine die vervolgens (samen met je interne data) voor het volledige beeld.
- Teamcapaciteiten:
- Geen programmeervaardigheden? Gebruik no-code scrapingtools zoals Thunderbit.
- Geen data scientists? Gebruik gebruiksvriendelijke BI-tools of begin met basisanalyse.
- Tijdsdruk:
- Realtime behoefte? Zet doorlopende scraping en analyse op.
- Eenmalig project? Doe een eenmalige scrape en mine daarna de data.
Checklist:
- “Heb ik intern alle data die ik nodig heb?” Zo niet, scrape dan.
- “Begrijp ik de data die ik al heb?” Zo niet, mine dan.
- “Is het probleem groot genoeg om beide aanpakken te combineren?” Zo ja, doe allebei.
- “Heeft mijn team de juiste skills?” Zo niet, gebruik no-code tools of vraag hulp.
En onthoud: je hoeft niet alles in één keer te doen. Begin klein, draai een pilot en schaal op zodra je resultaat ziet.
Belangrijkste inzichten: data laten werken voor je team
Laten we de kern samenvatten:
- Web scraping en data mining zijn twee stappen in dezelfde reis. Scraping verzamelt de data (vooral uit externe bronnen), mining analyseert die voor inzicht.
- Verschillende rollen, verschillende doelen: sales, marketing en operations gebruiken scraping om data binnen te halen; analisten en BI-teams minen die voor betekenis.
- Ze vullen elkaar aan, ze concurreren niet: de beste resultaten krijg je door beide te combineren — scraping voor een rijke dataset, mining voor bruikbare inzichten.
- No-code tools en AI hebben de drempel verlaagd: Thunderbit en vergelijkbare tools maken scraping toegankelijk voor iedereen. Moderne BI-platformen maken mining ook eenvoudiger.
- Datakwaliteit en ethiek zijn belangrijk: maak je data schoon, respecteer privacy en handel altijd ethisch.
- Laat je use case je aanpak bepalen: begin met je zakelijke vraag en bepaal daarna welke data je nodig hebt en hoe je die gaat analyseren.
- Begin klein en schaal daarna op: gebruik gratis tiers, pilotprojecten en snelle successen om momentum op te bouwen.
Uiteindelijk is het doel om je team in staat te stellen betere beslissingen te nemen met data. Misschien betekent dat dat je salesteam minder tijd kwijt is aan handmatig onderzoek (dankzij scraping), of dat je strategiebesprekingen worden gevoed door echte inzichten (dankzij mining). Hoe dan ook: beide aanpakken combineren is hoe moderne teams hun concurrentievoordeel behalen.
Dus: verzamel die webdata-ingrediënten, kook er inzichten van en serveer je team de bruikbare intelligence die ze nodig hebben. En als je hulp in de keuken nodig hebt, is er om het voorbereidend werk een fluitje van een cent te maken.
Nieuwsgierig om het zelf te proberen? Download de en ontdek hoe makkelijk web scraping kan zijn. Voor meer tips en verhalen vanaf de frontlinie van data, bekijk de .
FAQ's
1. Wat is het belangrijkste verschil tussen web scraping en data mining?
Web scraping is het verzamelen van ruwe data van websites, terwijl data mining die data analyseert om patronen, inzichten of trends te ontdekken. Zie scraping als het verzamelen van ingrediënten en mining als het bereiden van de maaltijd.
2. Wie gebruikt doorgaans web scraping versus data mining?
Web scraping wordt vooral gebruikt door sales-, marketing-, operations- en onderzoeksteams die snel verse, externe data nodig hebben. Data mining wordt gebruikt door analisten, data scientists en productteams die strategische inzichten uit data willen halen.
3. Heb ik programmeerkennis nodig om web scraping te doen?
Niet meer. Tools zoals bieden no-code, AI-gedreven interfaces waarmee iedereen — ongeacht technische achtergrond — data kan scrapen met point-and-click-acties en directe exportfuncties.
4. Hoe werken web scraping en data mining samen?
Web scraping levert de ruwe, gestructureerde data waarop data mining voortbouwt. Samen vormen ze een pipeline: verzamel externe data met scraping en analyseer die daarna met mining om zakelijke beslissingen te sturen.
5. Wat zijn enkele praktijkvoorbeelden voor elk?
Web scraping wordt gebruikt voor taken zoals leadgeneratie, prijsmonitoring en het volgen van concurrenten. Data mining ondersteunt klantsegmentatie, trendvoorspelling, fraudedetectie en strategische planning op basis van de gescrapete data.